Kafka官方文档V2.7
1.开始
1.1 简介
什么是事件流?
事件流相当于人体的中枢神经系统的数字化。它是 "永远在线 "世界的技术基础,在这个世界里,业务越来越多地被软件定义和自动化,软件的用户更是软件。
从技术上讲,事件流是指以事件流的形式从数据库、传感器、移动设备、云服务和软件应用等事件源中实时捕获数据;将这些事件流持久地存储起来,以便日后检索;对事件流进行实时以及回顾性的操作、处理和反应;并根据需要将事件流路由到不同的目的技术。因此,事件流确保了数据的连续流动和解释,从而使正确的信息在正确的时间和地点出现。
我可以使用事件流做什么?
事件流被应用于众多行业和组织的各种用例中。它的许多例子包括:
- 实时处理支付和金融交易,如证券交易所、银行和保险公司。
- 实时跟踪和监控汽车、卡车、车队和货物,如物流和汽车行业。
- 持续采集和分析来自物联网设备或其他设备的传感器数据,例如在工厂和风场。
- 收集并立即响应客户的互动和订单,例如在零售、酒店和旅游行业以及移动应用中。
- 监测医院护理中的病人,并预测病情变化,以确保紧急情况下的及时治疗。
- 连接、存储和提供公司不同部门产生的数据。
- 作为数据平台、事件驱动架构和微服务的基础。
Apache Kafka是一个事件流平台。这意味着什么?
Kafka结合了三个关键功能,因此您可以通过一个经过实战检验的解决方案,端到端实现您的事件流用例。
- 发布(写)和订阅(读)事件流,包括从其他系统持续导入/导出数据。
- 只要你想,就能持久可靠地存储事件流。
- 在事件发生时处理事件流,或对事件流进行追溯。
所有这些功能都是以分布式、高度可扩展、弹性、容错和安全的方式提供的。Kafka可以部署在裸机硬件、虚拟机和容器上,也可以部署在企业内部以及云端。您可以在自我管理Kafka环境和使用由各种供应商提供的完全托管服务之间进行选择。
Kafka是如何工作的?
Kafka是一个分布式系统,由服务器和客户端组成,通过高性能的TCP网络协议进行通信。它可以部署在内部以及云环境中的裸机硬件、虚拟机和容器上。
服务器。Kafka以一个或多个服务器集群的形式运行,可以跨越多个数据中心或云区域。这些服务器中的一些构成了存储层,称为broker。其他服务器运行Kafka Connect,以事件流的形式持续导入和导出数据,将Kafka与您现有的系统(如关系型数据库以及其他Kafka集群)集成。为了让您实现关键任务用例,Kafka集群具有高度的可扩展性和容错性:如果它的任何一台服务器发生故障,其他服务器将接管它们的工作,以确保在没有任何数据丢失的情况下连续运行。
客户端。它们允许你编写分布式应用和微服务,即使在网络问题或机器故障的情况下,也能以并行、大规模、容错的方式读取、写入和处理事件流。Kafka船载包含了一些这样的客户端,Kafka社区提供的几十个客户端对其进行了增强:客户端可用于Java和Scala,包括更高级别的Kafka Streams库,用于Go、Python、C/C++和许多其他编程语言,以及REST API。
主要概念和术语
事件记录了世界上或你的企业中 "发生了什么 "的事实。它在文档中也被称为记录或消息。当你向Kafka读写数据时,你是以事件的形式进行的。概念上,一个事件有一个键、值、时间戳和可选的元数据头。下面是一个事件的例子。
- 事件键:"Alice"
- 事件价值: "支付了200美元给鲍勃"
- 事件时间戳: "2020年6月25日下午2点06分"
生产者是那些向Kafka发布(写)事件的客户端应用,消费者是那些订阅(读取和处理)这些事件的应用。在Kafka中,生产者和消费者是完全解耦的,彼此不可知,这是实现Kafka闻名的高可扩展性的关键设计元素。例如,生产者从来不需要等待消费者。Kafka提供了各种保证,例如,能够精确地处理事件-once。
事件被组织并持久地存储在主题中。非常简化,一个topic类似于文件系统中的一个文件夹,而事件就是该文件夹中的文件。一个例子的topic名称可以是 "支付"。Kafka中的topic总是多生产者和多订阅者的:一个topic可以有零个、一个或许多生产者向它写入事件,也可以有零个、一个或许多消费者订阅这些事件。主题中的事件可以根据需要随时读取--与传统的消息系统不同,事件在消耗后不会被删除。相反,你可以通过每个主题的配置设置来定义Kafka应该保留你的事件多长时间,之后旧的事件将被丢弃。Kafka的性能与数据大小有效地保持不变,所以长时间存储数据是完全可以的。
主题是分区的,也就是说一个主题会分布在位于不同的Kafkabroker上的多个 "桶 "上。这种数据的分布式放置对可扩展性非常重要,因为它允许客户端应用程序同时从/向许多broker读写数据。当一个新的事件被发布到一个主题时,它实际上被附加到主题的一个分区中。具有相同事件键的事件(例如,客户或车辆ID)被写入同一分区,Kafka保证给定主题-分区的任何消费者将始终以完全相同的顺序读取该分区的事件,因为它们被写入。
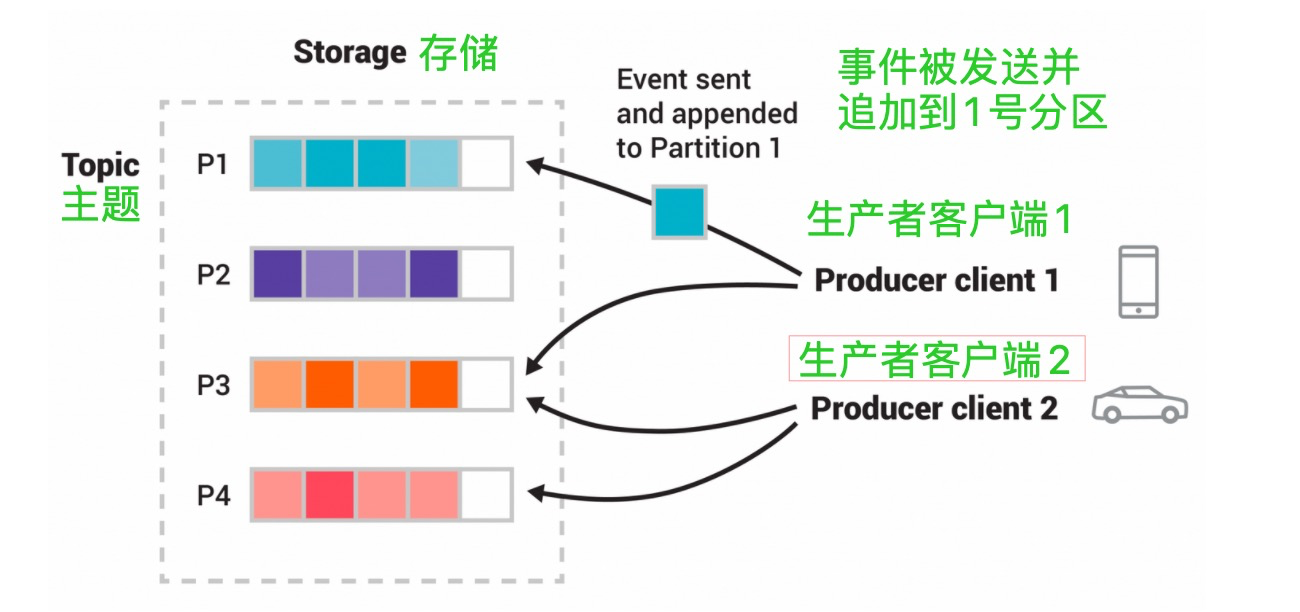
图:本例题有四个分区P1-P4。这个主题有四个分区P1 -P4。两个不同的生产者客户端通过网络将事件写入主题的分区,彼此独立地发布新事件到主题。具有相同键的事件(图中用它们的颜色表示)被写入同一个分区。注意,如果合适的话,两个生产者都可以写到同一个分区。
为了使你的数据具有容错性和高可用性,每个主题都可以被复制,甚至可以跨地理区域或数据中心,这样总有多个broker拥有数据的副本,以防万一出现问题,你想对broker进行维护等等。常见的生产设置是复制系数为3,即你的数据永远有三个副本。这种复制是在主题-分区的层面上进行的。
这个初级介绍应该足够了。如果你有兴趣的话,文档中的设计部分会完整详细地解释Kafka的各种概念。
Kafka APIs
除了用于管理和行政任务的命令行工具外,Kafka还有五个针对Java和Scala的核心API。
- 管理API用于管理和检查主题、broker和其他Kafka对象。
- Producer API用于向一个或多个Kafka主题发布(写入)事件流。
- 消费者API用于订阅(读取)一个或多个主题,并处理向其产生的事件流。
- Kafka Streams API用于实现流处理应用程序和微服务。它提供了更高层次的函数来处理事件流,包括转换、有状态的操作(如聚合和连接)、窗口化、基于事件时间的处理等。从一个或多个主题读取输入,以便生成输出到一个或多个主题,有效地将输入流转化为输出流。
- Kafka Connect API来构建和运行可重用的数据导入/导出连接器,这些连接器从外部系统和应用程序消耗(读)或产生(写)事件流,以便它们可以与Kafka集成。例如,连接PostgreSQL等关系型数据库的连接器可能会捕获一组表的每一个变化。然而,在实践中,你通常不需要实现自己的连接器,因为Kafka社区已经提供了数百个现成的连接器。
下一步是什么
- 要获得Kafka的实际操作经验,请关注快速入门。
- 要想更详细地了解Kafka,请阅读文档。您还可以选择Kafka书籍和学术论文。
- 浏览使用案例,了解全球社区的其他用户如何从Kafka中获得价值。
- 加入当地的Kafka meetup小组,观看Kafka社区的主要会议--Kafka Summit的演讲。
1.2使用案例
以下是对Apache Kafka的一些流行用例的描述。关于这些领域的概述,请看这篇博客文章。
讯息传递
Kafka可以很好地替代更传统的消息中介。消息broker的使用有多种原因(将处理与数据生产者解耦,缓冲未处理的消息等)。与大多数消息系统相比,Kafka具有更好的吞吐量、内置的分区、复制和容错能力,这使得它成为大规模消息处理应用的良好解决方案。
根据我们的经验,消息处理的用途往往是比较低的吞吐量,但可能需要较低的端到端延迟,并且往往依赖于Kafka提供的强大的耐久性保证。
在这个领域中,Kafka可以和传统的消息系统,如ActiveMQ或RabbitMQ相媲美。
网站活动跟踪
Kafka最初的用例是能够将用户活动跟踪管道重建为一组实时发布-订阅feeds。这意味着网站活动(页面浏览、搜索或用户可能采取的其他行动)被发布到中心主题,每个活动类型有一个主题。这些feed可供订阅,用于一系列用例,包括实时处理、实时监控以及加载到Hadoop或离线数据仓库系统中进行离线处理和报告。
活动跟踪通常是非常大的量,因为每个用户页面浏览都会产生许多活动消息。
衡量标准
Kafka经常用于运营监控数据。这涉及到从分布式应用中聚合统计数据,以产生集中的运营数据源。
日志聚合
许多人使用Kafka作为日志聚合解决方案的替代品。日志聚合通常会从服务器上收集物理日志文件,并将它们放在一个中心位置(可能是文件服务器或HDFS)进行处理。Kafka抽象掉了文件的细节,并将日志或事件数据抽象为一个更干净的消息流。这使得处理延迟更低,更容易支持多个数据源和分布式数据消费。与Scribe或Flume等以日志为中心的系统相比,Kafka同样具有良好的性能,由于复制而具有更强的耐久性保证,端到端延迟也低得多。
流处理
Kafka的许多用户在由多个阶段组成的处理管道中处理数据,原始输入数据从Kafka主题中消耗,然后聚合、丰富或以其他方式转化为新的主题,以便进一步消耗或后续处理。例如,用于推荐新闻文章的处理管道可能会从RSS订阅中抓取文章内容,并将其发布到 "文章 "主题中;进一步的处理可能会对这些内容进行归一化或重复数据化,并将清洗后的文章内容发布到新的主题中;最后的处理阶段可能会尝试向用户推荐这些内容。这样的处理流水线会根据各个主题创建实时数据流的图。从0.10.0.0开始,Apache Kafka中提供了一个轻量级但功能强大的流处理库Kafka Streams,用于执行上述此类数据处理。除了Kafka Streams,其他的开源流处理工具还包括Apache Storm和Apache Samza。
事件源
事件源是一种应用设计风格,其中状态变化被记录为一个时间顺序的记录序列。Kafka对非常大的存储日志数据的支持使其成为以这种风格构建的应用程序的优秀后端。
提交日志
Kafka可以作为分布式系统的一种外部提交日志。该日志有助于在节点之间复制数据,并作为失败节点的重新同步机制,以恢复其数据。Kafka中的日志压缩功能有助于支持这种用法。在这个用法上,Kafka类似于Apache BookKeeper项目。
1.3 快速开始
步骤一:获取kafka
下载最新的Kafka版本并解压。
$ tar -xzf kafka_2.13-2.7.0.tgz$ cd kafka_2.13-2.7.0
步骤二:启动kafka环境
注意:您的本地环境必须安装有 Java 8+。
运行以下命令,以便以正确的顺序启动所有服务。
# Start the ZooKeeper service# Note: Soon, ZooKeeper will no longer be required by Apache Kafka.$ bin/zookeeper-server-start.sh config/zookeeper.properties
打开另一个终端会话并运行。
# Start the Kafka broker service$ bin/kafka-server-start.sh config/server.properties
一旦所有服务成功启动,您将拥有一个基本的Kafka环境运行并准备使用。
步骤三:创建一个主题来存储你的事件
Kafka是一个分布式事件流平台,它可以让你在许多机器上读取、写入、存储和处理事件(在文档中也称为记录或消息)。
示例事件有支付交易、手机的地理位置更新、运输订单、物联网设备或医疗设备的传感器测量等等。这些事件被组织并存储在主题中。非常简化,一个主题类似于文件系统中的一个文件夹,而事件就是该文件夹中的文件。
所以在你写第一个事件之前,你必须创建一个topic。打开另一个终端会话并运行。
$ bin/kafka-topics.sh --create --topic quickstart-events --bootstrap-server localhost:9092
Kafka的所有命令行工具都有额外的选项:运行kafka-topics.sh命令,不需要任何参数就可以显示使用信息。例如,它还可以显示新主题的分区数等细节。
$ bin/kafka-topics.sh --describe --topic quickstart-events --bootstrap-server localhost:9092Topic:quickstart-events PartitionCount:1 ReplicationFactor:1 Configs:Topic: quickstart-events Partition: 0 Leader: 0 Replicas: 0 Isr: 0
步骤四:将一些事件写进主题里
Kafka客户端通过网络与Kafkabroker进行通信,以写入(或读取)事件。一旦接收到事件,brokers将以持久和容错的方式存储这些事件,只要你需要--甚至永远。
运行控制台生产者客户端,将一些事件写入你的主题中。默认情况下,你输入的每一行都会导致一个单独的事件被写入主题。
$ bin/kafka-console-producer.sh --topic quickstart-events --bootstrap-server localhost:9092This is my first eventThis is my second event
你可以在任何时候用Ctrl+C停止生产者客户端。
步骤五:读取事件
打开另一个终端会话,运行控制台消费者客户端来读取刚才创建的事件。
$ bin/kafka-console-consumer.sh --topic quickstart-events --from-beginning --bootstrap-server localhost:9092This is my first eventThis is my second event
你可以在任何时候用Ctrl+C停止消费者客户端。
随意试验一下:例如,切换回你的生产者终端(上一步)来写入额外的事件,看看这些事件是如何立即显示在你的消费者终端中的。
因为事件是持久存储在Kafka中的,所以它们可以被任意次数和任意数量的消费者读取。你可以通过打开另一个终端会话并再次重新运行上一条命令来轻松验证。
步骤六:使用KAFKA CONNECT将您的数据以事件流的形式导入/导出
你可能在现有的系统中拥有大量的数据,比如关系型数据库或传统的消息系统,以及许多已经使用这些系统的应用程序。Kafka Connect允许您将外部系统中的数据不断地摄入到Kafka中,反之亦然。因此,将现有系统与Kafka整合起来非常容易。为了使这一过程更加简单,有数百个这样的连接器随时可用。
看看Kafka连接部分,了解更多关于如何将你的数据连续导入/导出到Kafka中。
步骤七:使用KAFKA STREAMS处理您的事件
一旦您的数据以事件的形式存储在Kafka中,您就可以使用Java/Scala的Kafka Streams客户端库处理数据。它允许您实现任务关键型实时应用程序和微服务,其中输入和/或输出数据存储在Kafka主题中。Kafka Streams将在客户端编写和部署标准Java和Scala应用程序的简单性与Kafka服务器端集群技术的优势相结合,使这些应用程序具有高度的可扩展性、弹性、容错性和分布式。该库支持精确的一次性处理、有状态的操作和聚合、窗口化、连接、基于事件时间的处理等。
为了让大家先体验一下,下面是如何实现流行的WordCount算法。
KStream<String, String> textLines = builder.stream("quickstart-events");KTable<String, Long> wordCounts = textLines.flatMapValues(line -> Arrays.asList(line.toLowerCase().split(" "))).groupBy((keyIgnored, word) -> word).count();wordCounts.toStream().to("output-topic"), Produced.with(Serdes.String(), Serdes.Long()));
Kafka Streams演示和应用开发教程演示了如何从头到尾地编码和运行这样一个流媒体应用。
步骤八:终止kafka运行环境
现在你已经到达了快速入门的终点,可以随意拆掉Kafka环境--或者继续玩。
- 用Ctrl-C停止生产者和消费者客户端,如果你还没有这样做。
- 用Ctrl-C停止Kafka broker。
- 最后,用Ctrl-C停止ZooKeeper服务器。
如果你还想删除你本地Kafka环境的任何数据,包括你一路创建的任何事件,运行下列命令:
$ rm -rf /tmp/kafka-logs /tmp/zookeeper
祝贺!
您已经成功完成了Apache Kafka快速入门。
要了解更多信息,我们建议采取以下步骤。
- 阅读简短的介绍,了解Kafka如何在高层次上工作,它的主要概念,以及它与其他技术的比较。要了解Kafka的更多细节,请前往文档。
- 浏览使用案例,了解全球社区的其他用户如何从Kafka中获得价值。
- 加入当地的Kafka meetup小组,观看Kafka社区的主要会议--Kafka Summit的演讲。
1.4 生态系统
在主发行版之外,有大量的工具与Kafka集成。生态系统页面列出了其中的许多工具,包括流处理系统、Hadoop集成、监控和部署工具。
1.5 从旧版本升级
从0.8.x到2.6.x的任何版本升级到2.7.0
如果您要从 2.1.x 之前的版本升级,请查看下面关于用于存储消费者偏移量的模式变化的说明。一旦您将 inter.broker.protocol.version 更改为最新版本,将无法降级到 2.1 之前的版本。
如何平滑升级:
- 更新所有broker的server.properties,并添加以下属性。CURRENT_KAFKA_VERSION 指的是您要升级的版本。CURRENT_MESSAGE_FORMAT_VERSION 指的是当前使用的消息格式版本。如果您之前已经覆盖了消息格式版本,您应该保留它的当前值。另外,如果您从 0.11.0.x 之前的版本升级,那么 CURRENT_MESSAGE_FORMAT_VERSION 应该设置为与 CURRENT_KAFKA_VERSION 匹配。
- inter.broker.protocol.version=CURRENT_KAFKA_VERSION (例如,2.6、2.5等)
- log.message.format.version=CURRENT_MESSAGE_FORMAT_VERSION (关于这个配置的详细作用,请看升级后对性能的潜在影响。)
如果你是从0.11.0.x或更高版本升级的,并且你没有覆盖消息格式,那么你只需要覆盖inter-broker协议版本。 - inter.broker.protocol.version=CURRENT_KAFKA_VERSION(如2.6、2.5等)。
- 一次升级一个broker:关闭broker,更新代码,然后重新启动它。一旦你这样做了,broker将运行最新的版本,你可以验证集群的行为和性能是否符合预期。如果有任何问题,此时仍然可以降级。
- 一旦集群的行为和性能得到验证,通过编辑inter.broker.protocol.version并将其设置为2.7来提升协议版本。
- 逐个重启broker,让新协议版本生效。一旦brokers开始使用最新的协议版本,将不再可能将群集降级到旧版本。
- 如果你已经按照上面的指示覆盖了消息格式版本,那么你需要再做一次滚动重启,将其升级到最新版本。一旦所有(或大多数)消费者都升级到0.11.0或更高版本,在每个broker上将log.message.format.version改为2.7,然后逐个重启它们。需要注意的是,不再维护的旧版Scala客户端不支持0.11中引入的消息格式,因此为了避免转换成本(或利用精确的一次语义),必须使用较新的Java客户端。
2.7.0中的显著变化
- 2.7.0版本包括KIP-595中规定的核心Raft实现。有一个单独的 "Raft "模块,包含大部分的逻辑。在与控制器的集成完成之前,有一个独立的服务器,用户可以用来测试Raft实现的性能。详细内容请参见 raft 模块中的 README.md。
- KIP-651 增加了对使用 PEM 文件作为密钥和信任存储的支持。
- KIP-612 增加了对执行整个代理和每个监听器连接创建率的支持。2.7.0 版本包含 KIP-612 的第一部分,动态配置将在 2.8.0 版本中推出。
- 通过KIP-599,能够节制主题和分区的创建或主题的删除,以防止集群受到伤害。
- 当Kafka中出现新功能时,主要有两个问题。
- Kafka客户如何知道broker的功能?
- broker如何决定启用哪些功能?
- KIP-584提供了一个灵活且易于操作的解决方案,用于客户端发现、功能门控和使用一次重启进行滚动升级。
- 通过KIP-431,现在可以通过ConsoleConsumer打印记录偏移量和头文件的能力。
- KIP-554的加入,继续朝着从Kafka中移除Zookeeper的目标前进。KIP-554的加入意味着你不必再直接连接到ZooKeeper来管理SCRAM凭证。
- 改变存在的监听器的不可重新配置的配置会导致InvalidRequestException。相比之下,之前(非预期)的行为会导致更新的配置被持久化,但直到broker被重新启动才会生效。更多讨论请参见KAFKA-10479。请参阅DynamicBrokerConfig.DynamicSecurityConfigs和SocketServer.ListenerReconfigurableConfigs,了解存在的监听器的支持的可重新配置。
- Kafka Streams在KStreams DSL中增加了对Sliding Windows Aggregations的支持。
- 在状态存储上进行反向迭代,使KIP-617的最近更新搜索更加高效。
- Kafka Steams中的端到端延迟指标,详见KIP-613。
- Kafka Streams增加了用KIP-607报告默认RocksDB属性的指标。
- KIP-616提供更好的Scala隐式Serdes支持。
2. APIS
Kafka包括五个核心API。
- 生产者API允许应用程序向Kafka集群中的主题发送数据流。
- Consumer API允许应用程序从Kafka集群中的主题读取数据流。
- Streams API允许将数据流从输入主题转换为输出主题。
- 连接API允许实现连接器,不断地从一些源系统或应用拉入Kafka,或从Kafka推入一些汇系统或应用。
- 管理API允许管理和检查主题、broker和其他Kafka对象。
Kafka通过一个独立于语言的协议公开其所有功能,该协议有许多编程语言的客户端。然而,只有Java客户端是作为Kafka主项目的一部分来维护的,其他的客户端是作为独立的开源项目来提供的。非Java客户端的列表可以在这里找到。
2.1 生产者API
Producer API允许应用程序向Kafka集群中的主题发送数据流。
javadocs中给出了如何使用producer的例子。
要使用producer,你可以使用以下maven依赖。
<dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId><version>2.7.0</version></dependency>
2.2 消费者API
消费者API允许应用程序从Kafka集群中的主题读取数据流。
javadocs中给出了如何使用消费者的例子。
要使用消费者,你可以使用以下maven依赖。
<dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId><version>2.7.0</version></dependency>
2.3 流API
Streams API允许将数据流从输入主题转换为输出主题。
在javadocs中给出了如何使用这个库的例子。
关于使用Streams API的其他文档在这里。
要使用Kafka Streams,你可以使用以下maven依赖。
<dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-streams</artifactId><version>2.7.0</version></dependency>
当使用Scala时,你可以选择包含kafka-streams-scala库。关于使用Kafka Streams DSL for Scala的其他文档请参见开发者指南。
要使用Kafka Streams DSL for Scala for Scala 2.13,你可以使用以下maven依赖。
<dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-streams-scala_2.13</artifactId><version>2.7.0</version></dependency>
2.4 连接API
Connect API允许实现连接器,不断地从一些源数据系统拉入Kafka,或者从Kafka推送到一些汇数据系统。
很多Connect的用户不需要直接使用这个API,不过,他们可以使用预建的连接器,而不需要编写任何代码。关于使用Connect的其他信息可以在这里获得。
想要实现自定义连接器的用户可以查看javadoc。
2.5 管理API
管理API支持管理和检查主题、broker、acls和其他Kafka对象。
要使用Admin API,请添加以下Maven依赖关系。
<dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId><version>2.7.0</version></dependency>
有关Admin APIs的更多信息,请参阅javadoc。
3. 配置
Kafka使用属性文件格式的键值对进行配置。这些值可以从文件或程序上提供。
3.1 broker配置
基本配置如下。
- broker.id
- log.dirs
- zookeeper.connect
下面将详细讨论主题级配置和默认值。
zookeeper.connect
以 hostname:port 的形式指定 ZooKeeper 连接字符串,其中 host 和 port 是 ZooKeeper 服务器的主机和端口。为了允许在该ZooKeeper机器宕机时通过其他ZooKeeper节点进行连接,你也可以以hostname1:port1,hostname2:port2,hostname3:port3的形式指定多个主机。
服务器也可以有一个ZooKeeper chroot路径作为其ZooKeeper连接字符串的一部分,它将其数据放在全局ZooKeeper命名空间的某个路径下。例如,给chroot路径为/chroot/path,你可以给连接字符串为hostname1:port1,hostname2:port2,hostname3:port3/chroot/path。类型:字符串
默认值:
有效值:
重要性:高
更新模式:只读
advertised.host.name
已经废弃:只有在没有设置advertised.listeners或listeners时才使用。请使用advertised.listeners代替。
发布到ZooKeeper的主机名,供客户端使用。在IaaS环境中,这可能需要与broker绑定的接口不同。如果没有设置,它将使用host.name的值,如果配置。否则,它将使用从 java.net.InetAddress.getCanonicalHostName()返回的值。类型:字符串
默认值: null
有效值:
重要性:高
更新模式:只读
advertised.listeners
监听器发布到ZooKeeper供客户端使用,如果与监听器配置属性不同。在IaaS环境中,这可能需要与broker绑定的接口不同。如果没有设置这个,将使用监听器的值。与监听器不同,宣传0.0.0.0元地址是无效的。
同样与监听器不同的是,在这个属性中可以有重复的端口,这样一个监听器可以被配置为宣传另一个监听器的地址。这在某些使用外部负载均衡器的情况下很有用。类型:字符串
默认值: null
有效值:
重要性:高
更新模式:每个broker
advertised.port
已经废弃:只有在没有设置advertised.listeners或listeners时才使用。请使用advertised.listeners代替。
发布到ZooKeeper供客户端使用的端口。在IaaS环境中,这可能需要与broker绑定的端口不同。如果没有设置,它将发布与broker绑定的相同端口。类型:int
默认值: null
有效值:
重要性:高
更新模式:只读
auto.create.topics.enable
启用自动创建服务器上的主题类型: 布尔型
默认:true
有效值:
重要性:高
更新模式:只读
auto.leader.rebalance.enable
启用自动领导平衡。后台线程定期检查分区领导的分布情况,可由`leader.imbalance.check.interval.seconds`配置。如果leader.imbalance.per.broker.百分比超过`leader.imbalance.per.broker.百分比`,则会触发对分区的首选leader重新平衡。
类型:布尔值
默认:true
有效值:
重要性:高
更新模式:只读
background.threads
用于各种后台处理任务的线程数。
类型:int
默认值:10
有效值:[1,...]
重要性:高
更新模式:全集群
broker.id
这个服务器的broker id,如果没有设置,将生成一个唯一的broker id。为了避免zookeeper生成的broker id和用户配置的broker id之间的冲突,生成的broker id从 reserved.broker.max.id + 1 开始。
类型:int
默认值:-1
有效值:
重要性:高
更新模式:只读
compression.type
指定给定主题的最终压缩类型。此配置接受标准的压缩编解码器('gzip'、'snappy'、'lz4'、'zstd')。此外,它还接受'uncompressed',这相当于没有压缩;以及'producer',这意味着保留制作者设置的原始压缩编解码器。
类型:字符串
默认:生产者
有效值:
重要性:高
更新模式:全集群
control.plane.listener.name
用于控制器和broker之间通信的监听器的名称。broker将使用control.plane.listener.name来定位监听器列表中的端点,以监听来自控制器的连接。例如,如果一个broker的配置是.plane.listener.name。
listeners = INTERNAL://192.1.1.8:9092, EXTERNAL://10.1.1.5:9093, CONTROLLER://192.1.1.8:9094。
listener.security.protocol.map = INTERNAL:PLAINTEXT, EXTERNAL:SSL, CONTROLLER:SSL。
control.plane.listener.name = CONTROLLER
在启动时,broker将开始监听 "192.1.1.8:9094",安全协议为 "SSL"。
在控制器端,当它通过zookeeper发现一个broker发布的端点时,它会使用control.plane.listener.name来找到端点,然后用它来建立与broker的连接。
例如,如果broker在zookeeper上发布的端点是...。
"endpoints" : ["INTERNAL://broker1.example.com:9092", "EXTERNAL://broker1.example.com:9093", "CONTROLLER://broker1.example.com:9094"] 。
而控制器的配置是 。
listener.security.protocol.map = INTERNAL:PLAINTEXT, EXTERNAL:SSL, CONTROLLER:SSL。
control.plane.listener.name = CONTROLLER
那么控制器将使用 "broker1.example.com:9094 "和安全协议 "SSL "来连接到代理。
如果没有明确配置,默认值为空,控制器连接将没有专用端点。
类型:字符串
默认值: null
有效值:
重要性:高
更新模式:只读
delete.topic.enable
启用删除主题。如果关闭此配置,通过管理工具删除主题将没有效果。
类型: 布尔型
默认:true
有效值:
重要性:高
更新模式:只读
host.name
已经过期:只有在没有设置监听器时才使用。使用 listeners 代替。
broker的主机名。如果设置了这个,它将只绑定到这个地址。如果没有设置,则会绑定到所有接口。
类型:字符串
默认:""
有效值:
重要性:高
更新模式:只读
leader.imbalance.check.interval.seconds
控制器触发分区再平衡检查的频率。
类型:长
默认值:300
有效值:
重要性:高
更新模式:只读
leader.imbalance.per.broker.percentage
每个broker允许的领导者不平衡的比率。如果每个broker超过这个值,控制器将触发一个领导者平衡。该值以百分比指定。
类型:int
默认值:10
有效值:
重要性:高
更新模式:只读
listeners
Listener List - 我们将监听的URI和监听者名称的逗号分隔的列表,如果监听者名称不是安全协议,还必须设置listener.security.protocol.map。如果监听器名称不是安全协议,还必须设置listener.security.protocol.map。
监听器名称和端口号必须是唯一的。
将hostname指定为0.0.0.0,绑定到所有接口。
将hostname留空以绑定到默认接口。
合法监听器列表的例子。
PLAINTEXT://myhost:9092,SSL://:9091
CLIENT://0.0.0.0:9092,REPLICATION://localhost:9093。
类型:字符串
默认值: null
有效值:
重要性:高
更新模式:每个broker
log.dir
保存日志数据的目录(log.dirs属性的补充)。
类型:字符串
默认值:/tmp/kafka-logs。
有效值:
重要性:高
更新模式:只读
log.dirs
保存日志数据的目录。如果没有设置,则使用log.dir中的值。
类型:字符串
默认值: null
有效值:
重要性:高
更新模式:只读
log.flush.interval.messages
在将消息刷新到磁盘之前,日志分区上累积的消息数量。
类型:长
默认:9223372036854775807。
有效值:[1,...]
重要性:高
更新模式:全集群
log.flush.interval.ms
任何主题中的消息在刷新到磁盘之前在内存中保存的最大时间,单位为ms。如果没有设置,则使用log.flush.schedule.interval.ms中的值。
类型:长
默认值: null
有效值:
重要性:高
更新模式:全集群
log.flush.offset.checkpoint.interval.ms
我们更新作为日志恢复点的最后一次刷新的持久性记录的频率。
类型:int
默认:60000(1分钟)
有效值:[0,...]
重要性:高
更新模式:只读
log.flush.scheduler.interval.ms
日志刷新器检查是否需要将日志刷新到磁盘上的频率,单位为ms。
类型:长
默认:9223372036854775807。
有效值:
重要性:高
更新模式:只读
log.flush.start.offset.checkpoint.interval.ms
更新日志起始偏移量的持久性记录的频率。
类型:int
默认:60000(1分钟
有效值:[0,...]
重要性:高
更新模式:只读
log.retention.bytes
删除前日志的最大尺寸
类型:长
默认值:-1
有效值:
重要性:高
更新模式:全集群
log.retention.hours
在删除日志文件之前保留日志文件的小时数(小时),三级为log.retaining.ms属性。
类型:int
默认值:168
有效值:
重要性:高
更新模式:只读
log.retention.minutes
删除日志文件前保留日志文件的分钟数(以分钟为单位),次于log.retain.ms属性。如果没有设置,则使用 log.retaining.hours 属性中的值。
类型:int
默认值: null
有效值:
重要性:高
更新模式:只读
log.retention.ms
删除日志文件前保留日志文件的毫秒数(单位:毫秒),如果没有设置,则使用log.retention.minutes中的值。如果设置为-1,则没有时间限制。
类型:长
默认值: null
有效值:
重要性:高
更新模式:全集群
log.roll.hours
新日志段推出前的最长时间(小时),次要为log.roll.ms属性。
类型:int
默认值:168
有效值:[1,...]
重要性:高
更新模式:只读
log.roll.jitter.hours
从logRollTimeMillis(小时)中减去的最大抖动,次要用于log.roll.jitter.ms属性。
类型:int
默认值:0
有效值:[0,...]
重要性:高
更新模式:只读
log.roll.jitter.ms
从logRollTimeMillis(毫秒)中减去的最大抖动。如果没有设置,则使用log.roll.jitter.hours中的值。
类型:长
默认值: null
有效值:
重要性:高
更新模式:全集群
log.roll.ms
新日志段推出前的最长时间(毫秒)。如果没有设置,则使用log.roll.hours中的值。
类型:长
默认值: null
有效值:
重要性:高
更新模式:全集群
log.segment.bytes
单个日志文件的最大大小
类型:int
默认值:1073741824 (1 gibibyte)
有效值: [14,...]
重要性:高
更新模式:全集群
log.segment.delete.delay.ms
从文件系统中删除文件前等待的时间。
类型:长
默认:60000(1分钟
有效值:[0,...]
重要性:高
更新模式:全集群
message.max.bytes
Kafka允许的最大记录批次大小(如果启用压缩,则压缩后)。如果增加这个大小,并且有比0.10.2更老的消费者,消费者的取数大小也必须增加,这样才能取到这么大的记录批。在最新的消息格式版本中,为了提高效率,记录总是被分组成批。在以前的消息格式版本中,未压缩的记录不会被分组成批,在这种情况下,这个限制只适用于单条记录。这可以通过主题级别的max.message.bytes config来设置每个主题。
类型:int
默认值:1048588
有效值:[0,...]
重要性:高
更新模式:全集群
min.insync.replicas
当生产者将acks设置为 "all"(或"-1")时,min.insync.replicas指定了必须确认写入才算成功的最小复制数。如果不能满足这个最小数量,那么生产者将引发一个异常(NotEnoughReplicas或NotEnoughReplicasAfterAppend)。
当一起使用时,min.insync.replicas和acks允许你实施更大的耐久性保证。一个典型的场景是创建一个复制因子为3的主题,将min.insync.replicas设置为2,并以 "all "的acks进行生产。这将确保生产者在大多数副本没有收到写入时引发异常。
类型:int
默认值:1
有效值:[1,...]
重要性:高
更新模式:全集群
num.io.threads
服务器用于处理请求的线程数,其中可能包括磁盘I/O。
类型:int
默认值:8
有效值:[1,...]
重要性:高
更新模式:全集群
num.network.threads
服务器用于接收来自网络的请求并向网络发送响应的线程数。
类型:int
默认值:3
有效值:[1,...]
重要性:高
更新模式:全集群
num.recovery.threads.per.dir。
每个数据目录的线程数,用于启动时的日志恢复和关闭时的刷新。
类型:int
默认值:1
有效值:[1,...]
重要性:高
更新模式:全集群
num.replica.alter.log.dirs.threads。
可以在日志目录之间移动复制的线程数量,其中可能包括磁盘I/O。
类型:int
默认值: null
有效值:
重要性:高
更新模式:只读
num.replica.fetchers
用于从源broker复制消息的fetcher线程数量。增加这个值可以增加follower broker的I/O并行度。
类型:int
默认值:1
有效值:
重要性:高
更新模式:全集群
offset.metadata.max.bytes.
与偏移提交相关联的元数据条目的最大尺寸。
类型:int
默认值:4096(4 kibibytes)
有效值:
重要性:高
更新模式:只读
offsets.commit.required.acks
接受提交前所需的acks。一般来说,默认值(-1)不应该被覆盖。
类型:短
默认值:-1
有效值:
重要性:高
更新模式:只读
offsets.commit.timeout.ms
偏移提交将被延迟,直到主题的所有副本收到提交或达到这个超时。
偏移提交将被延迟,直到偏移主题的所有副本收到提交或达到这个超时。这与生产者请求超时类似。
类型:int
默认:5000(5秒
有效值:[1,...]
重要性:高
更新模式:只读
offsets.load.buffer.size
当把偏移量加载到缓存中时,从偏移量段读取的批次大小(软限制,如果记录太大,则重写)。
类型:int
默认:5242880
有效值:[1,...]
重要性:高
更新模式:只读
offsets.retention.check.interval.ms
检查过期偏移量的频率
类型:长
默认:600000(10分钟)。
有效值:[1,...]
重要性:高
更新模式:只读
offsets.retention.minutes
当一个消费者组失去所有消费者(即变成空的)后,它的偏移量将在这个保留期内保留,然后被丢弃。对于独立的消费者(使用手动分配),偏移量将在最后一次提交时间加上这个保留期后过期。
类型:int
默认值:10080
有效值:[1,...]
重要性:高
更新模式:只读
offsets.topic.compression.codec
偏移主题的压缩编解码器--压缩可用于实现 "原子 "提交。
类型:int
默认值:0
有效值:
重要性:高
更新模式:只读
offsets.topic.num.partitions
偏移提交主题的分区数(部署后不应改变)。
类型:int
默认值:50
有效值:[1,...]
重要性:高
更新模式:只读
offsets.topic.replication.factor
偏移主题的复制因子(设置更高以确保可用性)。内部主题创建将失败,直到集群大小满足此复制因子要求。
类型:短
默认值:3
有效值:[1,...]
重要性:高
更新模式:只读
offsets.topic.segment.bytes
偏移主题段的字节数应保持相对较小,以利于加快日志压缩和缓存加载速度
类型:int
默认值:104857600(100 mebibytes)。
有效值:[1,...]
重要性:高
更新模式:只读
port
删除:只有在没有设置监听器时才使用。请使用监听器代替。
监听和接受连接的端口。
类型:int
默认值:9092
有效值:
重要性:高
更新模式:只读
queued.max.requests
在阻塞网络线程之前,允许数据层排队请求的数量。
类型:int
默认值:500
有效值:[1,...]
重要性:高
更新模式:只读
quota.consumer.default
已取消。仅在Zookeeper没有配置动态默认配额时使用。任何以clientId/consumer group区分的消费者,如果每秒获取的字节数超过这个值,就会被节流。
类型:长
默认:9223372036854775807。
有效值:[1,...]
重要性:高
更新模式:只读
quota.producer.default
已取消。仅在没有配置动态默认配额时使用,或者在Zookeeper中使用。任何以clientId区分的生产者如果每秒产生的字节数超过这个值,就会被节流。
类型:长
默认:9223372036854775807。
有效值:[1,...]
重要性:高
更新模式:只读
replica.fetch.min.bytes
每个获取响应的最小字节数。如果字节数不够,则等待时间最多为 replica.fetch.wait.max.ms (broker 配置)。
类型:int
默认值:1
有效值:
重要性:高
更新模式:只读
replica.fetch.wait.max.ms
追随者副本发出的每个取数请求的最大等待时间。该值在任何时候都应始终小于 replica.lag.time.max.ms,以防止低吞吐量主题的 ISR 频繁缩减。
类型:int
默认值:500
有效值:
重要性:高
更新模式:只读
replica.high.watermark.checkpoint.interval.ms
高水印保存到磁盘的频率。
类型:长
默认:5000(5秒)
有效值:
重要性:高
更新模式:只读
replica.lag.time.max.ms
如果一个跟随者至少在这段时间内没有发送任何fetch请求,或者没有消耗到领导者的日志结束偏移量,领导者将把这个跟随者从isr
类型:长
默认:30000(30秒)
有效值:
重要性:高
更新模式:只读
replica.socket.receive.buffer.bytes
网络请求的套接字接收缓冲区
类型:int
默认值:65536(64 kibibytes)。
有效值:
重要性:高
更新模式:只读
replica.socket.timeout.ms
网络请求的套接字超时时间,其值应至少为 replica.fetch.wait.max.ms。它的值至少应该是 replica.fetch.wait.max.ms。
类型:int
默认:30000(30秒)
有效值:
重要性:高
更新模式:只读
request.timeout.ms
该配置控制客户端等待请求响应的最长时间。如果在超时之前没有收到响应,客户端将在必要时重新发送请求,或者在重试次数耗尽时失败。
类型:int
默认:30000(30秒)
有效值:
重要性:高
更新模式:只读
socket.receive.buffer.bytes
socket服务器套接字的SO_RCVBUF缓冲区。如果值为-1,则使用OS默认值。
类型:int
默认值:102400 (100 kibibytes)
有效值:
重要性:高
更新模式:只读
socket.request.max.bytes
套接字请求的最大字节数。
类型:int
默认值:104857600(100 mebibytes)。
有效值:[1,...]
重要性:高
更新模式:只读
socket.send.buffer.bytes
socket服务器套接字的SO_SNDBUF缓冲区。如果值为-1,则使用OS默认值。
类型:int
默认值:102400 (100 kibibytes)
有效值:
重要性:高
更新模式:只读
transaction.max.timeout.ms
交易的最大允许超时时间。如果客户端请求的交易时间超过了这个时间,那么broker将在InitProducerIdRequest中返回一个错误。这可以防止客户端的超时时间过大,从而拖延消费者从交易中包含的主题中读取。
类型:int
默认:900000(15分钟)
有效值:[1,...]
重要性:高
更新模式:只读
transaction.state.log.load.buffer.size
当把生产者id和交易加载到缓存中时,从交易日志段读取的批次大小(软限制,如果记录太大,则重写)。
类型:int
默认:5242880
有效值:[1,...]
重要性:高
更新模式:只读
transaction.state.log.min.isr
重写事务主题的min.insync.replicas配置。
类型:int
默认值:2
有效值:[1,...]
重要性:高
更新模式:只读
transaction.state.log.num.partitions
事务主题的分区数(部署后不应改变)。
类型:int
默认值:50
有效值:[1,...]
重要性:高
更新模式:只读
transaction.state.log.replication.factor
事务主题的复制因子(设置较高以确保可用性)。内部主题创建将失败,直到集群大小满足此复制因子要求。
类型:短
默认值:3
有效值:[1,...]
重要性:高
更新模式:只读
transaction.state.log.segment.bytes
事务主题段的字节数应保持相对较小,以利于加快日志压缩和缓存加载速度
类型:int
默认值:104857600(100 mebibytes)。
有效值:[1,...]
重要性:高
更新模式:只读
transactional.id.expiration.ms
事务协调器在没有收到当前事务的任何事务状态更新的情况下,在其事务id过期前等待的时间,单位为ms。这个设置也会影响生产者id过期--一旦这个时间在给定的生产者id最后一次写入后过去,生产者id就会过期。请注意,如果由于主题的保留设置,生产者id的最后一次写入被删除,那么生产者id可能会过期更早。
类型:int
默认:604800000(7天)
有效值:[1,...]
重要性:高
更新模式:只读
zookeeper.connection.timeout.ms
客户端等待与zookeeper建立连接的最大时间。如果没有设置,将使用zookeeper.session.timeout.ms中的值。
类型:int
默认值: null
有效值:
重要性:高
更新模式:只读
zookeeper.max.in.flight.requests
在阻止之前,客户端向Zookeeper发送的最大未确认请求数。
类型:int
默认值:10
有效值:[1,...]
重要性:高
更新模式:只读
zookeeper.session.timeout.ms
Zookeeper会话超时
类型:int
默认:18000(18秒)
有效值:
重要性:高
更新模式:只读
zookeeper.set.acl
设置客户端使用安全ACL
类型: 布尔型
默认:假
有效值:
重要性:高
更新模式:只读
broker.id.generation.enable
启用自动生成服务器上的broker id。当启用时,预留.broker.max.id的配置值应该被审查。
类型:布尔值
默认:true
有效值:
重要性:中等
更新模式:只读
broker.rack
broker的机架。这将用于机架感知复制分配,以实现容错。例子:"RACK1"、"us-east-1d"。`RACK1`,`us-east-1d`。
类型:字符串
默认值: null
有效值:
重要性:中等
更新模式:只读
connections.max.idle.ms
闲置连接超时:服务器套接字处理器线程关闭闲置时间超过这个时间的连接。
类型:长
默认:600000(10分钟)
有效值:
重要性:中等
更新模式:只读
connections.max.reauth.ms
当明确设置为正数时(默认为0,不是正数),当v2.2.0或更高版本的客户端进行身份验证时,将向他们传达一个不超过配置值的会话寿命。broker将断开任何没有在会话寿命内重新认证的连接,然后将其用于重新认证以外的任何目的。配置名称可以选择用监听器前缀和SASL机制名称的小写字母作为前缀。例如,listener.name.sasl_ssl.oauthbearer.connection.max.reauth.ms=3600000。
类型:长
默认值:0
有效值:
重要性:中等
更新模式:只读
controlled.shutdown.enable
启用受控关闭服务器
类型: 布尔型
默认:true
有效值:
重要性:中等
更新模式:只读
controlled.shutdown.max.retries
受控关机可能因多种原因而失败。这就决定了发生这种故障时的重试次数。
类型:int
默认值:3
有效值:
重要性:中等
更新模式:只读
controlled.shutdown.retry.backoff.ms
在每次重试之前,系统需要时间从导致上一次故障的状态中恢复过来(控制器失效,复制滞后等)。这个配置决定了重试前的等待时间。
类型:长
默认:5000(5秒)
有效值:
重要性:中等
更新模式:只读
controller.socket.timeout.ms
控制器到中间商通道的套接字超时时间。
类型:int
默认:30000(30秒)
有效值:
重要性:中等
更新模式:只读
default.replication.factor
自动创建主题的默认复制因子类型:int
默认值:1
有效值:
重要性:中等
更新模式:只读
delegation.token.expiry.time.ms
需要更新令牌前的有效时间,以毫秒为单位。默认值为1天。类型:长
默认:86400000(1天)
有效值:[1,...]
重要性:中等
更新模式:只读
delegation.token.master.key
用于生成和验证授权令牌的主/秘钥。必须在所有的broker中配置相同的密钥。如果没有设置密钥或将密钥设置为空字符串,则broker将禁用授权令牌支持。类型:密码
默认值: null
有效值:
重要性:中等
更新模式:只读
delegation.token.max.lifetime.ms
令牌有最大的使用期限,超过期限就不能再更新。默认值为7天。类型:长
默认:604800000(7天)
有效值:[1,...]
重要性:中等
更新模式:只读
delete.records.purgatory.purge.interval.requests
删除记录请求清理区的清理间隔(以请求次数为单位)类型:int
默认值:1
有效值:
重要性:中等
更新模式:只读
fetch.max.bytes
我们将为一个获取请求返回的最大字节数。必须至少为1024。类型:int
默认值:57671680 (55 mebibytes)
有效值: [1024,...]
重要性:中等
更新模式:只读
fetch.purgatory.purge.interval.requests
获取请求净化器的清理间隔(以请求数为单位)。类型:int
默认:1000
有效值:
重要性:中等
更新模式:只读
group.initial.rebalance.delay.ms
在执行第一次重新平衡之前,组协调员将等待更多消费者加入新组的时间。较长的延迟意味着可能会减少再平衡,但会增加处理开始前的时间。类型:int
默认:3000(3秒)
有效值:
重要性:中等
更新模式:只读
group.max.session.timeout.ms
注册消费者的最大允许会话超时。较长的超时让消费者有更多的时间来处理心跳之间的消息,但代价是需要更长的时间来检测故障。类型:int
默认:1800000(30分钟)
有效值:
重要性:中等
更新模式:只读
group.max.size
单个消费者群体可容纳的最大消费者数量。类型:int
默认:2147483647
有效值:[1,...]
重要性:中等
更新模式:只读
group.min.session.timeout.ms
注册消费者的最小允许会话超时。较短的超时会导致更快的故障检测,但代价是更频繁的消费者心跳,这会使broker资源不堪重负。类型:int
默认:6000(6秒)
有效值:
重要性:中等
更新模式:只读
inter.broker.listener.name
用于broker之间通信的监听器的名称。如果未设置,则监听器名称由 security.inter.broker.protocol 定义。同时设置此属性和 security.inter.broker.protocol 属性是错误的。类型:字符串
默认值: null
有效值:
重要性:中等
更新模式:只读
inter.broker.protocol.version
指定将使用哪个版本的broker间协议。
这通常是在所有broker升级到新版本后进行的。
一些有效值的例子是 0.8.0, 0.8.1, 0.8.1.1, 0.8.2, 0.8.2.0, 0.8.2.1, 0.9.0.0, 0.9.0.1 查看ApiVersion的完整列表。类型:字符串
默认:2.7-IV2
有效值。 [0.8.0、0.8.1、0.8.2、0.9.0、0.10.0-IV0、0.10.0-IV1、0.10.1-IV0、0.10.1-IV1、0.10.1-IV2、0.10.2-IV0、0.11.0-IV0、0.11.0-IV1、0.11.0-IV2、1.0-IV0、1. 1-IV0、2.0-IV0、2.0-IV1、2.1-IV0、2.1-IV1、2.1-IV2、2.2-IV0、2.2-IV1、2.3-IV0、2.3-IV1、2.4-IV0、2.4-IV1、2.5-IV0、2.6-IV0、2.7-IV0、2.7-IV1、2.7-IV2]
重要性:中等
更新模式:只读
log.cleaner.backoff.ms
当没有日志需要清理时的睡眠时间。类型:长
默认:15000(15秒
有效值:[0,...]
重要性:中等
更新模式:全集群
log.cleaner.dedupe.buffer.size
所有清理线程中用于日志重复数据删除的总内存。类型:长
默认:134217728
有效:
重要性:中等
更新模式:全集群
log.cleaner.delete.retention.ms
删除记录保留多长时间?类型:长
默认:86400000(1天)。
有效值。
重要性:中等
更新模式:全集群
log.cleaner.enable
启用服务器上运行的日志清理程序。如果使用任何带有cleanup.policy=compact的主题,包括内部偏移主题,则应启用。如果禁用,这些主题将不会被压缩,并会持续增长。类型:布尔值
默认:true
有效值。
重要性:中等
更新模式:只读
log.cleaner.io.buffer.load.factor
日志清理器重复数据删除缓冲区的负载系数。重复数据缓冲区满的百分比。较高的值将允许一次清理更多的日志,但会导致更多的哈希碰撞。类型:双人
默认值:0.9
有效值。
重要性:中等
更新模式:全集群
log.cleaner.io.buffer.size
所有清理线程的日志清理I/O缓冲区所使用的总内存。类型:int
默认值:524288
有效值:[0,...]
重要性:中等
更新模式:全集群
log.cleaner.io.max.bytes.per.second
日志清理器将被节流,使其读写i/o之和平均小于此值。类型:双人
Default: 1.7976931348623157E308
有效值。
重要性:中等
更新模式:全集群
log.cleaner.max.compaction.lag.ms
消息在日志中不符合压实条件的最长时间。仅适用于正在压缩的日志。类型:长
默认:9223372036854775807。
有效值。
重要性:中等
更新模式:全集群
log.cleaner.min.cleanable.ratio
有资格进行清理的日志的脏日志与总日志的最小比率。如果还指定了 log.cleaner.max.compaction.lag.ms 或 log.cleaner.min.compaction.lag.ms 配置,则日志压缩器会在以下任一情况下立即认为该日志符合压缩条件。(i) 达到 dirty ratio 阈值,并且日志至少在 log.cleaner.min.compaction.lag.ms 持续时间内有 dirty(未压实)记录,或 (ii) 如果日志至少在 log.cleaner.max.compaction.lag.ms 期间有 dirty(未压实)记录,则日志压实器认为该日志符合压实条件。类型:双
默认值:0.5
有效值。
重要性:中等
更新模式:全集群
log.cleaner.min.compaction.lag.ms
消息在日志中未被压缩的最少时间。仅适用于正在压缩的日志。类型:长
默认值:0
有效值。
重要性:中等
更新模式:全集群
log.cleaner.threads
用于清理日志的后台线程数。类型:int
默认值:1
有效值:[0,...]
重要性:中等
更新模式:全集群
log.cleanup.policy
超出保留窗口的片段的默认清理策略。逗号分隔的有效策略列表。有效的策略是:"删除 "和 "压缩"。"删除 "和 "压缩"
类型:list
默认:delete
有效值。 [compact, delete]
重要性:中等
更新模式:全集群
log.index.interval.bytes
我们在偏移指数中添加条目的时间间隔。
类型:int
默认值:4096(4 kibibytes)
有效值:[0,...]
重要性:中等
更新模式:全集群
log.index.size.max.bytes
偏移索引的最大大小,以字节为单位。类型:int
默认值:10485760(10 mebibytes)
有效值: [4,...]
重要性:中等
更新模式:全集群
log.message.format.version
指定broker将使用的消息格式版本来追加消息到日志。该值应该是一个有效的ApiVersion。一些例子是 0.8.2, 0.9.0.0, 0.10.0, 查看ApiVersion了解更多细节。通过设置一个特定的消息格式版本,用户证明磁盘上所有现有的消息都小于或等于指定的版本。不正确地设置这个值会导致使用旧版本的消费者崩溃,因为他们会收到一个他们不理解的格式的消息。类型:字符串
默认:2.7-IV2
有效值。 [0.8.0、0.8.1、0.8.2、0.9.0、0.10.0-IV0、0.10.0-IV1、0.10.1-IV0、0.10.1-IV1、0.10.1-IV2、0.10.2-IV0、0.11.0-IV0、0.11.0-IV1、0.11.0-IV2、1.0-IV0、1. 1-IV0、2.0-IV0、2.0-IV1、2.1-IV0、2.1-IV1、2.1-IV2、2.2-IV0、2.2-IV1、2.3-IV0、2.3-IV1、2.4-IV0、2.4-IV1、2.5-IV0、2.6-IV0、2.7-IV0、2.7-IV1、2.7-IV2]
重要性:中等
更新模式:只读
log.message.timestamp.difference.max.ms
broker收到消息时的时间戳和消息中指定的时间戳之间允许的最大差异。如果log.message.timestamp.type=CreateTime,如果时间戳的差异超过这个阈值,消息将被拒绝。如果log.message.timestamp.type=LogAppendTime.允许的最大时间戳差异不应大于log.retain.ms,以避免不必要的频繁日志滚动。类型:长
默认:9223372036854775807。
有效值。
重要性:中等
更新模式:全集群
log.message.timestamp.type
定义消息中的时间戳是消息创建时间还是日志追加时间。该值应该是`CreateTime`或`LogAppendTime`。类型:字符串
默认值。 CreateTime
有效值。 [CreateTime, LogAppendTime]
重要性:中等
更新模式:全集群
log.preallocate
创建新段时是否应该预分配文件?如果你在Windows上使用Kafka,你可能需要将其设置为true。类型:布尔值
默认:假
有效值。
重要性:中等
更新模式:全集群
log.retention.check.interval.ms
日志清理器检查任何日志是否符合删除条件的频率,以毫秒为单位。类型:长
默认:300000(5分钟)
有效值:[1,...]
重要性:中等
更新模式:只读
max.connection.creation.rate
我们在任何时候在broker中允许的最大连接创建速率。监听器级别的限制也可以通过在配置名前加上监听器前缀来配置,例如,listener.name.internal.max.connection.create.rate.broker范围内的连接速率限制应该根据broker的容量来配置,而监听器的限制应该根据应用需求来配置。如果达到了监听器或broker限制,新的连接将被节流,但broker间监听器除外。只有当达到监听器级速率限制时,broker间监听器上的连接才会被节流。类型:int
默认:2147483647
有效值:[0,...]
重要性:中等
更新模式:全集群
max.connections
我们在任何时候允许的最大连接数。除了使用 max.connections.per.ip 配置的任何 per-ip 限制外,这个限制也会被应用。监听器级别的限制也可以通过在配置名称前加上监听器前缀来配置,例如,listener.name.internal.max.connection。Broker范围的限制应该根据broker的容量来配置,而监听器的限制应该根据应用需求来配置。如果达到了监听器或broker的限制,新的连接就会被阻止。即使达到了broker-wide限制,也允许在broker间监听器上进行连接。在这种情况下,另一个监听器上最近使用最少的连接将被关闭。
类型:int
默认:2147483647
有效值:[0,...]
重要性:中等
更新模式:全集群
max.connections.per.ip
每个ip地址允许的最大连接数。如果使用max.connections.per.ip.overrides属性配置了覆盖项,则可以将其设置为0。如果达到上限,来自该ip地址的新连接将被丢弃。
类型:int
默认:2147483647
有效值:[0,...]
重要性:中等
更新模式:全集群
max.connections.per.ip.overrides
以逗号分隔的每ip或主机名的列表,覆盖默认的最大连接数。例如:"hostName:100,127.0.0.1:200"
类型:字符串
默认:""
有效值。
重要性:中等
更新模式:全集群
max.incremental.fetch.session.cache.slots
我们将维持的最大增量取数。
类型:int
默认:1000
有效值:[0,...]
重要性:中等
更新模式:只读
num.partitions
每个主题的默认日志分区数类型:int
默认值:1
有效值:[1,...]
重要性:中等
更新模式:只读
password.encoder.old.secret
用于动态配置密码编码的旧密码。只有在更新秘密时才需要这个。如果指定了,所有动态编码的密码都会使用这个旧的秘密进行解码,并在 broker 启动时使用 password.encoder.secret 重新编码。类型:密码
默认值: null
有效值。
重要性:中等
更新模式:只读
password.encoder.secret
用于编码该broker动态配置的密码的秘密。类型:密码
默认值: null
有效值。
重要性:中等
更新模式:只读
principal.builder.class
实现KafkaPrincipalBuilder接口的类的全称,该接口用于构建授权过程中使用的KafkaPrincipal对象。该配置还支持被废弃的PrincipalBuilder接口,该接口之前用于通过SSL进行客户端认证。如果没有定义Principal builder,默认行为取决于使用的安全协议。对于SSL身份验证,如果提供了客户证书,将使用应用于客户证书中的区别名称的ssl.principal.mapping.rule所定义的规则推导出Principal;否则,如果不需要客户身份验证,Principal名称将是ANONYMOUS。对于SASL认证,如果使用GSSAPI,则将使用sasl.kerberos.principal.to.local.rules定义的规则推导出principal,对于其他机制,则使用SASL认证ID。对于PLAINTEXT,principal将是ANONYMOUS。类型:类
默认值: null
有效值。
重要性:中等
更新模式:每个broker
producer.purgatory.purge.interval.requests
生产者请求净化器的净化间隔(以请求数为单位)。类型:int
默认:1000
有效值。
重要性:中等
更新模式:只读
queued.max.request.bytes
在不再读取更多请求之前,允许排队的字节数。类型:长
默认值:-1
有效值。
重要性:中等
更新模式:只读
replica.fetch.backoff.ms
发生取件分区错误时的睡眠时间。类型:int
默认:1000(1秒)
有效值:[0,...]
重要性:中等
更新模式:只读
replica.fetch.max.bytes
每个分区要尝试获取的消息字节数。这不是一个绝对的最大值,如果取回的第一个非空分区的第一个记录批大于这个值,记录批仍然会被返回,以确保可以取得进展。broker接受的最大记录批次大小通过message.max.bytes(broker配置)或max.message.bytes(topic配置)来定义。类型:int
默认值:1048576(1 mebibyte)
有效值:[0,...]
重要性:中等
更新模式:只读
replica.fetch.response.max.bytes
整个取回响应的最大字节数。记录是分批取回的,如果取回的第一个非空分区中的第一个记录批大于这个值,则仍然会返回该记录批,以确保可以取得进展。因此,这不是一个绝对的最大值。broker接受的最大记录批次大小通过message.max.bytes(broker配置)或max.message.bytes(topic配置)来定义。类型:int
默认值:10485760(10 mebibytes)
有效值:[0,...]
重要性:中等
更新模式:只读
replica.selector.class
实现 ReplicaSelector 的完全限定类名。这被broker用来寻找首选的读取副本。默认情况下,我们使用返回领导者的实现。类型:字符串
默认值: null
有效值。
重要性:中等
更新模式:只读
reserved.broker.max.id
broker.id可以使用的最大数量。类型:int
默认:1000
有效值:[0,...]
重要性:中等
更新模式:只读
sasl.client.callback.handler.class
实现AuthenticateCallbackHandler接口的SASL客户端回调处理程序类的全称。类型:类
默认值: null
有效值。
重要性:中等
更新模式:只读
sasl.enabled.mechanisms
Kafka服务器中启用的SASL机制列表。该列表可以包含任何安全提供者可用的机制。默认情况下,只有GSSAPI被启用。类型:列表
默认值。 GSSAPI
有效值。
重要性:中等
更新模式:每个broker
sasl.jaas.config
JAAS登录上下文参数,用于SASL连接,格式为JAAS配置文件使用的格式。JAAS配置文件的格式在这里有介绍。值的格式为:'loginModuleClass controlFlag (optionName=optionValue)*;'。对于broker来说,配置必须以监听器前缀和SASL机制名称为前缀,并以小写字母表示。例如,listener.name.sasl_ssl.scram-sha-256.sasl.jaas.config=com.exam.ScramLoginModule必填。类型:密码
默认值: null
有效值。
重要性:中等
更新模式:每个broker
sasl.kerberos.kinit.cmd
Kerberos kinit 命令路径。类型:字符串
默认值。 /usr/bin/kinit
有效值。
重要性:中等
更新模式:每个broker
sasl.kerberos.min.time.before.relogin
登录线程刷新尝试之间的睡眠时间。类型:长
默认值:60000
有效值。
重要性:中等
更新模式:每个broker
sasl.kerberos.principal.to.local.rules
从主名到短名(通常是操作系统用户名)的映射规则列表。这些规则按顺序评估,与主名匹配的第一条规则被用来将其映射为短名。列表中后面的任何规则都会被忽略。默认情况下,{username}/{hostname}@{REALM}形式的主名会被映射到{username}。有关格式的更多细节,请参见安全授权和acls。请注意,如果 principal.builder.class 配置提供了 KafkaPrincipalBuilder 的扩展,这个配置将被忽略。类型:列表
默认值。 DEFAULT
有效值。
重要性:中等
更新模式:每个broker
sasl.kerberos.service.name
Kafka 运行的 Kerberos 主体名称。这可以在Kafka的JAAS配置或Kafka的配置中定义。类型:字符串
默认值: null
有效值。
重要性:中等
更新模式:每个broker
sasl.kerberos.ticket.renew.jitter
随机抖动加到续航时间的百分比。类型:双倍
默认值:0.05
有效值。
重要性:中等
更新模式:每个broker
sasl.kerberos.ticket.renew.window.factor。
登录线程将休眠,直到达到从上次刷新到票据到期的指定时间窗口系数,这时它将尝试更新票据。类型:双倍
默认值:0.8
有效值。
重要性:中等
更新模式:每个broker
sasl.login.callback.handler.class
实现AuthenticateCallbackHandler接口的SASL登录回调处理程序类的完全限定名称。对于broker来说,登录回调处理程序配置必须以监听器前缀和小写的SASL机制名称为前缀。例如,listener.name.sasl_ssl.scram-sha-256.sasl.login.callback.handler.class=com.example.CustomScramLoginCallbackHandler。类型:类
默认值: null
有效值。
重要性:中等
更新模式:只读
sasl.login.class
实现Login接口的类的全称。对于broker来说,login config必须以监听器前缀和SASL机制名称为前缀,并使用小写。例如,listener.name.sasl_ssl.scram-sha-256.sasl.login.class=com.example.CustomScramLogin。类型:类
默认值: null
有效值。
重要性:中等
更新模式:只读
sasl.login.refresh.buffer.seconds
刷新凭证时,在凭证到期前要保持的缓冲时间,以秒为单位。如果刷新的时间离到期时间比缓冲秒数更近,那么刷新时间将被提前,以尽可能多地保持缓冲时间。法定值在0到3600(1小时)之间;如果没有指定值,则使用默认值300(5分钟)。如果该值和sasl.login.refresh.min.period.seconds的总和超过了凭证的剩余寿命,则该值和sasl.login.refresh.min.period.seconds都会被忽略。目前只适用于OAUTHBEARER。类型:short
默认值:300
有效值。
重要性:中等
更新模式:每个broker
sasl.login.refresh.min.period.seconds
登录刷新线程在刷新凭证前需要等待的最短时间,以秒为单位。合法值在0到900(15分钟)之间;如果没有指定值,则使用默认值60(1分钟)。如果这个值和sasl.login.refresh.buffer.seconds的总和超过了一个凭证的剩余寿命,那么这个值和sasl.login.buffer.seconds都会被忽略。目前只适用于OAUTHBEARER。类型:short
默认值:60
有效值。
重要性:中等
更新模式:每个broker
sasl.login.refresh.window.factor
登录刷新线程将休眠,直到达到相对于凭证寿命的指定窗口系数,此时将尝试刷新凭证。合法值在0.5(50%)到1.0(100%)之间,如果没有指定值,则使用默认值0.8(80%)。目前仅适用于OAUTHBEARER。类型:double
默认值:0.8
有效值。
重要性:中等
更新模式:每个broker
sasl.login.refresh.window.jitter
相对于凭证的寿命,加到登录刷新线程的睡眠时间的最大随机抖动量。合法值在0到0.25(25%)之间,如果没有指定值,则使用默认值0.05(5%)。目前只适用于OAUTHBEARER。类型:double
默认值:0.05
有效值。
重要性:中等
更新模式:每个broker
sasl.mechanism.inter.broker.protocol
用于broker之间通信的SASL机制。默认为GSSAPI。类型:string
默认值。 GSSAPI
有效值。
重要性:中等
更新模式:每个broker
sasl.server.callback.handler.class
实现AuthenticateCallbackHandler接口的SASL服务器回调处理程序类的完全限定名称。服务器回调处理程序必须以监听器前缀和SASL机制名称为前缀,并使用小写字母。例如,listener.name.sasl_ssl.plain.sasl.server.callback.handler.class=com.example.CustomPlainCallbackHandler。类型:class
默认值: null
有效值。
重要性:中等
更新模式:只读
security.inter.broker.protocol
用于broker之间通信的安全协议。有效值是: PLAINTEXT, SSL, SASL_PLAINTEXT, SASL_SSL. 同时设置此属性和inter.broker.listener.name属性是错误的。类型:string
默认值。 PLAINTEXT
有效值。
重要性:中等
更新模式:只读
socket.connection.setup.timeout.max.ms
客户端等待建立套接字连接的最大时间。连接设置超时时间将随着每一次连续的连接失败而成倍增加,直到这个最大值。为了避免连接风暴,超时时间将被应用于0.2的随机系数,结果是低于计算值20%到高于计算值20%的随机范围。类型:长
默认:127000(127秒)
有效值。
重要性:中等
更新模式:只读
socket.connection.setup.timeout.ms
客户端等待socket连接建立的时间。如果在超时之前没有建立连接,客户端将关闭socket通道。类型:long
默认:10000(10秒)
有效值。
重要性:中等
更新模式:只读
ssl.cipher.suites
密码套件的列表。这是一个命名的认证、加密、MAC和密钥交换算法的组合,用于使用TLS或SSL网络协议协商网络连接的安全设置。默认情况下,支持所有可用的密码套件。类型:list
默认:""
有效值。
重要性:中等
更新模式:每个broker
ssl.client.auth
配置kafka broker请求客户端认证。以下是常用的设置。ssl.client.auth=required 如果设置为require,则客户端认证是必须的。
ssl.client.auth=requested 这意味着客户端认证是可选的,与required不同,如果设置了这个选项,客户端可以选择不提供自己的认证信息。
ssl.client.auth=none 这表示不需要客户端认证。
类型:string
默认:无
有效值: [required, requested, none]
重要性:中等
更新模式:每个broker
ssl.enabled.protocols
为SSL连接启用的协议列表。默认值是 "TLSv1.2,TLSv1.3",当运行Java 11或更新版本时,否则为 "TLSv1.2"。在Java 11的默认值下,如果客户端和服务器都支持TLSv1.3,则会优先选择TLSv1.3,否则会回退到TLSv1.2(假设两者都至少支持TLSv1.2)。这个默认值在大多数情况下应该是没有问题的。也可以参考`ssl.protocol`的配置文档。类型:list
默认值: TLSv1.2
有效值。
重要性:中等
更新模式:每个broker
ssl.key.password
密钥存储文件中私钥的密码,或在`ssl.keystore.key'中指定的PEM密钥。只有在配置了双向身份验证的情况下,客户端才需要这个密码。类型:password
默认值: null
有效值。
重要性:中等
更新模式:每个broker
ssl.keymanager.algorithm
钥匙管理器工厂用于SSL连接的算法,默认值是为Java虚拟机配置的钥匙管理器工厂算法。默认值是为Java虚拟机配置的密钥管理器工厂算法。类型:string
默认值。 SunX509
有效值。
重要性:中等
更新模式:每个broker
ssl.keystore.certificate.chain
证书链的格式由'ssl.keystore.type'指定。默认的SSL引擎工厂只支持PEM格式的X.509证书列表。类型:password
默认值: null
有效值。
重要性:中等
更新模式:每个broker
ssl.keystore.key
私钥的格式由'ssl.keystore.type'指定。默认SSL引擎工厂只支持PEM格式的PKCS#8密钥。如果密钥是加密的,必须使用'ssl.key.password'指定密钥密码。类型:password
默认值: null
有效值。
重要性:中等
更新模式:每个broker
ssl.keystore.location
密钥存储文件的位置。对客户端来说是可选的,可以用于客户端的双向认证。类型:string
默认值: null
有效值。
重要性:中等
更新模式:每个broker
ssl.keystore.password
密钥存储文件的存储密码。这对客户端来说是可选的,只有在配置了'ssl.keystore.location'时才需要。对于PEM格式,不支持密钥存储密码。类型:password
默认值: null
有效值。
重要性:中等
更新模式:每个broker
ssl.keystore.type
密钥存储文件的文件格式。对客户端来说是可选的。类型:string
默认值。 JKS
有效值。
重要性:中等
更新模式:每个broker
ssl.protocol
用来生成SSLContext的SSL协议,默认为'TLSv1.3',否则为'TLSv1.2'。当运行Java 11或更新版本时,默认为'TLSv1.3',否则为'TLSv1.2'。这个值对于大多数的使用情况来说应该是没有问题的。在最近的JVM中允许的值是'TLSv1.2'和'TLSv1.3'。TLS','TLSv1.1','SSL','SSLv2'和'SSLv3'在旧的JVM中可能会被支持,但由于已知的安全漏洞,我们不鼓励使用它们。在这个配置和'ssl.enabled.protocols'的默认值下,如果服务器不支持'TLSv1.3',客户端将降级为'TLSv1.2'。如果这个配置被设置为'TLSv1.2',即使是ssl.enabled.protocols中的一个值,并且服务器只支持'TLSv1.3',客户端也不会使用'TLSv1.3'。类型:string
默认值: TLSv1.2
有效值。
重要性:中等
更新模式:每个broker
ssl.provider
用于SSL连接的安全提供者的名称。默认值是JVM的默认安全提供者。类型:string
默认值: null
有效值。
重要性:中等
更新模式:每个broker
ssl.trustmanager.algorithm
信任管理器工厂用于SSL连接的算法。默认值是为Java虚拟机配置的信任管理器工厂算法。类型:string
默认值。 PKIX
有效值。
重要性:中等
更新模式:每个broker
ssl.truststore.certificates
可信证书的格式由'ssl.truststore.type'指定。默认SSL引擎工厂只支持PEM格式的X.509证书。类型:password
默认值: null
有效值。
重要性:中等
更新模式:每个broker
ssl.truststore.location
信任存储文件的位置。类型:string
默认值: null
有效值。
重要性:中等
更新模式:每个broker
ssl.truststore.password
信任存储文件的密码。如果没有设置密码,则仍然使用配置的信任存储文件,但完整性检查被禁用。PEM格式不支持信任存储密码。类型:password
默认值: null
有效值。
重要性:中等
更新模式:每个broker
ssl.truststore.type
信任存储文件的文件格式。类型:string
默认值。 JKS
有效值。
重要性:中等
更新模式:每个broker
zookeeper.clientCnxnSocket
当使用TLS连接到ZooKeeper时,通常设置为org.apache.zookeeper.ClientCnxnSocketNetty。覆盖任何通过同名的zookeeper.clientCnxnSocket系统属性设置的显式值。类型:string
默认值: null
有效值。
重要性:中等
更新模式:只读
zookeeper.ssl.client.enable
设置客户端连接到ZooKeeper时使用TLS。显式的值会覆盖任何通过zookeeper.client.secure system属性设置的值(注意名称不同)。如果两者都没有设置,默认为false;当为true时,必须设置zookeeper.clientCnxnSocket(通常为org.apache.zookeeper.ClientCnxnSocketNetty);其他需要设置的值可能包括zookeeper.ssl.cipher.suites、zookeeper.ssl.crl.enable、zookeeper.ssl.enabled.protocols、zookeeper.ssl. endpoint.identification.algorithm, zookeeper.ssl.keystore.location, zookeeper.ssl.keystore.password, zookeeper.ssl.keystore.type, zookeeper.ssl.ocsp.enable, zookeeper.ssl.protocol, zookeeper.ssl.truststore.location, zookeeper.ssl.truststore.password, zookeeper.ssl.truststore.type。类型: boolean
默认:假
有效值。
重要性:中等
更新模式:只读
zookeeper.ssl.keystore.location
当使用客户端证书与TLS连接到ZooKeeper时的keystore位置。覆盖任何通过zookeeper.ssl.keyStore.location系统属性设置的显式值(注意是camelCase)。类型:string
默认值: null
有效值。
重要性:中等
更新模式:只读
zookeeper.ssl.keystore.password
当使用客户端证书与TLS连接到ZooKeeper时的密钥存储密码。覆盖任何通过zookeeper.ssl.keyStore.password系统属性设置的显式值(注意是camelCase)。注意ZooKeeper不支持与keystore密码不同的密钥密码,所以一定要将keystore中的密钥密码设置为与keystore密码相同,否则连接Zookeeper的尝试将失败。类型:password
默认值: null
有效值。
重要性:中等
更新模式:只读
zookeeper.ssl.keystore.type
当使用客户端证书与TLS连接到ZooKeeper时的keystore类型。覆盖任何通过zookeeper.ssl.keyStore.type系统属性设置的显式值(注意骆驼大写)。默认值为null意味着类型将根据keystore的文件扩展名自动检测。类型:string
默认值: null
有效值。
重要性:中等
更新模式:只读
zookeeper.ssl.truststore.location
当使用TLS连接到ZooKeeper时的Truststore位置。覆盖任何通过zookeeper.ssl.trustStore.location系统属性设置的显式值(注意是camelCase)。类型:string
默认值: null
有效值。
重要性:中等
更新模式:只读
zookeeper.ssl.truststore.password
当使用TLS连接到ZooKeeper时的Truststore密码。覆盖任何通过zookeeper.ssl.trustStore.password系统属性设置的显式值(注意是camelCase)。类型:password
默认值: null
有效值。
重要性:中等
更新模式:只读
zookeeper.ssl.truststore.type
当使用TLS连接到ZooKeeper时的Truststore类型。覆盖任何通过zookeeper.ssl.trustStore.type系统属性设置的显式值(注意骆驼大写)。默认值为null意味着该类型将根据truststore的文件扩展名自动检测。类型:string
默认值: null
有效值。
重要性:中等
更新模式:只读
alter.config.policy.class.name
应该用于验证的 alter configs 策略类。该类应该实现org.apache.kafka.server.policy.AlterConfigPolicy接口。类型:class
默认值: null
有效值。
重要性:低
更新模式:只读
alter.log.dirs.replication.quota.window.num
为改变日志目录复制配额而保留在内存中的样本数量。类型:int
默认值:11
有效值:[1,...]
