tensorflow用dropout解决over fitting
在机器学习中可能会存在过拟合的问题,表现为在训练集上表现很好,但在测试集中表现不如训练集中的那么好。
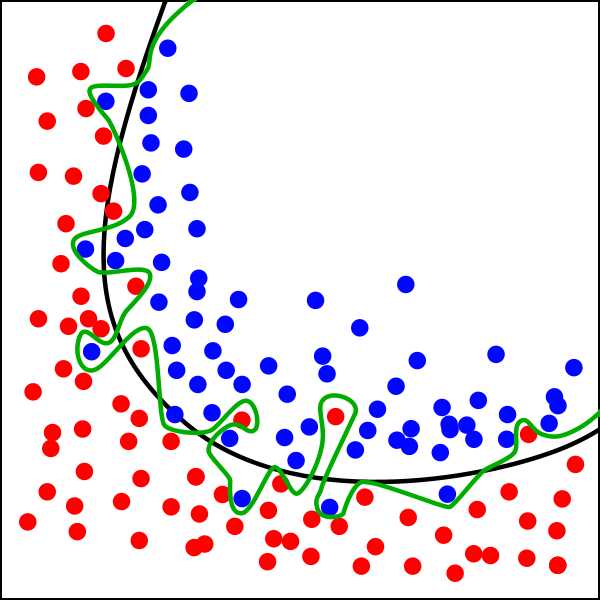
图中黑色曲线是正常模型,绿色曲线就是overfitting模型。尽管绿色曲线很精确的区分了所有的训练数据,但是并没有描述数据的整体特征,对新测试数据的适应性较差。
一般用于解决过拟合的方法有增加权重的惩罚机制,比如L2正规化,但在本处我们使用tensorflow提供的dropout方法,在训练的时候, 我们随机忽略掉一些神经元和神经联结 , 是这个神经网络变得”不完整”. 用一个不完整的神经网络训练一次.
到第二次再随机忽略另一些, 变成另一个不完整的神经网络. 有了这些随机 drop 掉的规则, 我们可以想象其实每次训练的时候, 我们都让每一次预测结果都不会依赖于其中某部分特定的神经元. 像l1, l2正规化一样, 过度依赖的 W , 也就是训练参数的数值会很大, l1, l2会惩罚这些大的 参数. Dropout 的做法是从根本上让神经网络没机会过度依赖.
本次我们使用之前sklearn中手写数字作为例子来进行。
加载数据
from sklearn.datasets import load_digits
from sklearn.preprocessing import LabelBinarizer
digits = load_digits()
X = digits.data
y = digits.target
# 把数值转换成one hot格式,例如:数字4就会被转换成:[0 0 0 0 1 0 0 0 0 0]
y = LabelBinarizer().fit_transform(y)
# 拆分数据集,以总量的30%作为测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)添加层
添加层函数如下:
import tensorflow as tf
def add_layer(inputs, in_size, out_size, activation_function=None):
"""
添加层
:param inputs: 输入数据
:param in_size: 输入数据的列数
:param out_size: 输出数据的列数
:param activation_function: 激励函数
:return:
"""
# 定义权重,初始时使用随机变量,可以简单理解为在进行梯度下降时的随机初始点,这个随机初始点要比0值好,因为如果是0值的话,反复计算就一直是固定在0中,导致可能下降不到其它位置去。
Weights = tf.Variable(tf.random_normal([in_size, out_size]))
# 偏置shape为1行out_size列
biases = tf.Variable(tf.zeros([1, out_size]) + 0.1)
# 建立神经网络线性公式:inputs * Weights + biases,我们大脑中的神经元的传递基本上也是类似这样的线性公式,这里的权重就是每个神经元传递某信号的强弱系数,偏置值是指这个神经元的原先所拥有的电位高低值
Wx_plus_b = tf.matmul(inputs, Weights) + biases
if activation_function is None:
# 如果没有设置激活函数,则直接就把当前信号原封不动地传递出去
outputs = Wx_plus_b
else:
# 如果设置了激活函数,则会由此激活函数来对信号进行传递或抑制
outputs = activation_function(Wx_plus_b)
return outputs定义placehoder和创建实际的网络结构
# 定义placeholder
# 输入的手写数字大小为8*8单位的数据
xs = tf.placeholder(tf.float32, [None, 8*8])
# 输出值为one hot结构的数据
ys = tf.placeholder(tf.float32, [None, 10])
# 添加层
# 第一层输入为8*8单位的手写输入数字图像,输出设定为100个神经元的层(为了能够看出是overfitting的问题),激活函数一般用tanh比较好
l1 = add_layer(xs, 8*8, 100, activation_function=tf.nn.tanh)
# 输出层因为最终是一个one hot的结构,因此输出的大小为10,激活函数用softmax
prediction = add_layer(l1, 100, 10, activation_function=tf.nn.softmax)定义损失函数
# 定义损失函数
cross_entropy = tf.reduce_mean(-tf.reduce_sum(ys * tf.log(prediction), axis=1))
# 在tensorboard中记录损失函数值
tf.summary.scalar(‘loss‘, cross_entropy)
# 用梯度下降优化器进行训练
train_step = tf.train.GradientDescentOptimizer(0.6).minimize(cross_entropy)记录损失函数并运行
sess = tf.Session()
merged = tf.summary.merge_all()
