Hadoop平台提供离线数据和Storm平台提供实时数据流
本文翻译自: https://github.com/nathanmarz/storm/wiki/Tutorial
Storm是一个分布式的、高容错的实时计算系统。
Storm对于实时计算的的意义相当于Hadoop对于批处理的意义。Hadoop为我们提供了Map和Reduce原语,使我们对数据进行批处理变的非常的简单和优美。同样,Storm也对数据的实时计算提供了简单Spout和Bolt原语。
Storm适用的场景:
1、流数据处理:Storm可以用来用来处理源源不断的消息,并将处理之后的结果保存到持久化介质中。
2、分布式RPC:由于Storm的处理组件都是分布式的,而且处理延迟都极低,所以可以Storm可以做为一个通用的分布式RPC框架来使用。
在这个教程里面我们将学习如何创建Topologies, 并且把topologies部署到storm的集群里面去。Java将是我们主要的示范语言, 个别例子会使用python以演示storm的多语言特性。
1、准备工作
这个教程使用storm-starter项目里面的例子。我推荐你们下载这个项目的代码并且跟着教程一起做。先读一下:配置storm开发环境和新建一个strom项目这两篇文章把你的机器设置好。
2、一个Storm集群的基本组件
storm的集群表面上看和hadoop的集群非常像。但是在Hadoop上面你运行的是MapReduce的Job, 而在Storm上面你运行的是Topology。它们是非常不一样的 — 一个关键的区别是: 一个MapReduce Job最终会结束, 而一个Topology运永远运行(除非你显式的杀掉他)。
在Storm的集群里面有两种节点: 控制节点(master node)和工作节点(worker node)。控制节点上面运行一个后台程序: Nimbus, 它的作用类似Hadoop里面的JobTracker。Nimbus负责在集群里面分布代码,分配工作给机器, 并且监控状态。
每一个工作节点上面运行一个叫做Supervisor的节点(类似 TaskTracker)。Supervisor会监听分配给它那台机器的工作,根据需要 启动/关闭工作进程。每一个工作进程执行一个Topology(类似 Job)的一个子集;一个运行的Topology由运行在很多机器上的很多工作进程 Worker(类似 Child)组成。

storm topology结构
Storm VS MapReduce
Nimbus和Supervisor之间的所有协调工作都是通过一个Zookeeper集群来完成。并且,nimbus进程和supervisor都是快速失败(fail-fast)和无状态的。所有的状态要么在Zookeeper里面, 要么在本地磁盘上。这也就意味着你可以用kill -9来杀死nimbus和supervisor进程, 然后再重启它们,它们可以继续工作, 就好像什么都没有发生过似的。这个设计使得storm不可思议的稳定。
3、Topologies
为了在storm上面做实时计算, 你要去建立一些topologies。一个topology就是一个计算节点所组成的图。Topology里面的每个处理节点都包含处理逻辑, 而节点之间的连接则表示数据流动的方向。
运行一个Topology是很简单的。首先,把你所有的代码以及所依赖的jar打进一个jar包。然后运行类似下面的这个命令。
|
1
|
strom jar all-your-code.jar backtype.storm.MyTopology arg1 arg2 |
这个命令会运行主类: backtype.strom.MyTopology, 参数是arg1, arg2。这个类的main函数定义这个topology并且把它提交给Nimbus。storm jar负责连接到nimbus并且上传jar文件。
因为topology的定义其实就是一个Thrift结构并且nimbus就是一个Thrift服务, 有可以用任何语言创建并且提交topology。上面的方面是用JVM
-based语言提交的最简单的方法, 看一下文章: 在生产集群上运行topology去看看怎么启动以及停止topologies。
4、Stream
Stream是storm里面的关键抽象。一个stream是一个没有边界的tuple序列。storm提供一些原语来分布式地、可靠地把一个stream传输进一个新的stream。比如: 你可以把一个tweets流传输到热门话题的流。
storm提供的最基本的处理stream的原语是spout和bolt。你可以实现Spout和Bolt对应的接口以处理你的应用的逻辑。
spout的流的源头。比如一个spout可能从Kestrel队列里面读取消息并且把这些消息发射成一个流。又比如一个spout可以调用twitter的一个api并且把返回的tweets发射成一个流。
通常Spout会从外部数据源(队列、数据库等)读取数据,然后封装成Tuple形式,之后发送到Stream中。Spout是一个主动的角色,在接口内部有个nextTuple函数,Storm框架会不停的调用该函数。

bolt可以接收任意多个输入stream, 作一些处理, 有些bolt可能还会发射一些新的stream。一些复杂的流转换, 比如从一些tweet里面计算出热门话题, 需要多个步骤, 从而也就需要多个bolt。 Bolt可以做任何事情: 运行函数, 过滤tuple, 做一些聚合, 做一些合并以及访问数据库等等。
