Federated Optimization: Distributed Machine Learning for On-Device Intelligence
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!
arXiv:1610.02527v1 [cs.LG] 8 Oct 2016

坐标下降法:https://blog.csdn.net/qq_32742009/article/details/81735274
Abstract
我们为机器学习中的分布式优化引入了一个越来越相关的新设置,其中规定优化的数据在极大量的节点上分布不均匀。我们的目标是训练一个高质量的集中式模型。我们将此设置称为联邦优化。在这种情况下,通信效率至关重要,最大限度地减少通信轮数是主要目标。
当我们在进行训练时,若是将局部训练数据保存在用户的移动设备上,而不是将其记录到数据中心,这就会出现一个令人激动的例子。在联邦优化中,设备被用作计算节点,对其局部数据执行计算,以更新全局模型。我们假设网络中的设备数量非常大,相当于给定服务的用户数量,每个用户只占可用数据总量的很小一部分。特别是,我们希望局部可用的数据点数量比设备数量小得多。此外,由于不同的用户使用不同的模式生成数据,因此可以合理地假设没有设备具有整个分布的代表性样本。
我们证明了现有的算法不适用于这种设置,并提出了一种新的算法,对稀疏凸问题给出了令人鼓舞的实验结果。这项工作还为联邦优化环境下的未来研究探明了一条道路。
1 Introduction
手机和平板电脑现在是许多人的主要计算设备。在许多情况下,这些设备很少与它们的所有者分离[19],而丰富的用户交互和强大的传感器的结合意味着它们能够访问前所未有的数据量,其中大部分是私有的。在这些数据上学习的模型有希望通过驱动更智能的应用程序来大大提高可用性,但数据的敏感性意味着将其集中存储存在风险和责任。
我们提倡一种替代方法——“联邦学习”,训练数据分散在移动设备上,并通过中央协调服务器聚合局部计算的更新来学习共享模型。这是《2012年白宫消费者数据隐私报告》[98]提出的集中收集或数据最小化原则的直接应用。由于这些更新是专门用于改进当前模型的,因此它们的存在时间可以十分短暂。一旦应用它们,就没有理由将它们存储在服务器上。此外,它们永远不会包含比原始训练数据更多的信息(由于数据处理不相等),而且通常包含的信息要少得多。这种方法的一个主要优点是将模型训练与直接访问原始训练数据的需求分离开来。显然,协调训练的服务器仍然需要一些信任,并且根据模型和算法的详细信息,更新可能仍然包含私有信息。但是,对于可以根据每个客户端上可用的数据指定训练目标的应用程序,联邦学习可以通过将攻击面仅限于设备而不是设备和云来显著降低隐私和安全风险。
如果需要额外的隐私,可以使用来自差异隐私的随机技术。可以修改集中式算法以生成一个不同的私有模型[17,33,1],该模型允许发布,同时保护为训练过程提供更新的个人的隐私。如果需要防止恶意(或妥协的)协调服务器,则可以应用来自局部差异隐私的技术来私有化单个更新[32]。这方面的细节超出了目前的工作范围,但对未来的研究是一个有希望的方向。
关于联邦学习的应用以及隐私衍生结果的更完整的讨论可以在[62]中找到。我们这项工作的重点将是联邦优化,这是一个必须解决的优化问题,以便使联邦学习成为当前方法的一个实用替代方案。
1.1 Problem Formulation
近年来,优化界对有限和结构问题的研究兴趣不断高涨。一般来说,目标的表述如下:
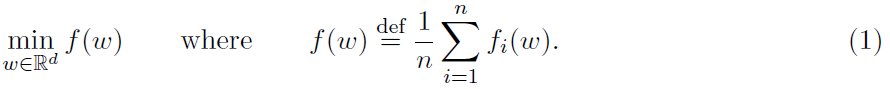
动机的主要来源是机器学习中出现的问题。问题结构(1)包括线性或逻辑回归、支持向量机,以及更复杂的模型,如条件随机场或神经网络。
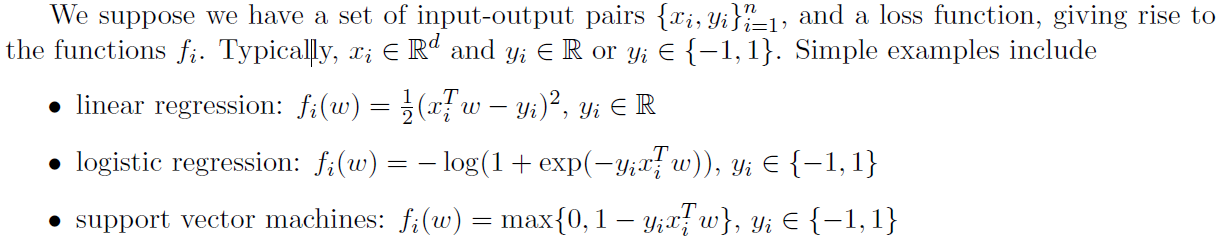
更复杂的非凸问题出现在神经网络的上下文中,而不是通过线性特征映射xiTw,网络通过特征向量xi的非凸函数进行预测。然而,由此产生的损失仍然可以写成fi(w),梯度可以使用反向传播来计算。
企业、政府和学术项目收集的数据量正在迅速增加。因此,实际出现的问题(1)通常不可能在单个节点上解决,因为仅仅将整个数据集存储在单个节点上变得不可行。这就需要使用分布式计算框架,其中训练数据分布式存储在多个互连节点上,优化问题由节点集群联合解决。
不严格地说,可以使用任何节点网络来模拟一个强大的节点,在这个节点上可以运行任何算法。实际问题是,在同一节点上,处理器和内存之间进行通信所需的时间通常比两个节点进行通信所需的时间小很多个数量级;对于所需的能源,也有类似的结论[89]。此外,为了充分利用每个节点的并行计算能力,有必要将问题细分为适合独立/并行计算的子问题。
最先进的优化算法通常是固有的顺序。此外,它们通常依赖于执行大量非常快的迭代。这个问题源于这样一个事实:如果在每次迭代之后需要执行一轮通信,那么实际性能会急剧下降,因为这轮通信比算法的一次迭代要耗费更多的时间。
这些考虑导致了专门针对分布式优化的新算法的开发(我们将彻底的回顾推迟到第2节)。现在,我们注意到大多数文献中的结果都是在数据均匀分布的情况下工作的,并且进一步假设K << n / K,其中K是节点数。当数据存储在一个大的数据中心时,这确实非常接近现实。此外,分布式学习领域的一个重要子领域依赖于这样一个假设:每台机器都有一个局部可用数据的代表性样本。也就是说,假设每台机器都有一个来自底层分布的独立同分布(IID)样本。然而,这种假设往往太强;事实上,即使在数据中心范例中,情况也往往不是这样,因为单个节点上的数据可以在时间尺度上彼此接近,或者由其地理来源聚集。由于数据中的模式会随着时间的推移而变化,因此一个特征可能经常出现在一个节点上,而完全不出现在另一个节点上。
联邦优化设置描述了一个新的优化场景,其中没有上述假设。我们将在下一节中更详细地概述此设置。
1.2 The Setting of Federated Optimization
本文的主要目的是令机器学习和优化界注意到一个新的、越来越实际相关的分布式优化设置。该设置不满足任何一个典型假设,并将通信效率视为最重要的。特别指出,联邦优化算法必须处理具有以下特征的训练数据:
- 大规模分布:数据点存储在大量节点K上。特别是,节点的数量可以比存储在给定节点上的训练样例的平均数量(n / K)大得多。
- 非IID:每个节点上的数据可以从不同分布中提取;也就是说,局部可用的数据点远不是整个分布的代表性样本。
- 不平衡:不同的节点在它们所拥有的训练样例数量上可能会按数量级变化。
在这项工作中,我们特别关注稀疏数据,其中一些特征只出现在一小部分节点或数据点上。虽然这不是联邦优化设置的必要特性,但我们将证明稀疏结构可以用来开发一种有效的联邦优化算法。请注意,目前正在解决的最大规模机器学习问题(即点击率预测)中出现的数据非常稀疏。
我们对训练数据在用户移动设备(手机和平板电脑)上的使用设置特别感兴趣,这些数据可能对隐私敏感。数据{xi, yi}是通过设备使用(例如,通过与应用程序的交互)生成的。例如,预测用户将键入的下一个单词(智能键盘应用程序的语言建模)、预测用户最可能共享的照片或预测最重要的通知。
为了使用传统的分布式学习算法来训练这种模型,我们将在一个集中的位置(数据中心)收集训练样例,在那里它会被打乱然后均匀地分布在专有的计算节点上。在本文中,我们提出并研究了一个替代模型:训练样例不发送到集中的位置,可能会节省大量的网络带宽并提供额外的隐私保护。作为交换,用户允许使用设备的计算能力,用于训练模型。
在本文的通信模型中,每一轮我们都会向一个集中式服务器发送更新δ(δ属于Rd),其中d是正在计算/改进的模型的维度。例如,更新δ可以是一个梯度向量。虽然在某些应用程序中,δ可能会对用户的一些私有信息进行编码,但它可能比原始数据本身的敏感度(以及数量级)要低得多。例如,考虑这样一种情况:原始训练数据是移动设备上大量视频文件的集合。更新δ的大小将独立于局部训练数据集的大小。我们表明,一个全局模型可以使用少量的通信轮数进行训练,与将数据复制到数据中心相比,这也将训练所需的网络带宽降低了数量级。
此外,非正式地,我们选择δ作为改进全局模型所需的最少信息;与原始数据相比,其用于其他用途的效用显著降低。因此,很自然地,设计一个系统,它不存储这些超过更新模型所需时间的更新δ,再次增加隐私保护程度,并减少集中模型训练者的责任。在这种设置中,每轮传输一个向量δ(δ属于Rd),涵盖了大多数现有的一阶方法,包括CoCoA+[57]等双重方法。
由于网络连接可能受到限制(例如,在移动设备充电并连接到Wi-Fi网络之前,我们可能希望解除所有通信),因此在大规模分布式设置中自然会出现通信限制。因此,在现实场景中,我们可能仅限于每天进行一轮沟通。这意味着,在合理的范围内,我们可以获得本质上无限的局部计算能力。因此,实际目标仅仅是尽量减少通信轮数。
这项工作的主要目的是启动联邦优化的研究,并设计第一个实际实现。我们的结果表明,使用合适的优化算法,即使没有一个可用数据的IID样本,损失也会很小。而且即使在存在大量节点的情况下,我们仍然可以在相对较少的几轮通信中实现收敛。
2 Related Work
在本节中,我们将详细介绍相关文献。我们特别关注可以在各种环境中用来解决问题(1)的算法。首先,在第2.1节和第2.2节中,我们将研究设计在单个计算机上运行的算法。在第2.3节中,我们接着讨论了分布式设置,其中没有单独节点可以直接访问描述 f 的所有数据。我们描述了一个衡量分布式方法效率的范例,然后概述了现有方法,并评论了它们是否在设计时考虑到了通信效率。
2.1 Baseline Algorithms
