RabbitMQ基础教程
RabbitMQ相关概念介绍
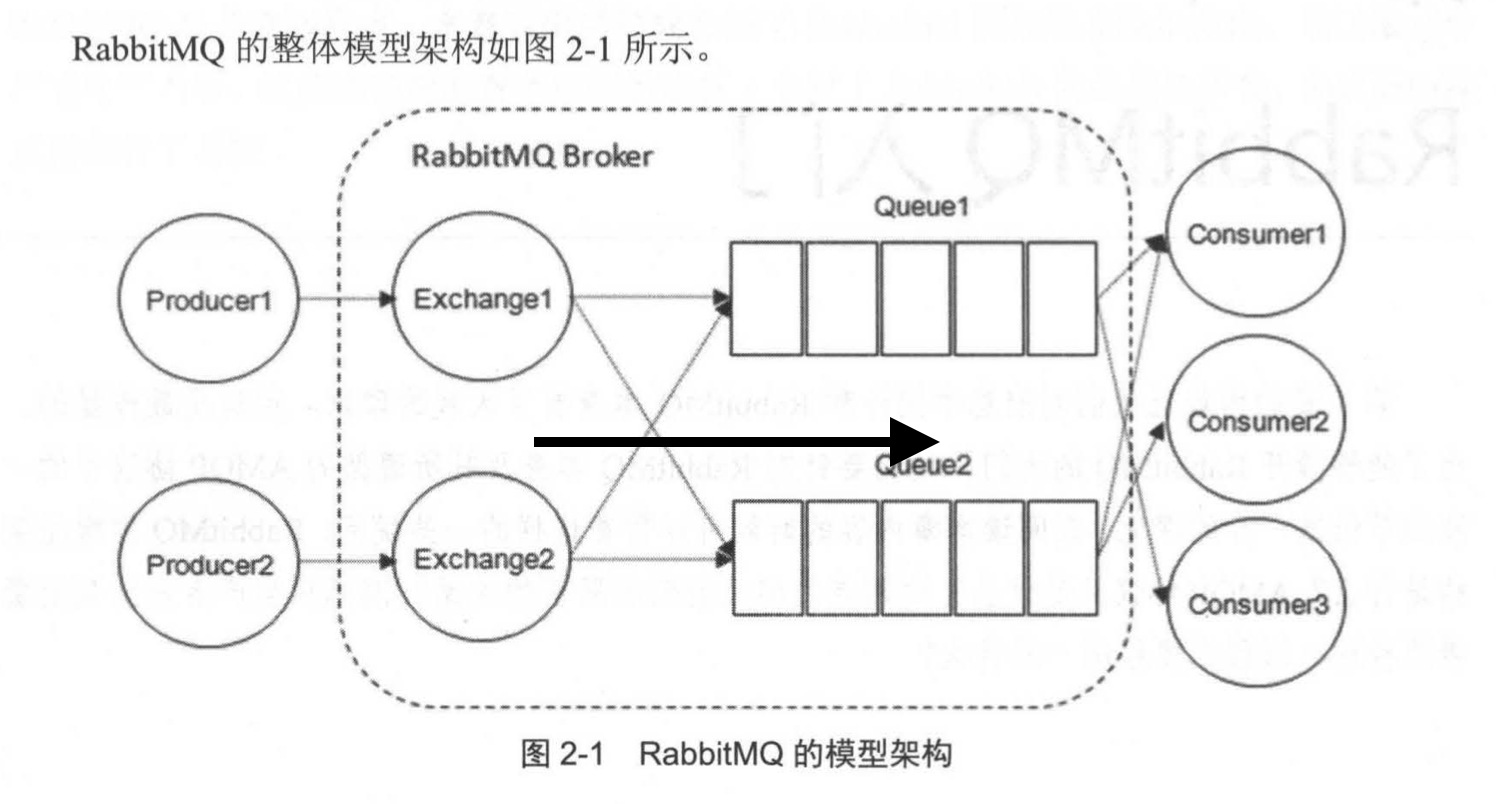
RabbitMQ整体上是一个生产者与消费者模型,主要负责接收、存储和转发消息。可以把消息传递的过程想象成:当你将一个包裹送到邮局,邮局会暂存并最终将邮件通过邮递员送到收件人的手上,RabbitMQ就好比邮局、邮箱和邮递员组成的一个系统。从计算机术语层面来说,RabbitMQ模型更像是一种交换机模型。
生产者和消费者
Producer:生产者,就是投递消息的一方。
生产者创建消息,然后发布到RabbitMQ中。消息一般可以包含2个部分:消息体和标签(Label)。消息体也可以称之为payload,在实际应用中,消息体一般是一个带有业务逻辑结构的数据,比如一个JSON字符串。当然可以进一步对这个消息体进行序列化操作。消息的标签用来描述这条消息,比如一个交换器的名称和一个路由键。生产者把消息交由RabbitMQ,RabbitMQ之后会根据标签把消息发送给感兴趣的消费者(Consumer)。
Consumer:消费者,就是接受消息的一方。
消费者连接到RabbitMQ服务器,并订阅到队列上。当消费者消费一条消息时,只是消费消息的消息体(payload)。在消息路由的过程中,消息的标签会丢弃,存入到队列中的消息只有消息体,消费者也只会消费到消息体,也就不知道消息的生产者是谁,当然消费者也不需要知道。
Broker:消息中间件的服务节点。
对于RabbitMQ来说,一个RabbitMQ Broker可以简单地看做一个RabbitMQ服务节点,或者RabbitMQ服务实例。大多数情况下也可以将一个RabbitMQ Broker看做一台RabbitMQ服务器。
图2-2展示了生产者将消息存入RabbitMQ Broker,以及消费者从Broker中消费数据的整个流程。

首先生产者将业务方数据进行可能的包装,之后封装成消息,发送(AMQP协议里这个动作对应的命令为Basic.Publish)到Broker中。消费者订阅并接受消息(AMQP协议里这个动作对应的命令为Basic.Consume或者Basic.Get),经过可能的解包处理得到原始的数据,之后在进行业务处理逻辑。这个业务处理逻辑并不一定需要和接收消息的逻辑使用同一个线程。消费者进程可以使用一个线程去接收消息,存入到内存中,比如使用Java中的BlockingQueue。业务处理逻辑使用另一个线程从内存中读取数据,这样可以将应用进一步解耦,提高整个应用的处理效率。
队列
Queue:队列,是RabbitMQ的内部对象,用于存储消息。参考图2-1,队列可以用图2-3表示。

RabbitMQ中消息都只能存储在队列中,这一点和Kafka这种消息中间件相反。Kafka将消息存储在topic(主题)这个逻辑层面,而相对应的队列逻辑知识topic实际存储文件中的位移标识。RabbitMQ的生产者生产消息并最终投递到队列中,消费者可以从队列中获取消息并消费。
多个消费者可以订阅同一个队列,这时队列中的消息会被平均分摊(Round-Robin,即轮询)给多个消费者进行处理,而不是每个消费者都收到所有的消息并处理,如图2-4所示。
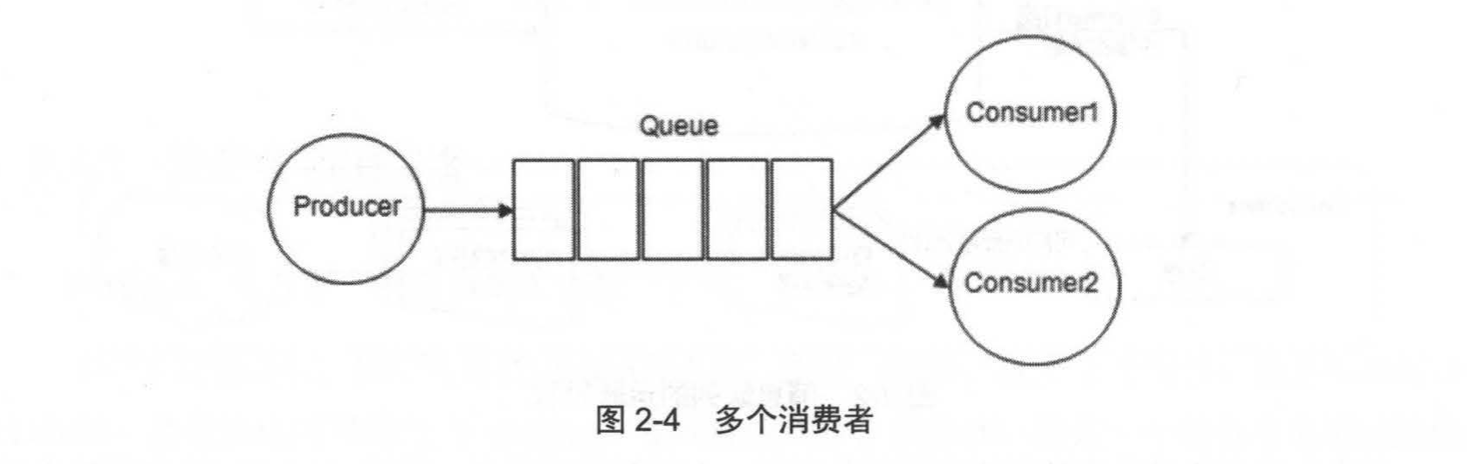
RabbitMQ不支持队列层面的广播消息,如果需要广播消费,需要在其上进行二次开发,处理逻辑会变得异常复杂,同时也不建议这么做。
