记一次css字体反爬
前段时间在看css反爬的时候,发现很多网站都做了css反爬,比如,设置字体反爬的(58同城租房版块,实习僧招聘https://www.shixiseng.com/等)设置雪碧图反爬的(自如租房http://gz.ziroom.com/)。
还有一个网站本身是没有其他反爬措施的,只是设置了字体反爬,但是这个网站的反爬就有些扯淡,http://www.qiwen007.com/,我们随便点开一个文章,并打开开发者工具
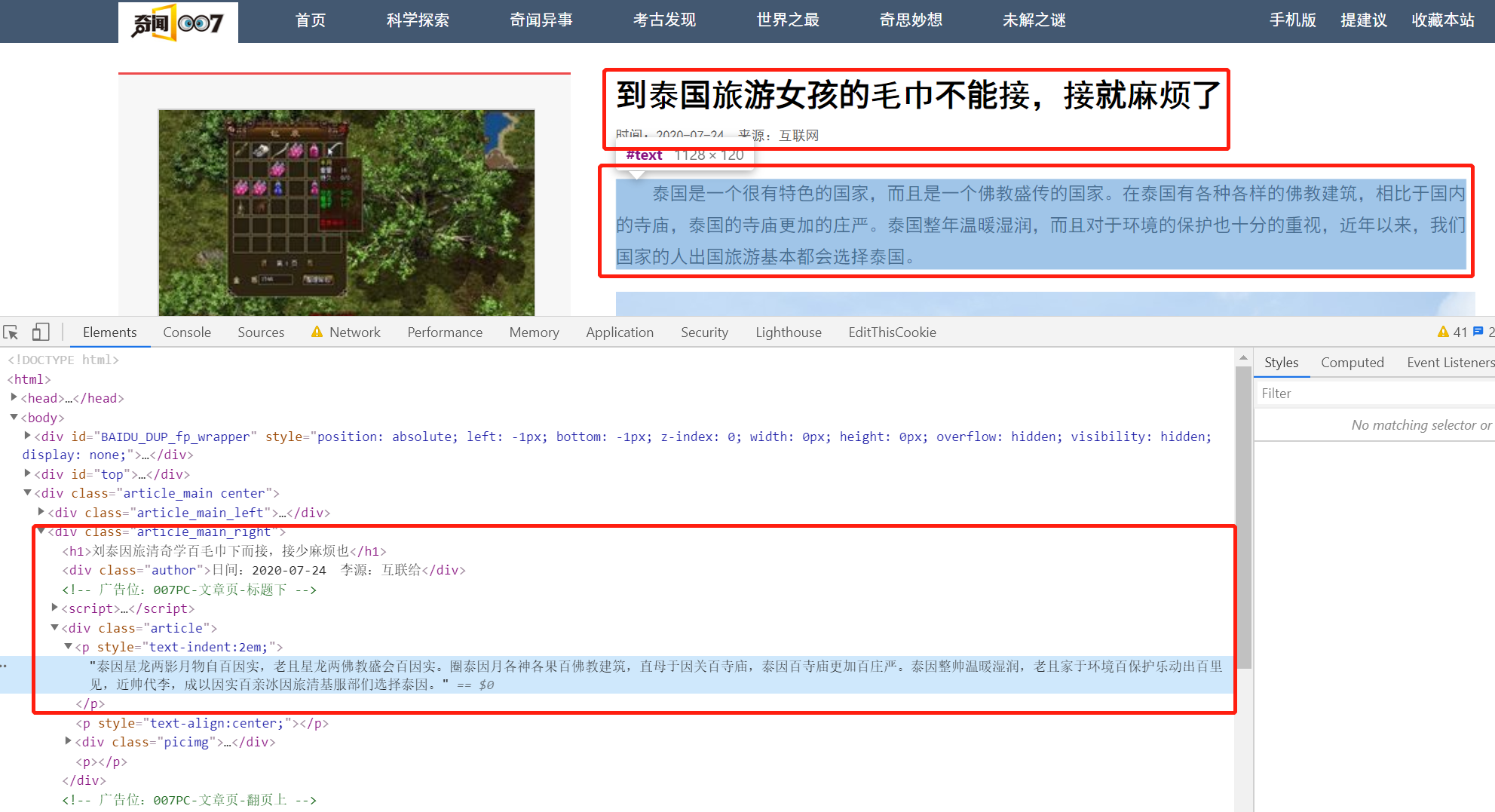
其中的文字并不是像其他字体反爬一样,是将某些文字转为了Unicode显示在源码中的
首先来看一下破解流程及思路:
import requests
from lxml import etree
from fontTools.ttLib import TTFont
from xml.dom.minidom import parse """
此案例是破解css反爬 网站:http://www.qiwen007.com
经过查看网站页面源码后发现,tff文字库是 '/hansansjm.ttf',因此判定该网站的文字库不会自动变换 woff/ttf文件样式查看(在线) http://fontstore.baidu.com/static/editor/index.html
也可以使用FontCreator(下载地址) https://www.onlinedown.net/soft/88758.htm
""" """
流程及思路:
1. 通过requests请求获取响应数据,得到的就是源码中加密数据(杂乱的文章)
2. 将加密数据的每一个字符转成Unicode编码,得到字符的Unicode列表
3. 通过搜索源码中font-face关键字,找到字体库文件(ttf/woff文件)将当前域名拼接上/hansansjm.ttf,即 http://www.qiwen007.com/hansansjm.ttf,打开后即下载
4. 使用FontCreator或者百度字体编辑器打开ttf文件,会看到里面每个字符
5. 将ttf转为xml文件
6. 同时使用pycharm打开xml文件,找到 glyf 标签下面的 TTGlyph 标签,里面的name 即是xml文件中的Unicode编码,
里面contour下面的pt的x,y即是每个字符的坐标,计算坐标差(计算坐标差的时候,可以直接取第一个contour的前两组pt即可)
(但是 TTGlyph name的顺序 有可能和ttf文件里面的字符的Unicode顺序对应不上,此时就要从GlyphOrder里面看是否对应,
如果对应,就从GlyphOrder中获取每个xml文件中的每个字符的Unicode列表,然后遍历列表,从 glyf 中找到对应的坐标)
7. 手动去组成汉字字符的列表,然后使用映射(dict(zip()))得到汉字和坐标差的映射
8. 在第6步中我们可以获取Unicode和坐标差的映射
9. 然后回到第2步,拿到加密数据的Unicode编码列表后,去Unicode和坐标差的映射中找到对应的坐标差,拿到坐标差后找到对应的汉字
至此,破解过程结束
""" # 此汉字列表,需要通过百度字体编辑器(在线)打开ttf/woff文件,或者FontCreator,将全部汉字按照顺序写到列表中
hans_list = ['万', '三', '上', '下', '不', '与', '世', '东', '两', '个', '中', '为', '主',
'丽', '么', '之', '乐', '也', '了', '事', '二', '五', '些', '亲', '人', '什', '今',
'他', '代', '以', '们', '会', '传', '位', '体', '何', '作', '你', '值', '做', '像',