在本节中,我们将描述几种基本的基准算法,这些算法可用于解决形式(1)的问题。
梯度下降:解决结构(1)问题的一个基准是梯度下降(GD),当函数fi是平滑的(或非平滑函数的次梯度下降)[69]。GD算法执行迭代
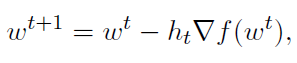
其中,ht>0是一个步长参数。正如我们前面提到的,函数的数量与训练数据对的数量n通常非常大。这使得GD不满足实际需求,因为它需要处理整个数据集,以便求出单个梯度并更新模型。
在理论和实践中,梯度下降可以通过增加动量项而大大加速。凸优化中梯度法的加速思想可以追溯到Polyak[73]和Nesterov[68,69]的工作。虽然加速的GD方法有一个相当好的收敛速度,但在每次迭代中,它们仍然需要至少对所有数据进行一次扫描。因此,对于n非常大的问题,它们是不实际的。
随机梯度下降:目前,一个基本的但在实践中非常流行,用来替代GD的算法是随机梯度下降(SGD),这可以追溯到Robbins和Monro的开创性工作[82]。在(1)的上下文中,SGD对迭代t中的随机函数(即随机数据-标签对)it( it属于{1,2,…,n} )进行采样,并执行更新
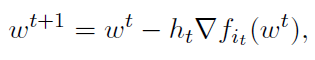
其中,ht>0是一个步长参数。直观地说,这种方法是有效的,因为如果 it 从序号1到n中进行随机均匀抽样,更新方向是对梯度的无偏估计

然而,采样引入的噪声会减慢收敛速度,收敛需要一个不断变小的步长序列hk。关于凸函数的理论分析,我们请读者参考[66,64,65]和[87,93]以了解SVM问题。在最近的回顾[12]中,作者概述了进一步的研究方向。有关更注重实际的讨论,请参见[11]。在神经网络的背景下,随机梯度的计算被称为反向传播[49]。反向传播不是显式地指定函数fi及其梯度,而是计算梯度的一种通用方法。在[70]中比较了几种有竞争力的算法在深度神经网络训练中的性能。
为了提供更好的性能,一个常见的技巧是通过以随机顺序遍历所有函数it来替换每次迭代中的随机采样。在每一个这样的循环之后,这个顺序被另一个随机顺序所取代[10]。对这一现象的理论解释是一个长期存在的开放性问题,最近在[40]中得到了解释。
GD和SGD之间的核心区别可以总结如下。GD具有快速的收敛速度,但是在(1)的上下文中每个迭代都可能非常慢,因为它需要在每个迭代中处理整个数据集。另一方面,SGD的收敛速度较慢,但每次迭代都很快,因为所需的工作与数据点n的数目无关。对于(1)的问题结构,SGD通常更好,因为实际需要的精度相对较低。在极端情况下,当SGD已经遍历完数据时,GD可能只进行了一次更新。然而,如果需要达到较高的精度,GD或其更快的变体更为适用。
2.2 A Novel Breed of Randomized Algorithms
近年来出现了一系列新的随机方法,这些方法在一阶近似中结合了SGD廉价迭代和GD快速收敛的优点。这些方法大多可以说是属于随机坐标下降变体中的两类对偶方法之一,以及原始的具有方差消减变种的随机梯度下降法。
随机坐标下降:尽管坐标下降的概念在不同的环境中已经存在了几十年(并且对于二次函数,可以追溯到更远的Gauss-Seidel方法),但它在机器学习和优化方面的突出表现是,Nesterov的工作[67]采用了随机策略。Nesterov在随机坐标下降(RCD)方面的工作推广了该方法并证明了这种随机化对结构问题(1)非常有用。
RCD算法的每次迭代都会选择一个随机坐标jt( jt属于{1,…,d},d表示模型计算与改进的维度 ),并执行更新
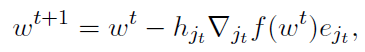
其中hjt>0是一个步长参数,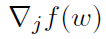 表示函数f对第j个坐标的偏导数,ej是Rd中的第j个坐标的标准单位基向量。对于广义线性模型,当数据具有一定的稀疏结构时,可以有效地对偏导数
表示函数f对第j个坐标的偏导数,ej是Rd中的第j个坐标的标准单位基向量。对于广义线性模型,当数据具有一定的稀疏结构时,可以有效地对偏导数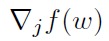 进行求值,即无需处理整个数据集,也可得到实际有效的算法,实例参见[79,第6节]。
进行求值,即无需处理整个数据集,也可得到实际有效的算法,实例参见[79,第6节]。
许多后续工作将这一概念扩展到了近端设置[79]、单处理器并行[15,80],并有效地开发了可实现的加速[51]。在[35]中,这三个属性都被结合在一个算法中,我们参考它(特别是表1中的概述)向读者介绍RCD领域的早期发展。
随机对偶坐标上升:当一个显式强凸但不一定光滑的正则项加到平均损失(1)中时,就可以写下它的(Fenchel)对偶和存在于n维空间中的对偶变量。应用RCD可以得到一种求解(1)的算法,即随机对偶坐标上升法[88]。这种方法在实践中得到了广泛的应用,可能是因为对于许多损失函数,这种方法不需要调整任何超参数。工作[88]首先表明,通过将RCD[79]应用于对偶问题,人们还可以解决原始问题(1)。有关将RCD应用于原始问题与对偶问题的理论和计算比较,请参见[21]。
一种直接的原始-对偶随机坐标下降法称为Quartz,这提出于[75]。最近在SDNA[74]中已经表明,将曲率信息包含在由几个坐标跨越的随机低维子空间中,有时会导致大幅加速。最近的工作[86,20]解释了原始设置中的SDCA方法,阐明了为什么使用具有方差消减属性的SGD方法版本。
我们现在改动第二类新的随机算法,通常可以解释为SGD的变体,试图减少梯度估计过程中固有的方差。
随机平均梯度:这类中第一个值得注意的算法是随机平均梯度(SAG)[83,85]。SAG算法存储着在算法历史中不同点上计算的n个函数 fi 梯度的平均值。在每次迭代中,该算法都会从该平均值中更新随机选择的梯度,并朝着平均值的方向迈出一步。这样,每次迭代的复杂度与n无关,并且算法具有快速收敛性。该算法的缺点是,由于执行了更新操作,它需要在内存中存储n个梯度。在广义线性模型的情况下,由于梯度是数据点的多重标量,因此这种内存需求可以减少到n个标量的需要。这种方法最近被扩展用于条件随机场[84]。然而,内存需求使得该算法即使在相对较小的神经网络中也无法应用。
后续算法SAGA[26]及其简化版本[25],修改了SAG算法,以实现对梯度的无偏估计。内存需求仍然存在,但该方法大大简化了理论分析,并产生了一个稍强的收敛保证。
随机方差消减梯度:
SGD类方法的另一种算法是随机方差消减梯度(SVRG)[43]和[47,100,44]。SVRG算法在两个嵌套循环中运行。在外循环中,它计算整个函数的全梯度,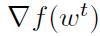 。一般来说,这是人们试图避免的昂贵操作。在内部循环中,更新步骤迭代计算为
。一般来说,这是人们试图避免的昂贵操作。在内部循环中,更新步骤迭代计算为
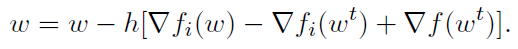
其核心思想是利用随机梯度估计点wt和w之间梯度的变化,而不是直接估计梯度。我们将在第3.2节中对该算法进行更详细的描述。
SVRG的优点是它没有SAG/SAGA的额外内存需求,但是它需要不时地处理整个数据集。实际上,与SGD(通常在第一次遍历数据时取得显著进展)相比,而SVRG无论怎样不进行任何更新,因为它需要计算完整的梯度。这一点和其他一些实际问题最近在[41]中得到了解决,使算法在早期能与SGD竞争,并在后期迭代中更具优势。虽然没有什么可以阻止我们在深度学习中应用SVRG及其变体,但是我们不知道在这种情况下任何对其系统性能的评估。在[43,77]中的Vanilla实验表明SVRG与基本的SGD相当,甚至有所超越,考虑到SVRG的迭代方差似乎明显较小。然而,为了得出任何有意义的结论,我们需要进行大量的实验,并与通常具有许多启发式方法的最先进方法进行比较。
已经有人尝试将SVRG类型的算法与随机坐标下降结合起来[46,97]。虽然这些工作突出了一些有趣的理论性质,但目前的算法似乎并不实用;在这方面需要做更多的工作。第一次尝试统一SVRG和SAG/SAGA等算法已经出现在SAGA论文[26]中,作者将SAGA解释为SAG和SVRG之间的中点。最近的工作[76]提出了一种将SVRG、SAGA、SAG和GD恢复为特殊情况的通用算法,并将这些算法的异步变量作为公式的副产品。SVRG可以配备动量(和负动量),从而产生一种新的加速SVRG方法,称为Katyusha[3]。SVRG可以通过原始聚类机制[4]进一步加速。
随机Quasi-Newton方法:第三类的新算法是随机Qusai-Newton方法[16,9]。这些算法通常试图模仿有限内存的BFGS方法(L-BFGS)[54],但使用来自SGD过程的不精确梯度来模拟局部曲率信息。最近可以在[63]中找到尝试将这些方法与SVRG结合起来。在[38]中,作者利用随机矩阵反演领域的最新进展[39]揭示了与Quasi-Newton方法的新联系,并设计了一种与SVRG协同工作的随机有限记忆BFGS新方法。事实上,对这一研究分支的理论解释是最不明确的,并且有几个细节使得实施比上述方法更困难,这可能限制其广泛使用。然而,这种方法一旦被更好地解释,对于深度学习是最有前景的。
机器学习的一个重要方面是,我们正在解决的经验风险最小化问题(1)只是我们最终感兴趣的预期风险的一个代替。当一个人能找到经验风险的精确最小值时,一切都会降低到平衡近似值估计权衡,这是大量文献的研究对象——例如参见[96]。一些优化算法作为大规模学习问题中的学习算法,其渐进性能评估已在[13]中介绍。最近在[41]中的扩展表明方差消减算法(SAG,SVRG,.…)可以在一定的设置下成为比SGD更好的学习算法,不仅仅是更好的优化算法。