Bolt处理输入的Stream,并产生新的输出Stream。Bolt可以执行过滤、函数操作、Join、操作数据库等任何操作。Bolt是一个被动的角色,其接口中有一个execute(Tuple input)方法,在接收到消息之后会调用此函数,用户可以在此方法中执行自己的处理逻辑。
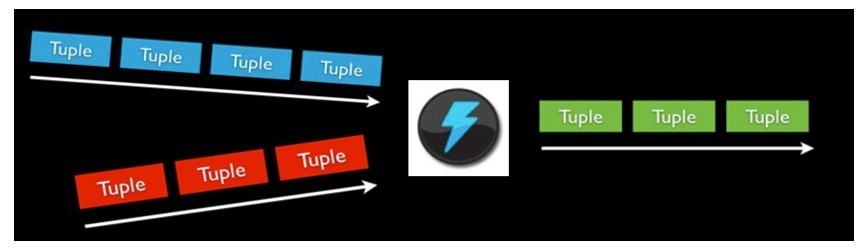
spout和bolt所组成一个网络会被打包成topology, topology是storm里面最高一级的抽象(类似 Job), 你可以把topology提交给storm的集群来运行。topology的结构在Topology那一段已经说过了,这里就不再赘述了。
topology结构
topology里面的每一个节点都是并行运行的。 在你的topology里面, 你可以指定每个节点的并行度, storm则会在集群里面分配那么多线程来同时计算。
一个topology会一直运行直到你显式停止它。storm自动重新分配一些运行失败的任务, 并且storm保证你不会有数据丢失, 即使在一些机器意外停机并且消息被丢掉的情况下。
5、数据模型(Data Model)
storm使用tuple来作为它的数据模型。每个tuple是一堆值,每个值有一个名字,并且每个值可以是任何类型, 在我的理解里面一个tuple可以看作一个没有方法的java对象。总体来看,storm支持所有的基本类型、字符串以及字节数组作为tuple的值类型。你也可以使用你自己定义的类型来作为值类型, 只要你实现对应的序列化器(serializer)。
一个Tuple代表数据流中的一个基本的处理单元,例如一条cookie日志,它可以包含多个Field,每个Field表示一个属性。

Tuple本来应该是一个Key-Value的Map,由于各个组件间传递的tuple的字段名称已经事先定义好了,所以Tuple只需要按序填入各个Value,所以就是一个Value List。
一个没有边界的、源源不断的、连续的Tuple序列就组成了Stream。

topology里面的每个节点必须定义它要发射的tuple的每个字段。 比如下面这个bolt定义它所发射的tuple包含两个字段,类型分别是: double和triple。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
publicclassDoubleAndTripleBoltimplementsIRichBolt { privateOutputCollectorBase _collector; @Override publicvoidprepare(Map conf, TopologyContext context, OutputCollectorBase collector) { _collector = collector; } @Override publicvoidexecute(Tuple input) { intval = input.getInteger(0); _collector.emit(input,newValues(val*2, val*3)); _collector.ack(input); } @Override publicvoidcleanup() { } @Override publicvoiddeclareOutputFields(OutputFieldsDeclarer declarer) { declarer.declare(newFields("double","triple")); }} |
declareOutputFields方法定义要输出的字段 : ["double", "triple"]。这个bolt的其它部分我们接下来会解释。
6、一个简单的Topology
让我们来看一个简单的topology的例子, 我们看一下storm-starter里面的ExclamationTopology:
|
1
2
3
4
5
6
|
TopologyBuilder builder =newTopologyBuilder();builder.setSpout(1,newTestWordSpout(),10);builder.setBolt(2,newExclamationBolt(),3) .shuffleGrouping(1);builder.setBolt(3,newExclamationBolt(),2) .shuffleGrouping(2); |
这个Topology包含一个Spout和两个Bolt。Spout发射单词, 每个bolt在每个单词后面加个”!!!”。这三个节点被排成一条线: spout发射单词给第一个bolt, 第一个bolt然后把处理好的单词发射给第二个bolt。如果spout发射的单词是["bob"]和["john"], 那么第二个bolt会发射["bolt!!!!!!"]和["john!!!!!!"]出来。
我们使用setSpout和setBolt来定义Topology里面的节点。这些方法接收我们指定的一个id, 一个包含处理逻辑的对象(spout或者bolt), 以及你所需要的并行度。
这个包含处理的对象如果是spout那么要实现IRichSpout的接口, 如果是bolt,那么就要实现IRichBolt接口.
