Fairseq-快速可扩展的序列建模工具包
一种快速、可扩展的序列建模工具包,Pytorch的高级封装库,适用于机器翻译、语言模型和篇章总结等建模任务。
抽象
Dataset:数据加载
Fairseq中的Dataset基本都是按功能逐层封装,按需组合起来。所有数据加载的实现均位于fairseq/data下面。
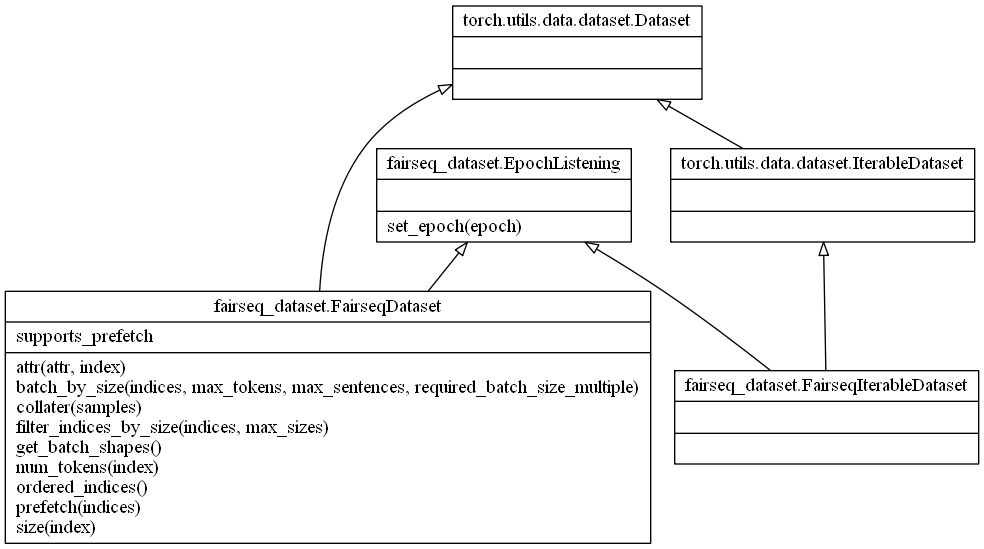
两个比较常用的数据处理类:
IndexedDataset直接处理/读取,bin/raw文件。LanguagepairDataset包含src和tgt两个Dataset,用于处理成对的数据。比如在机器翻译的中翻英任务中,处理中文和英文文本。
Option:参数定义
Fairseq中的参数统一使用argsparser库实现,模型通用参数被定义在fairseq/option.py下。同时每个模型均有其特有参数,通过每个模型的add_args(parser)函数定义。
在
fairseq/option.py中定义了6类通用参数,对应的函数分别是get_preprocessing_parser(),get_training_parser(),get_generation_parser(),get_interactive_generation_parser(),get_eval_lm_parser()和get_validation_parser。这6类通用参数又通过add_***_args()组装起来。在模型各自的实现中,通过继承接口中的
add_args()添加模型特有的参数,比如fairseq\models\lstm.py中通过add_args()添加了LSTM模型的encoder-embed-dim,encoder-layers,encoder-bidirectional等参数。
Model:网络模型的抽象
Fairseq中的Model负责模型的定义,包括各个模型的总体结构,每个模型提供argeparser供用户传入自定义参数。所有的模型定义均位于fairseq/models下。
所有的模型均继承自类BaseFairseqModel,而BaseFairseqModel又继承自torch.nn.Module,因此所有的Fairseq模型均可以作为其它Pytorch代码的模块。模型的具体结构,比如嵌入层的维度、隐藏层的个数由architectures定义。特别地,
LanguageModel和EncoderDecoderModel均直接继承自BaseFairseqModel,BaseFairseqModel主要提供add_args()、build_model()等统一的接口,以及模型加载等功能。Encoder和Decoder均直接继承自torch.nn.Module,LanguageModel和EncoderDecoder包含Encoder和Decoder。Decoder包含一个output_layer抽象接口,BERT这样的语言模型由于存在输出,因此继承的是Decoder。
FairseqTask
Fairseq主要以FairseqTask为核心,使用FairseqTask将各个部分衔接起来。一个Task可以是TranslationTask(比如使用Transformer做翻译),也可以是一个LanguageModelTask。所有的任务定义均位于fairseq/tasks下。一个FairseqTask实例需要实现以下功能:
字典存储/加载。
提供加载、分切数据的帮助类,获得装载数据的
Dataloader、iterator等。创建模型。
创建
criterion。循环训练、验证,直至收敛或达到指定训练轮数。
FairseqTask实现的功能基本上包含了模型运行的全部要素,可以看到主函数的调用流程:

Criterion
所有的准则(criterion)定义在fairseq/criterions内,准则对给定的模型和小批量数据计算损失(Loss)。也就是:
\]
在Fairseq中,实现所谓的“混合专家”(mixture-of-experts)模型,准则(criterion)实现EM风格(EM-style)的训练,以节约算力。
Optimizer
