Markov Decision Process in Detail
From the last post about MDP, we know the environment consists of 5 basic elements:
S:State Space of environment;
A:Actions Space that the environment allows;
{Ps,s'}:Transition Matrix, the probabilities of how environment state transit from one to another when actions are taken. The number of matrices equals to the number of actions.
R: Reward, when the system transitions from state s to s' due to action a, how much reward can an agent receive from the environment. Sometimes, reward have different definition.
γ: How reward discounts by time.
How Different between MDP and MRP:
Keyword: Action
The five elements of MDP can be illustrated by the chart below, in which the green circles are states, orange circles are actions, and there are two rewards. In MRP and Markov Process, we directly know the transition matrix. However, in the transition path from one state to another is interupted by actions. And it's worth noting that when the environment is at a certain state, there is no probabilities for actions. The reason is quite understandable: we live in the some world(environment), but different people have different behaviors.

Agent and Policy
Agent is the person or robot who interacts with the environment in Reinforcement Learning. Like human being, everyone may have different behavior under the same condition. The probability distribution of behaviors under different states is Policy. There are so many probabilities in an environment, but for a specific agent (person), he or she may take only one or several possible actions under a certain state. Given states, the policy is defined by:
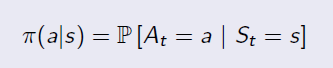
An example of policy is shown below:

From MRP to MDP: MRP+Policy
Transition Matrix: Without policies we do not exactly know the the probability from state s transitioning to s', because different agents may have different probabilitie to take actions. As long as we get π, we can calculate the state transition matrix. 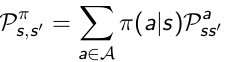
In the chart above, for example, if an agent has probabilitie 0.4 and 0.6 for action a0 and a1, the transition probability from s0 to s1 is: 0.4*0.5+0.6*1=0.8
Reward:
In MDP the reward function is related to actions, which average the uncertainties of the result from an action.
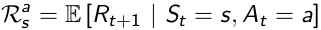
Once we've got the Policy π, we know the action distribution of a specific agent, so we can average the uncertaintie of actions, then measure how much immediate reward can receive from state s under policy π.

So now we go back from MDP to MRP, and the Markov Reward Process is defined by the tuple

Two Value Functions:
State Value Function:
State Value Function is the same as the value function in MRP. It is used to evaluate the goodness of being in a state s(by immedate and future reward), and the only difference is to average the uncertainty of actions under policy π. It is in the form of:
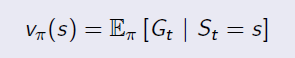
Action Value Function:
To average uncertainties of actions, it's neccesary to know the expected reward from possible actions. So we have Action Value Functionin MDP, which reveals whether an action is good or bad when an agent takes an particular action in state s.

If we calculate expectation of Action Value Functions under the same state s, we will end up with the State Value Function v:
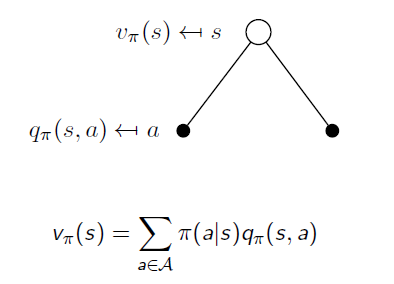
Similarly, when an action is taken, the system may end up with different states. When we remove the uncertainty of state transition, we go back from State Value Function to Action Value Function:
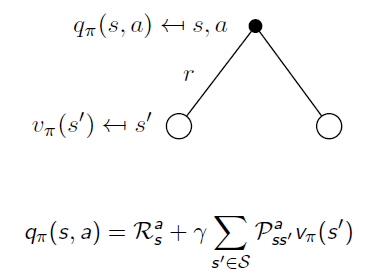
If we put them together:
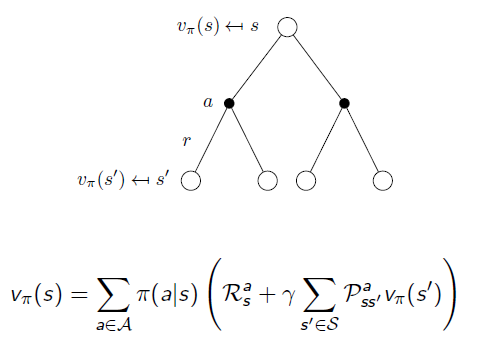
Another way:

