CUDA编程之环境配置
VS2015+CUDA8.0环境配置
Anyway,在这里记录下正确的配置方式:
1、首先,上官网下载对应vs版本的CUDA toolkit:
https://developer.nvidia.com/cuda-toolkit-50-archive
(记住vs2010对应CUDA5.0,vs2013对应CUDA7.5,vs2015对应CUDA8.0)
2、接着,直接安装,记得在安装过程中如果你不想换你原有的显卡驱动的话,就选择自定义不安装driver;否则如果你直接选“精简”又不安装驱动,则CUDA安装无法成功。
3、安装完成之后,进入C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v8.0 之后可以看到有好几个文件夹:bin、lib 、include等等,这就表明安装成功了
4、接下来,看看如何创建一个利用cuda编程的项目,打开vs创建项目时,你可以看到有了新的项目类型:

但是我们这里教你如何在一个空项目中编译cu文件,所以我们还是 创建一个vc++的空项目,接着创建一个新的cpp文件和cu文件
test.cpp代码如下:
#include <time.h>
#include <stdlib.h>
#include <stdio.h>
//这里不要忘了加引用声明
extern "C" void MatrixMultiplication_CUDA(const float* M, const float* N, float* P, int Width);
//构造函数...
//析构函数...
// 产生矩阵,矩阵中元素0~1
void matgen(float* a, int Width)
{
int i, j;
for (i = 0; i < Width; i++)
{
for (j = 0; j < Width; j++)
{
a[i * Width + j] = (float)rand() / RAND_MAX + (float)rand() / (RAND_MAX*RAND_MAX);
}
}
}
//矩阵乘法(CPU验证)
void MatrixMultiplication(const float* M, const float* N, float* P, int Width)
{
int i, j, k;
for (i = 0; i < Width; i++)
{
for (j = 0; j < Width; j++)
{
float sum = 0;
for (k = 0; k < Width; k++)
{
sum += M[i * Width + k] * N[k * Width + j];
}
P[i * Width + j] = sum;
}
}
}
double MatrixMul_GPU()
{
float *M, *N, *Pg;
int Width = 1024; //1024×1024矩阵乘法
M = (float*)malloc(sizeof(float)* Width * Width);
N = (float*)malloc(sizeof(float)* Width * Width);
Pg = (float*)malloc(sizeof(float)* Width * Width); //保存GPU计算结果
srand(0);
matgen(M, Width); //产生矩阵M
matgen(N, Width); //产生矩阵N
double timeStart, timeEnd; //定义时间,求时间差用
timeStart = clock();
MatrixMultiplication_CUDA(M, N, Pg, Width); //GPU上计算
timeEnd = clock();
free(M);
free(N);