所有的优化器(optimizer)定义在fairseq/optim中,优化器根据梯度,更新模型参数。
Scheduler
定义在fairseq/lr_scheduler中。在训练过程中,调整学习率。
注册
注册机制
Fairseq中许多组件都是公共的,模块之间尽量解耦,需要一种方式指定应该跑哪一个Model,数据装载使用哪一个Dataset。注册机制在Fairseq中大量使用。
以FairseqTask的注册机制为例,FairseqTask包含了多个子类,如TranslationTask、MaskedLMTask、LanguageModeling等。在fairseq/task/__init__.py中会通过for循环import该目录下的所有文件,最后在TASK_REGISTRY中可以得到key:cls形式的模块存储器。其中,key为字符串,cls为模块的cls对象。这种方式可以很方便的通过指定参数,导入想要的模块。在函数装饰器setup_task()和register_task()中,通过TASK_REGISTRY载入和注册task。
举个例子,通过装饰器进行注册,比如:
@register_task('language_modeling')
class LanguageModelingTask(FairseqTask):
...
在Model、Criterion部分都有该机制的身影。
在主函数train.py中,通过setup_task(),build_model(),build_criterion()中得到所需部分。
同样地,可以使用注册机制固化模型参数。一些模型仅仅有模型参数上的区别,本质并无区别,比如roberta_base,roberta_large。因此需要指定各个模型的具体默认参数,当然这些参数,用户可以通过fairseq的参数系统进行指定。这些模型的具体参数同样可以用注册的方式固定下来,在使用时可以更加方便。
- 对于模型,使用
@register_model装饰器注册。
@register_model('roberta')
class RobertaModel(FairLanguageModel):
...
- 对于具体的模型结构,使用
@register_model_architecture装饰器注册。
@register_model_architecture('robtera','roberta_large')
def roberta_large_architecture(args):
args.encoder_layers = getattr(args,'encoder_layers',24)
args.encoder_embed_dim = getattr(args,'encoder_embed_dim',1024)
...
base_architecture(args)
注册的函数对象会在ARCH_CONFIG_REGISTERY中存储,并在option.py中调用:
ARCH_CONFIG_REGISTRY[args.arch](args)
实现上的特点
Fairseq使用Pytorch实现,支持多机、多卡、混合精度训练。提升速度,降低显存占用。
分批次
Fairseq依据序列长度对源/目标序列进行分组,相似长度的序列作为一组,以减小对序列的补齐填充操作。每一个mini-batch内的样本在训练过程中不变,但每一轮训练时都会打乱mini-batch间的顺序。当在多卡、多机上运行时,每一个worker的mini-batches平均长度有所不同,以实现更有代表性(more representative)的迭代。
多GPU训练
使用NCCL2库和
torch.distributed作为GPU间的通信。每个GPU上保留一个模型副本。
前向计算和反向传播异步。Fairseq中每一层的梯度计算完成后,都会把结果存放到缓存中,当缓存大小达到某一个阈值之后,在一个后台线程中同步梯度,反向传播照常进行。在每一个GPU上累加梯度,以减小worker上处理时间的方差,这样就不必等待计算比较慢的worker。
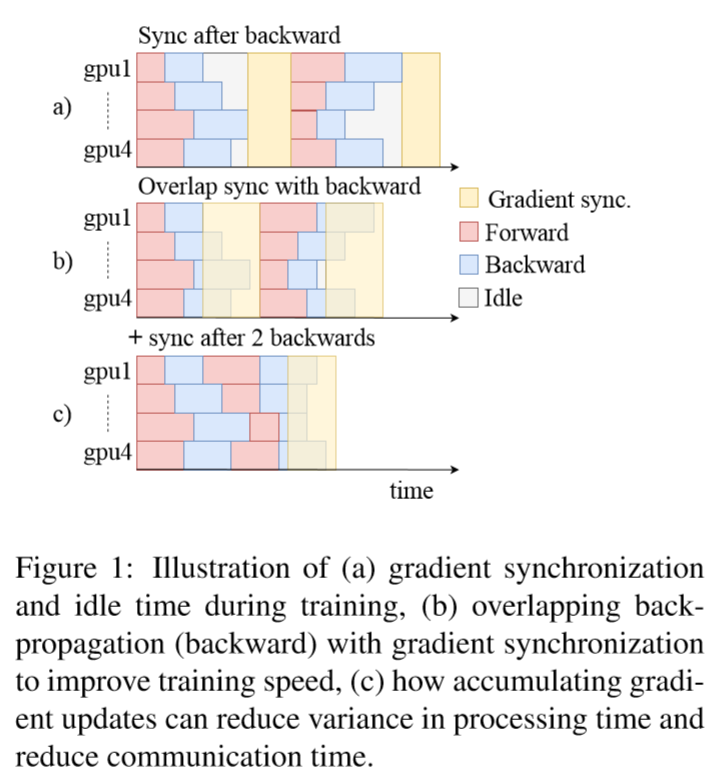