交换器、路由键、绑定
Exchange:交换器。在图2-4中我们暂时可以理解成生产者将消息投递到队列中,实际上这个在RabbitMQ中不会发生。真实情况是,生产者将消息发送到Exchange(交换器,通常也可以用大写的"X"来表示),有交换器将消息路由到一个或者多个队列中。如果路由不到,或许会返回给生产者,或许直接丢弃。这里可以将RabbitMQ中的交换器看做一个简单的实体。
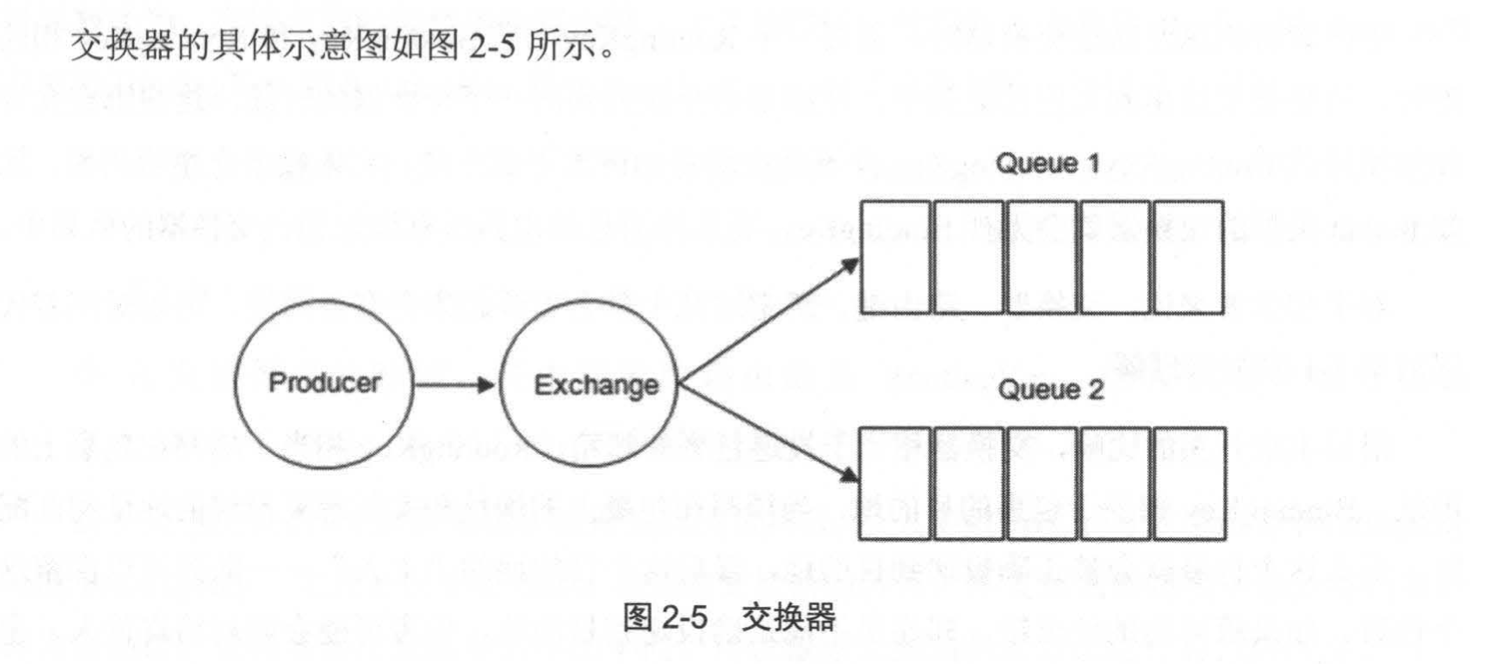
RabbitMQ中的交换器有四种类型,不同的类型有着不同的路由决策。
RoutingKey:路由键。生产者将消息发给交换器的时候,一般会指定一个RoutingKey,用来指定这个消息的路由规则,而这个RoutingKey需要与交换器类型和绑定键(BindingKey)联合使用才能最终生效。
在交换器类型和绑定键(BindingKey)固定的情况下,生产者可以在发送消息给交换器时,通过指定RoutingKey来决定消息流向哪里。
Binding:绑定。RabbitMQ中通过绑定将交换器与队列联合起来,在绑定的时候一般会指定一个绑定键(BindingKey),这样RabbitMQ就知道如何正确地将消息路由到队列了,如果2-6所示。
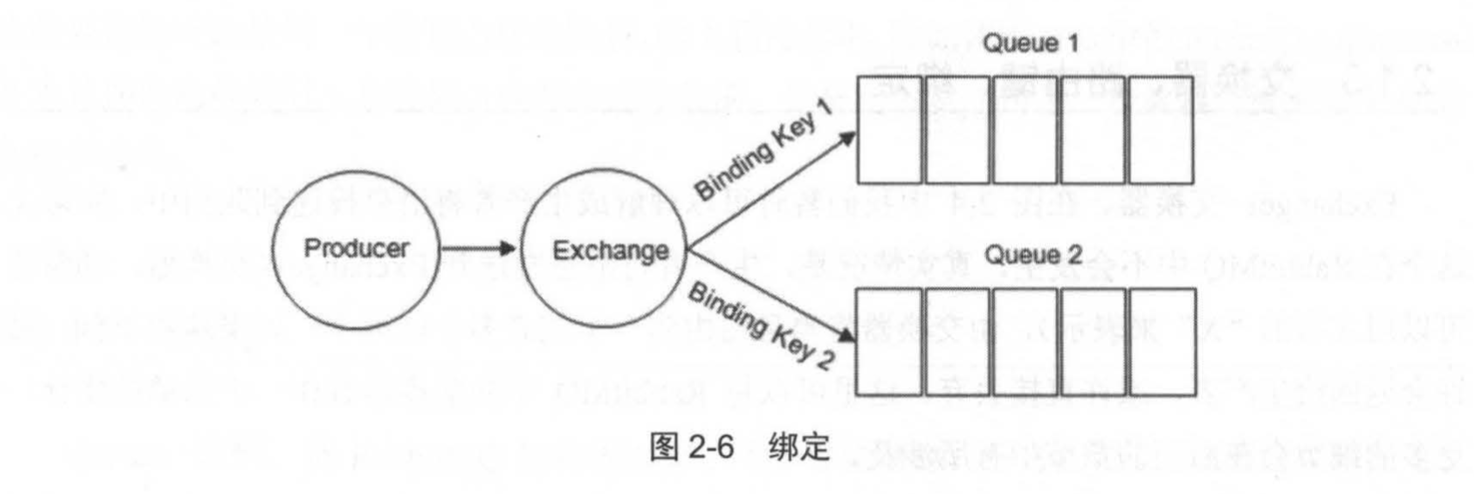
生产者将消息发送给交换器时,需要一个RoutingKey,当BindingKey和RoutingKey相匹配时,消息会被路由到对应的队列中。在绑定多个队列到同一个交换器的时候,这些绑定允许使用相同的BindingKey。BindingKey并不是在所有的情况下都生效,它依赖于交换器类型,比如fanout类型的交换器就会无视BindingKey,而是将消息路由到所有绑定该交换器的队列中。
对于初学者来说,交换器、路由键、绑定这几个概念理解起来会有点晦涩,可以对照着代码来加深理解。
沿用本章开头的比喻,交换器相当于投递包裹的邮箱,RoutingKey相当于填写在包裹上面的地址,BindingKey相当于包裹的目的地,当填写在包裹上的地址和实际想要投递的地址相匹配时,那么这个包裹就会被正确投递地目的地,最后这个目的地的“主人”--队列可以保留这个包裹。如果填写的地址出错,邮递员不能正确投递到目的地,包裹可能会回退给寄件人,也可能被丢弃。
有经验的读者可能会发现,在某些情形下,RoutingKey和BindingKey可以看做同一个东西。
use PhpAmqpLib\Connection\AMQPStreamConnection;
use PhpAmqpLib\Message\AMQPMessage;
define('EXCHANGE_NAME', '交换器名');
define('QUEUE_NAME', '队列名');
define('ROUTING_KEY', '路由键');
$con = new AMQPStreamConnection('39.105.15.108', 5672, 'root', 'root');
$channel = $con->channel();
$channel->exchange_declare(EXCHANGE_NAME, 'direct', false, false, false);
$channel->queue_declare(QUEUE_NAME, false, false, false, false);