'儿', '元', '光', '入', '全', '公', '关', '内', '写', '冰', '出', '分', '刘', '到',
'前', '剧', '力', '动', '十', '千', '却', '原', '去', '友', '发', '变', '古', '只',
'可', '吃', '合', '同', '名', '后', '吗', '吴', '员', '和', '四', '回', '因', '国',
'图', '圈', '在', '地', '场', '型', '外', '多', '大', '天', '太', '夫', '头', '奇',
'女', '她', '好', '如', '妈', '妻', '娱', '婚', '子', '学', '孩', '宝', '实', '家',
'对', '将', '小', '少', '就', '山', '岁', '已', '巴', '帅', '年', '底', '度', '开',
'张', '当', '影', '很', '得', '心', '性', '怪', '情', '惊', '想', '意', '感', '戏',
'成', '我', '房', '手', '打', '拍', '排', '新', '方', '无', '日', '时', '明', '星',
'是', '曝', '曾', '最', '月', '有', '服', '本', '机', '李', '来', '杨', '林', '果',
'样', '榜', '次', '死', '母', '比', '民', '气', '水', '没', '法', '活', '海', '清',
'游', '演', '火', '点', '热', '然', '照', '爱', '片', '物', '特', '狗', '王', '现',
'球', '生', '用', '电', '男', '界', '白', '百', '的', '直', '相', '看', '真', '眼',
'着', '知', '神', '种', '秘', '称', '穿', '竟', '笑', '第', '粉', '红', '经', '结',
'给', '网', '美', '老', '而', '能', '脸', '自', '色', '艺', '花', '英', '行', '衣',
'被', '装', '西', '要', '见', '视', '认', '让', '说', '谁', '走', '赵', '起', '超',
'路', '身', '车', '过', '还', '这', '造', '道', '遭', '部', '都', '里', '重', '金',
'长', '陈', '面', '颖', '颜', '食', '马', '高', '鱼', '黄', '黑', '龙', '一',
] def get_result_article():
"""获取加密文章内容"""
url = 'http://www.qiwen007.com/mb-db/pc-sg/zbwz/363609.html'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36',
}
resp = requests.get(url=url, headers=headers) html = etree.HTML(resp.text) p_list = html.xpath('//div[@class="article"]/p')
for p in p_list:
temp_article = p.xpath('./text()')
if len(temp_article) > 0:
print('temp_article', temp_article)
result = to_unicode(temp_article[0])
print('result', result)
break def to_unicode(temp_article):