重要性:低
更新模式:只读
alter.log.dirs.replication.quota.window.size.seconds
alter log dirs复制配额的每个样本的时间跨度。类型:int
默认值:1
有效值:[1,...]
重要性:低
更新模式:只读
authorizer.class.name
实现sorg.apache.kafka.server.authorizer.Authorizer接口的类的完全限定名称,该类被broker用于授权。该配置还支持实现已废弃的kafka.security.uth.Authorizer trait的授权者,该授权者以前用于授权。类型:string
默认:""
有效值。
重要性:低
更新模式:只读
client.quota.callback.class
实现ClientQuotaCallback接口的类的全称,该类用于确定应用于客户端请求的配额限制。默认情况下,应用的是 ,或ZooKeeper中存储的配额。对于任何给定的请求,将应用与会话的用户主控和请求的client-id相匹配的最具体的配额。类型:class
默认值: null
有效值。
重要性:低
更新模式:只读
connection.failed.authentication.delay.ms
认证失败时的连接关闭延迟:这是认证失败时连接关闭延迟的时间(毫秒)。该值必须配置为小于 connections.max.idle.ms,以防止连接超时。类型:int
默认值:100
有效值:[0,...]
重要性:低
更新模式:只读
controller.quota.window.num
控制器突变配额在内存中保留的样本数量。类型:int
默认值:11
有效值:[1,...]
重要性:低
更新模式:只读
controller.quota.window.size.seconds
控制器突变定额的每个样本的时间跨度。类型:int
默认值:1
有效值:[1,...]
重要性:低
更新模式:只读
create.topic.policy.class.name
应该用于验证的创建主题策略类。该类应该实现org.apache.kafka.server.policy.CreateTopicPolicy接口。类型:class
默认值: null
有效值。
重要性:低
更新模式:只读
delegation.token.expiry.check.interval.ms
移除过期的授权令牌的扫描间隔。类型:长
默认:3600000(1小时)
有效值:[1,...]
重要性:低
更新模式:只读
kafka.metrics.polling.interval.secs
kafka.metrics.reporters实现中可以使用的度量值轮询间隔(秒)。类型:int
默认值:10
有效值:[1,...]
重要性:低
更新模式:只读
kafka.metrics.reporters
作为Yammer metrics自定义报告器的类列表。这些报告器应该实现kafka.metrics.KafkaMetricsReporter trait。如果客户端想要在自定义报告器上公开JMX操作,自定义报告器需要额外实现一个MBean trait,这个MBean trait扩展了kafka.metrics.KafkaMetricsReporterMBean trait,以便注册的MBean符合标准MBean约定。类型:list
默认:""
有效值。
重要性:低
更新模式:只读
listener.security.protocol.map
监听器名称和安全协议之间的映射。要想让同一个安全协议在多个端口或IP中使用,就必须定义这个映射。例如,内部和外部流量可以分开,即使两者都需要SSL。具体来说,用户可以将名称为INTERNAL和EXTERNAL的监听器和这个属性定义为。`INTERNAL:SSL,EXTERNAL:SSL`。如图所示,键和值用冒号隔开,映射项用逗号隔开。每个监听器名称在地图中只能出现一次。通过在配置名称中添加规范化的前缀(监听器名称为小写),可以为每个监听器配置不同的安全(SSL和SASL)设置。例如,如果要为INTERNAL监听器设置不同的keystore,就可以设置名称为listener.name.internal.ssl.keystore.location的config。如果没有设置监听器名称的config,config将回落到通用config(即ssl.keystore.location)。类型:string
默认值。 PLAINTEXT:PLAINTEXT,SSL:SSL,SASL_PLAINTEXT:SASL_PLAINTEXT,SASL_SSL:SASL_SSL。
有效值。
重要性:低
更新模式:每个broker
log.message.downconversion.enable
此配置控制是否启用消息格式的向下转换以满足消费请求。当设置为false时,broker不会对期待旧消息格式的消费者执行向下转换。broker 会对来自此类旧客户的消费请求作出 UNSUPPORTED_VERSION 错误响应。此配置不适用于复制到跟随者时可能需要的任何消息格式转换。类型:boolean
默认:true
有效值。
重要性:低
更新模式:全集群
metric.reporters
作为度量报告器使用的类的列表。实现org.apache.kafka.common.metrics.MetricsReporter接口允许插入将被通知新的度量创建的类。JmxReporter总是被包含在注册JMX统计数据中。类型:list
默认:""
有效值。
重要性:低
更新模式:全集群
metrics.num.samples
为计算指标而维护的样本数量。类型:int
默认值:2
有效值:[1,...]
重要性:低
更新模式:只读
metrics.recording.level
指标的最高记录级别。类型:string
默认:INFO
有效值。
重要性:低
更新模式:只读
metrics.sample.window.ms
度量样本计算的时间窗口。类型:长
默认:30000(30秒)
有效值:[1,...]
重要性:低
更新模式:只读
password.encoder.cipher.algorithm
动态配置密码的加密算法。类型:string
默认情况下,AES/CBC/PKCS5Padding AES/CBC/PKCS5Padding。
有效值。
重要性:低
更新模式:只读
password.encoder.iterations
动态配置的密码编码的迭代次数。类型:int
默认值:4096
有效值: [1024,...]
重要性:低
更新模式:只读
password.encoder.key.length
动态配置密码的密钥长度。类型:int
默认值:128
有效值: [8,...]
重要性:低
更新模式:只读
password.encoder.keyfactory.algorithm
用于动态配置密码编码的SecretKeyFactory算法,如果有的话,默认为PBKDF2WithHmacSHA512,否则为PBKDF2WithHmacSHA1。默认值为PBKDF2WithHmacSHA512(如果可用),否则为PBKDF2WithHmacSHA1。类型:string
默认值: null
有效值。
重要性:低
更新模式:只读
quota.window.num
客户端配额在内存中保留的样本数量。类型:int
默认值:11
有效值:[1,...]
重要性:低
更新模式:只读
quota.window.size.seconds
客户定额的每个样本的时间跨度。类型:int
默认值:1
有效值:[1,...]
重要性:低
更新模式:只读
replication.quota.window.num
为复制配额而保留在内存中的样本数量。类型:int
默认值:11
有效值:[1,...]
重要性:低
更新模式:只读
replication.quota.window.size.seconds
复制定额的每个样本的时间跨度。类型:int
默认值:1
有效值:[1,...]
重要性:低
更新模式:只读
security.providers
一个可配置的创建者类的列表,每个类都返回一个实现安全算法的提供者。这些类应该实现org.apache.kafka.common.security.ah.SecurityProviderCreator接口。类型:string
默认值: null
有效值。
重要性:低
更新模式:只读
ssl.endpoint.identification.algorithm
使用服务器证书验证服务器主机名的端点识别算法。类型:string
默认:https
有效值。
重要性:低
更新模式:每个broker
ssl.engine.factory.class
org.apache.kafka.common.security.auth.SslEngineFactory类型的类来提供SSLEngine对象。默认值是org.apache.kafka.common.security.ssl.DefaultSslEngineFactory。类型:class
默认值: null
有效值。
重要性:低
更新模式:每个broker
ssl.principal.mapping.rules
用于将客户证书中的区别名称映射到短名称的规则列表。这些规则按顺序评估,第一条与主名匹配的规则被用来将其映射为短名。列表中的任何后面的规则将被忽略。默认情况下,X.500 证书的区别名称将是主证书。有关格式的更多细节,请参见安全授权和 acls。请注意,如果 principal.builder.class 配置提供了 KafkaPrincipalBuilder 的扩展,这个配置将被忽略。类型:string
默认值。 默认值: DEFAULT
有效值。
重要性:低
更新模式:只读
ssl.secure.random.implementation
用于SSL加密操作的SecureRandom PRNG实现。类型:string
默认值: null
有效值。
重要性:低
更新模式:每个broker
transaction.abort.timed.out.transaction.cleanup.interval.ms
回滚已超时的事务的时间间隔。类型:int
默认:10000(10秒)
有效值:[1,...]
重要性:低
更新模式:只读
transaction.remove.expired.transaction.cleanup.interval.ms
删除因transactional.id.expertation.ms过期而过期的事务的时间间隔。类型:int
默认:3600000(1小时)
有效值:[1,...]
重要性:低
更新模式:只读
zookeeper.ssl.cipher.suites
指定ZooKeeper TLS协商中使用的密码套件(csv)。覆盖任何通过zookeeper.ssl.ciphersuites系统属性设置的显式值(注意单字 "ciphersuites")。默认值为null意味着启用的密码套件列表是由正在使用的Java运行时决定的。类型:list
默认值: null
有效值。
重要性:低
更新模式:只读
zookeeper.ssl.crl.enable
指定是否启用ZooKeeper TLS协议中的证书撤销列表。覆盖任何通过zookeeper.ssl.crl系统属性设置的显式值(注意是短名)。类型:boolean
默认:假
有效值。
重要性:低
更新模式:只读
zookeeper.ssl.enabled.protocols
指定ZooKeeper TLS协商(csv)中启用的协议。覆盖任何通过zookeeper.ssl.enabledProtocols系统属性设置的显式值(注意骆驼大写)。默认值为null意味着启用的协议将是zookeeper.ssl.protocol配置属性的值。类型:list
默认值: null
有效值。
重要性:低
更新模式:只读
zookeeper.ssl.endpoint.identification.algorithm
指定是否在ZooKeeper TLS协商过程中启用主机名验证,(不区分大小写)"https "表示启用ZooKeeper主机名验证,显式的空白值表示禁用(仅为测试目的建议禁用)。明确的值会覆盖任何通过zookeeper.ssl.hostnameVerification系统属性设置的 "true "或 "false "值(注意不同的名称和值,true意味着https,false意味着空白)。类型:string
默认:HTTPS
有效值。
重要性:低
更新模式:只读
zookeeper.ssl.ocsp.enable
指定是否启用ZooKeeper TLS协议中的在线证书状态协议。覆盖任何通过zookeeper.ssl.ocsp系统属性设置的显式值(注意是短名)。类型:boolean
默认:假
有效值。
重要性:低
更新模式:只读
zookeeper.ssl.protocol
指定ZooKeeper TLS协商中使用的协议。一个显式的值会覆盖通过同名的zookeeper.ssl.protocol系统属性设置的任何值。类型:string
默认值: TLSv1.2
有效值。
重要性:低
更新模式:只读
zookeeper.sync.time.ms
一个ZK跟随者可以落后于一个ZK领导者多远类型:int
默认:2000(2秒)
有效值。
重要性:低
更新模式:只读
关于broker配置的更多细节可以在scala类kafka.server.KafkaConfig中找到。
3.1.1 更新broker配置
从Kafka 1.1版本开始,部分broker配置可以在不重新启动broker的情况下进行更新。请参阅Broker Configs中的动态更新模式列,了解每个broker配置的更新模式。
- 只读。需要重启broker才能更新
- 每家broker。可为每个broker动态更新
- 全群集。可作为全群组的默认值动态更新。也可以作为每个broker的值进行更新,以便测试。
要改变当前broker id 0的broker配置(例如,日志清理线程的数量)。
> bin/kafka-configs.sh --bootstrap-server localhost:9092 --entity-type brokers --entity-name 0 --alter --add-config log.cleaner.threads=2
要描述当前动态broker配置的broker id 0:
> bin/kafka-configs.sh --bootstrap-server localhost:9092 --entity-type brokers --entity-name 0 --describe
要删除config覆盖,并恢复到broker id 0的静态配置或默认值(例如,日志清理线程的数量)。
> bin/kafka-configs.sh --bootstrap-server localhost:9092 --entity-type brokers --entity-name 0 --alter --delete-config log.cleaner.threads
某些配置可能会被配置为整个群集的默认值,以保持整个群集的一致值。集群中的所有broker将处理集群默认更新。例如,要更新所有broker上的日志清理线程。
> bin/kafka-configs.sh --bootstrap-server localhost:9092 --entity-type brokers --entity-default --alter --add-config log.cleaner.threads=2
要描述当前配置的动态全集群默认配置。
> bin/kafka-configs.sh --bootstrap-server localhost:9092 --entity-type brokers --entity-default --describe
所有在群集级别上可配置的配置值也可以在每个路由器级别上配置(例如用于测试)。如果一个配置值在不同级别定义,则使用以下优先顺序。
- 在ZooKeeper中的动态存储每个broker配置。
- 动态的全集群默认配置存储在ZooKeeper中。
- 从server.properties中静态配置broker
- Kafka默认值,见broker配置
动态更新密码设置
动态更新的密码配置值在ZooKeeper中存储前会被加密。broker配置password.encoder.secret必须在server.properties中配置以启用动态更新密码配置。不同的broker的secret可能不同。
用于密码编码的秘密可能会随着broker的滚动重启而轮换。目前ZooKeeper中用于编码密码的旧秘密必须在静态broker配置password.encoder.old.secret中提供,新秘密必须在password.encoder.secret中提供。所有存储在ZooKeeper中的动态密码配置将在broker启动时用新的秘密重新编码。
在Kafka 1.1.x中,当使用kafka-configs.sh更新配置时,必须在每个alter请求中提供所有动态更新的密码配置,即使密码配置没有被改变。这个限制将在未来的版本中被移除。
在开始broker之前更新ZooKeeper的密码设置
从Kafka 2.0.0开始,kafka-configs.sh可以在启动broker进行引导之前,使用ZooKeeper更新动态broker配置。这使得所有的密码配置都以加密的形式存储,避免了在server.properties中清除密码的需要。如果在alter命令中包含任何密码配置,还必须指定broker配置password.encoder.secret。也可以指定其他加密参数。密码编码器配置将不会在ZooKeeper中持续存在。例如,要在broker 0上存储监听器INTERNAL的SSL密钥密码。
> bin/kafka-configs.sh --zookeeper localhost:2182 --zk-tls-config-file zk_tls_config.properties --entity-type brokers --entity-name 0 --alter --add-config'listener.name.internal.ssl.key.password=key-password,password.encoder.secret=secret,password.encoder.iterations=8192'
配置监听器.name.internal.ssl.key.password将使用提供的编码器配置以加密的形式持久化在ZooKeeper中。编码器的秘密和迭代不会持续在ZooKeeper中。
更新现有监听器的SSL密钥库
broker可以配置有效期较短的SSL密钥存储,以降低证书泄露的风险。密钥存储可以动态更新,而无需重新启动broker。配置名称必须以监听器前缀listener.name.{listenerName}为前缀,这样就只更新特定监听器的keystore配置。以下配置可以在每个broker级别的单个alter请求中更新。
- ssl.keystore.type
- ssl.keystore.location
- ssl.keystore.password
- ssl.key.password
如果监听器是broker之间的监听器,只有当新的keystore被为该监听器配置的truststore信任时,才允许更新。对于其他监听器,broker不会对密钥store进行信任验证。证书必须由签署旧证书的同一证书颁发机构签署,以避免任何客户端验证的失败。
更新现有监听器的SSL Truststore
brokertruststores可以动态更新,而不需要重新启动broker来添加或删除证书。更新后的truststore将用于验证新的客户端连接。配置名称必须以监听器前缀listener.name.{listenerName}为前缀,这样只有特定监听器的truststore配置才会更新。以下配置可以在每个broker级别的单个alter请求中更新。
- ssl.truststore.type
- ssl.truststore.location
- ssl.truststore.password
如果监听器是broker之间的监听器,只有当该监听器的现有keystore被新的truststore信任时,才允许更新。对于其他监听器,更新前,中间商不进行信任验证。从新的信任store中删除用于签署客户端证书的CA证书会导致客户端认证失败。
更新默认主题配置
broker使用的默认主题配置选项可以在不重启broker的情况下更新。这些配置被应用于没有主题配置覆盖的主题,相当于每个主题的配置。这些配置中的一个或多个可以在所有broker使用的集群默认级别被覆盖。
log.segment.byteslog.roll.mslog.roll.hourslog.roll.jitter.mslog.roll.jitter.hourslog.index.size.max.byteslog.flush.interval.messageslog.flush.interval.mslog.retention.byteslog.retention.mslog.retention.minuteslog.retention.hourslog.index.interval.byteslog.cleaner.delete.retention.mslog.cleaner.min.compaction.lag.mslog.cleaner.max.compaction.lag.mslog.cleaner.min.cleanable.ratiolog.cleanup.policylog.segment.delete.delay.msunclean.leader.election.enablemin.insync.replicasmax.message.bytescompression.typelog.preallocatelog.message.timestamp.typelog.message.timestamp.difference.max.ms
从Kafka 2.0.0版本开始,当动态更新配置unclean.leader.election.enhance时,控制器会自动启用unclean.leader.election.enhance。在Kafka 1.1.x版本中,对unclean.leader.election.enable的更改只有在新控制器当选时才会生效。可以通过运行控制器重新选举来强制执行。
> bin/zookeeper-shell.sh localhostrmr /controller
更新日志清理器配置
日志清理配置可以在所有broker使用的集群默认级别动态更新。这些更改将在下一次日志清理迭代时生效。这些配置中的一个或多个可以被更新。
log.cleaner.threadslog.cleaner.io.max.bytes.per.secondlog.cleaner.dedupe.buffer.sizelog.cleaner.io.buffer.sizelog.cleaner.io.buffer.load.factorlog.cleaner.backoff.ms
更新线程配置
broker使用的各种线程池的大小可以在所有broker使用的集群默认级别动态更新。更新限制在currentSize / 2到currentSize * 2的范围内,以确保配置更新被优雅地处理。
num.network.threadsnum.io.threadsnum.replica.fetchersnum.recovery.threads.per.data.dirlog.cleaner.threadsbackground.threads
更新连接配额配置
broker对给定 IP/主机允许的最大连接数可以在所有broker使用的集群默认级别动态更新。这些变化将适用于新连接的创建,现有的连接数将被新的限制所考虑。
max.connections.per.ipmax.connections.per.ip.overrides
添加和删除监听器
监听器可以被动态地添加或删除。当添加新的监听器时,必须以监听器前缀listener.name.{listenerName}.的监听器配置来提供监听器的安全配置。如果新的监听器使用SASL,必须使用JAAS配置属性sasl.jaas.config提供监听器的JAAS配置,并加上监听器和机制前缀。详情请参见Kafkabroker的JAAS配置。
在Kafka 1.1.x版本中,broker间监听器使用的监听器可能无法动态更新。要将broker间监听器更新为新的监听器,可以在所有broker上添加新的监听器,而不需要重新启动broker。然后需要滚动重启来更新inter.broker.listener.name。
除了新监听器的所有安全配置外,以下配置可以在每个broker级别动态更新。
listenersadvertised.listenerslistener.security.protocol.map
broker之间的监听器必须使用静态broker配置inter.broker.listener.name或inter.broker.security.protocol进行配置。
3.2 主题级配置
与主题相关的配置既有服务器默认值,也有可选的每个主题覆盖值。如果没有给出每个主题的配置,则使用服务器默认值。覆盖可以在创建主题时通过给出一个或多个--config选项来设置。这个例子创建了一个名为my-topic的主题,并自定义了最大消息大小和刷新率。
> bin/kafka-topics.sh --bootstrap-server localhost:9092 --create --topic my-topic --partitions 1 \--replication-factor 1 --config max.message.bytes=64000 --config flush.messages=1
覆盖也可以在以后使用 alter configs 命令进行更改或设置。这个例子更新了my-topic的最大消息大小。
> bin/kafka-configs.sh --bootstrap-server localhost:9092 --entity-type topics --entity-name my-topic--alter --add-config max.message.bytes=128000
要检查主题上重载的设置,你可以执行以下操作
> bin/kafka-configs.sh --bootstrap-server localhost:9092 --entity-type topics --entity-name my-topic --describe
要删除重载的设置,您可以执行以下操作
> bin/kafka-configs.sh --bootstrap-server localhost:9092 --entity-type topics --entity-name my-topic--alter --delete-config max.message.bytes
以下是主题级的配置。在服务器默认属性标题下给出了该属性的服务器默认配置。给定的服务器默认配置值只适用于没有明确的主题配置覆盖的主题。
cleanup.policy
字符串,可以是 "删除 "或 "压缩",或者两者都是。此字符串指定对旧日志段使用的保留策略。默认策略("删除")将在达到保留时间或大小限制时丢弃旧片段。紧凑 "设置将启用主题上的日志压缩。类型:list
默认:delete
有效值。[compact, delete]
服务器默认属性:log.cleanup.policy。
重要性:中等
compression.type
指定给定主题的最终压缩类型。此配置接受标准的压缩编解码器('gzip'、'snappy'、'lz4'、'zstd')。此外,它还接受'uncompressed',这相当于没有压缩;以及'producer',这意味着保留制作者设置的原始压缩编解码器。类型:string
默认:producer
有效值。 [uncompressed, zstd, lz4, snappy, gzip, producer]
服务器默认属性:compression.type
重要性:中等
delete.retention.ms
为日志压缩主题保留删除墓碑标记的时间。如果消费者从偏移量0开始读取,这个设置还给出了消费者必须完成读取的时间界限,以确保他们得到最后阶段的有效快照(否则,删除墓碑可能会在完成扫描之前被收集)。类型:long
默认:86400000(1天)。
有效值:[0,...]
服务器默认属性:log.cleaner.delete.retention.ms
重要性:中等
file.delete.delay.ms
从文件系统中删除文件前等待的时间。类型:long
默认:60000(1分钟)
有效值:[0,...]
服务器默认属性:log.segment.delete.delay.ms
重要性:中等
flush.messages
这个设置允许指定一个时间间隔,在这个时间间隔内,我们将强制对写入日志的数据进行fsync。例如,如果设置为1,我们将在每条消息后进行fsync;如果设置为5,我们将在每五条消息后进行fsync。一般情况下,我们建议你不要设置这个,使用复制来保证持久性,并允许操作系统的后台刷新功能,因为它更有效率。这个设置可以在每个主题的基础上被覆盖(见每个主题配置部分)。类型:长
默认:9223372036854775807。
有效值:[0,...]
服务器默认属性:log.flush.interval.messages
重要性:中等
flush.ms
这个设置允许指定一个时间间隔,在这个时间间隔内,我们将强制对写入日志的数据进行fsync。例如,如果设置为1000,我们将在1000毫秒后进行fsync。一般情况下,我们建议你不要设置这个,使用复制来提高耐用性,并允许操作系统的后台刷新功能,因为它更有效。类型:long
默认:9223372036854775807。
有效值:[0,...]
服务器默认属性:log.flush.interval.ms
重要性:中等
follower.replication.throttled.replicas
一个副本的列表,对于这些副本,日志复制应该在follower端进行节流。该列表应该以[PartitionId]:[BrokerId],[PartitionId]:[BrokerId]:...的形式描述一组副本,或者使用通配符'*'来节制这个主题的所有副本。类型:list
默认:""
有效值。 [partitionId]:[brokerId],[partitionId]:[brokerId],...
服务器默认属性:follower.replication.throttled.replicas
重要性:中等
index.interval.bytes
这个设置控制了Kafka向其偏移索引添加索引项的频率。默认设置确保我们大约每4096个字节为一条消息建立索引。更多的索引允许读取跳转到更接近日志中的准确位置,但会使索引更大。你可能不需要改变这个设置。类型:int
默认值:4096(4 kibibytes)
有效值:[0,...]
服务器默认属性:log.index.interval.bytes
重要性:中等
leader.replication.throttled.replicas
复制的列表,对于这些复制,日志复制应该在领导侧进行节流。该列表应以[PartitionId]:[BrokerId],[PartitionId]:[BrokerId]:...的形式描述一组副本,或者使用通配符'*'来节制这个主题的所有副本。类型:list
默认:""
有效值。 [partitionId]:[brokerId],[partitionId]:[brokerId],...
服务器默认属性:leader.replication.throttled.replicas
重要性:中等
max.compaction.lag.ms
消息在日志中不符合压实条件的最长时间。仅适用于正在压缩的日志。类型:long
默认:9223372036854775807
有效值:[1,...]
服务器默认属性:log.cleaner.max.compaction.lag.ms
重要性:中等
max.message.bytes
Kafka允许的最大记录批次大小(如果启用压缩,则压缩后)。如果增加这个大小,并且有比0.10.2更老的消费者,消费者的取数大小也必须增加,这样才能取到这么大的记录批。在最新的消息格式版本中,为了提高效率,记录总是被分组成批。在以前的消息格式版本中,未压缩的记录不会被分组成批,在这种情况下,这个限制只适用于单个记录。类型:int
默认值:1048588
有效值:[0,...]
服务器默认属性: message.max.bytes
重要性:中等
message.format.version
指定broker将使用的消息格式版本来追加消息到日志。该值应该是一个有效的ApiVersion。一些例子是 0.8.2, 0.9.0.0, 0.10.0, 查看ApiVersion了解更多细节。通过设置一个特定的消息格式版本,用户证明磁盘上所有现有的消息都小于或等于指定的版本。不正确地设置这个值会导致使用旧版本的消费者崩溃,因为他们会收到一个他们不理解的格式的消息。类型:string
默认:2.7-IV2
有效值。 [0.8.0、0.8.1、0.8.2、0.9.0、0.10.0-IV0、0.10.0-IV1、0.10.1-IV0、0.10.1-IV1、0.10.1-IV2、0.10.2-IV0、0.11.0-IV0、0.11.0-IV1、0.11.0-IV2、1.0-IV0、1. 1-IV0、2.0-IV0、2.0-IV1、2.1-IV0、2.1-IV1、2.1-IV2、2.2-IV0、2.2-IV1、2.3-IV0、2.3-IV1、2.4-IV0、2.4-IV1、2.5-IV0、2.6-IV0、2.7-IV0、2.7-IV1、2.7-IV2]
服务器默认属性:log.message.format.version
重要性:中等
message.timestamp.difference.max.ms
broker收到消息时的时间戳和消息中指定的时间戳之间允许的最大差异。如果 message.timestamp.type=CreateTime,如果时间戳的差异超过这个阈值,消息将被拒绝。如果 message.timestamp.type=LogAppendTime,这个配置会被忽略。类型:long
默认:9223372036854775807
有效值:[0,...]
服务器默认属性:log.message.timestamp.difference.max.ms
重要性:中等
message.timestamp.type
定义消息中的时间戳是消息创建时间还是日志追加时间。该值应该是`CreateTime`或`LogAppendTime`。类型:string
默认值: CreateTime
有效值: [CreateTime, LogAppendTime]
服务器默认属性:log.message.timestamp.type
重要性:中等
min.cleanable.dirty.ratio
此配置可控制日志压缩器尝试清理日志的频率(假设已启用日志压缩)。默认情况下,我们将避免清理日志中超过 50% 的日志已被压缩。这个比率限制了重复的日志所浪费的最大空间(在50%时,最多有50%的日志可能是重复的)。更高的比率意味着更少、更有效的清理,但意味着日志中浪费的空间更多。如果还指定了max.compaction.lag.ms或min.compaction.lag.ms配置,那么日志压缩器认为只要达到以下任一条件,该日志就有资格进行压缩。(i) 达到 dirty ratio 阈值,并且日志至少在 min.compaction.lag.ms 持续时间内有 dirty(未压缩)记录,或 (ii) 如果日志最多在 max.compaction.lag.ms 期间有 dirty(未压缩)记录,则日志压缩器认为有资格进行压缩。类型:double
默认值:0.5
有效值:[0,...,1]
服务器默认属性:log.cleaner.min.cleanable.ratio
重要性:中等
min.compaction.lag.ms
消息在日志中未压缩的最短时间。仅适用于正在压缩的日志。
类型:long
默认值:0
有效值:[0,...]
服务器默认属性:log.cleaner.min.compaction.lag.ms
重要性:中等
min.insync.replicas
当生产者将acks设置为 "all"(或"-1")时,这个配置指定了必须确认写入才能被认为是成功的最低数量的复制。如果不能满足这个最小数量,那么生产者将引发一个异常(NotEnoughReplicas或NotEnoughReplicasAfterAppend)。
当一起使用时,min.insync.replicas和acks允许你实施更大的耐久性保证。一个典型的场景是创建一个复制因子为3的主题,将min.insync.replicas设置为2,并以 "all "的acks进行生产。这将确保生产者在大多数副本没有收到写入时引发异常。类型:int
默认值:1
有效值:[1,...]
服务器默认属性:min.insync.replicas
重要性:中等
preallocate
当创建一个新的日志段时,如果我们应该在磁盘上预分配文件,则为真。类型:boolean
默认:false
有效值:
服务器默认属性:log.preallocate
重要性:中等
retention.bytes
如果我们使用 "删除 "保留策略,此配置可控制分区(由日志段组成)的最大大小,然后我们才会丢弃旧的日志段以释放空间。默认情况下,没有大小限制,只有时间限制。由于该限制是在分区级别执行的,因此将其乘以分区的数量来计算以字节为单位的主题保留。类型:long
默认值:-1
有效值:
服务器默认属性:log.retaining.bytes
重要性:中等
retention.ms
如果我们使用 "删除 "保留策略,此配置可控制我们在丢弃旧的日志段以释放空间之前保留日志的最长时间。这代表了消费者必须在多长时间内读取其数据的SLA。如果设置为-1,则不适用时间限制。类型:long
默认:604800000(7天)
有效值:[-1,...]
服务器默认属性:log.retention.ms
重要性:中等
segment.bytes
此配置控制日志的段文件大小。保留和清理总是以文件为单位进行的,因此较大的段大小意味着较少的文件,但对保留的精细控制较少。类型:int
默认值:1073741824 (1 gibibyte)
有效值: [14,...]
服务器默认属性:log.segment.bytes
重要性:中等
segment.index.bytes
这个配置控制了将偏移量映射到文件位置的索引的大小。我们预先分配这个索引文件,只有在日志滚动后才会将其缩小。一般来说,你不应该需要改变这个设置。类型:int
默认值:10485760(10 mebibytes)
有效值:[0,...]
服务器默认属性:log.index.size.max.bytes
重要性:中等
segment.jitter.ms
从预定的段滚动时间中减去的最大随机抖动,以避免雷鸣般的段滚动群。类型:long
默认值:0
有效值:[0,...]
服务器默认属性:log.roll.jitter.ms
重要性:中等
segment.ms
这个配置控制了一段时间后,即使段文件没有满,Kafka也会强制滚动日志,以确保留存可以删除或压缩旧数据。类型:long
默认:604800000(7天)
有效值:[1,...]
服务器默认属性:log.roll.ms
重要性:中等
unclean.leader.election.enable
表示是否启用不在 ISR 集中的副本作为最后手段被选为领导者,即使这样做可能会导致数据丢失。类型:boolean
默认:false
有效值
服务器默认属性:unclean.leader.election.enable
重要性:中等
message.downconversion.enable
此配置控制是否启用消息格式的向下转换以满足消费请求。当设置为false时,broker不会对期待旧消息格式的消费者执行向下转换。broker 会对来自此类旧客户的消费请求作出 UNSUPPORTED_VERSION 错误响应。此配置不适用于复制到跟随者时可能需要的任何消息格式转换。类型:boolean
默认:true
有效值:
服务器默认属性:log.message.downconversion.enable
重要性:低
3.3 生产者配置
下面是生产者的配置:
key.serializer
实现org.apache.kafka.common.serialization.Serializer接口的key的Serializer类。类型:class
默认值:
有效值:
重要性:高
value.serializer
实现 org.apache.kafka.common.serialization.Serializer 接口的值的 Serializer 类。类型:class
默认值:
有效值:
重要性:高
acks
生产者要求领导人在认为请求完成之前收到的确认次数。这控制了发送记录的耐久性。允许以下设置。acks=0 如果设置为0,那么生产者将完全不等待服务器的任何确认。记录将立即被添加到套接字缓冲区中,并被视为已发送。在这种情况下,不能保证服务器已经收到了记录,重试配置也不会生效(因为客户端一般不会知道任何失败)。每条记录回馈的偏移量将始终设置为-1。
acks=1 这意味着领导者将把记录写到它的本地日志中,但不需要等待所有跟随者的完全确认就会做出回应。在这种情况下,如果领导者在确认记录后,但在追随者复制记录之前立即失败,那么记录将丢失。
acks=all 这意味着领导者将等待所有同步复制的记录确认。这保证了只要至少有一个同步复制体还活着,记录就不会丢失。这是最强的可用保证。这相当于 acks=-1 设置。
类型 : string
默认值:1
有效值:[all, -1, 0, 1]
重要性:高
bootstrap.servers
用于建立Kafka集群初始连接的主机/端口对的列表。客户端将使用所有的服务器,不管这里指定了哪些服务器用于引导--这个列表只影响用于发现全部服务器集的初始主机。这个列表的形式应该是 host1:port1,host2:port2,....。因为这些服务器只是用于初始连接,以发现完整的集群成员(可能会动态变化),所以这个列表不需要包含完整的服务器集(不过,你可能需要多个服务器,以防某个服务器宕机)。类型:list
默认:""
有效值:non-null string
重要性:高
buffer.memory
生产者可以用来缓冲等待发送到服务器的记录的总内存字节数。如果记录的发送速度超过了服务器的发送速度,那么生产者就会缓冲max.block.ms,之后就会抛出一个异常。这个设置应该与生产者将使用的总内存大致对应,但并不是一个硬约束,因为生产者使用的内存并不都是用来缓冲的。一些额外的内存将被用于压缩(如果启用了压缩)以及维护飞行中的请求。
类型:long
默认:33554432
有效值:[0,...]
重要性:高
compression.type
生产者生成的所有数据的压缩类型。默认值是none(即无压缩)。有效值为none、gzip、snappy、lz4或zstd。压缩的是整批的数据,所以批处理的功效也会影响压缩比(批处理越多意味着压缩效果越好)。类型:string
默认:none
有效值:
重要性:高
retries
设置一个大于零的值,将导致客户端重新发送任何发送失败的记录,并可能出现短暂的错误。请注意,这种重试与客户端在收到错误后重新发送记录没有区别。允许重试而不将max.in.flight.request.per.connection设置为1,将有可能改变记录的顺序,因为如果向一个分区发送两批记录,第一批失败并重试,但第二批成功,那么第二批的记录可能会先出现。另外需要注意的是,如果delivery.timeout.ms配置的超时时间在成功确认前先过期,那么在重试次数用完之前,produce请求就会失败。一般来说,用户最好不要设置这个配置,而是使用delivery.timeout.ms来控制重试行为。类型:int
默认:2147483647
有效值: [0,...,2147483647]
重要性:高
ssl.key.password
密钥存储文件中私钥的密码,或在`ssl.keystore.key'中指定的PEM密钥。只有在配置了双向身份验证的情况下,客户端才需要这个密码。类型:password
默认值: null
有效值:
重要性:高
ssl.keystore.certificate.chain
证书链的格式由'ssl.keystore.type'指定。默认的SSL引擎工厂只支持PEM格式的X.509证书列表。类型:password
默认值: null
有效值:
重要性:高
ssl.keystore.key
私钥的格式由'ssl.keystore.type'指定。默认SSL引擎工厂只支持PEM格式的PKCS#8密钥。如果密钥是加密的,必须使用'ssl.key.password'指定密钥密码。类型:password
默认值: null
有效值。
重要性:高
ssl.keystore.location
密钥存储文件的位置。对客户端来说是可选的,可以用于客户端的双向认证。类型:string
默认值: null
有效值:
重要性:高
ssl.keystore.password
密钥存储文件的存储密码。这对客户端来说是可选的,只有在配置了'ssl.keystore.location'时才需要。对于PEM格式,不支持密钥存储密码。类型:password
默认值: null
有效值。
重要性:高
ssl.truststore.certificates
可信证书的格式由'ssl.truststore.type'指定。默认SSL引擎工厂只支持PEM格式的X.509证书。类型:password
默认值: null
有效值。
重要性:高
ssl.truststore.location
信任存储文件的位置。类型:string
默认值: null
有效值。
重要性:高
ssl.truststore.password
信任存储文件的密码。如果没有设置密码,则仍然使用配置的信任存储文件,但完整性检查被禁用。PEM格式不支持信任存储密码。类型:password
默认值: null
有效值。
重要性:高
batch.size
每当多个记录被发送到同一个分区时,生产者会尝试将记录一起批处理成较少的请求。这有助于提高客户端和服务器的性能。这个配置控制默认的批处理大小,单位是字节。不会尝试将大于此大小的记录批量化。
发送给broker的请求将包含多个批次,每个具有可发送数据的分区都有一个批次。
批量小会使批处理不常见,并可能会降低吞吐量(批量为零会完全禁止批处理)。一个非常大的批次大小可能会更浪费地使用内存,因为我们总是会分配一个指定的批次大小的缓冲区,以应对额外的记录。
类型:int
默认值:16384
有效值:[0,...]
重要性:中等
client.dns.lookup
控制客户端如何使用DNS查找。如果设置为use_all_dns_ips,则依次连接到每个返回的IP地址,直到成功建立连接。断开连接后,会使用下一个IP。一旦所有的IP都被使用过一次,客户端就会再次解析主机名中的IP(然而,JVM和操作系统都会缓存DNS名称查询)。如果设置为resolve_canonical_bootstrap_servers_only,则将每个引导地址解析成一个canonical名称列表。在引导阶段之后,这和use_all_dns_ips的行为是一样的。如果设置为默认(已废弃),即使查找返回多个IP地址,也会尝试连接到查找返回的第一个IP地址。类型:string
默认值: use_all_dns_ips
有效值。 [default, use_all_dns_ips, resolve_canonical_bootstrap_servers_only] 。
重要性:中等
client.id
一个ID字符串,在发出请求时传递给服务器。这样做的目的是为了在服务器端请求日志中包含一个逻辑应用程序名称,从而能够跟踪请求的来源,而不仅仅是ip/端口。类型:string
默认:""
有效值。
重要性:中等
connections.max.idle.ms
在该配置指定的毫秒数之后关闭空闲连接。类型:long
默认:540000(9分钟)
有效值:
重要性:中等
delivery.timeout.ms
调用send()返回后报告成功或失败的时间的上限。这限制了记录在发送前被延迟的总时间,等待broker确认的时间(如果预期),以及允许的可重复发送失败的时间。如果遇到不可恢复的错误,重试次数已经用尽,或者记录被添加到一个达到较早发送到期期限的批次中,生产者可能会报告未能在这个配置之前发送记录。这个配置的值应该大于或等于 request.timeout.ms 和 linger.ms 之和。类型:int
默认:120000(2分钟)
有效值:[0,...]
重要性:中等
linger.ms
制作者将请求传输之间到达的所有记录归为一个单一的批量请求。通常只有在负载下,当记录到达的速度超过了它们的发送速度时,才会出现这种情况。然而在某些情况下,即使在中等负载下,客户端也可能希望减少请求的数量。这个设置通过添加少量的人为延迟来实现--也就是说,生产者不会立即发送一条记录,而是会等待到给定的延迟,以允许其他记录被发送,这样就可以将这些记录一起打包发送。这可以被认为是类似于TCP中的Nagle算法。这个设置给出了批处理延迟的上限:一旦我们得到一个分区的 batch.size 值的记录,不管这个设置如何,它都会立即被发送,但是如果我们为这个分区积累的字节数少于这个数,我们就会在指定的时间内 "滞留",等待更多记录的出现。这个设置默认为0(即没有延迟)。例如,设置linger.ms=5,会减少发送请求的数量,但在没有负载的情况下,发送的记录会增加5ms的延迟。类型:long
默认值:0
有效值:[0,...]
重要性:中等
max.block.ms
该配置控制KafkaProducer的send()、partitionsFor()、initTransactions()、sendOffsetsToTransaction()、commitTransaction()和abortTransaction()方法阻塞的时间。对于send()来说,这个超时限制了等待元数据获取和缓冲区分配的总时间(用户提供的序列器或分区器中的阻塞不计入这个超时)。对于partitionsFor()来说,如果元数据不可用,这个超时就会限制等待元数据的时间。与事务相关的方法总是阻塞,但如果事务协调器不能被发现或没有在超时内响应,则可能超时。类型:long
默认:60000(1分钟)
有效值:[0,...]
重要性:中等
max.request.size
请求的最大大小,单位是字节。这个设置将限制制作者在一次请求中发送的记录批次数量,以避免发送巨大的请求。这实际上也是对未压缩的最大记录批次大小的一个上限。请注意,服务器有自己的记录批量大小的上限(如果启用了压缩,则在压缩后),可能与此不同。类型:int
默认值:1048576
有效值:[0,...]
重要性:中等
partitioner.class
Partitioner类,实现了org.apache.kafka.client.producer.Partitioner接口。类型:class
默认值:org.apache.kafka.client.producer.internals.DefaultPartitioner。
有效值:
重要性:中等
receive.buffer.bytes
读取数据时要使用的TCP接收缓冲区(SO_RCVBUF)的大小。如果该值为-1,则使用OS默认值。类型:int
默认值:32768(32 kibibytes)
有效值:[-1,...]
重要性:中等
request.timeout.ms
该配置控制客户端等待请求响应的最长时间。如果在超时之前没有收到响应,客户端将在必要时重新发送请求,或者在重试次数用尽时失败请求。这个值应该大于 replica.lag.time.max.ms(一种broker配置),以减少由于不必要的生产者重试而导致消息重复的可能性。类型:int
默认:30000(30秒)
有效值:[0,...]
重要性:中等
sasl.client.callback.handler.class
实现AuthenticateCallbackHandler接口的SASL客户端回调处理程序类的全称。类型:class
默认值: null
有效值:
重要性:中等
sasl.jaas.config
JAAS登录上下文参数,用于SASL连接,格式为JAAS配置文件使用的格式。JAAS配置文件的格式在这里有介绍。值的格式为:'loginModuleClass controlFlag (optionName=optionValue)*;'。对于broker来说,配置必须以监听器前缀和SASL机制名称为前缀,并以小写字母表示。例如,listener.name.sasl_ssl.scram-sha-256.sasl.jaas.config=com.exam.ScramLoginModule必填。类型:password
默认值: null
有效值。
重要性:中等
sasl.kerberos.service.name
Kafka 运行的 Kerberos 主体名称。这可以在Kafka的JAAS配置或Kafka的配置中定义。类型:string
默认值: null
有效值。
重要性:中等
sasl.login.callback.handler.class
实现AuthenticateCallbackHandler接口的SASL登录回调处理程序类的完全限定名称。对于broker来说,登录回调处理程序配置必须以监听器前缀和小写的SASL机制名称为前缀。例如,listener.name.sasl_ssl.scram-sha-256.sasl.login.callback.handler.class=com.example.CustomScramLoginCallbackHandler。类型:class
默认值: null
有效值。
重要性:中等
sasl.login.class
实现Login接口的类的全称。对于broker来说,login config必须以监听器前缀和SASL机制名称为前缀,并使用小写。例如,listener.name.sasl_ssl.scram-sha-256.sasl.login.class=com.example.CustomScramLogin。类型:class
默认值: null
有效值。
重要性:中等
sasl.mechanism
用于客户端连接的SASL机制。这可以是任何有安全提供者的机制。GSSAPI是默认机制。类型:string
默认值。 GSSAPI
有效值。
重要性:中等
security.protocol
用于与broker通信的协议。有效值是: PLAINTEXT, SSL, SASL_PLAINTEXT, SASL_SSL.类型:string
默认值。 PLAINTEXT
有效值。
重要性:中等
send.buffer.bytes
发送数据时要使用的TCP发送缓冲区(SO_SNDBUF)的大小。如果该值为-1,则使用OS默认值。类型:int
默认值:131072 (128 kibibytes)
有效值:[-1,...]
重要性:中等
socket.connection.setup.timeout.max.ms
客户端等待建立套接字连接的最大时间。连接设置超时时间将随着每一次连续的连接失败而成倍增加,直到这个最大值。为了避免连接风暴,超时时间将被应用于0.2的随机系数,结果是低于计算值20%到高于计算值20%的随机范围。类型:long
默认:127000(127秒)
有效值:
重要性:中等
socket.connection.setup.timeout.ms
客户端等待socket连接建立的时间。如果在超时之前没有建立连接,客户端将关闭socket通道。类型:long
默认:10000(10秒)
有效值。
重要性:中等
ssl.enabled.protocols
为SSL连接启用的协议列表。默认值是 "TLSv1.2,TLSv1.3",当运行Java 11或更新版本时,否则为 "TLSv1.2"。在Java 11的默认值下,如果客户端和服务器都支持TLSv1.3,则会优先选择TLSv1.3,否则会回退到TLSv1.2(假设两者都至少支持TLSv1.2)。这个默认值在大多数情况下应该是没有问题的。也可以参考`ssl.protocol`的配置文档。类型:list
默认值: TLSv1.2
有效值。
重要性:中等
ssl.keystore.type
密钥存储文件的文件格式。对客户端来说是可选的。类型:string
默认值。 JKS
有效值。
重要性:中等
ssl.protocol
用来生成SSLContext的SSL协议,默认为'TLSv1.3',否则为'TLSv1.2'。当运行Java 11或更新版本时,默认为'TLSv1.3',否则为'TLSv1.2'。这个值对于大多数的使用情况来说应该是没有问题的。在最近的JVM中允许的值是'TLSv1.2'和'TLSv1.3'。TLS','TLSv1.1','SSL','SSLv2'和'SSLv3'在旧的JVM中可能会被支持,但由于已知的安全漏洞,我们不鼓励使用它们。在这个配置和'ssl.enabled.protocols'的默认值下,如果服务器不支持'TLSv1.3',客户端将降级为'TLSv1.2'。如果这个配置被设置为'TLSv1.2',即使是ssl.enabled.protocols中的一个值,并且服务器只支持'TLSv1.3',客户端也不会使用'TLSv1.3'。类型:string
默认值: TLSv1.2
有效值。
重要性:中等
ssl.provider
用于SSL连接的安全提供者的名称。默认值是JVM的默认安全提供者。类型:string
默认值: null
有效值。
重要性:中等
ssl.truststore.type
信任存储文件的文件格式。类型:string
默认值。 JKS
有效值。
重要性:中等
enable.idempotence
当设置为'true'时,生产者将确保每条消息的副本正好写在流中。如果为'false',生产者因broker故障等原因重试,可能会将重试的消息重复写入流中。注意,启用idempotence需要max.in.flight.request.per.connection小于或等于5,重试大于0,acks必须是'all'。如果用户没有明确设置这些值,将选择合适的值。如果设置了不兼容的值,将抛出一个ConfigException。类型:boolean
默认:假
有效值。
重要性:低
interceptor.classes
作为拦截器使用的类的列表。实现org.apache.kafka.clients.producer.ProducerInterceptor接口,可以让你在记录发布到Kafka集群之前,拦截(并可能突变)生产者收到的记录。默认情况下,没有拦截器。类型:list
默认:""
有效值:非空字符串
重要性:低
max.in.flight.requests.per.connection
客户端在阻断之前在单个连接上发送的未确认请求的最大数量。请注意,如果此设置大于1,并且发送失败,则有可能因重试而重新排序消息(即,如果启用了重试)。类型:int
默认值:5
有效值:[1,...]
重要性:低
metadata.max.age.ms
即使我们没有看到任何分区领导权变化,我们也会强制刷新元数据,以主动发现任何新的broker或分区的时间,以毫秒为单位。类型:长
默认:300000(5分钟)
有效值:[0,...]
重要性:低
metadata.max.idle.ms
控制生产者为空闲的主题缓存元数据的时间。如果一个主题最后一次被生产出来后的时间超过了元数据的空闲时间,那么这个主题的元数据就会被遗忘,下一次访问它时将强制执行元数据获取请求。类型:长
默认:300000(5分钟)
有效值:[5000,...]
重要性:低
metric.reporters
作为度量报告器使用的类的列表。实现org.apache.kafka.common.metrics.MetricsReporter接口允许插入将被通知新的度量创建的类。JmxReporter总是被包含在注册JMX统计数据中。类型:list
默认:""
有效值:非空字符串
重要性:低
metrics.num.samples
为计算指标而维护的样本数量。类型:int
默认值:2
有效值:[1,...]
重要性:低
metrics.recording.level
指标的最高记录级别。类型:string
默认:INFO
有效值:[INFO, DEBUG, TRACE]
重要性:低
metrics.sample.window.ms
度量样本计算的时间窗口。类型:长
默认:30000(30秒)
有效值:[0,...]
重要性:低
reconnect.backoff.max.ms
当重新连接到一个反复连接失败的broker时,等待的最大时间,以毫秒为单位。如果提供,每台主机的backoff将在每一次连续连接失败时以指数形式增加,直到这个最大值。在计算背离增加后,20%的随机抖动被添加到避免连接风暴中。类型:长
默认:1000(1秒)
有效值:[0,...]
重要性:低
reconnect.backoff.ms
试图重新连接到给定主机前的基本等待时间。这可以避免在一个紧密的循环中重复连接到主机。这个backoff适用于客户端到broker的所有连接尝试。类型:long
默认值:50
有效值:[0,...]
重要性:低
retry.backoff.ms
试图重试给定主题分区的失败请求前的等待时间。这可以避免在某些失败情况下,在一个紧密的循环中重复发送请求。类型:long
默认值:100
有效值:[0,...]
重要性:低
sasl.kerberos.kinit.cmd
Kerberos kinit 命令路径。类型:string
默认值:/usr/bin/kinit
有效值:
重要性:低
sasl.kerberos.min.time.before.relogin
登录线程刷新尝试之间的睡眠时间。类型:long
默认值:60000
有效值。
重要性:低
sasl.kerberos.ticket.renew.jitter
随机抖动加到续航时间的百分比。类型:double
默认值:0.05
有效值。
重要性:低
sasl.kerberos.ticket.renew.window.factor
登录线程将休眠,直到达到从上次刷新到票据到期的指定时间窗口系数,这时它将尝试更新票据。类型:double
默认值:0.8
有效值。
重要性:低
sasl.login.refresh.buffer.seconds
刷新凭证时,在凭证到期前要保持的缓冲时间,以秒为单位。如果刷新的时间离到期时间比缓冲秒数更近,那么刷新时间将被提前,以尽可能多地保持缓冲时间。法定值在0到3600(1小时)之间;如果没有指定值,则使用默认值300(5分钟)。如果该值和sasl.login.refresh.min.period.seconds的总和超过了凭证的剩余寿命,则该值和sasl.login.refresh.min.period.seconds都会被忽略。目前只适用于OAUTHBEARER。类型:short
默认值:300
有效值:[0,...,3600]
重要性:低
sasl.login.refresh.min.period.seconds
登录刷新线程在刷新凭证前需要等待的最短时间,以秒为单位。合法值在0到900(15分钟)之间;如果没有指定值,则使用默认值60(1分钟)。如果这个值和sasl.login.refresh.buffer.seconds的总和超过了一个凭证的剩余寿命,那么这个值和sasl.login.buffer.seconds都会被忽略。目前只适用于OAUTHBEARER。类型:short
默认值:60
有效值: [0,...,900]
重要性:低
sasl.login.refresh.window.factor
登录刷新线程将休眠,直到达到相对于凭证寿命的指定窗口系数,此时将尝试刷新凭证。合法值在0.5(50%)到1.0(100%)之间,如果没有指定值,则使用默认值0.8(80%)。目前仅适用于OAUTHBEARER。类型:double
默认值:0.8
有效值: [0.5,...,1.0]
重要性:低
sasl.login.refresh.window.jitter
相对于凭证的寿命,加到登录刷新线程的睡眠时间的最大随机抖动量。合法值在0到0.25(25%)之间,如果没有指定值,则使用默认值0.05(5%)。目前只适用于OAUTHBEARER。类型:double
默认值:0.05
有效值:[0.0,...,0.25]
重要性:低
security.providers
一个可配置的创建者类的列表,每个类都返回一个实现安全算法的提供者。这些类应该实现org.apache.kafka.common.security.ah.SecurityProviderCreator接口。类型:string
默认值: null
有效值。
重要性:低
ssl.cipher.suites
密码套件的列表。这是一个命名的认证、加密、MAC和密钥交换算法的组合,用于使用TLS或SSL网络协议协商网络连接的安全设置。默认情况下,支持所有可用的密码套件。类型:list
默认值: null
有效值。
重要性:低
ssl.endpoint.identification.algorithm
使用服务器证书验证服务器主机名的端点识别算法。类型:string
默认:https
有效值。
重要性:低
ssl.engine.factory.class
org.apache.kafka.common.security.auth.SslEngineFactory类型的类来提供SSLEngine对象。默认值是org.apache.kafka.common.security.ssl.DefaultSslEngineFactory。类型:class
默认值: null
有效值。
重要性:低
ssl.keymanager.algorithm
钥匙管理器工厂用于SSL连接的算法,默认值是为Java虚拟机配置的钥匙管理器工厂算法。默认值是为Java虚拟机配置的密钥管理器工厂算法。类型:string
默认值。 SunX509
有效值。
重要性:低
ssl.secure.random.implementation
用于SSL加密操作的SecureRandom PRNG实现。类型:string
默认值: null
有效值。
重要性:低
ssl.trustmanager.algorithm
信任管理器工厂用于SSL连接的算法。默认值是为Java虚拟机配置的信任管理器工厂算法。类型:string
默认值。 PKIX
有效值。
重要性:低
transaction.timeout.ms
事务协调器在主动中止正在进行的事务之前,等待生产者的事务状态更新的最大时间,单位为ms。如果这个值大于broker中的transaction.max.timeout.ms设置,请求将以InvalidTxnTimeoutException错误失败。类型:int
默认:60000(1分钟)
有效值。
重要性:低
transactional.id
用于事务交付的TransactionalId。这可以实现跨越多个生产者会话的可靠性语义,因为它允许客户端保证使用相同TransactionalId的事务在开始任何新事务之前已经完成。如果没有提供TransactionalId,那么生产者只能进行幂等交付。如果配置了TransactionalId,则会隐含enable.idempotence。默认情况下,TransactionId没有配置,这意味着不能使用事务。请注意,默认情况下,事务需要至少三个broker的集群,这是生产中的推荐设置;对于开发,你可以改变这一点,通过调整broker设置transaction.state.log.replication.factor。类型:string
默认值: null
有效值:非空字符串
重要性:低
3.4 消费者配置
下面是消费者的配置:
key.deserializer
实现org.apache.kafka.common.serialization.Deserializer接口的key的Deserializer类。类型:class
默认值。
有效值。
重要性:高
value.deserializer
实现 org.apache.kafka.common.serialization.Deserializer 接口的值的 Deserializer 类。类型:class
默认值。
有效值。
重要性:高
bootstrap.servers
用于建立Kafka集群初始连接的主机/端口对的列表。客户端将使用所有的服务器,不管这里指定了哪些服务器用于引导--这个列表只影响用于发现全部服务器集的初始主机。这个列表的形式应该是 host1:port1,host2:port2,....。因为这些服务器只是用于初始连接,以发现完整的集群成员(可能会动态变化),所以这个列表不需要包含完整的服务器集(不过,你可能需要多个服务器,以防某个服务器宕机)。类型:list
默认:""
有效值:非空字符串
重要性:高
fetch.min.bytes
服务器对一个取数请求应返回的最小数据量。如果没有足够的数据,请求将等待积累这么多数据后再回复请求。默认设置为1个字节,意味着只要有一个字节的数据可用,取回请求就会被响应,或者取回请求超时等待数据到达。将其设置为大于1会导致服务器等待更多的数据积累,这可以提高服务器的吞吐量,但代价是一些额外的延迟。类型:int
默认值:1
有效值:[0,...]
重要性:高
group.id
一个唯一的字符串,用于标识此消费者所属的消费者组。如果消费者通过使用 subscribe(topic) 或基于 Kafka 的偏移管理策略使用组管理功能,则需要此属性。类型:string
默认值: null
有效值。
重要性:高
heartbeat.interval.ms
使用Kafka的群组管理设施时,消费者协调人的预期心跳间隔时间。心跳用于确保消费者的会话保持活跃,并在新消费者加入或离开组时方便重新平衡。该值必须设置为低于session.timeout.ms,但通常不应设置为高于该值的1/3。它可以调整得更低,以控制正常重新平衡的预期时间。类型:int
默认:3000(3秒)
有效值。
重要性:高
max.partition.fetch.bytes
服务器将返回的每个分区的最大数据量。消费者会分批取回记录。如果取回的第一个非空分区中的第一个记录批次大于此限制,则仍将返回该批次,以确保消费者能够取得进展。broker接受的最大记录批次大小通过 message.max.bytes(broker 配置)或 max.message.bytes(topic 配置)来定义。请参阅 fetch.max.bytes 来限制消费者请求的大小。类型:int
默认值:1048576(1 mebibyte)
有效值:[0,...]
重要性:高
session.timeout.ms
当使用Kafka的组管理设施时,用于检测客户端故障的超时。客户端会定期发送心跳来向broker表示其活跃度。如果在该会话超时结束前,broker没有收到心跳,那么broker将从组中删除该客户端,并启动重新平衡。请注意,该值必须在broker配置中通过 group.min.session.timeout.ms 和 group.max.session.timeout.ms 配置的允许范围内。类型:int
默认:10000(10秒)
有效值。
重要性:高
ssl.key.password
密钥存储文件中私钥的密码,或在`ssl.keystore.key'中指定的PEM密钥。只有在配置了双向身份验证的情况下,客户端才需要这个密码。类型:password
默认值: null
有效值。
重要性:高
ssl.keystore.certificate.chain
证书链的格式由'ssl.keystore.type'指定。默认的SSL引擎工厂只支持PEM格式的X.509证书列表。类型:password
默认值: null
有效值。
重要性:高
ssl.keystore.key
私钥的格式由'ssl.keystore.type'指定。默认SSL引擎工厂只支持PEM格式的PKCS#8密钥。如果密钥是加密的,必须使用'ssl.key.password'指定密钥密码。类型:password
默认值: null
有效值。
重要性:高
ssl.keystore.location
密钥存储文件的位置。对客户端来说是可选的,可以用于客户端的双向认证。类型:字符串
默认值: null
有效值。
重要性:高
ssl.keystore.password
密钥存储文件的存储密码。这对客户端来说是可选的,只有在配置了'ssl.keystore.location'时才需要。对于PEM格式,不支持密钥存储密码。类型:password
默认值: null
有效值。
重要性:高
ssl.truststore.certificate
可信证书的格式由'ssl.truststore.type'指定。默认SSL引擎工厂只支持PEM格式的X.509证书。类型:password
默认值: null
有效值。
重要性:高
ssl.truststore.location
信任存储文件的位置。类型:字符串
默认值: null
有效值。
重要性:高
ssl.truststore.password
信任存储文件的密码。如果没有设置密码,则仍然使用配置的信任存储文件,但完整性检查被禁用。PEM格式不支持信任存储密码。类型:password
默认值: null
有效值。
重要性:高
allow.auto.create.topics
当订阅或分配一个主题时,允许在broker上自动创建主题。只有当broker使用`auto.create.topic.enable`broker配置允许时,才会自动创建被订阅的主题。当使用老于0.11.0的broker时,此配置必须设置为 "false"。类型:布尔值
默认:true
有效值。
重要性:中等
auto.offset.reset
当Kafka中没有初始偏移量或者当前偏移量在服务器上不存在了(比如因为该数据已经被删除),该怎么办。最早:自动将偏移量重置为最早的偏移量。
latest:自动将偏移量重置为最新的偏移量。
none:如果消费者的组没有找到以前的偏移量,则向消费者抛出异常。
其他任何东西:向消费者抛出异常。
类型:字符串
默认:latest
有效值:[latest, earliest, none]
重要性:中等
client.dns.lookup
控制客户端如何使用DNS查找。如果设置为use_all_dns_ips,则依次连接到每个返回的IP地址,直到成功建立连接。断开连接后,会使用下一个IP。一旦所有的IP都被使用过一次,客户端就会再次解析主机名中的IP(然而,JVM和操作系统都会缓存DNS名称查询)。如果设置为resolve_canonical_bootstrap_servers_only,则将每个引导地址解析成一个canonical名称列表。在引导阶段之后,这和use_all_dns_ips的行为是一样的。如果设置为默认(已废弃),即使查找返回多个IP地址,也会尝试连接到查找返回的第一个IP地址。类型:字符串
默认值: use_all_dns_ips
有效值。 [default, use_all_dns_ips, resolve_canonical_bootstrap_servers_only] 。
重要性:中等
connections.max.idle.ms
在该配置指定的毫秒数之后关闭空闲连接。类型:long
默认:540000(9分钟)
有效值。
重要性:中等
default.api.timeout.ms
指定客户端API的超时时间(以毫秒为单位)。此配置被用作所有未指定超时参数的客户端操作的默认超时。类型:int
默认:60000(1分钟)
有效值:[0,...]
重要性:中等
enable.auto.commit
如果为真,消费者的偏移量将在后台定期提交。类型:布尔值
默认:true
有效值。
重要性:中等
exclude.internal.topics
是否应将与订阅模式相匹配的内部主题从订阅中排除。总是可以明确地订阅一个内部主题。类型:布尔值
默认:true
有效值。
重要性:中等
fetch.max.bytes
服务器对于一个取数请求应该返回的最大数据量。消费者会分批取回记录,如果取回的第一个非空分区中的第一个记录批次大于这个值,则仍会返回该记录批次,以保证消费者能够取得进展。因此,这不是一个绝对的最大值。broker接受的最大记录批次大小是通过message.max.bytes(broker配置)或max.message.bytes(topic配置)来定义的。请注意,消费者会并行执行多个获取。类型:int
默认值:52428800(50 mebibytes)。
有效值:[0,...]
重要性:中等
group.instance.id
终端用户提供的消费者实例的唯一标识符。只允许使用非空字符串。如果设置,消费者将被视为静态成员,这意味着在任何时候,消费者组中只允许有一个具有此ID的实例。这可以与较大的会话超时结合使用,以避免因短暂的不可用性(如进程重启)而引起的组重新平衡。如果不设置,消费者将作为动态成员加入组,这是传统行为。类型:字符串
默认值: null
有效值。
重要性:中等
isolation.level
控制如何读取以事务方式写入的消息。如果设置为read_committed,consumer.poll()将只返回已经提交的事务性消息。如果设置为read_uncommitted(默认值),consumer.poll()将返回所有消息,甚至是已经中止的事务性消息。非事务性消息在任何一种模式下都会无条件返回。消息总是按偏移量顺序返回。因此,在read_committed模式下,consumer.poll()将只返回直到最后一个稳定偏移量(LSO)的消息,也就是比第一个打开的事务的偏移量小的那个。特别是在属于正在进行的事务的消息之后出现的任何消息将被扣留,直到相关事务完成。因此,当存在飞行中的事务时,read_committed消费者将无法读到高水印。
此外,当处于read_committed时,seekToEnd方法将返回LSO的
类型:字符串
默认值:read_uncommitted
有效值:[read_committed, read_uncommitted]。 [read_committed, read_uncommitted]
重要性:中等
max.poll.interval.ms
使用消费者组管理时,poll()调用之间的最大延迟。这对消费者在获取更多记录之前可以闲置的时间设置了一个上限。如果poll()在这个超时时间到期前没有被调用,那么消费者被认为失败,组将重新平衡,以便将分区重新分配给另一个成员。对于使用非空的group.instance.id的消费者,如果达到这个超时,分区将不会立即被重新分配。相反,消费者将停止发送心跳,分区将在 session.timeout.ms 过期后重新分配。这反映了已关闭的静态消费者的行为。类型:int
默认:300000(5分钟)
有效值:[1,...]
