MapReduce分析明星微博数据
互联网时代的到来,使得名人的形象变得更加鲜活,也拉近了明星和粉丝之间的距离。歌星、影星、体育明星、作家等名人通过互联网能够轻易实现和粉丝的互动,赚钱也变得前所未有的简单。同时,互联网的飞速发展本身也造就了一批互联网明星,这些人借助新的手段,最大程度发挥了粉丝经济的能量和作用,在互联网时代赚得盆满钵满。
正是基于这样一个大背景,今天我们做一个分析明星微博数据的小项目
1、项目需求
自定义输入格式,将明星微博数据排序后按粉丝数关注数 微博数分别输出到不同文件中。
2、数据集
明星 明星微博名称 粉丝数 关注数 微博数
俞灏明 俞灏明 10591367 206 558
李敏镐 李敏镐 22898071 11 268
林心如 林心如 57488649 214 5940
黄晓明 黄晓明 22616497 506 2011
张靓颖 张靓颖 27878708 238 3846
李娜 李娜 23309493 81 631
徐小平 徐小平 11659926 1929 13795
唐嫣 唐嫣 24301532 200 2391
有斐君 有斐君 8779383 577 4251
3、分析
自定义InputFormat读取明星微博数据,通过自定义getSortedHashtableByValue方法分别对明星的fan、followers、microblogs数据进行排序,然后利用MultipleOutputs输出不同项到不同的文件中
4、实现
1、定义WeiBo实体类,实现WritableComparable接口
package com.buaa; import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException; import org.apache.hadoop.io.WritableComparable; /**
* @ProjectName MicroblogStar
* @PackageName com.buaa
* @ClassName WeiBo
* @Description TODO
* @Author 刘吉超
* @Date 2016-05-07 14:54:29
*/
public class WeiBo implements WritableComparable<Object> {
// 粉丝
private int fan;
// 关注
private int followers;
// 微博数
private int microblogs; public WeiBo(){}; public WeiBo(int fan,int followers,int microblogs){
this.fan = fan;
this.followers = followers;
this.microblogs = microblogs;
} public void set(int fan,int followers,int microblogs){
this.fan = fan;
this.followers = followers;
this.microblogs = microblogs;
} // 实现WritableComparable的readFields()方法,以便该数据能被序列化后完成网络传输或文件输入
@Override
public void readFields(DataInput in) throws IOException {
fan = in.readInt();
followers = in.readInt();
microblogs = in.readInt();
} // 实现WritableComparable的write()方法,以便该数据能被序列化后完成网络传输或文件输出
@Override
public void write(DataOutput out) throws IOException {
out.writeInt(fan);
out.writeInt(followers);
out.writeInt(microblogs);
} @Override
public int compareTo(Object o) {
// TODO Auto-generated method stub
return 0;
} public int getFan() {
return fan;
} public void setFan(int fan) {
this.fan = fan;
} public int getFollowers() {
return followers;
} public void setFollowers(int followers) {
this.followers = followers;
} public int getMicroblogs() {
return microblogs;
} public void setMicroblogs(int microblogs) {
this.microblogs = microblogs;
}
}
2、自定义WeiboInputFormat,继承FileInputFormat抽象类
package com.buaa; import java.io.IOException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.RecordReader;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.util.LineReader; /**
* @ProjectName MicroblogStar
* @PackageName com.buaa
* @ClassName WeiboInputFormat
* @Description TODO
* @Author 刘吉超
* @Date 2016-05-07 10:23:28
*/
public class WeiboInputFormat extends FileInputFormat<Text,WeiBo>{ @Override
public RecordReader<Text, WeiBo> createRecordReader(InputSplit arg0, TaskAttemptContext arg1) throws IOException, InterruptedException {
// 自定义WeiboRecordReader类,按行读取
return new WeiboRecordReader();
} public class WeiboRecordReader extends RecordReader<Text, WeiBo>{
public LineReader in;
// 声明key类型
public Text lineKey = new Text();
// 声明 value类型
public WeiBo lineValue = new WeiBo(); @Override