"""将汉字全部转为Unicode编码"""
bytes_article = temp_article.encode(encoding='unicode-escape')
str_article_li = str(bytes_article)[2:-1].split('\\')
uni_article_li = ['uni' + uni[1:].upper() for uni in str_article_li if uni != '']
# print(uni_article_li)
return parse_uni(uni_article_li) def parse_uni(uni_article_li):
# 获取坐标差汉字映射,和 Unicode 坐标差的映射
get_map = get_coordinate_hans_and__unicode_coordinate_map
coordinate_hans_map, _unicode_coordinate_map = get_map()
result_article_content = ''
for uni in uni_article_li:
if uni in list(_unicode_coordinate_map.keys()):
coordinate = _unicode_coordinate_map.get(uni)
hans = coordinate_hans_map.get(coordinate)
# print('1', hans)
result_article_content += hans
else:
hans = chr(int(uni[3:], 16))
# print('2', hans)
result_article_content += hans return result_article_content # 将ttf/woff文件转换为xml文件(ttf/woff文件pycharm打开是乱码,xml可以打开)
def ttf_to_xml():
font = TTFont('hansansjm.ttf')
# 此时就将ttf/woff文件转换为了xml文件
font.saveXML('hansansjm.xml') def get_coordinate_hans_and__unicode_coordinate_map():
"""
获取所有汉字和坐标差的映射,和 Unicode和坐标差的映射,
接下来便可以通过映射找到Unicode所对应的坐标差,
拿到坐标差之后,就可以再通过coordinate_hans_map,找到具体的汉字
"""
# 存储该hansansjm.xml文件中所有的字符坐标差
coordinate_diff_list = [] # Unicode和坐标差的映射
_unicode_coordinate_map = {} print('>>> 开始计算xml文件中所有字符的坐标差')
content = parse('hansansjm.xml')
# 此处有个坑,应当先获取GlyphOrder中的GlyphID对应的name即Unicode,这里的Unicode是和ttf文件中一一对应的
# 而glyf中的TTGlyph对应的name(Unicode)不是和ttf文件中一一对应的
# 应该拿到GlyphOrder 下面所有的Unicode编码后,再去 glyf中根据Unicode找对应的坐标
GlyphID_list = content.getElementsByTagName('GlyphID')
TTGlyph_list = content.getElementsByTagName('TTGlyph')