最后一个指定并行度的参数是可选的。它表示集群里面需要多少个thread来一起执行这个节点。如果你忽略它那么storm会分配一个线程来执行这个节点。
setBolt方法返回一个InputDeclarer对象, 这个对象是用来定义Bolt的输入。 这里第一个Bolt声明它要读取spout所发射的所有的tuple — 使用shuffle grouping。而第二个bolt声明它读取第一个bolt所发射的tuple。shuffle grouping表示所有的tuple会被随机的分发给bolt的所有task。给task分发tuple的策略有很多种,后面会介绍。
如果你想第二个bolt读取spout和第一个bolt所发射的所有的tuple, 那么你应该这样定义第二个bolt:
|
1
2
3
|
builder.setBolt(3,newExclamationBolt(),5) .shuffleGrouping(1) .shuffleGrouping(2); |
让我们深入地看一下这个topology里面的spout和bolt是怎么实现的。Spout负责发射新的tuple到这个topology里面来。TestWordSpout从["nathan", "mike", "jackson", "golda", "bertels"]里面随机选择一个单词发射出来。TestWordSpout里面的nextTuple()方法是这样定义的:
|
1
2
3
4
5
6
7
8
|
publicvoidnextTuple() { Utils.sleep(100); finalString[] words =newString[] {"nathan","mike", "jackson","golda","bertels"}; finalRandom rand =newRandom(); finalString word = words[rand.nextInt(words.length)]; _collector.emit(newValues(word));} |
可以看到,实现很简单。
ExclamationBolt把”!!!”拼接到输入tuple后面。我们来看下ExclamationBolt的完整实现。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
publicstaticclassExclamationBoltimplementsIRichBolt { OutputCollector _collector; publicvoidprepare(Map conf, TopologyContext context, OutputCollector collector) { _collector = collector; } publicvoidexecute(Tuple tuple) { _collector.emit(tuple,newValues(tuple.getString(0) +"!!!")); _collector.ack(tuple); } publicvoidcleanup() { } publicvoiddeclareOutputFields(OutputFieldsDeclarer declarer) { declarer.declare(newFields("word")); }} |
prepare方法提供给bolt一个Outputcollector用来发射tuple。Bolt可以在任何时候发射tuple — 在prepare, execute或者cleanup方法里面, 或者甚至在另一个线程里面异步发射。这里prepare方法只是简单地把OutputCollector作为一个类字段保存下来给后面execute方法使用。
execute方法从bolt的一个输入接收tuple(一个bolt可能有多个输入源). ExclamationBolt获取tuple的第一个字段,加上”!!!”之后再发射出去。如果一个bolt有多个输入源,你可以通过调用Tuple#getSourceComponent方法来知道它是来自哪个输入源的。
execute方法里面还有其它一些事情值得一提: 输入tuple被作为emit方法的第一个参数,并且输入tuple在最后一行被ack。这些呢都是Storm可靠性API的一部分,后面会解释。
cleanup方法在bolt被关闭的时候调用, 它应该清理所有被打开的资源。但是集群不保证这个方法一定会被执行。比如执行task的机器down掉了,那么根本就没有办法来调用那个方法。cleanup设计的时候是被用来在local mode的时候才被调用(也就是说在一个进程里面模拟整个storm集群), 并且你想在关闭一些topology的时候避免资源泄漏。