Markov Decision Process in Detail的更多相关文章
- Step-by-step from Markov Process to Markov Decision Process
In this post, I will illustrate Markov Property, Markov Reward Process and finally Markov Decision P ...
- Ⅱ Finite Markov Decision Processes
Dictum: Is the true wisdom fortitude ambition. -- Napoleon 马尔可夫决策过程(Markov Decision Processes, MDPs ...
- Markov Decision Processes
为了实现某篇论文中的算法,得先学习下马尔可夫决策过程~ 1. https://leonardoaraujosantos.gitbooks.io/artificial-inteligence/conte ...
- Reinforcement Learning Index Page
Reinforcement Learning Posts Step-by-step from Markov Property to Markov Decision Process Markov Dec ...
- 论文笔记之:Learning to Track: Online Multi-Object Tracking by Decision Making
Learning to Track: Online Multi-Object Tracking by Decision Making ICCV 2015 本文主要是研究多目标跟踪,而 online ...
- 强化学习二:Markov Processes
一.前言 在第一章强化学习简介中,我们提到强化学习过程可以看做一系列的state.reward.action的组合.本章我们将要介绍马尔科夫决策过程(Markov Decision Processes ...
- (转) Deep Reinforcement Learning: Pong from Pixels
Andrej Karpathy blog About Hacker's guide to Neural Networks Deep Reinforcement Learning: Pong from ...
- 机器学习算法基础(Python和R语言实现)
https://www.analyticsvidhya.com/blog/2015/08/common-machine-learning-algorithms/?spm=5176.100239.blo ...
- How do I learn machine learning?
https://www.quora.com/How-do-I-learn-machine-learning-1?redirected_qid=6578644 How Can I Learn X? ...
随机推荐
- Weak Pair (dfs+树状数组)
Weak Pair (dfs+树状数组) 题意 这个题目是要求:一颗树上,有n个节点,给出每个节点的权值.另外给出一个值k,问有多少对节点满足: \(power[u]*power[v]<=k\) ...
- <meta>标签中http-equiv属性的属性值X-UA-Compatible详解
X-UA-Compatible是针对IE8新加的一个设置,对于IE8之外的浏览器是不识别的,这个区别与content="IE=7"在无论页面是否包含<!DOCTYPE> ...
- 基于socket 实现单线程并发
基于socket 实现单线程并发: 基于协程实现内IO的快速切换,我们必须提前导入from gevent import monkey;monkey pacth_all() 以为 gevent spaw ...
- MVC加深理解
MVC MVC约定:Controllers文件夹 对应 Views文件夹:所有子文件的名称一一对应. 页面请求 -> 路由 -> 找到 controller/action -> re ...
- lua视频教程三套高清新
目录 1. 下载地址 2. 某网校 Lua 经典教程 3. lua脚本语言零基础开发教程19课全 4. LUA完整视频+Cocos2d-x项目实战 1. 下载地址 https://www.cnblog ...
- tf.clip_by_global_norm
首先明白这个事干嘛的,在我们做求导的时候,会遇到一种情况,求导函数突然变得特别陡峭,是不是意味着下一步的进行会远远高于正常值,这个函数的意义在于,在突然变得陡峭的求导函数中,加上一些判定,如果过于陡峭 ...
- Django登录(含随机生成图片验证码)注册实例
登录,生成随机图片验证码 一.登录 - 随机生成图片验证码 1.随机生成验证码 Python随机生成图片验证码,需要使用PIL模块,安装方式如下: pip3 install pillow 1)创建图片 ...
- centos 6.5 安装 maven
从nexus官网下载Nexus Repository Manager OSS 2.x的安装包:nexus-2.14.1-01-bundle.tar.gz,3.x版本需要jdk8及以上 解压 tar x ...
- nginx之安装
1.简介 Nginx是一款轻量级的Web 服务器/反向代理服务器及电子邮件(IMAP/POP3)代理服务器,并在一个BSD-like 协议下发行.由俄罗斯的程序设计师Igor Sysoev所开发,供俄 ...
- 调整ceph的pg数(pg_num, pgp_num)
https://www.jianshu.com/p/ae96ee24ef6c 调整ceph的pg数 PG全称是placement groups,它是ceph的逻辑存储单元.在数据存储到cesh时,先打 ...