# 由于xml文件中glyf下面的第一个TTGlyph 所对应的Unicode为.notdef ,要剔除掉,因此TTGlyph_list不能包含第一个元素
# 注意:如果最后一个元素也不是Unicode编码的,应当也要剔除掉 # 获取GlyphID下面所有的Unicode编码
GlyphID_uni_list = []
for GlyphID in GlyphID_list[1:]:
# 获取Unicode
_unicode = GlyphID.getAttribute('name')
GlyphID_uni_list.append(_unicode)
for uni in GlyphID_uni_list:
for TTGlyph in TTGlyph_list[1:]:
if uni == TTGlyph.getAttribute('name'):
# 获取第一个contour
# print(TTGlyph.getElementsByTagName('contour')[0])
first_contour = TTGlyph.getElementsByTagName('contour')[0] # 获取第一个contour中的前两个pt元素,进一步获取这两个元素的x,y属性,便于计算坐标差
first_pt = first_contour.getElementsByTagName('pt')[0]
first_pt_x = int(first_pt.getAttribute('x'))
first_pt_y = int(first_pt.getAttribute('y'))
# print(first_pt_x, first_pt_y) second_pt = first_contour.getElementsByTagName('pt')[1]
second_pt_x = int(second_pt.getAttribute('x'))
second_pt_y = int(second_pt.getAttribute('y'))
# print(second_pt_x, second_pt_y) # 计算坐标差
coordinate_diff = (second_pt_x - first_pt_x, second_pt_y - first_pt_y)
# print(coordinate_diff)
coordinate_diff_list.append(coordinate_diff)
# break
_unicode_coordinate_map[uni] = coordinate_diff # print(coordinate_diff_list) # 将坐标差和汉字组成字典,完成映射
coordinate_hans_map = dict(zip(coordinate_diff_list, hans_list))
print(coordinate_hans_map)
print(_unicode_coordinate_map)
return coordinate_hans_map, _unicode_coordinate_map # ttf_to_xml()
get_result_article()
这里说明一下,为什么加密内容转Unicode之后不能直接用的原因,因为加密内容的Unicode和ttf文件中的Unicode不对应

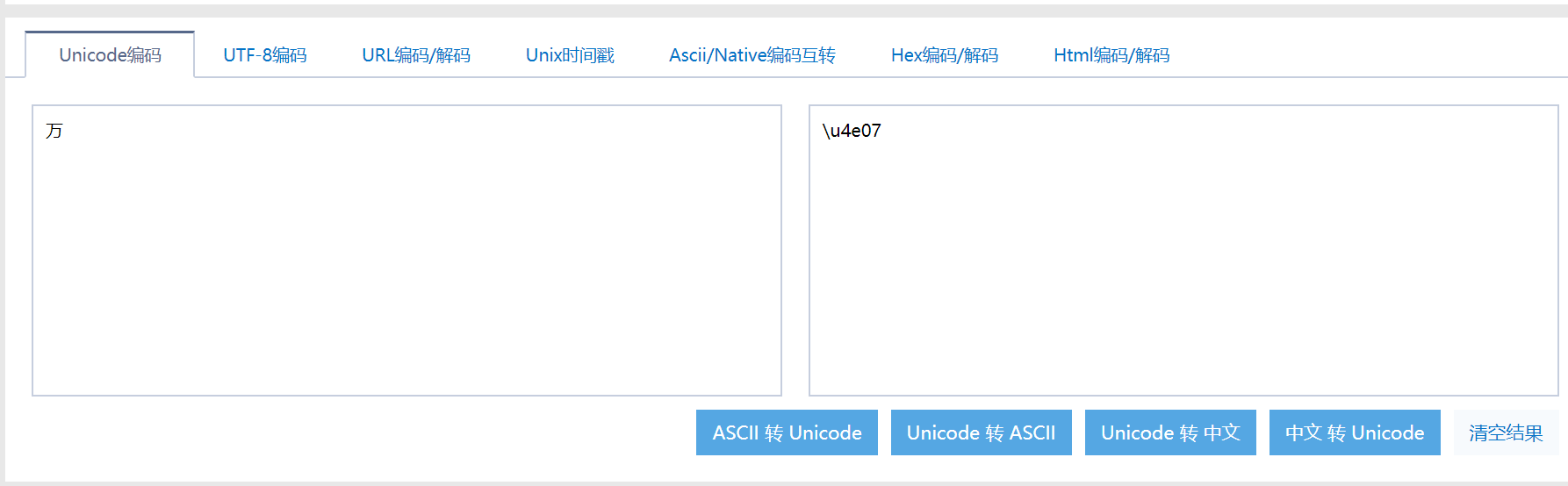
可以看到在ttf文件中万字的编码为uni2F00,而在Unicode在线编码中 为\u4e07,uni 和 \u 可忽略,直接看后四位,后面代码中有做转换
获取文章加密内容,及将每个字符转为Unicode编码
def get_source_article():
"""获取加密文章内容"""
url = 'http://www.qiwen007.com/mb-db/pc-sg/zbwz/363609.html'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36',