# 分别记录训练集的loss和测试集的loss值,目的是为了能够对比训练集和测试集中得拟合情况
train_writer = tf.summary.FileWriter("D:/todel/data/tensorflow/train", sess.graph)
test_writer = tf.summary.FileWriter("D:/todel/data/tensorflow/test", sess.graph)
init = tf.global_variables_initializer()
sess.run(init)
for i in range(500):
sess.run(train_step, feed_dict={xs:X_train, ys:y_train})
if i % 50 == 0:
# 分别用训练集和测试集数据获得损失函数值
train_result = sess.run(merged, feed_dict={xs:X_train, ys: y_train})
train_writer.add_summary(train_result, i)
test_result = sess.run(merged, feed_dict={xs:X_test, ys: y_test})
test_writer.add_summary(test_result, i)完整代码
from sklearn.datasets import load_digits
from sklearn.preprocessing import LabelBinarizer
from sklearn.model_selection import train_test_split
digits = load_digits()
X = digits.data
y = digits.target
# 把数值转换成one hot格式,例如:数字4就会被转换成:[0 0 0 0 1 0 0 0 0 0]
y = LabelBinarizer().fit_transform(y)
# 拆分数据集,以总量的30%作为测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
import tensorflow as tf
def add_layer(inputs, in_size, out_size, activation_function=None):
"""
添加层
:param inputs: 输入数据
:param in_size: 输入数据的列数
:param out_size: 输出数据的列数
:param activation_function: 激励函数
:return:
"""
# 定义权重,初始时使用随机变量,可以简单理解为在进行梯度下降时的随机初始点,这个随机初始点要比0值好,因为如果是0值的话,反复计算就一直是固定在0中,导致可能下降不到其它位置去。
Weights = tf.Variable(tf.random_normal([in_size, out_size]))
# 偏置shape为1行out_size列
biases = tf.Variable(tf.zeros([1, out_size]) + 0.1)
# 建立神经网络线性公式:inputs * Weights + biases,我们大脑中的神经元的传递基本上也是类似这样的线性公式,这里的权重就是每个神经元传递某信号的强弱系数,偏置值是指这个神经元的原先所拥有的电位高低值
Wx_plus_b = tf.matmul(inputs, Weights) + biases
if activation_function is None:
# 如果没有设置激活函数,则直接就把当前信号原封不动地传递出去
outputs = Wx_plus_b
else:
# 如果设置了激活函数,则会由此激活函数来对信号进行传递或抑制
outputs = activation_function(Wx_plus_b)
return outputs
# 定义placeholder
# 输入的手写数字大小为8*8单位的数据
xs = tf.placeholder(tf.float32, [None, 8*8])
# 输出值为one hot结构的数据
ys = tf.placeholder(tf.float32, [None, 10])
# 添加层
# 第一层输入为8*8单位的手写输入数字图像,输出设定为100个神经元的层(为了能够看出是overfitting的问题),激活函数一般用tanh比较好
l1 = add_layer(xs, 8*8, 100, activation_function=tf.nn.tanh)
# 输出层因为最终是一个one hot的结构,因此输出的大小为10,激活函数用softmax
prediction = add_layer(l1, 100, 10, activation_function=tf.nn.softmax)
# 定义损失函数
cross_entropy = tf.reduce_mean(-tf.reduce_sum(ys * tf.log(prediction), axis=1))
# 在tensorboard中记录损失函数值
tf.summary.scalar(‘loss‘, cross_entropy)
# 用梯度下降优化器进行训练
train_step = tf.train.GradientDescentOptimizer(0.6).minimize(cross_entropy)