重要性:中等
max.poll.records
单次调用poll()时返回的最大记录数。类型:int
默认值:500
有效值:[1,...]
重要性:中等
partition.assignment.strategy
支持的分区分配策略的类名或类类型列表,按偏好排序,当使用分组管理时,客户端将使用这些策略在消费者实例之间分配分区所有权。除了下面指定的默认类之外,您还可以使用org.apache.kafka.clients.consumer.RoundRobinAssignorclass对消费者进行分区的循环分配。
实现org.apache.kafka.clients.consumer.ConsumerPartitionAssignor接口可以让你插入一个自定义的分配策略。
类型:list
默认值:class org.apache.kafka.client.consumer.RangeAssignor。
有效值:非空字符串
重要性:中等
receive.buffer.bytes
读取数据时要使用的TCP接收缓冲区(SO_RCVBUF)的大小。如果该值为-1,则使用OS默认值。类型:int
默认值:65536(64 kibibytes)
有效值:[-1,...]
重要性:中等
request.timeout.ms
该配置控制客户端等待请求响应的最长时间。如果在超时之前没有收到响应,客户端将在必要时重新发送请求,或者在重试次数耗尽时失败。类型:int
默认:30000(30秒)
有效值:[0,...]
重要性:中等
sasl.client.callback.handler.class
实现AuthenticateCallbackHandler接口的SASL客户端回调处理程序类的全称。类型:class
默认值: null
有效值。
重要性:中等
sasl.jaas.config
JAAS登录上下文参数,用于SASL连接,格式为JAAS配置文件使用的格式。JAAS配置文件的格式在这里有介绍。值的格式为:'loginModuleClass controlFlag (optionName=optionValue)*;'。对于broker来说,配置必须以监听器前缀和SASL机制名称为前缀,并以小写字母表示。例如,listener.name.sasl_ssl.scram-sha-256.sasl.jaas.config=com.exam.ScramLoginModule必填。类型:password
默认值: null
有效值。
重要性:中等
sasl.kerberos.service.name
Kafka 运行的 Kerberos 主体名称。这可以在Kafka的JAAS配置或Kafka的配置中定义。类型:string
默认值: null
有效值。
重要性:中等
sasl.login.callback.handler.class
实现AuthenticateCallbackHandler接口的SASL登录回调处理程序类的完全限定名称。对于broker来说,登录回调处理程序配置必须以监听器前缀和小写的SASL机制名称为前缀。例如,listener.name.sasl_ssl.scram-sha-256.sasl.login.callback.handler.class=com.example.CustomScramLoginCallbackHandler。类型:class
默认值: null
有效值。
重要性:中等
sasl.login.class
实现Login接口的类的全称。对于broker来说,login config必须以监听器前缀和SASL机制名称为前缀,并使用小写。例如,listener.name.sasl_ssl.scram-sha-256.sasl.login.class=com.example.CustomScramLogin。类型:类
默认值: null
有效值。
重要性:中等
sasl.mechanism
用于客户端连接的SASL机制。这可以是任何有安全提供者的机制。GSSAPI是默认机制。类型:string
默认值。 GSSAPI
有效值。
重要性:中等
security.protocol
用于与broker通信的协议。有效值是: PLAINTEXT, SSL, SASL_PLAINTEXT, SASL_SSL.类型:string
默认值。 PLAINTEXT
有效值。
重要性:中等
send.buffer.bytes
发送数据时要使用的TCP发送缓冲区(SO_SNDBUF)的大小。如果该值为-1,则使用OS默认值。类型:int
默认值:131072 (128 kibibytes)
有效值:[-1,...]
重要性:中等
socket.connection.setup.timeout.max.ms
客户端等待建立套接字连接的最大时间。连接设置超时时间将随着每一次连续的连接失败而成倍增加,直到这个最大值。为了避免连接风暴,超时时间将被应用于0.2的随机系数,结果是低于计算值20%到高于计算值20%的随机范围。类型:long
默认:127000(127秒)
有效值。
重要性:中等
socket.connection.setup.timeout.ms
客户端等待socket连接建立的时间。如果在超时之前没有建立连接,客户端将关闭socket通道。类型:long
默认:10000(10秒)
有效值。
重要性:中等
ssl.enabled.protocols
为SSL连接启用的协议列表。默认值是 "TLSv1.2,TLSv1.3",当运行Java 11或更新版本时,否则为 "TLSv1.2"。在Java 11的默认值下,如果客户端和服务器都支持TLSv1.3,则会优先选择TLSv1.3,否则会回退到TLSv1.2(假设两者都至少支持TLSv1.2)。这个默认值在大多数情况下应该是没有问题的。也可以参考`ssl.protocol`的配置文档。类型:list
默认值: TLSv1.2
有效值。
重要性:中等
ssl.keystore.type
密钥存储文件的文件格式。对客户端来说是可选的。类型:string
默认值。 JKS
有效值。
重要性:中等
ssl.protocol
用来生成SSLContext的SSL协议,默认为'TLSv1.3',否则为'TLSv1.2'。当运行Java 11或更新版本时,默认为'TLSv1.3',否则为'TLSv1.2'。这个值对于大多数的使用情况来说应该是没有问题的。在最近的JVM中允许的值是'TLSv1.2'和'TLSv1.3'。TLS','TLSv1.1','SSL','SSLv2'和'SSLv3'在旧的JVM中可能会被支持,但由于已知的安全漏洞,我们不鼓励使用它们。在这个配置和'ssl.enabled.protocols'的默认值下,如果服务器不支持'TLSv1.3',客户端将降级为'TLSv1.2'。如果这个配置被设置为'TLSv1.2',即使是ssl.enabled.protocols中的一个值,并且服务器只支持'TLSv1.3',客户端也不会使用'TLSv1.3'。类型:string
默认值: TLSv1.2
有效值。
重要性:中等
ssl.provider
用于SSL连接的安全提供者的名称。默认值是JVM的默认安全提供者。类型:string
默认值: null
有效值。
重要性:中等
ssl.truststore.type
信任存储文件的文件格式。类型:string
默认值。 JKS
有效值。
重要性:中等
auto.commit.interval.ms
如果 enable.auto.commit 设置为 true,消费者偏移量自动提交到 Kafka 的频率,以毫秒为单位。类型:int
默认:5000(5秒)
有效值:[0,...]
重要性:低
check.crcs
自动检查所消耗记录的CRC32。这确保了信息没有发生线上或磁盘上的损坏。这个检查会增加一些开销,所以在追求极致性能的情况下,可能会被禁用。类型:布尔值
默认:true
有效值。
重要性:低
client.id
一个ID字符串,在发出请求时传递给服务器。这样做的目的是为了在服务器端请求日志中包含一个逻辑应用程序名称,从而能够跟踪请求的来源,而不仅仅是ip/端口。类型:字符串
默认:""
有效值。
重要性:低
client.rack
该客户端的机架标识符。这可以是任何字符串值,表示该客户端的物理位置。它与broker配置'broker.rack'相对应。类型:字符串
默认:""
有效值。
重要性:低
fetch.max.wait.ms
如果没有足够的数据来立即满足fetch.min.bytes给出的要求,服务器在回复fetch请求前会阻塞的最大时间。类型:int
默认值:500
有效值:[0,...]
重要性:低
interceptor.classes
作为拦截器使用的类的列表。实现org.apache.kafka.clients.consumer.ConsumerInterceptor接口可以让你拦截(并可能突变)消费者收到的记录。默认情况下,没有拦截器。类型:列表
默认:""
有效值:非空字符串
重要性:低
metadata.max.age.ms
即使我们没有看到任何分区领导权变化,我们也会强制刷新元数据,以主动发现任何新的broker或分区的时间,以毫秒为单位。类型:长
默认:300000(5分钟)
有效值:[0,...]
重要性:低
metric.reporters
作为度量报告器使用的类的列表。实现org.apache.kafka.common.metrics.MetricsReporter接口允许插入将被通知新的度量创建的类。JmxReporter总是被包含在注册JMX统计数据中。类型:列表
默认:""
有效值:非空字符串
重要性:低
metrics.num.samples
为计算指标而维护的样本数量。类型:int
默认值:2
有效值:[1,...]
重要性:低
metrics.recording.level
指标的最高记录级别。类型:字符串
默认:INFO
有效值:[INFO, DEBUG, TRACE]
重要性:低
metrics.sample.window.ms
度量样本计算的时间窗口。类型:长
默认:30000(30秒)
有效值:[0,...]
重要性:低
reconnect.backoff.max.ms
当重新连接到一个反复连接失败的broker时,等待的最大时间,以毫秒为单位。如果提供,每台主机的backoff将在每一次连续连接失败时以指数形式增加,直到这个最大值。在计算背离增加后,20%的随机抖动被添加到避免连接风暴中。类型:长
默认:1000(1秒)
有效值:[0,...]
重要性:低
reconnect.backoff.ms
试图重新连接到给定主机前的基本等待时间。这可以避免在一个紧密的循环中重复连接到主机。这个backoff适用于客户端到broker的所有连接尝试。类型:长
默认值:50
有效值:[0,...]
重要性:低
retry.backoff.ms
试图重试给定主题分区的失败请求前的等待时间。这可以避免在某些失败情况下,在一个紧密的循环中重复发送请求。类型:long
默认值:100
有效值:[0,...]
重要性:低
Sasl.kerberos.kinit.cmd
Kerberos kinit 命令路径。类型:字符串
默认值。 /usr/bin/kinit
有效值。
重要性:低
sasl.kerberos.min.time.before.relogin
登录线程刷新尝试之间的睡眠时间。类型:long
默认值:60000
有效值。
重要性:低
sasl.kerberos.ticket.review.jitter
随机抖动加到续航时间的百分比。类型:double
默认值:0.05
有效值。
重要性:低
sasl.kerberos.ticket.renew.window.factor
登录线程将休眠,直到达到从上次刷新到票据到期的指定时间窗口系数,这时它将尝试更新票据。类型:double
默认值:0.8
有效值。
重要性:低
sasl.login.refresh.buffer.seconds
刷新凭证时,在凭证到期前要保持的缓冲时间,以秒为单位。如果刷新的时间离到期时间比缓冲秒数更近,那么刷新时间将被提前,以尽可能多地保持缓冲时间。法定值在0到3600(1小时)之间;如果没有指定值,则使用默认值300(5分钟)。如果该值和sasl.login.refresh.min.period.seconds的总和超过了凭证的剩余寿命,则该值和sasl.login.refresh.min.period.seconds都会被忽略。目前只适用于OAUTHBEARER。类型:short
默认值:300
有效值:[0,...,3600]
重要性:低
sasl.login.refresh.min.period.seconds
登录刷新线程在刷新凭证前需要等待的最短时间,以秒为单位。合法值在0到900(15分钟)之间;如果没有指定值,则使用默认值60(1分钟)。如果这个值和sasl.login.refresh.buffer.seconds的总和超过了一个凭证的剩余寿命,那么这个值和sasl.login.buffer.seconds都会被忽略。目前只适用于OAUTHBEARER。类型:short
默认值:60
有效值: [0,...,900]
重要性:低
sasl.login.refresh.window.factor
登录刷新线程将休眠,直到达到相对于凭证寿命的指定窗口系数,此时将尝试刷新凭证。合法值在0.5(50%)到1.0(100%)之间,如果没有指定值,则使用默认值0.8(80%)。目前仅适用于OAUTHBEARER。类型:double
默认值:0.8
有效值:[0.5,...,1.0]
重要性:低
sasl.login.refresh.window.jitter
相对于凭证的寿命,加到登录刷新线程的睡眠时间的最大随机抖动量。合法值在0到0.25(25%)之间,如果没有指定值,则使用默认值0.05(5%)。目前只适用于OAUTHBEARER。类型:double
默认值:0.05
有效值: [0.0,...,0.25]
重要性:低
security.providers
一个可配置的创建者类的列表,每个类都返回一个实现安全算法的提供者。这些类应该实现org.apache.kafka.common.security.ah.SecurityProviderCreator接口。类型:字符串
默认值: null
有效值。
重要性:低
ssl.cipher.suites
密码套件的列表。这是一个命名的认证、加密、MAC和密钥交换算法的组合,用于使用TLS或SSL网络协议协商网络连接的安全设置。默认情况下,支持所有可用的密码套件。类型:列表
默认值: null
有效值。
重要性:低
ssl.endpoint.identification.algorithm
使用服务器证书验证服务器主机名的端点识别算法。类型:字符串
默认:https
有效值。
重要性:低
ssl.engine.factory.class
org.apache.kafka.common.security.auth.SslEngineFactory类型的类来提供SSLEngine对象。默认值是org.apache.kafka.common.security.ssl.DefaultSslEngineFactory。类型:class
默认值: null
有效值。
重要性:低
ssl.keymanager.algorithm
钥匙管理器工厂用于SSL连接的算法,默认值是为Java虚拟机配置的钥匙管理器工厂算法。默认值是为Java虚拟机配置的密钥管理器工厂算法。类型:字符串
默认值。 SunX509
有效值。
重要性:低
ssl.secure.random.implementation
用于SSL加密操作的SecureRandom PRNG实现。类型:字符串
默认值: null
有效值。
重要性:低
ssl.trustmanager.algorithm
信任管理器工厂用于SSL连接的算法。默认值是为Java虚拟机配置的信任管理器工厂算法。类型:字符串
默认值。 PKIX
有效值。
重要性:低
3.5 Kafka连接配置
下面是Kafka 连接框架的配置。
config.storage.topic
存储连接器配置的Kafka主题的名称。类型:字符串
默认值。
有效值。
重要性:高
group.id
标识此 Worker 所属的 Connect 群集组的唯一字符串。类型:字符串
默认值。
有效值。
重要性:高
key.converter
转换器类用于转换Kafka Connect格式和写入Kafka的序列化形式。这控制了向Kafka写入或从Kafka读取的消息中键的格式,由于这与连接器无关,所以允许任何连接器与任何序列化格式一起工作。常见格式的例子包括JSON和Avro。类型:类
默认值。
有效值。
重要性:高
offset.storage.topic
存储连接器偏移量的Kafka主题的名称。类型:字符串
默认值。
有效值。
重要性:高
status.storage.topic
存储连接器和任务状态的Kafka主题的名称。类型:字符串
默认值。
有效值。
重要性:高
value.converter
转换器类用于转换Kafka Connect格式和写入Kafka的序列化形式。这控制了向Kafka写入或从Kafka读取的消息中的值的格式,由于这与连接器无关,所以允许任何连接器与任何序列化格式一起工作。常见格式的例子包括JSON和Avro。类型:类
默认值。
有效值。
重要性:高
bootstrap.servers
用于建立Kafka集群初始连接的主机/端口对的列表。客户端将使用所有的服务器,不管这里指定了哪些服务器用于引导--这个列表只影响用于发现全部服务器集的初始主机。这个列表的形式应该是 host1:port1,host2:port2,....。因为这些服务器只是用于初始连接,以发现完整的集群成员(可能会动态变化),所以这个列表不需要包含完整的服务器集(不过,你可能需要多个服务器,以防某个服务器宕机)。类型:list
默认:localhost:9092
有效值。
重要性:高
heartbeat.interval.ms
使用Kafka的群组管理设施时,对群组协调人的预期心跳间隔时间。心跳用于确保工作者的会话保持活跃,并在新成员加入或离开组时便于重新平衡。该值必须设置为低于session.timeout.ms,但通常不应设置为高于该值的1/3。它可以调整得更低,以控制正常重新平衡的预期时间。类型:int
默认:3000(3秒)
有效值。
重要性:高
rebalance.timeout.ms
重新平衡开始后,每个 Worker 加入组的最大允许时间。这基本上是对所有任务刷新任何未决数据和提交偏移所需时间的限制。如果超过了超时时间,那么该工作者将被从组中移除,这将导致偏移提交失败。类型:int
默认:60000(1分钟)
有效值。
重要性:高
session.timeout.ms
用于检测 Worker 故障的超时时间。Worker 会定期发送心跳,以向 broker 显示其活跃度。如果在该会话超时结束前,broker没有收到心跳,那么broker将从组中删除该 Worker 并启动重新平衡。请注意,该值必须在 broker 配置中通过 group.min.session.timeout.ms 和 group.max.session.timeout.ms 配置的允许范围内。类型:int
默认:10000(10秒)
有效值。
重要性:高
ssl.key.password
密钥存储文件中私钥的密码,或在`ssl.keystore.key'中指定的PEM密钥。只有在配置了双向身份验证的情况下,客户端才需要这个密码。类型:password
默认值: null
有效值。
重要性:高
ssl.keystore.certificate.chain
证书链的格式由'ssl.keystore.type'指定。默认的SSL引擎工厂只支持PEM格式的X.509证书列表。类型:password
默认值: null
有效值。
重要性:高
ssl.keystore.key
私钥的格式由'ssl.keystore.type'指定。默认SSL引擎工厂只支持PEM格式的PKCS#8密钥。如果密钥是加密的,必须使用'ssl.key.password'指定密钥密码。类型:password
默认值: null
有效值。
重要性:高
ssl.keystore.location
密钥存储文件的位置。对客户端来说是可选的,可以用于客户端的双向认证。类型:字符串
默认值: null
有效值。
重要性:高
ssl.keystore.password
密钥存储文件的存储密码。这对客户端来说是可选的,只有在配置了'ssl.keystore.location'时才需要。对于PEM格式,不支持密钥存储密码。类型:password
默认值: null
有效值。
重要性:高
ssl.truststore.certificate
可信证书的格式由'ssl.truststore.type'指定。默认SSL引擎工厂只支持PEM格式的X.509证书。类型:password
默认值: null
有效值。
重要性:高
ssl.truststore.location
信任存储文件的位置。类型:字符串
默认值: null
有效值。
重要性:高
ssl.truststore.password
信任存储文件的密码。如果没有设置密码,则仍然使用配置的信任存储文件,但完整性检查被禁用。PEM格式不支持信任存储密码。类型:password
默认值: null
有效值。
重要性:高
client.dns.lookup
控制客户端如何使用DNS查找。如果设置为use_all_dns_ips,则依次连接到每个返回的IP地址,直到成功建立连接。断开连接后,会使用下一个IP。一旦所有的IP都被使用过一次,客户端就会再次解析主机名中的IP(然而,JVM和操作系统都会缓存DNS名称查询)。如果设置为resolve_canonical_bootstrap_servers_only,则将每个引导地址解析成一个canonical名称列表。在引导阶段之后,这和use_all_dns_ips的行为是一样的。如果设置为默认(已废弃),即使查找返回多个IP地址,也会尝试连接到查找返回的第一个IP地址。类型:字符串
默认值: use_all_dns_ips
有效值。 [default, use_all_dns_ips, resolve_canonical_bootstrap_servers_only] 。
重要性:中等
connections.max.idle.ms
在该配置指定的毫秒数之后关闭空闲连接。类型:long
默认:540000(9分钟)
有效值。
重要性:中等
connector.client.config.override.policy
ConnectorClientConfigOverridePolicy的实现类名或别名。定义哪些客户端配置可以被连接器覆盖。默认的实现是`None`。框架中其他可能的策略包括`全部`和`主要`。类型:字符串
默认值。 无
有效值。
重要性:中等
receive.buffer.bytes
读取数据时使用的TCP接收缓冲区(SO_RCVBUF)的大小。如果该值为-1,则使用OS默认值。类型:int
默认值:32768(32 kibibytes)
有效值:[0,...]
重要性:中等
request.timeout.ms
该配置控制客户端等待请求响应的最长时间。如果在超时之前没有收到响应,客户端将在必要时重新发送请求,或者在重试次数耗尽时失败。类型:int
默认:40000(40秒)
有效值:[0,...]
重要性:中等
sasl.client.callback.handler.class
实现AuthenticateCallbackHandler接口的SASL客户端回调处理程序类的全称。类型:类
默认值: null
有效值。
重要性:中等
sasl.jaas.config
JAAS登录上下文参数,用于SASL连接,格式为JAAS配置文件使用的格式。JAAS配置文件的格式在这里有介绍。值的格式为:'loginModuleClass controlFlag (optionName=optionValue)*;'。对于broker来说,配置必须以监听器前缀和SASL机制名称为前缀,并以小写字母表示。例如,listener.name.sasl_ssl.scram-sha-256.sasl.jaas.config=com.exam.ScramLoginModule必填。类型:password
默认值: null
有效值。
重要性:中等
sasl.kerberos.service.name。
Kafka 运行的 Kerberos 主体名称。这可以在Kafka的JAAS配置或Kafka的配置中定义。类型:字符串
默认值: null
有效值。
重要性:中等
sasl.login.callback.handler.class。
实现AuthenticateCallbackHandler接口的SASL登录回调处理程序类的完全限定名称。对于broker来说,登录回调处理程序配置必须以监听器前缀和小写的SASL机制名称为前缀。例如,listener.name.sasl_ssl.scram-sha-256.sasl.login.callback.handler.class=com.example.CustomScramLoginCallbackHandler。类型:类
默认值: null
有效值。
重要性:中等
sasl.login.class
实现Login接口的类的全称。对于broker来说,login config必须以监听器前缀和SASL机制名称为前缀,并使用小写。例如,listener.name.sasl_ssl.scram-sha-256.sasl.login.class=com.example.CustomScramLogin。类型:类
默认值: null
有效值。
重要性:中等
sasl.mechanism
用于客户端连接的SASL机制。这可以是任何有安全提供者的机制。GSSAPI是默认机制。类型:字符串
默认值。 GSSAPI
有效值。
重要性:中等
security.protocol
用于与broker通信的协议。有效值是: PLAINTEXT, SSL, SASL_PLAINTEXT, SASL_SSL.类型:字符串
默认值。 PLAINTEXT
有效值。
重要性:中等
send.buffer.bytes
发送数据时要使用的TCP发送缓冲区(SO_SNDBUF)的大小。如果该值为-1,则使用OS默认值。
类型:int
默认值:131072 (128 kibibytes)
有效值:[0,...]
重要性:中等
ssl.enabled.protocols
为SSL连接启用的协议列表。默认值是 "TLSv1.2,TLSv1.3",当运行Java 11或更新版本时,否则为 "TLSv1.2"。在Java 11的默认值下,如果客户端和服务器都支持TLSv1.3,则会优先选择TLSv1.3,否则会回退到TLSv1.2(假设两者都至少支持TLSv1.2)。这个默认值在大多数情况下应该是没有问题的。也可以参考`ssl.protocol`的配置文档。类型:列表
默认值: TLSv1.2
有效值。
重要性:中等
ssl.keystore.type
密钥存储文件的文件格式。对客户端来说是可选的。类型:字符串
默认值。 JKS
有效值。
重要性:中等
ssl.protocol
用来生成SSLContext的SSL协议,默认为'TLSv1.3',否则为'TLSv1.2'。当运行Java 11或更新版本时,默认为'TLSv1.3',否则为'TLSv1.2'。这个值对于大多数的使用情况来说应该是没有问题的。在最近的JVM中允许的值是'TLSv1.2'和'TLSv1.3'。TLS','TLSv1.1','SSL','SSLv2'和'SSLv3'在旧的JVM中可能会被支持,但由于已知的安全漏洞,我们不鼓励使用它们。在这个配置和'ssl.enabled.protocols'的默认值下,如果服务器不支持'TLSv1.3',客户端将降级为'TLSv1.2'。如果这个配置被设置为'TLSv1.2',即使是ssl.enabled.protocols中的一个值,并且服务器只支持'TLSv1.3',客户端也不会使用'TLSv1.3'。类型:字符串
默认值: TLSv1.2
有效值。
重要性:中等
ssl.provider
用于SSL连接的安全提供者的名称。默认值是JVM的默认安全提供者。类型:字符串
默认值: null
有效值。
重要性:中等
ssl.truststore.type
信任存储文件的文件格式。类型:字符串
默认值。 JKS
有效值。
重要性:中等
worker.sync.timeout.ms
当worker与其他worker不同步,需要重新同步配置时,最多等待这个时间,然后才会放弃,离开组,等待一个后退期再重新加入。类型:int
默认:3000(3秒)
有效值。
重要性:中等
worker.unsync.backoff.ms
当worker与其他worker不同步,并且在worker.sync.timeout.ms内未能赶上时,在重新加入之前,要离开Connect集群这么长时间。类型:int
默认:300000(5分钟)
有效值。
重要性:中等
access.control.allow.methods
通过设置 Access-Control-Allow-Methods 标头,设置支持跨源请求的方法。Access-Control-Allow-Methods头的默认值允许GET、POST和HEAD的跨源请求。类型:字符串
默认:""
有效值。
重要性:低
access.control.allow.origin
为REST API请求设置Access-Control-Allow-Origin头的值。要启用跨源访问,请将其设置为应允许访问API的应用程序的域,或'*'允许从任何域访问。默认值只允许从REST API的域进行访问。类型:字符串
默认:""
有效值。
重要性:低
admin.listeners
管理REST API将监听的以逗号分隔的URI列表。支持的协议是HTTP和HTTPS。一个空的或空白的字符串将禁用此功能。默认行为是使用常规监听器(由'listeners'属性指定)。类型:列表
默认值: null
有效值:org.apache.kafka.connect.runtime.WorkerConfig$AdminListenersValidator@7b1d7fff。
重要性:低
client.id
一个ID字符串,在发出请求时传递给服务器。这样做的目的是为了在服务器端请求日志中包含一个逻辑应用程序名称,从而能够跟踪请求的来源,而不仅仅是ip/端口。类型:字符串
默认:""
有效值。
重要性:低
config.providers
ConfigProvider类的逗号分隔的名称,按照指定的顺序加载和使用。通过实现接口ConfigProvider,您可以替换连接器配置中的变量引用,例如对于外部化的秘密。类型:列表
默认:""
有效值。
重要性:低
config.storage.replication.factor
创建配置存储主题时使用的复制因子。类型:short
默认值:3
有效值。 正数,不大于Kafka集群中的broker数量,或-1使用broker的默认值。
重要性:低
connect.protocol
Kafka连接协议的兼容性模式类型:字符串
默认值:sessioned
有效值: [eager, compatible, sessioned]
重要性:低
header.converter
HeaderConverter类用于在Kafka Connect格式和写入Kafka的序列化形式之间进行转换。这控制了向Kafka写入或从Kafka读取的消息中头值的格式,由于这与连接器无关,所以允许任何连接器与任何序列化格式一起工作。常见格式的例子包括JSON和Avro。默认情况下,SimpleHeaderConverter用于将头值序列化为字符串,并通过推断模式反序列化它们。类型:类
默认值:org.apache.kafka.connect.storage.SimpleHeaderConverter。
有效值。
重要性:低
inter.worker.key.generation.algorithm
用于生成内部请求密钥的算法。类型:字符串
默认值:HmacSHA256
有效值。 workerJVM支持的任何KeyGenerator算法。
重要性:低
inter.worker.key.size
用于签署内部请求的密钥大小,以比特为单位。如果为空,将使用密钥生成算法的默认密钥大小。类型:int,如果为空,则使用密钥生成算法的默认密钥大小。
默认值: null
有效值。
重要性:低
inter.worker.key.ttl.ms
用于内部请求验证的生成的会话密钥的TTL(毫秒)。类型:int
默认:3600000(1小时)
有效值: [0,...,2147483647]
重要性:低
inter.worker.signature.algorithm
用于签署内部请求的算法类型:字符串
默认值:HmacSHA256
有效值。 worker 所在机器JVM支持的任何MAC算法。
重要性:低
inter.worker.verification.algorithms
核实内部请求的允许算法清单。类型:清单
默认值:HmacSHA256
有效值。 一个或多个MAC算法的列表,每个算法都由worker机器JVM支持。
重要性:低
internal.key.converter
转换器类用于转换Kafka Connect格式和写入Kafka的序列化形式。这控制了向Kafka写入或从Kafka读取的消息中键的格式,由于这与连接器无关,所以允许任何连接器与任何序列化格式一起工作。常见格式的例子包括JSON和Avro。这个设置控制了框架使用的内部记账数据的格式,如配置和偏移量,所以用户通常可以使用任何功能的Converter实现。已废弃;将在下一个版本中删除。类型:类
默认值:org.apache.kafka.connect.json.JsonConverter。
有效值。
重要性:低
internal.value.converter
转换器类用于转换Kafka Connect格式和写入Kafka的序列化形式。这控制了向Kafka写入或从Kafka读取的消息中的值的格式,由于这与连接器无关,它允许任何连接器与任何序列化格式一起工作。常见格式的例子包括JSON和Avro。该设置控制框架使用的内部记账数据的格式,如配置和偏移量,因此用户通常可以使用任何功能的转换器实现。已废弃;将在下一个版本中删除。类型:类
默认值:org.apache.kafka.connect.json.JsonConverter。
有效值。
重要性:低
listeners
REST API将监听的以逗号分隔的URI列表。支持的协议是HTTP和HTTPS。
指定hostname为0.0.0.0以绑定到所有接口。
将hostname留空以绑定到默认接口。
合法列表的例子。HTTP://myhost:8083,HTTPS://myhost:8084。类型:清单
默认值: null
有效值。
重要性:低
metadata.max.age.ms
即使我们没有看到任何分区领导权变化,我们也会强制刷新元数据,以主动发现任何新的broker或分区的时间,以毫秒为单位。类型:long
默认:300000(5分钟)
有效值:[0,...]
重要性:低
metric.reporters
作为度量报告器使用的类的列表。实现org.apache.kafka.common.metrics.MetricsReporter接口允许插入将被通知新的度量创建的类。JmxReporter总是被包含在注册JMX统计数据中。类型:列表
默认:""
有效值。
重要性:低
metrics.num.samples
为计算指标而维护的样本数量。类型:int
默认值:2
有效值:[1,...]
重要性:低
metrics.recording.level
指标的最高记录级别。类型:字符串
默认:INFO
有效值: [INFO, DEBUG]
重要性:低
metrics.sample.window.ms
度量样本计算的时间窗口。类型:long
默认:30000(30秒)
有效值:[0,...]
重要性:低
offset.flush.interval.ms
尝试提交任务的偏移量的时间间隔。类型:long
默认:60000(1分钟)
有效值。
重要性:低
offset.flush.timeout.ms
等待记录刷新和分区偏移数据提交到偏移存储的最大毫秒数,然后取消进程并在未来尝试中恢复要提交的偏移数据。类型:long
默认:5000(5秒)
有效值。
重要性:低
offset.storage.partitions
创建偏移存储主题时使用的分区数量。类型:int
默认值:25
有效值:正数,或-1使用broker的默认值。
重要性:低
offset.storage.replication.factor
创建偏移存储主题时使用的复制因子。类型:short
默认值:3
有效值。 正数,不大于Kafka集群中的broker数量,或-1使用broker的默认值。
重要性:低
plugin.path
由逗号(,)分隔的包含插件(连接器、转换器、转换)的路径列表。该列表应该由顶级目录组成,其中包括以下任意组合。
a) 紧接着包含有插件和它们的依赖关系的罐子的目录。
b) uber-jars与插件和它们的依赖关系。
c) 紧接着包含插件类及其依赖关系的包目录结构的目录。
注意:将遵循符号链接来发现依赖关系或插件。
例如:plugin.path=/usr/local/share/java,/usr/local/share/kafka/plugins,/opt/connectors。
不要在此属性中使用配置提供者变量,因为在初始化配置提供者并用于替换变量之前,worker的扫描器会使用原始路径。类型:列表
默认值: null
有效值。
重要性:低
reconnect.backoff.max.ms
当重新连接到一个反复连接失败的broker时,等待的最大时间,以毫秒为单位。如果提供,每台主机的backoff将在每一次连续连接失败时以指数形式增加,直到这个最大值。在计算背离增加后,20%的随机抖动被添加到避免连接风暴中。类型:long
默认:1000(1秒)
有效值:[0,...]
重要性:低
reconnect.backoff.ms
试图重新连接到给定主机前的基本等待时间。这可以避免在一个紧密的循环中重复连接到主机。这个backoff适用于客户端到broker的所有连接尝试。类型:long
默认值:50
有效值:[0,...]
重要性:低
response.http.headers.config
REST API HTTP响应头的规则类型:字符串
默认:""
有效值。 逗号分隔的页眉规则,其中每个页眉规则的形式为"[行动][页眉名称]:[页眉值]",如果页眉规则的任何部分包含逗号,则可选择用双引号包围。
重要性:低
rest.advertised.host.name
如果设置了这个,这就是将提供给其他worker连接的主机名。类型:字符串
默认值: null
有效值。
重要性:低
rest.advertised.listener
设置公告的监听器(HTTP或HTTPS),该监听器将提供给其他工作者使用。类型:字符串
默认值: null
有效值。
重要性:低
rest.advertised.port
如果设置了这个端口,这就是给其他worker连接的端口。类型:int
默认值: null
有效值。
重要性:低
rest.extension.classes
ConnectRestExtension类的逗号分隔的名称,按照指定的顺序加载和调用。实现接口ConnectRestExtension允许您向Connect的REST API中注入用户定义的资源,如过滤器。通常用于添加自定义能力,如日志记录、安全等。类型:列表
默认:""
有效值。
重要性:低
rest.host.name
REST API的主机名。如果设置了这个,它将只绑定到这个接口。类型:字符串
默认值: null
有效值。
重要性:低
rest.port
REST API的监听端口。类型:int
默认值:8083
有效值。
重要性:低
retry.backoff.ms
试图重试给定主题分区的失败请求前的等待时间。这可以避免在某些失败情况下,在一个紧密的循环中重复发送请求。类型:long
默认值:100
有效值:[0,...]
重要性:低
sasl.kerberos.kinit.cmd
Kerberos kinit 命令路径。类型:字符串
默认值。 /usr/bin/kinit
有效值。
重要性:低
sasl.kerberos.min.time.before.relogin
登录线程刷新尝试之间的睡眠时间。类型:long
默认值:60000
有效值。
重要性:低
sasl.kerberos.ticket.renew.jitter
随机抖动加到续航时间的百分比。类型:double
默认值:0.05
有效值。
重要性:低
sasl.kerberos.ticket.renew.window.factor
登录线程将休眠,直到达到从上次刷新到票据到期的指定时间窗口系数,这时它将尝试更新票据。类型:double
默认值:0.8
有效值。
重要性:低
sasl.login.refresh.buffer.seconds
刷新凭证时,在凭证到期前要保持的缓冲时间,以秒为单位。如果刷新的时间离到期时间比缓冲秒数更近,那么刷新时间将被提前,以尽可能多地保持缓冲时间。法定值在0到3600(1小时)之间;如果没有指定值,则使用默认值300(5分钟)。如果该值和sasl.login.refresh.min.period.seconds的总和超过了凭证的剩余寿命,则该值和sasl.login.refresh.min.period.seconds都会被忽略。目前只适用于OAUTHBEARER。类型:short
默认值:300
有效值:[0,...,3600]
重要性:低
sasl.login.refresh.min.period.seconds
登录刷新线程在刷新凭证前需要等待的最短时间,以秒为单位。合法值在0到900(15分钟)之间;如果没有指定值,则使用默认值60(1分钟)。如果这个值和sasl.login.refresh.buffer.seconds的总和超过了一个凭证的剩余寿命,那么这个值和sasl.login.buffer.seconds都会被忽略。目前只适用于OAUTHBEARER。类型:short
默认值:60
有效值:[0,...,900]
重要性:低
sasl.login.refresh.window.factor。
登录刷新线程将休眠,直到达到相对于凭证寿命的指定窗口系数,此时将尝试刷新凭证。合法值在0.5(50%)到1.0(100%)之间,如果没有指定值,则使用默认值0.8(80%)。目前仅适用于OAUTHBEARER。类型:double
默认值:0.8
有效值:[0.5,...,1.0]
重要性:低
sasl.login.refresh.window.jitter
相对于凭证的寿命,加到登录刷新线程的睡眠时间的最大随机抖动量。合法值在0到0.25(25%)之间,如果没有指定值,则使用默认值0.05(5%)。目前只适用于OAUTHBEARER。类型:double
默认值:0.05
有效值:[0.0,...,0.25]
重要性:低
scheduled.rebalance.max.delay.ms
为了等待一个或多个离职worker返回,在重新平衡和重新分配他们的连接器和任务到组之前所安排的最大延迟。在此期间,已离职worker的连接器和任务仍未分配。类型:int
默认:300000(5分钟)
有效值: [0,...,2147483647]
重要性:低
socket.connection.setup.timeout.max.ms
客户端等待建立套接字连接的最大时间。连接设置超时时间将随着每一次连续的连接失败而成倍增加,直到这个最大值。为了避免连接风暴,超时时间将被应用于0.2的随机系数,结果是低于计算值20%到高于计算值20%的随机范围。类型:long
默认:127000(127秒)
有效值:[0,...]
重要性:低
socket.connection.setup.timeout.ms
客户端等待socket连接建立的时间。如果在超时之前没有建立连接,客户端将关闭socket通道。类型:长
默认:10000(10秒)
有效值:[0,...]
重要性:低
ssl.cipher.suites
密码套件的列表。这是一个命名的认证、加密、MAC和密钥交换算法的组合,用于使用TLS或SSL网络协议协商网络连接的安全设置。默认情况下,支持所有可用的密码套件。类型:列表
默认值: null
有效值。
重要性:低
ssl.client.auth
配置kafka broker请求客户端认证。以下是常用的设置。ssl.client.auth=required 如果设置为require,则客户端认证是必须的。
ssl.client.auth=requested 这意味着客户端认证是可选的,与required不同,如果设置了这个选项,客户端可以选择不提供自己的认证信息。
ssl.client.auth=none 这表示不需要客户端认证。
类型:字符串
默认:无
有效值。
重要性:低
ssl.endpoint.identification.algorithm
使用服务器证书验证服务器主机名的端点识别算法。类型:字符串
默认:https
有效值。
重要性:低
ssl.engine.factory.class
org.apache.kafka.common.security.auth.SslEngineFactory类型的类来提供SSLEngine对象。默认值是org.apache.kafka.common.security.ssl.DefaultSslEngineFactory。类型:类
默认值: null
有效值。
重要性:低
ssl.keymanager.algorithm
钥匙管理器工厂用于SSL连接的算法,默认值是为Java虚拟机配置的钥匙管理器worker进程算法。默认值是为Java虚拟机配置的密钥管理器工厂算法。类型:字符串
默认值。 SunX509
有效值。
重要性:低
ssl.secure.random.implementation
用于SSL加密操作的SecureRandom PRNG实现。类型:字符串
默认值: null
有效值。
重要性:低
ssl.trustmanager.algorithm
信任管理器工厂用于SSL连接的算法。默认值是为Java虚拟机配置的信任管理器工厂算法。类型:字符串
默认值。 PKIX
有效值。
重要性:低
status.storage.partitions
创建状态存储主题时使用的分区数量。类型:int
默认值:5
有效值:正数,或-1使用broker的默认值。
重要性:低
status.storage.replication.factor
创建状态存储主题时使用的复制因子。类型:short
默认值:3
有效值。 正数,不大于Kafka集群中的broker数量,或-1使用broker的默认值。
重要性:低
task.shutdown.graceful.timeout.ms
等待任务优雅关闭的时间。这是总的时间量,而不是每个任务。所有任务都被触发关机,然后依次等待。类型:long
默认:5000(5秒)
有效值。
重要性:低
topic.creation.enable
当源连接器配置了`topic.create.`属性时,是否允许自动创建源连接器使用的主题。每个任务将使用管理客户端来创建它的主题,而不是依赖Kafkabroker来自动创建主题。类型:布尔值
默认:true
有效值。
重要性:低
topic.tracking.allow.reset
如果设置为 "true",它允许用户请求重置每个连接器的活动主题集。类型:布尔值
默认:true
有效值。
重要性:低
topic.tracking.enable
启用在运行时跟踪每个连接器的活动主题集。类型:布尔值
默认:true
有效值。
重要性:低
3.5.1 源连接器配置
下面是源连接器的配置。
name
该连接器的全局唯一名称。类型:字符串
默认值。
有效值:非空字符串,不含ISO控制字符。
重要性:高
connector.class
该连接器类的名称或别名。必须是org.apache.kafka.connect.connector.Connector的子类。如果连接器是org.apache.kafka.connect.file.FileStreamSinkConnector,你可以指定这个全名,或者使用 "FileStreamSink "或 "FileStreamSinkConnector "来使配置更短一些。类型:字符串
默认值。
有效值。
重要性:高
tasks.max
该连接器可使用的最大任务数。类型:int
默认值:1
有效值:[1,...]
重要性:高
key.converter
转换器类用于转换Kafka Connect格式和写入Kafka的序列化形式。这控制了向Kafka写入或从Kafka读取的消息中键的格式,由于这与连接器无关,所以允许任何连接器与任何序列化格式一起工作。常见格式的例子包括JSON和Avro。类型:类
默认值: null
有效值。
重要性:低
value.converter
转换器类用于转换Kafka Connect格式和写入Kafka的序列化形式。这控制了向Kafka写入或从Kafka读取的消息中的值的格式,由于这与连接器无关,所以允许任何连接器与任何序列化格式一起工作。常见格式的例子包括JSON和Avro。类型:类
默认值: null
有效值。
重要性:低
header.converter
HeaderConverter类用于在Kafka Connect格式和写入Kafka的序列化形式之间进行转换。这控制了向Kafka写入或从Kafka读取的消息中头值的格式,由于这与连接器无关,所以允许任何连接器与任何序列化格式一起工作。常见格式的例子包括JSON和Avro。默认情况下,SimpleHeaderConverter用于将头值序列化为字符串,并通过推断模式反序列化它们。类型:类
默认值: null
有效值。
重要性:低
config.action.reload
当外部配置提供者的变化导致连接器的配置属性发生变化时,Connect应该对连接器采取的行动。值为'none'表示Connect将不做任何操作。值为'restart'表示Connect应该使用更新的配置属性重新启动/重新加载连接器.如果外部配置提供者表示某个配置值将在未来过期,那么实际上可能会在未来安排重新启动。类型:字符串
默认:restart
有效值。 [none, restart]
重要性:低
transforms
要应用于记录的转换的别名。类型:列表
默认:""
有效值:非空字符串,唯一的转换别名。
重要性:低
predicates
变换所使用的谓词的别名。类型:列表
默认:""
有效值:非空字符串,唯一的谓词别名。
重要性:低
errors.retry.timeout
失败后重新尝试操作的最大持续时间,以毫秒为单位。默认值是0,表示不尝试重试。使用-1表示无限次重试。类型:long
默认值:0
有效值。
重要性:中等
errors.retry.delay.max.ms
连续重试尝试之间的最大持续时间,单位为毫秒。一旦达到这个限制,抖动将被添加到延迟中,以防止雷鸣般的群组问题。类型:long
默认:60000(1分钟)
有效值。
重要性:中等
errors.tolerance
在连接器操作期间容忍错误的行为。'none'是默认值,表示任何错误都会导致连接器任务立即失败;'all'会改变行为,跳过有问题的记录。类型:字符串
默认:none
有效值。 [none, all]
重要性:中等
errors.log.enable
如果为 "true",则将每个错误以及失败操作和问题记录的详细信息写入 Connect 应用程序日志。默认为'false',因此只有不能容忍的错误才会被报告。类型:布尔值
默认:false
有效值。
重要性:中等
errors.log.include.messages
是否在日志中包含导致失败的连接记录。默认为'false',这将防止记录键、值和标题被写入日志文件,尽管一些信息(如主题和分区号)仍将被记录。类型:布尔值
默认:false
有效值。
重要性:中等
topic.creation.groups
由源连接器创建的主题配置组。类型:清单
默认:""
有效值:非空字符串,唯一的主题创建组。
重要性:低
3.5.2 sink连接器配置
下面是sink连接器的配置。
名称
该连接器的全局唯一名称。类型:字符串
默认值。
有效值:非空字符串,不含ISO控制字符。
重要性:高
connector.class
该连接器类的名称或别名。必须是org.apache.kafka.connect.connector.Connector的子类。如果连接器是org.apache.kafka.connect.file.FileStreamSinkConnector,你可以指定这个全名,或者使用 "FileStreamSink "或 "FileStreamSinkConnector "来使配置更短一些。类型:字符串
默认值。
有效值。
重要性:高
tasks.max
该连接器可使用的最大任务数。类型:int
默认值:1
有效值:[1,...]
重要性:高
topics
消耗的主题清单,用逗号隔开。类型:清单
默认:""
有效值。
重要性:高
topics.regex
正则表达式给出要消耗的题目。在下面,regex被编译成java.util.regex.Pattern。只能指定 topics 或 topics.regex 中的一个。类型:字符串
默认:""
有效值:有效的regex
重要性:高
key.converter
转换器类用于转换Kafka Connect格式和写入Kafka的序列化形式。这控制了向Kafka写入或从Kafka读取的消息中键的格式,由于这与连接器无关,所以允许任何连接器与任何序列化格式一起工作。常见格式的例子包括JSON和Avro。类型:类
默认值: null
有效值。
重要性:低
value.converter
转换器类用于转换Kafka Connect格式和写入Kafka的序列化形式。这控制了向Kafka写入或从Kafka读取的消息中的值的格式,由于这与连接器无关,所以允许任何连接器与任何序列化格式一起工作。常见格式的例子包括JSON和Avro。类型:类
默认值: null
有效值。
重要性:低
header.converter
HeaderConverter类用于在Kafka Connect格式和写入Kafka的序列化形式之间进行转换。这控制了向Kafka写入或从Kafka读取的消息中头值的格式,由于这与连接器无关,所以允许任何连接器与任何序列化格式一起工作。常见格式的例子包括JSON和Avro。默认情况下,SimpleHeaderConverter用于将头值序列化为字符串,并通过推断模式反序列化它们。类型:类
默认值: null
有效值。
重要性:低
config.action.reload
当外部配置提供者的变化导致连接器的配置属性发生变化时,Connect应该对连接器采取的行动。值为'none'表示Connect将不做任何操作。值为'restart'表示Connect应该使用更新的配置属性重新启动/重新加载连接器.如果外部配置提供者表示某个配置值将在未来过期,那么实际上可能会在未来安排重新启动。类型:字符串
默认:restart
有效值。[none, restart]
重要性:低
transforms
要应用于记录的转换的别名。类型:列表
默认:""
有效值:非空字符串,唯一的转换别名。
重要性:低
predicates
变换所使用的谓词的别名。类型:列表
默认:""
有效值:非空字符串,唯一的谓词别名。
重要性:低
errors.retry.timeout
失败后重新尝试操作的最大持续时间,以毫秒为单位。默认值是0,表示不尝试重试。使用-1表示无限次重试。类型:长
默认值:0
有效值。
重要性:中等
errors.retry.delay.max.ms
连续重试尝试之间的最大持续时间,单位为毫秒。一旦达到这个限制,抖动将被添加到延迟中,以防止雷鸣般的群组问题。类型:long
默认:60000(1分钟
有效值。
重要性:中等
errors.tolerance
在连接器操作期间容忍错误的行为。'none'是默认值,表示任何错误都会导致连接器任务立即失败;'all'会改变行为,跳过有问题的记录。类型:字符串
默认:none
有效值。 [none,all]
重要性:中等
errors.log.enable
如果为 "true",则将每个错误以及失败操作和问题记录的详细信息写入 Connect 应用程序日志。默认为'false',因此只有不能容忍的错误才会被报告。类型:布尔值
默认:false
有效值。
重要性:中等
error.log.include.message
是否在日志中包含导致失败的连接记录。默认为'false',这将防止记录键、值和标题被写入日志文件,尽管一些信息(如主题和分区号)仍将被记录。类型:布尔值
默认:false
有效值。
重要性:中等
errors.deadletterqueue.topic.name
将用作死信队列(DLQ)的主题名称,用于处理由该sink或其转换或转换器处理时导致错误的消息。默认情况下,主题名称为空白,这意味着DLQ中不会记录任何消息。类型:字符串
默认:""
有效值。
重要性:中等
error.deadletterqueue.topic.replication.factor。
当死信队列主题还不存在时,用于创建死信队列主题的复制因子。类型:short
默认值:3
有效值。
重要性:中等
errors.deadletterqueue.context.headers.enable
如果为真,将包含错误上下文的头键添加到写入死信队列的消息中。为了避免与原始记录中的报头冲突,所有的错误上下文报头键,所有的错误上下文报头键将以__connect.errors开头。类型:布尔值
默认:false
有效值。
重要性:中等
3.6 Kafka流配置
下面是Kafka Streams客户端库的配置。
application.id
流处理应用程序的标识符。在Kafka集群中必须是唯一的。它被用作1)默认的client-id前缀,2)用于成员管理的group-id,3)changelog主题前缀。类型:字符串
默认值。
有效值。
重要性:高
bootstrap.servers
用于建立Kafka集群初始连接的主机/端口对的列表。客户端将使用所有的服务器,不管这里指定了哪些服务器用于引导--这个列表只影响用于发现全部服务器集的初始主机。这个列表的形式应该是 host1:port1,host2:port2,....。因为这些服务器只是用于初始连接,以发现完整的集群成员(可能会动态变化),所以这个列表不需要包含完整的服务器集(不过,你可能需要多个服务器,以防某个服务器宕机)。类型:列表
默认值。
有效值。
重要性:高
replication.factor
流处理应用程序创建的变更日志主题和重新分区主题的复制因子。类型:int
默认值:1
有效值。
重要性:高
state.dir
状态存储的目录位置。此路径对于共享相同底层文件系统的每个流实例必须是唯一的。类型:字符串
默认值。 /tmp/kafka-streams。
有效值。
重要性:高
acceptable.recovery.lag
客户端被认为赶上活动任务的最大可接受滞后(追赶的偏移数).对于给定的工作量,应该对应于远低于一分钟的恢复时间。必须至少为0。类型:long
默认值:10000
有效值:[0,...]
重要性:中等
cache.max.bytes.buffering
所有线程中用于缓冲的最大内存字节数。类型:long
默认值:10485760
有效值:[0,...]
重要性:中等
client.id
一个ID前缀字符串,用于内部消费者、生产者和还原消费者的客户端ID,模式为'-StreamThread--'。类型:字符串
默认:""
有效值。
重要性:中等
default.deserialization.exception.handler
实现org.apache.kafka.streams.errors.DeserializationExceptionHandler接口的异常处理类。类型:类
默认:org.apache.kafka.streams.errors.LogAndFailExceptionHandler。
有效值。
重要性:中等
default.key.serde
实现org.apache.kafka.common.serialization.Serde接口的key的默认序列化器/反序列化器类。注意,当使用windowed serde类时,需要通过'default.windowed.key.serde.inner'或'default.windowed.value.serde.inner'来设置实现org.apache.kafka.common.serialization.Serde接口的内部serde类。类型:类
默认值:org.apache.kafka.common.serialization.Serdes$ByteArraySerde。
有效值。
重要性:中等
default.production.exception.handler
实现org.apache.kafka.streams.errors.ProductionExceptionHandler接口的异常处理类。类型:类
默认:org.apache.kafka.streams.errors.DefaultProductionExceptionHandler。
有效值。
重要性:中等
default.timestamp.extractor
默认的时间戳提取器类,实现了org.apache.kafka.streams.processor.TimestampExtractor接口。类型:类
默认值:org.apache.kafka.streams.processor.FailOnInvalidTimestamp。
有效值。
重要性:中等
default.value.serde
实现org.apache.kafka.common.serialization.Serde接口的值的默认序列化器/反序列化器类。注意,当使用windowed serde类时,需要通过'default.windowed.key.serde.inner'或'default.windowed.value.serde.inner'来设置实现org.apache.kafka.common.serialization.Serde接口的内部serde类。类型:类
默认值:org.apache.kafka.common.serialization.Serdes$ByteArraySerde。
有效值。
重要性:中等
default.windowed.key.serde.inner
窗口化键的内部类的默认序列化器/反序列化器。必须实现org.apache.kafka.common.serialization.Serde接口。类型:类
默认值: null
有效值。
重要性:中等
default.windowed.value.serde.inner
窗口值内部类的默认序列化器/反序列化器。必须实现org.apache.kafka.common.serialization.Serde接口。类型:类
默认值: null
有效值。
重要性:中等
max.task.idle.ms
当不是所有分区缓冲区都包含记录时,流任务保持空闲的最大时间(毫秒),以避免潜在的跨多个输入流的无序记录处理。类型:long
默认值:0
有效值。
重要性:中等
max.warmup.replicas
一次可以分配的最大暖机副本数量(超出配置的num.standbys的额外备用),目的是在一个实例上保持任务可用,同时在另一个被重新分配的实例上暖机。用于节制多少额外的broker流量和集群状态可以用于高可用性。必须至少为1。类型:int
默认值:2
有效值:[1,...]
重要性:中
num.standby.replicas
每个任务的备用副本数量。类型:int
默认值:0
有效值。
重要性:中等
num.stream.threads
执行流处理的线程数。类型:int
默认值:1
有效值。
重要性:中等
processing.guarantee
应该使用的处理保证。可能的值是 at_least_once (默认),exactly_once (需要broker版本 0.11.0 或更高),和 exactly_once_beta (需要broker版本 2.5 或更高)。需要注意的是,exactly-once处理需要至少三个broker的集群,默认情况下,这是生产中的推荐设置;对于开发,你可以通过调整broker设置transaction.state.log.replication.factor和transaction.state.log.min.isr来改变这个设置。类型:字符串
默认:at_least_once
有效值。 [at_least_once, exactly_once, exactly_once_beta]
重要性:中等
security.protocol
用于与broker通信的协议。有效值是: PLAINTEXT, SSL, SASL_PLAINTEXT, SASL_SSL.类型:字符串
默认值。 PLAINTEXT
有效值。
重要性:中等
task.timeout.ms
任务因内部错误而停滞的最大时间,以毫秒为单位,并重试,直到发出错误。对于0毫秒的超时,任务会在第一次内部错误时引发错误。对于任何大于0ms的超时,任务将在引发错误之前至少重试一次。类型:长
默认:300000(5分钟)
有效值:[0,...]
重要性:中等
topology.optimization
一个告诉Kafka Streams是否应该优化拓扑的配置,默认情况下是禁用的。类型:字符串
默认:none
有效值: [none, all]
重要性:中等
application.server
主机:端口对,指向一个用户定义的端点,该端点可用于该KafkaStreams实例的状态存储发现和交互式查询。类型:字符串
默认:""
有效值。
重要性:低
buffered.records.per.partition
每个分区要缓冲的最大记录数。类型:int
默认:1000
有效值。
重要性:低
built.in.metrics.version
要使用的内置指标的版本。类型:字符串
默认:latest
有效值。 [0.10.0-2.4,latest]
重要性:低
commit.interval.ms
保存处理器位置的频率,以毫秒为单位。(注意,如果processing.guarantee设置为exactly_once,默认值为100,否则默认值为30000)。类型:long
默认:30000(30秒)
有效值:[0,...]
重要性:低
connections.max.idle.ms
在该配置指定的毫秒数之后关闭空闲连接。类型:long
默认:540000(9分钟)
有效值。
重要性:低
metadata.max.age.ms
即使我们没有看到任何分区领导权变化,我们也会强制刷新元数据,以主动发现任何新的broker或分区的时间,以毫秒为单位。类型:long
默认:300000(5分钟)
有效值:[0,...]
重要性:低
metric.reporters
作为度量报告器使用的类的列表。实现org.apache.kafka.common.metrics.MetricsReporter接口允许插入将被通知新的度量创建的类。JmxReporter总是被包含在注册JMX统计数据中。类型:列表
默认:""
有效值。
重要性:低
metrics.num.samples
为计算指标而维护的样本数量。类型:int
默认值:2
有效值:[1,...]
重要性:低
metrics.recording.level
指标的最高记录级别。类型:字符串
默认:INFO
有效值:[INFO, DEBUG, TRACE] [INFO, DEBUG, TRACE]
重要性:低
metrics.sample.window.ms
度量样本计算的时间窗口。类型:long
默认:30000(30秒)
有效值:[0,...]
重要性:低
partition.grouper
实现org.apache.kafka.streams.processor.PartitionGrouper接口的分区聚类。警告:该配置已被废弃,并将在3.0.0版本中被移除。类型:类
默认值:org.apache.kafka.streams.processor.DefaultPartitionGrouper。
有效值。
重要性:低
poll.ms
块等待输入的时间,以毫秒为单位。类型:long
默认值:100
有效值。
重要性:低
probing.rebalance.interval.ms
在触发再平衡以探查已完成预热并准备成为活动状态的预热副本之前,等待的最大时间(毫秒)。探测再平衡将继续被触发,直到任务平衡。必须至少为1分钟。类型:long
默认:600000(10分钟)
有效值: [60000,...]
重要性:低
receive.buffer.bytes
读取数据时要使用的TCP接收缓冲区(SO_RCVBUF)的大小。如果该值为-1,则使用OS默认值。类型:int
默认值:32768(32 kibibytes)。
有效值:[-1,...]
重要性:低
reconnect.backoff.max.ms
当重新连接到一个反复连接失败的broker时,等待的最大时间,以毫秒为单位。如果提供,每台主机的backoff将在每一次连续连接失败时以指数形式增加,直到这个最大值。在计算背离增加后,20%的随机抖动被添加到避免连接风暴中。类型:long
默认:1000(1秒)
有效值:[0,...]
重要性:低
reconnect.backoff.ms
试图重新连接到给定主机前的基本等待时间。这可以避免在一个紧密的循环中重复连接到主机。这个backoff适用于客户端到broker的所有连接尝试。类型:long
默认值:50
有效值:[0,...]
重要性:低
request.timeout.ms
该配置控制客户端等待请求响应的最长时间。如果在超时之前没有收到响应,客户端将在必要时重新发送请求,或者在重试次数耗尽时失败。类型:int
默认:40000(40秒)
有效值:[0,...]
重要性:低
retries
设置一个大于零的值将导致客户端重新发送任何失败的请求,并可能出现短暂的错误。建议将该值设置为零或`MAX_VALUE`,并使用相应的超时参数来控制客户端重试请求的时间。类型:int
默认值:0
有效值:[0,...,2147483647]
重要性:低
retry.backoff.ms
试图重试给定主题分区的失败请求前的等待时间。这可以避免在某些失败情况下,在一个紧密的循环中重复发送请求。类型:long
默认值:100
有效值:[0,...]
重要性:低
rocksdb.config.setter
一个实现org.apache.kafka.streams.state.RocksDBConfigSetter接口的Rocks DB配置设置器类或类名。类型:类
默认值: null
有效值。
重要性:低
send.buffer.bytes
发送数据时要使用的TCP发送缓冲区(SO_SNDBUF)的大小。如果该值为-1,则使用OS默认值。类型:int
默认值:131072 (128 kibibytes)
有效值:[-1,...]
重要性:低
state.cleanup.delay.ms
分区迁移后,在删除状态之前要等待的时间,以毫秒为单位。只有在至少state.cleanup.delay.ms内未被修改的状态目录才会被删除。类型:长
默认:600000(10分钟)。
有效值。
重要性:低
upgrade.from
允许以向后兼容的方式升级。当从[0.10.0, 1.1]升级到2.0+,或者从[2.0, 2.3]升级到2.4+时,需要这个配置。当从2.4升级到更新的版本时,不需要指定这个配置。默认值是`null`。接受的值是 "0.10.0"、"0.10.1"、"0.10.2"、"0.11.0"、"1.0"、"1.1"、"2.0"、"2.1"、"2.2"、"2.3"(从相应的旧版本升级)。类型:字符串
默认值: null
有效值。 [空、0.10.0、0.10.1、0.10.2、0.11.0、1.0、1.1、2.0、2.1、2.2、2.3]
重要性:低
windowstore.changelog.additional.retention.ms
添加到一个windows维护Ms,以确保数据不会过早从日志中删除。允许时钟漂移。默认为1天类型:long
默认:86400000(1天)
有效值。
重要性:低
3.7 管理设置
下面是Kafka Admin客户端库的配置。
bootstrap.server
用于建立Kafka集群初始连接的主机/端口对的列表。客户端将使用所有的服务器,不管这里指定了哪些服务器用于引导--这个列表只影响用于发现全部服务器集的初始主机。这个列表的形式应该是 host1:port1,host2:port2,....。因为这些服务器只是用于初始连接,以发现完整的集群成员(可能会动态变化),所以这个列表不需要包含完整的服务器集(不过,你可能需要多个服务器,以防某个服务器宕机)。类型:列表
默认值。
有效值。
重要性:高
ssl.key.password
密钥存储文件中私钥的密码,或在`ssl.keystore.key'中指定的PEM密钥。只有在配置了双向身份验证的情况下,客户端才需要这个密码。类型:password
默认值: null
有效值。
重要性:高
ssl.keystore.certificate.chain
证书链的格式由'ssl.keystore.type'指定。默认的SSL引擎工厂只支持PEM格式的X.509证书列表。类型:password
默认值: null
有效值。
重要性:高
ssl.keystore.key
私钥的格式由'ssl.keystore.type'指定。默认SSL引擎工厂只支持PEM格式的PKCS#8密钥。如果密钥是加密的,必须使用'ssl.key.password'指定密钥密码。类型:password
默认值: null
有效值。
重要性:高
ssl.keystore.location
密钥存储文件的位置。对客户端来说是可选的,可以用于客户端的双向认证。类型:字符串
默认值: null
有效值。
重要性:高
ssl.keystore.password
密钥存储文件的存储密码。这对客户端来说是可选的,只有在配置了'ssl.keystore.location'时才需要。对于PEM格式,不支持密钥存储密码。类型:password
默认值: null
有效值。
重要性:高
ssl.truststore.certificate
可信证书的格式由'ssl.truststore.type'指定。默认SSL引擎工厂只支持PEM格式的X.509证书。类型:password
默认值: null
有效值。
重要性:高
ssl.truststore.location
信任存储文件的位置。类型:字符串
默认值: null
有效值。
重要性:高
ssl.truststore.password
信任存储文件的密码。如果没有设置密码,则仍然使用配置的信任存储文件,但完整性检查被禁用。PEM格式不支持信任存储密码。类型:password
默认值: null
有效值。
重要性:高
client.dns.lookup
控制客户端如何使用DNS查找。如果设置为use_all_dns_ips,则依次连接到每个返回的IP地址,直到成功建立连接。断开连接后,会使用下一个IP。一旦所有的IP都被使用过一次,客户端就会再次解析主机名中的IP(然而,JVM和操作系统都会缓存DNS名称查询)。如果设置为resolve_canonical_bootstrap_servers_only,则将每个引导地址解析成一个canonical名称列表。在引导阶段之后,这和use_all_dns_ips的行为是一样的。如果设置为默认(已废弃),即使查找返回多个IP地址,也会尝试连接到查找返回的第一个IP地址。类型:字符串
默认值: use_all_dns_ips
有效值。 [default, use_all_dns_ips, resolve_canonical_bootstrap_servers_only] 。
重要性:中等
client.id
一个ID字符串,在发出请求时传递给服务器。这样做的目的是为了在服务器端请求日志中包含一个逻辑应用程序名称,从而能够跟踪请求的来源,而不仅仅是ip/端口。类型:字符串
默认:""
有效值。
重要性:中等
connections.max.idle.ms
在该配置指定的毫秒数之后关闭空闲连接。类型:long
默认:300000(5分钟)
有效值。
重要性:中等
default.api.timeout.ms
指定客户端API的超时时间(以毫秒为单位)。此配置被用作所有未指定超时参数的客户端操作的默认超时。类型:int
默认:60000(1分钟)
有效值:[0,...]
重要性:中等
receive.buffer.bytes
读取数据时要使用的TCP接收缓冲区(SO_RCVBUF)的大小。如果该值为-1,则使用OS默认值。类型:int
默认值:65536(64 kibibytes)。
有效值:[-1,...]
重要性:中等
request.timeout.ms
该配置控制客户端等待请求响应的最长时间。如果在超时之前没有收到响应,客户端将在必要时重新发送请求,或者在重试次数耗尽时失败。类型:int
默认:30000(30秒)
有效值:[0,...]
重要性:中等
sasl.client.callback.handler.class
实现AuthenticateCallbackHandler接口的SASL客户端回调处理程序类的全称。类型:类
默认值: null
有效值。
重要性:中等
sasl.jaas.config
JAAS登录上下文参数,用于SASL连接,格式为JAAS配置文件使用的格式。JAAS配置文件的格式在这里有介绍。值的格式为:'loginModuleClass controlFlag (optionName=optionValue)*;'。对于broker来说,配置必须以监听器前缀和SASL机制名称为前缀,并以小写字母表示。例如,listener.name.sasl_ssl.scram-sha-256.sasl.jaas.config=com.exam.ScramLoginModule必填。类型:password
默认值: null
有效值。
重要性:中等
sasl.kerberos.service.name。
Kafka 运行的 Kerberos 主体名称。这可以在Kafka的JAAS配置或Kafka的配置中定义。类型:字符串
默认值: null
有效值。
重要性:中等
sasl.login.callback.handler.class。
实现AuthenticateCallbackHandler接口的SASL登录回调处理程序类的完全限定名称。对于broker来说,登录回调处理程序配置必须以监听器前缀和小写的SASL机制名称为前缀。例如,listener.name.sasl_ssl.scram-sha-256.sasl.login.callback.handler.class=com.example.CustomScramLoginCallbackHandler。类型:类
默认值: null
有效值。
重要性:中等
sasl.login.class
实现Login接口的类的全称。对于broker来说,login config必须以监听器前缀和SASL机制名称为前缀,并使用小写。例如,listener.name.sasl_ssl.scram-sha-256.sasl.login.class=com.example.CustomScramLogin。类型:类
默认值: null
有效值。
重要性:中等
sasl.mechanism
用于客户端连接的SASL机制。这可以是任何有安全提供者的机制。GSSAPI是默认机制。类型:字符串
默认值。 GSSAPI
有效值。
重要性:中等
security.protocol
用于与broker通信的协议。有效值是: PLAINTEXT, SSL, SASL_PLAINTEXT, SASL_SSL.类型:字符串
默认值。 PLAINTEXT
有效值。
重要性:中等
send.buffer.bytes
发送数据时要使用的TCP发送缓冲区(SO_SNDBUF)的大小。如果该值为-1,则使用OS默认值。类型:int
默认值:131072 (128 kibibytes)
有效值:[-1,...]
重要性:中等
socket.connection.setup.timeout.max.ms
客户端等待建立套接字连接的最大时间。连接设置超时时间将随着每一次连续的连接失败而成倍增加,直到这个最大值。为了避免连接风暴,超时时间将被应用于0.2的随机系数,结果是低于计算值20%到高于计算值20%的随机范围。类型:long
默认:127000(127秒
有效值。
重要性:中等
socket.connection.setup.timeout.ms
客户端等待socket连接建立的时间。如果在超时之前没有建立连接,客户端将关闭socket通道。类型:long
默认:10000(10秒
有效值。
重要性:中等
ssl.enabled.protocols
为SSL连接启用的协议列表。默认值是 "TLSv1.2,TLSv1.3",当运行Java 11或更新版本时,否则为 "TLSv1.2"。在Java 11的默认值下,如果客户端和服务器都支持TLSv1.3,则会优先选择TLSv1.3,否则会回退到TLSv1.2(假设两者都至少支持TLSv1.2)。这个默认值在大多数情况下应该是没有问题的。也可以参考`ssl.protocol`的配置文档。类型:列表
默认值: TLSv1.2
有效值。
重要性:中等
ssl.keystore.type
密钥存储文件的文件格式。对客户端来说是可选的。类型:字符串
默认值。 JKS
有效值。
重要性:中等
ssl.protocol
用来生成SSLContext的SSL协议,默认为'TLSv1.3',否则为'TLSv1.2'。当运行Java 11或更新版本时,默认为'TLSv1.3',否则为'TLSv1.2'。这个值对于大多数的使用情况来说应该是没有问题的。在最近的JVM中允许的值是'TLSv1.2'和'TLSv1.3'。TLS','TLSv1.1','SSL','SSLv2'和'SSLv3'在旧的JVM中可能会被支持,但由于已知的安全漏洞,我们不鼓励使用它们。在这个配置和'ssl.enabled.protocols'的默认值下,如果服务器不支持'TLSv1.3',客户端将降级为'TLSv1.2'。如果这个配置被设置为'TLSv1.2',即使是ssl.enabled.protocols中的一个值,并且服务器只支持'TLSv1.3',客户端也不会使用'TLSv1.3'。类型:字符串
默认值: TLSv1.2
有效值。
重要性:中等
ssl.provider
用于SSL连接的安全提供者的名称。默认值是JVM的默认安全提供者。类型:字符串
默认值: null
有效值。
重要性:中等
ssl.truststore.type
信任存储文件的文件格式。类型:字符串
默认值。 JKS
有效值。
重要性:中等
metadata.max.age.ms
即使我们没有看到任何分区领导权变化,我们也会强制刷新元数据,以主动发现任何新的broker或分区的时间,以毫秒为单位。类型:长
默认:300000(5分钟)
有效值:[0,...]
重要性:低
metric.reporters
作为度量报告器使用的类的列表。实现org.apache.kafka.common.metrics.MetricsReporter接口允许插入将被通知新的度量创建的类。JmxReporter总是被包含在注册JMX统计数据中。类型:列表
默认:""
有效值。
重要性:低
metrics.num.samples
为计算指标而维护的样本数量。类型:int
默认值:2
有效值:[1,...]
重要性:低
metrics.recording.level
指标的最高记录级别。类型:字符串
默认:INFO
有效值:[INFO, DEBUG, TRACE] [INFO, DEBUG, TRACE]
重要性:低
metrics.sample.window.ms
度量样本计算的时间窗口。类型:long
默认:30000(30秒)
有效值:[0,...]
重要性:低
reconnect.backoff.max.ms
当重新连接到一个反复连接失败的broker时,等待的最大时间,以毫秒为单位。如果提供,每台主机的backoff将在每一次连续连接失败时以指数形式增加,直到这个最大值。在计算背离增加后,20%的随机抖动被添加到避免连接风暴中。类型:long
默认:1000(1秒)
有效值:[0,...]
重要性:低
reconnect.backoff.ms
试图重新连接到给定主机前的基本等待时间。这可以避免在一个紧密的循环中重复连接到主机。这个backoff适用于客户端到broker的所有连接尝试。类型:long
默认值:50
有效值:[0,...]