最后,declareOutputFields定义一个叫做”word”的字段的tuple。
以local mode运行ExclamationTopology
让我们看看怎么以local mode运行ExclamationToplogy。
storm的运行有两种模式: 本地模式和分布式模式. 在本地模式中, storm用一个进程里面的线程来模拟所有的spout和bolt. 本地模式对开发和测试来说比较有用。 你运行storm-starter里面的topology的时候它们就是以本地模式运行的, 你可以看到topology里面的每一个组件在发射什么消息。
在分布式模式下, storm由一堆机器组成。当你提交topology给master的时候, 你同时也把topology的代码提交了。master负责分发你的代码并且负责给你的topolgoy分配工作进程。如果一个工作进程挂掉了, master节点会把认为重新分配到其它节点。关于如何在一个集群上面运行topology, 你可以看看Running topologies on a production cluster文章。
下面是以本地模式运行ExclamationTopology的代码:
|
1
2
3
4
5
6
7
8
9
|
Config conf =newConfig();conf.setDebug(true);conf.setNumWorkers(2); LocalCluster cluster =newLocalCluster();cluster.submitTopology("test", conf, builder.createTopology());Utils.sleep(10000);cluster.killTopology("test");cluster.shutdown(); |
首先, 这个代码定义通过定义一个LocalCluster对象来定义一个进程内的集群。提交topology给这个虚拟的集群和提交topology给分布式集群是一样的。通过调用submitTopology方法来提交topology, 它接受三个参数:要运行的topology的名字,一个配置对象以及要运行的topology本身。
topology的名字是用来唯一区别一个topology的,这样你然后可以用这个名字来杀死这个topology的。前面已经说过了, 你必须显式的杀掉一个topology, 否则它会一直运行。
Conf对象可以配置很多东西, 下面两个是最常见的:
- TOPOLOGY_WORKERS(setNumWorkers) 定义你希望集群分配多少个工作进程给你来执行这个topology. topology里面的每个组件会被需要线程来执行。每个组件到底用多少个线程是通过setBolt和setSpout来指定的。这些线程都运行在工作进程里面. 每一个工作进程包含一些节点的一些工作线程。比如, 如果你指定300个线程,60个进程, 那么每个工作进程里面要执行6个线程, 而这6个线程可能属于不同的组件(Spout, Bolt)。你可以通过调整每个组件的并行度以及这些线程所在的进程数量来调整topology的性能。
- TOPOLOGY_DEBUG(setDebug), 当它被设置成true的话, storm会记录下每个组件所发射的每条消息。这在本地环境调试topology很有用, 但是在线上这么做的话会影响性能的。
感兴趣的话可以去看看Conf对象的Javadoc去看看topology的所有配置。
可以看看创建一个新storm项目去看看怎么配置开发环境以使你能够以本地模式运行topology.
运行中的Topology主要由以下三个组件组成的:
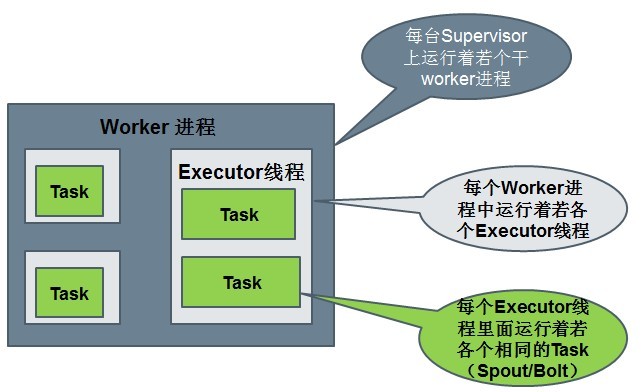
Spout或者Bolt的Task个数一旦指定之后就不能改变了,而Executor的数量可以根据情况来进行动态的调整。默认情况下# executor = #tasks即一个Executor中运行着一个Task


7、流分组策略(Stream grouping)
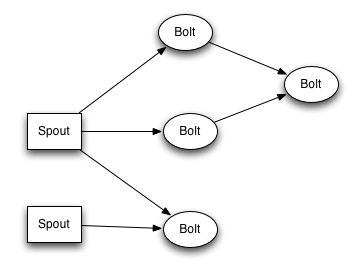
流分组策略告诉topology如何在两个组件之间发送tuple。 要记住, spouts和bolts以很多task的形式在topology里面同步执行。如果从task的粒度来看一个运行的topology, 它应该是这样的:
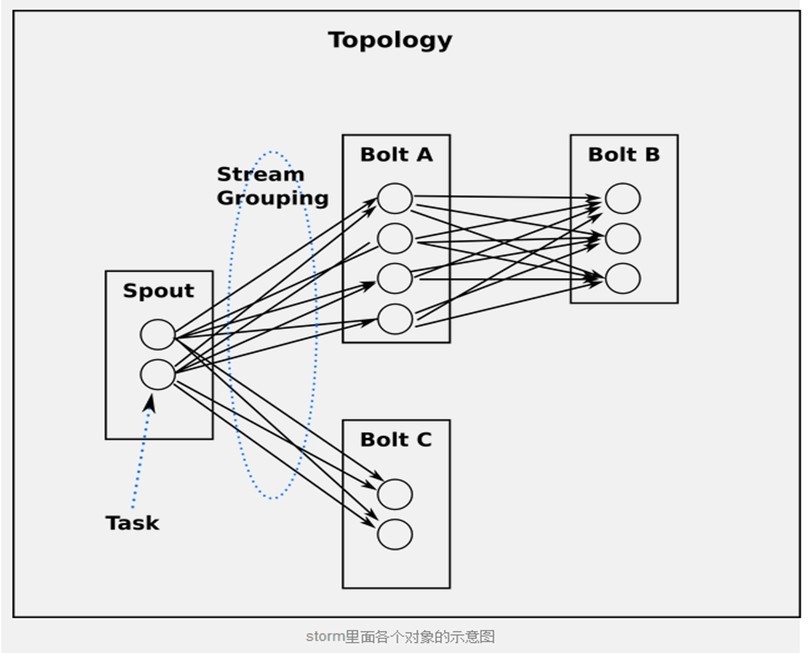