进一步说明:一种被称为通用催化剂(Universal Catalyst)[53,37]的通用方法有效地使前面章节中提到的一些算法转换为它们的“加速”变体。由此产生的收敛保证在许多情况下几乎达到了下限。然而,需要调整额外的参数使得该方法相当不实用。
近年来,关于形式(1)问题的随机方法的复杂度下限和上限可以在[99]中得到。
2.3 Distributed Setting
在本节中,我们将回顾有关分布式环境中求解(1)的算法的文献。当我们谈到分布式设置时,我们指的是描述函数fi的数据没有存储在单个存储设备上的情况。这可以包括设置的数据仅不适合一个单独的RAM/计算机/节点,但两个就足够了。这还包括数据分布在世界各地的多个数据中心,以及这些数据中心中的多个节点上的情况。关键是在系统中,没有一个处理单元可以直接访问所有数据。因此,分布式设置不包括单处理器并行。与任何单个节点上的局部计算相比,节点之间的通信成本在速度和能耗方面都要高得多[6,89],这为优化过程以及其他问题带来了新的计算挑战。
对第2.3.1节中给定的问题,我们首先回顾了确定实际最佳算法的理论决策规则,其次是第2.3.2节中的分布式算法概述,以及第2.3.3节中的通信效率算法。下面的范例强调了为什么通信效率算法类型不仅仅是一般意义上的首选。通信效率高的算法为设计整体优化过程提供了更为灵活的工具,使算法能够适应计算资源和体系结构的差异。
2.3.1 A Paradigm for Measuring Distributed Optimization Efficiency
本节回顾了一个比较分布式算法效率的范例。假设我们有许多现成的算法A来解决这个问题(1)。问题是:"我们如何确定哪种算法最适合我们的目的?”这种论证的最初版本已经出现在[57]中,也适用于[78]。
首先,考虑一台机器的基本设置。我们令IA(ε)定义为算法A收敛到某个固定精度ε需要的迭代次数。令TA为一次迭代所需的时间。然后,在实践中,最好的算法是最小化以下指标的算法:

迭代次数IA(ε)通常由理论保证或经验观察得出。TA可以通过经验观测,也可以通过观察每个迭代所需的时间在不同的算法之间是如何变化的来加以了解。这种简化设置的要点是通过将算法扩展到分布式设置来突出关键问题。
对分布式设置的自然扩展如下。假设c是在算法A在一次迭代中通信所需的时间。为了清楚起见,我们假设只考虑在每一轮通信中需要通信一个向量Rd的算法。请注意,基本上所有的一阶算法都属于这一类,因此这不是一个限制性假设,它有效地将c设置为一个常量,前提是可以使用任何特定的分布式体系结构。

通信成本c不仅包括数据的实际交换,还包括许多其他的事情,如建立和关闭节点之间的连接。因此,即使我们需要通信非常少量的信息,c始终保持在一个非常重要的阈值之上。
大多数(如果不是全部)当前最先进的算法在(2)的设置中是最好的,它们是随机的,并且依赖于做大量(大IA(ε))的快速(小TA)迭代。因此,即使是相对较小的c,也会导致这些算法的实际性能显著下降,因为c >> TA。
这在实践中确实得到了观察,并推动了从最开始就将这一事实考虑在内的新方法的开发,我们在第2.3.2节中对此进行了回顾。尽管这对学术界探索新环境的动机来说是一个很好的发展,但对行业来说并不一定是一个好消息。
许多公司已经花费了大量的资源来构建优秀的算法来解决形式(1)的问题,并根据所需的数据和边应用程序中出现的特定模式进行微调。当数据公司收集的数据太大,无法在一台机器上进行处理时,可以理解的是,他们不愿意放弃经过微调的算法。CoCoA[57]首次明确讨论了这个问题,它更像是算法而不是框架,其工作原理如下(更详细的描述见第2.3.3节)。
CoCoA框架基于局部可用的数据和需要分发到所有节点的单个共享向量,制定了在每个节点上形成特定子问题的一般方法。在框架的迭代中,每个节点都使用任意优化算法A,以达到局部子问题的相对Θ精度。然后,来自所有节点的更新进行聚合,以形成对全局模型的更新。
效率范式的变化如下:
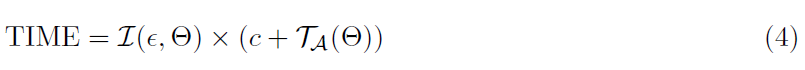
迭代次数I(ε,Θ)与用作局部求解器的算法A的选择无关,因为有理论预测,如果我们将局部子问题求解到相对Θ精度,CoCoA框架需要多少次迭代才能达到精度ε。这里,Θ=0意味着我们需要将子问题求解到最优,而Θ=1意味着我们不需要任何进展。对于强凸目标,CoCoA框架迭代次数的一般上限为I(ε,Θ) = O(log(1 / ε)) / (1 - Θ) [42,58,57]。从对1 - Θ的逆依赖可以看出,对所需的通信轮数有一个基本限制。因此,花费过多的资源以获得非常高的局部精度(小Θ)可能不有效。每次迭代时间TA(Θ)表示算法A需要在局部子问题上达到相对Θ精度的时间。
这种效率模式更强大的原因有很多:
- 它允许实践者继续使用他们微调的只能在一台机器上运行的求解器,而不必从头开始执行全新的算法。
- 从通信轮数来看,实际性能与优化算法的选择无关,使得整体性能的优化更加容易。
- 由于常数c依赖于体系结构,因此在一个节点网络上运行的优化算法在另一个节点上不一定是最优。在设置(3)中,这可能意味着从一个集群移动到另一个集群,一种完全不同的算法是最优的,这是一个主要的变化。在设置(4)中,可以通过简单地更改Θ来改进这一点,这通常由算法A运行的迭代次数隐式确定。
在这项工作中,我们提出了一种不同的方法来制定局部子问题,它不依赖于对偶性,就像在CoCoA中一样。我们还强调,一些算法似乎特别适合解决这些局部子问题,有效地产生了新的分布式优化算法。
2.3.2 Distributed Algorithms
如下文第2.3.1节所述,这种设置会带来独特的挑战。分布式优化算法每次迭代通常需要少量(1-4)的通信轮数。通过通信轮数,我们通常了解单个MapReduce操作[24],这是为迭代过程[36],例如优化算法,而有效实现的。Spark[102]已经被建立为一个流行的开源框架,用于实现分布式迭代算法,这包括本节提到的几种算法。
几十年来,人们一直在研究分布式环境中的优化问题,至少可以追溯到Bertsekas和Tsitiklis的工作[8,7,95]。近十年来,人们对这一领域的兴趣激增,很大程度上是因为机器学习应用程序中数据可用性的快速增加。
最近的大部分工作都集中在通过构建适合在单个处理器上运行的流行算法的变体(见第2.1节),创建新的优化算法上。其中许多工作的一个相对常见的特点是 a)同步算法的计算开销;b)在没有限制性假设的情况下分析异步算法的困难。通过计算开销,我们的意思是,如果优化程序在计算-通信-更新周期中运行,则更新部分在所有节点完成计算之前无法启动。这导致一些节点处于空闲状态,而其余的节点完成了它们的部分计算,显然是对计算资源的低效利用。这种模式通常会从分布式计算中减少或完全恢复潜在的加速。通常在异步设置中,可以对参数向量应用更新,然后根据该参数向量的当前过时版本进行计算。正式掌握这种模式,同时保持环境的现实性往往是相当具有挑战性的。因此,这是一个非常开放的领域,在任何特定情况下,算法的最佳选择通常很大程度上取决于问题的规模、结构的细节、可用的计算体系结构,尤其是从业者的专业知识。
这个一般性的问题通过多次尝试并行化随机梯度下降及其变体得到了最好表现。作为一个例子,[27,29]通过节点数量提供了理论上的线性加速,但很难有效地实现,因为节点需要经常同步以计算合理的梯度平均值。作为替代方案,在[71,2,31]中假定机器之间没有同步。因此,每个机器从内存中读取wt,即时间点t处的参数向量w,计算随机梯度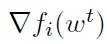 ,并将其应用于参数向量wt+τ的已更改状态。上述方法假设延迟τ由一个常量约束,这不一定是实际假设。一些工作还引入了稀疏结构或f的Hessian条件的假设。在[30]中用相当轻微的假设证明了渐近最优收敛速度。对异步SGD的改进分析也在[22]中提出,同时引入了一种在不牺牲性能的情况下使用低精度算法的版本,这是未来几年机器学习其他部分可能会用到的一种趋势。
,并将其应用于参数向量wt+τ的已更改状态。上述方法假设延迟τ由一个常量约束,这不一定是实际假设。一些工作还引入了稀疏结构或f的Hessian条件的假设。在[30]中用相当轻微的假设证明了渐近最优收敛速度。对异步SGD的改进分析也在[22]中提出,同时引入了一种在不牺牲性能的情况下使用低精度算法的版本,这是未来几年机器学习其他部分可能会用到的一种趋势。
SGD的异步分布式实现的负面影响似乎可以忽略不计,当应用于训练非常大的深度网络时,这是当今的最终工业应用。例如,谷歌的Downpour SGD[23]和微软的Project Adam[18]证明了这种方法的实用性。
坐标下降算法的第一个分布式版本是Hydra及其加速变体Hydra2,[81,34],这已被证明对在计算集群上实现的大型稀疏问题非常重要。在[61]中提供了一个扩展版本,描述了实现细节。在[56,55]的工作中,对异步效应进行了探索,并从理论上对其进行了部分解释。在[72]中提出了另一个异步的框架,用于协调更新,适用于更广泛的目标类别。
在上述算法中,假设数据通过特征/坐标划分到节点。如果不能预先分发数据,此设置可能会受到限制,但数据是按“原样”分发的,在这种情况下,数据最常见的分发方式是按数据点分发。如果使用对偶版本的坐标下降,则这不需要成为一个问题,其中分布由数据点[94]完成,然后进行高效通信对偶坐标上升,如下一节所述。然而,对偶性的使用需要额外的显式强凸正则化项,因此可以用来解决较小的问题。尽管存在明显的实际缺点,但分布式坐标下降算法的变体是实践中使用最广泛的方法之一。