}
resp = requests.get(url=url, headers=headers) html = etree.HTML(resp.text) p_list = html.xpath('//div[@class="article"]/p')
for p in p_list:
temp_article = p.xpath('./text()')
if len(temp_article) > 0:
print('temp_article', temp_article)
result = to_unicode(temp_article[0])
print('result', result)
break def to_unicode(temp_article):
"""将汉字全部转为Unicode编码"""
bytes_article = temp_article.encode(encoding='unicode-escape')
str_article_li = str(bytes_article)[2:-1].split('\\')
uni_article_li = ['uni' + uni[1:].upper() for uni in str_article_li if uni != '']
print(uni_article_li)
将ttf文件或者woff文件转为xml文件
# 将ttf/woff文件转换为xml文件(ttf/woff文件pycharm打开是乱码,xml可以打开)
from fontTools.ttLib import TTFont
font = TTFont('hansansjm.ttf')
# 此时就将ttf/woff文件转换为了xml文件
font.saveXML('hansansjm.xml')
坑:TTGlyph name的顺序 有可能和ttf文件里面的字符的Unicode顺序对应不上
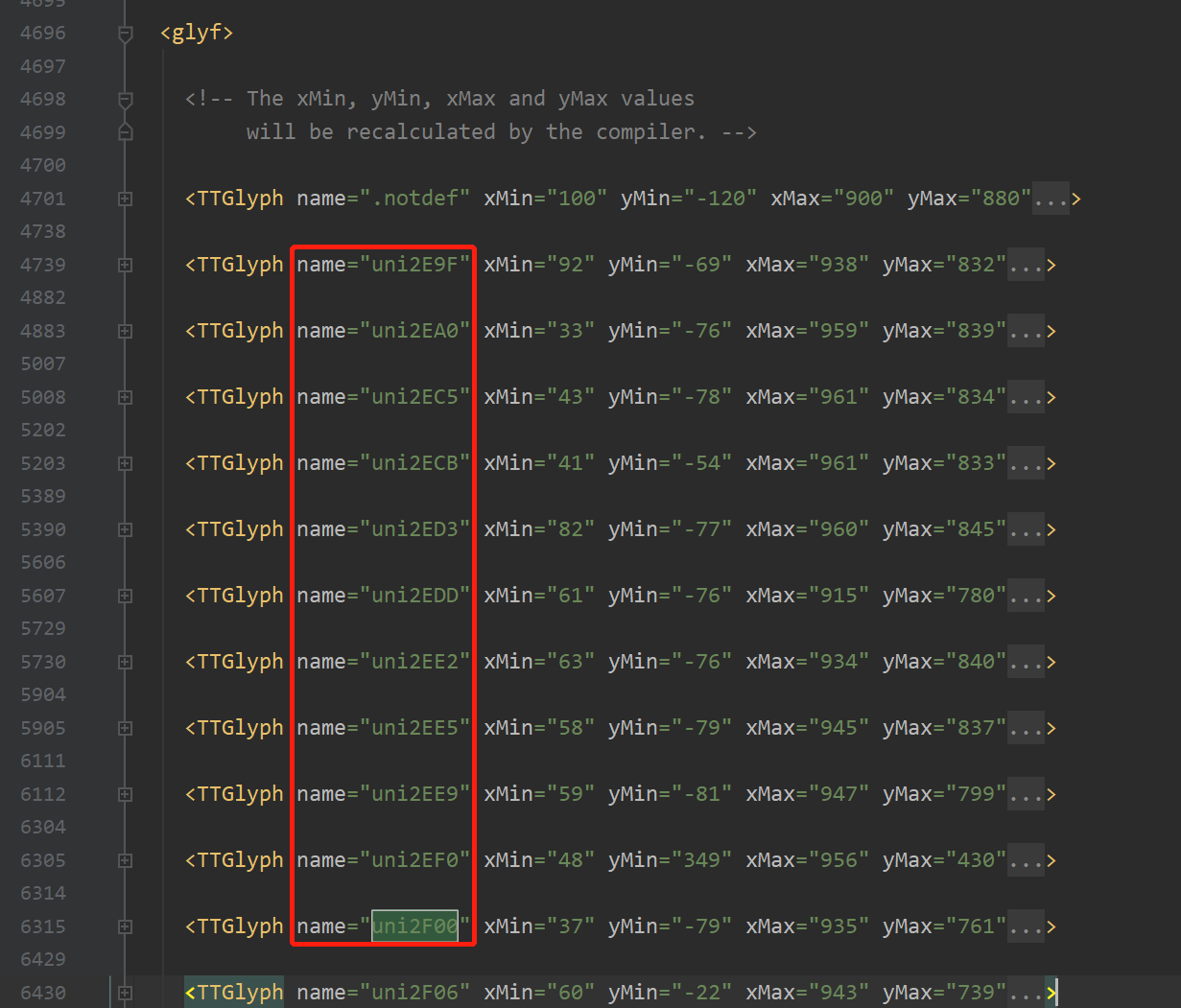

此时就要找 GlyphOrder 中的name
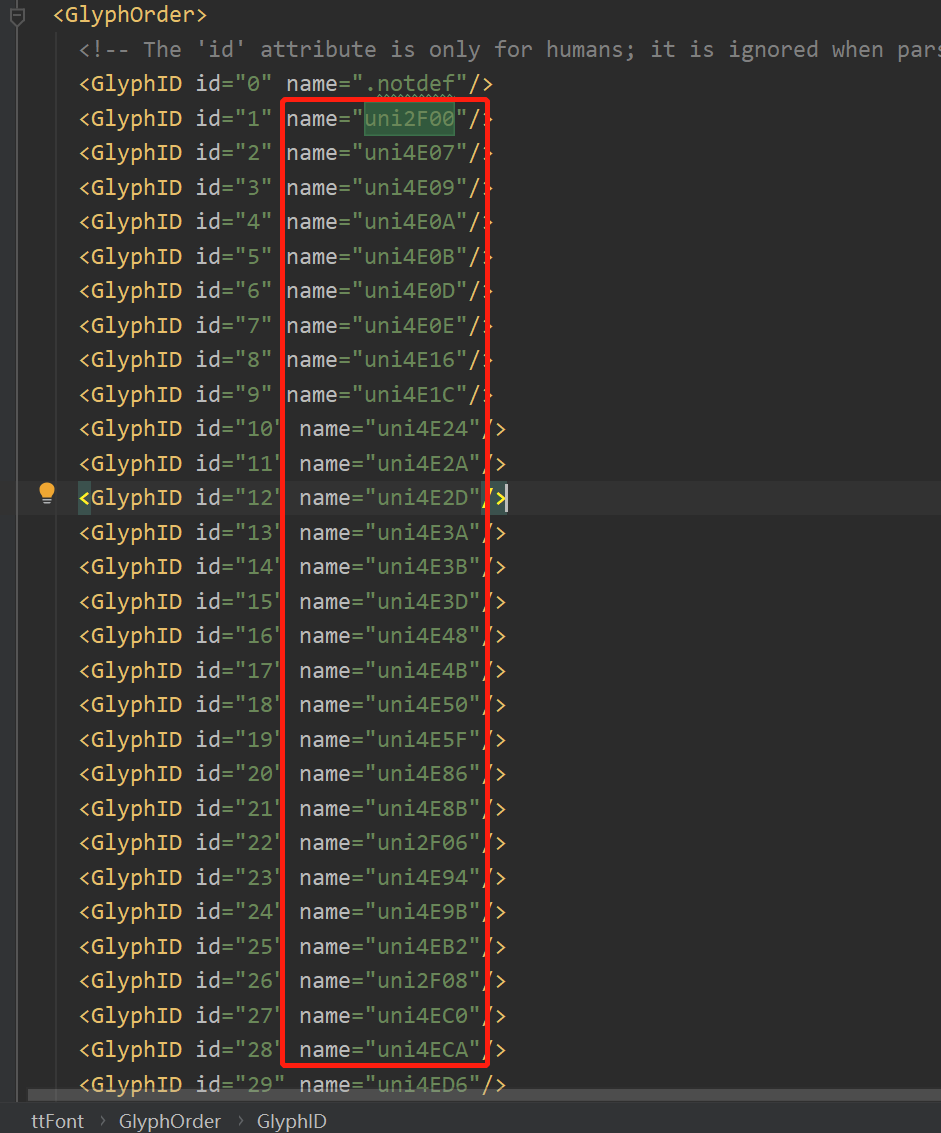
组成 所有汉字和坐标差的映射,和 Unicode和坐标差的映射
# 此汉字列表,需要通过百度字体编辑器(在线)打开ttf/woff文件,或者FontCreator,将全部汉字按照顺序写到列表中
hans_list = ['万', '三', '上', '下', '不', '与', '世', '东', '两', '个', '中', '为', '主',
'丽', '么', '之', '乐', '也', '了', '事', '二', '五', '些', '亲', '人', '什', '今',
'他', '代', '以', '们', '会', '传', '位', '体', '何', '作', '你', '值', '做', '像',
'儿', '元', '光', '入', '全', '公', '关', '内', '写', '冰', '出', '分', '刘', '到',
'前', '剧', '力', '动', '十', '千', '却', '原', '去', '友', '发', '变', '古', '只',
'可', '吃', '合', '同', '名', '后', '吗', '吴', '员', '和', '四', '回', '因', '国',
'图', '圈', '在', '地', '场', '型', '外', '多', '大', '天', '太', '夫', '头', '奇',
'女', '她', '好', '如', '妈', '妻', '娱', '婚', '子', '学', '孩', '宝', '实', '家',
'对', '将', '小', '少', '就', '山', '岁', '已', '巴', '帅', '年', '底', '度', '开',