重要性:低
retries
设置一个大于零的值将导致客户端重新发送任何失败的请求,并可能出现短暂的错误。建议将该值设置为零或`MAX_VALUE`,并使用相应的超时参数来控制客户端重试请求的时间。类型:int
默认:2147483647
有效值: [0,...,2147483647]
重要性:低
retry.backoff.ms
试图重试一个失败的请求前的等待时间。这可以避免在某些失败情况下,在一个紧密的循环中重复发送请求。类型:long
默认值:100
有效值:[0,...]
重要性:低
sasl.kerberos.kinit.cmd
Kerberos kinit 命令路径。类型:字符串
默认值。 /usr/bin/kinit
有效值。
重要性:低
sasl.kerberos.min.time.before.relogin
登录线程刷新尝试之间的睡眠时间。类型:long
默认值:60000
有效值。
重要性:低
sasl.kerberos.ticket.renew.jitter
随机抖动加到续航时间的百分比。类型:double
默认值:0.05
有效值。
重要性:低
sasl.kerberos.ticket.renew.window.factor
登录线程将休眠,直到达到从上次刷新到票据到期的指定时间窗口系数,这时它将尝试更新票据。类型:double
默认值:0.8
有效值。
重要性:低
sasl.login.refresh.buffer.seconds
刷新凭证时,在凭证到期前要保持的缓冲时间,以秒为单位。如果刷新的时间离到期时间比缓冲秒数更近,那么刷新时间将被提前,以尽可能多地保持缓冲时间。法定值在0到3600(1小时)之间;如果没有指定值,则使用默认值300(5分钟)。如果该值和sasl.login.refresh.min.period.seconds的总和超过了凭证的剩余寿命,则该值和sasl.login.refresh.min.period.seconds都会被忽略。目前只适用于OAUTHBEARER。类型:short
默认值:300
有效值:[0,...,3600]
重要性:低
sasl.login.refresh.min.period.seconds
登录刷新线程在刷新凭证前需要等待的最短时间,以秒为单位。合法值在0到900(15分钟)之间;如果没有指定值,则使用默认值60(1分钟)。如果这个值和sasl.login.refresh.buffer.seconds的总和超过了一个凭证的剩余寿命,那么这个值和sasl.login.buffer.seconds都会被忽略。目前只适用于OAUTHBEARER。类型:short
默认值:60
有效值:[0,...,900]
重要性:低
sasl.login.refresh.window.factor
登录刷新线程将休眠,直到达到相对于凭证寿命的指定窗口系数,此时将尝试刷新凭证。合法值在0.5(50%)到1.0(100%)之间,如果没有指定值,则使用默认值0.8(80%)。目前仅适用于OAUTHBEARER。类型:double
默认值:0.8
有效值:[0.5,...,1.0]
重要性:低
sasl.login.refresh.window.jitter
相对于凭证的寿命,加到登录刷新线程的睡眠时间的最大随机抖动量。合法值在0到0.25(25%)之间,如果没有指定值,则使用默认值0.05(5%)。目前只适用于OAUTHBEARER。类型:double
默认值:0.05
有效值:[0.0,...,0.25]
重要性:低
security.providers
一个可配置的创建者类的列表,每个类都返回一个实现安全算法的提供者。这些类应该实现org.apache.kafka.common.security.ah.SecurityProviderCreator接口。类型:字符串
默认值: null
有效值。
重要性:低
ssl.cipher.suites
密码套件的列表。这是一个命名的认证、加密、MAC和密钥交换算法的组合,用于使用TLS或SSL网络协议协商网络连接的安全设置。默认情况下,支持所有可用的密码套件。类型:列表
默认值: null
有效值。
重要性:低
ssl.endpoint.identification.algorithm
使用服务器证书验证服务器主机名的端点识别算法。类型:字符串
默认:https
有效值。
重要性:低
ssl.engine.factory.class
org.apache.kafka.common.security.auth.SslEngineFactory类型的类来提供SSLEngine对象。默认值是org.apache.kafka.common.security.ssl.DefaultSslEngineFactory。类型:类
默认值: null
有效值。
重要性:低
ssl.keymanager.algorithm
钥匙管理器工厂用于SSL连接的算法,默认值是为Java虚拟机配置的钥匙管理器工厂算法。默认值是为Java虚拟机配置的密钥管理器工厂算法。类型:字符串
默认值。 SunX509
有效值。
重要性:低
ssl.secure.random.implementation
用于SSL加密操作的SecureRandom PRNG实现。类型:字符串
默认值: null
有效值。
重要性:低
ssl.trustmanager.algorithm
信任管理器工厂用于SSL连接的算法。默认值是为Java虚拟机配置的信任管理器工厂算法。类型:字符串
默认值。 PKIX
有效值。
重要性:低
4.设计
4.1 动机
我们设计Kafka是为了能够作为一个统一的平台来处理一个大公司可能拥有的所有实时数据源。要做到这一点,我们必须考虑一套相当广泛的用例。
它必须具备高吞吐量,以支持大容量的事件流,如实时日志聚合。
它需要优雅地处理大量的数据积压,以支持来自离线系统的定期数据负载。
这也意味着系统必须处理低延迟交付,以处理更多传统的消息传递用例。
我们希望支持对这些feeds进行分区、分布式、实时处理,以创建新的衍生feeds。这激励了我们的分区和消费者模型。
最后,在将数据流送入其他数据系统进行服务的情况下,我们知道系统必须能够保证在机器出现故障时的容错性。
支持这些用途使得我们设计出了一个具有一些独特元素的系统,更类似于数据库日志,而不是传统的消息系统。我们将在下面的章节中概述该设计的一些元素。
4.2 持久性
别担心文件系统!
Kafka严重依赖文件系统来存储和缓存消息。人们普遍认为 "磁盘很慢",这让人们怀疑持久化结构是否能提供有竞争力的性能。事实上磁盘比人们预期的慢和快都要快得多,这取决于如何使用磁盘;而设计得当的磁盘结构往往可以和网络一样快。
关于磁盘性能的关键事实是,在过去的十年里,硬盘的吞吐量与磁盘寻道的延迟一直在分化。因此,在6块7200rpm SATA RAID-5阵列的JBOD配置上,线性写入的性能约为600MB/秒,但随机写入的性能只有约100k/秒--相差6000多倍。这些线性读写是所有使用模式中最可预测的,并且由操作系统进行了大量优化。现代操作系统提供了读前和写后技术,以大块倍数预取数据,并将较小的逻辑写入分组为大的物理写入。关于这个问题的进一步讨论可以在这篇ACM Queue文章中找到,实际上他们发现顺序磁盘访问在某些情况下可以比随机内存访问更快!
为了补偿这种性能上的分歧,现代操作系统在使用主内存进行磁盘缓存方面变得越来越积极。现代操作系统会很乐意将所有的空闲内存转移到磁盘缓存中,而当内存被回收时,几乎没有性能上的损失。所有的磁盘读写都会经过这个统一的缓存。如果不使用直接的I/O,就不能轻易关闭这个功能,所以即使一个进程维护了数据的进程内缓存,这些数据也很可能会在OS的pagecache中重复,实际上是把所有的东西都存储了两次。
此外,我们是在JVM之上构建的,任何花过时间研究Java内存使用的人都知道两件事。
- 对象的内存开销是非常大的,往往是存储的数据大小的两倍(或者更糟)。
- 随着堆内数据的增加,Java垃圾收集变得越来越费事和缓慢。
由于这些因素,使用文件系统和依靠pagecache比维护内存中的缓存或其他结构更优越--我们通过对所有空闲内存的自动访问,至少使可用的缓存增加一倍,而且通过存储一个紧凑的字节结构而不是单个对象,很可能再增加一倍。这样做的结果是,在32GB的机器上,可以获得高达28-30GB的缓存,而不会受到GC的惩罚。此外,即使服务重启,这个缓存也会保持温热,而进程中的缓存则需要在内存中重建(对于10GB的缓存来说,可能需要10分钟),否则就需要从一个完全冷的缓存开始(这很可能意味着糟糕的初始性能)。这也极大地简化了代码,因为所有维持缓存和文件系统之间一致性的逻辑现在都在操作系统中,这往往比一次性的进程内尝试更有效、更正确。如果你的磁盘使用倾向于线性读取,那么read-ahead有效地在每次磁盘读取时用有用的数据预先填充这个缓存。
这表明了一种非常简单的设计:与其在内存中保持尽可能多的数据,并在空间耗尽时慌忙将其全部冲到文件系统中,不如反过来。所有的数据都会立即写入文件系统上的一个持久性日志,而不一定要冲到磁盘上。实际上,这只是意味着它被转移到内核的pagecache中。
这种以pagecache为中心的设计风格在Varnish设计的一篇文章中有所描述(还有一点傲慢)。
固定的时间就足够了
消息系统中使用的持久性数据结构通常是每个消费者队列,并有一个相关的BTree或其他通用的随机访问数据结构来维护消息的元数据。BTree是目前最通用的数据结构,它使得在消息系统中支持各种各样的事务性和非事务性语义成为可能。不过它们的成本确实相当高:Btree的操作是O(log N)。通常O(log N)被认为基本等同于恒定时间,但对于磁盘操作来说,这并不是真的。磁盘搜索的速度是10毫秒一次,而且每个磁盘一次只能做一次搜索,所以并行性是有限的。因此,即使是少量的磁盘寻道也会导致非常高的开销。由于存储系统将非常快的缓存操作和非常慢的物理磁盘操作混合在一起,所以树形结构的观察性能往往是随着数据的增加而固定缓存的超线性的--也就是说,你的数据增加一倍,情况就会比慢一倍要糟糕得多。
直观地讲,一个持久性队列可以建立在简单的文件读取和追加上,就像常见的日志解决方案一样。这种结构的优点是,所有的操作都是O(1),读不会阻塞写或彼此。这具有明显的性能优势,因为性能与数据大小完全解耦--一台服务器现在可以充分利用一些廉价的、低转速的1+TB SATA硬盘。虽然这些硬盘的寻道性能较差,但对于大型读写来说,它们的性能还是可以接受的,而且价格只有1/3,容量只有3倍。
在没有任何性能损失的情况下,可以访问几乎无限的磁盘空间,这意味着我们可以提供一些通常在消息系统中找不到的功能。例如,在Kafka中,我们可以将消息保留相对较长的时间(比如一周),而不是在消息消耗完后立即尝试删除它们。这为消费者带来了很大的灵活性,我们将进行描述。
4.3 效率
我们在效率方面下了很大功夫。我们的主要用例之一是处理网络活动数据,这是非常大的工作量:每个页面浏览可能会产生几十次写入。此外,我们假设每条发布的消息至少被一个消费者(通常是许多)读取,因此我们努力使消费尽可能便宜。
从构建和运行一些类似系统的经验中,我们还发现,效率是多租户有效运营的关键。如果下游的基础设施服务很容易因为应用的一个小的使用量的提升而成为瓶颈,这种小的变化往往会带来问题。通过非常快的速度,我们有助于确保应用在负载下会先于基础设施而倾覆。当我们试图在一个集中式集群上运行一个支持几十个或几百个应用程序的集中式服务时,这一点尤为重要,因为使用模式的变化几乎每天都会发生。
我们在上一节讨论了磁盘效率。一旦消除了不良的磁盘访问模式,在这种类型的系统中,有两个常见的低效率原因:过多的小I/O操作,以及过多的字节复制。
小I/O问题既发生在客户端和服务器之间,也发生在服务器自身的持久化操作中。
为了避免这种情况,我们的协议是围绕着一个 "消息集 "抽象建立的,它自然地将消息分组。这使得网络请求可以将消息分组,并摊销网络往返的开销,而不是每次只发送一条消息。而服务器则一次性将消息分块追加到其日志中,消费者则一次取回大的线性分块。
这个简单的优化产生了数量级的速度提升。批量导致更大的网络数据包、更大的顺序磁盘操作、连续的内存块等等,所有这些都让Kafka将随机消息写入的突发流变成线性写入,流向消费者。
另一个低效率是在字节复制方面。在低消息速率下,这不是问题,但在负载下,影响很大。为了避免这种情况,我们采用了标准化的二进制消息格式,由生产者、broker和消费者共享(因此数据块可以在他们之间不加修改地传输)。
broker维护的消息日志本身只是一个文件目录,每个文件都由一连串的消息集填充,这些消息集已经以生产者和消费者使用的相同格式写入磁盘。保持这种共同的格式可以优化最重要的操作:网络传输持久的日志块。现代的unix操作系统提供了一个高度优化的代码路径,用于将数据从pagecache中传输到socket中;在Linux中,这是通过sendfile系统调用完成的。
要了解sendfile的影响,就必须了解从文件到socket传输数据的常用数据路径。
- 操作系统从磁盘上读取数据到内核空间的pagecache中。
- 应用程序将数据从内核空间读取到用户空间缓冲区中
- 应用程序将数据写回内核空间到socket缓冲区中
- 操作系统将数据从套接字缓冲区复制到网卡缓冲区,并通过网络发送。
这显然效率很低,有四次拷贝和两次系统调用。使用sendfile,可以让操作系统直接将数据从pagecache发送到网络上,避免了这种重复复制。所以在这个优化的路径中,只需要最后复制到网卡缓冲区。
我们预计一个常见的用例是一个主题上有多个消费者。使用上面的零拷贝优化,数据被准确地复制到pagecache中一次,并在每次消费时重复使用,而不是存储在内存中,并在每次读取时复制到用户空间。这样可以使消息的消耗速度接近网络连接的极限。
pagecache和sendfile的这种组合意味着,在一个Kafka集群中,消费者大部分都被赶上了,你将看到磁盘上没有任何读取活动,因为它们将完全从缓存中提供数据。
关于Java中sendfile和零拷贝支持的更多背景,请看这篇文章。
端到端批量压缩
在某些情况下,瓶颈其实不是CPU或磁盘,而是网络带宽。对于一个需要通过广域网在数据中心之间发送消息的数据管道来说尤其如此。当然,用户总是可以在不需要Kafka提供任何支持的情况下一次压缩其消息,但这可能会导致很差的压缩比,因为很多冗余是由于相同类型的消息之间的重复(例如JSON中的字段名或Web日志中的用户代理或共同的字符串值)。高效的压缩需要将多个消息一起压缩,而不是单独压缩每个消息。
Kafka通过高效的批处理格式来支持这一点。一批消息可以被丛生压缩在一起,并以这种形式发送到服务器。这批消息将以压缩的形式写入日志,并在日志中保持压缩状态,只有消费者才会解压。
Kafka支持GZIP、Snappy、LZ4和ZStandard压缩协议。关于压缩的更多细节可以在这里找到。
4.4 生产者
负载均衡
生产者直接将数据发送到作为分区领导者的broker,而不需要任何干预的路由层。为了帮助生产者做到这一点,所有的Kafka节点都可以应答关于哪些服务器是活着的,以及某个主题的分区的领导者在哪里的元数据请求,以便生产者适当地引导其请求。
客户端控制它将消息发布到哪个分区。这可以是随机的,实现一种随机负载均衡,也可以通过一些语义分区函数来实现。我们公开了语义分区的接口,允许用户指定一个密钥来进行分区,并使用这个密钥来哈希到一个分区(如果需要的话,还可以选择覆盖分区函数)。例如,如果选择的键是一个用户id,那么给定用户的所有数据将被发送到同一个分区。这又将允许消费者对他们的消费进行位置性假设。这种分区风格被明确设计为允许消费者进行区位性敏感处理。
异步发送
批量是提高效率的一大驱动力,为了实现批量化,Kafka生产者会尝试在内存中积累数据,并在一次请求中发送更大的批量。批量可以配置为积累不超过固定数量的消息,并且等待的时间不超过某个固定的延迟边界(比如64k或10ms)。这样可以积累更多的字节发送,服务器上很少有较大的I/O操作。这种缓冲是可配置的,并提供了一种机制来换取少量的额外延迟以获得更好的吞吐量。
关于配置的细节和生产者的api可以在文档的其他地方找到。
4.5 消费者
Kafka消费者的工作方式是向它要消费的分区的领导broker发出 "获取 "请求。消费者通过每个请求指定其在日志中的偏移量,并接收回从该位置开始的一大块日志。因此,消费者对这个位置有很大的控制权,如果需要的话,可以将其倒转过来重新消费数据。
推送 vs 拉取
我们最初考虑的一个问题是,消费者应该从broker那里拉取数据,还是broker应该将数据推送给消费者。在这方面,Kafka遵循的是一种比较传统的设计,大多数消息系统都有这种设计,数据从生产者推送给broker,消费者从broker那里拉取数据。一些以日志为中心的系统,如Scribe和Apache Flume,遵循的是一种非常不同的基于推送的路径,数据被推送到下游。这两种方法各有利弊。然而,基于推送的系统很难处理不同的消费者,因为broker控制数据传输的速度。目标一般是让消费者能够以最大可能的速率消费;不幸的是,在推式系统中,这意味着当消费者的消费速率低于生产速率时,消费者往往会被淹没(本质上是拒绝服务攻击)。基于拉的系统有一个较好的特性,即消费者只是落在后面,当它能赶上的时候就会赶上。这种情况可以通过某种后退协议来缓解,消费者可以通过这种协议来表示它已经不堪重负,但是让传输速率充分利用(但永远不要过度利用)消费者是比看起来更棘手的。之前以这种方式构建系统的尝试,让我们选择了更传统的拉式模式。
基于拉的系统的另一个优点是,它适合于积极地批量发送数据给消费者。基于推的系统必须选择要么立即发送请求,要么积累更多的数据,然后在不知道下游消费者是否能够立即处理的情况下再发送。如果针对低延迟进行调整,这将导致每次发送一条消息,但最后还是被缓冲传输,这是一种浪费。基于拉动的设计解决了这个问题,因为消费者总是在日志中的当前位置后拉动所有可用的消息(或达到某个可配置的最大大小)。因此,人们可以在不引入不必要的延迟的情况下获得最佳的批处理。
天真的基于拉动的系统的不足之处是,如果broker没有数据,消费者可能最终会在一个紧密的循环中进行轮询,实际上是忙于等待数据的到来。为了避免这种情况,我们在拉动请求中设置了参数,允许消费者请求以 "长轮询 "的方式阻塞,等待数据的到来(也可以选择等待到给定的字节数,以确保大的传输规模)。
你可以想象其他可能的设计,这将是只拉,端到端。生产者将在本地写入本地日志,而broker将从中拉取数据,消费者也将从中拉取数据。类似类型的 "存储和转发 "生产者经常被提出。这很有吸引力,但我们觉得不太适合我们的目标用例,因为我们的目标用例有成千上万的生产者。我们在大规模运行持久性数据系统的经验使我们感到,在系统中涉及数千块磁盘,跨越许多应用,实际上不会使事情变得更可靠,而且会成为操作的噩梦。而在实践中我们发现,我们可以在不需要生产者持久化的情况下,大规模运行具有强大SLA的流水线。
消费者位置
追踪哪些消息已经被消费,竟然是消息系统的关键性能点之一。
大多数消息系统都会在broker上保存关于哪些消息已经被消费的元数据。也就是说,当一条消息被递给消费者时,broker要么立即在本地记录这一事实,要么可能会等待消费者的确认。这是一个相当直观的选择,事实上对于单机服务器来说,并不清楚这个状态还能去哪里。由于许多消息系统中用于存储的数据结构扩展性很差,这也是一个实用主义的选择--由于中间商知道什么东西被消耗了,它可以立即删除它,保持数据的小规模。
也许并不明显的是,让中间商和消费者就什么被消耗了达成一致并不是一个小问题。如果broker每次在网络上递出一条消息时,都会立即记录为已消耗,那么如果消费者未能处理该消息(比如说因为它崩溃或请求超时或其他原因),该消息将丢失。为了解决这个问题,很多消息系统都增加了一个确认功能,也就是说消息在发送的时候只标记为已发送而非消耗,中间人会等待消费者的特定确认,将消息记录为消耗。这种策略解决了消息丢失的问题,但又产生了新的问题。首先,如果消费者处理了消息,但在发送确认之前就失败了,那么消息就会被消耗两次。第二个问题是围绕着性能,现在broker必须对每一条消息保持多个状态(首先要锁定它,这样它就不会被第二次发出,然后把它标记为永久消耗,这样就可以删除它)。必须处理一些棘手的问题,比如如何处理那些已经发送但从未被确认的消息。
Kafka的处理方式不同。我们的主题被划分为一组完全有序的分区,每个分区在任何时候都正好被每个订阅消费者组中的一个消费者消耗。这意味着消费者在每个分区中的位置只是一个单一的整数,即下一个要消耗的消息的偏移。这使得关于已经消耗的状态非常小,每个分区只有一个数字。这个状态可以定期检查点。这使得相当于消息确认的成本非常低。
这个决定有一个侧面的好处。消费者可以故意倒退到一个旧的偏移量,重新消耗数据。这违反了队列的普通契约,但对许多消费者来说,这原来是一个必不可少的功能。例如,如果消费者的代码有一个bug,并且在一些消息被消耗后被发现,那么一旦bug被修复,消费者就可以重新消耗这些消息。
离线数据加载
可扩展的持久性允许只进行周期性消费的消费者,比如批量数据加载,周期性地将数据批量加载到Hadoop或关系型数据仓库等离线系统中。
在Hadoop的情况下,我们通过将数据负载拆分到各个地图任务上,每个节点/主题/分区组合一个任务,实现数据负载的完全并行化。Hadoop提供了任务管理,失败的任务可以重新开始,而不会有重复数据的危险--它们只是从原来的位置重新开始。
静态会员制度
静态成员资格旨在提高建立在组再平衡协议之上的流应用、消费者组和其他应用的可用性。再平衡协议依赖于组协调器为组成员分配实体id。这些生成的id是短暂的,当成员重新启动和重新加入时,这些id会发生变化。对于基于消费者的应用程序,这种 "动态成员 "可能会导致在管理操作期间(如代码部署、配置更新和定期重启),将大比例的任务重新分配给不同的实例。对于大状态的应用,洗牌后的任务在处理前需要长时间恢复其本地状态,并导致应用部分或完全不可用。在这一观察的激励下,Kafka的组管理协议允许组成员提供持久的实体id。组成员基于这些id保持不变,因此不会触发重新平衡。
如果你想使用静态成员资格。
- 将broker集群和客户端应用都升级到2.3或更高版本,同时确保升级后的broker也使用2.3或更高版本的inter.broker.协议。
- 将config ConsumerConfig#GROUP_INSTANCE_ID_CONFIG设置为一个组下每个消费者实例的唯一值。
- 对于Kafka Streams应用,为每个KafkaStreams实例设置一个唯一的ConsumerConfig#GROUP_INSTANCE_ID_CONFIG即可,与实例的使用线程数无关。
如果你的broker处于比2.3更老的版本,但你选择在客户端设置ConsumerConfig#GROUP_INSTANCE_ID_CONFIG,应用程序将检测broker的版本,然后抛出一个UnsupportedException。如果你不小心为不同的实例配置了重复的id,broker端的围栏机制会通过触发org.apache.kafka.common.error.FencedInstanceIdException来通知你的重复客户端立即关闭。更多细节,请参见KIP-345
4.6 消息传递语义
现在我们已经对生产者和消费者的工作方式有了一些了解,让我们来讨论一下Kafka在生产者和消费者之间提供的语义保证。显然,可以提供多种可能的消息传递保证。
- 最多一次--消息可能会丢失,但永远不会被重传。
- 至少一次--消息永远不会丢失,但可能会被重新传递。
- 正好一次--这才是人们真正想要的,每条信息都是一次,而且只有一次。
值得注意的是,这分为两个问题:发布消息的耐久性保证和消费消息时的保证。
很多系统都声称提供 "精确一次 "的交付语义,但要看清字面意思,这些说法大多是误导性的(即不能转化为消费者或生产者可能失败的情况,也不能转化为有多个消费进程的情况,或者写入磁盘的数据可能丢失的情况)。
Kafka的语义是直接的。当发布一条消息时,我们有一个消息被 "提交 "到日志的概念。一旦发布的消息被提交,只要有一个复制这个消息写入的分区的broker仍然 "活着",它就不会丢失。提交的消息、活着的分区的定义,以及我们试图处理哪些类型的故障的描述,将在下一节中详细介绍。现在让我们假设一个完美的、无损的broker,并尝试理解对生产者和消费者的保证。如果生产者尝试发布消息并遇到网络错误,它无法确定这个错误是发生在消息提交之前还是之后。这类似于用自动生成的键插入到数据库表中的语义。
在0.11.0.0之前,如果生产者没有收到表明消息已提交的响应,它几乎没有选择,只能重新发送消息。这提供了至少一次的交付语义,因为如果原始请求事实上已经成功,消息可能会在重新发送期间再次写入日志。从0.11.0.0开始,Kafka生产者也支持幂等传递选项,它保证重新发送不会导致日志中的重复条目。为了实现这一点,broker为每个生产者分配一个ID,并使用生产者随每条消息一起发送的序列号对消息进行重复复制。同时从0.11.0.0开始,生产者支持使用类似事务的语义向多个主题分区发送消息:即要么所有消息都成功写入,要么都没有。主要的用例是Kafka主题之间的精确一次处理(如下所述)。
并非所有的用例都需要如此强大的保证。对于延迟敏感的用例,我们允许生产者指定它想要的耐久性级别。如果生产者指定它希望等待消息被提交,这可能需要10毫秒的时间。然而,生产者也可以指定它想完全异步地执行发送,或者它想只等待直到领导者(但不一定是跟随者)得到消息。
现在让我们从消费者的角度来描述语义。所有的副本都有完全相同的日志,有相同的偏移量。消费者控制它在这个日志中的位置。如果消费者从来没有崩溃过,它可以只把这个位置存储在内存中,但是如果消费者失败了,我们希望这个主题分区被另一个进程接管,新的进程就需要选择一个合适的位置,从这个位置开始处理。比方说,消费者读取了一些消息--它有几个选择来处理这些消息并更新它的位置。
- 它可以读取消息,然后将其位置保存在日志中,最后处理消息。在这种情况下,消费者进程有可能在保存其位置后但在保存其消息处理的输出之前崩溃。在这种情况下,接手处理的进程将从保存的位置开始,即使在该位置之前的几个报文还没有被处理。这对应于 "最多一次 "的语义,因为在消费者失败的情况下,消息可能不会被处理。
- 它可以读取消息,处理消息,最后保存自己的位置。在这种情况下,消费者进程有可能在处理完消息后但在保存位置之前崩溃。在这种情况下,当新进程接手时,它收到的前几个报文已经被处理过了。这对应于消费者失败时的 "at-least-once "语义。在许多情况下,消息有一个主键,因此更新是幂等的(两次收到相同的消息只是用另一个副本覆盖了一条记录)。
那么到底一次语义(即你真正想要的东西)呢?当从一个Kafka主题中消费并生产到另一个主题时(如在Kafka Streams应用中),我们可以利用上面提到的0.11.0.0中新的事务生产者功能。消费者的位置作为消息存储在一个主题中,所以我们可以在同一个事务中把偏移量写到Kafka,与接收处理数据的输出主题一样。如果事务中止,消费者的位置将恢复到旧值,输出主题上产生的数据将对其他消费者不可见,这取决于他们的 "隔离级别"。在默认的 "read_uncommitted "隔离级别中,所有的消息对消费者都是可见的,即使它们是被中止的事务的一部分,但在 "read_committed "中,消费者将只返回来自已提交的事务的消息(以及任何不属于事务的消息)。
当向外部系统写入时,其局限性在于需要协调消费者的位置与实际存储的输出内容。实现这一目标的经典方法是在消费者位置的存储和消费者输出的存储之间引入一个两阶段的提交。但这可以通过让消费者将其偏移量存储在与其输出相同的地方来处理,更加简单和普遍。这样做比较好,因为消费者可能要写入的许多输出系统都不会支持两阶段提交。作为一个例子,考虑一个Kafka Connect连接器,它在HDFS中填充数据的同时,也填充了它所读取的数据的偏移量,这样就可以保证数据和偏移量都更新,或者都不更新。我们对许多其他数据系统遵循类似的模式,这些系统需要这些更强的语义,而且对于这些系统来说,消息没有一个主键来允许重复数据删除。
因此,有效地,Kafka支持Kafka Streams中的精确一交,当在Kafka主题之间传输和处理数据时,事务性生产者/消费者可以被普遍用于提供精确一交。对于其他目的系统的精确一次交付一般需要与这些系统合作,但Kafka提供了偏移,使得实现这一功能是可行的(另见Kafka Connect)。否则,Kafka默认保证最多一次交付,并允许用户在处理一批消息之前,通过在生产者上禁用重试和在消费者中提交偏移来实现最多一次交付。
4.7 副本
Kafka将每个主题的分区的日志复制到可配置数量的服务器上(你可以按主题设置这个复制因子)。这样当集群中的一台服务器出现故障时,可以自动将故障转移到这些复制件上,这样在出现故障时消息仍然可用。
其他消息系统也提供了一些与复制相关的功能,但是,在我们(完全有偏见)看来,这似乎是一个附加的东西,并没有被大量使用,而且有很大的弊端:复制体不活跃,吞吐量受到严重影响,需要繁琐的手动配置等等。Kafka是要默认使用复制的--事实上,我们把未复制的topic实现为复制的topic,复制因子为1。
复制的单位是主题分区。在非故障条件下,Kafka中的每个分区都有一个领导者和零个或多个跟随者。包括leader在内的复制总数构成复制因子。所有的读和写都要到分区的领导者那里去。通常情况下,分区的数量比broker多得多,领袖在broker中均匀分布。跟随者的日志与领导者的日志完全相同--所有的日志都有相同的偏移量,消息的顺序也相同(当然,在任何时候,领导者的日志末尾可能有一些尚未复制的消息)。
跟随者就像普通的Kafka消费者一样从领导者那里消费消息,并将它们应用到自己的日志中。让追随者从领导者那里拉取消息有一个很好的特性,即允许追随者自然地将他们应用到自己的日志中的日志条目批量化。
与大多数分布式系统一样,自动处理故障需要对一个节点的 "活着 "的含义有一个精确的定义。对于Kafka来说,节点的活泼度有两个条件
- 一个节点必须能够维持它与ZooKeeper的会话(通过ZooKeeper的心跳机制)。
- 如果它是一个跟随者,它必须复制发生在领导者身上的写法,而不是 "太远 "地落在后面。
我们将满足这两个条件的节点称为 "同步",以避免 "活着 "或 "失败 "的模糊性。领导者会跟踪 "同步 "节点的集合。如果一个跟随者死亡、卡住或落后,领导者会将其从同步副本列表中移除。卡住和滞后的副本的确定由 replica.lag.time.max.ms 配置控制。
在分布式系统术语中,我们只尝试处理 "失败/恢复 "模型的故障,即节点突然停止工作,然后再恢复(可能不知道自己已经死亡)。Kafka不处理所谓的 "拜占庭 "故障,在这种情况下,节点会产生任意或恶意的响应(也许是由于bug或犯规)。
我们现在可以更精确地定义,当该分区的所有同步复制体都将消息应用到它们的日志中时,该消息就被认为是已提交的。只有已提交的消息才会被提供给消费者。这意味着消费者不需要担心可能会看到一条消息,如果领导者失败,这条消息就会丢失。另一方面,生产者可以选择等待消息提交或不提交,这取决于他们对延迟和耐用性之间权衡的偏好。这个偏好由生产者使用的 acks 设置控制。请注意,主题有一个设置,当生产者请求确认消息已经写入全部同步副本集时,会检查同步副本的 "最小数量"。如果生产者请求一个不那么严格的确认,那么即使in-synchronic replicas的数量低于最小值(比如可以低到只有leader),消息也可以被提交,并被消费。
Kafka提供的保证是,只要至少有一个在同步副本活着,在任何时候,提交的消息都不会丢失。
Kafka在经过短暂的故障切换期后,在节点故障的情况下仍能保持可用,但在网络分区的情况下可能无法保持可用。
重复的日志:ISRs集群, 以及状态机器
Kafka分区的核心是一个复制日志。复制日志是分布式数据系统中最基本的基元之一,实现复制日志的方法有很多。复制日志可以被其他系统作为一个基元来实现其他分布式系统的状态机风格。
复制日志模拟了对一系列值的顺序达成共识的过程(一般将日志条目编号为0,1,2,...)。有很多方法可以实现,但最简单和最快的是由一个领导者选择提供给它的值的顺序。只要领导者还活着,所有的跟随者只需要复制领导者选择的值和排序。
当然,如果领导者不失败,我们就不需要追随者了! 当领袖真的死了,我们需要从追随者中选择一个新的领袖。但是追随者本身可能会落后或者崩溃,所以我们必须保证选择一个最新的追随者。一个日志复制算法必须提供的基本保证是,如果我们告诉客户端一个消息被提交,而领导者失败了,我们选出的新领导者也必须有这个消息。这就产生了一个权衡:如果领导者等待更多的追随者确认一条消息后再宣布它已提交,那么就会有更多潜在的可选领导者。
如果你选择确认所需的数量和必须比较的日志数量来选举一个领导者,这样就保证了有一个重叠,那么这就叫做Quorum。
对于这种权衡,一个常见的方法是在提交决定和领袖选举中都使用多数票。这不是Kafka所做的,但我们还是来探讨一下,以了解其中的权衡。假设我们有2f+1个副本。如果f+1个复制体必须在领导者宣布提交之前收到一条消息,如果我们通过选举至少f+1个复制体中日志最完整的跟随者来选举新的领导者,那么,在不超过f次失败的情况下,领导者可以保证拥有所有的提交消息。这是因为在任何f+1个副本中,一定有至少一个副本包含所有已提交的消息。该副本的日志将是最完整的,因此将被选为新的领导者。还有很多其余的细节,每个算法都必须处理(比如精确定义什么使日志更完整,在领导者失败时确保日志的一致性,或者改变副本集的服务器集),但我们暂时忽略这些。
这种多数票的方法有一个非常好的特性:延迟只依赖于最快的服务器。也就是说,如果复制因子为三,延迟是由速度更快的跟随者决定的,而不是由速度较慢的跟随者决定的。
这个系列的算法非常丰富,包括ZooKeeper的Zab、Raft和Viewstamped Replication。据我们所知,与Kafka实际实现最相似的学术刊物是微软的PacificA。
多数票的缺点是,不需要很多次失败就可以让你没有可选的领导者。要容忍一次失败需要三份数据,要容忍两次失败需要五份数据。根据我们的经验,只拥有足够的冗余来容忍一次故障,对于一个实用的系统来说是不够的,但是每一次写都要做五次,对磁盘空间的要求是5倍,吞吐量是1/5,对于大批量的数据问题来说是不太实用的。这可能就是为什么在ZooKeeper等共享集群配置中更多的出现配额算法,但在主数据存储中却不常见的原因。例如在HDFS中,namenode的高可用性功能是建立在基于多数票的日记上,但这种比较昂贵的方法并没有用于数据本身。
Kafka在选择其法定人数集时采取了一种稍微不同的方法。Kafka不采用多数票,而是动态地维护了一组追赶上领导者的同步副本(ISR)。只有这个集合的成员才有资格当选为领导者。对Kafka分区的写入,在所有同步复制体收到写入之前,不被认为是提交。每当ISR集发生变化时,这个ISR集就会被持久化到ZooKeeper上。正因为如此,ISR中的任何副本都有资格当选为领导者。这对于Kafka的使用模型来说是一个重要的因素,因为在Kafka的使用模型中,有很多分区,确保领导力的平衡是很重要的。有了这个ISR模型和f+1个副本,一个Kafka主题可以容忍f次失败而不会丢失已提交的消息。
对于我们希望处理的大多数用例,我们认为这种权衡是合理的。在实践中,为了容忍f次失败,多数票和ISR方法都会在提交消息之前等待相同数量的副本确认(例如,为了在一次失败中幸存下来,多数票需要三个副本和一个确认,而ISR方法需要两个副本和一个确认)。在没有最慢服务器的情况下提交的能力是多数票方式的一个优势。然而,我们认为,通过允许客户端选择是否在消息提交时阻塞,可以改善这种情况,由于较低的所需复制因子而带来的额外吞吐量和磁盘空间是值得的。
另一个重要的设计区别是,Kafka不要求崩溃的节点在恢复时所有数据都完好无损。在这个空间中,复制算法依赖于 "稳定存储 "的存在,在任何故障恢复情况下都不能丢失,而不会出现潜在的一致性违反,这并不罕见。这种假设有两个主要问题。首先,磁盘错误是我们在持久性数据系统的实际运行中观察到的最常见的问题,它们往往不会让数据保持完整。其次,即使这不是问题,我们也不希望要求在每次写入时都使用fsync来保证我们的一致性,因为这会使性能降低两到三个数量级。我们允许一个副本重新加入ISR的协议确保在重新加入之前,即使它在崩溃中丢失了未刷新的数据,也必须再次完全重新同步。
不干净的领袖选举。如果他们都死了怎么办?
请注意,Kafka对数据丢失的保证是以至少一个副本保持同步为前提的。如果复制一个分区的所有节点都死了,这个保证就不再成立。
然而一个实用的系统需要在所有的复制体都死掉的时候做一些合理的事情。如果你很不走运地发生了这种情况,就要考虑会发生什么。有两种行为可以实现。
- 等待ISR中的一个副本复活,然后选择这个副本作为领导者(希望它还有所有数据)。
- 选择第一个恢复生命的副本(不一定在ISR中)作为领导者。
这是可用性和一致性之间的简单权衡。如果我们在ISR中等待副本,那么只要这些副本宕机,我们就会一直不可用。如果这样的副本被破坏或者它们的数据丢失,那么我们就会永久宕机。另一方面,如果一个非同步的副本恢复了生命,我们允许它成为领导者,那么它的日志就会成为真理的来源,即使它不能保证拥有每一条提交的消息。从0.11.0.0版本开始,默认情况下,Kafka会选择第一种策略,并偏向于等待一个一致的副本。这种行为可以使用配置属性unclean.leader.election.enable进行更改,以支持正常运行时间优于一致性的用例。
这个难题并不是Kafka特有的。它存在于任何基于法定人数的方案中。例如,在多数投票方案中,如果大多数服务器遭遇永久性故障,那么你必须选择失去100%的数据,或者违反一致性,将现有服务器上剩余的数据作为新的真理来源。
可用性和耐用性保证
当向Kafka写入消息时,生产者可以选择是等待消息被0,1还是所有(-1)复制体确认。请注意,"所有副本的确认 "并不能保证所有分配的副本都收到了消息。默认情况下,当acks=all时,只要当前所有同步的副本都收到了消息,就会发生确认。例如,如果一个主题只配置了两个副本,而其中一个失败了(即只剩下一个同步副本),那么指定acks=all的写入将成功。但是,如果剩余的副本也发生故障,这些写入可能会丢失。虽然这确保了分区的最大可用性,但对于一些喜欢耐久性而不是可用性的用户来说,这种行为可能是不可取的。因此,我们提供了两种主题级配置,可以用来优先选择消息耐久性而不是可用性。
- Disable unclean leader election - 如果所有的副本都变得不可用,那么分区将保持不可用,直到最近的领导者再次变得可用。这有效地优先考虑了不可用性而不是消息丢失的风险。请参阅上一节 "不干净的领导者选举 "进行说明。
- 指定最小ISR大小--只有当ISR的大小超过某个最小值时,分区才会接受写入,以防止只写入一个副本的消息丢失,而这个副本随后变得不可用。这个设置只有在生产者使用acks=all,并保证消息至少会被这么多的in-synchronic replicas承认的情况下才会生效。这个设置提供了一致性和可用性之间的权衡。更高的最小ISR大小设置保证了更好的一致性,因为消息被保证写入更多的副本,从而降低了消息丢失的概率。然而,它降低了可用性,因为如果同步副本的数量降到最小阈值以下,分区将不可用于写入。
副本管理
上面关于复制日志的讨论其实只涉及到一个日志,即一个主题分区。然而一个Kafka集群将管理成百上千的这些分区。我们试图以轮回的方式平衡集群内的分区,以避免将高容量主题的所有分区集中在少数节点上。同样,我们也试图平衡领导力,使每个节点在其分区中按比例成为领导者。
优化领导力选举过程也很重要,因为那是不可用的关键窗口。领导者选举的天真实现最终会在一个节点失败时,为该节点托管的所有分区进行每个分区的选举。取而代之的是,我们选择其中一个broker作为 "控制器"。这个控制器在broker级别检测故障,并负责改变故障broker中所有受影响分区的leader。其结果是,我们能够将许多所需的领导层变更通知批处理在一起,这使得选举过程对于大量的分区来说更加便宜和快速。如果控制器失败,其中一个幸存的broker将成为新的控制器。
4.8 日志压缩
日志压实确保Kafka将始终为单个主题分区的数据日志内的每个消息键保留至少最后一个已知值。它解决了一些用例和场景,如在应用崩溃或系统故障后恢复状态,或在运行维护期间重启应用后重载缓存。让我们更详细地深入了解这些用例,然后描述压实的工作原理。
到目前为止,我们只描述了较简单的数据保留方法,即在固定时间后或当日志达到某个预定大小时,旧的日志数据将被丢弃。这对于时间性事件数据,比如每条记录都是独立存在的记录,效果很好。然而一类重要的数据流是键控的、可突变的数据的变化日志(例如,数据库表的变化)。
我们来讨论一下这种数据流的一个具体例子。假设我们有一个包含用户电子邮件地址的主题;每次用户更新他们的电子邮件地址时,我们都会使用他们的用户id作为主键向这个主题发送一条消息。现在假设我们在一段时间内为一个id为123的用户发送以下消息,每条消息对应于一个电子邮件地址的变化(其他id的消息省略)。
123 => bill@microsoft.com...123 => bill@gatesfoundation.org...123 => bill@gmail.com
日志压缩为我们提供了一个更细化的保留机制,这样我们就可以保证至少保留每个主键的最后一次更新(例如:bill@gmail.com)。通过这样做,我们保证日志中包含了每个键的最终值的完整快照,而不仅仅是最近改变的键。这意味着下游消费者可以在这个主题之外恢复他们自己的状态,而无需我们保留所有变化的完整日志。
让我们先看几个有用的用例,然后再看看如何使用它。
- 数据库变更订阅。经常需要在多个数据系统中拥有一个数据集,而这些系统中经常有一个是某种数据库(无论是RDBMS还是可能是一个新式的键值存储)。例如你可能有一个数据库、一个缓存、一个搜索集群和一个Hadoop集群。数据库的每一次变化都需要反映在缓存、搜索集群中,最终反映在Hadoop中。在一个只处理实时更新的情况下,你只需要最近的日志。但如果你想能够重新加载缓存或恢复失败的搜索节点,你可能需要一个完整的数据集。
- 事件来源。这是一种将查询处理与应用设计共存的应用设计风格,并将变化日志作为应用的主要存储。
- 高可用性的日志。一个进行本地计算的进程,可以通过记录出它对本地状态的变化,使其具有容错性,这样另一个进程就可以重新加载这些变化,并在失败时继续进行。一个具体的例子是处理流查询系统中的计数、聚合和其他类似 "group by "的处理。Samza,一个实时流处理框架,正是为了这个目的而使用了这个功能。
在这些情况下,人们主要需要处理变化的实时馈送,但偶尔,当机器崩溃或数据需要重新加载或重新处理时,人们需要进行全面加载。日志压缩允许将这两种用例从同一个支持主题上进行反馈。这种日志的使用方式在这篇博文中会有更详细的介绍。
总体思路很简单。如果我们有无限的日志保留,并且我们记录了上述情况下的每一个变化,那么我们就会捕捉到系统从最初开始时每一个时间的状态。利用这个完整的日志,我们可以通过重放日志中的前N条记录来还原到任何时间点。这种假设的完整日志对于多次更新一条记录的系统来说,并不是很实用,因为即使对于一个稳定的数据集,日志也会无限制的增长。简单的日志保留机制将旧的更新扔掉,会约束空间,但日志不再是恢复当前状态的方法,现在从日志开始恢复不再重现当前状态,因为旧的更新可能根本没有被捕获。
日志压实是一种机制,给每个记录提供更细粒度的保留,而不是更粗粒度的基于时间的保留。这个想法是有选择地删除我们有相同主键的最近更新的记录。这样就可以保证日志至少有每个键的最后状态。
这个保留策略可以按主题设置,所以一个集群可以有一些主题是通过大小或时间来执行保留,而其他主题则是通过压实来执行保留。
这个功能的灵感来自于LinkedIn最古老也是最成功的基础设施之一--名为Databus的数据库changelog缓存服务。与大多数日志结构的存储系统不同,Kafka是为订阅而构建的,并组织数据进行快速线性读写。与Databus不同的是,Kafka作为一个真实源存储,因此即使在上游数据源无法以其他方式重放的情况下,它也很有用。
日志压缩基础
这里是一张高级图片,显示了Kafka日志的逻辑结构,以及每个消息的偏移量。
日志的头部与传统的Kafka日志相同。它有密集的顺序偏移,并保留所有消息。日志压实增加了一个处理日志尾部的选项。上图显示的是一个带有压缩尾巴的日志。请注意,日志尾部的消息保留了首次写入时分配的原始偏移量,这一点永远不会改变。还需要注意的是,所有的偏移量在日志中仍然是有效的位置,即使带有该偏移量的消息已经被压缩掉了;在这种情况下,这个位置与日志中出现的下一个最高偏移量是无法区分的。例如,在上图中,偏移量36、37和38都是等价的位置,从这些偏移量中的任何一个开始读取,都会返回一个从38开始的消息集。
压实还允许删除。一个带有键和空有效载荷的消息将被视为从日志中删除。这种记录有时被称为墓碑。这个删除标记会导致之前任何带有该键的消息被删除(就像任何带有该键的新消息一样),但删除标记是特殊的,因为它们本身会在一段时间后从日志中清理出来以释放空间。在上图中,将不再保留删除的时间点标记为 "删除保留点"。
压实是在后台通过定期重新复制日志段来完成的。清理不会阻塞读取,并且可以节流使用不超过可配置的 I/O 吞吐量,以避免影响生产者和消费者。实际压缩日志段的过程是这样的。
日志压缩有哪些保障?
日志压缩保证以下几点。
- 任何追赶到日志头部的消费者都会看到所写的每一条消息;这些消息会有顺序的偏移。题目中的min.compaction.lag.ms可以用来保证一个消息被写入后必须经过的最小时间长度,然后才能进行压缩。即它提供了每个消息在(未压缩的)头部停留时间的下限。topic的max.compaction.lag.ms可以用来保证从消息被写入到消息有资格被压实之间的最大延迟。
- 消息的顺序总是被保持的。Compaction永远不会重新排序消息,只是删除一些消息。
- 消息的偏移量永远不会改变。它是日志中某个位置的永久标识符。
- 任何从日志开始进展的消费者至少会看到所有记录的最终状态,其顺序是按照它们被写入的顺序。此外,只要消费者在小于主题的delete.retain.ms设置(默认为24小时)的时间段内到达日志的头部,就会看到所有删除记录的删除标记。换句话说:由于删除标记的删除是与读取同时发生的,如果消费者的滞后时间超过delete.retention.ms,就有可能错过删除标记。
日志压缩的细节
日志压实由日志清理器处理,它是一个后台线程池,负责重新复制日志段文件,删除键出现在日志头部的记录。每个压缩器线程的工作原理如下。
- 它选择日志头部和尾部比例最高的日志。
- 它为日志头部的每个键创建了一个简明扼要的最后偏移量摘要。
- 它从头到尾重新复制日志,删除日志中较晚出现的键。新的、干净的片段会立即被交换到日志中,因此所需的额外磁盘空间只是一个额外的日志片段(不是日志的完整副本)。
- 日志头的摘要本质上只是一个空间紧凑的哈希表。它每个条目正好使用24个字节。因此,如果有8GB的清理器缓冲区,一个清理器迭代可以清理大约366GB的日志头(假设有1k条消息)。
配置日志清理器
日志清理器默认为启用。这将启动清理线程池。要在特定主题上启用日志清理,请添加特定于日志的属性
log.cleanup.policy=compact
log.cleanup.policy属性是在broker的server.properties文件中定义的broker配置设置;它影响集群中所有没有配置覆盖的主题,如这里所描述的。日志清理器可以被配置为保留最小数量的未压缩的日志 "头部"。这可以通过设置压实时间滞后来启用。
log.cleaner.min.compaction.lag.ms
这可以用来防止超过最小消息年龄的消息被压缩。如果没有设置,除了最后一个段,即当前正在写入的段,所有日志段都有资格进行压实。即使活动段的所有消息都超过了最小压实时滞,也不会对其进行压实。日志清理器可以被配置为确保最大延迟,在此延迟之后,未压缩的日志 "头 "才有资格进行日志压缩。
log.cleaner.max.compaction.lag.ms
此项可用于防止产生率较低的日志在无限制的时间内不符合压实条件。如果不设置,不超过min.cleanable.dirty.ratio的日志将不会被压实。请注意,这个压实期限并不是一个硬性保证,因为它仍然受制于日志清理线程的可用性和实际压实时间。你要监控uncleanable-partitions-count、max-clean-time-secs和max-compaction-delay-secs指标。
更多的清理器配置在这里介绍。
4.9 配额
Kafka集群具有对请求执行配额的能力,以控制客户端使用的经纪资源。Kafkabroker可以为每一组共享配额的客户执行两种类型的客户配额。
- 网络带宽配额定义了字节速率阈值(从0.9开始)。
- 请求率配额定义了CPU利用率阈值,作为网络和I/O线程的百分比(自0.11起)
为什么要有配额?
生产者和消费者有可能产生/消耗非常大的数据量,或者以非常高的速度产生请求,从而垄断broker的资源,造成网络饱和,并且通常会使其他客户和broker自己陷入困境。拥有配额可以防止这些问题,在大型多租户集群中就更加重要了,因为一小撮表现不好的客户端会降低表现好的客户端的用户体验。事实上,当Kafka作为服务运行时,这甚至可以根据商定的合同来执行API限制。
客户端组
Kafka客户端的身份是用户principal,它代表安全集群中的认证用户。在支持非认证客户机的集群中,用户委托人是由代理使用可配置的PrincipalBuilder选择的非认证用户的分组。Client-id是由客户端应用程序选择的具有有意义的名称的客户端的逻辑分组。元组(user,client-id)定义了一个安全的客户机逻辑组,该组共享用户Principal和client-id。
配额可以应用于(用户,客户端-id)、用户或客户端-id组。对于给定的连接,将应用与该连接匹配的最具体的配额。配额组的所有连接共享为该组配置的配额。例如,如果(user="test-user",client-id="test-client")的生产配额为10MB/秒,则所有用户 "test-user "和client-id "test-client "的生产者实例都会共享这个配额。
配额设置
配额配置可以为(用户、客户端-id)、用户和客户端-id组定义。可以在任何一个需要更高(甚至更低)配额的配额级别覆盖默认配额。机制类似于每主题日志配置覆盖。用户和(用户,客户机ID)配额覆盖写在/config/users下,客户机ID配额覆盖写在/config/clients下。这些覆写会被所有的broker读取并立即生效。这让我们可以改变配额,而无需对整个集群进行滚动重启。详情请看这里。每个组的默认配额也可以使用相同的机制动态更新。
配额配置的优先顺序是。
- /config/users/<user>/clients/<client-id>
- /config/users/<user>/clients/<default>
- /config/users/<user>
- /config/users/<default>/clients/<client-id>
- /config/users/<default>/clients/<default>
- /config/users/<default>
- /config/clients/<client-id>
- /config/clients/<default>
broker属性(quota.producer.default,quota.consumer.default)也可用于为客户端id组设置网络带宽配额的默认值。这些属性正在被废弃,并将在以后的版本中被移除。客户端-id的默认配额可以在Zookeeper中设置,类似于其他配额覆盖和默认值。
网络带宽配额
网络带宽配额被定义为每组共享配额的客户机的字节速率阈值。默认情况下,每个独特的客户机组都会收到群集配置的以字节/秒为单位的固定配额。该配额是以每个代理为基础定义的。每组客户机在客户机被节流之前,每个broker最多可以发布/获取X个字节/秒的配额。
请求速率配额
请求率配额是指在一个配额窗口内,客户端在请求处理机I/O线程和每个代理的网络线程上可以利用的时间百分比。n%的配额代表一个线程的n%,所以配额出的总容量为((num.io.threads+num.network.threads)*100)%。每组客户机在被节流之前,可以在一个配额窗口中的所有I/O和网络线程中使用最多n%的总百分比。由于分配给I/O和网络线程的线程数通常基于broker主机上可用的内核数,因此请求率配额代表了每组共享配额的客户机可能使用的CPU的总百分比。
强制
默认情况下,每个独特的客户组都会收到群集配置的固定配额。这个配额是以每个代理为基础定义的。每个客户端在被节流之前可以利用每个代理的这个配额。我们决定,定义每个broker的这些配额比为每个客户端提供固定的集群范围带宽要好得多,因为这需要一个机制来在所有broker之间共享客户端配额使用情况。这可能比配额实现本身更难搞好!
当broker检测到配额违规时,它是如何反应的?在我们的解决方案中,broker首先计算出使违规客户端低于配额所需的延迟量,并立即返回一个带有延迟量的响应。在获取请求的情况下,响应将不包含任何数据。然后,代理会将通往客户端的通道静音,不再处理客户端的请求,直到延迟结束。在收到一个非零延迟持续时间的响应后,Kafka客户端也会在延迟期间不再向broker发送请求。因此,来自节流客户端的请求会被双方有效地阻止。即使是不尊重broker的延迟响应的旧客户端实现,broker通过静音其socket通道施加的背压仍然可以处理表现不好的客户端的节流。那些进一步向节流通道发送请求的客户端将在延迟结束后才收到响应。
字节率和线程利用率在多个小窗口(例如30个窗口,每个窗口1秒)中进行测量,以便快速检测和纠正违反配额的情况。通常情况下,拥有大的测量窗口(例如10个窗口,每个窗口30秒)会导致大的流量爆发,然后是长时间的延迟,这在用户体验方面不是很好。
5. 实现
5.1 网络层
网络层是一个相当直接的NIO服务器,就不详细介绍了。sendfile的实现是通过给MessageSet接口一个writeTo方法来完成的。这样就可以让文件支持的消息集使用效率更高的transferTo实现,而不是进程内缓冲写。线程模型是一个接受者线程和N个处理器线程,每个线程处理固定数量的连接。这种设计已经在其他地方进行了相当彻底的测试,发现它的实现简单而快速。协议保持相当简单,以便于将来用其他语言实现客户端。
5.2 消息
消息由一个可变长度的头、一个可变长度的不透明密钥字节数组和一个可变长度的不透明值字节数组组成。报文头的格式在下一节中描述。让键和值不透明是一个正确的决定:现在序列化库取得了很大的进展,任何特定的选择都不可能适合所有的用途。不用说一个使用Kafka的特定应用很可能会强制要求将特定的序列化类型作为其使用的一部分。RecordBatch接口只是一个消息的迭代器,有专门的方法用于批量读写NIO通道。
5.3 消息格式
消息(也就是记录)总是分批写入的。消息批的技术术语是记录批,一个记录批包含一条或多条记录。在退化的情况下,我们可以让一个记录批包含一条记录。记录批和记录都有自己的标题。下面将介绍每种格式。
5.3.1 记录批次
以下是RecordBatch的磁盘格式。
baseOffset: int64batchLength: int32partitionLeaderEpoch: int32magic: int8 (current magic value is 2)crc: int32attributes: int16bit 0~2:0: no compression1: gzip2: snappy3: lz44: zstdbit 3: timestampTypebit 4: isTransactional (0 means not transactional)bit 5: isControlBatch (0 means not a control batch)bit 6~15: unusedlastOffsetDelta: int32firstTimestamp: int64maxTimestamp: int64producerId: int64producerEpoch: int16baseSequence: int32records: [Record]
需要注意的是,当启用压缩功能时,压缩后的记录数据直接按照记录数的计数进行序列化。
CRC涵盖了从属性到批次结束的数据(即CRC之后的所有字节)。它位于魔法字节之后,这意味着客户端必须先解析魔法字节,然后再决定如何解释批次长度和魔法字节之间的字节。在CRC计算中不包括分区首领时间字段,以避免当该字段被分配给broker接收的每个批次时,需要重新计算CRC。计算时采用CRC-32C(Castagnoli)多项式。
关于压实:与旧的消息格式不同,magic v2及以上版本在清理日志时保留了原始批次的首尾偏移量/序列号。这是为了在重新加载日志时能够恢复生产者的状态而需要的。例如,如果我们没有保留最后一个序列号,那么在分区领导失败后,生产者可能会看到一个OutOfSequence错误。为了进行重复检查,必须保留基本序列号(broker通过验证传入批次的第一个和最后一个序列号与该生产者的最后一个序列号相匹配来检查传入的Produce请求是否有重复)。因此,当批中的所有记录都被清理,但为了保留生产者的最后一个序列号,批仍被保留时,日志中就有可能出现空批。这里有一个奇怪的地方,就是在压实过程中不保留firstTimestamp字段,所以如果批中的第一条记录被压实掉,它就会改变。
5.3.1.1 控制批次
一个控制批包含一条记录,称为控制记录。控制记录不应传递给应用程序。相反,它们被消费者用来过滤掉中止的事务性消息。
控制记录的键符合以下模式。
version: int16 (current version is 0)type: int16 (0 indicates an abort marker, 1 indicates a commit)
控制记录的值的模式取决于类型。该值对客户来说是不透明的。
5.3.2 记录
Kafka 0.11.0中引入了记录级头文件。带头记录的磁盘格式如下。
length: varintattributes: int8bit 0~7: unusedtimestampDelta: varintoffsetDelta: varintkeyLength: varintkey: byte[]valueLen: varintvalue: byte[]Headers => [Header]
5.3.2.1 记录头
headerKeyLength: varintheaderKey: StringheaderValueLength: varintValue: byte[]
我们使用与Protobuf相同的varint编码。关于后者的更多信息可以在这里找到。记录中的头数也是以varint编码的。
5.3.3 旧的信息格式
在Kafka 0.11之前,消息是以消息集的形式传输和存储的。在消息集中,每个消息都有自己的元数据。需要注意的是,虽然消息集以数组的形式表示,但并不像协议中的其他数组元素那样,前面有一个int32数组大小。
消息集合:
MessageSet (Version: 0) => [offset message_size message]offset => INT64message_size => INT32message => crc magic_byte attributes key valuecrc => INT32magic_byte => INT8attributes => INT8bit 0~2:0: no compression1: gzip2: snappybit 3~7: unusedkey => BYTESvalue => BYTES
MessageSet (Version: 1) => [offset message_size message]offset => INT64message_size => INT32message => crc magic_byte attributes timestamp key valuecrc => INT32magic_byte => INT8attributes => INT8bit 0~2:0: no compression1: gzip2: snappy3: lz4bit 3: timestampType0: create time1: log append timebit 4~7: unusedtimestamp => INT64key => BYTESvalue => BYTES
在Kafka 0.10之前的版本中,唯一支持的消息格式版本(用魔力值表示)是0,0.10版本中引入了消息格式版本1,并支持时间戳。
- 与上面的版本2类似,属性的最低位代表压缩类型。
- 在版本1中,生产者应该始终将时间戳类型位设置为0,如果主题被配置为使用日志追加时间,(通过broker级别配置log.message.timestamp.type = LogAppendTime或主题级别配置message.timestamp.type = LogAppendTime),broker将覆盖时间戳类型和消息集中的时间戳。
- 属性的最高位必须设置为0。
在消息格式版本0和1中,Kafka支持递归消息以实现压缩。在这种情况下,消息的属性必须被设置为指示压缩类型之一,并且值域将包含用该类型压缩的消息集。我们通常将嵌套消息称为 "内部消息",将封装消息称为 "外部消息"。请注意,外层消息的键应该是空的,其偏移量将是最后一个内部消息的偏移量。
当接收递归的版本0消息时,broker会对它们进行解压,并且每个内部消息都会单独分配一个偏移量。在版本1中,为了避免服务器端重新压缩,只有包装消息将被分配一个偏移量。内部消息将有相对的偏移量。绝对偏移量可以使用外层消息的偏移量来计算,它对应于分配给最后一个内部消息的偏移量。
crc字段包含后续报文字节的CRC32(而不是CRC-32C)(即从魔法字节到值)。
5.4 日志
一个名为 "my_topic "的主题的日志有两个分区,由两个目录(即my_topic_0和my_topic_1)组成,这两个目录中包含了该主题的消息数据文件。日志文件的格式是一个 "日志条目 "的序列;每个日志条目是一个4字节的整数N,存储消息长度,后面是N个消息字节。每条消息由一个64位整数偏移量唯一标识,给出该消息在该分区上所有发送到该主题的消息流中开始的字节位置。每条消息的磁盘格式如下。每个日志文件都以它所包含的第一条消息的偏移量命名。所以创建的第一个文件将是000000000.kafka,每一个额外的文件将有一个整数名,大约是前一个文件的S字节,其中S是配置中给出的最大日志文件大小。
记录的确切二进制格式是版本化的,并作为标准接口进行维护,因此在理想的情况下,记录批次可以在生产者、broker和客户端之间传输,而无需重新复制或转换。上一节包括了关于记录的磁盘格式的细节。
使用消息偏移量作为消息id是不寻常的。我们最初的想法是使用生产者生成的 GUID,并在每个broker上维护一个从 GUID 到偏移量的映射。但由于消费者必须为每个服务器维护一个ID,所以GUID的全局唯一性没有提供任何价值。此外,维护从随机id到偏移量的映射的复杂性,需要一个重磅的索引结构,而这个结构必须与磁盘同步,本质上需要一个完整的持久化随机访问数据结构。因此为了简化查找结构,我们决定使用一个简单的每个分区原子计数器,它可以与分区id和节点id耦合,以唯一标识一个消息;这使得查找结构更简单,尽管每个消费者请求仍有可能进行多次查找。然而,一旦我们确定了计数器,直接使用偏移量似乎是很自然的--毕竟两者都是分区唯一的单调递增整数。由于偏移量被隐藏在消费者API中,这个决定最终是一个实现细节,我们选择了更有效的方法。
写
日志允许串行追加,它总是转到最后一个文件。当这个文件达到一个可配置的大小(比如1GB)时,就会转到一个新的文件。日志需要两个配置参数。M,给出了在强制操作系统将文件刷新到磁盘之前要写的信息数量,S,给出了强制刷新的秒数。这样可以保证在系统崩溃时最多丢失M条消息或S秒数据的耐久性。
读
读取是通过给定消息的64位逻辑偏移量和S字节的最大分块大小来完成的,这将返回一个S字节缓冲区中的消息迭代器。这将返回一个迭代器,遍历S字节缓冲区中包含的消息。S 字节的大小要大于任何一条消息,但如果消息异常大,可以多次重试读取,每次都将缓冲区大小加倍,直到消息被成功读取。可以指定一个最大的消息和缓冲区大小,以使服务器拒绝大于某个大小的消息,并给客户端一个最大的约束,它需要读取一个完整的消息。读取的缓冲区很可能以部分消息结束,这很容易通过大小分隔来检测。
从偏移量读取的实际过程,需要先定位数据存放的日志段文件,从全局偏移量值中计算出特定文件的偏移量,然后从该文件偏移量中读取。搜索是以简单的二进制搜索变化的方式,针对每个文件维护的内存范围进行的。
日志提供了获取最近写的消息的功能,以便客户从 "现在 "开始订阅。在消费者未能在其SLA规定的天数内消费其数据的情况下,这也很有用。在这种情况下,当客户机试图消费一个不存在的偏移量时,它将得到一个OutOfRangeException,并且可以根据用例的情况重置自己或失败。
以下是发送给消费者的结果的格式。
MessageSetSend (fetch result)total length : 4 byteserror code : 2 bytesmessage 1 : x bytes...message n : x bytes
MultiMessageSetSend (multiFetch result)total length : 4 byteserror code : 2 bytesmessageSetSend 1...messageSetSend n
删除
每次删除一个日志段的数据。日志管理器应用两个指标来确定符合删除条件的片段:时间和大小。对于基于时间的策略,会考虑记录的时间戳,由分段文件中最大的时间戳(记录顺序无关)定义整个分段的保留时间。基于大小的保留默认为禁用。启用时,日志管理器会不断删除最旧的段文件,直到分区的整体大小再次在配置的限制范围内。如果同时启用了这两个策略,则会删除因任一策略而符合删除条件的段。为了避免锁定读取,同时仍然允许修改段列表的删除,我们使用了一种复制-写式的段列表实现,它提供了一致的视图,允许在删除进行时,在日志段的不可改变的静态快照视图上进行二进制搜索。
保障
日志提供了一个配置参数M,它控制了在强制刷新到磁盘之前写入的最大消息数量。在启动时,会运行一个日志恢复进程,该进程会遍历最新日志段中的所有消息,并验证每个消息条目是否有效。如果消息的大小和偏移量之和小于文件的长度,并且消息有效载荷的CRC32与消息存储的CRC相匹配,则消息条目有效。如果检测到损坏,日志会被截断到最后一个有效的偏移量。
请注意,必须处理两种腐败:截断,其中一个未写的块由于崩溃而丢失,以及一个无意义的块被添加到文件中的腐败。原因是一般情况下,操作系统不保证文件inode和实际块数据之间的写入顺序,所以如果inode更新了新的大小,但在写入包含该数据的块之前发生了崩溃,那么除了丢失写入数据外,文件还可能获得无意义数据。CRC可以检测到这种角落的情况,并防止它破坏日志(当然,未写入的信息会丢失)。
5.5 分配
消费者偏移量追踪
Kafka消费者跟踪它在每个分区中消耗的最大偏移量,并具有提交偏移量的能力,以便在重新启动时可以从这些偏移量恢复。Kafka提供了一个选项,可以将某个消费者组的所有偏移量存储在一个指定的broker(针对该组)中,称为组协调器.也就是说,该消费者组中的任何消费者实例都应该将其偏移量提交和取回发送到该组协调器(broker)。消费者组根据其组名被分配给协调器。消费者可以通过向任何Kafka broker发出FindCoordinatorRequest并读取FindCoordinatorResponse来查找它的协调人,FindCoordinatorResponse将包含协调人的详细信息。然后,消费者可以继续从协调人broker那里提交或获取偏移量。如果协调器移动了,消费者需要重新发现协调器。偏移提交可以由消费者实例自动或手动完成。
当组协调器收到OffsetCommitRequest时,它会将请求附加到一个名为__consumer_offsets的特殊压缩Kafka主题中。只有在offsets主题的所有副本都收到offsets之后,代理才会向消费者发送一个成功的偏移提交响应。如果偏移量未能在可配置的超时内复制,偏移量提交将失败,消费者可以在后退后重新尝试提交。broker会定期压缩偏移主题,因为它只需要维护每个分区的最新偏移提交。协调器还将偏移量缓存在内存表中,以便快速服务于偏移量的获取。
当协调器收到一个偏移获取请求时,它只需从偏移缓存中返回最后提交的偏移向量。在协调器刚刚启动的情况下,或者如果它刚刚成为一组新的消费者组的协调器(通过成为偏移量主题分区的领导者),它可能需要将偏移量主题分区加载到缓存中。在这种情况下,偏移量的获取将以CoordinatorLoadInProgressException失败,消费者可能会在后退后重新尝试OffsetFetchRequest。
Zookeeper目录
下面给出了ZooKeeper结构和用于协调消费者和broker的算法。
符号
当一个路径中的元素用[xyz]表示时,意味着xyz的值不是固定的,实际上xyz的每一个可能的值都有一个ZooKeeper znode。例如/topics/[topic]将是一个名为/topics的目录,其中包含了每个主题名的子目录。还给出了数字范围,如[0...5]来表示子目录0,1,2,3,4。箭头->用来表示一个znode的内容。例如,/hello -> world表示一个包含 "world "的znode /hello。
broker节点注册
/brokers/ids/[0...N] --> {"jmx_port":...,"timestamp":...,"endpoints":[...],"host":...,"version":...,"port":...} (ephemeral node)
这是所有存在的 broker 节点的列表,每个节点都提供了一个唯一的逻辑 broker id,它可以向消费者标识它(必须作为其配置的一部分给出)。在启动时,broker 节点通过在 /brokers/ids 下创建一个带有逻辑 broker id 的 znode 来注册自己。逻辑 broker id 的目的是允许 broker 移动到不同的物理机器上,而不影响消费者。试图注册一个已经在使用的broker id(比如说因为两台服务器配置了相同的broker id)会导致错误。
由于broker在ZooKeeper中使用短暂的znodes注册自己,这个注册是动态的,如果broker被关闭或死亡,这个注册就会消失(从而通知消费者它不再可用)。
broker主题注册
/brokers/topics/[topic]/partitions/[0...N]/state --> {"controller_epoch":...,"leader":...,"version":...,"leader_epoch":...,"isr":[...]} (ephemeral node)
每个broker在其维护的主题下注册自己,并存储该主题的分区数量。
集群ID
群集id是分配给Kafka群集的唯一且不可更改的标识符。群集id最多可以有22个字符,允许的字符由正则表达式[a-zA-Z0-9_/9/\-]+定义,它对应于没有填充的URL安全Base64变体所使用的字符。从概念上来说,它是在集群第一次启动时自动生成的。
在实现上,它是在第一次成功启动0.10.1或更高版本的broker时生成的。broker在启动过程中会尝试从/cluster/id znode中获取集群id。如果znode不存在,broker会生成一个新的集群id,并使用这个集群id创建znode。
broker节点注册
broker节点基本上是独立的,所以它们只发布自己所拥有的信息。当一个broker加入时,它在broker节点注册表目录下注册自己,并写入自己的主机名和端口信息。broker也会在broker主题注册表中注册现有主题的列表及其逻辑分区。新的主题在broker上创建时是动态注册的。
6.操作
以下是基于LinkedIn的使用情况和经验,关于将Kafka作为生产系统实际运行的一些信息。请将您知道的任何其他技巧发送给我们。
6.1 Kafka基本操作
本节将回顾您将在Kafka集群上执行的最常见的操作。本节回顾的所有工具都可以在Kafka发行版的bin/目录下使用,如果运行时没有参数,每个工具都会打印所有可能的命令行选项的详细信息。
添加和删除主题
您可以选择手动添加主题,或在数据首次发布到不存在的主题时让它们自动创建。如果主题是自动创建的,那么你可能要调整用于自动创建主题的默认主题配置。
使用主题工具添加和修改主题。
> bin/kafka-topics.sh --bootstrap-server broker_host:port --create --topic my_topic_name \--partitions 20 --replication-factor 3 --config x=y
复制因子控制有多少台服务器会复制每条被写入的消息。如果您的复制因子为3,那么在您失去对数据的访问之前,最多可以有2台服务器发生故障。我们建议您使用2或3的复制因子,这样您就可以在不中断数据消耗的情况下透明地跳转机器。
分区数控制主题将被分片成多少个日志。分区数有几个影响。首先每个分区必须完全适合在一台服务器上。因此,如果你有20个分区,那么全部数据集(以及读写负载)将由不超过20台服务器处理(不计算副本)。最后,分区数会影响你的消费者的最大并行性。这在概念部分有更详细的讨论。
每个分片分区的日志都会被放置到Kafka日志目录下自己的文件夹中。这种文件夹的名称由主题名称、破折号(-)和分区id组成。由于一个典型的文件夹名不能超过255个字符,所以主题名的长度会有限制。我们假设分区的数量永远不会超过100,000。因此,主题名不能超过249个字符。这就为文件夹名中的破折号和可能长达 5 位的分区 ID 留出了足够的空间。
在命令行上添加的配置覆盖了服务器的默认设置,比如数据应该保留的时间长度。完整的按主题配置集在这里有记载。
修改主题
您可以使用同一主题工具更改主题的配置或分区。
要添加分区,您可以执行以下操作
> bin/kafka-topics.sh --bootstrap-server broker_host:port --alter --topic my_topic_name \--partitions 40
要知道,分区的一个用例是对数据进行语义上的分区,而添加分区并不会改变现有数据的分区,所以如果消费者依赖该分区,这可能会打扰到他们。也就是说,如果数据是按照hash(key) % number_of_partitions进行分区的,那么这个分区将有可能通过添加分区来洗牌,但Kafka不会尝试以任何方式自动重新分配数据。
要添加配置:
> bin/kafka-configs.sh --bootstrap-server broker_host:port --entity-type topics --entity-name my_topic_name --alter --add-config x=y
要删除一个配置:
> bin/kafka-configs.sh --bootstrap-server broker_host:port --entity-type topics --entity-name my_topic_name --alter --delete-config x
最终删除一个主题:
> bin/kafka-topics.sh --bootstrap-server broker_host:port --delete --topic my_topic_name
Kafka目前不支持减少一个主题的分区数量。
更改主题的复制因子的说明可以在这里找到。
优雅地关机
Kafka集群将自动检测任何broker关闭或故障,并为该机器上的分区选举新的领导者。无论服务器发生故障,还是因维护或配置更改而故意宕机,都会发生这种情况。对于后一种情况,Kafka支持一种更优雅的机制来停止服务器,而不是直接杀死它。当一个服务器被优雅地停止时,它有两个优化,它会利用这两个优化。
- 它会将所有的日志同步到磁盘上,以避免在重新启动时需要进行任何日志恢复(即验证日志尾部所有消息的校验和)。日志恢复需要时间,所以这可以加快有意重启的速度。
- 它将在关闭之前把服务器是领导的任何分区迁移到其他副本。这将使领导权转移更快,并将每个分区不可用的时间减少到几毫秒。
除硬杀外,每当服务器停止时,同步日志将自动发生,但受控领导力迁移需要使用特殊设置:
controlled.shutdown.enable=true
请注意,只有当所有托管在broker上的分区都有副本时,受控关闭才会成功(即复制因子大于1,并且这些副本中至少有一个是活的)。这通常是你想要的,因为关闭最后一个副本会使该主题分区不可用。
平衡领导权
每当一个broker停止或崩溃时,该broker的分区的领导权就会转移到其他副本上。当broker重新启动时,它将只成为其所有分区的跟随者,这意味着它将不会被用于客户端读写。
为了避免这种不平衡,Kafka有一个首选副本的概念。如果一个分区的副本列表是1,5,9,那么节点1作为领导者比节点5或9都要优先,因为它在副本列表中更早。默认情况下,Kafka集群会尝试将领导权恢复给被恢复的副本。这种行为是通过以下方式配置的。
auto.leader.rebalance.enable=true
您也可以将此设置为false,但您需要通过运行命令手动将领导力恢复到恢复的副本。
> bin/kafka-preferred-replica-election.sh --bootstrap-server broker_host:port
平衡各机架上的副本
机架感知功能将同一分区的副本分布在不同机架上。这将Kafka为broker故障提供的保证扩展到覆盖机架故障,限制了一个机架上所有broker同时故障时的数据丢失风险。该功能还可以应用于其他broker分组,如EC2中的可用性区。
您可以通过在broker config中添加一个属性来指定某个broker属于某个机架:
broker.rack=my-rack-id
当一个主题被创建、修改或副本被重新分配时,机架约束将被尊重,确保副本跨越尽可能多的机架(一个分区将跨越min(#racks, replication-factor)不同的机架)。
用于将副本分配给broker的算法确保每个broker的leader数量不变,无论broker如何分布在机架上。这确保了均衡的吞吐量。
然而,如果机架上分配了不同数量的broker,那么复制件的分配将不会是均匀的。拥有较少broker的机架将获得更多的复制,这意味着它们将使用更多的存储并将更多的资源投入到复制中。因此,每个机架配置相同数量的broker是明智的。
集群之间的数据镜像和地理复制
Kafka管理员可以定义跨越单个Kafka集群、数据中心或地理区域边界的数据流。更多信息请参考 "地理复制 "一节。
检查消费者位置
有时候,看看你的消费者的位置是很有用的。我们有一个工具,可以显示一个消费群中所有消费者的位置,以及他们在日志末端的落后程度。如果要在一个名为my-group的消费群组上运行这个工具,消费一个名为my-topic的主题,会是这样的。
> bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --describe --group my-groupTOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-IDmy-topic 0 2 4 2 consumer-1-029af89c-873c-4751-a720-cefd41a669d6 /127.0.0.1 consumer-1my-topic 1 2 3 1 consumer-1-029af89c-873c-4751-a720-cefd41a669d6 /127.0.0.1 consumer-1my-topic 2 2 3 1 consumer-2-42c1abd4-e3b2-425d-a8bb-e1ea49b29bb2 /127.0.0.1 consumer-2
管理消费者组
通过ConsumerGroupCommand工具,我们可以列出、描述或删除消费者组。消费者组可以手动删除,也可以在该组最后一次提交的偏移量到期时自动删除。只有当该组没有任何活动成员时,手动删除才有效。例如,要列出所有主题的所有消费者组。
> bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --listtest-consumer-group
如前所述,为了查看偏移量,我们是这样 "描述 "消费群体的。
> bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --describe --group my-groupTOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-IDtopic3 0 241019 395308 154289 consumer2-e76ea8c3-5d30-4299-9005-47eb41f3d3c4 /127.0.0.1 consumer2topic2 1 520678 803288 282610 consumer2-e76ea8c3-5d30-4299-9005-47eb41f3d3c4 /127.0.0.1 consumer2topic3 1 241018 398817 157799 consumer2-e76ea8c3-5d30-4299-9005-47eb41f3d3c4 /127.0.0.1 consumer2topic1 0 854144 855809 1665 consumer1-3fc8d6f1-581a-4472-bdf3-3515b4aee8c1 /127.0.0.1 consumer1topic2 0 460537 803290 342753 consumer1-3fc8d6f1-581a-4472-bdf3-3515b4aee8c1 /127.0.0.1 consumer1topic3 2 243655 398812 155157 consumer4-117fe4d3-c6c1-4178-8ee9-eb4a3954bee0 /127.0.0.1 consumer4
有一些额外的 "描述 "选项可以用来提供有关消费者群体的更多详细信息。
--members 该选项提供消费群中所有活跃成员的清单:
> bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --describe --group my-group --membersCONSUMER-ID HOST CLIENT-ID #PARTITIONSconsumer1-3fc8d6f1-581a-4472-bdf3-3515b4aee8c1 /127.0.0.1 consumer1 2consumer4-117fe4d3-c6c1-4178-8ee9-eb4a3954bee0 /127.0.0.1 consumer4 1consumer2-e76ea8c3-5d30-4299-9005-47eb41f3d3c4 /127.0.0.1 consumer2 3consumer3-ecea43e4-1f01-479f-8349-f9130b75d8ee /127.0.0.1 consumer3 0
--members--verbose 除了上述"--成员 "选项报告的信息外,该选项还提供分配给每个成员的分区。
> bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --describe --group my-group --members --verboseCONSUMER-ID HOST CLIENT-ID #PARTITIONS ASSIGNMENTconsumer1-3fc8d6f1-581a-4472-bdf3-3515b4aee8c1 /127.0.0.1 consumer1 2 topic1(0), topic2(0)consumer4-117fe4d3-c6c1-4178-8ee9-eb4a3954bee0 /127.0.0.1 consumer4 1 topic3(2)consumer2-e76ea8c3-5d30-4299-9005-47eb41f3d3c4 /127.0.0.1 consumer2 3 topic2(1), topic3(0,1)consumer3-ecea43e4-1f01-479f-8349-f9130b75d8ee /127.0.0.1 consumer3 0 -
--offsets。这是默认的describe选项,提供与"--describe "选项相同的输出。
--state:这个选项提供了有用的组级信息。这个选项提供了有用的组级信息。
> bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --describe --group my-group --stateCOORDINATOR (ID) ASSIGNMENT-STRATEGY STATE #MEMBERSlocalhost:9092 (0) range Stable 4
要手动删除一个或多个消费群,可使用"--删除 "选项。
> bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --delete --group my-group --group my-other-groupDeletion of requested consumer groups ('my-group', 'my-other-group') was successful.
