(转)浅谈dedecms模板引擎工作原理及自定义标签
理解织梦模板引擎有什么意义?一方面可以更好地自定义标签。更多在于了解织梦系统,理解模板引擎是理解织梦工作原理的第一步。理解织梦会使我们写php代码时更顺手,同时能学习一些php代码的组织方式。
这似乎不是那么简单,如果你只想学习自定义标签,可以看一下“是否需要自定义标签”和““扩展标签””就够了。
一解析式引擎
如果你还没用过dedecms的标签,先用一下,也可以看一下“dedecms网页模板编写”。熟悉一下memberlist这个标签,下面会以这个标签为例。
织梦提供的模板分析引擎有解析式和编译式两种,由于现在主要使用前者,这里也只讨论前者。
先来写个模板解析的hello world 程序
***root/test.php 封面php(root指的是根目录,以下都假设dedecms被放在了网站的根目录)

<?php
require_once (dirname(__file__).'/include/common.inc.php');
//利用解析式模板所需的文件
require_once (dirname(__file__).'/include/dedetag.class.php'); //生成解析模板引擎类对象
$dtp=new DedeTagParse();
//设置命名空间,由于下面的标签用tianya命名空间,所以要设置一下。
$dtp->SetNameSpace('tianya');
$dtp->LoadTemplate(dirname(__file__).'\test.tpl.htm '); //把标签替换成具体的值
foreach ($dtp->CTags as $id=>$tag)
{
if($tag->GetName()=='my')
//把id为$id的tag翻译成这是my标签<br/>
$dtp->Assign($id,'这是my标签<br/>');
else if($tag->GetName()=='test')
$dtp->Assign($id,'这是test标签<br/>');
} //把解析好的html文本echo出来
$dtp->Display();
?>
***root/test.tpl.htm 网页模板
{tianya:my att1=1 att2='2'}
[field:my/]
{/tianya:my}
{tianya:test att1=1 att2='2'}
[field:test/]
{/tianya:test}
执行root/test.php就能查看结果
由上面的例子可以看出解析式模板运作的套路:
1php文件调用网页模板,并显示。
2htm文件提供网页的大体框架,等待数据来完善网页的具体内容,称为网页模板。
上面的代码就是把第一个标签(my标签)显示为这是my标签<br/>;第二个标签显示为这是test标签<br/>。
上面的代码是怎么办妥的
更改***root/test.php如下
<?php
require_once (dirname(__file__).'/include/common.inc.php');
//利用解析式模板所需的文件
require_once (dirname(__file__).'/include/dedetag.class.php'); $dtp=new DedeTagParse();
//设置命名空间,由于下面的标签用tianya命名空间,所以要设置一下。
$dtp->SetNameSpace('tianya');
$dtp->LoadTemplate(dirname(__file__).'\test.tpl.htm ');
var_dump($dtp); //这是查看解析结果的重要方法
?>
***root/test.tpl.htm 网页模板
{tianya:my att1=1 att2='2'}
[field:my/]
{/tianya:my}
{tianya:test att1=1 att2='2'}
[field:test/]
{/tianya:test}
可以看到$dtp对象的内部结构,其中有一个DedeTag类的数组CTags,DedeTag类的定义见root/include/ dedetag.class.php。最好不要直接用DedeTag类的字段,而用DedeTag提供的函数。比如用tag1->GetName()而不是用tag1->TagName。花一小段时间就能把DedeTag类看完,这些语法在以后自定义标签时会有用。
再看一个例子,***root/test.php
<?php
require_once (dirname(__file__).'/include/common.inc.php');
require_once (dirname(__file__).'/include/dedetag.class.php'); function lib_my($att1,$att2)
{
return '这是my标签<br/>属性值'.$att1.$att2.'<br/>';
} $dtp=new DedeTagParse();
$dtp->SetNameSpace('tianya');
$dtp->LoadTemplate(dirname(__file__).'\test.tpl.htm'); foreach ($dtp->CTags as $id=>$tag)
{
if($tag->GetName()=='my')
$dtp->Assign($id , lib_my($tag->GetAtt('att1'),$tag->GetAtt('att2')));
} $dtp->Display();