从task角度来看topology
当Bolt A的一个task要发送一个tuple给Bolt B, 它应该发送给Bolt B的哪个task呢?
stream grouping专门回答这种问题的。在我们深入研究不同的stream grouping之前, 让我们看一下storm-starter里面的另外一个topology。WordCountTopology读取一些句子, 输出句子里面每个单词出现的次数.
|
1
2
3
4
5
6
7
|
TopologyBuilder builder =newTopologyBuilder(); builder.setSpout(1,newRandomSentenceSpout(),5);builder.setBolt(2,newSplitSentence(),8) .shuffleGrouping(1);builder.setBolt(3,newWordCount(),12) .fieldsGrouping(2,newFields("word")); |
SplitSentence对于句子里面的每个单词发射一个新的tuple, WordCount在内存里面维护一个单词->次数的mapping, WordCount每收到一个单词, 它就更新内存里面的统计状态。
有好几种不同的stream grouping:
- 最简单的grouping是shuffle grouping, 它随机发给任何一个task。上面例子里面RandomSentenceSpout和SplitSentence之间用的就是shuffle grouping, shuffle grouping对各个task的tuple分配的比较均匀。
- 一种更有趣的grouping是fields grouping, SplitSentence和WordCount之间使用的就是fields grouping, 这种grouping机制保证相同field值的tuple会去同一个task, 这对于WordCount来说非常关键,如果同一个单词不去同一个task, 那么统计出来的单词次数就不对了。
fields grouping是stream合并,stream聚合以及很多其它场景的基础。在背后呢, fields grouping使用的一致性哈希来分配tuple的。
还有一些其它类型的stream grouping. 你可以在Concepts一章里更详细的了解。
下面是一些常用的 “路由选择” 机制:
Storm的Grouping即消息的Partition机制。当一个Tuple被发送时,如何确定将它发送个某个(些)Task来处理??
8、使用别的语言来定义Bolt
Bolt可以使用任何语言来定义。用其它语言定义的bolt会被当作子进程(subprocess)来执行, storm使用JSON消息通过stdin/stdout来和这些subprocess通信。这个通信协议是一个只有100行的库, storm团队给这些库开发了对应的Ruby, Python和Fancy版本。
下面是WordCountTopology里面的SplitSentence的定义:
|
1
2
3
4
5
6
7
8
9
|
publicstaticclassSplitSentenceextendsShellBoltimplementsIRichBolt { publicSplitSentence() { super("python","splitsentence.py"); } publicvoiddeclareOutputFields(OutputFieldsDeclarer declarer) { declarer.declare(newFields("word")); }} |
SplitSentence继承自ShellBolt并且声明这个Bolt用python来运行,并且参数是: splitsentence.py。下面是splitsentence.py的定义:
|
1
2
3
4
5
6
7
8
9
|
importstorm classSplitSentenceBolt(storm.BasicBolt): defprocess(self, tup): words=tup.values[0].split(" ") forwordinwords: storm.emit([word]) SplitSentenceBolt().run() |
更多有关用其它语言定义Spout和Bolt的信息, 以及用其它语言来创建topology的 信息可以参见: Using non-JVM languages with Storm.