要重置一个消费群的偏移量,可以使用"--reset-offsets "选项。这个选项一次只支持一个消费群。它需要定义以下范围:---all-topics 或 ---topic。必须选择一个范围,除非你使用"--from-file "方案。另外,首先确保消费者实例是非活动的。更多细节请参见KIP-122。
它有3个执行选项。
- (default)显示要重置的偏移量。
- --execute : 执行 --reset-offsets 进程。
- --export : 将结果导出为CSV格式。
--reset-offsets也有以下方案可供选择(必须至少选择一个方案)。
- --to-dateatetime <String: datetime> : 将偏移量重置为日期时间的偏移量。格式:'YYYY-MM-DD'。'YYYY-MM-DDTHH:MM:SS.sss' 。
- --toearliest :将偏移量重置为最早的偏移量。
- --to-latest : 将偏移量重置为最早的偏移量。将偏移量重置为最新的偏移量。
- --shift-by <Long: number-of-offsets> : 重置偏移量,将当前偏移量移动'n',其中'n'可以是正或负。
- --from-file : 将偏移量重置为CSV文件中定义的值。
- --to-current : 将偏移量重置为当前偏移量。将偏移量重置为当前的偏移量。
- --by-duration <String: duration> : 将偏移量重置为当前时间戳的持续时间的偏移量。格式:'PnDTnHnM'。'PnDTnHnMnS'。
- --to-offset : 将偏移量重置为一个特定的偏移量。
请注意,超出范围的偏移将被调整到可用的偏移端。例如,如果偏移量在10,而偏移量的请求是15,那么,实际上将选择10的偏移量。
例如,将消费者组的偏移量重置为最新的偏移量:
> bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --reset-offsets --group consumergroup1 --topic topic1 --to-latestTOPIC PARTITION NEW-OFFSETtopic1 0 0
如果你使用旧的高级消费者,并将组元数据存储在ZooKeeper中(即offsets.storage=zookeeper),传递--zookeeper而不是--bootstrap-server。
> bin/kafka-consumer-groups.sh --zookeeper localhost:2181 --list
集群扩展
将服务器添加到Kafka集群很简单,只需给它们分配一个唯一的broker id,然后在新服务器上启动Kafka。然而这些新服务器不会自动分配任何数据分区,所以除非分区被移动到它们身上,否则它们不会做任何工作,直到新的主题被创建。因此,通常当你将机器添加到你的集群时,你会希望将一些现有的数据迁移到这些机器上。
迁移数据的过程是手动发起的,但完全自动化。在掩护下发生的事情是,Kafka会将新服务器添加为它要迁移的分区的跟随者,并允许它完全复制该分区中的现有数据。当新服务器完全复制了这个分区的内容,并加入了同步副本后,其中一个现有的副本将删除其分区的数据。
分区重新分配工具可以用来在不同的broker之间移动分区。理想的分区分布将确保所有broker的数据负载和分区大小均匀。分区重新分配工具没有能力自动研究Kafka集群中的数据分布,并移动分区以达到均匀的负载分布。因此,管理员必须弄清楚哪些主题或分区应该被移动。
分区重新分配工具可以在3种相互排斥的模式下运行。
- --生成模式 在这种模式下,给定一个主题列表和一个broker列表,该工具会生成一个候选的重新分配,将指定主题的所有分区移动到新的broker上。这个选项只是提供了一种方便的方式来生成给定主题和目标broker列表的分区重新分配计划。
- --执行。在这种模式下,工具会根据用户提供的重新分配计划启动分区的重新分配。(使用--reassignment-js-on-file选项)。这可以是管理员手工制作的自定义重新分配计划,也可以是使用--generate选项提供的。
- --验证:在该模式下,该工具将验证上次 --执行期间列出的所有分区的重新分配状态。状态可以是成功完成、失败或正在进行。
自动将数据迁移到新机器上
分区重新分配工具可用于将一些主题从当前的broker集合中移到新添加的broker中。这在扩展现有群集时通常很有用,因为将整个主题移动到新的broker集合中比一次移动一个分区更容易。当用来做这件事时,用户应该提供一个应该移动到新的broker集的主题列表和一个新broker的目标列表。然后,该工具会将给定主题列表的所有分区均匀地分配到新的broker集上。在这个移动过程中,主题的复制因子保持不变。实际上,输入的主题列表的所有分区的复制都从旧的broker集移动到新增加的broker。
例如,下面的例子将把主题foo1,foo2的所有分区移动到新的broker5,6集。在移动结束后,主题foo1和foo2的所有分区将只存在于broker5,6上。
由于该工具接受输入的主题列表为 json 文件,因此首先需要确定要移动的主题,并创建 json 文件,如下所示:
> cat topics-to-move.json{"topics": [{"topic": "foo1"},{"topic": "foo2"}],"version":1}
一旦json文件准备好,使用分区重分配工具生成候选分配。
> bin/kafka-reassign-partitions.sh --bootstrap-server localhost:9092 --topics-to-move-json-file topics-to-move.json --broker-list "5,6" --generateCurrent partition replica assignment{"version":1,"partitions":[{"topic":"foo1","partition":2,"replicas":[1,2]},{"topic":"foo1","partition":0,"replicas":[3,4]},{"topic":"foo2","partition":2,"replicas":[1,2]},{"topic":"foo2","partition":0,"replicas":[3,4]},{"topic":"foo1","partition":1,"replicas":[2,3]},{"topic":"foo2","partition":1,"replicas":[2,3]}]}Proposed partition reassignment configuration{"version":1,"partitions":[{"topic":"foo1","partition":2,"replicas":[5,6]},{"topic":"foo1","partition":0,"replicas":[5,6]},{"topic":"foo2","partition":2,"replicas":[5,6]},{"topic":"foo2","partition":0,"replicas":[5,6]},{"topic":"foo1","partition":1,"replicas":[5,6]},{"topic":"foo2","partition":1,"replicas":[5,6]}]}
该工具会生成一个候选任务,将所有分区从主题foo1,foo2移动到broker5,6。但请注意,此时分区移动还没有开始,它只是告诉你当前的分配和建议的新分配。当前的分配应该被保存,以防你想回滚到它。新的分配应该保存在一个json文件中(例如expand-cluster-reassignment.json),以便用--execute选项输入到工具中,如下所示。
> bin/kafka-reassign-partitions.sh --bootstrap-server localhost:9092 --reassignment-json-file expand-cluster-reassignment.json --executeCurrent partition replica assignment{"version":1,"partitions":[{"topic":"foo1","partition":2,"replicas":[1,2]},{"topic":"foo1","partition":0,"replicas":[3,4]},{"topic":"foo2","partition":2,"replicas":[1,2]},{"topic":"foo2","partition":0,"replicas":[3,4]},{"topic":"foo1","partition":1,"replicas":[2,3]},{"topic":"foo2","partition":1,"replicas":[2,3]}]}Save this to use as the --reassignment-json-file option during rollbackSuccessfully started reassignment of partitions{"version":1,"partitions":[{"topic":"foo1","partition":2,"replicas":[5,6]},{"topic":"foo1","partition":0,"replicas":[5,6]},{"topic":"foo2","partition":2,"replicas":[5,6]},{"topic":"foo2","partition":0,"replicas":[5,6]},{"topic":"foo1","partition":1,"replicas":[5,6]},{"topic":"foo2","partition":1,"replicas":[5,6]}]}
最后,--verify选项可以与该工具一起使用,以检查分区重新分配的状态。请注意,在使用--verify选项时,应该使用相同的expand-cluster-reassignment.json(与--execute选项一起使用)。
> bin/kafka-reassign-partitions.sh --bootstrap-server localhost:9092 --reassignment-json-file expand-cluster-reassignment.json --verifyStatus of partition reassignment:Reassignment of partition [foo1,0] completed successfullyReassignment of partition [foo1,1] is in progressReassignment of partition [foo1,2] is in progressReassignment of partition [foo2,0] completed successfullyReassignment of partition [foo2,1] completed successfullyReassignment of partition [foo2,2] completed successfully
自定义分区分配和迁移
分区重新分配工具还可用于有选择地将一个分区的副本移至一组特定的broker。当以这种方式使用时,假定用户知道重新分配计划,不需要该工具生成候选的重新分配,有效地跳过--生成步骤,直接进入--执行步骤。
例如,下面的例子将topic foo1的分区0移动到broker 5,6,将topic foo2的分区1移动到broker 2,3。
第一步是在json文件中手工制作自定义的重新分配计划:
> cat custom-reassignment.json{"version":1,"partitions":[{"topic":"foo1","partition":0,"replicas":[5,6]},{"topic":"foo2","partition":1,"replicas":[2,3]}]}
然后,使用带有--execute选项的json文件开始重新分配过程。
> bin/kafka-reassign-partitions.sh --bootstrap-server localhost:9092 --reassignment-json-file custom-reassignment.json --executeCurrent partition replica assignment{"version":1,"partitions":[{"topic":"foo1","partition":0,"replicas":[1,2]},{"topic":"foo2","partition":1,"replicas":[3,4]}]}Save this to use as the --reassignment-json-file option during rollbackSuccessfully started reassignment of partitions{"version":1,"partitions":[{"topic":"foo1","partition":0,"replicas":[5,6]},{"topic":"foo2","partition":1,"replicas":[2,3]}]}
--verify选项可用于工具检查分区重新分配的状态。请注意,在使用--验证选项时,应该使用相同的自定义重新分配.json(与--执行选项一起使用)。
> bin/kafka-reassign-partitions.sh --bootstrap-server localhost:9092 --reassignment-json-file custom-reassignment.json --verifyStatus of partition reassignment:Reassignment of partition [foo1,0] completed successfullyReassignment of partition [foo2,1] completed successfully
退役的broker
分区重新分配工具尚不具备为停用的代理自动生成重新分配计划的能力。因此,管理员必须提出一个重新分配计划,将托管在要停用的broker上的所有分区的副本转移到其他broker上。这可能是比较繁琐的,因为重新分配需要确保所有的副本不会从退役的broker移动到只有一个其他broker。为了使这一过程不费吹灰之力,我们计划在未来为退役broker增加工具支持。
增加复制因子
增加现有分区的复制因子很容易。只需在自定义的重新分配json文件中指定额外的复制因子,并与--execute选项一起使用,就可以增加指定分区的复制因子。
例如,下面的例子将topic foo的分区0的复制因子从1增加到3,在增加复制因子之前,该分区的唯一副本存在于broker 5上。作为增加复制因子的一部分,我们将在broker6和7上增加更多的副本。
第一步是在json文件中手工制作自定义的重新分配计划。
> cat increase-replication-factor.json{"version":1,"partitions":[{"topic":"foo","partition":0,"replicas":[5,6,7]}]}
然后,使用带有--execute选项的json文件开始重新分配过程。
> bin/kafka-reassign-partitions.sh --bootstrap-server localhost:9092 --reassignment-json-file increase-replication-factor.json --executeCurrent partition replica assignment{"version":1,"partitions":[{"topic":"foo","partition":0,"replicas":[5]}]}Save this to use as the --reassignment-json-file option during rollbackSuccessfully started reassignment of partitions{"version":1,"partitions":[{"topic":"foo","partition":0,"replicas":[5,6,7]}]}
--verify选项可以与该工具一起使用,以检查分区重新分配的状态。请注意,在使用--验证选项时,应该使用相同的递增复制因子.json(与--execute选项一起使用)。
> bin/kafka-reassign-partitions.sh --bootstrap-server localhost:9092 --reassignment-json-file increase-replication-factor.json --verifyStatus of partition reassignment:Reassignment of partition [foo,0] completed successfully
你也可以用kafka-topics工具验证复制因子的增加。
> bin/kafka-topics.sh --bootstrap-server localhost:9092 --topic foo --describeTopic:foo PartitionCount:1 ReplicationFactor:3 Configs:Topic: foo Partition: 0 Leader: 5 Replicas: 5,6,7 Isr: 5,6,7
限制数据迁移期间的带宽使用
Kafka让你可以对复制流量进行节流,对用于将复制从机器移动到机器的带宽设置一个上限。这在重新平衡集群、引导新的代理或添加或删除代理时非常有用,因为它限制了这些数据密集型操作对用户的影响。
有两个接口可以用来参与节流。最简单,也是最安全的是在调用kafka-reassign-partitions.sh时应用节流,但kafka-configs.sh也可以直接用来查看和改变节流值。
所以举例来说,如果你要执行重新分配,用下面的命令,它将以不超过50MB/s的速度移动分区。
- $ bin/kafka-reassign-partitions.sh --bootstrap-server localhost:9092 --execute --reassignment-json-file bigger-cluster.json --throttle 50000000
当你执行这个脚本时,你会看到节气门啮合。
The throttle limit was set to 50000000 B/sSuccessfully started reassignment of partitions.
如果你想在重新平衡过程中改变节流阀,比如说增加吞吐量以使其完成得更快,你可以通过重新运行传递相同的重新分配-js-文件的执行命令来实现。
- $ bin/kafka-reassign-partitions.sh --bootstrap-server localhost:9092 --execute --reassignment-json-file bigger-cluster.json --throttle 700000000
- There is an existing assignment running.
- The throttle limit was set to 700000000 B/s
一旦再平衡完成,管理员可以使用--验证选项检查再平衡的状态。如果再平衡已经完成,将通过--验证命令移除节流阀。重要的是,管理员在再平衡完成后,要通过运行带有--verify选项的命令及时移除节流阀。如果不这样做,可能会导致常规复制流量被节流。
当执行--verify选项,并且重新分配完成后,脚本将确认节流被移除。
> bin/kafka-reassign-partitions.sh --bootstrap-server localhost:9092 --verify --reassignment-json-file bigger-cluster.jsonStatus of partition reassignment:Reassignment of partition [my-topic,1] completed successfullyReassignment of partition [mytopic,0] completed successfullyThrottle was removed.
管理员也可以使用kafka-configs.sh来验证分配的配置。有两对节流配置用于管理节流过程。第一对是指节流值本身。这是在broker层面,使用动态属性进行配置的。
leader.replication.throttled.ratefollower.replication.throttled.rate
然后是配置对列举的节制复制集。
leader.replication.throttled.replicasfollower.replication.throttled.replicas
其中每个主题的配置值。
所有四个配置值都是由kafka-reassign-partitions.sh自动分配的(下面讨论)。
要查看节流限制配置。
> bin/kafka-configs.sh --describe --bootstrap-server localhost:9092 --entity-type brokersConfigs for brokers '2' are leader.replication.throttled.rate=700000000,follower.replication.throttled.rate=700000000Configs for brokers '1' are leader.replication.throttled.rate=700000000,follower.replication.throttled.rate=700000000
这显示了应用于复制协议的领导者和跟随者端的节流。默认情况下,两边都被分配了相同的节流吞吐量值。
要查看节流复制的列表。
> bin/kafka-configs.sh --describe --bootstrap-server localhost:9092 --entity-type topicsConfigs for topic 'my-topic' are leader.replication.throttled.replicas=1:102,0:101,follower.replication.throttled.replicas=1:101,0:102
在这里,我们看到领导节流被应用于broker102上的分区1和broker101上的分区0。同样的,跟随者节制也被应用于broker 101上的分区1和broker 102上的分区0。
默认情况下,kafka-reassign-partitions.sh会将leader节流应用到所有在重新平衡之前存在的复制,其中任何一个复制都可能是leader。它将对所有移动目的地应用follower节制。因此,如果在broker 101,102 上有一个复制的分区,被重新分配到 102,103,那么该分区的领导者节流将被应用到 101,102,而跟随者节流将只应用到 103。
如果需要,你也可以使用kafka-configs.sh上的--alter开关来手动改变节流配置。
安全使用节流复制
在使用节流复制时,应注意一些问题。尤其是
(1)节流器的移除。
重新分配完成后,应及时移除节流器(通过运行kafka-reassign-partitions.sh--verify)。
(2)保证进度。
如果节流阀设置得太低,与传入的写入速率相比,有可能导致复制没有进展。这种情况发生在以下情况。
- max(BytesInPerSec) > throttle
其中BytesInPerSec是监控生产者向每个broker写入吞吐量的度量。
管理员可以在重新平衡期间,使用该指标监控复制是否有进展。
- kafka.server:type=FetcherLagMetrics,name=ConsumerLag,clientId=([-.\w]+),topic=([-.\w]+),partition=([0-9]+)
在复制过程中,滞后应该不断减少。如果该指标没有减少,管理员应如上所述增加节流吞吐量。
设置配额
配额覆盖和默认值可以在(用户、客户端-id)、用户或客户端-id级别进行配置,如这里所述。默认情况下,客户端获得的配额是无限的。可以为每个(用户、客户机id)、用户或客户机id组设置自定义配额。
为(user=user1,client-id=clientA)配置自定义配额:
> bin/kafka-configs.sh --bootstrap-server localhost:9092 --alter --add-config 'producer_byte_rate=1024,consumer_byte_rate=2048,request_percentage=200' --entity-type users --entity-name user1 --entity-type clients --entity-name clientAUpdated config for entity: user-principal 'user1', client-id 'clientA'.
为user=user1配置自定义配额:
> bin/kafka-configs.sh --bootstrap-server localhost:9092 --alter --add-config 'producer_byte_rate=1024,consumer_byte_rate=2048,request_percentage=200' --entity-type users --entity-name user1Updated config for entity: user-principal 'user1'.
为client-id=clientA配置自定义配额:
> bin/kafka-configs.sh --bootstrap-server localhost:9092 --alter --add-config 'producer_byte_rate=1024,consumer_byte_rate=2048,request_percentage=200' --entity-type clients --entity-name clientAUpdated config for entity: client-id 'clientA'.
通过指定--entity-default选项而不是--entity-name,可以为每个(用户、client-id)、用户或client-id组设置默认配额。
为user=userA配置默认的client-id配额:
> bin/kafka-configs.sh --bootstrap-server localhost:9092 --alter --add-config 'producer_byte_rate=1024,consumer_byte_rate=2048,request_percentage=200' --entity-type users --entity-name user1 --entity-type clients --entity-defaultUpdated config for entity: user-principal 'user1', default client-id.
配置用户的默认配额:
> bin/kafka-configs.sh --bootstrap-server localhost:9092 --alter --add-config 'producer_byte_rate=1024,consumer_byte_rate=2048,request_percentage=200' --entity-type users --entity-defaultUpdated config for entity: default user-principal.
配置client-id的默认配额:
> bin/kafka-configs.sh --bootstrap-server localhost:9092 --alter --add-config 'producer_byte_rate=1024,consumer_byte_rate=2048,request_percentage=200' --entity-type clients --entity-defaultUpdated config for entity: default client-id.
下面是如何描述一个给定的(用户,client-id)的配额。
> bin/kafka-configs.sh --bootstrap-server localhost:9092 --describe --entity-type users --entity-name user1 --entity-type clients --entity-name clientAConfigs for user-principal 'user1', client-id 'clientA' are producer_byte_rate=1024,consumer_byte_rate=2048,request_percentage=200
描述给定用户的配额:
> bin/kafka-configs.sh --bootstrap-server localhost:9092 --describe --entity-type users --entity-name user1Configs for user-principal 'user1' are producer_byte_rate=1024,consumer_byte_rate=2048,request_percentage=200
描述给定客户ID的配额:
> bin/kafka-configs.sh --bootstrap-server localhost:9092 --describe --entity-type clients --entity-name clientAConfigs for client-id 'clientA' are producer_byte_rate=1024,consumer_byte_rate=2048,request_percentage=200
如果没有指定实体名称,则描述指定类型的所有实体。例如,描述所有用户:
> bin/kafka-configs.sh --bootstrap-server localhost:9092 --describe --entity-type usersConfigs for user-principal 'user1' are producer_byte_rate=1024,consumer_byte_rate=2048,request_percentage=200Configs for default user-principal are producer_byte_rate=1024,consumer_byte_rate=2048,request_percentage=200
同理,对于(用户,客户端):
> bin/kafka-configs.sh --bootstrap-server localhost:9092 --describe --entity-type users --entity-type clientsConfigs for user-principal 'user1', default client-id are producer_byte_rate=1024,consumer_byte_rate=2048,request_percentage=200Configs for user-principal 'user1', client-id 'clientA' are producer_byte_rate=1024,consumer_byte_rate=2048,request_percentage=200
通过在broker上设置这些配置,可以设置适用于所有客户端ID的默认配额。只有在Zookeeper中没有配置配额覆盖或默认值时,才会应用这些属性。默认情况下,每个客户机id都会收到一个无限的配额。下面将每个生产者和消费者客户端-id的默认配额设置为10MB/秒。
quota.producer.default=10485760quota.consumer.default=10485760
请注意,这些属性已经被废弃,可能会在未来的版本中被删除。使用kafka-configs.sh配置的默认值优先于这些属性。
6.2 数据中心
一些部署将需要管理一个跨越多个数据中心的数据管道。我们推荐的方法是在每个数据中心部署一个本地的Kafka集群,每个数据中心的应用实例仅与其本地集群进行交互,并在集群之间进行数据镜像(如何做到这一点,请参见关于地理复制的文档)。
这种部署模式允许数据中心作为独立的实体行事,并允许我们集中管理和调整数据中心间的复制。这允许每个设施独立运行,即使数据中心间链路不可用:当发生这种情况时,镜像会落后,直到链路恢复时才会赶上。
对于需要对所有数据进行全局查看的应用,您可以使用镜像提供集群,该集群的数据汇总从所有数据中心的本地集群中镜像出来。这些聚合集群用于需要完整数据集的应用的读取。
这不是唯一可能的部署模式。通过广域网从远程Kafka集群读取或写入也是可能的,不过很明显,这会增加获取集群所需的任何延迟。
Kafka自然地在生产者和消费者中都会对数据进行批处理,因此即使在高延迟的连接上也能实现高吞吐量。不过为了允许这样做,可能需要使用socket.send.buffer.bytes和socket.receive.buffer.bytes配置来增加生产者、消费者和broker的TCP socket缓冲区大小。这里记载了适当的设置方法。
一般来说,不建议在高延迟链路上运行跨越多个数据中心的单个Kafka集群。这将导致Kafka写入和ZooKeeper写入的复制延迟非常高,而且如果位置之间的网络不可用,Kafka和ZooKeeper都不会在所有位置保持可用。
6.3 地理复制(跨集群数据镜像)
地理复制概述
Kafka管理员可以定义跨越单个Kafka集群、数据中心或地理区域边界的数据流。这种事件流的设置通常是出于组织、技术或法律要求的需要。常见的场景包括
- 地理复制
- 灾难恢复
- 将边缘集群送入一个中央的聚合集群中
- 集群的物理隔离(如生产与测试)。
- 云迁移或混合云部署
- 法律和合规要求
管理员可以通过Kafka的MirrorMaker(第2版)来设置这样的集群间数据流,MirrorMaker是一个在不同Kafka环境之间以流式方式复制数据的工具。MirrorMaker建立在Kafka Connect框架之上,支持以下功能。
- 复制主题(数据加配置)
- 复制包括偏移在内的消费群体,以在集群之间迁移应用。
- 复制ACL
- 保留分区
- 自动检测新主题和分区
- 提供广泛的指标,如跨多个数据中心/集群的端到端复制延迟。
- 容错和横向可扩展的操作。
注意:使用MirrorMaker的Geo-replication可以跨Kafka集群复制数据。这种集群间的复制与Kafka的集群内复制不同,后者在同一个Kafka集群内复制数据。
什么是复制流
通过MirrorMaker,Kafka管理员可以将主题、主题配置、消费者组及其偏移量和ACL从一个或多个源Kafka集群复制到一个或多个目标Kafka集群,即跨集群环境。简而言之,MirrorMaker 使用 Connectors 从源集群消费,并生产到目标集群。
这些从源集群到目标集群的定向流称为复制流。它们在MirrorMaker配置文件中以{source_cluster}->{target_cluster}的格式进行定义,后面会介绍。管理员可以根据这些流创建复杂的复制拓扑。
以下是一些示例模式。
- Active/Active高可用性部署。A->B,B->A
- 主动/被动或主动/备用高可用性部署。A->B
- 聚集(如从许多簇到一个簇)。A->K,B->K,C->K。
- 扇出(如从一簇到多簇)。K->A,K->B,K->C。
- 转发:A->B、B->C、C->D A->B,B->C,C->D。
默认情况下,一个流会复制所有主题和消费者组。但是,可以对每个复制流进行独立配置。例如,您可以定义只将特定的主题或消费者组从源群集复制到目标群集。
下面是关于如何配置数据从主群集复制到辅助群集(主动/被动设置)的第一个例子。
# Basic settingsclusters = primary, secondaryprimary.bootstrap.servers = broker3-primary:9092secondary.bootstrap.servers = broker5-secondary:9092# Define replication flowsprimary->secondary.enable = trueprimary->secondary.topics = foobar-topic, quux-.*
配置地理复制
以下部分描述了如何配置和运行专用的MirrorMaker集群。如果您想在现有的 Kafka Connect 集群或其他支持的部署设置中运行 MirrorMaker,请参考 KIP-382: MirrorMaker 2.0,并注意不同部署模式的配置设置名称可能有所不同。
除了以下章节所涉及的内容外,还可在以下网址获得有关配置设置的进一步示例和信息。
- MirrorMakerConfig,MirrorConnectorConfig。
- 缺省主题过滤(DefaultTopicFilter),缺省组过滤(DefaultGroupFilter)。
- connect-mirror-maker.properties中的配置设置示例,KIP-382。MirrorMaker 2.0
配置文件语法
MirrorMaker配置文件通常命名为connect-mirror-maker.properties。你可以在这个文件中配置各种组件。
- MirrorMaker设置:全局设置,包括集群定义(别名),加上每个复制流的自定义设置。
- Kafka连接和连接器设置
- Kafka生产者、消费者和管理客户端设置
例子。定义MirrorMaker设置(后面会详细解释)。
# Global settingsclusters = us-west, us-east # defines cluster aliasesus-west.bootstrap.servers = broker3-west:9092us-east.bootstrap.servers = broker5-east:9092topics = .* # all topics to be replicated by default# Specific replication flow settings (here: flow from us-west to us-east)us-west->us-east.enable = trueus-west->us.east.topics = foo.*, bar.* # override the default above
MirrorMaker是基于Kafka Connect框架的。在Kafka Connect的文档章节中描述的任何Kafka Connect、source connector和sink connector设置都可以直接在MirrorMaker配置中使用,而无需更改或前缀配置设置的名称。
例子 定义自定义的Kafka Connect设置,供MirrorMaker使用。
# Setting Kafka Connect defaults for MirrorMakertasks.max = 5
除了tasks.max之外,大多数默认的Kafka Connect设置在MirrorMaker开箱即用的情况下都能正常工作。为了在多个MirrorMaker进程中均匀分配工作负载,建议根据可用的硬件资源和要复制的主题分区总数,将tasks.max设置为至少2(最好更高)。
您可以进一步自定义MirrorMaker按源集群或目标集群的Kafka Connect设置(更准确地说,您可以 "按连接器 "指定Kafka Connect worker级别的配置设置)。在MirrorMaker配置文件中使用{cluster}.{config_name}的格式。
例子 :为us-west集群定义自定义连接器设置:
# us-west custom settingsus-west.offset.storage.topic = my-mirrormaker-offsets
MirrorMaker内部使用Kafka生产者、消费者和管理员客户端。经常需要对这些客户端进行自定义设置。要覆盖默认值,请在MirrorMaker配置文件中使用以下格式。
- {source}.consumer.{consumer_config_name}。
- {target}.producer.{producer_config_name}。
- {source_or_target}.admin.{admin_config_name}。
例子:定义自定义生产者、消费者、管理员客户端的设置:
# us-west cluster (from which to consume)us-west.consumer.isolation.level = read_committedus-west.admin.bootstrap.servers = broker57-primary:9092# us-east cluster (to which to produce)us-east.producer.compression.type = gzipus-east.producer.buffer.memory = 32768us-east.admin.bootstrap.servers = broker8-secondary:9092
创建和启用复制流
要定义复制流,必须先在MirrorMaker配置文件中定义各自的源集群和目标Kafka集群。
- clusters(必填):以逗号分隔的Kafka集群 "别名 "列表。
- {clusterAlias}.bootstrap.servers (必填):特定集群的连接信息;以逗号分隔的 "bootstrap "Kafkabroker列表。
例子:定义两个集群别名primary和secondary,包括其连接信息:
clusters = primary, secondaryprimary.bootstrap.servers = broker10-primary:9092,broker-11-primary:9092secondary.bootstrap.servers = broker5-secondary:9092,broker6-secondary:9092
其次,您必须根据需要使用{source}->{target}.enabled = true显式启用单个复制流。请记住,流是有方向性的:如果你需要双向(双向)复制,你必须启用两个方向的流。
# Enable replication from primary to secondaryprimary->secondary.enable = true
默认情况下,复制流将把除少数特殊主题和消费者组以外的所有主题和消费者组从源群集复制到目标群集,并自动检测任何新创建的主题和组。在目标集群中复制的主题的名称将以源集群的名称为前缀(请参阅下面的进一步章节)。例如,源群集 us-west 中的主题 foo 将被复制到目标群集 us-east 中名为 us-west.foo 的主题。
后面的章节将解释如何根据你的需要定制这个基本设置。
配置复制流
复制流的配置是顶层默认设置(如主题)的组合,在顶层默认设置的基础上应用特定流的设置(如us-west->us-east.topic)。要更改顶层默认设置,请将相应的顶层设置添加到 MirrorMaker 配置文件中。要仅覆盖特定复制流的默认值,请使用语法格式{source}->{target}.{config.name}。
最重要的设置是
- topics:主题列表或定义源集群中哪些主题要复制的正则表达式(默认: topics = .*)。
- topics.exclude:topic的列表或正则表达式,用于随后排除由topic设置匹配的topic(默认:topic.exclude = .*[\-/\.]internal, .*/\.replica, __.*)
- groups:主题列表或正则表达式,用于定义源集群中要复制的消费者群体(默认:group = .*)。
- groups.exclude:主题列表或正则表达式,用于随后排除由 groups 设置匹配的消费者组(默认情况下:groups.exclude = console-consumer-.*, connect-.*, __.*)。
- {source}->{target}.enable:设置为true以启用复制流(默认:false)。
例如:
# Custom top-level defaults that apply to all replication flowstopics = .*groups = consumer-group1, consumer-group2# Don't forget to enable a flow!us-west->us-east.enable = true# Custom settings for specific replication flowsus-west->us-east.topics = foo.*us-west->us-east.groups = bar.*us-west->us-east.emit.heartbeats = false
支持其他配置设置,其中一些设置列在下面。在大多数情况下,你可以让这些设置保持默认值。更多细节请参见MirrorMakerConfig和MirrorConnectorConfig。
- refresh.topics.enabled:是否定期检查源集群中的新主题(默认:true)。
- refresh.topics.interval.seconds:在源集群中检查新主题的频率;比默认值低的值可能会导致性能下降(默认值:6000,每十分钟一次)。
- refresh.groups.enabled:是否定期检查源群集中的新消费群集(默认:true)。
- refresh.groups.interval.seconds:在源群集中检查新消费者群集的频率;低于默认值可能会导致性能下降(默认值:6000,每十分钟一次)。
- sync.topic.configs.enabled:是否从源集群复制topic配置(默认:true)。
- sync.topic.acls.enabled:是否从源集群同步ACL(默认:true)。
- emit.heartbeats.enabled:是否周期性地发出心跳声(默认:true)。
- emit.heartbeats.interval.seconds:发出心跳的频率(默认:5,每五秒一次)。
- heartbeats.topic.replication.factor:MirrorMaker内部心跳主题的复制因子(默认:3)。
- emit.checkpoints.enabled:是否定期发射MirrorMaker的消费偏移量(默认:true)。
- emit.checkpoints.interval.seconds:发出检查点的频率(默认:60,每分钟)。
- checkpoints.topic.replication.factor:MirrorMaker内部检查点主题的复制因子(默认:3)。
- sync.group.offsets.enabled:是否定期将复制的消费群组(在源群组中)的翻译偏移量写入目标群组中的__consumer_offsets主题,只要该群组中没有活跃的消费者连接到目标群组(默认:true)。
- sync.group.offsets.interval.seconds:同步消费组偏移量的频率(默认:60,每分钟)。
- offset-syncs.topic.replication.factor:MirrorMaker内部offset-syncs主题的复制因子(默认:3)
确保复制流的安全
MirrorMaker支持与Kafka Connect相同的安全设置,所以请参考链接部分了解更多信息。
例如: 加密MirrorMaker和us-east集群之间的通信:
us-east.security.protocol=SSLus-east.ssl.truststore.location=/path/to/truststore.jksus-east.ssl.truststore.password=my-secret-passwordus-east.ssl.keystore.location=/path/to/keystore.jksus-east.ssl.keystore.password=my-secret-passwordus-east.ssl.key.password=my-secret-password
自定义命名目标集群中重复的主题
在目标集群中复制的主题--有时称为远程主题--会根据复制策略重新命名。MirrorMaker使用该策略来确保来自不同集群的事件(也就是记录、消息)不会被写入同一个主题分区。默认情况下,按照DefaultReplicationPolicy,目标集群中复制的主题名称具有{source}.{source_topic_name}的格式。
us-west us-east========= =================bar-topicfoo-topic --> us-west.foo-topic
您可以使用 replication.policy.separator 设置自定义分隔符(默认:.)
# 自定义一个分隔符us-west->us-east.replication.policy.separator = _
如果你需要进一步控制复制的主题的命名方式,你可以实现一个自定义的ReplicationPolicy,并在MirrorMaker配置中覆盖replication.policy.class(默认为DefaultReplicationPolicy)。
防止配置冲突
MirrorMaker进程通过其目标Kafka集群共享配置。当针对同一目标集群操作的MirrorMaker进程之间的配置不同时,这种行为可能会导致冲突。
例如,以下两个MirrorMaker进程会很狂野:
# Configuration of process 1A->B.enabled = trueA->B.topics = foo# Configuration of process 2A->B.enabled = trueA->B.topics = bar
在这种情况下,两个进程将通过集群B共享配置,从而导致冲突。根据这两个进程中哪个进程是当选的 "领导者",结果将是主题foo或主题栏被复制,但不是两个都被复制。
因此,在复制到同一目标集群的各个复制流中保持MirrorMaker配置的一致性是非常重要的。例如,可以通过自动化工具或为整个组织使用单一的共享MirrorMaker配置文件来实现这一点。
最佳实践:远程消费,本地生产
为了最大限度地减少延迟("生产者滞后"),建议将MirrorMaker进程定位在尽可能靠近其目标集群的地方,即它生产数据的集群。这是因为Kafka生产者通常比Kafka消费者在不可靠或高延迟的网络连接中挣扎得更多。
First DC Second DC========== =========================primary --------- MirrorMaker --> secondary(remote) (local)
要运行这种 "从远程消费,生产到本地 "的设置,请在目标集群附近,最好是在同一位置运行MirrorMaker进程,并在--clusters命令行参数中明确设置这些 "本地 "集群(以空格分隔的集群别名列表)。
# Run in secondary's data center, reading from the remote `primary` cluster$ ./bin/connect-mirror-maker.sh connect-mirror-maker.properties --clusters secondary
--clusters secondary告诉MirrorMaker进程,给定的集群就在附近,并防止它复制数据或向其他远程位置的集群发送配置。
例子:主动/被动高可用性部署 主动/被动高可用性部署
下面的例子显示了将主题从主环境复制到辅助Kafka环境的基本设置,但不是从辅助环境复制回主环境。请注意,大多数生产设置将需要进一步的配置,例如安全设置。
# Unidirectional flow (one-way) from primary to secondary clusterprimary.bootstrap.servers = broker1-primary:9092secondary.bootstrap.servers = broker2-secondary:9092primary->secondary.enabled = truesecondary->primary.enabled = falseprimary->secondary.topics = foo.* # only replicate some topics
示例:主动/主动高可用性部署
下面的例子显示了在两个集群之间以两种方式复制主题的基本设置。请注意,大多数生产设置将需要进一步的配置,例如安全设置。
# Bidirectional flow (two-way) between us-west and us-east clustersclusters = us-west, us-eastus-west.bootstrap.servers = broker1-west:9092,broker2-west:9092Us-east.bootstrap.servers = broker3-east:9092,broker4-east:9092us-west->us-east.enabled = trueus-east->us-west.enabled = true
关于防止复制 "循环 "的注意点(即topic将原本从A复制到B,然后被复制的topic将再次从B复制到A,以此类推)。只要在同一个MirrorMaker配置文件中定义上述流程,就不需要明确添加topic.exclude设置来防止两个集群之间的复制循环。
例子: 多集群地理复制
让我们把前面几节的所有信息放在一个更大的例子中。想象一下,有三个数据中心(西、东、北),每个数据中心有两个Kafka集群(例如,西-1、西-2)。本节的示例展示了如何配置MirrorMaker (1)用于每个数据中心内的Active/Active复制,以及(2)用于跨数据中心复制(XDCR)。
首先,在配置中定义源集群和目标集群以及它们的复制流:
# Basic settingsclusters: west-1, west-2, east-1, east-2, north-1, north-2west-1.bootstrap.servers = ...west-2.bootstrap.servers = ...east-1.bootstrap.servers = ...east-2.bootstrap.servers = ...north-1.bootstrap.servers = ...north-2.bootstrap.servers = ...# Replication flows for Active/Active in West DCwest-1->west-2.enabled = truewest-2->west-1.enabled = true# Replication flows for Active/Active in East DCeast-1->east-2.enabled = trueeast-2->east-1.enabled = true# Replication flows for Active/Active in North DCnorth-1->north-2.enabled = truenorth-2->north-1.enabled = true# Replication flows for XDCR via west-1, east-1, north-1west-1->east-1.enabled = truewest-1->north-1.enabled = trueeast-1->west-1.enabled = trueeast-1->north-1.enabled = truenorth-1->west-1.enabled = truenorth-1->east-1.enabled = true
然后,在每个数据中心,启动一个或多个MirrorMaker,如下所示。
# In West DC:$ ./bin/connect-mirror-maker.sh connect-mirror-maker.properties --clusters west-1 west-2# In East DC:$ ./bin/connect-mirror-maker.sh connect-mirror-maker.properties --clusters east-1 east-2# In North DC:$ ./bin/connect-mirror-maker.sh connect-mirror-maker.properties --clusters north-1 north-2
通过这种配置,向任何集群生产的记录都将在数据中心内复制,也会跨到其他数据中心。通过提供--clusters参数,我们可以确保每个MirrorMaker进程只向附近的集群生产数据。
注意:从技术上讲,这里并不需要--clusters参数。MirrorMaker在没有它的情况下也能正常工作。但是,吞吐量可能会受到数据中心之间 "生产者滞后 "的影响,你可能会产生不必要的数据传输成本。
开始地理复制
您可以根据需要运行尽可能少的或尽可能多的MirrorMaker进程(认为:节点、服务器)。因为MirrorMaker是基于Kafka Connect的,所以配置为复制相同Kafka集群的MirrorMaker进程以分布式设置运行。它们会相互找到对方,共享配置(见下节),负载平衡它们的工作,等等。例如,如果你想提高复制流的吞吐量,一个选项是并行运行额外的MirrorMaker进程。
要启动一个MirrorMaker进程,请运行命令:
$ ./bin/connect-mirror-maker.sh connect-mirror-maker.properties
启动后,可能需要几分钟的时间,直到MirrorMaker进程第一次开始复制数据。
如前所述,可以选择设置参数--clusters,以确保MirrorMaker进程只向附近的集群产生数据。
# Note: The cluster alias us-west must be defined in the configuration file$ ./bin/connect-mirror-maker.sh connect-mirror-maker.properties \--clusters us-west
测试复制消费者组时的注意事项。默认情况下,MirrorMaker不会复制kafka-console-consumer.sh工具创建的消费者组,你可能会用它在命令行上测试你的MirrorMaker设置。如果你确实也想复制这些消费者组,请相应地设置groups.exclude配置(默认:groups.exclude = console-consumer-.*,connect-.*,__.*)。完成测试后,记得再次更新配置。
停止地理复制
你可以通过使用命令发送SIGTERM信号来停止正在运行的MirrorMaker进程。
$ kill <MirrorMaker pid>
应用配置更改
要使配置更改生效,必须重新启动MirrorMaker进程。
监测地理复制
建议监控MirrorMaker进程,以确保所有定义的复制流都能正常运行。MirrorMaker建立在Connect框架上,继承了Connect的所有度量,比如source-record-poll-rate。此外,MirrorMaker还在kafka.connect.mirror度量组下产生自己的度量。度量被标记为以下属性。
- source:源集群的别名(例如,主集群)。
- target:目标群组的别名(如二级)。
- topic:在目标群组上复制的主题
- partition:被复制的分区
对每个复制的主题进行度量跟踪。可以从主题名称推断出源集群。例如,从primary->secondary复制topic1将产生如下指标。
target=secondarytopic=primary.topic1partition=1
发出以下指标:
# MBean: kafka.connect.mirror:type=MirrorSourceConnector,target=([-.w]+),topic=([-.w]+),partition=([0-9]+)record-count # number of records replicated source -> targetrecord-age-ms # age of records when they are replicatedrecord-age-ms-minrecord-age-ms-maxrecord-age-ms-avgreplication-latency-ms # time it takes records to propagate source->targetreplication-latency-ms-minreplication-latency-ms-maxreplication-latency-ms-avgbyte-rate # average number of bytes/sec in replicated records# MBean: kafka.connect.mirror:type=MirrorCheckpointConnector,source=([-.w]+),target=([-.w]+)checkpoint-latency-ms # time it takes to replicate consumer offsetscheckpoint-latency-ms-mincheckpoint-latency-ms-maxcheckpoint-latency-ms-avg
这些指标并不区分create-at和log-append时间戳。
6.4 kfaka配置
重要的客户端配置
最重要的生产者配置是。
- acks
- compression
- batch size
最重要的消费者配置是获取大小。
所有的配置在配置部分都有记载。
生产服务器配置
下面是一个生产服务器配置的例子:
# ZooKeeperzookeeper.connect=[list of ZooKeeper servers]# Log configurationnum.partitions=8default.replication.factor=3log.dir=[List of directories. Kafka should have its own dedicated disk(s) or SSD(s).]# Other configurationsbroker.id=[An integer. Start with 0 and increment by 1 for each new broker.]listeners=[list of listeners]auto.create.topics.enable=falsemin.insync.replicas=2queued.max.requests=[number of concurrent requests]
我们的客户端配置在不同的用例之间有相当大的差异。
6.5 Java版本
支持Java 8和Java 11。如果启用了TLS,Java 11的性能会显著提高,所以强烈推荐使用(它还包括一些其他性能改进。G1GC、CRC32C、Compact Strings、线程本地握手等)。) 从安全角度来看,我们推荐最新发布的补丁版本,因为旧的免费版本已经披露了安全漏洞。用基于OpenJDK的Java实现(包括Oracle JDK)运行Kafka的典型配置是:
-Xmx6g -Xms6g -XX:MetaspaceSize=96m -XX:+UseG1GC-XX:MaxGCPauseMillis=20 -XX:InitiatingHeapOccupancyPercent=35 -XX:G1HeapRegionSize=16M-XX:MinMetaspaceFreeRatio=50 -XX:MaxMetaspaceFreeRatio=80 -XX:+ExplicitGCInvokesConcurrent
以下是LinkedIn最繁忙的一个集群(高峰期)使用上述Java参数的统计数据,供参考:
- 60个broker
- 5万个分区(复制系数为2)
- 80万条/秒的信息
- 入300 MB/秒,出1 GB/秒以上
该集群中的所有broker,90%的GC暂停时间约为21ms,每秒只有不到1个新生代GC。
6.6 硬件和操作系统
我们使用的是双四核Intel Xeon机器,内存为24GB。
你需要足够的内存来缓冲活跃的读写器。你可以通过假设你希望能够缓冲30秒,并计算你的内存需求为write_throughput*30,对内存需求做一个包络后的估计。
磁盘的吞吐量很重要。我们有8x7200转的SATA硬盘。一般来说,磁盘吞吐量是性能瓶颈,磁盘越多越好。取决于你如何配置刷新行为,你可能会或可能不会受益于更昂贵的磁盘(如果你经常强制刷新,那么更高转速的SAS驱动器可能会更好)。
操作系统
Kafka应该在任何unix系统上运行良好,并且已经在Linux和Solaris上进行了测试。
我们已经看到了一些在Windows上运行的问题,Windows目前不是一个很好的支持平台,尽管我们很乐意改变这种情况。
它不太可能需要太多的操作系统级别的调整,但是有三个潜在的重要的操作系统级别的配置。
- 文件描述符限制。Kafka对日志段和开放连接使用文件描述符。如果一个broker托管了许多分区,考虑到broker至少需要(number_of_partitions)*(partition_size/segment_size)来跟踪所有的日志段,此外还有broker的连接数。我们建议至少为broker进程提供100000个允许的文件描述符作为起点。注意:mmap()函数为与文件描述符 fildes 相关联的文件添加了一个额外的引用,这个引用不会被随后对该文件描述符的 close()删除。当没有更多的映射到文件时,这个引用就会被删除。
- 最大套接字缓冲区大小:可以增加,以实现这里所说的数据中心之间的高性能数据传输。
- 一个进程可能拥有的内存映射区域的最大数量(又名vm.max_map_count)。参见Linux内核文档。在考虑一个broker可能拥有的最大分区数时,你应该关注这个操作系统级别的属性。默认情况下,在一些Linux系统上,vm.max_map_count的值是65535左右。每个分区分配的每个日志段,都需要一对索引/时间索引文件,每个文件消耗1个地图区域。换句话说,每个日志段使用2个地图区域。因此,每个分区只要承载一个日志段,就至少需要2个地图区域。也就是说,在一个broker上创建50000个分区将导致100000个地图区域的分配,并且很可能导致broker在默认的vm.max_map_count系统上以OutOfMemoryError(地图失败)的方式崩溃。请记住,每个分区的日志段数根据段的大小、负载强度、保留策略的不同而不同,一般来说,往往会超过一个。
磁盘和文件系统
我们建议使用多个驱动器来获得良好的吞吐量,并且不要与应用程序日志或其他操作系统文件系统活动共享用于Kafka数据的相同驱动器,以确保良好的延迟。你可以将这些硬盘一起RAID成一个卷,或者将每个硬盘格式化并挂载为自己的目录。由于Kafka具有复制功能,RAID提供的冗余也可以在应用层提供。这种选择有几个权衡。
如果你配置了多个数据目录,分区将被轮流分配到数据目录中。每个分区将完全在其中一个数据目录中。如果数据在分区之间没有得到很好的平衡,就会导致磁盘之间的负载不平衡。
RAID有可能在平衡磁盘之间的负载方面做得更好(尽管它似乎并不总是这样),因为它在较低的层次上平衡负载。RAID的主要缺点是,它通常会对写入吞吐量造成很大的性能冲击,并减少可用的磁盘空间。
RAID的另一个潜在好处是能够容忍磁盘故障。然而我们的经验是,重建RAID阵列是如此的I/O密集型,以至于它有效地禁用了服务器,所以这并没有提供多少真正的可用性改进。
应用程序与操作系统刷新管理
Kafka总是立即将所有数据写入文件系统,并支持配置刷新策略的功能,控制何时使用刷新将数据从操作系统缓存中强制写入磁盘。这个刷新策略可以控制在一段时间后或在写入一定数量的消息后强制将数据放到磁盘上。这个配置有几种选择。
Kafka最终必须调用fsync才能知道数据被刷新。当从崩溃中恢复任何不知道是fsync'd的日志段时,Kafka将通过检查每个消息的CRC来检查其完整性,并且还重建附带的偏移索引文件,作为启动时执行的恢复过程的一部分。
请注意,Kafka中的耐久性不需要将数据同步到磁盘上,因为失败的节点总是会从其副本中恢复。
我们建议使用默认的刷新设置,它完全禁用应用程序fsync。这意味着依靠操作系统和Kafka自己的后台刷新来完成。这为大多数用途提供了最好的选择:无需调整旋钮,极大的吞吐量和延迟,以及完全的恢复保证。我们普遍觉得复制提供的保证比同步到本地磁盘更强,然而偏执狂还是可能更喜欢两者兼备,而且仍然支持应用级fsync策略。
使用应用级刷新设置的缺点是它的磁盘使用模式效率较低(它给操作系统重新排序写入的余地较小),而且它可能会引入延迟,因为大多数Linux文件系统中的fsync会阻止对文件的写入,而后台刷新做的是更细化的页级锁定。
一般来说,你不需要对文件系统进行任何低级别的调整,但在接下来的几节中,我们将介绍一些这方面的内容,以防有用。
了解Linux操作系统的刷新行为
在Linux中,写入文件系统的数据被保存在pagecache中,直到必须将其写入磁盘(由于应用程序级的fsync或操作系统自己的刷新策略)。数据的刷新是由一组称为pdflush的后台线程(或在2.6.32后的内核中称为 "flusher线程")完成的。
Pdflush有一个可配置的策略来控制缓存中可以保留多少脏数据,以及在多长时间内必须将其写回磁盘。这里描述了这个策略。当Pdflush无法跟上数据写入的速度时,它最终会导致写入过程阻塞,从而在写入过程中产生延迟,减缓数据的积累。
你可以通过执行以下操作来查看当前操作系统的内存使用状况
- > cat /proc/meminfo
这些值的含义在上面的链接中进行了描述。
与进程内缓存相比,使用pagecache来存储将写入磁盘的数据有几个优势。
- I/O调度器会将连续的小写合并成较大的物理写,从而提高吞吐量。
- I/O调度器会尝试重新排序写入,以减少磁盘头的移动,从而提高吞吐量。
- 它自动使用机器上所有的可用内存。
文件系统选择
Kafka使用的是磁盘上的常规文件,因此它对特定的文件系统没有硬性依赖。不过,使用率最高的两个文件系统是EXT4和XFS。从历史上看,EXT4的使用量更大,但最近对XFS文件系统的改进表明,它对Kafka的工作负载有更好的性能特性,而且在稳定性方面没有任何妥协。
对比测试是在一个具有重大消息负载的集群上进行的,使用各种文件系统创建和挂载选项。Kafka中被监控的主要指标是 "请求本地时间",表示追加操作所需的时间。XFS带来了更好的本地时间(160ms vs. 最佳EXT4配置的250ms+),以及更低的平均等待时间。XFS性能也显示出磁盘性能的变化较小。
一般文件系统注意事项
对于任何用于数据目录的文件系统,在Linux系统上,建议在挂载时使用以下选项。
- noatime 这个选项可以在读取文件时禁止更新文件的atime(最后访问时间)属性。这可以消除大量的文件系统写入,特别是在引导消费者的情况下。Kafka根本不依赖atime属性,所以禁用这个是安全的。
XFS文件系统注意事项
XFS文件系统有大量的自动调优功能,所以无论是在创建文件系统时还是在挂载时,都不需要改变默认设置。唯一值得考虑的调优参数是
- largeio: 这会影响 stat 调用报告的首选 I/O 大小。虽然这可以让较大的磁盘写入时获得更高的性能,但在实践中,它对性能的影响微乎其微,甚至没有影响。
- nobarrier。对于有电池支持缓存的底层设备,这个选项可以通过禁用周期性的写入刷新来提供更高的性能。但是,如果底层设备表现良好,它会向文件系统报告它不需要刷新,这个选项就没有影响。
EXT4文件系统注意事项
EXT4是Kafka数据目录的一个服务性的文件系统选择,然而要想获得最大的性能,需要调整几个挂载选项。此外,这些选项在故障情况下一般是不安全的,会导致更多的数据丢失和损坏。对于单个broker故障,这并不是什么大问题,因为可以擦除磁盘,并从集群中重建副本。在多重故障的情况下,例如断电,这可能意味着底层文件系统(因此也是数据)的损坏,不容易恢复。以下选项可以调整。
- data=writeeback: Ext4默认为data=ordered,它对一些写入进行了强烈的排序。Kafka不需要这个排序,因为它对所有未刷新的日志进行非常偏执的数据恢复。这个设置去掉了排序约束,似乎可以显著降低延迟。
- 禁用日志。日志是一种权衡:它使服务器崩溃后的重启速度更快,但它引入了大量额外的锁定,增加了写入性能的变数。那些不关心重启时间并希望减少写延迟峰值的主要来源的人可以完全关闭日志。
- commit=num_secs。这将调整 ext4 向元数据日志提交的频率。将其设置为较低的值可以减少崩溃时未刷新数据的损失。将其设置为较高的值将提高吞吐量。
- nobh:当使用data=writeback模式时,该设置控制额外的排序保证。这对Kafka来说应该是安全的,因为我们不依赖于写排序,并提高吞吐量和延迟。
- delalloc。延迟分配意味着文件系统避免分配任何块,直到物理写发生。这允许ext4分配一个大的范围,而不是较小的页面,并有助于确保数据按顺序写入。这个特性对于吞吐量来说是非常好的。它似乎涉及到文件系统中的一些锁定,这增加了一点延迟差异。
6.7 监测
Kafka在服务器中使用Yammer Metrics进行度量报告。Java客户端使用Kafka Metrics,这是一个内置的度量注册表,可以最大限度地减少拉到客户端应用程序中的过渡性依赖关系。两者都通过JMX暴露度量,并且可以配置使用可插拔的统计报告器来报告统计数据,以挂接到您的监控系统。
所有的Kafka速率指标都有一个相应的累计计数指标,后缀为-total。例如,records-consumed-rate有一个对应的度量,名为records-consumed-total。
查看可用指标的最简单方法是启动jconsole,并将其指向正在运行的kafka客户端或服务器;这将允许使用JMX浏览所有指标。
使用JMX进行远程监控的安全注意事项
Apache Kafka 默认情况下是禁用远程 JMX 的。您可以通过为使用 CLI 或标准 Java 系统属性启动的进程设置环境变量 JMX_PORT 来启用远程 JMX 的远程监控,从而以编程方式启用远程 JMX。在生产场景中启用远程 JMX 时,您必须启用安全功能,以确保未经授权的用户无法监视或控制您的broker或应用程序以及运行这些应用程序的平台。请注意,在Kafka中,默认情况下,JMX的身份验证是被禁用的,对于生产部署,必须通过为使用CLI启动的进程设置环境变量KAFKA_JMX_OPTS或设置适当的Java系统属性来覆盖安全配置。请参阅使用JMX技术的监控和管理,了解有关JMX安全的详细信息。
我们对以下指标进行图形化和警报:
| 描述 | 指标名称 | 值域 |
|---|---|---|
| 消息速率 | kafka.server:type=BrokerTopicMetrics,name=MessagesInPerSec | |
| 客户端消息速率 | kafka.server:type=BrokerTopicMetrics,name=BytesInPerSec | |
| 从其他broker同步消息速率 | kafka.server:type=BrokerTopicMetrics,name=ReplicationBytesInPerSec | |
| 请求速率 | kafka.network:type=RequestMetrics,name=RequestsPerSec,request={Produce|FetchConsumer|FetchFollower} | |
| 错误速率 | kafka.network:type=RequestMetrics,name=ErrorsPerSec,request=([-.\w]+),error=([-.\w]+) | 按请求类型和错误代码计算的响应中的错误数量。如果一个响应包含多个错误,则会计算所有错误。error=NONE表示成功的响应。 |
| 请求大小 | kafka.network:type=RequestMetrics,name=RequestBytes,request=([-.\w]+) | 每个请求类型的请求大小 |
| 临时内存大小 | kafka.network:type=RequestMetrics,name=TemporaryMemoryBytes,request={Produce|Fetch} |
用于消息格式转换和解压的临时内存 |
| 消息格式转换时间 | kafka.network:type=RequestMetrics,name=MessageConversionsTimeMs,request={Produce|Fetch} |
信息格式转换所花费的时间,以毫秒为单位。 |
| 消息格式转换速率 | kafka.server:type=BrokerTopicMetrics,name={Produce|Fetch}MessageConversionsPerSec,topic=([-.\w]+) |
需要转换电文格式的记录数量。 |
| 请求队列大小 | kafka.network:type=RequestChannel,name=RequestQueueSize | 请求队列大小 |
| 客户端的字节输出速率 | kafka.server:type=BrokerTopicMetrics,name=BytesOutPerSec | |
| 发送到其他broker字节输出速率 | kafka.server:type=BrokerTopicMetrics,name=ReplicationBytesOutPerSec | |
| 由于没有为压缩主题指定密钥而导致的消息验证失败率 | kafka.server:type=BrokerTopicMetrics,name=NoKeyCompactedTopicRecordsPerSec | |
| 因无效魔数导致的信息验证失败率 | kafka.server:type=BrokerTopicMetrics,name=InvalidMagicNumberRecordsPerSec | |
| 由于错误的crc校验和而导致的信息验证失败率 | kafka.server:type=BrokerTopicMetrics,name=InvalidMessageCrcRecordsPerSec | |
| 由于批次中的非连续偏移或序列号导致的信息验证失败率 | kafka.server:type=BrokerTopicMetrics,name=InvalidOffsetOrSequenceRecordsPerSec | |
| 日志刷新速度和时间 | kafka.log:type=LogFlushStats,name=LogFlushRateAndTimeMs | |
| # 复制不足的分区数(未重新分配的副本数-ISR数>0) | kafka.server:type=ReplicaManager,name=UnderReplicatedPartitions | 0 |
| # 小于最小Isr分区的数量(|ISR| < min.insync.replicas) | kafka.server:type=ReplicaManager,name=UnderMinIsrPartitionCount | 0 |
| # 等于最小Isr分区的数量 (|ISR| = min.insync.replicas) | kafka.server:type=ReplicaManager,name=AtMinIsrPartitionCount | 0 |
| # 离线的日志目录 | kafka.log:type=LogManager,name=OfflineLogDirectoryCount | 0 |
| broker的控制器是否活跃 | kafka.controller:type=KafkaController,name=ActiveControllerCount |
在集群中,应该有一个broker应该是1 |
| 选举leader的速率 | kafka.controller:type=ControllerStats,name=LeaderElectionRateAndTimeMs | 当出现broker故障时,非零 |
| 不干净的选举leader的速率 | kafka.controller:type=ControllerStats,name=UncleanLeaderElectionsPerSec | 0 |
| 待删除的topic的数量 | kafka.controller:type=KafkaController,name=TopicsToDeleteCount | |
| 待删除的分区数量 | kafka.controller:type=KafkaController,name=ReplicasToDeleteCount | |
| 待删除的不合格的topic的数量 | kafka.controller:type=KafkaController,name=TopicsIneligibleToDeleteCount | |
| 待删除的不合格的分区数量 | kafka.controller:type=KafkaController,name=ReplicasIneligibleToDeleteCount | |
| 分区计数 | kafka.server:type=ReplicaManager,name=PartitionCount | 通常是奇数 |
| Leader副本计数 | kafka.server:type=ReplicaManager,name=LeaderCount | 通常是奇数 |
| ISR 收缩速率 | kafka.server:type=ReplicaManager,name=IsrShrinksPerSec |
如果一个broker宕机,部分分区的ISR会缩减。当该broker再次启动时,一旦副本被完全赶上,ISR将被扩大。除此之外,ISR收缩率和扩张率的预期值都是0。 |
| ISR 扩展速率 | kafka.server:type=ReplicaManager,name=IsrExpandsPerSec | 参考上面 |
| 追随者和领导者副本之间的消息最大滞后性 | kafka.server:type=ReplicaFetcherManager,name=MaxLag,clientId=Replica |
滞后时间应与最大的一个生产者请求大小成正比。 |
| 每个追随者副本的消息滞后 | kafka.server:type=FetcherLagMetrics,name=ConsumerLag,clientId=([-.\w]+),topic=([-.\w]+),partition=([0-9]+) |
滞后时间应与最大的一个生产者请求大小成正比。 |
| 在生产者发送队列中等待的请求数量 | kafka.server:type=DelayedOperationPurgatory,name=PurgatorySize,delayedOperation=Produce | 如果使用ack=-1,则为非零。 |
| 在消费者队列中等待的请求 | kafka.server:type=DelayedOperationPurgatory,name=PurgatorySize,delayedOperation=Fetch |
大小取决于消费者中的fetch.wait.max.ms。 |
| 请求总计用时 | kafka.network:type=RequestMetrics,name=TotalTimeMs,request={Produce|FetchConsumer|FetchFollower} |
分为队列、本地、远程和响应发送时间。 |
| 请求在请求队列中的等待时间 | kafka.network:type=RequestMetrics,name=RequestQueueTimeMs,request={Produce|FetchConsumer|FetchFollower} | |
| 请求在leader处处理的时间 | kafka.network:type=RequestMetrics,name=LocalTimeMs,request={Produce|FetchConsumer|FetchFollower} | |
| 请求等待follower的时间 | kafka.network:type=RequestMetrics,name=RemoteTimeMs,request={Produce|FetchConsumer|FetchFollower} |
当ACK=-1时,生产请求的非零。 |
| 请求在响应队列中的等待时间 | kafka.network:type=RequestMetrics,name=ResponseQueueTimeMs,request={Produce|FetchConsumer|FetchFollower} | |
| 发出答复的时间 | kafka.network:type=RequestMetrics,name=ResponseSendTimeMs,request={Produce|FetchConsumer|FetchFollower} | |
| 消费者落后于生产者的信息数量。由消费者发布,而非broker发布。 | kafka.consumer:type=consumer-fetch-manager-metrics,client-id={client-id} Attribute: records-lag-max | |
| 网络处理器空闲的平均时长。 | kafka.network:type=SocketServer,name=NetworkProcessorAvgIdlePercent |
在0和1之间,理想的情况是>0.3。 |
| 由于客户机没有重新认证,然后使用超过到期时间的连接进行重新认证以外的其他操作而在处理器上断开的连接数。 | kafka.server:type=socket-server-metrics,listener=[SASL_PLAINTEXT|SASL_SSL],networkProcessor=<#>,name=expired-connections-killed-count |
理想情况下,当重新认证被启用时,意味着不再有任何旧的、2.2.0之前的客户端连接到这个(监听器、处理器)组合上。 |
| 由于客户机没有重新认证,然后在过期后将连接用于除重新认证以外的其他用途而断开的连接总数,跨越所有处理器。 | kafka.network:type=SocketServer,name=ExpiredConnectionsKilledCount |
理想情况下,当重新认证被启用时,意味着不再有任何旧的、2.2.0之前的客户端连接到这个broker。 |
| 请求处理程序线程空闲的平均时长。 | kafka.server:type=KafkaRequestHandlerPool,name=RequestHandlerAvgIdlePercent |
在0和1之间,理想的情况是>0.3。 |
| 每个(用户、客户端ID)、用户或客户端ID的带宽配额指标 | kafka.server:type={Produce|Fetch},user=([-.\w]+),client-id=([-.\w]+) |
两个属性。 throttle-time表示客户端被节流的时间,单位为ms。理想情况下=0.byte-rate表示客户端的数据产生/消耗率,单位为字节/秒。对于(user,client-id)配额,用户和client-id都要指定。如果对客户端应用了per-client-id配额,则不指定用户。如果应用了per-user配额,则不指定client-id。 |
| 按(用户、客户机ID)、用户或客户机ID申请配额指标。 | kafka.server:type=Request,user=([-.\w]+),client-id=([-.\w]+) |
两个属性.throttle-time表示客户端被节流的时间,单位为ms。理想情况下=0.request-time表示在broker网络和I/O线程中处理来自客户端组的请求所花费的时间百分比。对于(user,client-id)配额,用户和client-id都要指定。如果对客户端应用了per-client-id配额,则不指定用户。如果应用了per-user配额,则不指定client-id。 |
| 免于节流的请求 | kafka.server:type=Request |
exempt-throttle-time表示经纪网络和I/O线程处理免于节流的请求所花费的时间百分比。 |
| ZooKeeper客户端请求延迟 | kafka.server:type=ZooKeeperClientMetrics,name=ZooKeeperRequestLatencyMs |
从broker发出ZooKeeper请求的延迟,以毫秒计。 |
| ZooKeeper连接状态 | kafka.server:type=SessionExpireListener,name=SessionState |
brokerZooKeeper会话的连接状态可能是Disconnected|SyncConnected|AuthFailed|ConnectedReadOnly|SaslAuthenticated|Expired。 |
| 加载组元数据的最大时间 | kafka.server:type=group-coordinator-metrics,name=partition-load-time-max |
从过去30秒内加载的消费者偏移分区加载偏移量和组元数据所花费的最大时间(包括等待加载任务被安排的时间),以毫秒为单位。 |
| 加载组元数据的平均时间 | kafka.server:type=group-coordinator-metrics,name=partition-load-time-avg |
过去30秒内从消费者偏移分区加载偏移量和组元数据所花费的平均时间(包括等待加载任务被安排的时间),单位为毫秒。 |
| 加载交易元数据的最大时间 | kafka.server:type=transaction-coordinator-metrics,name=partition-load-time-max |
从过去30秒内加载的消费者偏移分区加载事务元数据所花费的最大时间(包括等待加载任务被安排的时间),单位为毫秒。 |
| 载入交易元数据的平均时间 | kafka.server:type=transaction-coordinator-metrics,name=partition-load-time-avg |
从过去30秒内加载的消费者偏移分区中加载事务元数据所需的平均时间(包括等待加载任务被安排的时间),以毫秒为单位。 |
| 消费者组偏离量统计 | kafka.server:type=GroupMetadataManager,name=NumOffsets |
消费者组提交的偏移量总数 |
| 消费者组总数 | kafka.server:type=GroupMetadataManager,name=NumGroups | 消费者组的总数 |
| 消费者组总数,每种状态 | kafka.server:type=GroupMetadataManager,name=NumGroups[PreparingRebalance,CompletingRebalance,Empty,Stable,Dead] | 处于不同状态的消费者组总数。 PreparingRebalance, CompletingRebalance, Empty, Stable, Dead |
| 重新分配分区的数量 | kafka.server:type=ReplicaManager,name=ReassigningPartitions | 每台broker机器上正在重新分配的leader分区的数量 |
| 重新分配流量的出站字节率 | kafka.server:type=BrokerTopicMetrics,name=ReassignmentBytesOutPerSec | |
| 重新分配流量的传入字节率 | kafka.server:type=BrokerTopicMetrics,name=ReassignmentBytesInPerSec |
生产者/消费者/连接/流的共同监测指标
以下指标在生产者/消费者/连接者/流实例中可用。具体的指标,请看以下章节。
| 度量值 | 描述 | 度量名称 |
|---|---|---|
| connection-close-rate | 窗口中每秒钟关闭的连接数。 | kafka.[producer|consumer|connect]:type=[producer|consumer|connect]-metrics,client-id=([-.\w]+) |