free(Pg);
return timeEnd - timeStart;
}
double MatrixMul_CPU()
{
float *M, *N, *Pc;
int Width = 1024; //1024×1024矩阵乘法
M = (float*)malloc(sizeof(float)* Width * Width);
N = (float*)malloc(sizeof(float)* Width * Width);
Pc = (float*)malloc(sizeof(float)* Width * Width); //保存CPU计算结果
srand(0);
matgen(M, Width); //产生矩阵M
matgen(N, Width); //产生矩阵N
double timeStart, timeEnd; //定义时间,求时间差用
timeStart = clock();
MatrixMultiplication(M, N, Pc, Width); //CPU上计算
timeEnd = clock();
free(M);
free(N);
free(Pc);
return timeEnd - timeStart;
}
//////////////////////////////////////////////////////////////////////////
int main()
{
printf("CPU use time %g\n", MatrixMul_CPU());
printf("GPU use time %g\n", MatrixMul_GPU());
system("pause");
return 0;
}
test.cu代码如下:
////CUDAtest.cu
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#define TILE_WIDTH 16
// 核函数
// __global__ static void MatrixMulKernel(const float* Md,const float* Nd,float* Pd,int Width)
__global__ void MatrixMulKernel(const float* Md, const float* Nd, float* Pd, int Width)
{
//计算Pd和Md中元素的行索引
int Row = blockIdx.y * TILE_WIDTH + threadIdx.y; //行
int Col = blockIdx.x * TILE_WIDTH + threadIdx.x; //列
float Pvalue = 0.0;
for (int k = 0; k < Width; k++)
{
Pvalue += Md[Row * Width + k] * Nd[k * Width + Col];
}
//每个线程负责计算P中的一个元素
Pd[Row * Width + Col] = Pvalue;
}
// 矩阵乘法(CUDA中)
// 在外部调用,使用extern
extern "C" void MatrixMultiplication_CUDA(const float* M, const float* N, float* P, int Width)
{
cudaSetDevice(0); //设置目标GPU
float *Md, *Nd, *Pd;
int size = Width * Width * sizeof(float);//字节长度
cudaMalloc((void**)&Md, size);
cudaMalloc((void**)&Nd, size);
cudaMalloc((void**)&Pd, size);