$channel->queue_bind(QUEUE_NAME, EXCHANGE_NAME, ROUTING_KEY);
$msg = new AMQPMessage('hello world');
$channel->basic_publish($msg, EXCHANGE_NAME, ROUTING_KEY);
echo '[x]发送hello world!'.PHP_EOL;
$channel->close();
$con->close();
以上代码声明了一个direct类型的交换器,然后将交换器和队列绑定起来。注意这里使用的字样是"ROUTING_KEY",在本该使用BindingKey的$channel.queue_bind方法中却和$channel.basic_publish方法同样使用了RoutingKey,这样做的潜台词是:这里的RoutingKey和BindingKey是同一个东西。在direct交换器类型下,RoutingKey和BindingKey需要完全匹配才能使用,所以上面代码中采用了此种写法会显得方便许多。
但是在topic交换器类型下,RoutingKey和BindingKey之间需要做模糊匹配,两者并不是相同的。BindingKey其实也属于路由键中的一种,官方解释为:the routing key to use for the binding。可以翻译为:在绑定的时候使用的路由键。大多数时候,包括官方文档和RabbitMQ PHP API中都把BindingKey和RoutingKey看做RoutingKey,为了避免混淆,可以这么理解:
- 在使用绑定的时候,其中需要的路由键是BindingKey。涉及的客户端方法如:$channel.exchange_bind、$channel.queue_bind,对应的AMQP命令为Exchange.Bind、Queue.bind。
- 在发送消息的时候,其中需要的路由键是RoutingKey。涉及的客户端方法如$channel.basic_publish,对应的AMQP命令为basic.publish。
由于某些历史的原因,包括现存能搜集到的资料显示:大多数情况下习惯性地将BindingKey写成RoutingKey,尤其是在使用direct类型的交换器的时候。后面的内容会将两者合称为路由键,读者需要注意区分其中的不同,可以根据上面的辨别方法进行有效的区分。
交换器类型
RabbitMQ常用的交换器类型有fanout、direct、topic、headers四种。AMQP协议里还提到另外两种类型:System和自定义,这里不与描述。对于这四种类型下面一一阐述。
fanout
它会把所有发送到该交换器的消息路由到所有与该交换器绑定的队列中。direct
direct类型的交换器路由规则也很简单,它会把消息路由到那些BindingKey和RoutingKey完全匹配的队列中。
以图2-7为例,交换器的类型为direct,如果我们发送一条消息,并在发送消息的时候设置了路由键为"warning",则消息会路由到Queue1和Queue2,对应的实例代码如下:$channel->basic_publish($msg, EXCHANGE_NAME, 'waning');

如果在发送消息的时候设置路由键为"info"或者"debug",消息只会路由到Queue2。如果以其它的路由键发送消息,则消息不会路由到这两个队列中。
topic