从方差消减法来看,SAG/SAGA算法的分布式版本还没有被提出。然而,SVRG算法的几个分布式版本已经存在。在[50]中提出了一种在分布式环境下复制数据以模拟IID采样的方案。虽然性能分析得很好,但设置要求对数据分布进行更强有力的控制,这在实际中很少可行。在[78]中提出了一种与本文算法3较为类似的方法,并在[59]中进行了分析,这是一项主要的实验工作,以证实高效通信,这在第2.3.3节中将会详细描述。
与这项工作相关的另一类算法是交替方向乘数法(ADMM)[14,28]。这些算法一般适用于更广泛的问题类别,在(1)的机器学习设置中,没有观察到比本节中介绍的其他算法性能更好。
2.3.3 Communication-Efficient Algorithms
在这一节中,我们将介绍可以被转换为“通信效率”的算法。本文提出的算法的共同主题是,为了更好地执行(3),我们应该设计具有高TA的算法,以使通信成本c可以忽略不计。
在使用特定的方法之前,值得注意的是关于我们在分布式设置中试图解决的问题的一些核心限制。在[90]中研究了问题(1)随机版本在运行时间、通信成本和使用的样本数量方面的基本限制。分布式统计估计的高效算法和下限在[104,103]中建立。
但是,这些工作不适合我们的框架,因为它们假定每个节点都可以访问从单个分布生成的IID数据。在[104,103]的情况下,K << n / K,即假设节点数K比每个节点上的数据点数目小得多。正如我们在引言中强调的,这些假设在我们的环境中远未得到满足。直观地说,放松这些假设会使问题更难解决。然而,得出这一结论并不是那么简单,因为肯定有一些特殊的非IID数据分布简化了问题,例如,如果数据是根据目标的可分离性结构分布的。[5]给出了(1)的分布式凸优化的通信复杂度下限,结论是对于IID数据分布,现有算法在特定的环境下已经达到了最优的复杂度。
可能首先,相当极端,工作[107]提出在一轮通信中并行SGD。每个节点仅在局部可用的数据上运行SGD,并对其输出进行平均以形成最终结果。然而,这种方法对于局部可用的数据分布的差异不是很鲁棒,而且[91,附录A]已经表明,一般来说,忽略所有其他数据,它不能比使用单个机器的输出取得更优的性能。
Shamir等人提出了DANE算法,Distributed Approximate Newton[91],在对解取平均之前,精确求解局部可用的一般子问题。该方法依赖于局部目标的Hessians相似性,将它们的迭代表示为不精确牛顿步骤的平均值。我们在第3.4节中更详细地描述了此算法,因为我们提出的工作是基于它的。在[59]中提出了一种非常相似的方法,其中包含了更丰富的子问题类型,这些子问题类型可以局部公式化,并且可以近似求解。对DANE的不精确版本及其加速变种AIDE的分析最近出现在[78]中。不精确的DANE与本文提出的算法密切相关。然而,我们继续朝着联邦优化设置所形成的不同方向发展。
Zhang和Xiao的DiSCO算法[105]基于非精确阻尼牛顿法。其核心思想是,非精确牛顿每一步是由分布式预处理共轭梯度计算的,如果数据以IID的方式分布,它可以非常快地使一个好的预处理程序进行局部计算。根据DANE和其他方法,通信轮数的理论上限得到了改进,并且在某些设置中与[5]中给出的下限相匹配。DiSCO算法与[52,106]有关,这是一种分布式截断牛顿法。尽管DiSCO算法在实际应用中表现良好,但共轭梯度迭代的总数仍可能过高,而使得其不被认为是一种高效通信算法。
上述算法的共同点是假设每个节点都可以访问采样自相同分布的IID数据点。这一假设不仅在理论上是必需的,而且会导致算法收敛速度明显减慢,甚至出现发散(如[91,表3]所述)。因此,这些算法,至少以它们的默认形式,不适合设置这里提出的联邦优化。
CoCoA是一种绕过IID数据假设需求的算法,它可以证明在任何数据分布下都会收敛,而收敛速度则取决于数据分布的特性。该算法的第一版在[101]中作为DisDCA被提议出,但没有收敛保证。在[42]中介绍了第一个分析,在[58]中进一步改进,在[57]中介绍了更通用的版本。最近,在[92]中介绍了针对L1规范化目标的变体。
CoCoA框架基于(1)的对偶形式(参见例如[57,等式2])制定一般的局部子问题。数据点与相应的对偶变量一起分布到节点上。采用任意优化算法,只改变局部对偶变量,就可以得到局部子问题的相对Θ精度。这些更新对原始变量w进行了相应的更新,这些变量w被同步聚合(可以是平均值,总和,或介于两者之间;这取决于局部子问题公式)。
从本节中的描述来看,CoCoA框架似乎是设置联邦优化的唯一可用工具。然而,对于病态问题的通信轮数的理论界限与节点数目K成比例。事实上,正如我们将在第4节展示的真实数据那样,CoCoA框架的收敛速度非常缓慢。
3 Algorithms for Federated Optimization
在这一节中,我们将介绍第一个针对联邦优化的独特挑战而设计的算法。在继续解释之前,我们首先回顾了两个重要的但乍一看不相关的算法。这些算法之间的联系有助于激发我们的研究,即随机方差消减梯度(SVRG)[43,47],一种显式降低方差的随机方法,和分布式优化的分布式近似牛顿(DANE)[91]。
这些描述后面是它们之间的联系,由此产生了一种新的分布式优化算法,乍一看几乎与SVRG算法相同,我们称之为联邦SVRG(FSVRG)。
虽然该算法在简单情况下的实践效果良好,但在我们在第3.3节中指定的一般设置中,其性能仍然不令人满意。我们通过使FSVRG算法适应不同的局部数据大小、通用的稀疏模式以及局部可用数据模式和整个数据集中存在的模式的显著差异来对其进行改进。
3.1 Desirable Algorithmic Properties
这是一个有用的思想实验,来考虑在非IID、不平衡和大规模分布式设置的算法中希望找到的属性。特别地:
(A)如果算法被初始化为最优解,它将保持在那里。
(B)如果所有数据都在一个节点上,算法应在O(1)轮通信中收敛。
(C)如果每个特征都发生在一个节点上,那么问题是完全可分解的(每个机器基本上都在学习一个不相交的参数块),那么算法应该在O(1)轮通信中收敛。
(D)如果每个节点包含相同的数据集,那么算法应该在O(1)轮通信中收敛。
对于凸问题,“收敛”具有通常的技术意义,即找到一个足够接近全局最小值的解,但这些性质也适用于非凸问题,“收敛”可以理解为“找到一个足够质量的解”。在这些陈述中,O(1)轮理论上就是一轮通信。
属性(A)在任何优化设置中都是有价值的。属性(B)和(C)是联邦优化设置的极端情况(非IID、不平衡和稀疏),而(D)是经典分布式优化设置的极端情况(每台机器有大量IID数据)。因此,(D)是联邦优化设置中算法最不重要的属性。
3.2 SVRG
SVRG算法[43,47]是一种随机方法,旨在解决单个节点上的问题(1)。我们以稍微简单的形式将其作为算法1呈现。

该算法在两个嵌套循环中运行。在外循环中,它计算整个函数f的梯度(第3行),这就构成了一个对数据的完整遍历。一般来说,除非有必要,否则要避免这样昂贵的操作。然后是一个内部循环,其中m次快速随机更新被执行。在实践中,m通常设置为n的小倍数(1-5)。虽然理论上m的最佳选择是条件数的小倍数[47,定理6],但在实践中,这通常与n的顺序相同。
该算法的核心思想是避免使用随机梯度来直接估计整个梯度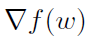 ,取而代之的是,在第7行的随机更新中,该算法计算了两个不同的随机梯度,
,取而代之的是,在第7行的随机更新中,该算法计算了两个不同的随机梯度,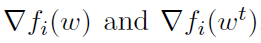 。这些梯度用于估计在点wt和w之间整个函数梯度的变化,即
。这些梯度用于估计在点wt和w之间整个函数梯度的变化,即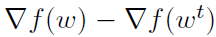 。利用这个估计和在外环中预先计算的
。利用这个估计和在外环中预先计算的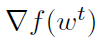 ,得出
,得出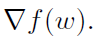 的无偏估计。
的无偏估计。
除了是一个无偏估计外,还可以直观地看出,如果w和wt彼此接近,估计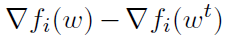 的方差应该要小,导致小方差的
的方差应该要小,导致小方差的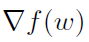 估计。随着内部迭代w的深入,方差会增大,算法会启动一个新的外循环来计算新的全梯度
估计。随着内部迭代w的深入,方差会增大,算法会启动一个新的外循环来计算新的全梯度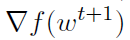 并重置方差。
并重置方差。
从理论上讲,这种表现是很好理解的。对于λ-强凸f和L-光滑函数fi,收敛结果如下:
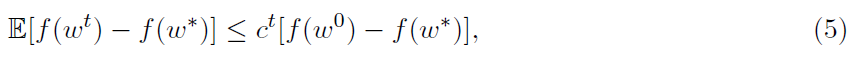
其中w*是最优解,且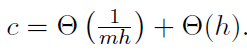
可以证明[47,定理6]对于适当的参数m和h的选择,收敛速度(5)转化为下式的需要
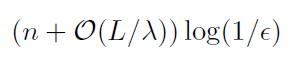
对一些i,计算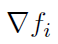 来实现
来实现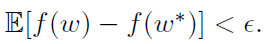