| connection-close-total | 窗口中关闭的连接总数。 | kafka.[producer|consumer|connect]:type=[producer|consumer|connect]-metrics,client-id=([-.\w]+) |
| connection-creation-rate | 窗口中每秒钟建立的新连接。 | kafka.[producer|consumer|connect]:type=[producer|consumer|connect]-metrics,client-id=([-.\w]+) |
| connection-creation-total | 窗口中建立的新连接总数。 | kafka.[producer|consumer|connect]:type=[producer|consumer|connect]-metrics,client-id=([-.\w]+) |
| network-io-rate | 每秒钟对所有连接的平均网络操作次数(读或写)。 | kafka.[producer|consumer|connect]:type=[producer|consumer|connect]-metrics,client-id=([-.\w]+) |
| network-io-total | 所有连接上的网络操作总数(读或写)。 | kafka.[producer|consumer|connect]:type=[producer|consumer|connect]-metrics,client-id=([-.\w]+) |
| outgoing-byte-rate | 每秒钟向所有服务器发送的平均外发字节数。 | kafka.[producer|consumer|connect]:type=[producer|consumer|connect]-metrics,client-id=([-.\w]+) |
| outgoing-byte-total | 发送给所有服务器的总字节数。 | kafka.[producer|consumer|connect]:type=[producer|consumer|connect]-metrics,client-id=([-.\w]+) |
| request-rate | 平均每秒发出的请求数。 | kafka.[producer|consumer|connect]:type=[producer|consumer|connect]-metrics,client-id=([-.\w]+) |
| request-total | 发送的请求总数; | kafka.[producer|consumer|connect]:type=[producer|consumer|connect]-metrics,client-id=([-.\w]+) |
| request-size-avg | 窗口中所有请求的平均大小。 | kafka.[producer|consumer|connect]:type=[producer|consumer|connect]-metrics,client-id=([-.\w]+) |
| request-size-max | 窗口中发送的任何请求的最大尺寸。 | kafka.[producer|consumer|connect]:type=[producer|consumer|connect]-metrics,client-id=([-.\w]+) |
| incoming-byte-rate | 从所有socket上读取的字节/秒。 | kafka.[producer|consumer|connect]:type=[producer|consumer|connect]-metrics,client-id=([-.\w]+) |
| incoming-byte-total | 从所有套接字读取的总字节数。 | kafka.[producer|consumer|connect]:type=[producer|consumer|connect]-metrics,client-id=([-.\w]+) |
| response-rate | 每秒钟收到的答复。 | kafka.[producer|consumer|connect]:type=[producer|consumer|connect]-metrics,client-id=([-.\w]+) |
| response-total | 收到的答复总数 | kafka.[producer|consumer|connect]:type=[producer|consumer|connect]-metrics,client-id=([-.\w]+) |
| select-rate | I/O层每秒检查新I/O执行的次数。 | kafka.[producer|consumer|connect]:type=[producer|consumer|connect]-metrics,client-id=([-.\w]+) |
| select-total | I/O层检查新I/O执行的总次数。 | kafka.[producer|consumer|connect]:type=[producer|consumer|connect]-metrics,client-id=([-.\w]+) |
| io-wait-time-ns-avg | I/O线程等待一个准备好读或写的socket的平均时间,单位为纳秒。 | kafka.[producer|consumer|connect]:type=[producer|consumer|connect]-metrics,client-id=([-.\w]+) |
| io-wait-ratio | I/O线程等待的时间分数。 | kafka.[producer|consumer|connect]:type=[producer|consumer|connect]-metrics,client-id=([-.\w]+) |
| io-time-ns-avg | 每次选择调用的平均I/O时间长度,单位为纳秒。 | kafka.[producer|consumer|connect]:type=[producer|consumer|connect]-metrics,client-id=([-.\w]+) |
| io-ratio | I/O线程做I/O的时间分数。 | kafka.[producer|consumer|connect]:type=[producer|consumer|connect]-metrics,client-id=([-.\w]+) |
| connection-count | 当前的活动连接数。 | kafka.[producer|consumer|connect]:type=[producer|consumer|connect]-metrics,client-id=([-.\w]+) |
| successful-authentication-rate | 每秒钟使用SASL或SSL成功认证的连接。 | kafka.[producer|consumer|connect]:type=[producer|consumer|connect]-metrics,client-id=([-.\w]+) |
| successful-authentication-total | 使用SASL或SSL成功认证的连接总数。 | kafka.[producer|consumer|connect]:type=[producer|consumer|connect]-metrics,client-id=([-.\w]+) |
| failed-authentication-rate | 认证失败的每秒连接数。 | kafka.[producer|consumer|connect]:type=[producer|consumer|connect]-metrics,client-id=([-.\w]+) |
| failed-authentication-total | 未能通过认证的连接总数。 | kafka.[producer|consumer|connect]:type=[producer|consumer|connect]-metrics,client-id=([-.\w]+) |
| successful-reauthentication-rate | 每秒钟使用SASL成功重新认证的连接。 | kafka.[producer|consumer|connect]:type=[producer|consumer|connect]-metrics,client-id=([-.\w]+) |
| successful-reauthentication-total | 使用SASL成功重新认证的连接总数。 | kafka.[producer|consumer|connect]:type=[producer|consumer|connect]-metrics,client-id=([-.\w]+) |
| reauthentication-latency-max | 观察到的因重新认证而产生的最大延迟,单位为毫秒。 | kafka.[producer|consumer|connect]:type=[producer|consumer|connect]-metrics,client-id=([-.\w]+) |
| reauthentication-latency-avg | 观察到的平均延迟时间,以毫秒为单位,由于重新认证。 | kafka.[producer|consumer|connect]:type=[producer|consumer|connect]-metrics,client-id=([-.\w]+) |
| failed-reauthentication-rate | 重新认证失败的每秒连接数。 | kafka.[producer|consumer|connect]:type=[producer|consumer|connect]-metrics,client-id=([-.\w]+) |
| failed-reauthentication-total | 未能重新认证的连接总数。 | kafka.[producer|consumer|connect]:type=[producer|consumer|connect]-metrics,client-id=([-.\w]+) |
| successful-authentication-no-reauth-total | 不支持重新认证的2.2.0之前的旧版SASL客户端成功认证的连接总数。只能为非零 | kafka.[producer|consumer|connect]:type=[producer|consumer|connect]-metrics,client-id=([-.\w]+) |
每个broker的指标 生产者/消费者/连接/流
以下指标在生产者/消费者/连接者/流实例中可用。具体的指标,请看以下章节。
| 属性名称 | 描述 | MBEAN NAME |
|---|---|---|
| outgoing-byte-rate | 节点平均每秒发送的外发字节数。 | kafka.[producer|consumer|connect]:type=[consumer|producer|connect]-node-metrics,client-id=([-.\w]+),node-id=([0-9]+) |
| outgoing-byte-total | 一个节点发送出去的总字节数。 | kafka.[producer|consumer|connect]:type=[consumer|producer|connect]-node-metrics,client-id=([-.\w]+),node-id=([0-9]+) |
| request-rate | 一个节点平均每秒发送的请求数。 | kafka.[producer|consumer|connect]:type=[consumer|producer|connect]-node-metrics,client-id=([-.\w]+),node-id=([0-9]+) |
| request-total | 为一个节点发送的总请求数。 | kafka.[producer|consumer|connect]:type=[consumer|producer|connect]-node-metrics,client-id=([-.\w]+),node-id=([0-9]+) |
| request-size-avg | 一个节点的窗口中所有请求的平均大小。 | kafka.[producer|consumer|connect]:type=[consumer|producer|connect]-node-metrics,client-id=([-.\w]+),node-id=([0-9]+) |
| request-size-max | 一个节点在窗口中发送的任何请求的最大尺寸。 | kafka.[producer|consumer|connect]:type=[consumer|producer|connect]-node-metrics,client-id=([-.\w]+),node-id=([0-9]+) |
| incoming-byte-rate | 节点每秒收到的平均字节数。 | kafka.[producer|consumer|connect]:type=[consumer|producer|connect]-node-metrics,client-id=([-.\w]+),node-id=([0-9]+) |
| incoming-byte-total | 节点收到的总字节数。 | kafka.[producer|consumer|connect]:type=[consumer|producer|connect]-node-metrics,client-id=([-.\w]+),node-id=([0-9]+) |
| request-latency-avg | 节点的平均请求延迟,单位为ms。 | kafka.[producer|consumer|connect]:type=[consumer|producer|connect]-node-metrics,client-id=([-.\w]+),node-id=([0-9]+) |
| request-latency-max | 节点的最大请求延迟,单位为ms。 | kafka.[producer|consumer|connect]:type=[consumer|producer|connect]-node-metrics,client-id=([-.\w]+),node-id=([0-9]+) |
| response-rate | 节点每秒收到的响应。 | kafka.[producer|consumer|connect]:type=[consumer|producer|connect]-node-metrics,client-id=([-.\w]+),node-id=([0-9]+) |
| response-total | 一个节点收到的答复总数 | kafka.[producer|consumer|connect]:type=[consumer|producer|connect]-node-metrics,client-id=([-.\w]+),node-id=([0-9]+) |
生产者监测
生产者实例有以下指标。
| 属性名称 | 描述 | MBEAN NAME |
|---|---|---|
| waiting-threads | 等待缓冲区内存查询记录的用户线程阻塞的数量。 | kafka.producer:type=producer-metrics,client-id=([-.\w]+) |
| buffer-total-bytes | 客户端可以使用的最大缓冲区内存量(无论当前是否使用)。 | kafka.producer:type=producer-metrics,client-id=([-.\w]+) |
| buffer-available-bytes | 未被使用的缓冲区内存总量(未分配或在空闲列表中)。 | kafka.producer:type=producer-metrics,client-id=([-.\w]+) |
| bufferpool-wait-time | 应用者等待空间分配的时间分数。 | kafka.producer:type=producer-metrics,client-id=([-.\w]+) |
生产者sender线程指标
| kafka.producer:type=producer-metrics,client-id="{client-id}" | ||
| 属性名称 | 描述 | |
|---|---|---|
| batch-size-avg |
每个分区每次请求发送的平均字节数。 |
|
| batch-size-max |
每个分区每次请求发送的最大字节数。 |
|
| batch-split-rate |
每秒平均分批次数 |
|
| batch-split-total |
批次分割的总数量 |
|
| compression-rate-avg |
记录批次的平均压缩率,定义为压缩批次大小与未压缩大小的平均比率。 |
|
| metadata-age |
当前正在使用的生产者元数据的年龄,以秒为单位。 |
|
| produce-throttle-time-avg |
请求被broker节流的平均时间,以毫秒计 |
|
| produce-throttle-time-max | broker对请求进行节流的最大时间,以毫秒为单位。 | |
| record-error-rate |
平均每秒钟发送的导致错误的记录数量。 |
|
| record-error-total |
导致错误的记录发送总数。 |
|
| record-queue-time-avg |
以ms为单位的记录批次在发送缓冲区中花费的平均时间。 |
|
| record-queue-time-max |
记录批次在发送缓冲区中花费的最大时间,单位为ms。 |
|
| record-retry-rate |
平均每秒钟的重试记录发送次数。 |
|
| record-retry-total |
重试记录发送的总次数 |
|
| record-send-rate |
平均每秒发送的记录数。 |
|
| record-send-total |
发送的记录总数。 |
|
| record-size-avg | 平均记录大小 | |
| record-size-max |
最大记录大小 |
|
| records-per-request-avg |
每次请求的平均记录数量; |
|
| request-latency-avg |
平均请求延迟时间(ms) |
|
| request-latency-max |
最大请求延迟,单位为ms |
|
| requests-in-flight |
目前等待答复的飞行中请求的数量。 |
|
| kafka.producer:type=producer-topic-metrics,client-id="{client-id}",topic="{topic}" | ||
| 属性名称 | 描述 | |
| byte-rate |
一个主题平均每秒发送的字节数。 |
|
| byte-total |
一个主题的总发送字节数。 |
|
| compression-rate |
一个主题的记录批次的平均压缩率,定义为压缩后的批次大小与未压缩大小的平均比例。 |
|
| record-error-rate |
每秒钟平均发送记录的次数,导致一个主题出现错误。 |
|
| record-error-total |
导致一个主题出错的记录发送总数。 |
|
| record-retry-rate |
一个主题的平均每秒钟重试记录发送次数。 |
|
| record-retry-total |
一个主题的重试记录发送总数。 |
|
| record-send-rate |
一个主题平均每秒发送的记录数。 |
|
| record-send-total | 一个主题的总发送记录数。 | |
消费者监测
消费者实例有以下指标:
| 属性名称 | 描述 | MBEAN NAME |
|---|---|---|
| time-between-poll-avg | poll()调用之间的平均延迟。 | kafka.consumer:type=consumer-metrics,client-id=([-.\w]+) |
| time-between-poll-max | poll()调用之间的最大延迟。 | kafka.consumer:type=consumer-metrics,client-id=([-.\w]+) |
| last-poll-seconds-ago | 上次调用poll()后的秒数。 | kafka.consumer:type=consumer-metrics,client-id=([-.\w]+) |
| poll-idle-ratio-avg | 消费者的poll()相对于等待用户代码处理记录的平均空闲时间的分数。 | kafka.consumer:type=consumer-metrics,client-id=([-.\w]+) |
消费者组指标
| 属性名称 | 描述 | MBEAN NAME |
|---|---|---|
| commit-latency-avg | 提交请求的平均时间 | kafka.consumer:type=consumer-coordinator-metrics,client-id=([-.\w]+) |
| commit-latency-max | 提交请求所需的最大时间 | kafka.consumer:type=consumer-coordinator-metrics,client-id=([-.\w]+) |
| commit-rate | 每秒钟的提交次数 | kafka.consumer:type=consumer-coordinator-metrics,client-id=([-.\w]+) |
| commit-total | 提交总次数 | kafka.consumer:type=consumer-coordinator-metrics,client-id=([-.\w]+) |
| assigned-partitions | 当前分配给该消费者的分区数量。 | kafka.consumer:type=consumer-coordinator-metrics,client-id=([-.\w]+) |
| heartbeat-response-time-max | 接收心跳请求响应所需的最大时间。 | kafka.consumer:type=consumer-coordinator-metrics,client-id=([-.\w]+) |
| heartbeat-rate | 平均每秒心跳次数 | kafka.consumer:type=consumer-coordinator-metrics,client-id=([-.\w]+) |
| heartbeat-total | 心跳的总次数 | kafka.consumer:type=consumer-coordinator-metrics,client-id=([-.\w]+) |
| join-time-avg | 小组重新加入的平均时间 | kafka.consumer:type=consumer-coordinator-metrics,client-id=([-.\w]+) |
| join-time-max | 小组重新加入所需的最长时间 | kafka.consumer:type=consumer-coordinator-metrics,client-id=([-.\w]+) |
| join-rate | 每秒钟加入的组数 | kafka.consumer:type=consumer-coordinator-metrics,client-id=([-.\w]+) |
| join-total | 消费者组加盟的总机器数 | kafka.consumer:type=consumer-coordinator-metrics,client-id=([-.\w]+) |
| sync-time-avg | 组同步的平均时间 | kafka.consumer:type=consumer-coordinator-metrics,client-id=([-.\w]+) |
| sync-time-max | 组同步的最大时间 | kafka.consumer:type=consumer-coordinator-metrics,client-id=([-.\w]+) |
| sync-rate | 每秒钟的组同步次数 | kafka.consumer:type=consumer-coordinator-metrics,client-id=([-.\w]+) |
| sync-total | 群体同步的总次数 | kafka.consumer:type=consumer-coordinator-metrics,client-id=([-.\w]+) |
| rebalance-latency-avg | 组内重新平衡所需的平均时间。 | kafka.consumer:type=consumer-coordinator-metrics,client-id=([-.\w]+) |
| rebalance-latency-max | 组内重新平衡所需的最大时间。 | kafka.consumer:type=consumer-coordinator-metrics,client-id=([-.\w]+) |
| rebalance-latency-total | 迄今为止,消费者组重新平衡所需的总时间。 | kafka.consumer:type=consumer-coordinator-metrics,client-id=([-.\w]+) |
| rebalance-total | 消费者组再平衡总数 | kafka.consumer:type=consumer-coordinator-metrics,client-id=([-.\w]+) |
| rebalance-rate-per-hour | 每小时再平衡次数 | kafka.consumer:type=consumer-coordinator-metrics,client-id=([-.\w]+) |
| failed-rebalance-total | 失败的消费者组再平衡次数 | kafka.consumer:type=consumer-coordinator-metrics,client-id=([-.\w]+) |
| failed-rebalance-rate-per-hour | 每小时失败的再平衡总数 | kafka.consumer:type=consumer-coordinator-metrics,client-id=([-.\w]+) |
| last-rebalance-seconds-ago | 最后一次发生再平衡过去的时间 秒数 | kafka.consumer:type=consumer-coordinator-metrics,client-id=([-.\w]+) |
| last-heartbeat-seconds-ago | 最后一次收到控制器的心跳信号过去的时间 秒数 | kafka.consumer:type=consumer-coordinator-metrics,client-id=([-.\w]+) |
| partitions-revoked-latency-avg | 由on-partitions-revoked rebalance监听器回调的平均时间。 | kafka.consumer:type=consumer-coordinator-metrics,client-id=([-.\w]+) |
| partitions-revoked-latency-max | 由on-partitions-revoked rebalance监听器回调的最大时间。 | kafka.consumer:type=consumer-coordinator-metrics,client-id=([-.\w]+) |
| partitions-assigned-latency-avg | 分区分配的重新平衡监听器回调所需的平均时间。 | kafka.consumer:type=consumer-coordinator-metrics,client-id=([-.\w]+) |
| partitions-assigned-latency-max | 分区分配的重新平衡监听器回调所需的最大时间。 | kafka.consumer:type=consumer-coordinator-metrics,client-id=([-.\w]+) |
| partitions-lost-latency-avg | 分区丢失的重新平衡监听器回调的平均时间。 | kafka.consumer:type=consumer-coordinator-metrics,client-id=([-.\w]+) |
| partitions-lost-latency-max | on-partitions-lost rebalance监听器回调的最大时间。 | kafka.consumer:type=consumer-coordinator-metrics,client-id=([-.\w]+) |
消费者拉取性能
| kafka.consumer:type=consumer-fetch-manager-metrics,client-id="{client-id}" | ||
| 属性名称 | 描述 | |
|---|---|---|
| bytes-consumed-rate |
每秒钟消耗的平均字节数。 |
|
| bytes-consumed-total |
消耗的总字节数 |
|
| fetch-latency-avg | 拉取一个请求的平均时间 | |
| fetch-latency-max | 拉取一个请求最大时间 | |
| fetch-rate | 每秒钟拉取的请求的数量 | |
| fetch-size-avg | 每秒钟拉取的请求的平均大小 字节数 | |
| fetch-size-max |
每次请求获取的最大字节数。 |
|
| fetch-throttle-time-avg |
平均节流时间(毫秒) |
|
| fetch-throttle-time-max |
最大节流时间(ms) |
|
| fetch-total |
获取请求的总次数。 |
|
| records-consumed-rate |
每秒钟消耗的平均记录数 |
|
| records-consumed-total |
消耗的记录总数 |
|
| records-lag-max |
该窗口中任何分区的记录数的最大滞后量。 |
|
| records-lead-min |
该窗口中任何分区的记录数的最小前导值。 |
|
| records-per-request-avg |
每次请求的平均记录数量 |
|
| kafka.consumer:type=consumer-fetch-manager-metrics,client-id="{client-id}",topic="{topic}" | ||
| 属性名称 | 描述 | |
| bytes-consumed-rate |
一个主题每秒消耗的平均字节数。 |
|
| bytes-consumed-total |
一个主题消耗的总字节数。 |
|
| fetch-size-avg |
一个主题每次请求所获取的平均字节数。 |
|
| fetch-size-max |
一个主题每次请求获取的最大字节数。 |
|
| records-consumed-rate |
某一主题每秒消耗的平均记录数。 |
|
| records-consumed-total |
某一主题所消耗的记录总数。 |
|
| records-per-request-avg |
每项请求的平均记录数。 |
|
| kafka.consumer:type=consumer-fetch-manager-metrics,partition="{partition}",topic="{topic}",client-id="{client-id}" | ||
| 属性名称 | 描述 | |
| preferred-read-replica |
分区的当前读取副本,如果从领导读取,则为-1。 |
|
| records-lag |
分区的最新滞后时间 |
|
| records-lag-avg |
分区的平均滞后时间 |
|
| records-lag-max | 分区的最大滞后时间 | |
| records-lead | 分区的领先程度 | |
| records-lead-avg | 分区的平均领先幅度 | |
| records-lead-min | 分割的最小领先幅度 | |
连接监测
一个Connect worker流程包含所有生产者和消费者的度量,以及Connect特有的度量。Worker进程本身有许多指标,而每个连接器和任务都有额外的指标。
[2020-12-04 10:03:05,630] INFO Metrics scheduler closed (org.apache.kafka.common.metrics.Metrics:668)
[2020-12-04 10:03:05,632] INFO Metrics reporters closed (org.apache.kafka.common.metrics.Metrics:678)
| kafka.connect:type=connect-worker-metrics | ||
| 属性名称 | 描述 | |
|---|---|---|
| connector-count |
该worker中运行的连接器数量。 |
|
| connector-startup-attempts-total |
该worker尝试过的连接器启动总数。 |
|
| connector-startup-failure-percentage |
这个worker的连接器启动失败的平均比例。 |
|
| connector-startup-failure-total |
失败的连接器启动总数。 |
|
| connector-startup-success-percentage |
这个worker的连接器启动成功的平均百分比。 |
|
| connector-startup-success-total |
成功的连接器启动总数。 |
|
| task-count |
该worker运行的任务数量。 |
|
| task-startup-attempts-total |
该worker尝试过的任务启动总数。 |
|
| task-startup-failure-percentage |
这个worker的任务启动失败的平均百分比。 |
|
| task-startup-failure-total |
任务启动失败的总次数。 |
|
| task-startup-success-percentage |
这个worker的任务开始成功的平均百分比。 |
|
| task-startup-success-total |
成功的任务启动总数。 |
|
| kafka.connect:type=connect-worker-metrics,connector="{connector}" | ||
| 属性名称 | 描述 | |
| connector-destroyed-task-count |
worker身上连接器的销毁任务数量。 |
|
| connector-failed-task-count |
worker身上的连接器的失败任务数。 |
|
| connector-paused-task-count |
worker上连接器的暂停任务数。 |
|
| connector-running-task-count |
worker上连接器的运行任务数。 |
|
| connector-total-task-count |
worker上的连接器的任务数量。 |
|
| connector-unassigned-task-count |
worker上的连接器的未分配任务数。 |
|
| kafka.connect:type=connect-worker-rebalance-metrics | ||
| 属性名称 | 描述 | |
| completed-rebalances-total |
worker完成的再平衡总数。 |
|
| connect-protocol |
该集群使用的Connect协议 |
|
| epoch |
worker的时代或代数。 |
|
| leader-name |
组leader的名字。 |
|
| rebalance-avg-time-ms |
worker重新平衡所花费的平均时间(毫秒)。 |
|
| rebalance-max-time-ms |
worker重新平衡所花费的最大时间(毫秒)。 |
|
| rebalancing |
worker目前是否在重新平衡。 |
|
| time-since-last-rebalance-ms |
worker完成最近一次重新平衡后的时间,以毫秒为单位。 |
|
| kafka.connect:type=connector-metrics,connector="{connector}" | ||
| 属性名称 | 描述 | |
| connector-class |
连接器类的名称。 |
|
| connector-type |
连接器的类型。"source "或 "sink "之一。 |
|
| connector-version |
连接器类的版本,由连接器报告。 |
|
| status |
连接器的状态。"未分配"、"运行"、"暂停"、"失败 "或 "销毁 "中的一种。 |
|
| kafka.connect:type=connector-task-metrics,connector="{connector}",task="{task}" | ||
| 属性名称 | 描述 | |
| batch-size-avg |
连接器处理的平均批次大小。 |
|
| batch-size-max |
连接器处理的最大批次大小。 |
|
| offset-commit-avg-time-ms |
该任务提交偏移量所需的平均时间(毫秒)。 |
|
| offset-commit-failure-percentage |
该任务的偏移提交尝试失败的平均百分比。 |
|
| offset-commit-max-time-ms |
该任务提交偏移量所需的最大时间(毫秒)。 |
|
| offset-commit-success-percentage |
该任务的偏移提交尝试成功的平均百分比。 |
|
| pause-ratio |
该任务在暂停状态下所花费的时间分数。 |
|
| running-ratio |
该任务在运行状态下所花费的时间分数。 |
|
| status |
连接器任务的状态。未分配"、"运行"、"暂停"、"失败 "或 "销毁 "中的一种。 |
|
| kafka.connect:type=sink-task-metrics,connector="{connector}",task="{task}" | ||
| 属性名称 | 描述 | |
| offset-commit-completion-rate |
平均每秒钟成功完成的偏移提交次数。 |
|
| offset-commit-completion-total |
成功完成的偏移提交总数。 |
|
| offset-commit-seq-no |
当前偏移提交的序列号。 |
|
| offset-commit-skip-rate |
平均每秒钟收到的太晚和跳过/忽略的偏移提交完成数。 |
|
| offset-commit-skip-total |
太晚收到的和跳过/忽略的偏移提交完成总数。 |
|
| partition-count |
分配给该任务的主题分区的数量,属于该worker中命名的sink连接器。 |
|
| put-batch-avg-time-ms |
这个任务把一批汇记录的平均时间。 |
|
| put-batch-max-time-ms |
这个任务放一批汇记录所需的最大时间。 |
|
| sink-record-active-count |
已从Kafka读取但尚未完全提交/刷新/被sink任务认可的记录数量。 |
|
| sink-record-active-count-avg |
已从Kafka读取但尚未完全提交/刷新/被sink任务认可的记录的平均数量。 |
|
| sink-record-active-count-max |
从Kafka读取但尚未完全提交/刷新/被sink任务认可的记录的最大数量。 |
|
| sink-record-lag-max |
对于任何主题分区而言,汇任务落后于消费者位置的记录数的最大滞后。 |
|
| sink-record-read-rate |
此任务从 Kafka 读取的平均每秒记录数,属于此 worker 中命名的 sink 连接器。这是在应用转换之前。 |
|
| sink-record-read-total |
自该任务上次重启以来,该任务从Kafka读取的属于该worker中命名的sink连接器的记录总数。 |
|
| sink-record-send-rate |
从转换中输出并发送到该任务的记录的平均每秒数量,这些记录属于该工作者中指定的sink。这是在应用了转换之后的数据,不包括任何被转换过滤掉的记录。 |
|
| sink-record-send-total |
自任务最后一次重启以来,从变换中输出并发送给该任务的属于该worker中命名的sink连接器的记录总数。 |
|
| kafka.connect:type=source-task-metrics,connector="{connector}",task="{task}" | ||
| 属性名称 | 描述 | |
| poll-batch-avg-time-ms |
该任务轮询一批源记录所需的平均时间(毫秒)。 |
|
| poll-batch-max-time-ms |
该任务轮询一批源记录所需的最大时间(毫秒)。 |
|
| source-record-active-count |
这个任务已经产生但还没有完全写入Kafka的记录数量。 |
|
| source-record-active-count-avg |
该任务已产生但尚未完全写入Kafka的平均记录数。 |
|
| source-record-active-count-max |
该任务已产生但尚未完全写入Kafka的最大记录数。 |
|
| source-record-poll-rate |
此任务在此工作者中属于命名的源连接器的平均每秒钟产生/轮询(转换前)的记录数。 |
|
| source-record-poll-total |
该任务产生/轮询的记录总数(转换前),属于该工作者中的指定源连接器。 |
|
| source-record-write-rate |
从转换中输出并写入 Kafka 的记录的平均每秒记录数,该任务属于该 Worker 中的命名源连接器。这是在应用了转换之后的数据,不包括任何被转换过滤掉的记录。 |
|
| source-record-write-total |
自任务最后一次重启以来,该任务从变换中输出并写入Kafka的记录数量,这些记录属于该worker中命名的源连接器。 |
|
| kafka.connect:type=task-error-metrics,connector="{connector}",task="{task}" | ||
| 属性名称 | 描述 | |
| deadletterqueue-produce-failures |
向挂掉队列写入失败的次数。 |
|
| deadletterqueue-produce-requests |
试图写入挂掉的队列的次数。 |
|
| last-error-timestamp |
该任务最后一次遇到错误时的时间戳。 |
|
| total-errors-logged |
记录的错误数量。 |
|
| total-record-errors |
本任务中记录处理错误的次数。 |
|
| total-record-failures |
该任务中记录处理失败的次数。 |
|
| total-records-skipped |
由于错误而跳过的记录数量。 |
|
| total-retries | 重试的操作次数。 | |
流监测
一个Kafka Streams实例包含所有的生产者和消费者指标,以及Streams特有的附加指标。默认情况下,Kafka Streams的度量有两个记录级别:debug和info。
需要注意的是,度量有一个4层的层次结构。在顶层,有每个启动的Kafka Streams客户端的客户端级指标。每个客户端都有流线程,有自己的度量。每个流线程有任务,有自己的指标。每个任务有若干个处理器节点,有自己的指标。每个任务也有许多状态存储和记录缓存,都有自己的度量。
使用下面的配置选项来指定你要收集哪些度量。
metrics.recording.level="info"
客户端指标
以下所有的指标都有一个记录级别的信息。
| 属性名称 | 描述 | MBEAN NAME |
|---|---|---|
| version | Kafka Streams客户端的版本。 | kafka.streams:type=stream-metrics,client-id=([-.\w]+) |
| commit-id | Kafka Streams客户端的版本控制提交ID。 | kafka.streams:type=stream-metrics,client-id=([-.\w]+) |
| application-id | Kafka Streams客户端的应用ID。 | kafka.streams:type=stream-metrics,client-id=([-.\w]+) |
| topology-description | Kafka Streams客户端中执行的拓扑的描述。 | kafka.streams:type=stream-metrics,client-id=([-.\w]+) |
| state | Kafka Streams客户端的状态。 | kafka.streams:type=stream-metrics,client-id=([-.\w]+) |
线程指标
以下所有的指标都有一个记录级别的信息。
| 指标名称 | 描述 | MBEAN NAME |
|---|---|---|
| commit-latency-avg | 该线程所有运行任务的平均执行时间,以毫秒为单位。 | kafka.streams:type=stream-thread-metrics,thread-id=([-.\w]+) |
| commit-latency-max | 该线程所有正在运行的任务中,提交的最大执行时间,单位为ms。 | kafka.streams:type=stream-thread-metrics,thread-id=([-.\w]+) |
| poll-latency-avg | 平均执行时间,单位为毫秒,用于消费者投票。 | kafka.streams:type=stream-thread-metrics,thread-id=([-.\w]+) |
| poll-latency-max | 最大执行时间,以ms为单位,用于消费者轮询。 | kafka.streams:type=stream-thread-metrics,thread-id=([-.\w]+) |
| process-latency-avg | 平均执行时间,以毫秒为单位,进行处理。 | kafka.streams:type=stream-thread-metrics,thread-id=([-.\w]+) |
| process-latency-max | 最大执行时间,单位为ms,进行处理。 | kafka.streams:type=stream-thread-metrics,thread-id=([-.\w]+) |
| punctuate-latency-avg | 平均执行时间,单位为毫秒,用于标点符号。 | kafka.streams:type=stream-thread-metrics,thread-id=([-.\w]+) |
| punctuate-latency-max | 标点符号的最大执行时间,单位为ms。 | kafka.streams:type=stream-thread-metrics,thread-id=([-.\w]+) |
| commit-rate | 平均每秒提交的次数。 | kafka.streams:type=stream-thread-metrics,thread-id=([-.\w]+) |
| commit-total | 提交的总次数。 | kafka.streams:type=stream-thread-metrics,thread-id=([-.\w]+) |
| poll-rate | 平均每秒钟的消费者poll调用数量。 | kafka.streams:type=stream-thread-metrics,thread-id=([-.\w]+) |
| poll-total | 消费者poll调用的总数量。 | kafka.streams:type=stream-thread-metrics,thread-id=([-.\w]+) |
| process-rate | 平均每秒处理的记录数。 | kafka.streams:type=stream-thread-metrics,thread-id=([-.\w]+) |
| process-total | 处理的记录总数。 | kafka.streams:type=stream-thread-metrics,thread-id=([-.\w]+) |
| punctuate-rate | 平均每秒钟的标点符号调用次数。 | kafka.streams:type=stream-thread-metrics,thread-id=([-.\w]+) |
| punctuate-total | 标点符号调用的总次数。 | kafka.streams:type=stream-thread-metrics,thread-id=([-.\w]+) |
| task-created-rate | 平均每秒创建的任务数。 | kafka.streams:type=stream-thread-metrics,thread-id=([-.\w]+) |
| task-created-total | 创建的任务总数。 | kafka.streams:type=stream-thread-metrics,thread-id=([-.\w]+) |
| task-closed-rate | 平均每秒关闭的任务数。 | kafka.streams:type=stream-thread-metrics,thread-id=([-.\w]+) |
| task-closed-total | 结束的任务总数。 | kafka.streams:type=stream-thread-metrics,thread-id=([-.\w]+) |
任务指标
除了drop-records-rate和drop-records-total这两个指标的记录级别为info之外,以下所有指标的记录级别为debug。
| 指标名称 | 描述 | MBEAN NAME |
|---|---|---|
| process-latency-avg | 平均执行时间以ns为单位,进行处理。 | kafka.streams:type=stream-task-metrics,thread-id=([-.\w]+),task-id=([-.\w]+) |
| process-latency-max | 处理的最大执行时间,以ns为单位。 | kafka.streams:type=stream-task-metrics,thread-id=([-.\w]+),task-id=([-.\w]+) |
| process-rate | 该任务的所有源处理器节点每秒处理的平均记录数。 | kafka.streams:type=stream-task-metrics,thread-id=([-.\w]+),task-id=([-.\w]+) |
| process-total | 该任务的所有源处理器节点的处理记录总数。 | kafka.streams:type=stream-task-metrics,thread-id=([-.\w]+),task-id=([-.\w]+) |
| commit-latency-avg | 提交的平均执行时间,以ns为单位。 | kafka.streams:type=stream-task-metrics,thread-id=([-.\w]+),task-id=([-.\w]+) |
| commit-latency-max | 提交的最大执行时间,单位为ns。 | kafka.streams:type=stream-task-metrics,thread-id=([-.\w]+),task-id=([-.\w]+) |
| commit-rate | 平均每秒的提交调用次数。 | kafka.streams:type=stream-task-metrics,thread-id=([-.\w]+),task-id=([-.\w]+) |
| commit-total | 提交commit的总次数。 | kafka.streams:type=stream-task-metrics,thread-id=([-.\w]+),task-id=([-.\w]+) |
| record-lateness-avg | 记录的平均观察延迟时间(流时间-记录时间戳)。 | kafka.streams:type=stream-task-metrics,thread-id=([-.\w]+),task-id=([-.\w]+) |
| record-lateness-max | 观察到的最大记录延迟(流时间-记录时间戳)。 | kafka.streams:type=stream-task-metrics,thread-id=([-.\w]+),task-id=([-.\w]+) |
| enforced-processing-rate | 平均每秒的强制处理次数。 | kafka.streams:type=stream-task-metrics,thread-id=([-.\w]+),task-id=([-.\w]+) |
| enforced-processing-total | 强制处理的总数。 | kafka.streams:type=stream-task-metrics,thread-id=([-.\w]+),task-id=([-.\w]+) |
| dropped-records-rate | 本任务内平均掉落的记录数。 | kafka.streams:type=stream-task-metrics,thread-id=([-.\w]+),task-id=([-.\w]+) |
| dropped-records-total | 本任务中放弃的记录总数。 | kafka.streams:type=stream-task-metrics,thread-id=([-.\w]+),task-id=([-.\w]+) |
节点指标处理器
以下指标仅在某些类型的节点上可用,即进程-速率和进程-总数仅在源处理器节点上可用,压制-发射-速率和压制-发射-总数仅在压制操作节点上可用。所有的指标都有一个记录级别的调试。
| 指标名称 | 描述 | MBEAN NAME |
|---|---|---|
| process-rate | 源处理器节点平均每秒处理的记录数。 | kafka.streams:type=stream-processor-node-metrics,thread-id=([-.\w]+),task-id=([-.\w]+),processor-node-id=([-.\w]+) |
| process-total | 源处理器节点每秒处理的记录总数。 | kafka.streams:type=stream-processor-node-metrics,thread-id=([-.\w]+),task-id=([-.\w]+),processor-node-id=([-.\w]+) |
| suppression-emit-rate | 从抑制操作节点下游发出的记录的速度。 | kafka.streams:type=stream-processor-node-metrics,thread-id=([-.\w]+),task-id=([-.\w]+),processor-node-id=([-.\w]+) |
| suppression-emit-total | 从抑制操作节点下游发出的记录总数。 | kafka.streams:type=stream-processor-node-metrics,thread-id=([-.\w]+),task-id=([-.\w]+),processor-node-id=([-.\w]+) |
状态存储指标
以下所有指标的记录级别均为debug。需要注意的是,对于用户自定义的状态存储,存储范围值在StoreSupplier#metricsScope()中指定;对于内置的状态存储,目前我们有。
- in-memory-state
- in-memory-lru-state
- in-memory-window-state
- in-memory-suppression (for suppression buffers)
- rocksdb-state (for RocksDB backed key-value store)
- rocksdb-window-state (for RocksDB backed window store)
- rocksdb-session-state (for RocksDB backed session store)
压制缓冲区大小-平均值、压制缓冲区大小-最大值、压制缓冲区计数-平均值和压制缓冲区计数-最大值等指标只适用于压制缓冲区。所有其他指标都不适用于压制缓冲区。
| 指标名称 | 描述 | MBEAN NAME |
|---|---|---|
| put-latency-avg | 平均执行时间(ns)。 | kafka.streams:type=stream-state-metrics,thread-id=([-.\w]+),task-id=([-.\w]+),[store-scope]-id=([-.\w]+) |
| put-latency-max | 最大执行时间(ns)。 | kafka.streams:type=stream-state-metrics,thread-id=([-.\w]+),task-id=([-.\w]+),[store-scope]-id=([-.\w]+) |
| put-if-absent-latency-avg | 平均put-if-absent执行时间,单位为ns。 | kafka.streams:type=stream-state-metrics,thread-id=([-.\w]+),task-id=([-.\w]+),[store-scope]-id=([-.\w]+) |
| put-if-absent-latency-max | 最大的put-if-absent执行时间,单位为ns。 | kafka.streams:type=stream-state-metrics,thread-id=([-.\w]+),task-id=([-.\w]+),[store-scope]-id=([-.\w]+) |
| get-latency-avg | 平均获取执行时间,单位为ns。 | kafka.streams:type=stream-state-metrics,thread-id=([-.\w]+),task-id=([-.\w]+),[store-scope]-id=([-.\w]+) |
| get-latency-max | 最大获取执行时间,单位为ns。 | kafka.streams:type=stream-state-metrics,thread-id=([-.\w]+),task-id=([-.\w]+),[store-scope]-id=([-.\w]+) |
| delete-latency-avg | 平均删除执行时间(ns)。 | kafka.streams:type=stream-state-metrics,thread-id=([-.\w]+),task-id=([-.\w]+),[store-scope]-id=([-.\w]+) |
| delete-latency-max | 最大删除执行时间(ns)。 | kafka.streams:type=stream-state-metrics,thread-id=([-.\w]+),task-id=([-.\w]+),[store-scope]-id=([-.\w]+) |
| put-all-latency-avg | 平均put-all执行时间,单位为ns。 | kafka.streams:type=stream-state-metrics,thread-id=([-.\w]+),task-id=([-.\w]+),[store-scope]-id=([-.\w]+) |
| put-all-latency-max | 最大put-all执行时间,单位为ns。 | kafka.streams:type=stream-state-metrics,thread-id=([-.\w]+),task-id=([-.\w]+),[store-scope]-id=([-.\w]+) |
| all-latency-avg | 所有操作的平均执行时间(ns)。 | kafka.streams:type=stream-state-metrics,thread-id=([-.\w]+),task-id=([-.\w]+),[store-scope]-id=([-.\w]+) |
| all-latency-max | 所有操作的最大执行时间,单位为ns。 | kafka.streams:type=stream-state-metrics,thread-id=([-.\w]+),task-id=([-.\w]+),[store-scope]-id=([-.\w]+) |
| range-latency-avg | 平均范围执行时间(ns)。 | kafka.streams:type=stream-state-metrics,thread-id=([-.\w]+),task-id=([-.\w]+),[store-scope]-id=([-.\w]+) |
| range-latency-max | 最大范围执行时间,单位为ns。 | kafka.streams:type=stream-state-metrics,thread-id=([-.\w]+),task-id=([-.\w]+),[store-scope]-id=([-.\w]+) |
| flush-latency-avg | 平均刷新执行时间(ns)。 | kafka.streams:type=stream-state-metrics,thread-id=([-.\w]+),task-id=([-.\w]+),[store-scope]-id=([-.\w]+) |
| flush-latency-max | 最大刷新执行时间,单位为ns。 | kafka.streams:type=stream-state-metrics,thread-id=([-.\w]+),task-id=([-.\w]+),[store-scope]-id=([-.\w]+) |
| restore-latency-avg | 平均还原执行时间(ns)。 | kafka.streams:type=stream-state-metrics,thread-id=([-.\w]+),task-id=([-.\w]+),[store-scope]-id=([-.\w]+) |
| restore-latency-max | 最大还原执行时间,单位为ns。 | kafka.streams:type=stream-state-metrics,thread-id=([-.\w]+),task-id=([-.\w]+),[store-scope]-id=([-.\w]+) |
| put-rate | 这个存储的平均投放率。 | kafka.streams:type=stream-state-metrics,thread-id=([-.\w]+),task-id=([-.\w]+),[store-scope]-id=([-.\w]+) |
| put-if-absent-rate | 这个存储的平均放如果率。 | kafka.streams:type=stream-state-metrics,thread-id=([-.\w]+),task-id=([-.\w]+),[store-scope]-id=([-.\w]+) |
| get-rate | 这个存储的平均获取速率。 | kafka.streams:type=stream-state-metrics,thread-id=([-.\w]+),task-id=([-.\w]+),[store-scope]-id=([-.\w]+) |
| delete-rate | 这个存储的平均删除速率。 | kafka.streams:type=stream-state-metrics,thread-id=([-.\w]+),task-id=([-.\w]+),[store-scope]-id=([-.\w]+) |
| put-all-rate | 这个存储的平均put-all速率。 | kafka.streams:type=stream-state-metrics,thread-id=([-.\w]+),task-id=([-.\w]+),[store-scope]-id=([-.\w]+) |
| all-rate | 这个存储的所有操作的平均速率。 | kafka.streams:type=stream-state-metrics,thread-id=([-.\w]+),task-id=([-.\w]+),[store-scope]-id=([-.\w]+) |
| range-rate | 该存储的平均范围速率。 | kafka.streams:type=stream-state-metrics,thread-id=([-.\w]+),task-id=([-.\w]+),[store-scope]-id=([-.\w]+) |
| flush-rate | 这个存储的平均冲洗率。 | kafka.streams:type=stream-state-metrics,thread-id=([-.\w]+),task-id=([-.\w]+),[store-scope]-id=([-.\w]+) |
| restore-rate | 这个存储的平均还原率。 | kafka.streams:type=stream-state-metrics,thread-id=([-.\w]+),task-id=([-.\w]+),[store-scope]-id=([-.\w]+) |
| suppression-buffer-size-avg | 采样窗口中缓冲数据的平均总大小,以字节为单位。 | kafka.streams:type=stream-state-metrics,thread-id=([-.\w]+),task-id=([-.\w]+),in-memory-suppression-id=([-.\w]+) |
| suppression-buffer-size-max | 采样窗口中缓冲数据的最大总大小,以字节为单位。 | kafka.streams:type=stream-state-metrics,thread-id=([-.\w]+),task-id=([-.\w]+),in-memory-suppression-id=([-.\w]+) |
| suppression-buffer-count-avg | 采样窗口中缓冲的平均记录数。 | kafka.streams:type=stream-state-metrics,thread-id=([-.\w]+),task-id=([-.\w]+),in-memory-suppression-id=([-.\w]+) |
| suppression-buffer-count-max | 采样窗口中缓冲的最大记录数。 | kafka.streams:type=stream-state-metrics,thread-id=([-.\w]+),task-id=([-.\w]+),in-memory-suppression-id=([-.\w]+) |
RocksDB指标
RocksDB的度量分为基于统计的度量和基于属性的度量。前者记录的是RocksDB状态存储收集的统计数据,而后者记录的是RocksDB公开的属性。RocksDB收集的统计数据提供了一段时间内的累积测量值,例如写入状态存储的字节数。RocksDB暴露的属性提供了当前的测量值,例如,当前使用的内存量。请注意,目前内置的RocksDB状态存储的存储范围如下。
- rocksdb-state (for RocksDB backed key-value store)
- rocksdb-window-state (for RocksDB backed window store)
- rocksdb-session-state (for RocksDB backed session store)
基于RocksDB统计的指标。以下所有基于统计的指标都有一个记录级别的调试,因为在RocksDB中收集统计数据可能会对性能产生影响。基于统计的指标每分钟都会从RocksDB状态存储中收集。如果一个状态存储由多个RocksDB实例组成,就像随着时间和会话窗口的聚合一样,每个度量都会报告状态存储的RocksDB实例的聚合情况。
| 指标名称 | 描述 | MBEAN NAME |
|---|---|---|
| bytes-written-rate | 平均每秒写入RocksDB状态存储的字节数。 | kafka.streams:type=stream-state-metrics,thread-id=([-.\w]+),task-id=([-.\w]+),[store-scope]-id=([-.\w]+) |
| bytes-written-total | 写入RocksDB状态存储的总字节数。 | kafka.streams:type=stream-state-metrics,thread-id=([-.\w]+),task-id=([-.\w]+),[store-scope]-id=([-.\w]+) |
| bytes-read-rate | 平均每秒从RocksDB状态存储中读取的字节数。 | kafka.streams:type=stream-state-metrics,thread-id=([-.\w]+),task-id=([-.\w]+),[store-scope]-id=([-.\w]+) |
| bytes-read-total | 从RocksDB状态存储中读取的总字节数。 | kafka.streams:type=stream-state-metrics,thread-id=([-.\w]+),task-id=([-.\w]+),[store-scope]-id=([-.\w]+) |
| memtable-bytes-flushed-rate | 平均每秒从内存表到磁盘上刷新的字节数。 | kafka.streams:type=stream-state-metrics,thread-id=([-.\w]+),task-id=([-.\w]+),[store-scope]-id=([-.\w]+) |
| memtable-bytes-flushed-total | 从memtable刷新到磁盘的总字节数。 | kafka.streams:type=stream-state-metrics,thread-id=([-.\w]+),task-id=([-.\w]+),[store-scope]-id=([-.\w]+) |
| memtable-hit-ratio | 相对于所有查找到的memtable来说,memtable的点击率。 | kafka.streams:type=stream-state-metrics,thread-id=([-.\w]+),task-id=([-.\w]+),[store-scope]-id=([-.\w]+) |
| block-cache-data-hit-ratio | 数据块的块缓存点击率相对于数据块的所有查找到块缓存的比率。 | kafka.streams:type=stream-state-metrics,thread-id=([-.\w]+),task-id=([-.\w]+),[store-scope]-id=([-.\w]+) |
| block-cache-index-hit-ratio | 索引块的块缓存点击率相对于索引块的所有查找到块缓存的比率。 | kafka.streams:type=stream-state-metrics,thread-id=([-.\w]+),task-id=([-.\w]+),[store-scope]-id=([-.\w]+) |
| block-cache-filter-hit-ratio | 过滤器块的块缓存点击率相对于过滤器块的所有查找到块缓存的比率。 | kafka.streams:type=stream-state-metrics,thread-id=([-.\w]+),task-id=([-.\w]+),[store-scope]-id=([-.\w]+) |
| write-stall-duration-avg | 写入停顿的平均持续时间(毫秒)。 | kafka.streams:type=stream-state-metrics,thread-id=([-.\w]+),task-id=([-.\w]+),[store-scope]-id=([-.\w]+) |
| write-stall-duration-total | 写入停顿的总时间,单位为ms。 | kafka.streams:type=stream-state-metrics,thread-id=([-.\w]+),task-id=([-.\w]+),[store-scope]-id=([-.\w]+) |
| bytes-read-compaction-rate | 压实过程中平均每秒读取的字节数。 | kafka.streams:type=stream-state-metrics,thread-id=([-.\w]+),task-id=([-.\w]+),[store-scope]-id=([-.\w]+) |
| bytes-written-compaction-rate | 压实过程中平均每秒写入的字节数。 | kafka.streams:type=stream-state-metrics,thread-id=([-.\w]+),task-id=([-.\w]+),[store-scope]-id=([-.\w]+) |
| number-open-files | 当前打开的文件数量。 | kafka.streams:type=stream-state-metrics,thread-id=([-.\w]+),task-id=([-.\w]+),[store-scope]-id=([-.\w]+) |
| number-file-errors-total | 文件错误发生的总次数。 | kafka.streams:type=stream-state-metrics,thread-id=([-.\w]+),task-id=([-.\w]+),[store-scope]-id=([-.\w]+) |
RocksDB基于属性的度量:以下所有基于属性的度量都有记录级别的信息,并在度量被访问时被记录。如果一个状态存储由多个RocksDB实例组成,就像随着时间和会话窗口的聚合一样,每个度量都会报告该状态存储的所有RocksDB实例的总和,除了块缓存度量block-cache-*。如果每个实例都使用自己的块缓存,则块缓存度量报告所有RocksDB实例的总和,如果所有实例共享一个块缓存,则只报告一个实例的记录值。
| 指标名称 | 描述 | MBEAN NAME |
|---|---|---|
| num-immutable-mem-table | 还没有刷新的不可更改的记忆表的数量。 | kafka.streams:type=stream-state-metrics,thread-id=([-.\w]+),task-id=([-.\w]+),[store-scope]-id=([-.\w]+) |
| cur-size-active-mem-table | 活动内存表的大概大小,以字节为单位。 | kafka.streams:type=stream-state-metrics,thread-id=([-.\w]+),task-id=([-.\w]+),[store-scope]-id=([-.\w]+) |
| cur-size-all-mem-tables | 活动的和未刷新的不可更改的内存表的大致大小,以字节为单位。 | kafka.streams:type=stream-state-metrics,thread-id=([-.\w]+),task-id=([-.\w]+),[store-scope]-id=([-.\w]+) |
| size-all-mem-tables | 活动的、未刷新的不可变的和钉住的不可变的memtables的大概大小,单位是字节。 | kafka.streams:type=stream-state-metrics,thread-id=([-.\w]+),task-id=([-.\w]+),[store-scope]-id=([-.\w]+) |
| num-entries-active-mem-table | 活动记忆表中的条目数。 | kafka.streams:type=stream-state-metrics,thread-id=([-.\w]+),task-id=([-.\w]+),[store-scope]-id=([-.\w]+) |
| num-entries-imm-mem-tables | 未刷新的不可更改记忆表的条目数。 | kafka.streams:type=stream-state-metrics,thread-id=([-.\w]+),task-id=([-.\w]+),[store-scope]-id=([-.\w]+) |
| num-deletes-active-mem-table | 活动记忆表的删除条数。 | kafka.streams:type=stream-state-metrics,thread-id=([-.\w]+),task-id=([-.\w]+),[store-scope]-id=([-.\w]+) |
| num-deletes-imm-mem-tables | 未刷新的不可更改记忆表的删除条目数。 | kafka.streams:type=stream-state-metrics,thread-id=([-.\w]+),task-id=([-.\w]+),[store-scope]-id=([-.\w]+) |
| mem-table-flush-pending | 如果记忆表刷新待定,该指标报告1,否则报告0。 | kafka.streams:type=stream-state-metrics,thread-id=([-.\w]+),task-id=([-.\w]+),[store-scope]-id=([-.\w]+) |
| num-running-flushes | 当前正在运行的冲洗总数。 | kafka.streams:type=stream-state-metrics,thread-id=([-.\w]+),task-id=([-.\w]+),[store-scope]-id=([-.\w]+) |
| compaction-pending | 如果至少有一次压实正在进行,则该指标报告1,否则报告0。 | kafka.streams:type=stream-state-metrics,thread-id=([-.\w]+),task-id=([-.\w]+),[store-scope]-id=([-.\w]+) |
| num-running-compactions | 当前运行的压实次数。 | kafka.streams:type=stream-state-metrics,thread-id=([-.\w]+),task-id=([-.\w]+),[store-scope]-id=([-.\w]+) |
| estimate-pending-compaction-bytes | 估计压实需要在磁盘上重写的总字节数,以使所有层级降到目标大小以下(仅对层级压实有效)。 | kafka.streams:type=stream-state-metrics,thread-id=([-.\w]+),task-id=([-.\w]+),[store-scope]-id=([-.\w]+) |
| total-sst-files-size | 所有SST文件的总大小,以字节为单位。 | kafka.streams:type=stream-state-metrics,thread-id=([-.\w]+),task-id=([-.\w]+),[store-scope]-id=([-.\w]+) |
| live-sst-files-size | 属于最新LSM树的所有SST文件的总大小,以字节为单位。 | kafka.streams:type=stream-state-metrics,thread-id=([-.\w]+),task-id=([-.\w]+),[store-scope]-id=([-.\w]+) |
| num-live-versions | LSM树的实际版本数量。 | kafka.streams:type=stream-state-metrics,thread-id=([-.\w]+),task-id=([-.\w]+),[store-scope]-id=([-.\w]+) |
| block-cache-capacity | 块状缓存的容量,单位为字节。 | kafka.streams:type=stream-state-metrics,thread-id=([-.\w]+),task-id=([-.\w]+),[store-scope]-id=([-.\w]+) |
| block-cache-usage | 驻留在块缓存中的内存大小,单位为字节。 | kafka.streams:type=stream-state-metrics,thread-id=([-.\w]+),task-id=([-.\w]+),[store-scope]-id=([-.\w]+) |
| block-cache-pinned-usage | 块缓存中被钉入的条目的内存大小,单位为字节。 | kafka.streams:type=stream-state-metrics,thread-id=([-.\w]+),task-id=([-.\w]+),[store-scope]-id=([-.\w]+) |
| estimate-num-keys | 激活的和未刷新的不可更改的记忆表和存储中的估计密钥数。 | kafka.streams:type=stream-state-metrics,thread-id=([-.\w]+),task-id=([-.\w]+),[store-scope]-id=([-.\w]+) |
| estimate-table-readers-mem | 读取SST表所使用的估计内存,以字节为单位,不包括块缓存中使用的内存。 | kafka.streams:type=stream-state-metrics,thread-id=([-.\w]+),task-id=([-.\w]+),[store-scope]-id=([-.\w]+) |
| background-errors | 背景错误的总数。 | kafka.streams:type=stream-state-metrics,thread-id=([-.\w]+),task-id=([-.\w]+),[store-scope]-id=([-.\w]+) |
记录缓存指标4
以下所有指标的记录级别均为调试。
| 指标名称 | 描述 | MBEAN NAME |
|---|---|---|
| hit-ratio-avg | 平均缓存命中率定义为缓存读取命中量与缓存读取请求总量的比率。 | kafka.streams:type=stream-record-cache-metrics,thread-id=([-.\w]+),task-id=([-.\w]+),record-cache-id=([-.\w]+) |
| hit-ratio-min | 最小缓存命中率。 | kafka.streams:type=stream-record-cache-metrics,thread-id=([-.\w]+),task-id=([-.\w]+),record-cache-id=([-.\w]+) |
| hit-ratio-max | 最大缓存命中率。 | kafka.streams:type=stream-record-cache-metrics,thread-id=([-.\w]+),task-id=([-.\w]+),record-cache-id=([-.\w]+) |
其他
我们建议监控GC时间等统计和各种服务器统计,如CPU利用率、I/O服务时间等。在客户端,我们建议监控消息/字节速率(全局和每个主题)、请求速率/大小/时间,在消费端,监控所有分区间消息的最大滞后和最小取回请求速率。对于消费者来说,最大滞后需要小于一个阈值,最小获取率需要大于0。
6.8 Zookeeper
稳定版
目前的稳定分支是3.5。Kafka会定期更新,包括3.5系列的最新版本。
操作ZooKeeper
在操作上,为了健康的ZooKeeper安装,我们做到以下几点。
- 物理/硬件/网络布局的冗余:尽量不要把它们放在同一个机架上,体面的(但不要太疯狂)硬件,尽量保持冗余的电源和网络路径等。一个典型的ZooKeeper合集有5或7台服务器,分别可以容忍2台和3台服务器宕机。如果你的部署规模较小,那么使用3台服务器也是可以接受的,但要记住,这种情况下你只能容忍1台服务器宕机。
- I/O隔离:如果你做了很多写类型的流量,你几乎肯定会希望事务日志在一个专用磁盘组上。对事务日志的写入是同步的(但为了性能而分批进行),因此,并发写入会明显影响性能。ZooKeeper快照可以是这样一个并发写入的源头,理想的情况是应该写在与事务日志分开的磁盘组上。快照是异步写入磁盘的,所以一般情况下与操作系统和消息日志文件共享是可以的。你可以通过dataLogDir参数配置服务器使用一个单独的磁盘组。
- 应用隔离。除非你真的了解你想安装在同一个盒子上的其他应用程序的应用模式,否则隔离运行ZooKeeper是个不错的主意(尽管这可能是一个与硬件能力平衡的行为)。
- 使用虚拟化时要小心。根据你的集群布局和读/写模式和SLA,它可以工作,但虚拟化层引入的微小开销可能会增加,并抛开ZooKeeper,因为它可能对时间非常敏感。
- ZooKeeper配置。它是java,确保你给它足够的堆空间(我们通常用3-5G运行它们,但这主要是由于我们这里的数据集大小)。不幸的是,我们没有一个好的公式,但请记住,允许更多的ZooKeeper状态意味着快照会变得很大,而大的快照会影响恢复时间。事实上,如果快照变得太大了(几GB),那么你可能需要增加initLimit参数,以给服务器足够的时间来恢复和加入合集。
- 监控。JMX和4个字母词(4lw)命令都非常有用,它们在某些情况下会重叠(在这些情况下,我们更喜欢4个字母命令,它们看起来更可预测,或者至少,它们与LI监控基础设施配合得更好)
- 不要过度构建集群:大型集群,特别是在重写使用模式下,意味着大量的集群内通信(写入和后续集群成员更新的配额),但不要过度构建(并有可能淹没集群)。拥有更多的服务器会增加你的读取能力。
总的来说,我们尽量让ZooKeeper系统保持小规模,因为它可以处理负载(加上标准的增长容量规划),并且尽可能的简单。与官方版本相比,我们尽量不做任何花哨的配置或应用程序布局,以及保持尽可能的自我控制。由于这些原因,我们倾向于跳过操作系统的打包版本,因为它有一种倾向,即试图把东西放在操作系统标准的层次结构中,这可能是 "混乱的",想要一个更好的方式来形容它。
7.安全
7.1 安全概述
在0.9.0.0版本中,Kafka社区增加了一些功能,这些功能可以单独使用,也可以一起使用,增加Kafka集群的安全性。目前支持以下安全措施。
- 从客户(生产者和消费者)、其他broker和工具连接到broker的认证,使用SSL或SASL。Kafka支持以下SASL机制。
- SASL/GSSAPI (Kerberos) - starting at version 0.9.0.0
- SASL/PLAIN - starting at version 0.10.0.0
- SASL/SCRAM-SHA-256 and SASL/SCRAM-SHA-512 - starting at version 0.10.2.0
- SASL/OAUTHBEARER - starting at version 2.0
- 从broker到ZooKeeper的连接认证。
- 使用SSL对broker和客户机之间、broker之间或broker和工具之间传输的数据进行加密(注意,启用SSL后会出现性能下降,下降的幅度取决于CPU类型和JVM实现)。
- 客户端对读/写操作的授权
- 授权是可插拔的,并支持与外部授权服务的集成。
值得注意的是,安全性是可选的 - 支持非安全集群,以及认证、非认证、加密和非加密客户端的混合。下面的指南解释了如何在客户端和broker中配置和使用安全功能。
7.2 使用SSL进行加密和认证
Apache Kafka允许客户端使用SSL对流量进行加密以及认证。默认情况下,SSL是被禁用的,但如果需要的话可以打开。下面的段落详细解释了如何设置自己的PKI基础架构,使用它来创建证书并配置Kafka使用这些证书。
为每个Kafka代理生成SSL密钥和证书
部署一个或多个支持SSL的broker的第一步是为每个服务器生成一个公钥/私钥对。由于Kafka期望所有的密钥和证书都存储在keystores中,我们将使用Java的keytool命令来完成这个任务。该工具支持两种不同的keystore格式,Java特有的jks格式,现在已经被废弃了,还有PKCS12。PKCS12是Java版本9的默认格式,为了确保无论使用哪个Java版本都能使用这种格式,以下所有命令都明确指定PKCS12格式
keytool -keystore {keystorefile} -alias localhost -validity {validity} -genkey -keyalg RSA -storetype pkcs12
你需要在上述命令中指定两个参数。
- keystorefile:存储这个broker的密钥(以及后来的证书)的keystore文件。keystore文件包含了这个broker的私钥和公钥,因此需要保证它的安全。理想情况下,这一步是在密钥将被使用的Kafka broker上运行的,因为这个密钥永远不应该被传输/离开它所要使用的服务器。
- validity:密钥的有效时间,单位为天。请注意,这与证书的有效期不同,证书的有效期将在签署证书中确定。你可以使用同一个密钥来申请多个证书:如果你的密钥的有效期是10年,但你的CA只签署有效期为一年的证书,你可以使用同一个密钥与10个证书在一段时间内。
要想获得一个可以和刚刚创建的私钥一起使用的证书,需要创建一个证书签署请求。这个签名请求,当由一个受信任的CA签署时,会产生实际的证书,然后可以安装在密钥存储中,并用于认证目的。
要生成证书签名请求,请为目前创建的所有服务器密钥库运行以下命令:
keytool -keystore server.keystore.jks -alias localhost -validity {validity} -genkey -keyalg RSA -destkeystoretype pkcs12 -ext SAN=DNS:{FQDN},IP:{IPADDRESS1}
此命令假设你要在证书中添加主机名信息,如果不是这样,可以省略扩展参数-ext SAN=DNS:{FQDN},IP:{IPADDRESS1}。请看下面的内容:
主机名验证
启用主机名验证后,是将连接到的服务器所提供的证书中的属性与该服务器的实际主机名或ip地址进行核对,以确保你确实连接到了正确的服务器。
这种检查的主要原因是为了防止中间人攻击。对于Kafka来说,这项检查在默认情况下已经被禁用了很长时间,但是从Kafka 2.0.0开始,服务器的主机名校验在默认情况下对客户端连接和broker之间的连接都是启用的。
通过将ssl.endpoint.identification.algorithm设置为空字符串,可以禁用服务器主机名验证。
对于动态配置的broker监听器,可以使用kafka-configs.sh禁用主机名验证:
bin/kafka-configs.sh --bootstrap-server localhost:9093 --entity-type brokers --entity-name 0 --alter --add-config "listener.name.internal.ssl.endpoint.identification.algorithm="
注意:在正常情况下,没有什么好的理由禁用主机名验证。
通常情况下,没有什么好的理由来禁用主机名验证,除了最快捷的方式 "只要能正常工作",然后承诺 "以后有更多的时间时再解决"!如果在正确的时间内完成主机名验证,并不难,但一旦集群启动和运行,就会变得很难。
如果在正确的时间内完成主机名验证并不难,但一旦集群启动并运行,就会变得更加困难--帮你自己一个忙,现在就去做吧!