?>
***root/test.htm 网页模板
{tianya:my att1=1 att2='2'}
[field:my/]
{/tianya:my}
{tianya:test att1=1 att2='2'}
[field:test/]
{/tianya:test}
会发现模板解析中有四种“势力”
在include/ DedeTagParse.class.php中定义的解析引擎类,负责读取模板,把其中的dedecms标签替换成具体html文本。DedeTagParse、SetNameSpace、LoadTemplate就是类里面的方法。
标签翻译需要一些转换规则,lib_my就是这一类根据标签的属性和具体数据得出html。
待显示的php创建编译引擎类对象,对模板进行编译,在Display时,echo出html文件。
htm模板,调用标签,用html的形式写出动态网页的效果,属于被翻译的部分。Html模板主要负责界面层次,利用封装好的标签进行内部处理。
除了这四大势力,还有一个势力视图类。include/中以arc开头的文件都是解析引擎的视图类。视图类就是封装了解析引擎类的类,仅仅加了一些函数而已。在下载的cms默认模板中,root/index.php就用了PartView这个视图类,解析了templets/default/index.htm。五大势力的关系如下图。
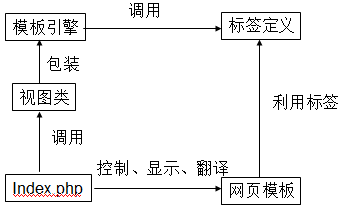
我们现在想象一个标签如何被解析的。我们知道,一个xml标签有四个元素:命名空间(上面的tianya,在dedecms中是dede)、标签名(my)、属性(att)、InnerText(标签之间的内容)。命名空间在SetNameSpace中指明了,标签名由if($tag->GetName()=='my')这一句分配任务,属性作为函数参数使用,就差InnerText的处理。
再来看看如何处理底层模板字段([field:my/]等,field是一个关键字,在实际应用中,常常是数据库元组中的字段)
***root/test.php
<?php
require_once (dirname(__file__).'/include/common.inc.php');
require_once (dirname(__file__).'/include/dedetag.class.php'); //看完后面的代码再来看这个函数
function lib_zoo(&$ctag)
{
//还记得刚才$dtp->CTags的结构吗?这里把$ctag作为参数传递,lib__zoo外面的代码就不用涉及太多的标签处理了
$reval='这是my标签<br/>属性值'. $ctag->GetAtt('att1').$ctag->GetAtt('att2').'<br/>';
$innerText = $ctag->GetInnerText(); //底层模板字段的结构都形如[field:XX]这里把它看作以field为命名空间,[]为分隔符的标签。
$dtp=new DedeTagParse();
$dtp->SetNameSpace('field','[',']');
$dtp->LoadSource($innerText); //不妨把$row想想成从数据库中读取出来的出来的数据
$row[‘name’]= 'Snoopy';
$row[‘animal’]= 'dog'; //把标签替换成具体的值
foreach ($dtp->CTags as $id=>$tag)
{
if($tag->GetName()=='name')
$dtp->Assign($id, $row[‘name’]);
else if($tag->GetName()=='animal')
$dtp->Assign($id, $row[‘animal’]);
}
$reval.=$dtp->GetResult().'<br/>';
return $reval;
} $dtp=new DedeTagParse();
$dtp->SetNameSpace('tianya');
$dtp->LoadTemplate(dirname(__file__).'\test.htm'); foreach ($dtp->CTags as $id=>$tag)
{
if($tag->GetName()=='zoo')
$dtp->Assign($id, lib_zoo($tag));
} $dtp->Display();
?>
***root/test.htm
{tianya:zoo att1=1 att2='2'}
[field:name/] is a [field:animal/]
{/tianya:zoo}
可见,解析底层模板和解析标签是一样的,只不过把底层模板当作是以field为命名空间,‘[’和‘]’为边界的标签而已。
接着看一下include/taglib/memberlist.lib.php,和lib_zoo很像吧。你是不是突然懂得如何定义标签了,读memberlist.lib.php里面的代码,模仿,就能自定义标签了,可参考“扩展标签”。所以自定义标签只用在include/taglib里加入XX.lib.php文件,里面定义lib_XX函数即可。快点去试一试。
***把root/index.php(默认模板根目录中的)里面的
$pv->SetTemplet($cfg_basedir . $cfg_templets_dir . "/" . $row['templet']);
改成$pv->SetTemplet($cfg_basedir .'/test.htm');