public void initialize(InputSplit input, TaskAttemptContext context) throws IOException, InterruptedException {
// 获取split
FileSplit split = (FileSplit)input;
// 获取配置
Configuration job = context.getConfiguration();
// 分片路径
Path file = split.getPath(); FileSystem fs = file.getFileSystem(job);
// 打开文件
FSDataInputStream filein = fs.open(file); in = new LineReader(filein,job);
} @Override
public boolean nextKeyValue() throws IOException, InterruptedException {
// 一行数据
Text line = new Text(); int linesize = in.readLine(line); if(linesize == 0)
return false; // 通过分隔符'\t',将每行的数据解析成数组
String[] pieces = line.toString().split("\t"); if(pieces.length != 5){
throw new IOException("Invalid record received");
} int a,b,c;
try{
// 粉丝
a = Integer.parseInt(pieces[2].trim());
// 关注
b = Integer.parseInt(pieces[3].trim());
// 微博数
c = Integer.parseInt(pieces[4].trim());
}catch(NumberFormatException nfe){
throw new IOException("Error parsing floating poing value in record");
} //自定义key和value值
lineKey.set(pieces[0]);
lineValue.set(a, b, c); return true;
} @Override
public void close() throws IOException {
if(in != null){
in.close();
}
} @Override
public Text getCurrentKey() throws IOException, InterruptedException {
return lineKey;
} @Override
public WeiBo getCurrentValue() throws IOException, InterruptedException {
return lineValue;
} @Override
public float getProgress() throws IOException, InterruptedException {
return 0;
} }
}
3、编写mr程序
package com.buaa; import java.io.IOException;
import java.util.Arrays;
import java.util.Comparator;
import java.util.HashMap;
import java.util.Map;
import java.util.Map.Entry; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.LazyOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.MultipleOutputs;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner; /**
* @ProjectName MicroblogStar
* @PackageName com.buaa
* @ClassName WeiboCount
* @Description TODO
* @Author 刘吉超
* @Date 2016-05-07 09:07:36
*/
public class WeiboCount extends Configured implements Tool {
// tab分隔符
private static String TAB_SEPARATOR = "\t";
// 粉丝
private static String FAN = "fan";
// 关注
private static String FOLLOWERS = "followers";
// 微博数
private static String MICROBLOGS = "microblogs"; public static class WeiBoMapper extends Mapper<Text, WeiBo, Text, Text> {
@Override
protected void map(Text key, WeiBo value, Context context) throws IOException, InterruptedException {
// 粉丝
context.write(new Text(FAN), new Text(key.toString() + TAB_SEPARATOR + value.getFan()));
// 关注
context.write(new Text(FOLLOWERS), new Text(key.toString() + TAB_SEPARATOR + value.getFollowers()));
// 微博数
context.write(new Text(MICROBLOGS), new Text(key.toString() + TAB_SEPARATOR + value.getMicroblogs()));
}
} public static class WeiBoReducer extends Reducer<Text, Text, Text, IntWritable> {
private MultipleOutputs<Text, IntWritable> mos; protected void setup(Context context) throws IOException, InterruptedException {
mos = new MultipleOutputs<Text, IntWritable>(context);
} protected void reduce(Text Key, Iterable<Text> Values,Context context) throws IOException, InterruptedException {
Map<String,Integer> map = new HashMap< String,Integer>(); for(Text value : Values){