3.3 Distributed Problem Formulation
在本节中,我们引入了符号,并详细说明了我们考虑的问题(1)的分布式版本的结构,重点讨论了fi是凸的情况。我们假设数据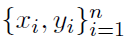 ,描述函数fi存储在大量节点上。
,描述函数fi存储在大量节点上。
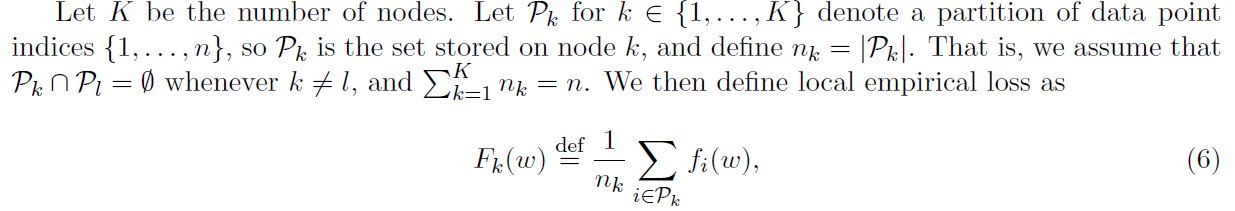
这是基于机器k上存储数据的局部目标。然后我们可以将目标(1)重新表述为
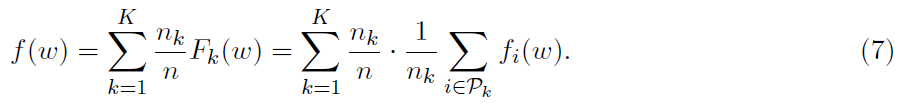
解释这种结构的方法是将经验损失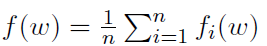 视为可用于节点k的局部经验损失Fk(w)的凸组合。然后,问题(1)采用简化形式
视为可用于节点k的局部经验损失Fk(w)的凸组合。然后,问题(1)采用简化形式

3.4 DANE
在本节中,我们将介绍一种通用论证,为DANE算法[91]提供更强的直观支持,我们将在下面详细描述该算法。我们将在附录A中对此论证进行跟进,并在文献不知道的两种现有方法之间建立联系。
如果我们想设计一个分布式算法来解决上述问题(8),其中节点k包含描述函数Fk的数据。首先,正如我们将看到的,一个相当幼稚的想法是要求每个节点最小化它们的局部函数,并对结果进行平均(这种想法的变体出现在[107]中):
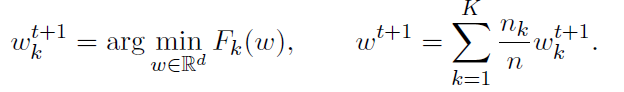
显然,在多个迭代中运行该算法是没有意义的,因为输出w总是相同的。这仅仅是因为wkt+1不依赖于t,换句话说,这个方法只执行一轮通信。虽然其简单性很吸引人,但这种方法的缺点是它不能工作。实际上,没有理由期望(8)的解是局部解的加权平均值,除非局部函数都相同——在这种情况下,我们不需要分布式算法,而只要去解决一个更简单的问题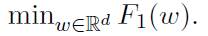 。这种直观的论证也可以得到正式的支持,例如参见[91,附录A]。
。这种直观的论证也可以得到正式的支持,例如参见[91,附录A]。
解决上述问题的一个方法是在每个聚合步骤之前修改局部问题。最简单的策略之一是用二次项形式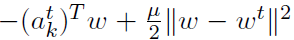 来扰动迭代t中的局部函数Fk,并要求每个节点去求解扰动后的问题。通过这一改变,改进后的方法就成了如下形式:
来扰动迭代t中的局部函数Fk,并要求每个节点去求解扰动后的问题。通过这一改变,改进后的方法就成了如下形式:
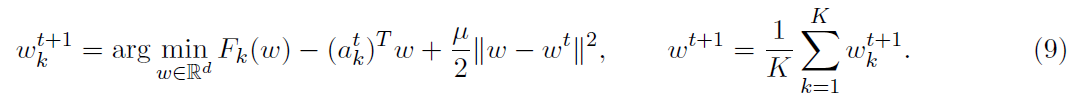
此种形式的迭代背后的想法如下:我们希望每个节点k( k属于[K] )使用存储在Fk中尽可能多的曲率信息。通过将函数Fk保持在子问题的整体上,我们将曲率信息保持在几乎完整的状态——子问题的海森矩阵为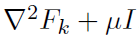 ,并且我们甚至可以选择μ=0。
,并且我们甚至可以选择μ=0。
如前所述,该方法还没有被很好地定义,因为我们还没有描述向量akt在迭代中将会如何改变,以及应该如何选择μ。为了深入了解这种方法是如何工作的,让我们检查一下最优性条件。当t趋向于无穷时,我们希望akt是这样的:每个子问题的最小值等于w*;(8)的极小值。因此,我们希望w*是下式的解
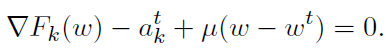
因此,在极限情况下,我们理想地选择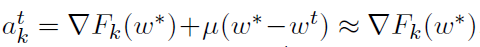 ,此时w* ≈ wt。因为不知道w*,所以我们不能简单地将akt设置为该值。因此,第二种选择是提出一个更新规则,以保证akt在t趋于无穷时收敛到
,此时w* ≈ wt。因为不知道w*,所以我们不能简单地将akt设置为该值。因此,第二种选择是提出一个更新规则,以保证akt在t趋于无穷时收敛到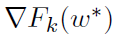 。注意,在优化领域中,长期以来都知道,在最优点时目标的梯度与对偶问题的最优解密切相关。这里的情况更为复杂,因为我们需要学习K这样的梯度。在下面,我们展示了DANE实际上是上述方案的一个特殊实例。
。注意,在优化领域中,长期以来都知道,在最优点时目标的梯度与对偶问题的最优解密切相关。这里的情况更为复杂,因为我们需要学习K这样的梯度。在下面,我们展示了DANE实际上是上述方案的一个特殊实例。
DANE. 我们将分布式近似牛顿算法(DANE)[91]作为算法2。该算法最初是为了解决结构(7)问题的,其中,每个k的nk是相同的,即每台计算机具有相同数量的数据点。但没有什么能阻止我们在更一般的环境中运行它。

正如前面提到的,DANE的主要思想是形成一个局部子问题,只依赖于局部数据和整个函数的梯度,这可以在一轮通信中计算出来(第3行)。然后精确求解子问题(第4行),对每个节点的更新取平均,形成新的迭代(第5行)。这种方法允许使用任意算法来求解局部子问题(10)。因此,它通常在需要在多轮通信之间进行昂贵的局部计算的情况下实现通信效率,以求使得通信所需的时间变得无关紧要(见第2.3.1节)。此外,请注意,DANE属于通过二次扰动技巧(9)操作的分布式方法家族,它使用
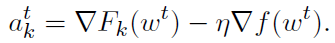
如果我们假设这个方法有效,那么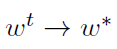 ,因此
,因此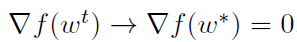 ,然后
,然后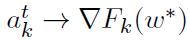 ,这与前面的讨论是一致的。
,这与前面的讨论是一致的。
在默认设置中,当μ=0和η=1时,DANE实现了所需的属性(D)(当所有局部数据集都相同时立即收敛)。在这种情况下,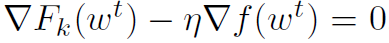 ,并且我们在每个机器上精确地最小化
,并且我们在每个机器上精确地最小化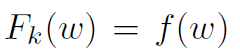 。对于μ和η的任何选择,DANE也实现了属性(A)。在这种情况下,
。对于μ和η的任何选择,DANE也实现了属性(A)。在这种情况下,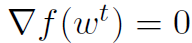 ,并且wt是
,并且wt是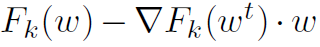 的极小值以及正则化项。不幸的是,DANE没有实现联邦优化特别期望的属性(B)和(C)。
的极小值以及正则化项。不幸的是,DANE没有实现联邦优化特别期望的属性(B)和(C)。
在DANE的收敛分析中假设函数是两次可微的,并且每个节点都可以访问来自相同底层分布的IID样本。这暗示着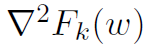 的海森矩阵与其他节点相似[91,引理1]。在线性回归时,对于
的海森矩阵与其他节点相似[91,引理1]。在线性回归时,对于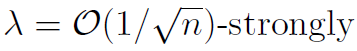 凸函数,要达到准确率ε,DANE需要的迭代次数为
凸函数,要达到准确率ε,DANE需要的迭代次数为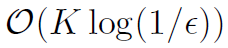 。然而,对于一般的L-光滑损失,理论与实际情况严重不符。
。然而,对于一般的L-光滑损失,理论与实际情况严重不符。
实际性能还取决于附加的局部正则化参数μ。对于少量节点K,当μ=0时算法收敛速度较快。然而,如[91,图3]所示,随着K的增长,它会迅速发散。μ越大,算法就越稳定,但收敛速度越慢。实际选择仍然是一个悬而未决的问题。
3.5 SVRG meets DANE
正如我们前面提到的,即使没有联邦优化带来的挑战,DANE算法在某些设置中的性能也很差。DANE的另一个缺点是需要找到(10)的精确最小值——这对于尺寸相对较小的四边形是可行的,但对于其他问题来说是不可行的或极其昂贵的。我们采用了CoCoA算法[57]的思想,使用任意优化算法来获得局部子问题的相对Θ精度。我们用任意优化算法得到的近似解来代替精确优化。
考虑到所有的算法可以用来解决(10),SVRG算法似乎是一个特别好的候选方案。从点wt开始对(10)进行局部优化,算法自动获得点wt的导数,这在每个节点上都是相同的——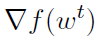 。因此,SVRG算法可以跳过初始的昂贵操作,对整个梯度进行求值(第3行,算法1),并且只在内循环中进行随机更新。
。因此,SVRG算法可以跳过初始的昂贵操作,对整个梯度进行求值(第3行,算法1),并且只在内循环中进行随机更新。
结果表明,DANE算法的这个改进版本相当于SVRG的一个分布式版本。
命题1. 考虑以下两种算法:
- 在η=1和μ=0下运行DANE算法(算法2),并使用SVRG(算法1)作为(10)的局部求解器,运行它进行单次迭代,在点wt处初始化。
- 运行SVRG算法的分布式变体,如算法3所述。
这些算法在以下意义上是等效的。如果两个都从同一个点wt开始,它们将生成相同的迭代序列{wt}。
证明. 我们通过证明应用于计算机k上问题(10)的SVRG算法的单步与算法3中第8行的更新是一致的,从而构造了证明。
求(10)的随机梯度的方法是对构成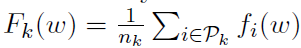 的其中一个函数进行采样,然后加入线性项