9、可靠的消息处理
在这个教程的前面,我们跳过了有关tuple的一些特征。这些特征就是storm的可靠性API: storm如何保证spout发出的每一个tuple都被完整处理。看看《storm如何保证消息不丢失》以更深入了解storm的可靠性API.
Storm允许用户在Spout中发射一个新的源Tuple时为其指定一个MessageId,这个MessageId可以是任意的Object对象。多个源Tuple可以共用同一个MessageId,表示这多个源Tuple对用户来说是同一个消息单元。Storm的可靠性是指Storm会告知用户每一个消息单元是否在一个指定的时间内被完全处理。完全处理的意思是该MessageId绑定的源Tuple以及由该源Tuple衍生的所有Tuple都经过了Topology中每一个应该到达的Bolt的处理。
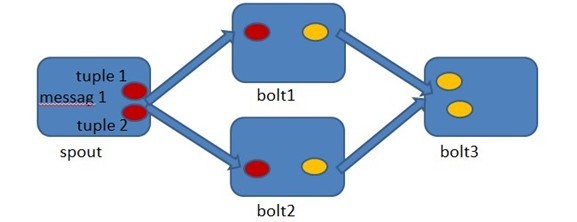
在Spout中由message 1绑定的tuple1和tuple2分别经过bolt1和bolt2的处理,然后生成了两个新的Tuple,并最终流向了bolt3。当bolt3处理完之后,称message 1被完全处理了。
Storm中的每一个Topology中都包含有一个Acker组件。Acker组件的任务就是跟踪从Spout中流出的每一个messageId所绑定的Tuple树中的所有Tuple的处理情况。如果在用户设置的最大超时时间内这些Tuple没有被完全处理,那么Acker会告诉Spout该消息处理失败,相反则会告知Spout该消息处理成功。
那么Acker是如何记录Tuple的处理结果呢??
A xor A = 0.
A xor B…xor B xor A = 0,其中每一个操作数出现且仅出现两次。
在Spout中,Storm系统会为用户指定的MessageId生成一个对应的64位的整数,作为整个Tuple Tree的RootId。RootId会被传递给Acker以及后续的Bolt来作为该消息单元的唯一标识。同时,无论Spout还是Bolt每次新生成一个Tuple时,都会赋予该Tuple一个唯一的64位整数的Id。
当Spout发射完某个MessageId对应的源Tuple之后,它会告诉Acker自己发射的RootId以及生成的那些源Tuple的Id。而当Bolt处理完一个输入Tuple并产生出新的Tuple时,也会告知Acker自己处理的输入Tuple的Id以及新生成的那些Tuple的Id。Acker只需要对这些Id进行异或运算,就能判断出该RootId对应的消息单元是否成功处理完成了。
10、单机版安装指南
环境:centos 6.4
安装步骤请参考:http://blog.sina.com.cn/s/blog_546abd9f0101cce8.html
要注意上面的本地模式运行WordCount其实并没有使用到上述安装的工具,只是一个storm的虚拟环境下测试demo。那我们怎样将程序运行在刚刚搭建的单机版的环境里面呢,
很简单,官方的例子:
注意看官方实例中WordCountTopology类如果不带参数其实是执行的本地模式,也就是刚说的虚拟的环境,带上参数就是将jar发送到了storm执行了。
首先弄好环境:
启动zookeeper:
/usr/local/zookeeper/bin/zkServer.sh 单机版直接启动,不用修改什么配置,如集群就需要修改zoo.cfg另一篇文章会讲到。
配置storm:
文件在/usr/local/storm/conf/storm.yaml
内容:
storm.zookeeper.servers:
- 127.0.0.1
storm.zookeeper.port: 2181
nimbus.host: "127.0.0.1"
storm.local.dir: "/tmp/storm"
supervisor.slots.ports:
- 6700
- 6701
- 6702
- 6703
这个脚本文件写的不咋地,所以在配置时一定注意在每一项的开始时要加空格,冒号后也必须要加空格,否则storm就不认识这个配置文件了。
说明一下:storm.local.dir表示storm需要用到的本地目录。nimbus.host表示那一台机器是master机器,即nimbus。storm.zookeeper.servers表示哪几台机器是zookeeper服务器。storm.zookeeper.port表示zookeeper的端口号,这里一定要与zookeeper配置的端口号一致,否则会出现通信错误,切记切记。当然你也可以配superevisor.slot.port,supervisor.slots.ports表示supervisor节点的槽数,就是最多能跑几个worker进程(每个sprout或bolt默认只启动一个worker,但是可以通过conf修改成多个)。
执行:
# bin/storm nimbus(启动主节点)
# bin/storm supervisor(启动从节点)
执行命令:# storm jar StormStarter.jar storm.starter.WordCountTopology test
此命令的作用就是用storm将jar发送给storm去执行,后面的test是定义的toplogy名称。
搞定,任务就发送到storm上运行起来了,还可以通过命令:
# bin/storm ui
然后执行 jps 会看到 3 个进程:zookeeper 、nimbus、 supervisor
启动ui,可以通过浏览器, ip:8080/ 查看运行i情况。
配置后,执行 storm jar sm.jar main.java.TopologyMain words.txt
也许会报:java.lang.NoClassDefFoundError: clojure.core.protocols$seq_reduce