// value = 名称 + (粉丝数 或 关注数 或 微博数)
String[] records = value.toString().split(TAB_SEPARATOR);
map.put(records[0], Integer.parseInt(records[1].toString()));
} // 对Map内的数据进行排序
Map.Entry<String, Integer>[] entries = getSortedHashtableByValue(map); for(int i = 0; i < entries.length;i++){
mos.write(Key.toString(),entries[i].getKey(), entries[i].getValue());
}
} protected void cleanup(Context context) throws IOException, InterruptedException {
mos.close();
}
} @SuppressWarnings("deprecation")
@Override
public int run(String[] args) throws Exception {
// 配置文件对象
Configuration conf = new Configuration(); // 判断路径是否存在,如果存在,则删除
Path mypath = new Path(args[1]);
FileSystem hdfs = mypath.getFileSystem(conf);
if (hdfs.isDirectory(mypath)) {
hdfs.delete(mypath, true);
} // 构造任务
Job job = new Job(conf, "weibo");
// 主类
job.setJarByClass(WeiboCount.class); // Mapper
job.setMapperClass(WeiBoMapper.class);
// Mapper key输出类型
job.setMapOutputKeyClass(Text.class);
// Mapper value输出类型
job.setMapOutputValueClass(Text.class); // Reducer
job.setReducerClass(WeiBoReducer.class);
// Reducer key输出类型
job.setOutputKeyClass(Text.class);
// Reducer value输出类型
job.setOutputValueClass(IntWritable.class); // 输入路径
FileInputFormat.addInputPath(job, new Path(args[0]));
// 输出路径
FileOutputFormat.setOutputPath(job, new Path(args[1])); // 自定义输入格式
job.setInputFormatClass(WeiboInputFormat.class) ;
//自定义文件输出类别
MultipleOutputs.addNamedOutput(job, FAN, TextOutputFormat.class, Text.class, IntWritable.class);
MultipleOutputs.addNamedOutput(job, FOLLOWERS, TextOutputFormat.class, Text.class, IntWritable.class);
MultipleOutputs.addNamedOutput(job, MICROBLOGS, TextOutputFormat.class, Text.class, IntWritable.class); // 去掉job设置outputFormatClass,改为通过LazyOutputFormat设置
LazyOutputFormat.setOutputFormatClass(job, TextOutputFormat.class); //提交任务
return job.waitForCompletion(true)?0:1;
} // 对Map内的数据进行排序(只适合小数据量)
@SuppressWarnings("unchecked")
public static Entry<String, Integer>[] getSortedHashtableByValue(Map<String, Integer> h) {
Entry<String, Integer>[] entries = (Entry<String, Integer>[]) h.entrySet().toArray(new Entry[0]);
// 排序
Arrays.sort(entries, new Comparator<Entry<String, Integer>>() {
public int compare(Entry<String, Integer> entry1, Entry<String, Integer> entry2) {
return entry2.getValue().compareTo(entry1.getValue());
}
});
return entries;
} public static void main(String[] args) throws Exception {
String[] args0 = {
"hdfs://ljc:9000/buaa/microblog/weibo.txt",
"hdfs://ljc:9000/buaa/microblog/out/"
};
int ec = ToolRunner.run(new Configuration(), new WeiboCount(), args0);
System.exit(ec);
}
}
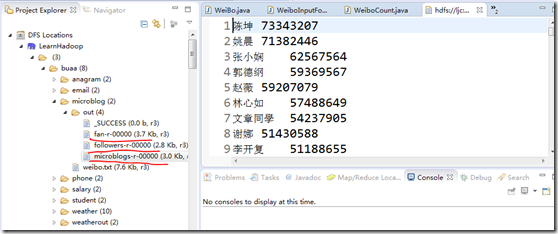
5、运行结果
MapReduce分析明星微博数据的更多相关文章
- 使用hadoop mapreduce分析mongodb数据
使用hadoop mapreduce分析mongodb数据 (现在很多互联网爬虫将数据存入mongdb中,所以研究了一下,写此文档) 版权声明:本文为yunshuxueyuan原创文章.如需转载请标明 ...
- 2020不平凡的90天,Python分析三个月微博热搜数据带你回顾
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者:刘早起早起 PS:如有需要Python学习资料的小伙伴可以加点击下方链 ...
- 用python爬取微博数据并生成词云
很早之前写过一篇怎么利用微博数据制作词云图片出来,之前的写得不完整,而且只能使用自己的数据,现在重新整理了一下,任何的微博数据都可以制作出来,放在今天应该比较应景. 一年一度的虐汪节,是继续蹲在角落默 ...