'张', '当', '影', '很', '得', '心', '性', '怪', '情', '惊', '想', '意', '感', '戏',
'成', '我', '房', '手', '打', '拍', '排', '新', '方', '无', '日', '时', '明', '星',
'是', '曝', '曾', '最', '月', '有', '服', '本', '机', '李', '来', '杨', '林', '果',
'样', '榜', '次', '死', '母', '比', '民', '气', '水', '没', '法', '活', '海', '清',
'游', '演', '火', '点', '热', '然', '照', '爱', '片', '物', '特', '狗', '王', '现',
'球', '生', '用', '电', '男', '界', '白', '百', '的', '直', '相', '看', '真', '眼',
'着', '知', '神', '种', '秘', '称', '穿', '竟', '笑', '第', '粉', '红', '经', '结',
'给', '网', '美', '老', '而', '能', '脸', '自', '色', '艺', '花', '英', '行', '衣',
'被', '装', '西', '要', '见', '视', '认', '让', '说', '谁', '走', '赵', '起', '超',
'路', '身', '车', '过', '还', '这', '造', '道', '遭', '部', '都', '里', '重', '金',
'长', '陈', '面', '颖', '颜', '食', '马', '高', '鱼', '黄', '黑', '龙', '一',
] def get_coordinate_hans_and__unicode_coordinate_map():
"""
获取所有汉字和坐标差的映射,和 Unicode和坐标差的映射,
接下来便可以通过映射找到Unicode所对应的坐标差,
拿到坐标差之后,就可以再通过coordinate_hans_map,找到具体的汉字
"""
# 存储该hansansjm.xml文件中所有的字符坐标差
coordinate_diff_list = [] # Unicode和坐标差的映射
_unicode_coordinate_map = {} print('>>> 开始计算xml文件中所有字符的坐标差')
content = parse('hansansjm.xml')
# 此处有个坑,应当先获取GlyphOrder中的GlyphID对应的name即Unicode,这里的Unicode是和ttf文件中一一对应的
# 而glyf中的TTGlyph对应的name(Unicode)不是和ttf文件中一一对应的
# 应该拿到GlyphOrder 下面所有的Unicode编码后,再去 glyf中根据Unicode找对应的坐标
GlyphID_list = content.getElementsByTagName('GlyphID')
TTGlyph_list = content.getElementsByTagName('TTGlyph')
# 由于xml文件中glyf下面的第一个TTGlyph 所对应的Unicode为.notdef ,要剔除掉,因此TTGlyph_list不能包含第一个元素
# 注意:如果最后一个元素也不是Unicode编码的,应当也要剔除掉 # 获取GlyphID下面所有的Unicode编码
GlyphID_uni_list = []
for GlyphID in GlyphID_list[1:]:
# 获取Unicode
_unicode = GlyphID.getAttribute('name')
GlyphID_uni_list.append(_unicode)