如图所示,图a在同步梯度时,等待最慢的worker,因此产生了大量的等待时间(白色所示,idle)。但Fairseq同时采用了图b和图c的技术,反向传播(back-propagation)和梯度同步(gradient synchronization)同时进行,并且累加梯度以减少worker上面处理时间的“抖动”,从而提升训练速度。
混合精度训练
Fairseq同时支持半精度浮点(half precision float point, FP16)和全精度浮点(full precision float point, FP32)的训练和推断。在前后向以及worker之间规约(all-reduce)时,使用FP16。但在参数更新时仍然采用FP32,以保证计算精度。由于FP16提供的精度有限,为了防止激活和梯度的下溢出,Fairseq实现了所谓的动态损失缩放(dynamic loss scaling)。当FP16的梯度在worker之间同步完成之后,将缩放到FP16的数字恢复为原来的FP32,并更新模型权重。
推断优化
Fairseq通过增量解码(incremental decoding)提供了更快的推理速度。所谓的增量解码,就是在解码时,将之前tokens处于激活beam状态下的模型状态(model states)缓存起来,以备后用,这样每一个新的token进来,只需要计算新的状态即可。也就是说,如果使用FairseqDecoder接口实现普通的解码器,对于每一个输出,都需要重新整个解码器隐状态,计算复杂度O(n^2)。而使用FairseqIncrementalDecoder接口实现增量解码,就可以实现O(n)的解码速度。
在训练和推理阶段,通过用户指定的最大tokens数量,构建动态样本数量的batch。并且Fairseq在保证准确率的前提下,支持FP16精度的推断。相比于FP32,FP16推断将解码速度提高54%。注意:Fairseq中没有batch size的概念,用户通过指定max-tokens,Fairseq会自动构建不定数量的batch送入模型训练。
Fairseq repo (Python): https://github.com/pytorch/fairseq
Paper: http://cn.arxiv.org/abs/1904.01038
Document: fairseq.readthedocs.io
https://zhuanlan.zhihu.com/p/100249351
https://zhuanlan.zhihu.com/p/100643955
Fairseq-快速可扩展的序列建模工具包的更多相关文章
- 基于机器学习的web异常检测——基于HMM的状态序列建模,将原始数据转化为状态机表示,然后求解概率判断异常与否
基于机器学习的web异常检测 from: https://jaq.alibaba.com/community/art/show?articleid=746 Web防火墙是信息安全的第一道防线.随着网络 ...
- BZOJ_2242_[SDOI2011]计算器_快速幂+扩展GCD+BSGS
BZOJ_2242_[SDOI2011]计算器_快速幂+扩展GCD+BSGS 题意: 你被要求设计一个计算器完成以下三项任务: 1.给定y,z,p,计算Y^Z Mod P 的值: 2.给定y,z,p, ...
- 阿里CTR预估:用户行为长序列建模
本文将介绍Alibaba发表在KDD'19 的论文<Practice on Long Sequential User Behavior Modeling for Click-Through Ra ...
- 【笔记】论文阅读:《Gorilla: 一个快速, 可扩展的, 内存式时序数据库》
英文:Gorilla: A fast, scalable, in-memory time series database 中文:Gorilla: 一个快速, 可扩展的, 内存式时序数据库
- Slickflow.Graph 开源工作流引擎快速入门之四: 图形编码建模工具使用手册
前言: 业务人员绘制流程时,通常使用图形GUI界面交互操作来完成,然而对于需要频繁操作或者管理较多流程的系统管理用户,就需要一款辅助工具,来帮助他们快速完成流程的创建和编辑更新.Slickflow.G ...