这是由于我使用了 oracle JDK 1.7 的缘故,换成 open JDK 1.6 就正常了,
|
1
|
su -c "yum install java-1.6.0-openjdk-devel" |
具体参考:https://github.com/technomancy/leiningen/issues/676
测试代码:
https://github.com/storm-book/examples-ch02-getting_started
运行结果:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
|
storm jar sm.jar main.java.TopologyMain words.txt ...6020 [main] INFO backtype.storm.messaging.loader - Shutdown receiving-thread: [Getting-Started-Toplogie-1-1374946750, 4]6020 [main] INFO backtype.storm.daemon.worker - Shut down receive thread6020 [main] INFO backtype.storm.daemon.worker - Terminating zmq context6020 [main] INFO backtype.storm.daemon.worker - Shutting down executorsOK:is6021 [main] INFO backtype.storm.daemon.executor - Shutting down executor word-counter:[2 2]OK:anOK:stormOK:simple6023 [Thread-16] INFO backtype.storm.util - Async loop interrupted!OK:applicationOK:butOK:veryOK:powerfullOK:reallyOK:OK:StOrmOK:isOK:great6038 [Thread-15] INFO backtype.storm.util - Async loop interrupted!-- Word Counter [word-counter-2] --really: 1but: 1application: 1is: 2great: 2are: 1test: 1simple: 1an: 1powerfull: 1storm: 3very: 16043 [main] INFO backtype.storm.daemon.executor - Shut down executor word-counter:[2 2]6044 [main] INFO backtype.storm.daemon.executor - Shutting down executor word-normalizer:[3 3]6045 [Thread-18] INFO backtype.storm.util - Async loop interrupted!6052 [Thread-17] INFO backtype.storm.util - Async loop interrupted!6056 [main] INFO backtype.storm.daemon.executor - Shut down executor word-normalizer:[3 3]6056 [main] INFO backtype.storm.daemon.executor - Shutting down executor word-reader:[4 4]6058 [Thread-19] INFO backtype.storm.util - Async loop interrupted!... |
其它参考地址:
https://github.com/philipgao/storm-demo
http://blog.sina.com.cn/s/blog_8ae7b3fe010124mr.html
http://blog.jobbole.com/48595/ Storm:最火的流式处理框架
http://www.searchtb.com/2012/09/introduction-to-storm.html storm简介
https://www.ibm.com/developerworks/cn/opensource/os-twitterstorm/#list1 使用 Twitter Storm 处理实时的大数据
http://blog.csdn.net/tntzbzc/article/details/19974515 storm 计算 CCU 的小例子
分布式安装指南:
http://hitina.lofter.com/post/a8c5e_136579#
注:本文主体部分来源于 徐明明同学 翻译的 storm wiki 教程,
http://xumingming.sinaapp.com/138/twitter-storm%E5%85%A5%E9%97%A8/
Hadoop平台提供离线数据和Storm平台提供实时数据流的更多相关文章
- 阿里巴巴离线数据同步工具/平台datax安装、使用笔记
废话不多说,直接上笔记,先来看下参考链接GitHub: https://github.com/alibaba/DataX.此链接有较详细的安装使用方法,还有json参数编写的文档说明,建议多看. Fi ...
- Hadoop大数据通用处理平台
1.简介 Hadoop是一款开源的大数据通用处理平台,其提供了分布式存储和分布式离线计算,适合大规模数据.流式数据(写一次,读多次),不适合低延时的访问.大量的小文件以及频繁修改的文件. *Hadoo ...