在root/test.htm使用自定义标签吧
是否需要自定义标签
笔者刚学织梦标签时,第一个感觉就是之梦的标签比较抽象,不够好用。比如说刚才的zoo的问题,我就会定义一个zoo标签。后来才发现应该用定义频道的方法解决,可参考“dedecms中自定义数据模型”这篇文章。另外,标签也有一些弱点,在开发中会慢慢体会到。
上面讲了五大势力的关系、一个标签的解析过程和如何定义标签,回忆一下看看是否对标签解析有了六七成的把握。解析式模板的运作还有很多细节,读源码是最好的学习方法。但有点难度,看自己需要的程度吧,可以跳过这一段。
***把root/index.php(默认模板根目录中的)里面的
$pv->SetTemplet($cfg_basedir . $cfg_templets_dir . "/" . $row['templet']);
改成$pv->SetTemplet($cfg_basedir .'/test.htm');
编写root/test.htm
{dede:memberlist row=6 signlen=30}
<li><a href="[field:spaceurl/]" target="_blank">[field:uname/]</a></li>
{/dede:memberlist}
运行index.php
这是怎么办到的,跟踪代码自己想吧(tips:适当地var_dump一些变量,还有用一下ctrl+F)。主要看dedetag.class.php这个文件,是织梦的核心文件,还是该看一看的。
过程大概是这样的:new PartView()(include/ arc.partview.class中)调用了DedeTagParse(),SetNameSpace ()做了一些初始化工作。LoadTemplate() 一方面读取网页模板代码,另一方面调用ParseTemplet()把网页模板分解标签,属性,底层模板等,得到$pv->CTags。
Display()调用echo GetResult()的结果。GetResult()就是由分解好的标签,属性,底层模板等算出结果html。由于dedecms标记满足树形的语法规则(像html一样),所以,计算标签是一个遍历树的过程。至于每个标签的值的计算,就调用了AssignSysTag(),它处理了global等标记。对于自定义标记,通过调用IncludeFile处理,这个函数又通过了复杂的调用,最后调用了include\helpers\channelunit.helper中的MakeOneTag()的函数。
自己整理一下吧!
二 解析与网页的上下文
后面的部分是我在写完“关于网页模板”后补上的,涉及到封面模板、列表模板和文档模板,不了解的读者可以先看看那篇文章。
通过链接,网页可以在封面页、列表页和文档页间跳转,那怎么样在页面中传递信息呢?可以用get方式。由于系统有生成功能,它会把解析的结果生成纯的html页面,不太容易看清解析的过程。不妨先不用生成功能,如在后台添加一篇文章,在发布选项处选“仅动态浏览”,之后保存,预览。看到地址栏内容形如http://localhost/plus/view.php?aid=114。
不妨细细研究这个超链接,首先是aid=114。aid指article id,是文章的编号。通过给出这个编号,通过XXX处理,就能得出文章的所有信息,再加上文档模板(就像一个格式),就能的出具体的html文档页。类似地,还有tid(type id,栏目号)、cid(channel id,频道/模型号)或其他。这是在上下文间传递的信息。
之后说说plus/view.php。打开该文件,发现里面用aid为参数,创建了一个视图类Archives的对象(在include/arc.archives.class中定义),并调用Display函数显示。这和根目录/index.php用partview视图类对象来解析模板的道理是一样的,不过这里多附加了aid表示具体的文章(而index中的东西是通用的,不用附加上下文)。也就是说,解析封面模板、列表模板和文档模板都有建立解析引擎对象。
另外,链接中对应php文件不一定是plus/view.php,显示文档可用plus/view.php;显示列表可用plus/list.php。我猜测之所以会有文档模板和列表模板差异就是来自于不同的视图类。
之后,若在文章的发布选项处选“生成html”,就是调用视图类的SaveToHtml函数。得到的文章链接形如http://localhost/a/webbase/javascript-ajax/2010/0409/114.html。
(转)浅谈dedecms模板引擎工作原理及自定义标签的更多相关文章
- 浅谈dedecms模板引擎工作原理及其自定义标签
浅谈dedecms模板引擎工作原理: 理解织梦模板引擎有什么意思? 可以更好地自定义标签.更多在于了解织梦系统,理解模板引擎是理解织梦工作原理的第一步. 理解织梦会使我们写PHP代码是更顺手,同时能学 ...
- 【Thymeleaf】浅谈Java模板引擎(带更新...)
什么是模板引擎 模板引擎(这里特指用于Web开发的模板引擎)是为了使用户界面与业务数据(内容)分离而产生的,它可以生成特定格式的文档,用于网站的模板引擎就会生成一个标准的HTML文档. 为什么要用模板 ...
- 浅谈malloc()和free()工作原理
编程之路刚刚开始,错误难免,希望大家能够指出. malloc()和free()是我经常需要用到的函数,一般情况下,C程序使用malloc()在堆上分配内存,free()释放内存,两者的参数和返回值就 ...