前面讲到direct类型的交换器路由规则是完全匹配BindingKey和RoutingKey,但是这种严格的匹配方式在很多情况下不能满足实际业务的需求。topic类型的交换器在匹配规则上进行了扩展,它与direct类型的交换器类似,也是将消息路由到BindingKey和RoutingKey想匹配的队列中,但这里的匹配规则有些不同,它约定:- RoutingKey为一个点号“.”分割的字符串(被点号“.”分隔开的每一段独立的字符串称为一个单词),如“com.rabbitmq.client”、“java.util.concurrent”、“com.hidden.client”;
- BindingKey和RoutingKey一样也是点号“.”分隔的字符串;
- BindingKey中可以存在两种特殊字符串“*”和“#”,用于做模糊匹配,其中“*”用于匹配一个单词,“#”用于匹配多规则单词(可以是零个)。
已图2-8中的配置为例:
- 路由键为“com.rabbitmq.client”的消息会同时路由到Queue1和Queue2;
- 路由键为“com.hidden.client”的消息只会路由到Queue2中;
- 路由键为“com.hidden.demo”的消息只会路由到Queue2中;
- 路由键为“java.rabbitmq.demo”的消息只会路由到Queue1中;
- 路由键为“java.util.concurrent”的消息将会被丢弃或者返回给生产者(需要设置mandatory参数),因为它没有匹配任何路由键。

headers
headers类型的交换器不依赖于路由键的匹配规则来路由消息,而是根据发送的消息内容中的headers属性进行匹配。在绑定队列和交换器时制定一组键值对,当发送消息到交换器时,RabbitMQ会获取到该消息的headers(也是一个键值对的形式),对比其中的键值对是否完全匹配队列和交换器绑定时指定的键值对,如果完全匹配则消息会路由到该队列,否则不会路由到该队列。headers类型的交换器性能会很差,而且也不实用,基本上不会看到它的存在。
RabbitMQ运转流程
了解了以上的RabbitMQ架构模型及相关术语,再来回顾整个消息队列过程。
在最初状态下,生产者发送消息的时候(可依照图2-1):
(1)生产者连接到RabbitMQ Broker,建立一个连接(Connection),开启一个信道(Channel)
(2)生产者声明一个交换器,并设置相关属性,比如交换器类型、是否持久化等
(3)生产者声明一个队列并设置相关属性,比如是否排他、是否持久化、是否自动删除等
(4)生产者通过路由键将交换器和队列绑定起来
(5)生产者发送消息至RabbitMQ Broker,其中包含路由键、交换器等信息
(6)相应的交换器根据接收到的路由键查找相匹配的队列。
(7)如果找到,则将从生产者发送过来的消息存入相应的队列。
(8)如果没有找到,则根据生产者配置的属性选择丢弃还是回退给生产者
(9)关闭信道
(10)关闭连接
消费者接收消息的过程:
(1)消费者连接到RabbitMQ Broker,建立一个连接(Connection),开启一个信道(Channel)。
(2)消费者向RabbitMQ Broker请求消费相应队列中的消息,可能会设置相应的回调函数,以及做一些准备工作。
(3)等待RabbitMQ Broker回应并投递相应队列中队列的消息,消费者接收消息。
(4)消费者确认(ack)接收到的消息。