的其中一个函数进行采样,然后加入线性项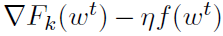 ,这是已知的,不需要估计。在对索引
,这是已知的,不需要估计。在对索引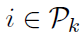 进行抽样时,更新方向如下
进行抽样时,更新方向如下
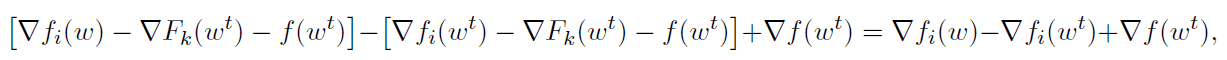
这与算法3中第8行的方向相同。断言之后链接相同的更新以形成相同的迭代wt+1。

评论2. 在命题1中考虑的算法本质上是随机的。在两种情况的假设下,命题的陈述都是有效的,所有节点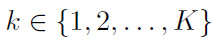 都会生成相同的样本
都会生成相同的样本 序列。
序列。
评论3. 在命题1中,我们考虑具有特定值η和μ的DANE算法。算法3和命题可以很容易地进行泛化,但是为了清晰起见,我们只提供默认版本。
从本文的第一个版本开始,[78]就提到了这种联系,它分析了DANE算法的一个不精确版本。我们通过调整上述算法来应对联邦优化环境中出现的其他挑战。
3.6 Federated SVRG
从经验上看,算法3符合第2.3.1节描述的分布式优化效率模型,因为我们可以做到本地执行的随机迭代次数与通信成本之间的平衡。但是,为了在完整的联邦优化设置(第3.3节)中获得良好的性能,需要进行一些修改。需要解决的一个非常重要的方面是,给定节点可用的数据点数量可能与任何单个节点可用的平均数据点数量大不相同。此外,此设置总是伴随着本地可用的数据围绕特定模式聚集在一起,因此不是我们试图学习的总体分布的代表性样本。在实验部分,我们将重点放在L2正则化逻辑回归的情况,但这些想法还涉及到其他广义线性预测问题。
3.6.1 Notation
请注意,在大规模广义线性预测问题中,产生的数据几乎总是稀疏的,例如词库样式的特征表示。这意味着只有矢量xi中d个元素的小子集具有非零值。在这类问题中,梯度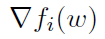 是数据向量xi的倍数。这会造成额外的复杂性,但也有可能利用问题结构,从而加快算法的速度。在继续之前,让我们总结并表示描述算法所需的量。
是数据向量xi的倍数。这会造成额外的复杂性,但也有可能利用问题结构,从而加快算法的速度。在继续之前,让我们总结并表示描述算法所需的量。
- n —— 数据点/训练样例/函数的数量。
- Pk —— 索引集合,对应于存储在设备k上的数据点。
- nk = |Pk| —— 存储在设备k上的数据点的数目。
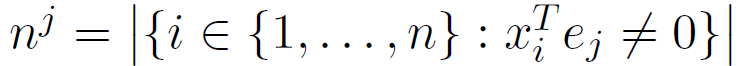 具有非零jth坐标的数据点数量。
具有非零jth坐标的数据点数量。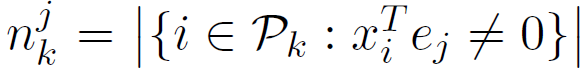 具有非零jth坐标且存储在k节点上的数据点数量。
具有非零jth坐标且存储在k节点上的数据点数量。- Φj = nj / n —— jth坐标非零的数据点出现的频率。
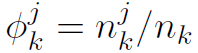 —— 在节点k上jth坐标非零的数据点出现的频率。
—— 在节点k上jth坐标非零的数据点出现的频率。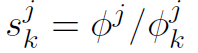 —— 在节点k上jth坐标非零的数据点,其全局和局部出现频率之比。
—— 在节点k上jth坐标非零的数据点,其全局和局部出现频率之比。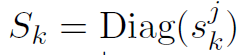 —— 对角矩阵,由
—— 对角矩阵,由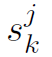 作为第j个对角元素组成。
作为第j个对角元素组成。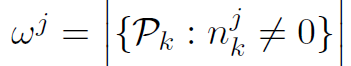 —— 包含具有非零jth坐标的数据点的节点数。
—— 包含具有非零jth坐标的数据点的节点数。- aj = K / wj —— 坐标j的聚合参数。
- A = Diag(aj) —— 由aj作为jth对角元素组成的对角矩阵。
当这些量被定义后,我们可以将所提出的算法描述为算法4。实验表明,该算法在实际应用中效果很好,但对于特定规模的更新,动机可能不是很清楚。在下面的部分中,我们提供了导致该算法开发的直觉。
3.6.2 Intuition Behind FSVRG Updates

算法4和算法3的区别在于引入了以下特性:
- 局部步长 —— hk = h / nk
- 与分区大小成比例的更新聚合 —— nk(wk - wt) / n
- 用对角矩阵缩放随机梯度 —— Sk
- 聚合更新的逐坐标缩放 —— A(wk - wt)
现在让我们解释一下是什么促使我们得到这个特定的实现。
作为一个简化,假设在某个时间点,我们有一些w,对所有的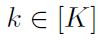 都有wk = w。换句话说,所有节点都有相同的本地迭代。尽管实际情况并非如此,但在这种简化的环境中思考这个问题,将使我们了解如果它是真的,我们做什么是有意义的。进一步说,我们可以希望现实离简化不远,它在实践中仍然有效。实际上,所有节点都是从同一点开始的,并且将线性项
都有wk = w。换句话说,所有节点都有相同的本地迭代。尽管实际情况并非如此,但在这种简化的环境中思考这个问题,将使我们了解如果它是真的,我们做什么是有意义的。进一步说,我们可以希望现实离简化不远,它在实践中仍然有效。实际上,所有节点都是从同一点开始的,并且将线性项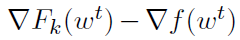 添加到局部目标会强制所有节点朝同一方向移动,至少在最初是这样的。
添加到局部目标会强制所有节点朝同一方向移动,至少在最初是这样的。
假设节点要同步进行单个步骤,将节点k上的更新方向表示为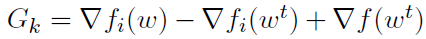 ,其中i从Pk中随机均匀采样。
,其中i从Pk中随机均匀采样。
如果我们只有一个节点,即K=1,很明显我们会有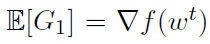 。如果K大于1,Gk的值一般为
。如果K大于1,Gk的值一般为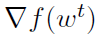 的有偏估计。我们希望实现以下目标:
的有偏估计。我们希望实现以下目标: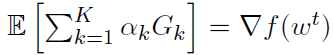 ,对于ak的一些选择。这是由于人们普遍希望采用随机一阶方法来实现期望中的一步梯度。
,对于ak的一些选择。这是由于人们普遍希望采用随机一阶方法来实现期望中的一步梯度。
我们有 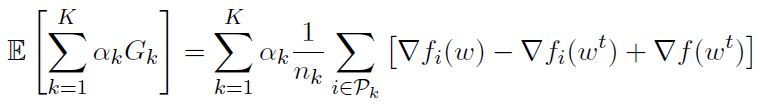
通过设置ak = nk / n,我们得到
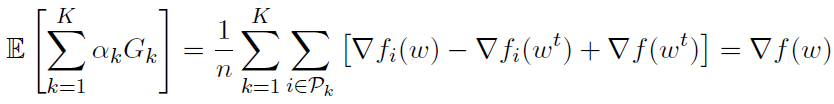
这会促使与nk(本地可用数据点的数量)成比例的节点聚合更新(第2点)。
接下来,我们认识到如果本地数据大小nk不相同,我们可能不想在每个节点k上执行相同数量的本地迭代。直观地说,执行一次数据遍历(或固定数量的遍历)是有意义的。因此,上述动机的聚集不再具有完美的意义。然而,我们可以通过设置与nk成反比的步长hk,使其均匀化,以确保每个节点的总体进度大致相同。因此,hk = h / nk(第1点)。
为了得到第3点,利用对角矩阵Sk对随机梯度进行缩放,考虑下面的例子。我们有1000000个数据点,分布在K=1000个节点上。当我们观察数据点的一个特殊特征时,我们发现只有1000个数据点是非零的,而且所有这些数据恰好存储在一个节点上,该节点只存储1000个数据点。从该节点采样一个数据点并计算相应的梯度,将清楚地得出1000倍大的梯度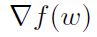 的估计值。如果只做一次,这不一定是个问题。然而,重复采样和超调梯度的大小可能会导致迭代过程迅速发散。
的估计值。如果只做一次,这不一定是个问题。然而,重复采样和超调梯度的大小可能会导致迭代过程迅速发散。
因此,我们用对角矩阵来对随机梯度进行缩放。这可以看作是一种尝试,当算法设计者在意识到稀疏模式分布结构的情况下,将梯度的估计值强制变为正确的大小。
现在让我们重点介绍第4点中修改的一些属性。在没有任何额外信息,或者在完全密集的数据情况下,对本地更新取平均是唯一真正有意义的方法 —— 因为每个节点都输出一个代理的近似解以实现总体目标,并且在输出中没有诱发型的可分离性结构,例如在CoCoA中[57]。然而,在另一个极端,我们可以做得更多。如果稀疏结构使得每个数据点只依赖于一组不相交的变量中的一个,并且数据是按照这种结构分布的,那么我们就可以有效地解决多个不相交的问题。对每一个问题进行局部求解,并将结果相加,就可以用单次迭代解决问题——所需算法性质(C)。
我们提出在这两个设置之间以每个变量为基础进行插值。如果一个变量出现在每个节点的数据中,我们将取平均值。但是,一个特定变量出现的节点越少,我们越想信任这些节点,以便通知我们对该变量的有意义的更新,或者采取更长的步骤。因此,聚合更新的每个变量都进行了缩放。
3.7 Further Notes
从命题1出发,我们确定了两种算法的等价性,并对第二种算法进行了修正,使其适合于联邦优化的设置。自然会出现一个问题:是否可以通过修改第一个适合联邦优化的算法来实现这一点——只需改变局部优化目标?