sess = tf.Session()
merged = tf.summary.merge_all()
# 分别记录训练集的loss和测试集的loss值,目的是为了能够对比训练集和测试集中得拟合情况
train_writer = tf.summary.FileWriter("D:/todel/data/tensorflow/train", sess.graph)
test_writer = tf.summary.FileWriter("D:/todel/data/tensorflow/test", sess.graph)
init = tf.global_variables_initializer()
sess.run(init)
for i in range(500):
sess.run(train_step, feed_dict={xs:X_train, ys:y_train})
if i % 50 == 0:
# 分别用训练集和测试集数据获得损失函数值
train_result = sess.run(merged, feed_dict={xs:X_train, ys: y_train})
train_writer.add_summary(train_result, i)
test_result = sess.run(merged, feed_dict={xs:X_test, ys: y_test})
test_writer.add_summary(test_result, i)输出结果
当我们运行了上面的代码后,会在D:/todel/data/tensorflow/目录下生成tensorboard收集的日志文件,我们可以在那个目录下输入:

最终在tensorboard中显示的图形为:

我们发现,训练集(蓝色的那条曲线)损失值要比测试集(黄色的那条曲线)小,这样就存在过拟合的情况。
消除过拟合
为了消除过拟合,我们采用dropout方式来进行。
首先设置一个保留概率的placeholder,这样在运行时可以通过参数来进行设置
# 设置保留概率,即我们要保留的结果所占比例,它作为一个placeholder,在run时传入, 当keep_prob=1的时候,相当于100%保留,也就是dropout没有起作用。
keep_prob = tf.placeholder(tf.float32)然后在add_layer函数中调用dropout功能:
# 调用dropout功能
Wx_plus_b = tf.nn.dropout(Wx_plus_b, keep_prob)最后在训练时设置保留的概率,但在获得损失值时用全部的数据来进行获取:
for i in range(500):
sess.run(train_step, feed_dict={xs:X_train, ys:y_train, keep_prob: 0.7})
if i % 50 == 0:
# 分别用训练集和测试集数据获得损失函数值
train_result = sess.run(merged, feed_dict={xs:X_train, ys: y_train, keep_prob:1})
train_writer.add_summary(train_result, i)
test_result = sess.run(merged, feed_dict={xs:X_test, ys: y_test, keep_prob:1})
test_writer.add_summary(test_result, i)这样全部代码为:
from sklearn.datasets import load_digits
from sklearn.preprocessing import LabelBinarizer
from sklearn.model_selection import train_test_split
digits = load_digits()
X = digits.data
y = digits.target
# 把数值转换成one hot格式,例如:数字4就会被转换成:[0 0 0 0 1 0 0 0 0 0]
y = LabelBinarizer().fit_transform(y)
# 拆分数据集,以总量的30%作为测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
import tensorflow as tf
def add_layer(inputs, in_size, out_size, activation_function=None):
"""
添加层
:param inputs: 输入数据
:param in_size: 输入数据的列数
:param out_size: 输出数据的列数
:param activation_function: 激励函数
:return:
"""
# 定义权重,初始时使用随机变量,可以简单理解为在进行梯度下降时的随机初始点,这个随机初始点要比0值好,因为如果是0值的话,反复计算就一直是固定在0中,导致可能下降不到其它位置去。
Weights = tf.Variable(tf.random_normal([in_size, out_size]))
# 偏置shape为1行out_size列
biases = tf.Variable(tf.zeros([1, out_size]) + 0.1)