(5)RabbitMQ从队列中删除相应已经被确认的消息。
(6)关闭信道
(7)关闭连接
如图2-9所示,我们又引入了两个新的概念:Connection和Channel。我们知道无论是生产者还是消费者,都需要和RabbitMQ Broker建立连接,这个连接就是一条TCP连接,也就是Connection。一旦TCP连接建立起来,客户端紧接着可以创建一个AMQP信道(Channel),每个信道都会被指派一个唯一的ID。信道是建立在Connection之上的虚拟连接,RabbitMQ处理的每条AMQP指令都是通过信道完成的。
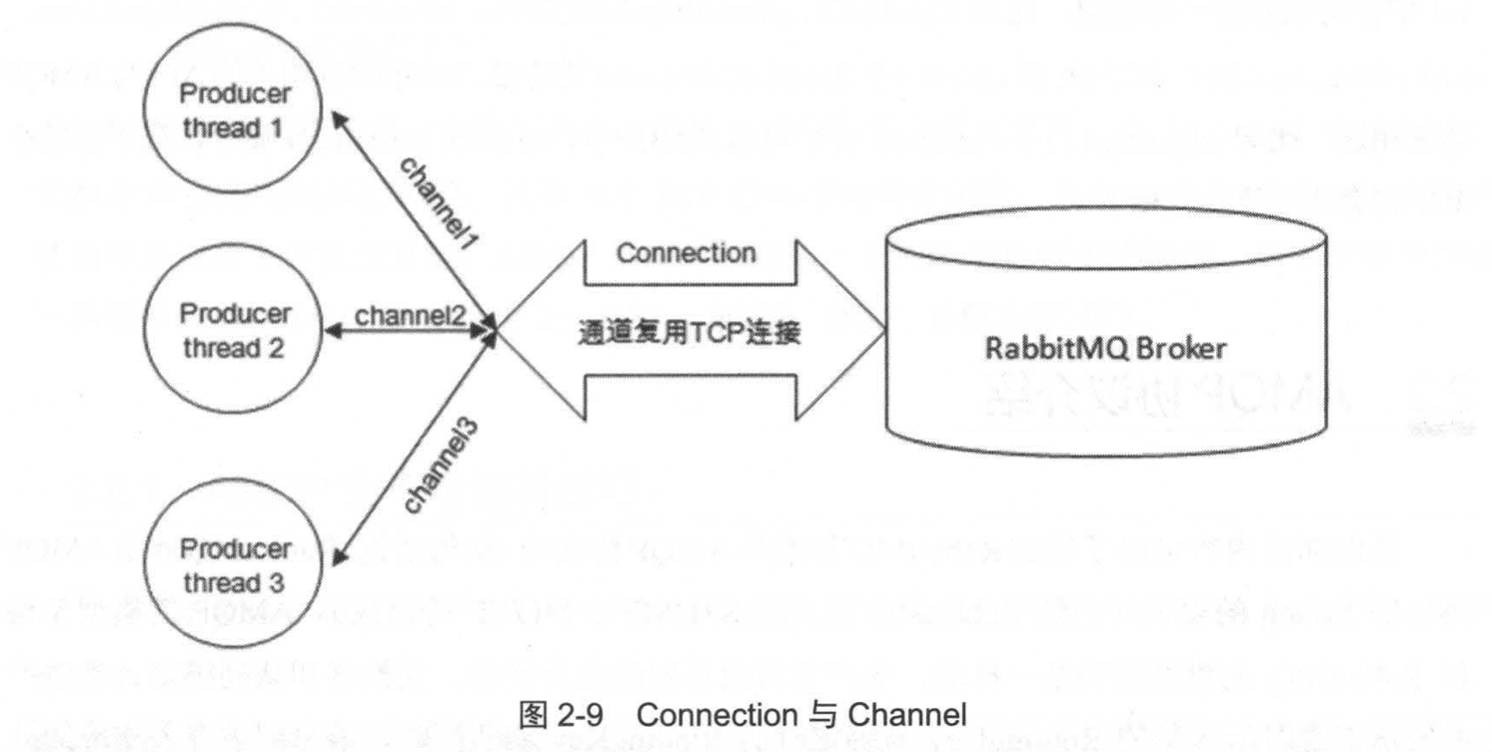
我们完全可以直接使用Connection就能完成信道的工作,为什么还要引入信道呢?试想这样一个场景,一个应用程序中有很多个线程需要从RabbitMQ中消费消息,或者生产消息,那么必然要建立很多个Connection,也就是许多个TCP连接。然后对于操作系统而言,建立和销毁TCP连接是非常昂贵的开销,如果遇到使用高峰,性能瓶颈也随之显现。RabbitMQ采用类似NIO(Non-blocking I/O)的做法,选择TCP连接复用,不仅可以减少性能开销,同时也便于管理。
每个线程把持一个信道,所以信道复用了Connection的TCP连接。同时RabbitMQ可以确保每个线程的私密性,就像拥有独立的连接一样。当每个信道的流量不是很大时,复用单一的Connection可以在产生性能瓶颈的情况下有效地节省TCP连接资源。但是当信道本身的流量很大时,这时候多个信道复用一个Connection就会产生性能瓶颈,进而使整体的流量被限制了。此时就需要开辟多个Connection,将这些信道均摊到这些Connection中,至于这些相关的调优策略需要根据业务自身的实际情况进行调节。
信道在AMQP中是一个很重要的概念,大多数操作都是在信道这个层面展开的。在代码中也可以看出一些端倪,比如$channel.exchange_declare、$channel.queue_declare、$channel.basic_publish和$channel.basic_consume等方法。RabbitMQ相关的API与AMQP紧密相连,比如$channel.basic_publish对应AMQP的Basic.Publish命令。
NIO,也称为非阻塞I/O,包含三大核心部分:Channel(信道)、Buffer(缓冲区)和Selector(选择器)。NIO基于Channel和Buffer进行操作,数据总是从信道读取数据到缓冲区中,或者从缓存区写入到信道中。Selector用于监听多个信道的事件(比如连接打开,数据到达等)。因此,单线程可以监听多个数据的信道。NIO中有一个很有名的Reactor模式,有兴趣的读者可以深入研究。
AMQP协议介绍
从前面的内容可恶意了解到RabbitMQ是遵从AMQP协议的,换句话说,RabbitMQ就是AMQP协议的Erlang实现(当然RabbitMQ还支持STOMP、MQTT等协议)。AMQP的模型架构和RabbitMQ的模型架构是一样的,生产者将消息发送给交换器,交换器和队列绑定。当生产者发送消息时所携带的RoutingKey与绑定时的BingingKey相匹配时,消息即被存入相应的队列之中。消费者可以订阅相应的队列来获取消息。