如果启用了主机名验证,客户端将根据以下两个字段之一验证服务器的完全合格域名(FQDN)或IP地址。
- 通用名(CN)
- 主题替代名称(SAN)
虽然Kafka会检查这两个字段,但自2000年以来,通用名字段用于主机名验证已经被废弃,应尽可能避免使用。此外,SAN字段更加灵活,允许在证书中声明多个DNS和IP条目。
另一个优点是,如果SAN字段被用于主机名验证,通用名可以设置为一个更有意义的值,用于授权目的。由于我们需要SAN字段包含在签名的证书中,所以在生成签名请求时将指定它。它也可以在生成密钥对时指定,但不会自动复制到签名请求中。
要添加 SAN 字段,请在 keytool 命令中添加以下参数 -ext SAN=DNS:{FQDN},IP:{IPADDRESS}:
keytool -keystore server.keystore.jks -alias localhost -validity {validity} -genkey -keyalg RSA -destkeystoretype pkcs12 -ext SAN=DNS:{FQDN},IP:{IPADDRESS1}
创建你自己的CA
这一步之后,集群中的每台机器都有一个公钥/私钥对,已经可以用来加密流量,还有一个证书签署请求,这是创建证书的基础。要添加认证功能,这个签名请求需要由一个受信任的权威机构来签名,这个权威机构将在这一步中创建。
证书颁发机构(CA)负责签署证书。CA的工作原理就像一个发行护照的政府--政府在每本护照上盖章(签名),这样护照就很难伪造。其他政府则会对印章进行验证,以确保护照的真实性。同样,CA对证书进行签名,密码学保证签名的证书在计算上难以伪造。因此,只要CA是一个真实可信的权威机构,客户就可以有力地保证他们连接到真实的机器。
在本指南中,我们将做自己的证书颁发机构。当在企业环境中建立生产集群时,这些证书通常会由整个公司都信任的企业CA签署。请参阅生产中的常见陷阱,了解这种情况下需要考虑的一些事情。
由于OpenSSL中的一个错误,x509模块不会将CSR中要求的扩展字段复制到最终证书中。由于我们希望SAN扩展字段能出现在证书中以实现主机名验证,我们将使用ca模块来代替。这需要在生成 CA 密钥对之前进行一些额外的配置。
将以下列表保存到一个名为openssl-ca.cnf的文件中,并根据需要调整有效性和通用属性的值。
HOME = .RANDFILE = $ENV::HOME/.rnd####################################################################[ ca ]default_ca = CA_default # The default ca section[ CA_default ]base_dir = .certificate = $base_dir/cacert.pem # The CA certifcateprivate_key = $base_dir/cakey.pem # The CA private keynew_certs_dir = $base_dir # Location for new certs after signingdatabase = $base_dir/index.txt # Database index fileserial = $base_dir/serial.txt # The current serial numberdefault_days = 1000 # How long to certify fordefault_crl_days = 30 # How long before next CRLdefault_md = sha256 # Use public key default MDpreserve = no # Keep passed DN orderingx509_extensions = ca_extensions # The extensions to add to the certemail_in_dn = no # Don't concat the email in the DNcopy_extensions = copy # Required to copy SANs from CSR to cert####################################################################[ req ]default_bits = 4096default_keyfile = cakey.pemdistinguished_name = ca_distinguished_namex509_extensions = ca_extensionsstring_mask = utf8only####################################################################[ ca_distinguished_name ]countryName = Country Name (2 letter code)countryName_default = DEstateOrProvinceName = State or Province Name (full name)stateOrProvinceName_default = Test ProvincelocalityName = Locality Name (eg, city)localityName_default = Test TownorganizationName = Organization Name (eg, company)organizationName_default = Test CompanyorganizationalUnitName = Organizational Unit (eg, division)organizationalUnitName_default = Test UnitcommonName = Common Name (e.g. server FQDN or YOUR name)commonName_default = Test NameemailAddress = Email AddressemailAddress_default = test@test.com####################################################################[ ca_extensions ]subjectKeyIdentifier = hashauthorityKeyIdentifier = keyid:always, issuerbasicConstraints = critical, CA:truekeyUsage = keyCertSign, cRLSign####################################################################[ signing_policy ]countryName = optionalstateOrProvinceName = optionallocalityName = optionalorganizationName = optionalorganizationalUnitName = optionalcommonName = suppliedemailAddress = optional####################################################################[ signing_req ]subjectKeyIdentifier = hashauthorityKeyIdentifier = keyid,issuerbasicConstraints = CA:FALSEkeyUsage = digitalSignature, keyEncipherment
然后创建一个数据库和序列号文件,这些将用于跟踪哪些证书是与这个CA签署的。这两个文件都是简单的文本文件,与你的CA密钥驻留在同一个目录下
echo 01 > serial.txttouch index.txt
完成这些步骤后,你现在就可以生成你的CA了,它将被用来签署证书。
keytool -keystore client.truststore.jks -alias CARoot -import -file ca-cert
注意:如果你在Kafka brokers配置中通过将ssl.client.auth设置为 "requested "或 "required "来配置Kafka brokers需要客户端认证,那么你必须为Kafka brokers也提供一个truststore,它应该有客户端的密钥所签署的所有CA证书。
keytool -keystore server.truststore.jks -alias CARoot -import -file ca-cert
与步骤1中存储每台机器自身身份的keystore不同,客户端的truststore存储了客户端应该信任的所有证书。将一个证书导入到自己的truststore中,也意味着信任所有由该证书签署的证书。就像上面的比喻,信任政府(CA)也意味着信任它颁发的所有护照(证书)。这个属性被称为信任链,当在大型Kafka集群上部署SSL时,它特别有用。你可以用一个CA来签署集群中的所有证书,并让所有机器共享同一个信任CA的truststore。这样所有的机器都可以对所有其他机器进行认证。
签署证书
然后在CA上签字:
openssl ca -config openssl-ca.cnf -policy signing_policy -extensions signing_req -out {server certificate} -infiles {certificate signing request}
最后,你需要将CA的证书和签名的证书都导入到密钥存储中。
keytool -keystore {keystore} -alias CARoot -import -file {CA certificate}keytool -keystore {keystore} -alias localhost -import -file cert-signed
参数的定义如下。
- keystore:钥匙店的位置
- CA证书:CA的证书
- 证书签署请求:用服务器密钥创建的csr。
- 服务器证书:将服务器的签名证书写入的文件。
这将给你留下一个名为truststore.jks的truststore文件--这个文件可以对所有的客户和broker都是一样的,不包含任何敏感信息,所以没有必要保护这个文件。
此外,每个节点将有一个server.keystore.jks文件,其中包含该节点的密钥、证书和你的CAs证书,关于如何使用这些文件,请参考配置Kafkabroker和配置Kafka客户端。
关于这个主题的一些工具帮助,请查看easyRSA项目,它有大量的脚本来帮助完成这些步骤。
PEM格式的SSL密钥和证书
从2.7.0开始,可以直接在配置中以PEM格式为Kafkabroker和客户端配置SSL密钥和信任存储。这避免了在文件系统上存储单独的文件,并受益于Kafka配置的密码保护功能。除了JKS和PKCS12之外,PEM也可以作为基于文件的密钥和信任存储的存储类型。如果要在broker或客户端配置中直接配置PEM密钥存储,应在ssl.keystore.key中提供PEM格式的私钥,在ssl.keystore.certificate.chain中提供PEM格式的证书链。配置信任存储时,应在ssl.truststore.certificates中提供信任证书,如CA的公开证书。由于PEM通常存储为多行基数64的字符串,配置值可以在Kafka配置中以多行字符串的形式包含,并以反斜杠('/')作为行的延续。
存储密码配置ssl.keystore.password和ssl.truststore.password不用于PEM。如果私钥使用密码加密,必须在ssl.key.password中提供密钥密码。当直接在config值中指定PEM时,可以不使用密码以未加密的形式提供私钥。在生产部署中,这种情况下应该使用Kafka中的密码保护功能对config进行加密或外部化。需要注意的是,当使用OpenSSL等外部工具进行加密时,默认的SSL引擎工厂对加密私钥的解密能力有限。第三方库如BouncyCastle可能会被集成到自定义的SSL引擎工厂中,以支持更广泛的加密私钥。
生产中的常见陷阱
上面的段落展示了创建你自己的CA,并使用它为你的集群签署证书的过程。虽然对于沙盒、开发、测试和类似的系统非常有用,但这通常不是为企业环境中的生产集群创建证书的正确过程。企业通常会运营自己的CA,用户可以发送CSR到这个CA上进行签名,这样做的好处是用户不用负责保证CA的安全,同时也是大家可以信任的中央权威机构。然而这也剥夺了用户对证书签署过程的很多控制权。不少时候,操作企业CA的人员会对证书进行严格的限制,当试图将这些证书与Kafka一起使用时,就会出现问题。
- 扩展密钥使用
- 证书可能包含一个扩展字段,用于控制证书的使用目的,如果该字段为空,则对使用没有限制,但如果在这里指定了任何用途,有效的SSL实现必须强制执行这些用途。如果该字段为空,则对使用没有限制,但如果在这里指定了任何用途,有效的SSL实现必须执行这些用途。
- Kafka的相关用途有
- 客户端认证
- 服务器认证
- Kafkabroker需要这两种用法都被允许,因为对于集群内的通信,每个broker对其他broker都会表现为既是客户端又是服务器。企业CA有一个webservers的签名配置文件,并将其也用于Kafka,这并不罕见,它将只包含serverAuth用法值,并导致SSL握手失败。
- 中级证书
- 出于安全原因,公司的根证书经常处于离线状态。为了保证日常的使用,创建了所谓的中间CA,然后用来签署最终的证书。当把一个由中间CA签署的证书导入到密钥存储中时,有必要提供整个信任链到根CA。这可以通过简单地将证书文件编码为一个合并的证书文件,然后用keytool导入来完成。
- 复制扩展字段失败
- 核证机运营商往往不愿意从企业社会责任书中复制和要求的扩展字段,而更愿意自己指定这些字段,因为这使恶意方更难获得具有潜在误导性或欺诈性价值的证书。建议仔细检查已签署的证书,是否包含所有要求的SAN字段,以便进行正确的主机名验证。下面的命令可以用来打印证书细节到控制台,并与最初的要求进行比较。
openssl x509 -in certificate.crt -text -noout
配置Kafka brokers
Kafka Brokers支持监听多个端口上的连接。我们需要在server.properties中配置以下属性,该属性必须有一个或多个逗号分隔的值:
- listeners
如果没有为broker之间的通信启用SSL(见下文如何启用),则需要同时启用PLAINTEXT和SSL端口。
listeners=PLAINTEXT://host.name:port,SSL://host.name:port
broker端需要以下SSL配置。
ssl.keystore.location=/var/private/ssl/server.keystore.jksssl.keystore.password=test1234ssl.key.password=test1234ssl.truststore.location=/var/private/ssl/server.truststore.jksssl.truststore.password=test1234
注意:ssl.truststore.password在技术上是可选的,但强烈建议使用。如果没有设置密码,对truststore的访问仍然可用,但完整性检查被禁用。值得考虑的可选设置。
- ssl.client.auth=none ("required" => 客户端认证是必须的, "requested" => 客户端认证是必须的,没有证书的客户端仍然可以连接。不鼓励使用 "requested",因为它提供了一种虚假的安全感,配置错误的客户端仍然可以成功连接。)
- ssl.cipher.suites (可选)。密码套件是一个命名的认证、加密、MAC和密钥交换算法的组合,用于使用TLS或SSL网络协议协商网络连接的安全设置。(默认为空列表)
- ssl.enabled.protocols=TLSv1.2,TLSv1.1,TLSv1 (列出你要从客户端接受的SSL协议。请注意,SSL已经被TLS取代,不建议在生产中使用SSL。)
- ssl.keystore.type=JKS
- ssl.truststore.type=JKS
- ssl.secure.random.implement=SHA1PRNG。
如果你想为broker之间的通信启用SSL,请在server.properties文件中添加以下内容(默认为PLAINTEXT)。
security.inter.broker.protocol=SSL
由于某些国家的进口法规,Oracle的实施限制了默认情况下可用的加密算法的强度。如果需要更强的算法(例如,256位密钥的AES),则必须获得JCE无限强度Jurisdiction策略文件并安装在JDK/JRE中。更多信息请参见JCA供应商文档。
JRE/JDK会有一个默认的伪随机数生成器(PRNG),用于加密操作,因此不需要配置与ssl.secure.random.实现一起使用的实现。但是,有些实现存在性能问题(特别是Linux系统上选择的默认的NativePRNG,利用了全局锁)。在SSL连接的性能成为问题的情况下,可以考虑明确设置要使用的实现。SHA1PRNG实现是非阻塞的,并且在重负载下表现出了非常好的性能特性(每个broker每秒产生50 MB的消息,加上复制流量)。
一旦你启动了broker,你应该能够在server.log中看到以下信息
with addresses: PLAINTEXT -> EndPoint(192.168.64.1,9092,PLAINTEXT),SSL -> EndPoint(192.168.64.1,9093,SSL)
要快速检查服务器keystore和truststore是否设置正确,你可以运行以下命令
- openssl s_client -debug -connect localhost:9093 -tls1
(注意:TLSv1应该列在ssl.enabled.protocols下)
在这个命令的输出中,你应该看到服务器的证书。
-----BEGIN CERTIFICATE-----{variable sized random bytes}-----END CERTIFICATE-----subject=/C=US/ST=CA/L=Santa Clara/O=org/OU=org/CN=Sriharsha Chintalapaniissuer=/C=US/ST=CA/L=Santa Clara/O=org/OU=org/CN=kafka/emailAddress=test@test.com
如果证书没有显示出来,或者有任何其他错误信息,那么你的keystore没有正确设置。
配置Kafka客户端
SSL只支持新的Kafka生产者和消费者,不支持旧的API。对于生产者和消费者来说,SSL的配置将是相同的。
如果在broker中不需要客户端认证,那么下面是一个最小的配置示例。
security.protocol=SSLssl.truststore.location=/var/private/ssl/client.truststore.jksssl.truststore.password=test1234
注意:ssl.truststore.password在技术上是可选的,但强烈建议使用。如果没有设置密码,对truststore的访问仍然是可用的,但完整性检查被禁用。如果需要客户端认证,那么必须像步骤1那样创建一个keystore,并且还必须配置以下内容。
ssl.keystore.location=/var/private/ssl/client.keystore.jksssl.keystore.password=test1234ssl.key.password=test1234
根据我们的要求和broker配置,可能还需要其他配置设置。
- ssl.provider (可选)。用于 SSL 连接的安全提供商的名称。默认值是JVM的默认安全提供商。
- ssl.cipher.suites(可选)。密码套件是一个命名的认证、加密、MAC和密钥交换算法的组合,用于使用TLS或SSL网络协议协商网络连接的安全设置。
- ssl.enabled.protocols=TLSv1.2,TLSv1.1,TLSv1.它应该列出至少一个在broker端配置的协议。
- ssl.truststore.type=JKS
- ssl.keystore.type=JKS
使用控制台-生产者和控制台-消费者的例子:
kafka-console-producer.sh --bootstrap-server localhost:9093 --topic test --producer.config client-ssl.propertieskafka-console-consumer.sh --bootstrap-server localhost:9093 --topic test --consumer.config client-ssl.properties
7.3 使用SASL进行认证
(1)JAAS配置
Kafka使用Java认证和授权服务(JAAS)进行SASL配置。
Kafkabroker的JAAS配置
KafkaServer是JAAS文件中每个KafkaServer/Broker使用的部分名称。该部分为broker提供了SASL配置选项,包括broker为broker间通信所做的任何SASL客户端连接。如果多个监听器被配置为使用SASL,则该部分名称可以以监听器名称为前缀,用小写字母,后面加句号,例如:sasl_ssl.KafkaServer。
客户端部分用于验证与zookeeper的SASL连接。它还允许broker在zookeeper节点上设置SASL ACL,将这些节点锁定,只有broker可以修改它。所有的broker必须有相同的主名。如果你想使用Client以外的部分名称,请将系统属性zookeeper.sasl.clientconfig设置为适当的名称(例如,-Dzookeeper.sasl.clientconfig=ZkClient)。
ZooKeeper默认使用 "zookeeper "作为服务名。如果你想改变这一点,请将系统属性zookeeper.sasl.client.username设置为适当的名称(例如,-Dzookeeper.sasl.client.username=zk)。
broker也可以使用broker配置属性sasl.jaas.config来配置JAAS。属性名必须以监听器为前缀,包括SASL机制,即listener.name.{listenerName}.{saslMechanism}.sasl.jaas.config。config值中只能指定一个登录模块。如果在一个监听器上配置了多个机制,必须使用监听器和机制前缀为每个机制提供配置。例如
listener.name.sasl_ssl.scram-sha-256.sasl.jaas.config=org.apache.kafka.common.security.scram.ScramLoginModule required \username="admin" \password="admin-secret";listener.name.sasl_ssl.plain.sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required \username="admin" \password="admin-secret" \user_admin="admin-secret" \user_alice="alice-secret";
如果JAAS配置定义在不同的级别,使用的优先顺序是:
- broker配置属性listener.name.{listenerName}.{saslMechanism}.sasl.jaas.config。
- 静态JAAS配置的{listenerName}.KafkaServer部分。
- 静态JAAS配置的KafkaServer部分
注意,ZooKeeper JAAS配置只能使用静态JAAS配置。
请参阅GSSAPI(Kerberos),PLAIN,SCRAM或OAUTHBEARER的broker配置的例子。
Kafka客户端的JAAS配置
客户端可以使用客户端配置属性sasl.jaas.config或使用类似于brokers的静态JAAS配置文件来配置JAAS。
使用客户端配置属性进行JAAS配置
客户端可以将JAAS配置指定为生产者或消费者属性,而无需创建物理配置文件。这种模式还可以使同一JVM中的不同生产者和消费者通过为每个客户端指定不同的属性来使用不同的凭证。如果同时指定了静态 JAAS 配置系统属性 java.security.auth.login.config 和客户端属性 sasl.jaas.config,则将使用客户端属性。
请参阅GSSAPI(Kerberos)、PLAIN、SCRAM或OAUTHBEARER的配置示例。
使用静态配置文件进行JAAS配置
使用静态JAAS配置文件在客户端配置SASL认证。
- 添加一个JAAS配置文件,其中有一个名为KafkaClient的客户端登录部分。在KafkaClient中为所选机制配置登录模块,如设置GSSAPI(Kerberos)、PLAIN、SCRAM或OAUTHBEARER的示例中所述。例如,GSSAPI凭证可以配置为:
KafkaClient {com.sun.security.auth.module.Krb5LoginModule requireduseKeyTab=truestoreKey=truekeyTab="/etc/security/keytabs/kafka_client.keytab"principal="kafka-client-1@EXAMPLE.COM";};
- 将JAAS配置文件的位置作为JVM参数传递给每个客户端JVM。例如:
- -Djava.security.auth.login.config=/etc/kafka/kafka_client_jaas.conf
---------------------------------------
(2)SASL配置
SASL可与PLAINTEXT或SSL一起使用,分别使用安全协议SASL_PLAINTEXT或SASL_SSL作为传输层。如果使用SASL_SSL,那么也必须配置SSL。
1.SASL机制
Kafka支持以下SASL机制。
- GSSAPI (Kerberos)
- PLAIN
- SCRAM-SHA-256
- SCRAM-SHA-512
- OAUTHBEARER
2.Kafkabroker的SASL配置
1.在server.properties中配置一个SASL端口,在listeners参数中加入至少一个SASL_PLAINTEXT或SASL_SSL,其中包含一个或多个逗号分隔的值。
- listeners=SASL_PLAINTEXT://host.name:port
如果你只配置一个SASL端口(或者你想让Kafkabroker使用SASL相互认证),那么请确保你为broker之间的通信设置相同的SASL协议。
2.选择一个或多个受支持的机制在broker中启用,并按照步骤为该机制配置SASL。要在broker中启用多个机制,请按照这里的步骤进行操作。
3.Kafka客户端的SASL配置
SASL 身份验证只支持新的 Java Kafka 生产者和消费者,不支持旧的 API。
要在客户端上配置SASL身份验证,请选择一个在broker中启用的SASL机制进行客户端身份验证,并按照步骤为所选机制配置SASL。
---------------------------------------
(3)使用SASL/Kerberos进行认证
1)先决条件
1.Kerberos
如果您的组织已经使用了 Kerberos 服务器 (例如,通过使用 Active Directory),就不需要为 Kafka 安装一个新的服务器。否则,您需要安装一个,您的 Linux 供应商可能有 Kerberos 的软件包和关于如何安装和配置它的简短指南 (Ubuntu、Redhat)。注意, 如果您使用的是 Oracle Java, 则需要下载 Java 版本的 JCE 策略文件, 并将其复制到 $JAVA_HOME/jre/lib/security 中。
2.创建 Kerberos 标准
如果您正在使用组织的 Kerberos 或 Active Directory 服务器,请向 Kerberos 管理员询问集群中每个 Kafka broker和每个通过 Kerberos 身份验证访问 Kafka 的操作系统用户(通过客户端和工具)的 principal。
如果您已经安装了自己的 Kerberos,则需要使用以下命令来创建这些 principal。
sudo /usr/sbin/kadmin.local -q 'addprinc -randkey kafka/{hostname}@{REALM}'sudo /usr/sbin/kadmin.local -q "ktadd -k /etc/security/keytabs/{keytabname}.keytab kafka/{hostname}@{REALM}"
3.确保所有的主机都可以使用主机名进行访问
Kerberos 要求所有的主机都可以使用 FQDNs 进行解析。
2)配置Kafkabroker
1.在每个Kafka broker的config目录下添加一个经过适当修改的类似于下面的JAAS文件,在这个例子中,我们称它为kafka_server_jaas.conf(注意,每个broker应该有自己的keytab)。
KafkaServer {com.sun.security.auth.module.Krb5LoginModule requireduseKeyTab=truestoreKey=truekeyTab="/etc/security/keytabs/kafka_server.keytab"principal="kafka/kafka1.hostname.com@EXAMPLE.COM";};// Zookeeper client authenticationClient {com.sun.security.auth.module.Krb5LoginModule requireduseKeyTab=truestoreKey=truekeyTab="/etc/security/keytabs/kafka_server.keytab"principal="kafka/kafka1.hostname.com@EXAMPLE.COM";};
JAAS文件中的KafkaServer部分告诉broker要使用哪个principal,以及存放这个principal的keytab的位置。它允许broker使用本节中指定的keytab登录。关于Zookeeper SASL配置的更多细节,请参见注释。
2.将 JAAS 和可选的 krb5 文件位置作为 JVM 参数传递给每个 Kafka broker(详见这里)。
- -Djava.security.krb5.conf=/etc/kafka/krb5.conf
- -Djava.security.auth.login.config=/etc/kafka/kafka_server_jaas.conf
- -Djava.security.krb5.conf=/etc/kafka/krb5.conf
3.确保在JAAS文件中配置的keytabs可以被启动kafka broker的操作系统用户读取。
4.在server.properties中配置SASL端口和SASL机制,如这里所述。例如:
- listeners=SASL_PLAINTEXT://host.name:port
- security.inter.broker.protocol=SASL_PLAINTEXT
- sasl.mechanism.inter.broker.protocol=GSSAPI
- sasl.enabled.mechanisms=GSSAPI
我们还必须在server.properties中配置服务名,服务名应该与kafka brokers的principal名一致。在上面的例子中,principal是 "kafka/kafka1.hostname.com@EXAMPLE.com",所以。
- sasl.kerberos.service.name=kafka
3)配置kafka客户端
要在客户端配置SASL认证:
(1)客户端(生产者、消费者、连接工作者等)将用自己的委托人(通常与运行客户端的用户同名)对集群进行身份验证,因此根据需要获取或创建这些委托人。然后为每个客户端配置JAAS配置属性。在一个JVM中,不同的客户端可以通过指定不同的principals来作为不同的用户运行。producer.properties或consumer.properties中的属性sasl.jaas.config描述了生产者和消费者等客户端如何连接到Kafka Broker。下面是一个使用keytab的客户端的配置示例(推荐用于长期运行的进程)。
sasl.jaas.config=com.sun.security.auth.module.Krb5LoginModule required \useKeyTab=true \storeKey=true \keyTab="/etc/security/keytabs/kafka_client.keytab" \principal="kafka-client-1@EXAMPLE.COM";
对于kafka-console-consumer或kafka-console-producer这样的命令行实用程序,kinit可以和 "useTicketCache=true "一起使用,如:
sasl.jaas.config=com.sun.security.auth.module.Krb5LoginModule required \useTicketCache=true;
客户端的JAAS配置也可以指定为JVM参数,类似于这里描述的broker。客户端使用名为KafkaClient的登录部分。这个选项只允许一个用户从JVM的所有客户端连接。
(2)确保在JAAS配置中配置的keytabs可以被启动kafka客户端的操作系统用户读取。
(3)可以选择将krb5文件的位置作为JVM参数传递给每个客户端JVM(更多细节见这里)。
- -Djava.security.krb5.conf=/etc/kafka/krb5.conf
(4)在 producer.properties 或 consumer.properties 中配置以下属性。
security.protocol=SASL_PLAINTEXT (or SASL_SSL)sasl.mechanism=GSSAPIsasl.kerberos.service.name=kafka
------------------------------------
(4)使用SASL/PLAIN进行认证
SASL/PLAIN是一种简单的用户名/密码认证机制,通常与TLS一起用于加密以实现安全认证。Kafka支持SASL/PLAIN的默认实现,可以按照这里的描述对其进行扩展以用于生产。
用户名作为认证的Principal,用于配置ACL等。
1)配置Kafkabroker
(1)在每个Kafka broker的config目录下添加一个适当修改的类似于下面的JAAS文件,在本例中我们称之为kafka_server_jaas.conf。
KafkaServer {org.apache.kafka.common.security.plain.PlainLoginModule requiredusername="admin"password="admin-secret"user_admin="admin-secret"user_alice="alice-secret";};
这个配置定义了两个用户(admin和alice)。KafkaServer部分的属性用户名和密码被broker用来发起与其他broker的连接。在本例中,admin是用于broker之间通信的用户。属性集user_userName定义了所有连接到broker的用户的密码,broker使用这些属性验证所有客户端连接,包括来自其他broker的连接。
(2)将JAAS配置文件位置作为JVM参数传递给每个Kafka broker。
- -Djava.security.auth.login.config=/etc/kafka/kafka_server_jaas.conf
(3)在server.properties中配置SASL端口和SASL机制,如这里所述。例如:
- listeners=SASL_SSL://host.name:port
- security.inter.broker.protocol=SASL_SSL
- sasl.mechanism.inter.broker.protocol=PLAIN
- sasl.enabled.mechanisms=PLAIN
2)配置Kafka客户端
要在客户端配置SASL认证。
(1)在producer.properties或consumer.properties中为每个客户端配置JAAS配置属性。登录模块描述了生产者和消费者等客户端如何连接到Kafka Broker。下面是一个PLAIN机制的客户端的配置示例。
sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required \username="alice" \password="alice-secret";
username和password这两个选项被客户端用来配置客户端连接的用户。在这个例子中,客户端以用户alice的身份连接到broker。在一个JVM中,不同的客户端可以通过在sasl.jaas.config中指定不同的用户名和密码作为不同的用户进行连接。
客户端的JAAS配置也可以像这里描述的那样,作为类似于broker的JVM参数来指定。客户端使用名为KafkaClient的登录部分。这个选项只允许一个用户从JVM的所有客户端连接。
(2)在 producer.properties 或 consumer.properties 中配置以下属性。
security.protocol=SASL_SSLsasl.mechanism=PLAIN
(3)在生产中使用SASL/PLAIN
- SASL/PLAIN应该只在SSL作为传输层的情况下使用,以确保明确的密码在没有加密的情况下不会在有线上传输。
- Kafka中SASL/PLAIN的默认实现在JAAS配置文件中指定用户名和密码,如图所示。从Kafka 2.0版本开始,你可以通过配置选项sasl.server.callback.handler.class和sasl.client.callback.handler.class配置自己的回调处理程序,从外部获取用户名和密码,从而避免在磁盘上存储清晰的密码。
- 在生产系统中,外部认证服务器可以实现密码认证。从Kafka 2.0版本开始,你可以通过配置sasl.server.callback.handler.class,插入自己的回调处理程序,使用外部认证服务器进行密码验证。
-------------------------------------
( 5)使用SASL/SCRAM进行认证
盐化挑战响应认证机制(SCRAM)是一个SASL机制系列,它解决了传统机制(如PLAIN和DIGEST-MD5)执行用户名/密码认证的安全问题。该机制定义在RFC 5802中。Kafka支持SCRAM-SHA-256和SCRAM-SHA-512,它们可以和TLS一起执行安全认证。用户名作为认证的Principal,用于配置ACL等。Kafka中默认的SCRAM实现将SCRAM凭证存储在Zookeeper中,适用于Zookeeper在私有网络上的Kafka安装。更多细节请参考安全注意事项。
1)创建SCRAM证书
Kafka中的SCRAM实现使用Zookeeper作为凭证存储。可以使用kafka-configs.sh在Zookeeper中创建凭证。对于每个已启用的SCRAM机制,必须通过添加一个带有机制名称的配置来创建凭证。在Kafkabroker启动之前,必须创建broker间通信的凭证。客户端凭证可以动态创建和更新,更新后的凭证将用于验证新连接。
为用户alice创建SCRAM凭证,密码为alice-secret。
> bin/kafka-configs.sh --zookeeper localhost:2182 --zk-tls-config-file zk_tls_config.properties --alter --add-config 'SCRAM-SHA-256=[iterations=8192,password=alice-secret],SCRAM-SHA-512=[password=alice-secret]' --entity-type users --entity-name alice
如果没有指定迭代次数,则使用默认的4096迭代次数。随机创建一个salt,并在Zookeeper中存储由salt、iterations、StoredKey和ServerKey组成的SCRAM标识。关于SCRAM标识和各个字段的细节,请参见RFC 5802。
下面的例子还需要一个用户管理员来进行broker之间的通信,可以使用创建。
> bin/kafka-configs.sh --zookeeper localhost:2182 --zk-tls-config-file zk_tls_config.properties --alter --add-config 'SCRAM-SHA-256=[password=admin-secret],SCRAM-SHA-512=[password=admin-secret]' --entity-type users --entity-name admin
可以使用--describe选项列出现有的凭证。
> bin/kafka-configs.sh --zookeeper localhost:2182 --zk-tls-config-file zk_tls_config.properties --describe --entity-type users --entity-name alice
使用--alter--delete-config选项可以删除一个或多个SCRAM机制的证书。
> bin/kafka-configs.sh --zookeeper localhost:2182 --zk-tls-config-file zk_tls_config.properties --alter --delete-config 'SCRAM-SHA-512' --entity-type users --entity-name alice
2)配置Kafkabroker
(1)在每个Kafka broker的config目录下添加一个适当修改的类似于下面的JAAS文件,在本例中我们称之为kafka_server_jaas.conf。
KafkaServer {org.apache.kafka.common.security.scram.ScramLoginModule requiredusername="admin"password="admin-secret";};
KafkaServer部分的属性用户名和密码被broker用来发起与其他broker的连接。在本例中,admin是broker之间通信的用户。
(2)将JAAS配置文件位置作为JVM参数传递给每个Kafka broker。
- -Djava.security.auth.login.config=/etc/kafka/kafka_server_jaas.conf
(3)在server.properties中配置SASL端口和SASL机制,如这里所述。例如:
listeners=SASL_SSL://host.name:portsecurity.inter.broker.protocol=SASL_SSLsasl.mechanism.inter.broker.protocol=SCRAM-SHA-256 (or SCRAM-SHA-512)sasl.enabled.mechanisms=SCRAM-SHA-256 (or SCRAM-SHA-512)
3)配置Kafka客户端
要在客户端配置SASL认证。
(1)在producer.properties或consumer.properties中为每个客户端配置JAAS配置属性。登录模块描述了生产者和消费者等客户端如何连接到Kafka Broker。下面是一个SCRAM机制的客户端的配置示例。
sasl.jaas.config=org.apache.kafka.common.security.scram.ScramLoginModule required \username="alice" \password="alice-secret";
username和password这两个选项被客户端用来配置客户端连接的用户。在这个例子中,客户端以用户alice的身份连接到broker。在一个JVM中,不同的客户端可以通过在sasl.jaas.config中指定不同的用户名和密码作为不同的用户进行连接。
客户端的JAAS配置也可以像这里描述的那样,作为类似于broker的JVM参数来指定。客户端使用名为KafkaClient的登录部分。这个选项只允许一个用户从JVM的所有客户端连接。
(2)在 producer.properties 或 consumer.properties 中配置以下属性。
security.protocol=SASL_SSLsasl.mechanism=SCRAM-SHA-256 (or SCRAM-SHA-512)
4)SASL/SCRAM的安全注意事项
- Kafka中默认的SASL/SCRAM实现在Zookeeper中存储SCRAM证书。这适用于在Zookeeper安全的私有网络中的生产使用。
- Kafka只支持强哈希函数SHA-256和SHA-512,最小迭代次数为4096。强哈希函数与强密码和高迭代次数相结合,可以在Zookeeper安全受到威胁时防止蛮力攻击。
- SCRAM应该只与TLS加密一起使用,以防止SCRAM交换被拦截。这可以防止字典或蛮力攻击,并在Zookeeper受到损害时防止冒名顶替。
- 从Kafka 2.0版本开始,在Zookeeper不安全的安装中,可以通过配置sasl.server.callback.handler.class,使用自定义回调处理程序覆盖默认的SASL/SCRAM凭证存储。
- 关于安全考虑的更多细节,请参考RFC 5802。
-----------------------------------
(6)使用SASL/OAUTHBEARER进行认证
OAuth 2授权框架 "使第三方应用程序能够代表资源所有者获得对HTTP服务的有限访问,通过协调资源所有者和HTTP服务之间的审批交互,或允许第三方应用程序代表自己获得访问"。SASL OAUTHBEARER机制能够在SASL(即非HTTP)上下文中使用该框架;它在RFC 7628中进行了定义。Kafka中默认的OAUTHBEARER实现创建和验证Unsecured JSON Web Tokens,只适合在非生产型Kafka安装中使用。更多细节请参考安全注意事项。
1)配置Kafkabroker
(1)在每个Kafka broker的config目录下添加一个适当修改的类似于下面的JAAS文件,在本例中我们称之为kafka_server_jaas.conf
KafkaServer {org.apache.kafka.common.security.oauthbearer.OAuthBearerLoginModule requiredunsecuredLoginStringClaim_sub="admin";};
KafkaServer部分中的属性unsecuredLoginStringClaim_sub被broker在发起与其他broker的连接时使用。在这个例子中,admin将出现在主题(sub)索赔中,并将成为broker之间通信的用户。
(2)将JAAS配置文件位置作为JVM参数传递给每个Kafka broker。
- -Djava.security.auth.login.config=/etc/kafka/kafka_server_jaas.conf
(3)在server.properties中配置SASL端口和SASL机制,如这里所述。例如,在server.properties中配置SASL端口和SASL机制。
listeners=SASL_SSL://host.name:port (or SASL_PLAINTEXT if non-production)security.inter.broker.protocol=SASL_SSL (or SASL_PLAINTEXT if non-production)sasl.mechanism.inter.broker.protocol=OAUTHBEARERsasl.enabled.mechanisms=OAUTHBEARER
2)配置Kafka客户端
要在客户端配置SASL认证
(1)在producer.properties或consumer.properties中为每个客户端配置JAAS配置属性。登录模块描述了生产者和消费者等客户端如何连接到Kafka Broker。下面是一个客户端对OAUTHBEARER机制的配置示例。
sasl.jaas.config=org.apache.kafka.common.security.oauthbearer.OAuthBearerLoginModule required \unsecuredLoginStringClaim_sub="alice";
选项unsecuredLoginStringClaim_sub被客户端用来配置主题(sub)索赔,它决定了客户端连接的用户。在这个例子中,客户端以用户alice的身份连接到broker。在一个JVM中,不同的客户端可以通过在sasl.jaas.config中指定不同的主题(子)声明作为不同的用户进行连接。
客户端的JAAS配置也可以像这里描述的那样,作为类似于broker的JVM参数来指定。客户端使用名为KafkaClient的登录部分。这个选项只允许一个用户从JVM的所有客户端连接。
(2)在 producer.properties 或 consumer.properties 中配置以下属性
security.protocol=SASL_SSL (or SASL_PLAINTEXT if non-production)sasl.mechanism=OAUTHBEARER
(3)SASL/OAUTHBEARER的默认实现依赖于jackson-databind库。由于它是一个可选的依赖项,用户必须通过他们的构建工具将其配置为一个依赖项。
3)为SASL/OAUTHBEARER创建无担保的令牌选项
Kafka中SASL/OAUTHBEARER的默认实现可以创建和验证Unsecured JSON Web Tokens。虽然只适合非生产性使用,但它确实提供了在DEV或TEST环境中创建任意令牌的灵活性。
下面是客户端支持的各种JAAS模块选项(如果OAUTHBEARER是broker间协议,则在broker端也支持)
| 用于无担保令牌创建的JAAS模块选项 | 文档 |
|---|---|
| unsecuredLoginStringClaim_<claimname>="value" |
用给定的名称和值创建一个字符串索赔。除了 "iat "和 "exp "之外,可以指定任何有效的索赔名称(这些名称是自动生成的)。 |
| unsecuredLoginNumberClaim_<claimname>="value" |
用给定的名称和值创建一个Number索赔。除了 "iat "和 "exp "之外,可以指定任何有效的索赔名称(这些名称是自动生成的)。 |
| unsecuredLoginListClaim_<claimname>="value" |
用给定的名称和从给定的值中解析出的值创建一个字符串列表请求,其中第一个字符作为定界符。例如:unsecuredLoginListClaim_fubar="|value1|value2"。除了'iat'和'exp'之外,可以指定任何有效的索赔名称(这些名称是自动生成的)。 |
| unsecuredLoginExtension_<extensionname>="value" |
用给定的名称和值创建一个字符串扩展。例如:unsecuredLoginExtension_traceId="123"。有效的扩展名是小写或大写字母的任意序列。此外,"auth "扩展名是保留的。有效的扩展值是ASCII码1-127的任意字符组合。 |
| unsecuredLoginPrincipalClaimName |
如果您希望持有主名的字符串权利要求的名称不是 "sub",则设置为自定义权利要求名称。 |
| unsecuredLoginLifetimeSeconds |
如果令牌过期时间要设置为默认值3600秒(即1小时)以外的其他值,则设置为一个整数值。exp "要求将被设置为反映过期时间。 |
| unsecuredLoginScopeClaimName |
如果您希望持有任何标记作用域的字符串或字符串列表权利要求的名称是 "作用域 "以外的其他名称,则设置为自定义权利要求名称。 |
4)SASL/OAUTHBEARER的不安全令牌验证选项
以下是broker端支持的各种JAAS模块选项,用于不安全的JSON Web Token验证
| 用于非安全令牌验证的JAAS模块选项 | 文档 |
|---|---|
| unsecuredValidatorPrincipalClaimName="value" |
如果您希望检查持有主名称的特定字符串权利要求是否存在,则设置为非空值;默认为检查 "子 "权利要求是否存在。 |
| unsecuredValidatorScopeClaimName="value" |
如果您希望持有任何标记作用域的字符串或字符串列表权利要求的名称是 "作用域 "以外的其他名称,则设置为自定义权利要求名称。 |
| unsecuredValidatorRequiredScope="value" |
如果您希望检查持有标记作用域的String/String List权利要求,以确保它包含某些值,则设置为以空格限定的作用域值列表。 |
| unsecuredValidatorAllowableClockSkewMs="value" |
如果您希望允许时钟偏移的正毫秒数,则设置为正整数(默认为0)。 |
默认的不安全的SASL/OAUTHBEARER实现可以使用自定义登录和SASL服务器回调处理程序来覆盖(在生产环境中必须覆盖)。
有关安全考虑的更多细节,请参考RFC 6749第10节。
5)为SASL/OAUTHBEARER刷新令牌
Kafka会在任何令牌过期前定期刷新,以便客户端可以继续与broker进行连接。影响刷新算法操作方式的参数被指定为生产者/消费者/broker配置的一部分,如下所示。详情请参见其他地方的这些属性的文档。默认值通常是合理的,在这种情况下,这些配置参数就不需要明确设置了。
生产者/消费者/broker配置属性
- sasl.login.refresh.window.factor
- sasl.login.refresh.window.jitter
- sasl.login.refresh.min.period.seconds
- sasl.login.refresh.min.buffer.seconds
6)SASL/OAUTHBEARER的安全/生产使用
生产用例需要编写一个org.apache.kafka.common.security.auth.AuthenticateCallbackHandler的实现,它可以处理org.apache.kafka.common.security.oauthbearer.OAuthBearerTokenCallback的实例,并通过sasl.login.callback.handler.class配置选项为非broker客户端声明它,或者通过listener.name.sasl_ssl.oauthbearer.sasl.login.callback.handler.class配置选项声明它。 login.callback.handler.class配置选项来声明它,或者通过listener.name.sasl_ssl.oauthbearer.sasl.login.callback.handler.class配置选项来声明它(当SASL/OAUTHBEARER是broker之间的协议时)。
生产用例还需要编写一个org.apache.kafka.common.security.auth.AuthenticateCallbackHandler的实现,它可以处理org.apache.kafka.common.security.oauthbearer.OAuthBearerValidatorCallback的实例,并通过listener.name.sasl_ssl.oauthbearer.sasl.server.callback.handler.classbroker配置选项来声明它。
7)SASL/OAUTHBEARER的安全考虑因素
- Kafka中SASL/OAUTHBEARER的默认实现可以创建和验证不安全的JSON网络令牌。这只适合非生产性使用。
- OAUTHBEARER只能在生产环境中使用,并使用TLS加密来防止令牌的拦截。
- 默认的不安全的SASL/OAUTHBEARER实现可以使用自定义登录和SASL服务器回调处理程序来覆盖(在生产环境中必须覆盖),如上所述。
- 有关 OAuth 2 一般安全注意事项的更多细节,请参考 RFC 6749 第 10 节。
----------------------------------
(7)在broker中启用多个SASL机制
1)在JAAS配置文件的KafkaServer部分指定所有启用机制的登录模块的配置。例如
KafkaServer {com.sun.security.auth.module.Krb5LoginModule requireduseKeyTab=truestoreKey=truekeyTab="/etc/security/keytabs/kafka_server.keytab"principal="kafka/kafka1.hostname.com@EXAMPLE.COM";org.apache.kafka.common.security.plain.PlainLoginModule requiredusername="admin"password="admin-secret"user_admin="admin-secret"user_alice="alice-secret";};
2)在server.properties中启用SASL机制
- sasl.enabled.mechanisms=GSSAPI,PLAIN,SCRAM-SHA-256,SCRAM-SHA-512,OAUTHBEARER
3)如果需要的话,在server.properties中指定broker间通信的SASL安全协议和机制
security.inter.broker.protocol=SASL_PLAINTEXT (or SASL_SSL)sasl.mechanism.inter.broker.protocol=GSSAPI (or one of the other enabled mechanisms)
4)按照GSSAPI (Kerberos)、PLAIN、SCRAM和OAUTHBEARER中特定的机制步骤,为已启用的机制配置SASL。
---------------------------
(8)修改运行中集群的SASL机制
在运行的集群中,可以使用以下顺序修改 SASL 机制。
- 启用新的SASL机制,在server.properties中的sasl.enabled.methods中为每个broker添加该机制。更新 JAAS 配置文件以包含这里描述的两种机制。增量反弹集群节点。
- 使用新机制重新启动客户端。
- 要更改broker间通信的机制(如果需要的话),将server.properties中的sasl.mechanism.inter.broker.protocol设置为新的机制,并再次增量反弹集群。
- 要删除旧机制(如果需要),请从server.properties中的sasl.enabled.misms中删除旧机制,并从JAAS配置文件中删除旧机制的条目。再次递增地弹出集群。
---------------------------
(9)使用授权令牌进行认证
基于委托令牌的身份验证是一种轻量级的身份验证机制,用于补充现有的SASL/SSL方法。委托令牌是kafkabroker和客户端之间的共享秘密。委托令牌将帮助处理框架在安全的环境中把工作负载分配给可用的工作者,而不需要在使用2-way SSL时增加分配Kerberos TGT/keytabs或密钥存储的成本。更多细节请参见 KIP-48。
授权令牌使用的典型步骤是
- 用户通过SASL或SSL对Kafka集群进行身份验证,并获得一个授权令牌。这可以使用Admin APIs或使用kafka-delegation-tokens.sh脚本来完成。
- 用户将授权令牌安全地传递给Kafka客户端,以便与Kafka集群进行身份验证。
- 令牌所有者/更新者可以更新/到期授权令牌。
1)Token管理
主密钥/秘密用于生成和验证授权令牌。这是由config选项digation.token.master.key提供的。必须在所有broker中配置相同的秘钥。如果秘钥没有设置或设置为空字符串,则broker将禁用授权令牌验证。
在当前的实现中,令牌的详细信息存储在Zookeeper中,适合在Zookeeper处于私有网络的Kafka安装中使用。另外,目前主密钥/秘密是以纯文本形式存储在server.properties配置文件中。我们打算在未来的Kafka版本中对其进行配置。
一个令牌有一个当前的寿命,和一个最大的可更新的寿命。默认情况下,令牌必须每24小时更新一次,最多7天。这些都可以使用 delegation.token.exp expiry.time.ms 和 delegation.token.max.life.ms 配置选项来配置。
也可以明确地取消令牌。如果一个令牌在到期时间前没有更新,或者令牌超过了最大生命期,它将从所有的broker缓存和zookeeper中删除。
2)创建授权令牌
可以通过使用管理API或使用kafka-delegation-tokens.sh脚本创建令牌。授权令牌请求(创建/更新/到期/描述)只能在SASL或SSL认证的通道上发出。如果初始认证是通过授权令牌完成的,则不能请求令牌。kafka-delegation-tokens.sh脚本示例如下。
创建一个授权令牌。
> bin/kafka-delegation-tokens.sh --bootstrap-server localhost:9092 --create --max-life-time-period -1 --command-config client.properties --renewer-principal User:user1
更新一个授权令牌。
> bin/kafka-delegation-tokens.sh --bootstrap-server localhost:9092 --renew --renew-time-period -1 --command-config client.properties --hmac ABCDEFGHIJK
过期一个授权令牌。
> bin/kafka-delegation-tokens.sh --bootstrap-server localhost:9092 --expire --expiry-time-period -1 --command-config client.properties --hmac ABCDEFGHIJK
可以使用--describe选项来描述现有的tokens。
> bin/kafka-delegation-tokens.sh --bootstrap-server localhost:9092 --describe --command-config client.properties --owner-principal User:user1
3)令牌认证
委托令牌认证搭载在当前的SASL/SCRAM认证机制上,我们必须在Kafka集群上启用SASL/SCRAM机制,如这里所述。我们必须在Kafka集群上启用SASL/SCRAM机制,如这里所述。
(1)配置Kafka客户端
在producer.properties或consumer.properties中为每个客户端配置JAAS配置属性。登录模块描述了生产者和消费者等客户端如何连接到Kafka Broker。下面是一个客户端的令牌认证的配置示例。
sasl.jaas.config=org.apache.kafka.common.security.scram.ScramLoginModule required \username="tokenID123" \password="lAYYSFmLs4bTjf+lTZ1LCHR/ZZFNA==" \tokenauth="true";
选项username和password是客户端用来配置token id和token HMAC的,而选项tokenauth是用来指示服务器关于token认证的。而选项tokenauth用于向服务器指示token认证。在本例中,客户端使用token id:tokenID123连接到broker。在一个JVM中,不同的客户端可以通过在sasl.jaas.config中指定不同的token细节,使用不同的token进行连接。
客户端的JAAS配置也可以指定为JVM参数,类似于这里描述的broker。客户端使用名为KafkaClient的登录部分。这个选项只允许一个用户从JVM的所有客户端连接。
4)手动旋转秘密的程序
当需要旋转秘密时,我们需要重新部署。在这个过程中,已经连接的客户端将继续工作。但任何新的连接请求和用旧的令牌更新/过期请求都可能失败。步骤如下。
- 过期所有现有令牌。
- 通过滚动升级来轮换秘密,并
- 生成新的Token
我们打算在未来的Kafka版本中实现自动化。
5)关于授权令牌的说明
目前,我们只允许一个用户只为该用户创建授权令牌。所有者/更新者可以更新或到期Token。所有者/更新者可以随时描述他们自己的Token。要描述其他Token,我们需要在Token资源上添加DESCRIBE权限。 macos/deepLFree.translatedWithDeepL.text
---------------------------
7.4 授权和ACL
Kafka提供了一个可插拔的Authorizer和一个开箱即用的Authorizer实现,它使用zookeeper来存储所有的acls。Authorizer通过在server.properties中设置authorizer.class.name进行配置。要启用开箱即用的实现,请使用。
- authorizer.class.name=kafka.security.authorizer.AclAuthorizer
Kafka acls的一般格式定义为 "Principal P is [Allowed/Denied] Operation O From Host H on any Resource R matching ResourcePattern RP"。您可以在KIP-11中阅读更多关于acl结构的内容,在KIP-290中阅读资源模式的内容。为了添加、删除或列出acl,你可以使用Kafka授权器CLI。默认情况下,如果没有资源模式(ResourcePatterns)与特定的资源R相匹配,那么R就没有相关的acl,因此除了超级用户之外,其他任何人都不允许访问R,如果你想改变这种行为,你可以在server.properties中包含以下内容。
- allow.everyone.if.no.acl.found=true
你也可以在server.properties中添加超级用户,如下所示(注意分号是分号,因为SSL用户名可能包含逗号)。默认的PrincipalType字符串 "User "是区分大小写的。
- super.users=User:Bob;User:Alice
自定义SSL用户名
默认情况下,SSL用户名的形式为 "CN=writeuser,OU=Unknown,O=Unknown,L=Unknown,ST=Unknown,C=Unknown"。可以通过在server.properties中设置ssl.principal.mapping.rules为自定义规则来改变。这个配置允许一个规则列表,用于将X.500区分名映射为短名。这些规则是按顺序评估的,第一个匹配的规则会被用来将其映射为短名。列表中后面的任何规则都会被忽略。
ssl.principal.mapping.rule的格式是一个列表,其中每条规则以 "rule: "开头,并包含一个表达式,格式如下。默认规则将返回X.500证书区分名的字符串表示。如果该名称与模式匹配,那么替换命令将在该名称上运行。这也支持小写/大写选项,以强制翻译结果为小写/大写。这可以通过在规则末尾添加"/L "或"/U "来实现。
RULE:pattern/replacement/RULE:pattern/replacement/[LU]
示例ssl.principal.mapping.规则值为。
RULE:^CN=(.*?),OU=ServiceUsers.*$/$1/,RULE:^CN=(.*?),OU=(.*?),O=(.*?),L=(.*?),ST=(.*?),C=(.*?)$/$1@$2/L,RULE:^.*[Cc][Nn]=([a-zA-Z0-9.]*).*$/$1/L,DEFAULT
以上规则将区别名称 "CN=serviceuser,OU=ServiceUsers,O=Unknown,L=Unknown,ST=Unknown,C=Unknown "翻译为 "serviceuser",将 "CN=adminUser,OU=Admin,O=Unknown,L=Unknown,ST=Unknown,C=Unknown "翻译为 "adminuser@admin"。
对于高级用例,可以通过在server.properties中设置一个自定义的PrincipalBuilder来自定义名称,如以下所示:
- principal.builder.class=CustomizedPrincipalBuilderClass
自定义SASL用户名
默认情况下, SASL 用户名是 Kerberos principal 的主要部分。可以通过在 server.properties 中将 sasl.kerberos.principal.to.local.rules 设置为自定义规则来改变。sasl.kerberos.principal.to.local.rules 的格式是一个列表, 其中每条规则的工作方式与 Kerberos 配置文件 (krb5.conf) 中的 auth_to_local 相同。这也支持额外的小写/大写规则, 以强制翻译结果全部为小写/大写。这是通过在规则的结尾添加 "/L" 或 "/U" 来实现的。 查看下面的语法格式。每条规则都以RULE:开头,包含一个表达式,格式如下。更多细节请参见 kerberos 文档。
RULE:[n:string](regexp)s/pattern/replacement/RULE:[n:string](regexp)s/pattern/replacement/gRULE:[n:string](regexp)s/pattern/replacement//LRULE:[n:string](regexp)s/pattern/replacement/g/LRULE:[n:string](regexp)s/pattern/replacement//URULE:[n:string](regexp)s/pattern/replacement/g/U
添加一个规则来正确地将user@MYDOMAIN.COM 翻译成用户,同时保留默认规则的例子是。
- sasl.kerberos.principal.to.local.rules=RULE:[1:$1@$0](.*@MYDOMAIN.COM)s/@.*//,DEFAULT
命令行接口
Kafka授权管理CLI可以在bin目录下和其他CLI一起找到。CLI脚本名为kafka-acls.sh。下面列出了该脚本支持的所有选项。
| 选项 | 描述 | 默认值 | 选项类别 |
|---|---|---|---|
| --add | 向脚本表示用户正在尝试添加一个ACL。 | Action | |
| --remove | 向脚本表明用户正在尝试删除一个cl。 | Action | |
| --list | 向脚本表示用户正在尝试列出acls。 | Action | |
| --authorizer | 授权人的全称类名称。 | kafka.security.authorizer.AclAuthorizer | Configuration |
| --authorizer-properties | key=val对,将被传递给authorizer进行初始化。对于默认的授权器,例子中的值是:zookeeper.connect=localhost:2181。 | Configuration | |
| --bootstrap-server | 用于建立与Kafka集群连接的主机/端口对列表。只能指定--bootstrap-server或--authorizer选项中的一个。 | Configuration | |
| --command-config | 一个包含要传递给管理客户端的配置的属性文件。这个选项只能和--bootstrap-server选项一起使用。 | Configuration | |
| --cluster | 向脚本表明,用户正试图在单个集群资源上与acls交互。 | ResourcePattern | |
| --topic [topic-name] | 向脚本表明用户正试图与acls就主题资源模式进行交互。 | ResourcePattern | |
| --group [group-name] | 向脚本表明,用户正试图与消费者组资源模式的acls交互。 | ResourcePattern | |
| --transactional-id [transactional-id] | 应该添加或删除ACL的transactionalId。值为*表示ACLs应该适用于所有transactionalIds。 | ResourcePattern | |
| --delegation-token [delegation-token] | 应添加或删除ACL的授权标记。值为*表示ACL应适用于所有标记。 | ResourcePattern | |
| --resource-pattern-type [pattern-type] |
向脚本表明用户希望使用的资源模式类型(用于--添加)或资源模式过滤器(用于--list和--remove)。 |
literal | Configuration |
| --allow-principal |
Principal为PrincipalType:name格式,将被添加到允许权限的ACL中。默认的PrincipalType字符串 "User "是区分大小写的。 |
Principal | |
| --deny-principal |
Principal为PrincipalType:name格式,将被添加到ACL的Deny权限中。默认 PrincipalType 字符串 "User" 是区分大小写的。 |
Principal | |
| --principal |
Principal是PrincipalType:name格式,将与-list选项一起使用。默认的PrincipalType字符串 "User "是区分大小写的。这将列出指定Principal的ACL。 |
Principal | |
| --allow-host | 在--allow-principal中列出的委托人可以访问的IP地址。 | if --allow-principal is specified defaults to * which translates to "all hosts" | Host |
| --deny-host | 拒绝访问 --deny-principal 中列出的 principals 的 IP 地址。 | if --deny-principal is specified defaults to * which translates to "all hosts" | Host |
| --operation |
|
All | Operation |
| --producer | 可以方便地添加/删除生产者角色的acls。这将生成允许写入、描述和创建主题的 acls。 | Convenience | |
| --consumer | 为消费者角色添加/删除 acls 的方便选项。这将生成允许READ、DESCRIBE on topic和READ on consumer-group的acls。 | Convenience | |
| --idempotent |
启用生产者的同位素。这应该与--producer选项结合使用。 |
Convenience | |
| --force | 方便的选项,对所有的查询都假定是,不做提示。 | Convenience | |
| --zk-tls-config-file | 标识ZooKeeper客户端TLS连接性属性的授权者定义的文件。除了下列属性之外的任何属性(无论是否有 "authorizer. "前缀)都会被忽略:zookeeper.clientCnxnSocket, zookeeper.ssl.cipher.suites, zookeeper.ssl.client.enable, zookeeper.ssl.crl.enable, zookeeper.ssl.enabled.protocols, zookeeper.ssl.endpoint.identification.algorithm, zookeeper.ssl.keystore.location, zookeeper.ssl.keystore.password, zookeeper.ssl.keystore.type, zookeeper.ssl.ocsp.enable, zookeeper.ssl.protocol, zookeeper.ssl.truststore.location, zookeeper.ssl.truststore.password, zookeeper.ssl.truststore.type | Configuration |
例子
添加Acls
假设你想添加一个 acl "Principals User:Bob 和 User:Alice are allowed to perform Operation Read and Write on Topic Test-Topic from IP 198.51.100.0 and IP 198.51.100.1"。您可以通过以下选项执行CLI。
bin/kafka-acls.sh --authorizer-properties zookeeper.connect=localhost:2181 --add --allow-principal User:Bob --allow-principal User:Alice --allow-host 198.51.100.0 --allow-host 198.51.100.1 --operation Read --operation Write --topic Test-topic。
默认情况下,所有没有明确的允许对资源进行访问操作的 acl 的 principal 都会被拒绝。在极少数情况下,如果定义了一个允许访问所有资源但不允许访问某些 principal 的 acl,我们将不得不使用 --deny-principal 和 --deny-host 选项。例如,如果我们想允许所有用户从Test-topic读取数据,但只拒绝来自IP 198.51.100.3的User:BadBob,我们可以使用以下命令。
- bin/kafka-acls.sh --authorizer-properties zookeeper.connect=localhost:2181 --add --allow-principal User:* --allow-host * --deny-principal User:BadBob --deny-host 198.51.100.3 --operation Read --topic Test-topic
请注意,--allow-host和--deny-host只支持IP地址(不支持主机名)。上面的例子通过指定--topic [topic-name]作为资源模式选项,将acls添加到一个主题中。同样,用户可以通过指定--cluster将acls添加到集群,通过指定--group [group-name]将acls添加到消费者组。你可以在任何特定类型的资源上添加acls,例如,假设你想添加一个acl "Principal User:Peter is allowed to produce to any Topic from IP 198.51.200.0",你可以通过使用通配符资源'*'来实现,例如,通过执行CLI的以下选项。
- bin/kafka-acls.sh --authorizer-properties zookeeper.connect=localhost:2181 --add --allow-principal User:Peter --allow-host 198.51.200.1 --producer --topic *
你可以在前缀资源模式上添加acl,例如,假设你想添加一个acl "Principal User:Jane is allowed to produce to any Topic whose name starts with 'Test-' from any host"。你可以通过以下选项执行CLI来实现。
- bin/kafka-acls.sh --authorizer-properties zookeeper.connect=localhost:2181 --add --allow-principal User:Jane --producer --topic Test- --resource-pattern-type prefixed
注意,--resource-pattern-type默认为 "literal",它只影响具有完全相同名称的资源,或者在通配符资源名称 "*"的情况下,影响具有任何名称的资源。
删除 Acls
删除acls的方法大同小异,唯一不同的是,用户必须指定--remove选项,而不是--add选项。唯一不同的是,用户必须指定--remove选项,而不是--add选项。要删除上面第一个例子中添加的acls,我们可以通过以下选项执行CLI。
- bin/kafka-acls.sh --authorizer-properties zookeeper.connect=localhost:2181 --remove --allow-principal User:Bob --allow-principal User:Alice --allow-host 198.51.100.0 --allow-host 198.51.100.1 --operation Read --operation Write --topic Test-topic
如果你想删除上面添加在前缀资源模式中的acl,我们可以通过以下选项执行CLI。
bin/kafka-acls.sh --authorizer-properties zookeeper.connect=localhost:2181 --remove --allow-principal User:Jane --producer --topic Test--resource-pattern-type Prefixed(前缀资源模式)
List Acls
我们可以通过指定资源的 --list 选项来列出任何资源的 acls。要列出Test-topic这个资源模式的所有acls,我们可以通过以下选项执行CLI。
- bin/kafka-acls.sh --authorizer-properties zookeeper.connect=localhost:2181 --list --topic Test-topic
但是,这将只返回已经添加到这个资源模式的 acls。其他的 acls 可能会影响对主题的访问,例如,主题通配符 '*' 上的任何 acls,或者前缀资源模式上的任何 acls。通配符资源模式上的acls可以被显式查询。
- bin/kafka-acls.sh --authorizer-properties zookeeper.connect=localhost:2181 --list --topic *
然而,不一定能明确地查询与 Test-topic 匹配的前缀资源模式的 acls,因为这些模式的名称可能不知道。我们可以使用'--resource-pattern-type match'来列出所有影响Test-topic的acls,如
- bin/kafka-acls.sh --authorizer-properties zookeeper.connect=localhost:2181 --list --topic Test-topic --resource-pattern-type match
这将列出所有匹配的文字、通配符和前缀资源模式的acls。 macos/deepLFree.translatedWithDeepL.text
增加或删除作为生产者或消费者的委托人
在 acl 管理中,最常见的使用情况是添加/删除一个委托人作为生产者或消费者,所以我们添加了方便的选项来处理这些情况。为了添加User:Bob作为Test-topic的生产者,我们可以执行以下命令。
- bin/kafka-acls.sh --authorizer-properties zookeeper.connect=localhost:2181 --add --allow-principal User:Bob --producer --topic Test-topic
同样的,如果要添加Alice作为Test-topic的消费者,并加入消费者组Group-1,我们只需要通过--consumer选项。
- bin/kafka-acls.sh --authorizer-properties zookeeper.connect=localhost:2181 --add --allow-principal User:Bob --consumer --topic Test-topic --group Group-1
请注意,对于消费者选项,我们还必须指定消费者组。为了从生产者或消费者角色中移除一个委托人,我们只需要传递--remove选项。
基于管理API的ACL管理
在ClusterResource上拥有Alter权限的用户可以使用Admin API来管理ACL。kafka-acls.sh脚本支持AdminClient API来管理ACL,而不需要直接与zookeeper/authorizer交互。以上所有的例子都可以通过使用--bootstrap-server选项来执行。例如
bin/kafka-acls.sh --bootstrap-server localhost:9092 --command-config /tmp/adminclient-configs.conf --add --allow-principal User:Bob --producer --topic Test-topicbin/kafka-acls.sh --bootstrap-server localhost:9092 --command-config /tmp/adminclient-configs.conf --add --allow-principal User:Bob --consumer --topic Test-topic --group Group-1bin/kafka-acls.sh --bootstrap-server localhost:9092 --command-config /tmp/adminclient-configs.conf --list --topic Test-topic
授权基元
协议调用通常是对Kafka中的某些资源进行一些操作。需要了解这些操作和资源,才能设置有效的保护。在本节中,我们将列出这些操作和资源,然后列出这些操作和资源与协议的组合,看看有效的场景。
kafka中的操作
有一些操作基元可以用来建立权限。这些操作可与某些资源相匹配,以允许特定用户进行特定协议调用。这些资源是:
- Read
- Write
- Create
- Delete
- Alter
- Describe
- ClusterAction
- DescribeConfigs
- AlterConfigs
- IdempotentWrite
- All
kafka中的资源
上面的操作可以应用在某些资源上,下面将对这些资源进行说明。
- Topic:这只是代表一个Topic。所有对topic进行操作(如读、写)的协议调用都需要添加相应的权限。如果一个topic资源出现授权错误,那么将返回一个TOPIC_AUTHORIZATION_FAILED(错误代码:29)。
- Group:这代表了broker中的消费者组。所有与消费者组一起工作的协议调用,比如加入一个组,必须在主题中拥有组的权限。如果没有给定权限,那么协议响应中会返回一个GROUP_AUTHORIZATION_FAILED(错误代码:30)。
- Cluster:该资源代表集群。影响整个集群的操作,比如受控关机,都是由Cluster资源上的权限保护的。如果集群资源上存在授权问题,那么将返回一个CLUSTER_AUTHORIZATION_FAILED(错误代码:31)。
- TransactionalId:这个资源表示与事务相关的操作,比如提交。如果发生任何错误,那么broker将返回一个TRANSACTIONAL_ID_AUTHORIZATION_FAILED(错误代码:53)。
- DelegationToken:这代表集群中的授权令牌。诸如描述授权令牌的行为可以通过对DelegationToken资源的权限来保护。由于这些对象在Kafka中的行为有点特殊,建议阅读KIP-48和相关的上游文档,在Authentication using Delegation Tokens。
关于议定书的业务和资源
在下面的表格中,我们将列出Kafka API协议执行的对资源的有效操作:
| 协议(API KEY) | 操作 | 资源 | 备注 |
|---|---|---|---|
| PRODUCE (0) | Write | TransactionalId |
一个设置了transactional.id的事务生产者需要这个权限。 |
| PRODUCE (0) | IdempotentWrite | Cluster |
幂等的产生行动需要这种特权。 |
| PRODUCE (0) | Write | Topic |
这适用于正常的生产动作。 |
| FETCH (1) | ClusterAction | Cluster |
追随者必须在Cluster资源上有ClusterAction,才能获取分区数据。 |
| FETCH (1) | Read | Topic |
常规的Kafka消费者需要在他们获取的每个分区上获得READ权限。 |
| LIST_OFFSETS (2) | Describe | Topic | |
| METADATA (3) | Describe | Topic | |
| METADATA (3) | Create | Cluster |
如果启用了topic自动创建,那么broker端API将检查是否存在Cluster级别的权限。如果找到了,那么就会允许创建主题,否则就会遍历主题级别的权限(见下一个)。 |
| METADATA (3) | Create | Topic |
如果启用了自动创建主题,但给定的用户没有群集级别的权限(以上),这将授权自动创建主题。 |
| LEADER_AND_ISR (4) | ClusterAction | Cluster | |
| STOP_REPLICA (5) | ClusterAction | Cluster | |
| UPDATE_METADATA (6) | ClusterAction | Cluster | |
| CONTROLLED_SHUTDOWN (7) | ClusterAction | Cluster | |
| OFFSET_COMMIT (8) | Read | Group |
一个偏移只有在被授权给给定的组和主题时才能被提交(见下文)。首先检查组的访问权,然后检查主题的访问权。 |
| OFFSET_COMMIT (8) | Read | Topic |
由于偏移提交是消耗过程的一部分,所以它需要有读取操作的权限。 |
| OFFSET_FETCH (9) | Describe | Group |
与OFFSET_COMMIT类似,应用程序也必须有组和主题级别的权限才能获取。然而在这种情况下,它需要的是描述访问而不是读取。首先检查组的访问权限,然后检查主题的访问权限。 |
| OFFSET_FETCH (9) | Describe | Topic | |
| FIND_COORDINATOR (10) | Describe | Group |
FIND_COORDINATOR请求可以是 "Group "类型,在这种情况下,它是在寻找消费者组协调人。这个特权将代表Group模式。 |
| FIND_COORDINATOR (10) | Describe | TransactionalId |
这只适用于事务性生产者,当生产者试图寻找事务协调人时,会被检查。 |
| JOIN_GROUP (11) | Read | Group | |
| HEARTBEAT (12) | Read | Group | |
| LEAVE_GROUP (13) | Read | Group | |
| SYNC_GROUP (14) | Read | Group | |
| DESCRIBE_GROUPS (15) | Describe | Group | |
| LIST_GROUPS (16) | Describe | Cluster |
当broker检查授权一个list_groups请求时,它首先检查这个群集级别的授权。如果没有找到,那么它就继续逐个检查各组。这个操作不会返回CLUSTER_AUTHORIZATION_FAILED。 |
| LIST_GROUPS (16) | Describe | Group |
如果没有任何一个组被授权,那么只会返回一个空的响应,而不是一个错误。这个操作不会返回CLUSTER_AUTHORIZATION_FAILED。这是从2.1版本开始适用的。 |
| SASL_HANDSHAKE (17) |
SASL握手是认证过程的一部分,因此这里不可能应用任何形式的授权。 |
||
| API_VERSIONS (18) |
API_VERSIONS请求是Kafka协议握手的一部分,发生在连接时和任何认证之前。因此不可能通过授权来控制。 |
||
| CREATE_TOPICS (19) | Create | Cluster |
如果没有集群级别的授权,那么就不会返回CLUSTER_AUTHORIZATION_FAILED,而是回落到使用主题级别,也就是下面。如果有问题的话,那就会抛出错误。 |
| CREATE_TOPICS (19) | Create | Topic |
这是从2.0版本开始适用的。 |
| DELETE_TOPICS (20) | Delete | Topic | |
| DELETE_RECORDS (21) | Delete | Topic | |
| INIT_PRODUCER_ID (22) | Write | TransactionalId | |
| INIT_PRODUCER_ID (22) | IdempotentWrite | Cluster | |
| OFFSET_FOR_LEADER_EPOCH (23) | ClusterAction | Cluster |
如果这个操作没有群集级别的权限,那么就会检查主题一级。 |
| OFFSET_FOR_LEADER_EPOCH (23) | Describe | Topic |
这是从2.1版本开始适用的。 |
| ADD_PARTITIONS_TO_TXN (24) | Write | TransactionalId |
这个API只适用于事务性请求。它首先检查TransactionalId资源上的写操作,然后检查主题中的Topic(如下)。 |
| ADD_PARTITIONS_TO_TXN (24) | Write | Topic | |
| ADD_OFFSETS_TO_TXN (25) | Write | TransactionalId |
与ADD_PARTITIONS_TO_TXN类似,它只适用于事务性请求。它首先检查TransactionalId资源上是否有写操作,然后检查是否可以在给定的组上进行读操作(如下)。 |
| ADD_OFFSETS_TO_TXN (25) | Read | Group | |
| END_TXN (26) | Write | TransactionalId | |
| WRITE_TXN_MARKERS (27) | ClusterAction | Cluster | |
| TXN_OFFSET_COMMIT (28) | Write | TransactionalId | |
| TXN_OFFSET_COMMIT (28) | Read | Group | |
| TXN_OFFSET_COMMIT (28) | Read | Topic | |
| DESCRIBE_ACLS (29) | Describe | Cluster | |
| CREATE_ACLS (30) | Alter | Cluster | |
| DELETE_ACLS (31) | Alter | Cluster | |
| DESCRIBE_CONFIGS (32) | DescribeConfigs | Cluster |
如果broker配置被请求,那么broker将检查集群级别的权限。 |
| DESCRIBE_CONFIGS (32) | DescribeConfigs | Topic |
如果请求主题配置,那么broker将检查主题级别的权限。 |
| ALTER_CONFIGS (33) | AlterConfigs | Cluster |
如果broker配置被改变,那么broker将检查集群级别的权限。 |
| ALTER_CONFIGS (33) | AlterConfigs | Topic |
如果话题配置被更改,那么broker将检查话题级别的权限。 |
| ALTER_REPLICA_LOG_DIRS (34) | Alter | Cluster | |
| DESCRIBE_LOG_DIRS (35) | Describe | Cluster |
授权失败时将返回一个空的响应。 |
| SASL_AUTHENTICATE (36) |
SASL_AUTHENTICATE是认证过程的一部分,因此这里不可能应用任何形式的授权。 |
||
| CREATE_PARTITIONS (37) | Alter | Topic | |
| CREATE_DELEGATION_TOKEN (38) |
创建授权令牌有特殊的规则,关于这一点,请参见使用授权令牌的认证部分。 |
||
| RENEW_DELEGATION_TOKEN (39) |
更新授权令牌有特殊的规则,关于这一点,请参见使用授权令牌的认证部分。 |
||
| EXPIRE_DELEGATION_TOKEN (40) |
过期的授权令牌有特殊的规则,关于这一点,请参见使用授权令牌的认证部分。 |
||
| DESCRIBE_DELEGATION_TOKEN (41) | Describe | DelegationToken |
描述授权令牌有特殊的规则,关于这一点请参见使用授权令牌的认证部分。 |
| DELETE_GROUPS (42) | Delete | Group | |
| ELECT_PREFERRED_LEADERS (43) | ClusterAction | Cluster | |
| INCREMENTAL_ALTER_CONFIGS (44) | AlterConfigs | Cluster |
如果broker配置被改变,那么broker将检查集群级别的权限。 |
| INCREMENTAL_ALTER_CONFIGS (44) | AlterConfigs | Topic |
如果话题配置被更改,那么broker将检查话题级别的权限。 |
| ALTER_PARTITION_REASSIGNMENTS (45) | Alter | Cluster | |
| LIST_PARTITION_REASSIGNMENTS (46) | Describe | Cluster | |
| OFFSET_DELETE (47) | Delete | Group | |
| OFFSET_DELETE (47) | Read | Topic |
------------------------------
7.5 在运行的群集中加入安全功能
您可以通过前面讨论的一个或多个支持的协议来保护正在运行的群集。这是分阶段进行的。
- 逐步反弹群集节点以打开额外的安全端口。
- 使用安全端口而非 PLAINTEXT 端口重新启动客户端(假设您正在确保客户端-代理连接的安全)。
- 再次递增反弹群集,以启用代理对代理的安全(如果需要的话)。
- 最后增量弹出,关闭PLAINTEXT端口。
配置SSL和SASL的具体步骤在7.2和7.3节中描述。按照这些步骤为您所需的协议启用安全功能。
安全性实现允许您为代理-客户和代理-代理通信配置不同的协议。这些协议必须在单独的弹跳中启用。PLAINTEXT端口必须在整个过程中保持开放,以便broker和/或客户可以继续通信。
当执行增量反弹时,通过SIGTERM干净利落地停止broker。在进入下一个节点之前,等待重启的副本返回到ISR列表也是一个好的做法。
举个例子,比如说我们希望用SSL加密broker-客户和broker-broker的通信。在第一次增量反弹中,每个节点上都会打开一个SSL端口。
listeners=PLAINTEXT://broker1:9091,SSL://broker1:9092
然后我们重启客户机,修改他们的配置指向新打开的安全端口。
bootstrap.servers = [broker1:9092,...]security.protocol = SSL...etc
在第二次增量服务器跳转中,我们指示Kafka使用SSL作为broker-broker协议(将使用相同的SSL端口)。
listeners=PLAINTEXT://broker1:9091,SSL://broker1:9092security.inter.broker.protocol=SSL
在最后的反弹中,我们通过关闭PLAINTEXT端口来保证集群的安全。
listeners=SSL://broker1:9092security.inter.broker.protocol=SSL
另外,我们也可以选择开放多个端口,以便不同的协议可以用于broker-broker和broker-客户端的通信。假设我们希望在整个过程中使用 SSL 加密(即用于 broker-broker 和 broker-client 通信),但我们也希望在 broker-client 连接中添加 SASL 认证。我们将通过在第一次跳转时打开两个额外的端口来实现。
listeners=PLAINTEXT://broker1:9091,SSL://broker1:9092,SASL_SSL://broker1:9093
然后我们重启客户机,修改他们的配置指向新打开的SASL和SSL安全端口。
bootstrap.servers = [broker1:9093,...]security.protocol = SASL_SSL...etc
第二次服务器跳转会将集群切换到使用加密的broker-broker通信,通过我们之前开通的SSL端口9092端口。
listeners=PLAINTEXT://broker1:9091,SSL://broker1:9092,SASL_SSL://broker1:9093security.inter.broker.protocol=SSL
最后反弹通过关闭PLAINTEXT端口来保证集群的安全。
listeners=SSL://broker1:9092,SASL_SSL://broker1:9093security.inter.broker.protocol=SSL
ZooKeeper可以独立于Kafka集群而被保护。这样做的步骤在7.6.2节中介绍。
----------------------
7.6 ZooKeeper认证
ZooKeeper从3.5.x版本开始支持相互TLS(mTLS)认证。Kafka支持使用SASL和mTLS对ZooKeeper进行身份验证--可以单独使用,也可以同时使用--从2.5版本开始。参见KIP-515: 启用ZK客户端使用新的TLS支持的身份验证了解更多细节。
当单独使用mTLS时,每个代理和任何CLI工具(如ZooKeeper安全迁移工具)应该用相同的区别名称(DN)来识别自己,因为它是ACL'ed的DN。这可以按照下面的描述进行更改,但这涉及到编写和部署一个自定义的ZooKeeper验证提供商。一般来说,每个证书都应该有相同的DN,但有不同的主题替代名(SAN),这样ZooKeeper对broker和任何CLI工具的主机名验证就会成功。
当使用SASL认证到ZooKeeper与mTLS一起使用时,SASL身份和创建znode的DN(即创建broker的证书)或安全迁移工具的DN(如果迁移是在znode创建后进行的)将被ACL'ed,所有broker和CLI工具将被授权,即使他们都使用不同的DN,因为他们都将使用相同的ACL'ed SASL身份。只有当单独使用mTLS身份验证时,所有的DN必须匹配(SAN变得至关重要--同样,在没有编写和部署自定义ZooKeeper身份验证提供商的情况下,如下所述)。
使用broker属性文件为broker设置TLS配置,如下所述。
使用--zk-tls-config-file <file>选项在Zookeeper安全迁移工具中设置TLS配置。kafka-acls.sh和kafka-configs.sh CLI工具也支持--zk-tls-config-file <file>选项。
使用-zk-tls-config-file <file>选项(注意是单斜线而不是双斜线)为zookeeper-shell.sh CLI工具设置TLS配置。
7.6.1 新的集群
7.6.1.1 ZooKeeper SASL认证
要在broker上启用ZooKeeper SASL认证,有两个必要的步骤。
- 创建一个JAAS登录文件,并设置相应的系统属性指向它,如上所述。
- 将每个broker的配置属性zookeeper.set.acl设置为true。
存储在ZooKeeper中的Kafka集群的元数据是世界可读的,但只能由broker修改。这个决定背后的理由是,存储在ZooKeeper中的数据并不敏感,但对这些数据的不当操作会导致集群中断。我们还建议通过网络分段限制对ZooKeeper的访问(只有broker和一些管理工具需要访问ZooKeeper)。
7.6.1.2 ZooKeeper相互TLS认证
ZooKeeper的mTLS认证可以在有或没有SASL认证的情况下启用。如上所述,当单独使用mTLS时,每个broker和任何CLI工具(如ZooKeeper安全迁移工具)一般都必须用相同的区分名(DN)来标识自己,因为是DN被ACL'ed,这意味着每个证书都应该有一个合适的Subject Alternative Name(SAN),这样ZooKeeper对broker和任何CLI工具的主机名验证才能成功。
可以通过编写一个扩展 org.apache.zookeeper.server.auth.X509AuthenticationProvider 的类,并覆盖 protected String getClientId(X509Certificate clientCert)的方法,来使用 DN 以外的其他东西作为 mTLS 客户的身份。选择一个方案名,并在ZooKeeper中设置authProvider.[scheme]为自定义实现的全限定类名;然后设置ssl.authProvider=[scheme]来使用它。
这里是ZooKeeper启用TLS认证的一个示例(部分)配置。这些配置在ZooKeeper管理指南中有所描述。
secureClientPort=2182serverCnxnFactory=org.apache.zookeeper.server.NettyServerCnxnFactoryauthProvider.x509=org.apache.zookeeper.server.auth.X509AuthenticationProviderssl.keyStore.location=/path/to/zk/keystore.jksssl.keyStore.password=zk-ks-passwdssl.trustStore.location=/path/to/zk/truststore.jksssl.trustStore.password=zk-ts-passwd
重要提示:ZooKeeper不支持将ZooKeeper服务器keystore中的密钥密码设置为与keystore密码本身不同的值。请务必将密钥密码设置为与keystore密码相同。
这里是一个使用mTLS认证连接到ZooKeeper的Kafka Broker配置示例(部分)。这些配置在上面的Broker Configs里有描述:
# connect to the ZooKeeper port configured for TLSzookeeper.connect=zk1:2182,zk2:2182,zk3:2182# required to use TLS to ZooKeeper (default is false)zookeeper.ssl.client.enable=true# required to use TLS to ZooKeeperzookeeper.clientCnxnSocket=org.apache.zookeeper.ClientCnxnSocketNetty# define key/trust stores to use TLS to ZooKeeper; ignored unless zookeeper.ssl.client.enable=truezookeeper.ssl.keystore.location=/path/to/kafka/keystore.jkszookeeper.ssl.keystore.password=kafka-ks-passwdzookeeper.ssl.truststore.location=/path/to/kafka/truststore.jkszookeeper.ssl.truststore.password=kafka-ts-passwd# tell broker to create ACLs on znodeszookeeper.set.acl=true
重要提示:ZooKeeper不支持将ZooKeeper客户端(即broker)keystore中的密钥密码设置为与keystore密码本身不同的值。请务必将密钥密码设置为与keystore密码相同。
7.6.2 迁移群组
如果你运行的Kafka版本不支持安全,或者只是禁用了安全功能,而你又想让集群变得安全,那么你需要执行以下步骤来启用ZooKeeper身份验证,并尽量减少对你的操作的干扰。
- 在ZooKeeper上启用SASL和/或mTLS认证。如果启用mTLS,你现在会有一个非TLS端口和一个TLS端口,像这样
-
clientPort=2181secureClientPort=2182serverCnxnFactory=org.apache.zookeeper.server.NettyServerCnxnFactoryauthProvider.x509=org.apache.zookeeper.server.auth.X509AuthenticationProviderssl.keyStore.location=/path/to/zk/keystore.jksssl.keyStore.password=zk-ks-passwdssl.trustStore.location=/path/to/zk/truststore.jksssl.trustStore.password=zk-ts-passwd
-
- 根据需要对brokers进行滚动重启,设置JAAS登录文件和/或定义ZooKeeper相互的TLS配置(包括连接到启用TLS的ZooKeeper端口),这使得brokers能够对ZooKeeper进行认证。在滚动重启结束时,broker能够用严格的ACL操纵znodes,但他们不会用这些ACL创建znodes。
- 如果您启用了mTLS,请在ZooKeeper中禁用非TLS端口。
- 对brokers进行第二次滚动重启,这次将配置参数zookeeper.set.acl设置为true,这样可以在创建znodes时使用安全的ACL。
- 执行ZkSecurityMigrator工具。要执行这个工具,有这样一个脚本:bin/zookeeper-security-migration.sh,其中zookeeper.acl设置为secure。这个工具会遍历相应的子树,改变znodes的ACL。如果你启用了mTLS,请使用--zk-tls-config-file <file>选项。
也可以在安全集群中关闭身份验证。要做到这一点,请按照以下步骤进行:
- 对设置JAAS登录文件和/或定义ZooKeeper相互TLS配置的brokers进行滚动重启,使brokers能够进行身份验证,但将zookeeper.set.acl设置为false。在滚动重启结束时,broker停止创建具有安全ACL的znodes,但仍然能够验证和操作所有znodes。
- 执行ZkSecurityMigrator工具。要执行该工具,运行这个脚本 bin/zookeeper-security-migration.sh,并将zookeeper.acl设置为unsecure。这个工具会遍历相应的子树,改变znodes的ACL。如果你需要设置TLS配置,请使用--zk-tls-config-file <file>选项。
- 如果你禁用mTLS,请在ZooKeeper中启用非TLS端口。
- 对brokers进行第二次滚动重启,这次省略设置JAAS登录文件的系统属性和/或按要求删除ZooKeeper相互TLS配置(包括连接到未启用TLS的ZooKeeper端口)。
- 如果您正在禁用mTLS,请在ZooKeeper中禁用TLS端口。
下面是一个如何运行迁移工具的例子:
bin/zookeeper-security-migration.sh --zookeeper.acl=secure --zookeeper.connect=localhost:2181
运行此功能可查看完整的参数列表。
bin/zookeeper-security-migration.sh --help
7.6.3 迁移ZooKeeper合集
还需要在ZooKeeper合集上启用SASL和/或mTLS认证。要做到这一点,我们需要执行服务器的滚动重启并设置一些属性。请看上面的mTLS信息。更多细节请参考ZooKeeper文档。
- Apache ZooKeeper文档
- Apache ZooKeeper wiki
7.6.4 ZooKeeper Quorum Mutual TLS认证
可以启用ZooKeeper服务器之间的mTLS认证。更多细节请参考ZooKeeper文件。
7.7 ZooKeeper加密
ZooKeeper使用相互TLS的连接是加密的。从ZooKeeper 3.5.7版本开始(Kafka 2.5版本附带的版本),ZooKeeper支持server端配置ssl.clientAuth(不区分大小写:want/need/none为有效选项,默认为need),在ZooKeeper中把这个值设置为none,允许客户端通过TLS加密的连接,而不需要出示自己的证书。这里是一个仅用TLS加密连接到ZooKeeper的Kafka Broker配置示例(部分)。这些配置在上面的Broker Configs里有描述。
# connect to the ZooKeeper port configured for TLSzookeeper.connect=zk1:2182,zk2:2182,zk3:2182# required to use TLS to ZooKeeper (default is false)zookeeper.ssl.client.enable=true# required to use TLS to ZooKeeperzookeeper.clientCnxnSocket=org.apache.zookeeper.ClientCnxnSocketNetty# define trust stores to use TLS to ZooKeeper; ignored unless zookeeper.ssl.client.enable=true# no need to set keystore information assuming ssl.clientAuth=none on ZooKeeperzookeeper.ssl.truststore.location=/path/to/kafka/truststore.jkszookeeper.ssl.truststore.password=kafka-ts-passwd# tell broker to create ACLs on znodes (if using SASL authentication, otherwise do not set this)zookeeper.set.acl=true
8. KAFKA CONNECT
8.1 概述
Kafka Connect是一个用于在Apache Kafka和其他系统之间可扩展和可靠地流式数据的工具。它使快速定义连接器变得简单,这些连接器可以将大量的数据集合移入和移出Kafka。Kafka Connect可以从您的所有应用服务器中摄取整个数据库或收集指标到Kafka主题中,使数据可用于低延迟的流处理。导出作业可以将Kafka主题中的数据传送到二级存储和查询系统中,或者传送到批处理系统中进行离线分析。
Kafka Connect的功能包括:
- Kafka连接器的通用框架--Kafka Connect标准化了其他数据系统与Kafka的集成,简化了连接器的开发、部署和管理。
- 分布式和独立模式--扩大到支持整个组织的大型集中管理服务,或缩小到开发、测试和小型生产部署。
- REST接口--通过一个易于使用的REST API提交和管理连接器到您的Kafka Connect集群。
- 自动偏移管理--只需从连接器中获取一点信息,Kafka Connect就能自动管理偏移提交过程,因此连接器开发人员无需担心连接器开发中容易出错的部分。
- 默认的分布式和可扩展性--Kafka Connect建立在现有的组管理协议上。可以添加更多的工作者来扩展Kafka Connect集群。
- 流式/批处理集成--利用Kafka现有的功能,Kafka Connect是衔接流式和批处理数据系统的理想解决方案。
8.2 用户指南
快速入门提供了一个简短的例子,说明如何运行独立版本的Kafka Connect。本节将详细介绍如何配置、运行和管理Kafka Connect。
运行Kafka连接
Kafka Connect目前支持两种执行模式:独立模式(单进程)和分布式模式。
在独立模式下,所有的工作都在一个进程中执行。这种配置更容易设置和上手,在只有一个worker的情况下可能很有用(例如收集日志文件),但它不能从Kafka Connect的一些功能中受益,例如容错。您可以使用以下命令启动一个独立的进程。
- > bin/connect-standalone.sh config/connect-standalone.properties connector1.properties [connector2.properties ...]