//Copies a matrix from the memory* area pointed to by src to the memory area pointed to by dst
cudaMemcpy(Md, M, size, cudaMemcpyHostToDevice);
cudaMemcpy(Nd, N, size, cudaMemcpyHostToDevice);
//
dim3 dimGrid(Width / TILE_WIDTH, Width / TILE_WIDTH); //网格的维度
dim3 dimBlock(TILE_WIDTH, TILE_WIDTH); //块的维度
MatrixMulKernel <<< dimGrid, dimBlock >>>(Md, Nd, Pd, Width);
cudaMemcpy(P, Pd, size, cudaMemcpyDeviceToHost);
//释放设备上的矩阵
cudaFree(Md);
cudaFree(Nd);
cudaFree(Pd);
}接下来就是第三方库的链接了,首先呢,你得右击项目,打开项目属性
分别在可执行文件目录下输入:C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v8.0\bin
在包含目录下输入:C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v8.0\include
在库目录下输入:C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v8.0\lib\Win32

之后在链接器/输入/附加依赖项中输入:C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v8.0\lib\Win32目录下的所有lib文件的文件名
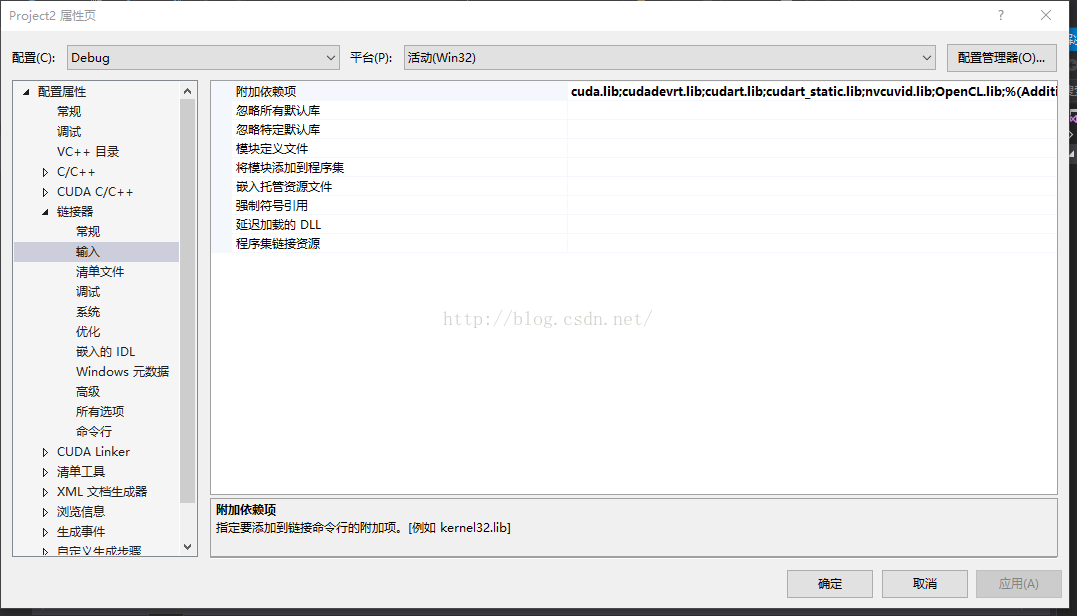
这时,如果你急于立马编译的话,你就会发现报错了:大致的意思是extern修饰的函数被应用,无法解析的外部命令
因为这时其实编译器没有编译cu文件,所以cpp文件中无法引用cu文件里的函数。
最关键的一步来了:
右击项目,点击生成依赖 项,选择“生成自定义”,然后勾选cuda
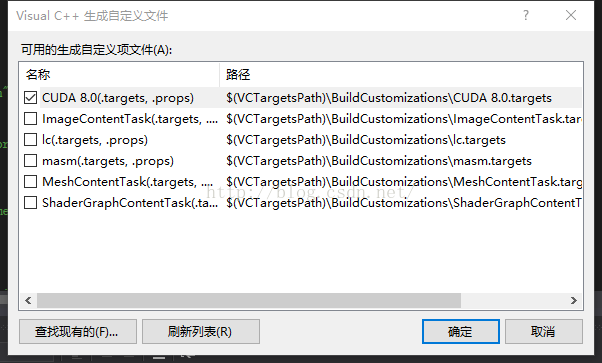
之后右击test.cu文件打开属性,修改“项目类型”如下:
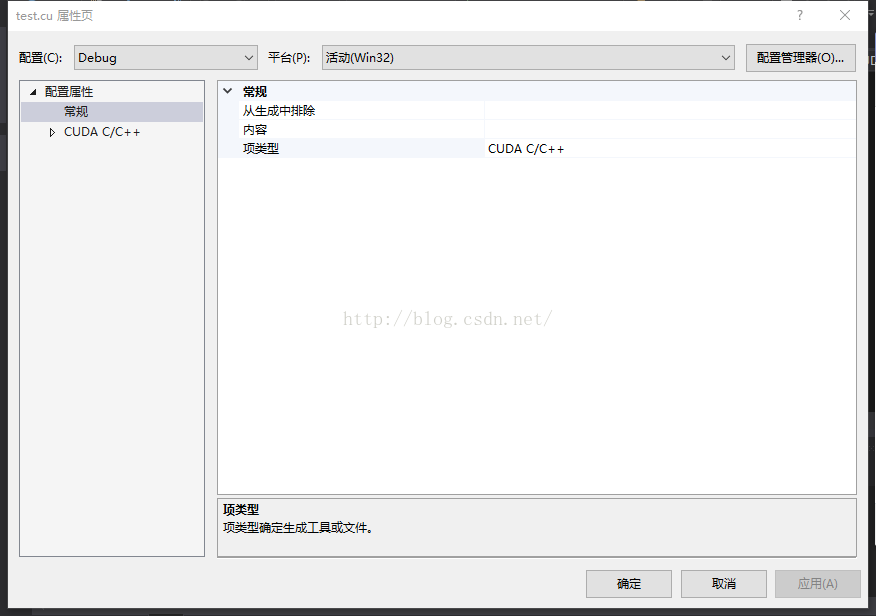
大功告成,愉快的调试吧
CUDA编程之环境配置的更多相关文章
- CUDA学习,环境配置和简单例子
根据摩尔定律,每18个月,硬件的速度翻一番.纵使CPU的主频会越来越高,但是其核数受到了极大的限制,目前来说,最多只有8个或者9个核.相比之下,GPU具有很大的优势,他有成千上万个核,能完成大规模的并 ...
- STM32编程环境配置(kile5)
2018-08-2513:53:33 折腾了很久,花了两天的空闲时间终于烧进去程序了.完成了kile5对stm32编程的环境配置. 1.下载kile5 激活破解 2.安装stm32配置环境 3.加载工 ...
- GPU编程自学2 —— CUDA环境配置
深度学习的兴起,使得多线程以及GPU编程逐渐成为算法工程师无法规避的问题.这里主要记录自己的GPU自学历程. 目录 <GPU编程自学1 -- 引言> <GPU编程自学2 -- CUD ...
- Java/javaEE/web/jsp/网站编程环境配置及其软件下载和网站路径
Java/javaEE/web/jsp/网站编程环境配置及其软件下载和网站路径 (2015/07/08更新) JDK下载地址(JDK官网下载地址) 下载地址为:http://www.oracle.co ...