RabbitMQ中的交换器、交换器类型、队列、绑定、路由键等都是遵循的AMQP协议中相应的概念。目前RabbitMQ最新版本默认支持的是AMQP0-9-1。
AMQP协议本身包括三层。
- Module Layer:位于协议最高层,主要定义了一些供客户端调用的命令,客户端可以利用这些命令实现自己的业务逻辑。例如,客户端可以使用Queue.Declare命令声明一个队列或者使用Basic.Consume订阅消费一个队列中的消息。
- Session Layer:位于中间层,主要负责将客户端的命令发送给服务器,再将服务端的应答返回给客户端,主要为客户端与服务器之间的通信提供可靠性同步机制和错误处理。
- Transport Layer:位于最底层,主要传输二进制数据流,提供帧的处理、信道复用、错误检测和数据表示等。
AMQP说到底还是一个通信协议,通信协议都会涉及报文交互,从low-level距离来说,AMQP本身是应用层的协议,其填充于TCP的协议层的数据部分。而从high-level来说,AMQP是通过协议命令进行交互的。AMQP协议可以看作一系列结构化命令的集合,这里的命令代表一种操作,类似于HTTP中的方法(GET、POST、PUT、DELETE等)。
AMQP生产者流转过程
为了形象地说明AMQP协议命令的流转过程,这里示例简洁版生产者代码说明:
//创建连接
$connection = new AMQPStreamConnection('39.105.15.108', 5672, 'root', 'root');
//创建信道
$channel = $connection->channel();
$channel->queue_declare('hello', false, false, false, false);
$msg = new AMQPMessage('Hello World!');
$channel->basic_publish($msg, '', 'hello');
echo " [x] Sent 'Hello World!'\n";
$channel->close();
$connection->close();
当客户端与Broker建立连接的时候,会调用AMQPStreamConnection()的构造方法,这方法会进一步封装成Protocol Header0-9-1的报文头发送给Broker,一次通知Broker本次交互采用的是AMQP0-9-1协议,紧接着Broker返回Connection.Start来建立连接,在连接的过程中涉及Connection.Start/.Start-OK、Connection.Tune/.Tunk-Ok、Connection.Open/.Open-Ok这6个命令的交互。
当客户端调用connection.createChannel方法准备开启信道的时候、其包装Channel.Open命令发送给Broker,等待Channel.Open-Ok命令。
当客户端发送消息的时候,需要调用channel.basicPublish方法, 对应的AMQP命令为Basic.Publish,注意这个命令和前面涉及的命令略有不同,这个命令还包含了Content Header和Content Body。Content Header里面包含的是消息体的属性,例如,投递模式、优先级等,而Content Body包含消息体本身。
当客户端发送完消息需要关闭资源时,涉及Channel.Close/.Close-Ok与Connection.Close/.Close-Ok的命令及哦啊胡。详细流转过程如下图所示。