# 建立神经网络线性公式:inputs * Weights + biases,我们大脑中的神经元的传递基本上也是类似这样的线性公式,这里的权重就是每个神经元传递某信号的强弱系数,偏置值是指这个神经元的原先所拥有的电位高低值
Wx_plus_b = tf.matmul(inputs, Weights) + biases
# 调用dropout功能
Wx_plus_b = tf.nn.dropout(Wx_plus_b, keep_prob)
if activation_function is None:
# 如果没有设置激活函数,则直接就把当前信号原封不动地传递出去
outputs = Wx_plus_b
else:
# 如果设置了激活函数,则会由此激活函数来对信号进行传递或抑制
outputs = activation_function(Wx_plus_b)
return outputs
# 定义placeholder
# 输入的手写数字大小为8*8单位的数据
xs = tf.placeholder(tf.float32, [None, 8*8])
# 输出值为one hot结构的数据
ys = tf.placeholder(tf.float32, [None, 10])
# 设置保留概率,即我们要保留的结果所占比例,它作为一个placeholder,在run时传入, 当keep_prob=1的时候,相当于100%保留,也就是dropout没有起作用。
keep_prob = tf.placeholder(tf.float32)
# 添加层
# 第一层输入为8*8单位的手写输入数字图像,输出设定为100个神经元的层(为了能够看出是overfitting的问题),激活函数一般用tanh比较好
l1 = add_layer(xs, 8*8, 100, activation_function=tf.nn.tanh)
# 输出层因为最终是一个one hot的结构,因此输出的大小为10,激活函数用softmax
prediction = add_layer(l1, 100, 10, activation_function=tf.nn.softmax)
# 定义损失函数
cross_entropy = tf.reduce_mean(-tf.reduce_sum(ys * tf.log(prediction), axis=1))
# 在tensorboard中记录损失函数值
tf.summary.scalar(‘loss‘, cross_entropy)
# 用梯度下降优化器进行训练
train_step = tf.train.GradientDescentOptimizer(0.6).minimize(cross_entropy)
sess = tf.Session()
merged = tf.summary.merge_all()
# 分别记录训练集的loss和测试集的loss值,目的是为了能够对比训练集和测试集中得拟合情况
train_writer = tf.summary.FileWriter("D:/todel/data/tensorflow/train", sess.graph)
test_writer = tf.summary.FileWriter("D:/todel/data/tensorflow/test", sess.graph)
init = tf.global_variables_initializer()
sess.run(init)
for i in range(500):
sess.run(train_step, feed_dict={xs:X_train, ys:y_train, keep_prob: 0.7})
if i % 50 == 0:
# 分别用训练集和测试集数据获得损失函数值
train_result = sess.run(merged, feed_dict={xs:X_train, ys: y_train, keep_prob:1})
train_writer.add_summary(train_result, i)
test_result = sess.run(merged, feed_dict={xs:X_test, ys: y_test, keep_prob:1})
test_writer.add_summary(test_result, i)运行后输出tensorboard图形为(记得把之前的文件或目录进行删除并运行tensorboard进行显示图形):

这样训练集和测试集的损失值就比较接近了。
tensorflow用dropout解决over fitting的更多相关文章
- tensorflow用dropout解决over fitting-【老鱼学tensorflow】
在机器学习中可能会存在过拟合的问题,表现为在训练集上表现很好,但在测试集中表现不如训练集中的那么好. 图中黑色曲线是正常模型,绿色曲线就是overfitting模型.尽管绿色曲线很精确的区分了所有的训 ...
- tensorflow学习之(八)使用dropout解决overfitting(过拟合)问题
#使用dropout解决overfitting(过拟合)问题 #如果有dropout,在feed_dict的参数中一定要加入dropout的值 import tensorflow as tf from ...
- 4 TensorFlow入门之dropout解决overfitting问题
------------------------------------ 写在开头:此文参照莫烦python教程(墙裂推荐!!!) ---------------------------------- ...