我们确实尝试过这个想法,但是我们没有报告细节,有两个原因。首先,对局部子问题的精确解的要求往往是不切实际的。把这个要求放松,会逐渐把我们带到前面几节介绍的环境中。但更重要的是,使用这种方法,我们只能获得明显低于后面实验部分报告的结果。
4 Experiments
在本节中,我们将介绍联邦优化设置中的第一个实验结果。特别是,我们提供了基于公共Google+帖子数据集的结果。这个数据集由用户集群组成——将每个用户模拟为一个独立的节点。这个初步的实验证明了为什么现有的算法都不适用于联邦优化,以及我们提出的方法对此挑战的鲁棒性。
4.1 Predicting Comments on Public Google+ Posts
这里显示的数据集是基于公开的Google+帖子生成的。我们随机挑选了10000名拥有至少100篇英文公开文章的作者,并试图预测一篇文章是否会收到至少一条评论(即二分类任务)。
对每一个作者,我们按时间顺序将数据进行划分,前75%用于训练,后25%用于测试。训练实例总数为n=2166693。我们创建了一个简单的词库语言模型,该模型基于Google+数据字典中20000个最常见的单词。这导致问题的维度d=20002。另外两个特征分别代表偏置项和未知词的变量。然后,我们使用逻辑回归模型来根据这些特征进行预测。
我们将分布优化问题的形式化如下:假设每个用户对应一个节点,得到K=10000。因此,节点K上的平均数据点数nk约为216。然而,实际上nk的取值范围是75到9000,这表明数据实际上是不平衡的。
很自然地,不同的用户可以在生成的数据中显示非常不同的模式。确实如此,因此节点的分布不能视为整个分布的IID样本。因为我们有一套词库模型,所以我们的数据非常稀疏。大多数帖子只包含字典中所有单词的一小部分。这一点,再加上数据是以每用户为基础自然集群的这一事实,造成了传统分布式设置中不存在的额外挑战。
图1显示了跨节点的不同特征的频率。有些特征随处可见,如偏置项,而大多数特征相对较少。特别是,超过88%的特征出现在不足1000个节点上。然而,这种分布并不一定与数据样例中的特征的总体外观相似。例如,虽然几乎每个用户的数据中都存在一个未知词,但它远未包含在每个数据点中。
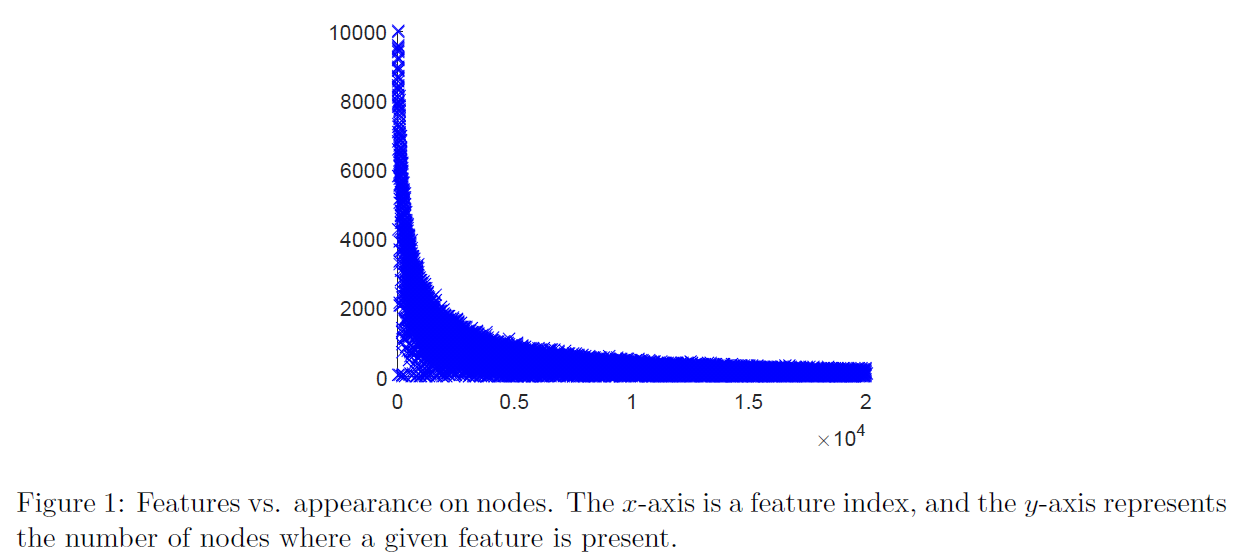
Naive prediction properties. 在呈现结果之前,查看数据的一些重要的基本预测属性是很有用的。我们采用L2正则化逻辑回归,正则化参数λ=1/n。我们选择在最优解的测试误差方面表现最优的λ。
- 如果选择预测-1(无注释),分类误差为33.16%。
- 全局逻辑回归问题的最优解产生26.27%的测试集误差。
- 根据训练数据预测每个作者的多数情况,得出17.14%的测试误差。也就是说,预测一个作者的所有帖子的+1或-1,基于哪个标签在该作者的训练数据中更常见。这表明了解作者实际上比了解他们说了什么更有用,这也许并不奇怪。
总之,这些数据代表了我们在联邦优化中的激励应用程序。可以使用固定的全局模型来改进原始基线。此外,每位作者的多数情况结果表明,通过将全局模型单独地适应每个用户,可以进一步改进性能。模型个性化是工业应用中的常见实践,用于此目的的技术与联邦优化的挑战是正交的。探索它的性能是一个自然的下一步,但超出了本工作的范围。
虽然我们没有为每个用户的个性化模型提供实验,但我们注意到这可能是一个很好的描述数据分布离IID有多远的描述符。实际上,如果每个节点都可以访问一个IID样本,那么对本地数据的任何调整都只是过度拟合。但是,如果我们可以通过对每个用户/节点的适应来显著改进全局模型,这意味着本地可用的数据显示特定节点的特定模式。
算法4的性能如下所示。用户唯一需要选择的参数是步长h。我们尝试了一组步长,并回顾性地选择了一个最适合的工作 —— 一个机器学习的典型实践。
在图2中,我们比较了以下优化算法:
- 蓝色方块(OPT)表示最佳的可能离线值(第一个图中优化任务的最佳值,第二个图中与最佳值对应的测试误差)。
- 青色钻石(GD)对应一个简单的分布式梯度下降。
- 紫色三角形(COCOA)用于CoCoA+算法[57]。
- 绿色圆圈(FSVRG)给出了我们提出的算法的值。
- 红色星星(FSVRGR)对应于同样的算法,应用于随机重组数据的同一个问题。也就是说,我们保持每个节点的样例数量不平衡,但是用随机选择的样例填充每个节点。
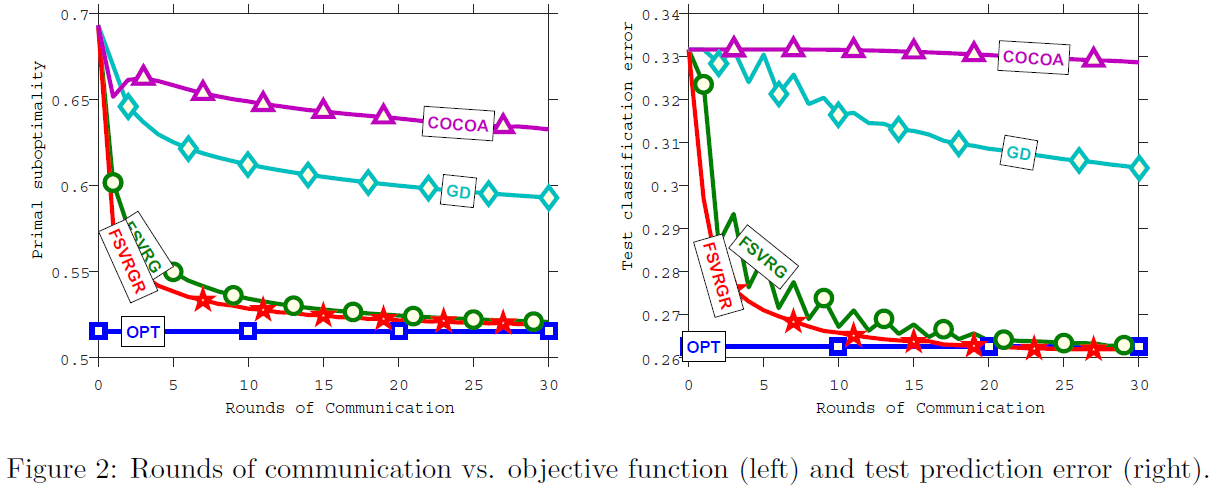
首先要注意的是,CoCoA+似乎比普通基准 —— 分布式梯度下降更糟糕。这种行为可以从理论上预测,因为总体收敛速度直接取决于聚合参数σ’的最佳选择。对于稀疏问题,它是以图1中报告值的最大值(即K)为上界的,并且在实践中也接近于它。尽管预计该算法可以根据这些数量的平均值(可能是数量级较小)进行修改,类似于坐标下降算法[79],但尚未完成。请注意,其他的高效通信算法不能完全收敛。
我们提出的算法FSVRG在30次迭代中收敛到最佳的测试分类精度。回想一下,在我们在1.2节中介绍的联邦优化设置中,最大限度地减少通信轮数是主要目标。然而如果直接得出结论,该方法明显优于现有方法,既不完全公平,也不正确。正确的结论应该是,FSVRG算法是解决联邦优化问题的第一种算法,而现有的方法无法推广到这一问题。必须强调的是,现有的方法都没有考虑到这些特定的挑战,我们制定了第一个基准。
由于其他方法无法收敛的核心原因是非IID数据分布,我们在相同的问题上测试了我们的方法,其中数据在相同数量的节点(FSVRGR;红色星星)之间随机重组。由于收敛性差异很小,我们可以得出结论,第3.6.2节中描述的技术符合其目的,并使算法对联邦优化中的挑战具有鲁棒性。
这个实验表明,从大量分散的数据中学习,在每个用户的基础上集群,确实是我们可以在实践中解决的问题。自本文第一版[45]以来,其他实验结果见[62]。在更具挑战性的深度学习环境中,我们会让读者参考本文,并进一步讨论如何在实践中实现这种系统。
5 Conclusions and Future Challenges
我们为分布式优化引入了一种新的设置,我们称之为联合优化。这个设置是由概述的远景所驱动的,在远景中,用户根本不将生成的数据发送给公司,而是提供部分计算能力,用于解决优化问题。这为分布式优化带来了一系列独特的挑战。特别是,我们认为联邦优化问题的大规模分布、非IID、不平衡和稀疏特性需要由优化社区来解决。
我们解释了为什么现有方法在此设置中不适用或不起作用。即使是可以应用的分布式算法,在存在大量数据存储节点的情况下也会非常缓慢地收敛。我们证明,在实践中,有可能设计出在联邦优化的挑战性环境中高效工作的算法,这使得视觉在概念上可行。
我们认识到,在每个坐标的基础上缩放随机梯度是很重要的,每个节点上的随机梯度不同,以提高性能。据我们所知,这是首次在分布式优化中使用这种逐节点缩放。此外,我们根据数据中稀疏模式的分布,使用每个节点更新的每个坐标聚合。
尽管我们的结果令人鼓舞,但仍有很大的工作空间。一个自然的方向是考虑我们的算法的完全异步版本,更新一到就应用到这里。另一个是对我们的算法有一个更好的理论理解,因为我们相信对收敛性的深入理解将推动这一领域的进一步研究。
非凸目标联邦优化问题的研究是另一个重要的研究方向。特别是,神经网络是机器学习工具中最重要的例子,它产生非凸函数fi,而没有任何方便的一般结构。因此,对于优化算法的收敛性保证,并没有有效的描述结果。尽管缺乏理论上的理解,神经网络现在在许多应用领域都是最先进的,从自然语言理解到视觉对象检测。这种应用程序在联邦优化设置中自然出现,因此将我们的工作扩展到这些问题是一个重要的方向。