AMQP消费者流转过程
我们继续来看消费者的流转过程,消费端的关键代码如下所示:
$connection = new AMQPStreamConnection('localhost', 5672, 'root', 'root');
$channel = $connection->channel();
$channel->queue_declare('hello', false, false, false, false);
echo "[x] Waiting for messages. To exit press Ctrl+C".PHP_EOL;
$callback = function ($msg) {
echo '[x] Received ', $msg->body, PHP_EOL;
};
$channel->basic_consume('hello', '', false, true, false, false, $callback);
while ($channel->is_consuming()) {
$channel->wait();
}
其详细流转过程如下图所示:

消费者客户端同样需要与Broker建立连接,与生产者客户端一样,协议交互同样设计Connection.Start/.Start-Ok、Connection.Tune/Tune-Ok和Connection.Open/.Open-Ok等,图2-11中省略了这些步骤,可以参考图2-10。
紧接着也少不了在Connection之上建立channel,和生产者客户端一样,协议涉及Channel.Open/Open-Ok。
如果消费者之前调用了channel.BasicQos(int prefetchCount)的方法来涉及消费者客户端最大能”保持“的未确认的消息数,那么协议流转会涉及Basic.Qos/.Qos-Ok这两个AMQP命令。
在真正消费之前,消费者客户端需要向Broker发送Basic.Consume命令(即调用channel.basicConsume方法)将Channel置为接收模式,之后Broker回执Basic.Consume-Ok以告诉消费者客户端准备好消息消息。紧接着Broker向消费者客户端推送(Push)消息,即Basic.Deliver命令,有意思的是这个和Basic.Publish命令一样会携带Content Header和Content Body。
消费者接收到消息并正确消费之后,向Broker发送确认,即Basic.Ack命令。
在消费者停止消费的时候,主动关闭连接,这点和生产者一样,设计Channel.Close/.Close-Ok和Connection.Close/.Close-Ok。
安装RabbitMQ
安装依赖
yum install -y make gcc gcc-c++ m4 openssl openssl-devel
yum install -y ncurses-devel unixODBC unixODBC-devel java java-devel socat
安装Erlang
Erlang RPM包下载地址:https://packagecloud.io/rabbitmq/erlang

下载成功后,到下载的文件资源目录执行以下命令
yum localinstall erlang-22.3.4.10-1.el7.x86_64.rpm