- 【软件安装与环境配置】ubuntu16.04+caffe+nvidia+CUDA+cuDNN安装配置
前言 博主想使用caffe框架进行深度学习相关网络的训练和测试,刚开始做,特此记录学习过程. 环境配置方面,博主以为最容易卡壳的是GPU的NVIDIA驱动的安装和CUDA的安装,前者尝试的都要吐了,可 ...
- windows下《Go Web编程》之Go环境配置和安装
<Go Web编程>笔者是基于unix下讲述的,作为入门练手,我选择在windows下开发,全程按照目录进行... 一.安装 windows下需要安装MinGW,通过MinGW安装gcc支 ...
- 深度学习 GPU环境 Ubuntu 16.04 + Nvidia GTX 1080 + Python 3.6 + CUDA 9.0 + cuDNN 7.1 + TensorFlow 1.6 环境配置
本节详细说明一下深度学习环境配置,Ubuntu 16.04 + Nvidia GTX 1080 + Python 3.6 + CUDA 9.0 + cuDNN 7.1 + TensorFlow 1.6 ...
- CUDA & cuDNN环境配置
环境 python3.5 tensorflow 1.3 VUDA 8.0 cuDNN V6.0 1.确保GPU驱动已经安装 lspci | grep -i nvidia 通过此命令可以查看GPU信息 ...
- TensorFlow-GPU环境配置之二——CUDA环境配置
1.安装最新显卡驱动 到系统设置->软件和更新->附加驱动中选中最新的显卡驱动,并应用 2.下载CUDA8.0 https://developer.nvidia.com/cuda-down ...
随机推荐
- RFC6241 NETCONF
概述 NETCONF = The Network Configuration Protocol SDN = Software Define Network NETCONF协议分为传输层.消息层.操作层 ...
- 用 Flask 来写个轻博客 (10) — M(V)C_Jinja 常用过滤器与 Flask 特殊变量及方法
Blog 项目源码:https://github.com/JmilkFan/JmilkFan-s-Blog 目录 目录 前文列表 Jinja 中常用的过滤器 default float int len ...
- linux命令行光标移动技巧
看一个真正的专家操作命令行绝对是一种很好的体验-光标在单词之间来回穿梭,命令行不同的滚动.在这里强烈建立适应GUI节目的开发者尝试一下在提示符下面工作.但是事情也不是那么简单,还是需要知道“如何去做” ...
- 使用 vue.js 的一些操作记录
vue.js不支持ie8以下 1. 在html的属性中赋值: 需要在属性前加上 v-bind
- selenium 3 下载 + Java使用
一.下载Selenium 3 的相关包和工具 Selenium 3 下载的官网地址为http://www.seleniumhq.org/download/.当然,需要翻墙才能登陆selenium的官网 ...
- C++ STL rope 可持久化平衡树 (可持久化数组)
官方文档好像 GG 了. rope 不属于标准 STL,属于扩展 STL,来自 pb_ds 库 (Policy-Based Data Structures). 基本操作: #include <e ...
- PAT甲级——A1148 WerewolfSimpleVersion【20】
Werewolf(狼人杀) is a game in which the players are partitioned into two parties: the werewolves and th ...
- Java转型大数据开发全套教程,都在这儿!
众所周知,很多语言技术已经在长久的历史发展中掩埋,这期间不同的程序员也走出的自己的发展道路. 有的去了解新的发展趋势的语言,了解新的技术,利用自己原先的思维顺利改变自己的title. 比如我自己,也都 ...
- c# 陈景润 15 子问题
初学编程时在 csdn 上写过一个陈景润 15 子问题的项目,https://blog.csdn.net/weixin_41628344/article/details/79171846 当时的主要精 ...
- 【知识强化】第五章 输入/输出(I/O)管理 5.2 I/O核心子系统I
学习I/O核心子系统相关的一系列功能. 设备独立性软件.设备驱动程序.中断处理程序这三层其实是属于操作系统的内核部分的,所以它们也称作“I/O核心子系统”,又可以简称为“I/O系统”.在考研当中我们需 ...