for uni in GlyphID_uni_list:
for TTGlyph in TTGlyph_list[1:]:
if uni == TTGlyph.getAttribute('name'):
# 获取第一个contour
# print(TTGlyph.getElementsByTagName('contour')[0])
first_contour = TTGlyph.getElementsByTagName('contour')[0] # 获取第一个contour中的前两个pt元素,进一步获取这两个元素的x,y属性,便于计算坐标差
first_pt = first_contour.getElementsByTagName('pt')[0]
first_pt_x = int(first_pt.getAttribute('x'))
first_pt_y = int(first_pt.getAttribute('y'))
# print(first_pt_x, first_pt_y) second_pt = first_contour.getElementsByTagName('pt')[1]
second_pt_x = int(second_pt.getAttribute('x'))
second_pt_y = int(second_pt.getAttribute('y'))
# print(second_pt_x, second_pt_y) # 计算坐标差
coordinate_diff = (second_pt_x - first_pt_x, second_pt_y - first_pt_y)
# print(coordinate_diff)
coordinate_diff_list.append(coordinate_diff)
# break
_unicode_coordinate_map[uni] = coordinate_diff # print(coordinate_diff_list) # 将坐标差和汉字组成字典,完成映射
coordinate_hans_map = dict(zip(coordinate_diff_list, hans_list))
print(coordinate_hans_map)
print(_unicode_coordinate_map)
return coordinate_hans_map, _unicode_coordinate_map
完整代码如下:
记一次css字体反爬的更多相关文章
- Python爬虫入门教程 64-100 反爬教科书级别的网站-汽车之家,字体反爬之二
说说这个网站 汽车之家,反爬神一般的存在,字体反爬的鼻祖网站,这个网站的开发团队,一定擅长前端吧,2019年4月19日开始写这篇博客,不保证这个代码可以存活到月底,希望后来爬虫coder,继续和汽车之 ...
- Python爬虫入门教程 63-100 Python字体反爬之一,没办法,这个必须写,反爬第3篇
背景交代 在反爬圈子的一个大类,涉及的网站其实蛮多的,目前比较常被爬虫coder欺负的网站,猫眼影视,汽车之家,大众点评,58同城,天眼查......还是蛮多的,技术高手千千万,总有五花八门的反爬技术 ...
- Python爬虫实例:爬取猫眼电影——破解字体反爬
字体反爬 字体反爬也就是自定义字体反爬,通过调用自定义的字体文件来渲染网页中的文字,而网页中的文字不再是文字,而是相应的字体编码,通过复制或者简单的采集是无法采集到编码后的文字内容的. 现在貌似不少网 ...
- 58 字体反爬攻略 python3
1.下载安装包 pip install fontTools 2.下载查看工具FontCreator 百度后一路傻瓜式安装即可 3.反爬虫机制 网页上看见的 后台源代码里面的 从上面可以看出,生这个字变 ...