- 基于Hadoop技术实现的离线电商分析平台(Flume、Hadoop、Hbase、SpringMVC、highcharts)
离线数据分析平台是一种利用hadoop集群开发工具的一种方式,主要作用是帮助公司对网站的应用有一个比较好的了解.尤其是在电商.旅游.银行.证券.游戏等领域有非常广泛,因为这些领域对数据和用户的特性把握 ...
- 谈B2B电商平台与大数据
数据为王,服务为本——谈B2B电商平台与大数据 2013-06-27 11:10:41 作者:B2B行业资讯 标签: 大数据 ...
- hadoop离线数据存储和挖掘架构
前序: 当你把你知道的东西,写下来,让人看明白是一种境界:当你能把自己写下来的东西给人讲明白,又是另一种境界.在这个过程中,我们都需要历练. 基于hadoop集群下海量离线数据存储和挖掘分析架构: 架 ...
- 奇点云数据中台技术汇(一) | DataSimba——企业级一站式大数据智能服务平台
在这个“数据即资产”的时代,大数据技术和体量都有了前所未有的进步,若企业能有效使用数据,让数据赚钱,这必将成为企业数字化转型升级的有力武器. 奇点云自研的一站式大数据智能服务平台——DataSimba ...
- TOP100summit:【分享实录-Microsoft】基于Kafka与Spark的实时大数据质量监控平台
本篇文章内容来自2016年TOP100summit Microsoft资深产品经理邢国冬的案例分享.编辑:Cynthia 邢国冬(Tony Xing):Microsoft资深产品经理.负责微软应用与服 ...
- java中用中国网建提供的SMS短信平台发送短信
接下来的项目需求中提到需要短信发送功能,以前没有做过,因此便在网上搜了一下.大体上说的都是有三种方法,分别是sina提供的webservice接口.短信mao和中国网建提供的SMS短信平台. 这三种方 ...
- 工程造价数据服务云平台(造价BIM)
为响应招标人的<ZQH工程造价数据平台>的技术邀约,特作以下陈述. 经过多次沟通和对招标文件的理解,招标人通过软件平台建立和使用人员库.项目库.材料设备价格库.数据库等四库的真实需求,本着 ...
随机推荐
- javaScript常用方法整合(项目中用到过的)
防止输入空格.缩进等字符: function trim(str){ return str.replace(/^\s+|\s+$/g,""); } JS去掉style样式标签 fun ...
- 知识管理(knowledge Management)2
①找到生命的主轴 ②跨领域知识管理
- const变量与define定义常量的区别
一.概念性区别 const 变量就是在普通变量前边加上一个关键字const,它赋值的唯一机会就是“定义时”,此变量不能被程序修改,存储在rodata区. define定义的是常量,不是变量,所以编译器 ...
- System.Reflection.Assembly.GetEntryAssembly()获取的为当前已加载的程序集
今天在使用System.Reflection.Assembly.GetEntryAssembly()获取程序集时,发现获取的程序集不全.原来是因为C#的程序集为延迟加载,此方法只获取当前已加载的,未加 ...
- 初级ant的学习
一.安装ant 到官方主页http://ant.apache.org下载新版(目前为Ant1.8.1)的ant,得到的是一个apache-ant-1.8.1-bin.zip的压缩包.将其解压到你的硬盘 ...
- bzoj 1079: [SCOI2008]着色方案 DP
1079: [SCOI2008]着色方案 Time Limit: 10 Sec Memory Limit: 162 MBSubmit: 803 Solved: 512[Submit][Status ...
- app内购提示,您已购买此商品,但未下载
出现这样的问题,是支付没有finish造成的,一般在支付过程中断网了,下次再购买同一商品的时候就会出现这样的问题, 解决办法,在点击购买的时候判断支付队列中是否有为finish的商品,若有,则进行处理 ...
- uva 10496 Collecting Beepers
一个简单的货郎担问题,用状态压缩dp可以解决: 解法: d(i,S)=min{d(j,S-{j})+dis(i,j) | j belongs to S}; 边界条件:d(i,{})=dis(0,i). ...
- 服务器RAID配置全程与RAID基础知识
服务器RAID配置全程 一.RAID介绍 RAID是Redundent Array of Inexpensive Disks的缩写,直译为“廉价冗余磁盘阵列”,也简称为“磁盘阵列”.后来RAID中的字 ...
- [LeetCode#261] Graph Valid Tree
Problem: Given n nodes labeled from 0 to n - 1 and a list of undirected edges (each edge is a pair o ...