第一个参数是worker的配置。这包括诸如Kafka连接参数、序列化格式以及提交偏移的频率等设置。所提供的示例在使用config/server.properties提供的默认配置运行的本地集群中应该可以很好地工作。它将需要调整以用于不同的配置或生产部署。所有的工作者(包括单机和分布式)都需要一些配置。
- bootstrap.server - 用于引导连接到Kafka的Kafka服务器列表。
- key.converter - 转换器类,用于在Kafka Connect格式和写入Kafka的序列化形式之间进行转换。这控制了向Kafka写入或从Kafka读取的消息中键的格式,由于这与连接器无关,所以允许任何连接器与任何序列化格式一起工作。常见格式的例子包括JSON和Avro。
- value.converter - 转换器类,用于在Kafka Connect格式和写入Kafka的序列化形式之间进行转换。这控制了向Kafka写入或从Kafka读取的消息中的值的格式,由于这与连接器无关,它允许任何连接器与任何序列化格式一起工作。常见格式的例子包括JSON和Avro。
- 单机模式特有的重要配置选项是。
offset.storage.file.filename - 要在其中存储偏移数据的文件。
这里配置的参数是为了让Kafka Connect使用的生产者和消费者访问配置、偏移和状态主题。对于Kafka源任务使用的生产者和Kafka汇任务使用的消费者的配置,可以使用相同的参数,但需要分别以producer.和consumer.为前缀。唯一一个从worker配置中继承的没有前缀的Kafka客户端参数是bootstrap.servers,在大多数情况下,这就足够了,因为经常使用同一个集群来实现所有目的。一个明显的例外是安全集群,它需要额外的参数来允许连接。这些参数最多需要在worker配置中设置三次,一次用于管理访问,一次用于Kafka源,一次用于Kafka汇。
从2.3.0开始,客户端配置覆盖可以通过使用前缀producer.override.和consumer.override.分别为Kafka源或Kafka汇单独配置每个连接器。这些覆盖项与连接器的其他配置属性一起包含在其中。
其余的参数是连接器的配置文件。你可以包含任意多的配置文件,但所有的配置文件都会在同一个进程中执行(在不同的线程上)。
分布式模式处理工作的自动平衡,允许您动态地扩大(或缩小)规模,并在活动任务中以及对配置和偏移提交数据提供容错。执行方式与单机模式非常相似。
- > bin/connect-distributed.sh config/connect-distributed.properties
区别在于启动的类和配置参数,这些参数改变了Kafka Connect进程如何决定在哪里存储配置、如何分配工作以及在哪里存储偏移量和任务状态。在分布式模式下,Kafka Connect将偏移量、配置和任务状态存储在Kafka主题中。建议手动创建偏移、配置和状态的主题,以达到所需的分区数量和复制因子。如果在启动Kafka Connect时还没有创建主题,主题将以默认的分区数和复制因子自动创建,这可能不是最适合它的使用。
特别是,除了上面提到的常用设置外,以下配置参数是启动集群前必须设置的关键。
- group.id(默认的connect-cluster)--群集的唯一名称,用于组建Connect群集群组;注意不能与消费者群组ID冲突。
- config.storage.topic(默认的connect-configs)--用于存储连接器和任务配置的topic;请注意,这应该是一个单一分区、高度复制、压缩的topic。您可能需要手动创建主题以确保正确的配置,因为自动创建的主题可能有多个分区或自动配置为删除而不是压缩
- offset.storage.topic (默认连接-offsets) - 用于存储偏移量的topic;这个topic应该有很多分区,可以复制,并配置为压实。
- status.storage.topic (默认的connect-status) - 用于存储状态的topic;这个topic可以有多个分区,并且应该被复制和配置为压实。
请注意,在分布式模式下,连接器配置不会在命令行中传递。相反,使用下面描述的REST API来创建、修改和销毁连接器。
配置连接器
连接器配置是简单的键值映射。对于单机模式,这些配置在属性文件中定义,并在命令行上传递给Connect进程。在分布式模式下,它们将包含在创建(或修改)连接器的请求的JSON有效载荷中。
大多数配置都是依赖于连接器的,所以不能在这里概述。然而,有几个常见的选项。
- name -连接器的唯一名称。试图用相同的名称再次注册将失败。
- connector.class - 连接器的Java类。
- tasks.max - 该连接器应创建的最大任务数。如果连接器不能达到这个级别的并行性,则可能会创建更少的任务。
- key.converter - (可选) 覆盖worker设置的默认key转换器。
- value.converter - (可选) 覆盖worker设置的默认值转换器。
connector.class配置支持以下几种格式:该连接器的类的全名或别名。如果连接器是org.apache.kafka.connect.file.FileStreamSinkConnector,你可以指定这个全名,或者使用FileStreamSink或FileStreamSinkConnector来使配置更短一些。
sink connector也有一些额外的选项来控制它们的输入。每个sink都必须设置以下内容之一。
- topics - 一个以逗号分隔的主题列表,用来作为这个连接器的输入。
- topics.regex - 主题的Java正则表达式,用来作为这个连接器的输入。
对于任何其他选项,您应该查阅连接器的文档。
Transformations
连接器可以通过转换配置来进行轻量级的一次消息修改。它们可以方便地进行数据群发和事件路由。
可以在连接器配置中指定一个转换链。
- transforms - 变换的别名列表,指定应用变换的顺序。
- transforms.$alias.type - 变换的完全限定类名。
- transforms.$alias.$transformationSpecificConfig - 变换的配置属性。
例如,让我们使用内置的文件源连接器,并使用转换来添加一个静态字段。
在整个例子中,我们将使用无模式JSON数据格式。为了使用无模式格式,我们将connect-standalone.properties中的以下两行从true改为false。
- key.converter.schemas.enable
- value.converter.schemas.enable
文件源连接器将每一行作为一个字符串读取。我们将把每一行都包在一个Map中,然后添加第二个字段来识别事件的起源。要做到这一点,我们使用两个转换。
- HoistField将输入行放在Map中
- InsertField来添加静态字段。在这个例子中,我们将指出该记录来自一个文件连接器
添加转换后,connect-file-source.properties文件如下。
- name=local-file-source
- connector.class=FileStreamSource
- tasks.max=1
- file=test.txt
- topic=connect-test
- transforms=MakeMap, InsertSource
- transforms.MakeMap.type=org.apache.kafka.connect.transforms.HoistField$Value
- transforms.MakeMap.field=line
- transforms.InsertSource.type=org.apache.kafka.connect.transforms.InsertField$Value
- transforms.InsertSource.static.field=data_source
- transforms.InsertSource.static.value=test-file-source
所有以transform开头的线条都是为变换而添加的。你可以看到我们创建的两个变换。"InsertSource "和 "MakeMap "是我们选择给变换的别名。变换类型是基于你可以看到下面的内置变换列表。每个变换类型都有额外的配置。HoistField需要一个名为 "field "的配置,它是地图中字段的名称,将包含文件中的原始String。InsertField转换让我们指定字段名和我们要添加的值。
当我们在我的示例文件上运行没有转化的文件源连接器,然后使用kafka-console-consumer.sh读取它们,结果是:
- "foo"
- "bar"
- "hello world"
然后,我们创建一个新的文件连接器,这次是在配置文件中添加变换后。这一次,结果将是。
- {"line":"foo","data_source":"test-file-source"}
- {"line":"bar","data_source":"test-file-source"}
- {"line":"hello world","data_source":"test-file-source"}
你可以看到,我们已经读取的行现在是JSON映射的一部分,并且有一个额外的字段与我们指定的静态值。这只是一个例子,说明你可以通过转换来实现。
内置转换
Kafka Connect中包含了一些广泛适用的数据和路由转换。
- InsertField - 使用静态数据或记录元数据添加字段。
- ReplaceField - 筛选或重命名字段
- MaskField - 用有效的空值(0,空字符串等)或自定义替换(非空字符串或数值)替换字段。
- ValueToKey - 用记录值中的字段子集形成的新键替换记录键。
- HoistField - 将整个事件作为一个单独的字段包在Struct或Map中。
- ExtractField - 从Struct和Map中提取一个特定的字段,并在结果中只包含这个字段。
- SetSchemaMetadata - 修改模式名称或版本。
- TimestampRouter - 根据原始主题和时间戳修改记录的主题。当使用需要根据时间戳写入不同的表或索引的sink时非常有用。
- RegexRouter - 根据原始主题、替换字符串和正则表达式修改记录的主题。
- Filter - 从所有进一步的处理中删除消息。这与谓词一起使用,以选择性地过滤某些消息。
下面列出了如何配置每个转换的细节:
org.apache.kafka.connect.transforms.InsertField
使用记录元数据的属性或配置的静态值插入字段。
使用为记录键(org.apache.kafka.connect.transform.InsertField$Key)或值(org.apache.kafka.connect.transform.InsertField$Value)设计的具体转换类型。
offset.field
Kafka偏移的字段名--仅适用于sink。
后缀为 !使其成为必填字段,或 ? 保持其为可选字段(默认)。类型:字符串
默认值: null
有效值。
重要性:中等
partition.field
Kafka分区的字段名。后缀为 !使其成为必填字段,或 ? 保持其为可选字段(默认)。类型:字符串
默认值: null
有效值。
重要性:中等
static.field
静态数据字段的字段名。用 ! 后缀使其成为必填字段,或用 ? 保持其为可选字段(默认)。类型:字符串
默认值: null
有效值。
重要性:中等
static.value
静态字段值,如果配置了字段名。类型:字符串
默认值: null
有效值。
重要性:中等
timestamp.field
记录时间戳的字段名。后缀为 !使其成为必填字段,或 ? 保持为可选字段(默认)。
类型:字符串
默认值: null
有效值。
重要性:中等
topic.field
Kafka主题的字段名。后缀为 !使其成为必填字段,或 ? 保持为可选字段(默认)。
类型:字符串
默认值: null
有效值。
重要性:中等
org.apache.kafka.connect.transforms.ReplaceField
过滤或重命名字段。
使用为记录键(org.apache.kafka.connect.transform.ReplaceField$Key)或值(org.apache.kafka.connect.transform.ReplaceField$Value)设计的具体转换类型。
exclude
要排除的字段。这优先于要包含的字段。类型:列表
默认:""
有效值。
重要性:中等
include
要包含的字段。如果指定,将只使用这些字段。类型:列表
默认:""
有效值。
重要性:中等
renames
字段重命名映射。类型:列表
默认:""
有效值:以冒号分隔的列表,如foo:bar,abc:xyz。
重要性:中等
blacklist
已不适用。使用exclude代替。类型:列表
默认值: null
有效值。
重要性:低
whitelist
已废弃。使用include代替。类型:列表
默认值: null
有效值。
重要性:低
org.apache.kafka.connect.transforms.MaskField
用字段类型的有效空值(如0、false、空字符串等)来屏蔽指定的字段。
对于数字和字符串字段,可以指定一个可选的替换值,该值会被转换为正确的类型。
使用为记录键(org.apache.kafka.connect.transform.MaskField$Key)或值(org.apache.kafka.connect.transform.MaskField$Value)设计的具体转换类型。
fields
要屏蔽的字段名称。类型:列表
默认值。
有效值:非空列表
重要性:高
replacement
自定义值替换,将应用于所有 "字段 "值(仅数字或非空字符串值)。类型:字符串
默认值: null
有效值:非空字符串
重要性:低
org.apache.kafka.connect.transforms.ValueToKey
用记录值中的字段子集形成的新键替换记录键。
fields
记录值上的字段名作为记录键提取。类型:列表
默认值。
有效值:非空列表
重要性:高
org.apache.kafka.connect.transforms.HoistField
当模式存在时,使用指定的字段名将数据封装在Struct中,如果是无模式数据,则使用Map。
使用为记录键(org.apache.kafka.connect.transform.HoistField$Key)或值(org.apache.kafka.connect.transform.HoistField$Value)设计的具体转换类型。
field
将在生成的结构或地图中创建的单个字段的字段名。类型:字符串
默认值。
有效值。
重要性:中等
org.apache.kafka.connect.transforms.ExtractField
当模式存在时,从Struct中提取指定的字段,如果是无模式数据,则从Map中提取。任何空值都会不加修改地传递。
使用为记录键(org.apache.kafka.connect.transform.ExtractField$Key)或值(org.apache.kafka.connect.transform.ExtractField$Value)设计的具体转换类型。
field
要提取的字段名。类型:字符串
默认值。
有效值。
重要性:中等
org.apache.kafka.connect.transforms.SetSchemaMetadata
在记录的key(org.apache.kafka.connect.transforms.SetSchemaMetadata$Key)或value(org.apache.kafka.connect.transforms.SetSchemaMetadata$Value)模式上设置模式名称、版本或两者。
schema.name
要设置的模式名称。类型:字符串
默认值: null
有效值。
重要性:高
schema.version
要设置的模式版本。类型:int
默认值: null
有效值。
重要性:高
org.apache.kafka.connect.transforms.TimestampRouter
更新记录的主题字段,作为原始主题值和记录时间戳的函数。
这对于sink来说主要是有用的,因为主题字段经常被用来确定目标系统中的等价实体名称(如数据库表或搜索索引名称)。
timestamp.format
与java.text.SimpleDateFormat兼容的时间戳的格式字符串。类型:字符串
默认:yyyMMdd
有效值。
重要性:高
topic.format
格式字符串,可以包含${topic}和${timestamp},分别作为主题和时间戳的占位符。类型:字符串
默认值:${topic}-${timestamp}。
有效值。
重要性:高
org.apache.kafka.connect.transforms.RegexRouter
使用配置的正则表达式和替换字符串更新记录主题。
在引擎盖下,regex被编译成java.util.regex.Pattern。如果模式与输入的主题相匹配,java.util.regex.Matcher#replaceFirst()将与替换字符串一起使用,以获得新的主题。
regex
用于匹配的正则表达式。类型:字符串
默认值:
有效值:有效的regex
重要性:高
replacement
替换字符串。类型:字符串
默认值。
有效值。
重要性:高
org.apache.kafka.connect.transforms.Flatten
扁平化一个嵌套的数据结构,通过在每个层次上用一个可配置的定界符连接字段名,为每个字段生成名称。当存在模式时,适用于Struct,如果是无模式数据,则适用于Map。默认定界符是'.'。
使用为记录键(org.apache.kafka.connect.transform.Flatten$Key)或值(org.apache.kafka.connect.transform.Flatten$Value)设计的具体转换类型。
delimiter
为输出记录生成字段名时,在输入记录的字段名之间插入定界符。类型:字符串
默认值: 。
有效值: 。
重要性:中等
org.apache.kafka.connect.transforms.Cast
将字段或整个键或值转换为特定的类型,例如将一个整数字段强制转换为较小的宽度。只支持简单的基元类型--整数、浮点数、布尔值和字符串。
使用为记录键(org.apache.kafka.connect.transform.Cast$Key)或值(org.apache.kafka.connect.transform.Cast$Value)设计的具体转换类型。
spec
字段列表以及要将它们投向的类型,形式为field1:type,field2:type,用于投向Maps或Structs的字段。一个单一的类型可以投出整个值。有效的类型有int8、int16、int32、int64、float32、float64、boolean和string。类型:list
默认值。
有效值:以冒号分隔的数字对列表,例如:foo:bar,abc:xyz。
重要性:高
org.apache.kafka.connect.transforms.TimestampConverter
在不同的格式之间转换时间戳,如Unix epoch、字符串和Connect Date/Timestamp类型。
使用为记录键(org.apache.kafka.connect.transform.TimestampConverter$Key)或值(org.apache.kafka.connect.transform.TimestampConverter$Value)设计的具体转换类型。
target.type
所需的时间戳表示方式:字符串、unix、日期、时间或时间戳。类型:字符串
默认值。
有效值。
重要性:高
field
包含时间戳的字段,如果整个值是时间戳,则为空。类型:字符串
默认:""
有效值。
重要性:高
format
一个与SimpleDateFormat兼容的时间戳格式,当type=string时用于生成输出,如果输入是字符串,则用于解析输入。当type=string时用于生成输出,如果输入是字符串,则用于解析输入。类型:字符串
默认:""
有效值。
重要性:中等
org.apache.kafka.connect.transforms.Filter
丢弃所有记录,从链中的后续转换中过滤出这些记录。这是有条件地用于过滤掉与特定谓词匹配(或不匹配)的记录。
Predicates
变换可以用谓词来配置,以便变换只适用于满足某些条件的消息。特别是,当与Filter变换相结合时,谓词可以用来选择性地过滤掉某些消息。
谓词是在连接器配置中指定的。
- predicates - 要应用于某些转换的谓词的别名集。
- predicates.$alias.type - 谓词的完全限定类名。
- predicates.$alias.$predicateSpecificConfig - 谓词的配置属性。
所有的转换都有隐式的配置属性 predicate 和 negate。通过将变换的 predicate config 设置为 predicate 的别名,可以将 predicular predicate 与变换关联起来。谓词的值可以使用否定配置属性来反转。
例如,假设你有一个源连接器,它产生了许多不同主题的消息,而你想:"过滤掉'f'中的消息。
- 完全过滤掉'foo'主题中的消息。
- 将字段名为'other_field'的ExtractField转换应用于除主题'bar'以外的所有主题中的记录。
要做到这一点,我们首先需要过滤掉主题 "foo "的记录。过滤转换将记录从进一步的处理中移除,并且可以使用 TopicNameMatches 谓词只将转换应用于符合特定正则表达式的主题中的记录。TopicNameMatches的唯一配置属性是pattern,它是一个Java正则表达式,用于与主题名进行匹配。配置如下。
- transforms=Filter
- transforms.Filter.type=org.apache.kafka.connect.transforms.Filter
- transforms.Filter.predicate=IsFoo
- predicates=IsFoo
- predicates.IsFoo.type=org.apache.kafka.connect.predicates.TopicNameMatches
- predicates.IsFoo.pattern=foo
接下来我们需要只在记录的主题名不是'bar'时应用ExtractField。我们不能直接使用 TopicNameMatches,因为那样会将转换应用于匹配的主题名,而不是不匹配的主题名。变换的隐式否定配置属性允许我们反转谓词匹配的记录集。在前面的例子中加入这方面的配置,我们就可以得到。
- transforms=Filter,Extract
- transforms.Filter.type=org.apache.kafka.connect.transforms.Filter
- transforms.Filter.predicate=IsFoo
- transforms.Extract.type=org.apache.kafka.connect.transforms.ExtractField$Key
- transforms.Extract.field=other_field
- transforms.Extract.predicate=IsBar
- transforms.Extract.negate=true
- predicates=IsFoo,IsBar
- predicates.IsFoo.type=org.apache.kafka.connect.predicates.TopicNameMatches
- predicates.IsFoo.pattern=foo
- predicates.IsBar.type=org.apache.kafka.connect.predicates.TopicNameMatches
- predicates.IsBar.pattern=bar
Kafka Connect包括以下谓词。
TopicNameMatches - 匹配主题中具有与特定Java正则表达式匹配的名称的记录。
HasHeaderKey - 匹配具有给定键的头的记录。
RecordIsTombstone - 匹配墓碑记录,即具有空值的记录。
下面列出了如何配置每个谓词的细节:
org.apache.kafka.connect.transforms.predicates.HasHeaderKey
对于至少一个带有配置名称的头的记录来说,这个前提条件为真。
name
头部名称。类型:字符串
默认值。
有效值:非空字符串
重要性:中等
org.apache.kafka.connect.transforms.predicates.RecordIsTombstone
墓碑记录(即有空值)的前提条件为真。
org.apache.kafka.connect.transforms.predicates.TopicNameMatches
一个谓词,对于具有与配置的正则表达式相匹配的主题名称的记录,该谓词为真。
pattern
一个Java正则表达式,用于与记录的主题名称进行匹配。类型:字符串
默认值。
有效值:非空字符串,有效的regex。
重要性:中等
REST API
由于Kafka Connect旨在作为服务运行,它还提供了一个REST API用于管理连接器。REST API服务器可以使用监听器配置选项进行配置。这个字段应该包含一个监听器列表,格式如下:protocol://host:port,protocol2://host2:port2。目前支持的协议有http和https。例如:http和https:
- listeners=http://localhost:8080,https://localhost:8443
默认情况下,如果没有指定监听器,REST服务器使用HTTP协议在8083端口上运行。当使用HTTPS时,配置必须包括SSL配置。默认情况下,它将使用ssl.*设置。如果需要为REST API使用与连接Kafka经纪商不同的配置,可以用listeners.https作为字段的前缀。当使用前缀时,只有前缀选项会被使用,而没有前缀的ssl.*选项将被忽略。以下字段可以用来配置REST API的HTTPS。
ssl.keystore.locationssl.keystore.passwordssl.keystore.typessl.key.passwordssl.truststore.locationssl.truststore.passwordssl.truststore.typessl.enabled.protocolsssl.providerssl.protocolssl.cipher.suitesssl.keymanager.algorithmssl.secure.random.implementationssl.trustmanager.algorithmssl.endpoint.identification.algorithmssl.client.auth
REST API不仅被用户用来监控/管理Kafka Connect。它还用于Kafka Connect的跨集群通信。在跟随节点REST API上收到的请求将被转发到领导节点REST API。如果给定的主机可到达的URI与它监听的URI不同,配置选项 rest.advertised.host.name、 rest.advertised.port和 rest.advertised.listener可以用来改变跟随者节点与领导者连接的URI。当同时使用HTTP和HTTPS监听器时,还可以使用rest.advertised.listener选项来定义哪个监听器将用于跨集群通信。当使用HTTPS进行节点间通信时,将使用相同的ssl.*或listeners.https选项来配置HTTPS客户端。
以下是当前支持的REST API端点。
- GET /connectors - 返回活动连接器的列表。
- POST /connectors - 创建一个新的连接器;请求体应该是一个JSON对象,包含一个字符串名称字段和一个包含连接器配置参数的对象配置字段。
- GET /connectors/{name} - 获取特定连接器的信息。
- GET /connectors/{name}/config - 获取特定连接器的配置参数。
- PUT /connectors/{name}/config - 更新特定连接器的配置参数。
- GET /connectors/{name}/status - 获取连接器的当前状态,包括它是否正在运行、失败、暂停等,它被分配给哪个worker,如果失败,则获取错误信息,以及它所有任务的状态。
- GET /connectors/{name}/tasks - 获取一个连接器当前运行的任务列表。
- GET /connectors/{name}/tasks/{taskid}/status - 获取任务的当前状态,包括是否正在运行、失败、暂停等,分配给哪个工作者,以及失败时的错误信息。
- PUT /connectors/{name}/pause - 暂停连接器及其任务,这将停止消息处理,直到连接器恢复。
- PUT /connectors/{name}/resume - 恢复已暂停的连接器(如果连接器没有暂停,则不做任何事情)。
- POST /connectors/{name}/restart - 重新启动一个连接器(通常是因为它已经失败了)。
- POST /connectors/{name}/tasks/{taskId}/restart - 重新启动一个单独的任务(通常是因为它已经失败)。
- DELETE /connectors/{name} - 删除一个连接器,停止所有任务并删除其配置。
- GET /connectors/{name}/topics - 获取特定连接器在创建连接器后或发出重置其活动主题集的请求后正在使用的主题集。
- PUT /connectors/{name}/topics/reset - 发送一个请求来清空连接器的活动主题集。
Kafka Connect还提供了一个REST API来获取连接器插件的信息。
- GET /connector-plugins-返回Kafka Connect集群中安装的连接器插件列表。请注意,该API只检查处理请求的worker上的连接器,这意味着您可能会看到不一致的结果,特别是在滚动升级期间,如果您添加了新的连接器jar的话
- PUT /connector-plugins/{connector-type}/config/validate - 根据配置定义验证提供的配置值。该API执行每个配置验证,在验证过程中返回建议值和错误信息。
以下是顶层(root)端点支持的REST请求。
- GET /-返回Kafka Connect集群的基本信息,如服务于REST请求的Connect worker的版本(包括源代码的git commit ID)和连接到的Kafka集群ID。
连接中的错误报告
Kafka Connect提供了错误报告,以处理在处理的各个阶段遇到的错误。默认情况下,在转换过程中或转换过程中遇到的任何错误都会导致连接器失败。每个连接器配置也可以通过跳过这些错误来启用容忍此类错误,选择性地将每个错误以及失败操作和问题记录的细节(具有不同的细节级别)写入Connect应用日志。这些机制还可以在汇接器处理从其Kafka主题中消耗的消息时捕获错误,所有的错误都可以写入可配置的 "死信队列"(DLQ)Kafka主题。
要将连接器的转换器、变换器或汇接器本身内部的错误报告到日志中,请在连接器配置中设置 errors.log.enable=true,以记录每个错误和问题记录的主题、分区和偏移的详细信息。出于额外的调试目的,设置 errors.log.include.messages=true,以将问题记录的键、值和标题也记录到日志中(注意这可能会记录敏感信息)。
要将连接器的转换器、变换器或汇接器本身内部的错误报告给死信队列主题,请设置 errors.deadletterqueue.topic.name,并可选 errors.deadletterqueue.context.headers.enable=true。
默认情况下,连接器在出现错误或异常时,会立即表现出 "快速失败 "行为。这相当于在连接器配置中添加以下配置属性及其默认值。
- # disable retries on failure
- errors.retry.timeout=0
- # do not log the error and their contexts
- errors.log.enable=false
- # do not record errors in a dead letter queue topic
- errors.deadletterqueue.topic.name=
- # Fail on first error
- errors.tolerance=none
这些和其他相关的连接器配置属性可以被更改以提供不同的行为。例如,可以将以下配置属性添加到连接器配置中,以设置具有多次重试的错误处理,记录到应用程序日志和my-connector-errors Kafka主题,并通过报告错误而不是失败连接器任务来容忍所有错误。
- # retry for at most 10 minutes times waiting up to 30 seconds between consecutive failures
- errors.retry.timeout=600000
- errors.retry.delay.max.ms=30000
- # log error context along with application logs, but do not include configs and messages
- errors.log.enable=true
- errors.log.include.messages=false
- # produce error context into the Kafka topic
- errors.deadletterqueue.topic.name=my-connector-errors
- # Tolerate all errors.
- errors.tolerance=all
8.3 连接器开发指南
本指南介绍了开发人员如何为Kafka Connect编写新的连接器,以便在Kafka和其他系统之间移动数据。它简要回顾了几个关键概念,然后介绍了如何创建一个简单的连接器。
核心概念和API
连接器和任务
要在Kafka和另一个系统之间复制数据,用户要为他们要从的系统中提取数据或推送数据的系统创建一个连接器。连接器有两种口味。SourceConnectors从另一个系统导入数据(如JDBCSourceConnector将关系型数据库导入Kafka),SinkConnectors导出数据(如HDFSSinkConnector将Kafka主题的内容导出到HDFS文件)。
连接器本身并不执行任何数据复制:它们的配置描述了要复制的数据,而连接器负责将该任务分解成一组可以分配给worker的Task。这些Task也有两种相应的口味。SourceTask和SinkTask。
有了任务后,每个Task必须将它的数据子集复制到Kafka或从Kafka复制。在Kafka Connect中,应该总是可以将这些任务构架为一组由具有一致模式的记录组成的输入和输出流。有时,这种映射是显而易见的:一组日志文件中的每个文件都可以被视为一个流,每个解析行都使用相同的模式和偏移量形成一个记录,并作为字节偏移量存储在文件中。在其他情况下,可能需要更多的努力来映射到这种模式:JDBC连接器可以将每个表映射到流,但偏移量不太清楚。一种可能的映射使用时间戳列生成查询,递增返回新的数据,最后查询的时间戳可以作为偏移量。
流和记录
每个数据流应该是一个键值记录的序列。键和值都可以有复杂的结构 -- -- 提供了许多原始类型,但也可以表示数组、对象和嵌套数据结构。运行时数据格式不假定任何特定的序列化格式;这种转换由框架内部处理。
除了键和值之外,记录(包括那些由源产生的记录和传递到sink的记录)还有相关的流ID和偏移量。框架使用这些来定期提交已处理的数据的偏移量,以便在发生故障时,可以从最后提交的偏移量开始恢复处理,避免不必要的重新处理和重复事件。
动态连接器
并非所有的任务都是静态的,因此,Connector实现还负责监控外部系统的任何可能需要重新配置的变化。例如,在JDBCSourceConnector的例子中,Connector可能为每个Task分配一组表。当创建新表时,它必须发现这一点,以便通过更新配置将新表分配给其中一个Task。当它注意到需要重新配置的变化(或Task数量的变化)时,它就会通知框架,框架就会更新任何相应的Task。
开发一个简单的连接器
开发一个连接器只需要实现两个接口,即连接器和任务。文件包中的Kafka源代码中包含了一个简单的例子。这个连接器是为了在单机模式下使用,它实现了一个SourceConnector/SourceTask,用于读取文件的每一行并将其作为记录发出,以及一个SinkConnector/SinkTask,用于将每个记录写入文件。
本节其余部分将通过一些代码来演示创建连接器的关键步骤,但开发人员还应该参考完整的示例源代码,因为为了简洁起见,很多细节都被省略了。
连接器示例
我们将以SourceConnector作为一个简单的例子来介绍。SinkConnector的实现非常相似。首先创建继承自SourceConnector的类,并添加几个字段来存储解析的配置信息(要读取的文件名和要发送数据的主题)。
- public class FileStreamSourceConnector extends SourceConnector {
- private String filename;
- private String topic;
最容易填写的方法是taskClass(),它定义了应该在worker进程中实例化的类来实际读取数据。
- @Override
- public Class<? extends Task> taskClass() {
- return FileStreamSourceTask.class;
- }
下面我们将定义FileStreamSourceTask类。接下来,我们添加一些标准的生命周期方法,start()和stop()。
- @Override
- public void start(Map<String, String> props) {
- // The complete version includes error handling as well.
- filename = props.get(FILE_CONFIG);
- topic = props.get(TOPIC_CONFIG);
- }
- @Override
- public void stop() {
- // Nothing to do since no background monitoring is required.
- }
最后,真正的实现核心是在 taskConfigs()中。在这种情况下,我们只处理一个文件,所以即使我们可能被允许根据maxTasks参数生成更多的任务,但我们返回的列表只有一个条目。
- @Override
- public List<Map<String, String>> taskConfigs(int maxTasks) {
- ArrayList<Map<String, String>> configs = new ArrayList<>();
- // Only one input stream makes sense.
- Map<String, String> config = new HashMap<>();
- if (filename != null)
- config.put(FILE_CONFIG, filename);
- config.put(TOPIC_CONFIG, topic);
- configs.add(config);
- return configs;
- }
虽然在示例中没有使用,但SourceTask还提供了两个API来提交源系统中的偏移量:commit和commitRecord。这些API是为具有消息确认机制的源系统提供的。重载这些方法可以让源连接器在源系统中确认消息,无论是批量还是单独的,一旦它们被写入Kafka。提交API会在源系统中存储偏移量,最多是poll返回的偏移量。这个API的实现应该阻塞,直到提交完成。commitRecord API将每个SourceRecord写入Kafka后,会在源系统中保存偏移量。由于Kafka Connect会自动记录偏移量,所以不需要SourceTasks来实现。在连接器确实需要在源系统中确认消息的情况下,通常只需要实现其中一个API。
即使有多个任务,这个方法的实现通常也很简单。它只需要确定输入任务的数量,可能需要联系它要拉取数据的远程服务,然后将它们分工。因为一些任务之间分工的模式非常常见,所以在ConnectorUtils中提供了一些实用程序来简化这些情况。
请注意,这个简单的例子不包括动态输入。关于如何触发任务配置的更新,请参阅下一节的讨论。
任务示例 - 源任务
接下来我们将介绍相应的SourceTask的实现。这个实现很短,但太长了,在本指南中无法完全介绍。我们将使用伪代码来描述大部分的实现,但你可以参考源代码来了解完整的例子。
就像连接器一样,我们需要创建一个继承自相应基础Task类的类。它也有一些标准的生命周期方法。
- public class FileStreamSourceTask extends SourceTask {
- String filename;
- InputStream stream;
- String topic;
- @Override
- public void start(Map<String, String> props) {
- filename = props.get(FileStreamSourceConnector.FILE_CONFIG);
- stream = openOrThrowError(filename);
- topic = props.get(FileStreamSourceConnector.TOPIC_CONFIG);
- }
- @Override
- public synchronized void stop() {
- stream.close();
- }
这些都是略微简化的版本,但表明这些方法应该是比较简单的,它们应该执行的唯一工作就是分配或释放资源。关于这个实现有两点需要注意。首先,start()方法还不能处理从以前的偏移量恢复,这将在后面的章节中解决。第二,stop()方法是同步的。这将是必要的,因为SourceTasks被赋予了一个专门的线程,它们可以无限期地阻塞,所以需要用Worker中不同线程的调用来停止它们。
接下来,我们实现任务的主要功能--poll()方法,它从输入系统中获取事件并返回一个List<SourceRecord>。
- @Override
- public List<SourceRecord> poll() throws InterruptedException {
- try {
- ArrayList<SourceRecord> records = new ArrayList<>();
- while (streamValid(stream) && records.isEmpty()) {
- LineAndOffset line = readToNextLine(stream);
- if (line != null) {
- Map<String, Object> sourcePartition = Collections.singletonMap("filename", filename);
- Map<String, Object> sourceOffset = Collections.singletonMap("position", streamOffset);
- records.add(new SourceRecord(sourcePartition, sourceOffset, topic, Schema.STRING_SCHEMA, line));
- } else {
- Thread.sleep(1);
- }
- }
- return records;
- } catch (IOException e) {
- // Underlying stream was killed, probably as a result of calling stop. Allow to return
- // null, and driving thread will handle any shutdown if necessary.
- }
- return null;
- }
同样,我们省略了一些细节,但我们可以看到重要的步骤:poll()方法会被反复调用,对于每一次调用,它都会循环尝试从文件中读取记录。对于它读取的每一行,它也会跟踪文件的偏移量。它使用这些信息来创建一个输出的SourceRecord,其中包含四条信息:源分区(只有一个,就是被读取的单个文件)、源偏移量(文件中的字节偏移量)、输出主题名和输出值(行,我们包含一个模式,表明这个值将永远是一个字符串)。SourceRecord构造函数的其他变体也可以包括一个特定的输出分区、一个键和标题。
请注意,这个实现使用正常的Java InputStream接口,如果数据不可用,可能会睡眠。这是可以接受的,因为Kafka Connect为每个任务提供了一个专用线程。虽然任务实现必须符合基本的poll()接口,但它们在如何实现方面有很大的灵活性。在这种情况下,基于NIO的实现会更有效,但这种简单的方法是可行的,实现速度快,而且兼容旧版本的Java。
Sink任务
上一节介绍了如何实现一个简单的SourceTask。与SourceConnector和SinkConnector不同的是,SourceTask和SinkTask的接口非常不同,因为SourceTask使用的是拉接口,而SinkTask使用的是推接口。两者共享共同的生命周期方法,但SinkTask接口却截然不同。
- public abstract class SinkTask implements Task {
- public void initialize(SinkTaskContext context) {
- this.context = context;
- }
- public abstract void put(Collection<SinkRecord> records);
- public void flush(Map<TopicPartition, OffsetAndMetadata> currentOffsets) {
- }
SinkTask文档包含了完整的细节,但这个接口几乎和SourceTask一样简单。put()方法应该包含大部分的实现,接受SinkRecords的集合,执行任何所需的翻译,并将它们存储在目标系统中。这个方法不需要在返回之前确保数据已经完全写入目的系统。事实上,在许多情况下,内部缓冲将是有用的,因此可以一次发送整批记录,减少将事件插入下游数据存储的开销。SinkRecords包含的信息与SourceRecords基本相同。Kafka主题,分区,偏移,事件的键和值,以及可选的头信息。
flush()方法在偏移提交过程中使用,它允许任务从失败中恢复,并从安全点恢复,这样就不会错过任何事件。该方法应该将任何未完成的数据推送到目标系统,然后阻塞,直到写入被确认。offsets参数通常可以被忽略,但在某些情况下是有用的,在这些情况下,实现者希望在目标存储中存储偏移信息,以提供精确的一次交付。例如,HDFS连接器可以做到这一点,并使用原子移动操作来确保flush()操作原子地将数据和偏移量提交到HDFS中的最终位置。
错误记录报告器
当为连接器启用错误报告时,连接器可以使用ErrantRecordReporter来报告发送到sink连接器的单个记录的问题。下面的示例显示了连接器的SinkTask子类如何获取和使用ErrantRecordReporter,当DLQ未启用或连接器安装在没有此报告功能的旧Connect运行时,安全地处理一个空报告。
- private ErrantRecordReporter reporter;
- @Override
- public void start(Map<String, String> props) {
- ...
- try {
- reporter = context.errantRecordReporter(); // may be null if DLQ not enabled
- } catch (NoSuchMethodException | NoClassDefFoundError e) {
- // Will occur in Connect runtimes earlier than 2.6
- reporter = null;
- }
- }
- @Override
- public void put(Collection<SinkRecord> records) {
- for (SinkRecord record: records) {
- try {
- // attempt to process and send record to data sink
- process(record);
- } catch(Exception e) {
- if (reporter != null) {
- // Send errant record to error reporter
- reporter.report(record, e);
- } else {
- // There's no error reporter, so fail
- throw new ConnectException("Failed on record", e);
- }
- }
- }
- }
从以前的偏移量恢复
SourceTask的实现包括一个流ID(输入文件名)和偏移量(在文件中的位置)与每个记录。框架使用这个来定期提交偏移量,这样在失败的情况下,任务可以恢复并尽量减少被重新处理和可能重复的事件数量(或者从最近的偏移量恢复,如果Kafka Connect被优雅地停止,例如在独立模式下或由于作业重新配置)。这个提交过程完全由框架自动完成,但只有连接器知道如何在输入流中寻找回正确的位置,从该位置恢复。
为了在启动时正确地恢复,任务可以使用传递到其initialize()方法中的SourceContext来访问偏移数据。在initialize()中,我们将添加更多的代码来读取偏移量(如果存在的话)并寻求到该位置。
- stream = new FileInputStream(filename);
- Map<String, Object> offset = context.offsetStorageReader().offset(Collections.singletonMap(FILENAME_FIELD, filename));
- if (offset != null) {
- Long lastRecordedOffset = (Long) offset.get("position");
- if (lastRecordedOffset != null)
- seekToOffset(stream, lastRecordedOffset);
- }
当然,你可能需要为每个输入流读取许多键。OffsetStorageReader接口还允许您发出批量读取,以有效地加载所有偏移量,然后通过寻找每个输入流到适当的位置来应用它们。
动态输入/输出流
Kafka Connect旨在定义批量数据复制作业,例如复制整个数据库,而不是创建许多作业来单独复制每个表。这种设计的一个后果是,一个连接器的输入或输出流的集合可以随着时间的推移而变化。
源连接器需要监控源系统的变化,例如数据库中表的添加/删除。当它们接收到变化时,应该通过ConnectorContext对象通知框架需要重新配置。例如,在一个SourceConnector:
- if (inputsChanged())
- this.context.requestTaskReconfiguration();
框架会及时请求新的配置信息并更新任务,让它们在重新配置之前优雅地提交它们的进度。需要注意的是,在SourceConnector中,这种监控目前是由连接器实现来完成的。如果需要一个额外的线程来执行这个监控,连接器必须自己分配它。
理想情况下,这种监控变化的代码将被隔离在连接器中,任务不需要担心这些变化。然而,变化也会影响到任务,最常见的是当它们的一个输入流在输入系统中被破坏时,例如,如果一个表从数据库中被丢弃。如果Task在Connector之前遇到了这个问题,如果Connector需要轮询变化,这将是常见的,那么Task将需要处理后续的错误。值得庆幸的是,这通常可以简单地通过捕获和处理适当的异常来处理。
SinkConnectors通常只需要处理流的添加,这可能转化为其输出中的新条目(例如,一个新的数据库表)。该框架管理Kafka输入的任何变化,例如当输入主题集因regex订阅而改变时。SinkTasks应该期待新的输入流,这可能需要在下游系统中创建新的资源,例如数据库中的新表。在这些情况下,最棘手的处理情况可能是多个SinkTasks第一次看到新的输入流并同时试图创建新资源之间的冲突。另一方面,SinkConnectors一般不需要特别的代码来处理一组动态的流。
连接配置验证
Kafka Connect允许您在提交连接器执行之前验证连接器配置,并且可以提供有关错误和推荐值的反馈。为了利用这一点,连接器开发者需要提供config()的实现,将配置定义暴露给框架。
FileStreamSourceConnector中的以下代码定义了配置并将其暴露给框架。
- private static final ConfigDef CONFIG_DEF = new ConfigDef()
- .define(FILE_CONFIG, Type.STRING, Importance.HIGH, "Source filename.")
- .define(TOPIC_CONFIG, Type.STRING, Importance.HIGH, "The topic to publish data to");
- public ConfigDef config() {
- return CONFIG_DEF;
- }
ConfigDef类用于指定预期配置的集合。对于每个配置,你可以指定名称、类型、默认值、文档、组信息、组中的顺序、配置值的宽度和适合在UI中显示的名称。另外,你还可以通过覆盖Validator类,提供用于单个配置验证的特殊验证逻辑。此外,由于配置之间可能存在依赖关系,例如,一个配置的有效值和可见性可能会根据其他配置的值而改变。为了处理这个问题,ConfigDef允许你指定配置的依赖关系,并提供一个Recommender的实现来获取配置的有效值,并在当前配置值的基础上设置配置的可见性。
另外,Connector中的validate()方法提供了一个默认的验证实现,它返回一个允许的配置列表,以及每个配置的配置错误和推荐值。但是,它并没有使用推荐值进行配置验证。您可以为自定义配置验证提供默认实现的重写,它可以使用推荐值。
使用模式
FileStream连接器是一个很好的例子,因为它们很简单,但它们也有微不足道的结构化数据--每一行只是一个字符串。几乎所有实用的连接器都需要具有更复杂数据格式的模式。
要创建更复杂的数据,你需要使用Kafka Connect数据API。大多数结构化记录除了原始类型外,还需要与两个类进行交互。Schema和Struct。
API文档提供了一个完整的参考,但这里是一个创建Schema和Struct的简单例子。
- Schema schema = SchemaBuilder.struct().name(NAME)
- .field("name", Schema.STRING_SCHEMA)
- .field("age", Schema.INT_SCHEMA)
- .field("admin", SchemaBuilder.bool().defaultValue(false).build())
- .build();
- Struct struct = new Struct(schema)
- .put("name", "Barbara Liskov")
- .put("age", 75);
如果你正在实现一个源连接器,你需要决定何时以及如何创建模式。在可能的情况下,你应该尽可能地避免重新计算它们。例如,如果你的连接器保证有一个固定的模式,就静态地创建它,并重用一个实例。
然而,许多连接器将具有动态模式。一个简单的例子是数据库连接器。考虑到即使只是一张表,整个连接器的模式也不会是预定义的(因为它因表而异)。但在连接器的生命周期内,它也可能不会固定在一张表上,因为用户可能会执行ALTER TABLE命令。连接器必须能够检测到这些变化并做出适当的反应。
汇接器通常比较简单,因为它们正在消耗数据,因此不需要创建模式。然而,它们应该同样小心地验证它们接收的模式是否具有预期的格式。当模式不匹配时 -- -- 通常表明上游生产者正在生成无法正确翻译到目的系统的无效数据 -- -- 水槽连接器应该抛出一个异常,向系统指出这个错误。
Kafka连接管理
Kafka Connect的REST层提供了一组API来实现集群的管理。这包括用于查看连接器的配置和其任务的状态,以及改变其当前行为(例如更改配置和重新启动任务)的API。
当一个连接器首次提交到集群时,Connect工作者之间会触发重新平衡,以便分配由新连接器的任务组成的负载。当连接器增加或减少其所需的任务数量时,当连接器的配置发生变化时,或者当作为Connect集群有意升级的一部分或由于故障而从组中添加或删除工作者时,也会使用这种相同的再平衡过程。
在 2.3.0 之前的版本中,Connect 工作者会重新平衡群集中的全部连接器及其任务,以此作为一种简单的方式,确保每个工作者的工作量大致相同。这个行为仍然可以通过设置connect.protocol=eager来启用。
从2.3.0开始,Kafka Connect默认使用的协议是执行增量合作再平衡,增量地平衡Connect worker中的连接器和任务,只影响新的、要删除的或需要从一个worker转移到另一个worker的任务。在重新平衡期间,其他任务不会像旧协议那样被停止和重新启动。
如果 Connect 工人有意或因故障离开组,Connect 会在触发重新平衡之前等待 scheduled.rebalance.max.delay.ms。该延迟默认为五分钟(300000ms),以容忍工人的故障或升级,而不会立即重新分配离开工人的负载。如果这个工人在配置的延迟内返回,它将获得之前分配的全部任务。但是,这意味着在 scheduled.rebalance.max.delay.ms 指定的时间过去之前,任务将保持未分配。如果某个工作者没有在该时间限制内返回,Connect 将在 Connect 集群中的剩余工作者之间重新分配这些任务。
当组成 Connect 群集的所有 Worker 都被配置为 connect.protocol=compatible 时,新的 Connect 协议就会被启用,当该属性缺失时,它也是默认值。因此,当所有工作者升级到 2.3.0 时,会自动升级到新的 Connect 协议。当最后一个工作者加入2.3.0版本时,Connect集群的滚动升级将激活增量合作再平衡。
您可以使用 REST API 来查看连接器及其任务的当前状态,包括每个连接器被分配到的工作者的 ID。例如,GET /connectors/file-source/status请求显示名为file-source的连接器的状态:
- {
- "name": "file-source",
- "connector": {
- "state": "RUNNING",
- "worker_id": "192.168.1.208:8083"
- },
- "tasks": [
- {
- "id": 0,
- "state": "RUNNING",
- "worker_id": "192.168.1.209:8083"
- }
- ]
- }
连接器及其任务将状态更新发布到一个共享主题(用status.storage.topic配置),集群中的所有工作者都会监控这个主题。由于工作者异步地消耗这个主题,因此在通过状态API看到状态变化之前通常会有一个(短暂的)延迟。连接器或其任务之一可能有以下状态。
- UNASSIGNED。该连接器/任务尚未分配给工人。
- RUNNING:连接器/任务正在运行。
- PAUSED(暂停):该连接器/任务已被管理。该连接器/任务在管理上已被暂停。
- FAILED:连接器/任务已经失败。连接器/任务失败了(通常通过引发异常,并在状态输出中报告)。
- DESTROYED:连接器/任务在管理上已经暂停。该连接器/任务已被管理删除,并将停止出现在Connect集群中。
在大多数情况下,连接器和任务状态将匹配,尽管在发生变化或任务失败时,它们可能会在短时间内有所不同。例如,当连接器首次启动时,在连接器及其任务全部过渡到RUNNING状态之前,可能会有一个明显的延迟。由于Connect不会自动重启失败的任务,因此在任务失败时,状态也会出现分歧。要手动重启连接器/任务,您可以使用上面列出的重启 API。请注意,如果您试图在重新平衡进行时重新启动任务,Connect 将返回 409(冲突)状态代码。您可以在重新平衡完成后重试,但可能没有必要,因为重新平衡会有效地重新启动集群中的所有连接器和任务。
从2.5.0开始,Kafka Connect使用status.storage.topic也存储与每个连接器正在使用的主题相关的信息。Connect Workers使用这些每个连接器的主题状态更新来响应对REST端点GET /connectors/{name}/topics的请求,返回连接器正在使用的主题名称集。向REST端点PUT /connectors/{name}/topics/reset发出的请求会重置连接器的活动主题集,并允许根据连接器最新的主题使用模式填充新的主题集。当连接器被删除时,连接器的活动主题集也会被删除。话题跟踪默认是启用的,但可以通过设置topic.tracking.enable=false来禁用。如果您想在运行时禁止请求重置连接器的活动主题,请设置Worker属性topic.tracking.allow.reset=false。
有时,暂时停止连接器的消息处理很有用。例如,如果远程系统正在进行维护,那么源连接器最好停止对其进行新数据的轮询,而不是用异常垃圾信息填充日志。对于这种用例,Connect提供了一个暂停/恢复API。当源连接器被暂停时,Connect将停止对其进行额外记录的轮询。当sink连接器暂停时,Connect将停止向其推送新消息。暂停状态是持久的,因此即使您重新启动群集,连接器也不会再次开始消息处理,直到任务被恢复。请注意,在连接器的所有任务过渡到paused状态之前,可能会有一个延迟,因为它们可能需要时间来完成它们在被暂停时正在进行的任何处理。此外,失败的任务在重新启动之前不会过渡到PAUSED状态。
9. KAFKA STREAMS
Kafka Streams是一个用于处理和分析存储在Kafka中的数据的客户端库。它建立在重要的流处理概念之上,如正确区分事件时间和处理时间、窗口支持、精确的一次性处理语义和简单而高效的应用状态管理。
Kafka Streams的入门门槛很低。你可以在一台机器上快速编写和运行一个小规模的概念验证;你只需要在多台机器上运行你的应用的额外实例,就可以扩展到大批量的生产工作负载。Kafka Streams通过利用Kafka的并行模型透明地处理同一应用的多个实例的负载平衡。
了解更多关于Kafka流的信息请阅读下一篇文章。
Kafka官方文档V2.7的更多相关文章
- 《KAFKA官方文档》入门指南(转)
1.入门指南 1.1简介 Apache的Kafka™是一个分布式流平台(a distributed streaming platform).这到底意味着什么? 我们认为,一个流处理平台应该具有三个关键 ...
- Kafka官方文档
Apache Kafka是 一个分布式消息发布订阅系统.它最初由LinkedIn公司基于独特的设计实现为一个分布式的提交日志系统( a distributed commit log),,之后成为Apa ...
- kafka安装配置及操作(官方文档)http://kafka.apache.org/documentation/(有单节点多代理配置)
https://www.cnblogs.com/biehongli/p/7767710.html w3school https://www.w3cschool.cn/apache_kafka/apac ...
- Spark官方文档 - 中文翻译
Spark官方文档 - 中文翻译 Spark版本:1.6.0 转载请注明出处:http://www.cnblogs.com/BYRans/ 1 概述(Overview) 2 引入Spark(Linki ...
- [dpdk] 读官方文档(1)
前提:已读了这本书<<深入浅出dpdk(朱清河等著)>>. 目标:读官方文档,同时跟着文档进行安装编译等工作. http://dpdk.org/doc/guides/index ...
- Spark Streaming官方文档学习--上
官方文档地址:http://spark.apache.org/docs/latest/streaming-programming-guide.html Spark Streaming是spark ap ...
- CentOS7.3利用kubeadm安装kubernetes1.7.3完整版(官方文档填坑篇)
安装前记: 近来容器对企业来说已经不是什么陌生的概念,Kubernetes作为Google开源的容器运行平台,受到了大家的热捧.搭建一套完整的kubernetes平台,也成为试用这套平台必须迈过的坎儿 ...
- 为开源社区尽一份力,翻译RocketMQ官方文档
正如在上一篇文章中写道:"据我所知,现在RocketMQ还没有中文文档.我打算自己试着在github上开一个项目,自行翻译."我这几天抽空翻译了文档的前3个小节,发现翻译真的不是一 ...
- vue插件官方文档,做个记录
vue的插件,组件都可以按照这种方式添加 官方文档 https://cn.vuejs.org/v2/guide/plugins.html 做个记录用
随机推荐
- online创建索引中途取消导致索引无法删除解决办法
问题:有一个表ID栏位没有索引,但是在一个update语句的where中被使用,因此打算online创建索引,但是长时间没有成功,此时决定取消,取消后发现索引无法删除 过程: 数据库监控报警有行锁,进 ...
- SAP中数据库表长度的界定
SAP中,如何查看表和关键字的长度?通过SE11菜单栏Extras->table width 可以看到.然而SAP在系统也会将表分类,特别是在可扩展的表维护视图中,分为如下几类 ult ...
- java 利用异或^进行加密
package com.zcj.eg001; import java.nio.charset.Charset; import org.junit.Test; public class Encrypti ...
- 基于.NET Core的优秀开源项目合集
开源项目非常适合入门,并且可以作为体系结构参考的好资源, GitHub中有几个开源的.NET Core项目,这些项目将帮助您使用不同类型的体系结构和编码模式来深入学习 .NET Core技术, 本文列 ...
- Java并发编程常识
这是why的第 85 篇原创文章 写中间件经常要做两件事: 1.延迟加载,在内存缓存已加载项. 2.统计调用次数,拦截并发量. 就这么个小功能,团队里的人十有八九写错. 上面这句话不是我说的,是梁飞在 ...
- 提示框,对话框,路由跳转页面,跑马灯,幻灯片及list组件的应用
目录: 主页面的js业务逻辑层 主页面视图层 主页面css属性设置 跳转页面一的js业务逻辑层 跳转页面一的视图层 跳转页面二的视图层 跳转页面三的js业务逻辑层 跳转页面三的视图层 跳转页面三的cs ...
- (Oracle)关于blob转到目标库报ORA-01461: 仅能绑定要插入 LONG 列的 LONG 值错误解决方案
在数据抽取时,开发需要clob类型的数据,但是目标库类型是blob类型的,于是抽取的时候报错: ORA-01461: 仅能绑定要插入 LONG 列的 LONG 值错误 可能有以下几种原因: 可能有以下 ...
- 高性能缓存 Caffeine 原理及实战
一.简介 Caffeine 是基于Java 8 开发的.提供了近乎最佳命中率的高性能本地缓存组件,Spring5 开始不再支持 Guava Cache,改为使用 Caffeine. 下面是 Caffe ...
- docker(mysql-redmine)
一.安装docker 首先查看自己的版本,我的是centos 版本为 [root@localhost redmine]# uname -r 3.10.0-862.el7.x86_64 移除旧版本 yu ...
- ElasticSearch 入门简介
公号:码农充电站pro 主页:https://codeshellme.github.io ElasticSearch 是一款强大的.开源的.分布式的搜索与分析引擎,简称 ES,它提供了实时搜索与聚合分 ...