- 浅谈JSONP 的本质工作原理
json 是一种数据格式jsonp 是一种数据调用的方式. 你可以简单的理解为 带callback的json就是jsonp 话说我们访问一个页面的时候 需要像另一个网站获取部分信息, 这就是所谓的跨域 ...
- PHP的模板引擎smarty原理浅谈
mvc是开发中的一个伟大的思想,使得开发代码有了更加清晰的层次,让代码分为了三层各施其职.无论是对代码的编写以及后期的阅读和维护,都提供了很大的便利. 我们在php开发中,视图层view是不允许有ph ...
- PHP的模板引擎smarty原理是什么(整理)
PHP的模板引擎smarty原理是什么(整理) 一.总结 一句话总结:其实所有的模板引擎的工作原理是差不多的,无非就是在php程序里面用正则匹配将模板里面的标签替换为php代码从而将两者混合为一个ph ...
- 深入浅出之Smarty模板引擎工作机制(一)
深入浅出Smarty模板引擎工作机制,我们将对比使用smarty模板引擎和没使用smarty模板引擎的两种开发方式的区别,并动手开发一个自己的模板引擎,以便加深对smarty模板引擎工作机制的理解. ...
- 深入浅出之Smarty模板引擎工作机制(二)
源代码下载地址:深入浅出之Smarty模板引擎工作机制 接下来根据以下的Smarty模板引擎原理流程图开发一个自己的模板引擎用于学习,以便加深理解. Smarty模板引擎的原理,其实是这么一个过程: ...
- 浅谈surging服务引擎中的rabbitmq组件和容器化部署
1.前言 上个星期完成了surging 的0.9.0.1 更新工作,此版本通过nuget下载引擎组件,下载后,无需通过代码build集成,引擎会通过Sidecar模式自动扫描装配异构组件来构建服务引擎 ...
随机推荐
- Node.js包(JXcore)
Node.js的代码是开放的,并准备好被复制像任何其他Javascript代码.但现在它不可能的了.JXcore 这是一个开源项目,引入了包装和源文件和其他资源加密成JX包一个独特的功能. 考虑大型项 ...
- Google Cardboard
Google Cardboard是谷歌的一个虚拟现实开源项目,旨在使用户可以以一种简单.有趣且廉价的方式体验虚拟现实.用户只需要在Android手机上安装一个Google Cardboard应用,并将 ...
- 12.HTML编辑器(CKEditor、CKFinder集成)
CKEditor原名为FckEditor,是著名的HTML编辑器,可以在线编辑HTML内容. 配置参考文档:主要将ckeditor中的lang.plugins.skins.ckeditor.js.co ...
- linux下so动态库一些不为人知的秘密(转)
linux 下有动态库和静态库,动态库以.so为扩展名,静态库以.a为扩展名.二者都使用广泛.本文主要讲动态库方面知识.基本上每一个linux 程序都至少会有一个动态库,查看某个程序使用了那些动态库, ...
- 【转】Android JNI编程—JNI基础
原文网址:http://www.jianshu.com/p/aba734d5b5cd 最近看到了很多关于热补的开源项目——Depoxed(阿里).AnFix(阿里).DynamicAPK(携程)等,它 ...
- (转载)HTML标签<br><br/>的区别在哪里?
(转载)http://zhidao.baidu.com/question/259205863.html HTML标签<br><br/>的区别在哪里? 如果一样为什么还要分2个标 ...
- 模板:强连通分量&2-sat
void Tarjan(int x){ low[x]=ID[x]=++tot; st[++top]=x;Inst[x]=true; for(int i=fir[x];i;i=nxt[i]) if(!I ...
- 【最短路】【数学】CSU 1806 Toll (2016湖南省第十二届大学生计算机程序设计竞赛)
题目链接: http://acm.csu.edu.cn/OnlineJudge/problem.php?id=1806 题目大意: N个点M条有向边,给一个时间T(2≤n≤10,1≤m≤n(n-1), ...
- QT5.7.0在win10下使用visual studio 2015编译(目标平台 xp)
环境:win10+vs2015+QT5.7.0 目标:编译出能在windows xp上运行的QT 通过baidu和bing找出来的结果没有一个能成功运行,大部分都能编译成功,并完美解决“exe不是有效 ...
- 吉哥系列故事--完美队形 - HDU 4513 (Manacher)
分析:刚开始的想法是匹配出来每个点的最大回文串,然后用每个点的最大不下降序找一个最小值,不过不明白为什么不对....很无奈,再匹配的时候加一些判断就可以过,或许还有什么没想到的地方吧..... 代 ...