- “盛大游戏杯”第15届上海大学程序设计联赛夏季赛暨上海高校金马五校赛题解&&源码【A,水,B,水,C,水,D,快速幂,E,优先队列,F,暴力,G,贪心+排序,H,STL乱搞,I,尼姆博弈,J,差分dp,K,二分+排序,L,矩阵快速幂,M,线段树区间更新+Lazy思想,N,超级快速幂+扩展欧里几德,O,BFS】
黑白图像直方图 发布时间: 2017年7月9日 18:30 最后更新: 2017年7月10日 21:08 时间限制: 1000ms 内存限制: 128M 描述 在一个矩形的灰度图像上,每个 ...
- 【bzoj2242】: [SDOI2011]计算器 数论-快速幂-扩展欧几里得-BSGS
[bzoj2242]: [SDOI2011]计算器 1.快速幂 2.扩展欧几里得(费马小定理) 3.BSGS /* http://www.cnblogs.com/karl07/ */ #include ...
- bzoj 2242: [SDOI2011]计算器 BSGS+快速幂+扩展欧几里德
2242: [SDOI2011]计算器 Time Limit: 10 Sec Memory Limit: 512 MB[Submit][Status][Discuss] Description 你被 ...
- bzoj 2242 [SDOI2011]计算器 快速幂+扩展欧几里得+BSGS
1:快速幂 2:exgcd 3:exbsgs,题里说是素数,但我打的普通bsgs就wa,exbsgs就A了...... (map就是慢)..... #include<cstdio> # ...
随机推荐
- 统计一个16位二进制数中1的个数,并将结果以十六进制形式显示在屏幕上,用COM格式实现。
问题 统计一个16位二进制数中1的个数,并将结果以十六进制形式显示在屏幕上,用COM格式实现. 代码 code segment assume cs:code org 100h main proc ne ...
- 从键盘输入一个字符串(长度不超过30),统计字符串中非数字的个数,并将统计的结果显示在屏幕上,用EXE格式实现。
问题 从键盘输入一个字符串(长度不超过30),统计字符串中非数字的个数,并将统计的结果显示在屏幕上,用EXE格式实现. 源程序 data segment hintinput db "plea ...
- 5分钟白嫖我常用的免费效率软件/工具!效率300% up!
Mac 免费效率软件/工具推荐 1. uTools(Windows/Mac) 还在为了翻译 English 而专门下载一个翻译软件吗? 还在为了格式某个 json 文本.时间戳转换而打开网址百度地址吗 ...
- PHP date_format() 函数
------------恢复内容开始------------ 实例 返回一个新的 DateTime 对象,然后格式化日期: <?php$date=date_create("2013-0 ...
- CF321E Ciel and Gondolas Wqs二分 四边形不等式优化dp 决策单调性
LINK:CF321E Ciel and Gondolas 很少遇到这么有意思的题目了.虽然很套路.. 容易想到dp \(f_{i,j}\)表示前i段分了j段的最小值 转移需要维护一个\(cost(i ...
- luogu P6125 [JSOI2009]有趣的游戏
LINK:有趣的游戏 直接说做法了.首先是 我是不会告诉你我看完题后不太会 摸了2h鱼后看题解 一直翻发现自己题目有些没读完整.. 题目中说了每个字符串长度相同 而我一直在思考AC自动机可能存在一些节 ...
- 学学Viewbinding
Viewbinding 1.环境需求 环境上,需要Android Studio 3.6 Canary 11+ 同样的Gradle也需要升级(这年头都4.0了,应该没有还在用低版本的了吧...) 2.配 ...
- Android html5和Android之间的交互
今天补充了会昨天的问题,然后搞半天又出现莫名其妙的问题. 今天讲的是交互,先说html5在Android的调用. 上面的hello world上面的部分都是安卓里的布局 然后按这些布局自动生成代码. ...
- XSS 渗透思路笔记
了解XSS首先要了解HTML里面的元素:共有5种元素:空元素.原始文本元素. RCDATA元素.外来元素以及常规元素. 空元素area.base.br.col. command. embed.hr.i ...
- 2020重新出发,JAVA入门,关键字&保留字
关键字 & 保留字 关键字(或者保留字)是对编译器有特殊意义的固定单词,不能在程序中做其他目的使用. 关键字具有专门的意义和用途,和自定义的标识符不同,不能当作一般的标识符来使用.例如, cl ...