- k 近邻算法解决字体反爬手段|效果非常好
字体反爬,是一种利用 CSS 特性和浏览器渲染规则实现的反爬虫手段.其高明之处在于,就算借助(Selenium 套件.Puppeteer 和 Splash)等渲染工具也无法拿到真实的文字内容. 这种反 ...
- python爬虫之字体反爬
一.什么是字体反爬? 字体反爬就是将关键性数据对应于其他Unicode编码,浏览器使用该页面自带的字体文件加载关键性数据,正常显示,而当我们将数据进行复制粘贴.爬取操作时,使用的还是标准的Unicod ...
- CSS常见反爬技术
目录 利用字体 反爬原理 应对措施 难点: 利用背景 反爬原理 应对措施 利用伪类 反爬原理 应对措施 利用元素定位 反爬原理 应对措施 利用字符切割 反爬原理 应对措施 利用字体 反爬原理 反爬原理 ...
- Python爬虫-字体反爬-猫眼国内票房榜
偶然间知道到了字体反爬这个东西, 所以决定了解一下. 目标: https://maoyan.com/board/1 问题: 类似下图中的票房数字无法获取, 直接复制粘贴的话会显示 □ 等无法识别的字 ...
- Spider-天眼查字体反爬
字体反爬也就是自定义字体反爬,通过调用自定义的woff文件来渲染网页中的文字,而网页中的文字不再是文字,而是相应的字体编码,通过复制或者简单的采集是无法采集到编码后的文字内容! 1.思路 近期在爬取天 ...
随机推荐
- 化繁就简,如何利用Spring AOP快速实现系统日志
1.引言 有关Spring AOP的概念就不细讲了,网上这样的文章一大堆,要讲我也不会比别人讲得更好,所以就不啰嗦了. 为什么要用Spring AOP呢?少写代码.专注自身业务逻辑实现(关注本身的业务 ...
- mat-paginatoor控件
pageNumber是点击搜索查询后,跟新的变量值. import { MatPaginatorIntl } from '@angular/material'; const getRangeLabel ...
- Python3笔记008 - 2.5 运算符
第2章 python语言基础 运算符:是一些特殊的符号,主要用于数学计算等. 表达式:使用运算符将不同类型的数据按照一定的规则连接起来的式子. 分类:算术运算符.赋值运算符.比较运算符.逻辑运算符.位 ...
- 从浏览器地址栏输入url到显示页面的步骤(以HTTP为例)
在浏览器地址栏输入URL 浏览器查看缓存,如果请求资源在缓存中并且新鲜,跳转到转码步骤 如果资源未缓存,发起新请求 如果已缓存,检验是否足够新鲜,足够新鲜直接提供给客户端,否则与服务器进行验证. 检验 ...
- The Shortest Statement,题解
题目链接 分析: 还是很明白的题意,直接分析问题,首先,这一题真的是给spfa用武之地,m比n大不超过20,但是这并不能使暴力不t,我们考虑一下如何改进一下,我们这样想,这个图只比它的生成树多最多21 ...
- redis 集群方案及搭建
由于Redis出众的性能,其在众多的移动互联网企业中得到广泛的应用.Redis在3.0版本前只支持单实例模式,虽然现在的服务器内存可以到100GB.200GB的规模,但是单实例模式限制了Redis没法 ...
- 自动化测试平台(Vue前端框架安装配置)
Vue简介: 通俗的来说Vue是前端框架,用来写html的框架,可轻量级也可不轻量级 Vue特性: 绑定性,响应性,实时性,组件性 安装软件以及控件: 控件库:element-ui node.js ( ...
- Flask 上下文机制和线程隔离
1. 计算机科学领域的任何问题都可以通过增加一个间接的中间层来解决, 上下文机制就是这句话的体现. 2. 如果一次封装解决不了问题,那就再来一次 上下文:相当于一个容器,保存了Flask程序运行过程中 ...
- 一篇文章教会你如何将DOM转换为virtual DOM
[一.Virtual DOM简介] Virtual DOM是虚拟节点,它通过Javascript的Object对象模拟DOM中的节点,然后通过特定的render方法将其渲染成真实的DOM节点. 浏览器 ...
- AMAP-TECH算法大赛开赛!基于车载视频图像的动态路况分析
阿里巴巴高德地图AMAP-TECH算法大赛于7月8日开启初赛,赛题为「基于车载视频图像的动态路况分析」,活动邀请了业界权威专家担任评委,优秀选手不仅可以瓜分丰厚的奖金,领取荣誉证书,还有机会进入高德地 ...