- MapReduce分析流量汇总
一.MapReduce编程规范 一.MapReduce编程规范 用户编写mr程序主要分为三个部分:Mapper,Reducer,Driver 1.Mapper阶段 (1)用户自定义Mapper类 要继 ...
- [iOS微博项目 - 2.6] - 获取微博数据
github: https://github.com/hellovoidworld/HVWWeibo A.新浪获取微博API 1.读取微博API 2.“statuses/home_time ...
- ANDROID_MARS学习笔记_S04_008_用Listview、自定义adapter显示返回的微博数据
一.简介 运行结果 二.代码1.xml(1)activity_main.xml <?xml version="1.0" encoding="utf-8"? ...
- 使用Hadoop的MapReduce与HDFS处理数据
hadoop是一个分布式的基础架构,利用分布式实现高效的计算与储存,最核心的设计在于HDFS与MapReduce,HDFS提供了大量数据的存储,mapReduce提供了大量数据计算的实现,通过Java ...
- 基于微博数据用 Python 打造一颗“心”
一年一度的虐狗节刚过去不久,朋友圈各种晒,晒自拍,晒娃,晒美食,秀恩爱的.程序员在晒什么,程序员在加班.但是礼物还是少不了的,送什么好?作为程序员,我准备了一份特别的礼物,用以往发的微博数据打造一颗“ ...
- 利用python基于微博数据打造一颗“心”
一年一度的虐狗节将至,朋友圈各种晒,晒自拍,晒娃,晒美食,秀恩爱的.程序员在晒什么,程序员在加班.但是礼物还是少不了的,送什么好?作为程序员,我准备了一份特别的礼物,用以往发的微博数据打造一颗&quo ...
随机推荐
- sourceInsight的技巧
在用sourceInsight看代码...在这里积累技巧,慢慢积累吧 1.如何高亮显示所有要搜的东西,例如 1.aaaaaa 2. bbbbbbbbaaaaaaa 3. ccccccc 4. aaaa ...
- BenchmarkDotNet
.NET Core性能测试组件BenchmarkDotNet 支持.NET Framework Mono .NET Core 超强性能测试组件BenchmarkDotNet 支持Full .NET F ...
- Quartz1.8.5例子(四)
/* * Copyright 2005 - 2009 Terracotta, Inc. * * Licensed under the Apache License, Version 2.0 (the ...
- JUnit扩展:引入新注解Annotation
发现问题 JUnit提供了Test Suite来帮助我们组织case,还提供了Category来帮助我们来给建立大的Test Set,比如BAT,MAT, Full Testing. 那么什么情况下, ...
- C++结构简介
结构是一种比数组更灵活的数据格式,因为同一个结构可以储存多种类型的数据,这使得能够将篮球运动员的信息放在一个结构中,从而将数据的表示的合并到一起. 结构也是C++堡垒OOP(类)的基石.结构是用户定义 ...
- Contest20140705 testB DP
testB 输入文件: testB.in 输出文件testB.out 时限2000ms 问题描述: 方师傅有两个由数字组成的串 a1,a2,⋯,an 和 b1,b2,⋯,bm.有一天,方师傅感到十分无 ...
- 【Itext】解决Itext5大并发大数据量下输出PDF发生内存溢出outofmemery异常
尼玛,这个问题干扰了我两个星期!! 关键字 itext5 outofmemery 内存溢出 大数据 高并发 多线程 pdf 导出 报表 itext 并发 在读<<iText in Acti ...
- 无插件Vim编程技巧
无插件Vim编程技巧 http://bbs.byr.cn/#!article/buptAUTA/59钻风 2014-03-24 09:43:46 发表于:vim 相信大家看过<简明Vim教程& ...
- MVVM in Depth
这篇文章开始粗略的介绍了软件开发中松耦合的概念并讲述了使用MVC.MVP和MVVM三种模式达到松耦合.然后分析了这三种模式适用范围,其中: MVC(Model-View-Controller)适用于w ...
- Java多线程同步方法Synchronized和volatile
11 同步方法 synchronized – 同时解决了有序性.可见性问题 volatile – 结果可见性问题 12 同步- synchronized synchronized可以在任意对象上加 ...