- TensorFlow实战第七课(dropout解决overfitting)
Dropout 解决 overfitting overfitting也被称为过度学习,过度拟合.他是机器学习中常见的问题. 图中的黑色曲线是正常模型,绿色曲线就是overfitting模型.尽管绿色曲 ...
- 【转载】 深度学习总结:用pytorch做dropout和Batch Normalization时需要注意的地方,用tensorflow做dropout和BN时需要注意的地方,
原文地址: https://blog.csdn.net/weixin_40759186/article/details/87547795 ------------------------------- ...
- Tensorflow调试Bug解决办法记录
1.ascii' codec can't encode characters in position 0-4: ordinal not in range(128) 原因是python2.X默认的编码是 ...
- TF:利用sklearn自带数据集使用dropout解决学习中overfitting的问题+Tensorboard显示变化曲线—Jason niu
import tensorflow as tf from sklearn.datasets import load_digits #from sklearn.cross_validation impo ...
- 【TensorFlow】:解决TensorFlow的ImportError: DLL load failed: 动态链接库(DLL)初始化例程失败
[背景] 在scikit-learn基础上系统结合数学和编程的角度学习了机器学习后(我的github:https://github.com/wwcom614/machine-learning),意犹未 ...
- TensorFlow 用神经网络解决非线性问题
本节涉及点: 激活函数 sigmoid 产生随机训练数据 使用随机训练数据训练 加入偏移量b加快训练过程 进阶:批量生产随机训练数据 在前面的三好学生问题中,学校改变了评三好的标准 —— 总分> ...
随机推荐
- Altium Designer 19 导出光绘文件
一.点击 文件--制造输出--Gerber Files 第一次设置如下 绘制层点击进去全选 钻孔光圈 符号大小50mil 生成文件 关闭不用保存 蚀刻图 二.点击 文件--制造输出--Gerber F ...
- HTML5 Canvas(实战:绘制饼图2 Tooltip)
继上一篇HTML5 Canvas(实战:绘制饼图)之后,笔者研究了一下如何给饼图加鼠标停留时显示的提示框. Plot对象 在开始Coding之前,笔者能够想到的最easy的方式,就是给饼图的每一个区域 ...
- common pom
<dependencies> <dependency> <groupId>com.github.pagehelper</groupId> <art ...
- Linux学习-基于CentOS7的MariaDB数据库的主从复制
一.MySQL主从复制原理 主从同步过程中主服务器有一个工作线程I/O dump thread,从服务器有两个工作线程I/O thread和SQL thread: 主服务器: dump Thread: ...
- 安卓环境home assistant搭建
准备搞个智能家居玩玩 先从home assistant(后面简写为HASS)开始吧 莫得树莓派,拿旧手机凑活一下 准备材料: root过的安卓机 一.安卓机Linux环境搭建 个人习惯不详细写基础环境 ...
- PHP获取时间排除周六、周日的两个方法
//方法一: <?php $now = time(); //指定日期用法 $now = strtotime('2014-01-08') ; $day = 3600*24; $total = 12 ...
- HashMap与HashTable的哈希算法——JDK1.9源码阅读总结
下面是HashTable源码中的put方法: 注意上面注释标注的地方: HashTable对于元素在哈希表中的坐标算法是: 将对象自身的哈希值key.hashCode()变为正数:hash & ...
- ctcss
CTCSS解码器基于非常窄的带通滤波器,其通过所需的CTCSS音调.滤波器的输出经过放大和整流,只要存在所需的音调,就会产生直流电压.直流电压用于打开,启用或取消静音接收器的扬声器音频级.当音调存在时 ...
- Share架构的一些心得
个人这些年,从web->system service->app 项目实战,陆陆续续经历的项目很多,自己也数不清.自己也一直对于架构没有明确去给出一个自己的定义描述. 刚好最近一直在flut ...
- mybatis有结果返回null
解决:application.yml 中mybatis此项(解决驼峰及数据库字段有下划线问题) map-underscore-to-camel-case: true 问题: mybatis debug ...