联邦优化中假定的非IID数据分布,特别是移动应用程序,建议考虑培训个性化模型和学习全局模型的问题。也就是说,如果在一个给定的节点上有足够的可用数据,并且我们假设数据是从与该节点的未来测试示例相同的分布中提取的,那么最好基于一个有利于本地数据良好性能的个性化模型进行预测,而不是只需使用全局模型。
References
(省略)
A Distributed Optimization via Quadratic Perturbations
本附录是根据一个通用算法扰动模板(9)对λ-strongly凸目标的激励DANE算法的讨论得出的。我们利用这一点提出了一种类似但新的方法,该方法不同于DANE在任意数据划分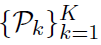 下收敛,并且强调了它与分布式优化的对偶CoCoA算法的关系。
下收敛,并且强调了它与分布式优化的对偶CoCoA算法的关系。
为了简化和方便绘制上述连接,我们假设在整个附录中,所有k(k属于{1,2,…,K})的nk都相同。所有的参数都可以简单地扩展,但是对于当前的目的来说,将不必要地使符号复杂化。
A.1 New method



A.2 L2-Regularized Linear Predictors

A.3 A Dual Method: Dual Block Proximal Gradient Ascent
(11)的对偶是问题



A.4 Proof of Theorem 5





Federated Optimization: Distributed Machine Learning for On-Device Intelligence的更多相关文章
- Distributed Machine Learning Toolkit
http://www.dmtk.io http://www.dmtk.io/download.html
- Federated Machine Learning: Concept and Applications
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布! Qiang Yang, Yang Liu, Tianjian Chen, and Yongxin Tong. 2019. Federate ...
- 【机器学习Machine Learning】资料大全
昨天总结了深度学习的资料,今天把机器学习的资料也总结一下(友情提示:有些网站需要"科学上网"^_^) 推荐几本好书: 1.Pattern Recognition and Machi ...
- ON THE EVOLUTION OF MACHINE LEARNING: FROM LINEAR MODELS TO NEURAL NETWORKS
ON THE EVOLUTION OF MACHINE LEARNING: FROM LINEAR MODELS TO NEURAL NETWORKS We recently interviewed ...
- 机器学习(Machine Learning)&深度学习(Deep Learning)资料【转】
转自:机器学习(Machine Learning)&深度学习(Deep Learning)资料 <Brief History of Machine Learning> 介绍:这是一 ...
- How do I learn machine learning?
https://www.quora.com/How-do-I-learn-machine-learning-1?redirected_qid=6578644 How Can I Learn X? ...
- 机器学习(Machine Learning)与深度学习(Deep Learning)资料汇总
<Brief History of Machine Learning> 介绍:这是一篇介绍机器学习历史的文章,介绍很全面,从感知机.神经网络.决策树.SVM.Adaboost到随机森林.D ...
- 机器学习(Machine Learning)&深度学习(Deep Learning)资料(Chapter 2)
##机器学习(Machine Learning)&深度学习(Deep Learning)资料(Chapter 2)---#####注:机器学习资料[篇目一](https://github.co ...
- (转)Introduction to Gradient Descent Algorithm (along with variants) in Machine Learning
Introduction Optimization is always the ultimate goal whether you are dealing with a real life probl ...
随机推荐
- MySQL索引介绍和实战
索引是什么 MySQL官方对索引的定义为:索引(Index)是帮助MySQL高效获取数据的数据结构. 可以得到索引的本质:索引是数据结构,索引的目的是提高查询效率,可以类比英语新华字典,根据目录定位词 ...
- layui实现图片上传
页面代码: <style> .uploadImgBtn2{ width: 120px; height: 92px; cursor: pointer; position: relative; ...
- C/C++编程笔记:C++入门知识丨认识C++面向过程编程的特点
一. 本篇要学习的内容和知识结构概览 二. 知识点逐条分析 1. 使用函数重载 C++允许为同一个函数定义几个版本, 从而使一个函数名具有多种功能, 这称之为函数重载. 像这样: 虽然函数名一样, 但 ...
- three.js 自制骨骼动画(二)
上一篇说了一下自制骨骼动画,这一篇郭先生使用帧动画让骨骼动画动起来.帧动画是一套比较完善的动画剪辑方法,详细我的api我们就不多说了,网上有很多例子,自行查找学习.在线案例请点击博客原文.话不多说先上 ...
- Efficient Knowledge Graph Accuracy Evaluation 论文笔记
前言 这篇论文主要讲的是知识图谱正确率的评估,将知识图谱的正确率定义为知识图谱中三元组表述正确的比例.如果要计算知识图谱的正确率,可以用人力一一标注是否正确,计算比例.但是实际上,知识图谱往往很大,不 ...
- .Net Core下基于Emit的打造AOP
之前的基于DispatchProxy的AOP组件,实现了属性注入,但是这个依旧有很多限制 比如不支持构造器注入,继承DispatchProxy的子类必须是公开类 个人有点代码洁癖,不喜欢这种不能控制的 ...
- ios数组基本用法和排序大全
1.创建数组 // 创建一个空的数组 NSArray *array = [NSArray array]; // 创建有1个元素的数组 array = [NSArray arrayWithObject: ...
- Java web 小测验
题目要求: 1登录账号:要求由6到12位字母.数字.下划线组成,只有字母可以开头:(1分) 2登录密码:要求显示“• ”或“*”表示输入位数,密码要求八位以上字母.数字组成.(1分) 3性别:要求用单 ...
- Python中匿名函数与内置高阶函数详解
大家好,从今天起早起Python将持续更新由小甜同学从 初学者的角度 学习Python的笔记,其特点就是全文大多由 新手易理解 的 代码与注释及动态演示 .刚入门的读者千万不要错过! 很多人学习pyt ...
- 【Java】JavaMail 554错误解决方法
一.解决连续发送多次 // 构件MimeMessage 对象,并设置在发送给收信人之前给自己(发送方)抄送一份 MimeMessage msg = mailSender.createMimeMessa ...