安装成功后,可以以下运行命令来查看你安装的erl版本
erl -version
安装RabbitMQ
RabbitMQ RPM包下载地址:https://github.com/rabbitmq/rabbitmq-server/releases

当你下载完成后,你需要运行下面的命令来将key导入
rpm --import https://www.rabbitmq.com/rabbitmq-release-signing-key.asc
使用 yum 进行本地安装,运行命令
yum localinstall rabbitmq-server-3.8.8-1.el7.noarch.rpm
当安装完成后,你可以使用命令来启动 rabbitmq 服务器:
systemctl start rabbitmq-server

然后我们就可以添加web管理插件了
# 添加web管理插件
rabbitmq-plugins enable rabbitmq_management

安装好web管理插件后记得重启rabbitmq-server
我们通过IP:端口(http://172.16.93.128:15672)的形式,就可以访问RabbitMQ的Web管理界面了

默认情况下,访问RabbitMQ服务的用户名和密码都是"guest",这个账户有限制,默认只能通过本地网络(如localhost)访问,远程网络访问受限,使用默认的用户 guest / guest (此也为管理员用户)登陆,会发现无法登陆,报错:User can only log in via localhost。那是因为默认是限制了guest用户只能在本机登陆,也就是只能登陆localhost:15672。所以在实现生产和消费消息之前,需要另外添加一个用户,并设置相应的访问权限
添加新用户,用户名为"root",密码为"root"
rabbitmqctl add_user root root
为root用户设置所有权限
rabbitmqctl set_permissions -p / root ".*" ".*" ".*"
设置用户为管理员角色
rabbitmqctl set_user_tags root administrator
我们通过该用户就可以访问了

RabbitMQ常用命令
服务启动与停止
# 启动
systemctl start rabbitmq-server
# 停止
systemctl stop rabbitmq-server
# 查看状态
systemctl status rabbitmq-server
插件管理
# 插件列表
rabbitmq-plugins list
# 启动插件(XXX为插件名)
rabbitmq-plugins enable XXX
# 停用插件(XXX为插件名)
rabbitmq-plugins disable XXX
用户管理
# 添加用户
rabbitmqctl add_user username password
# 删除用户
rabbitmqctl delete_user username
# 修改密码
rabbitmqctl change_password username newpassword
# 设置用户角色
rabbitmqctl set_user_tags username tag
# 列出用户
rabbitmqctl list_users
权限管理
# 列出所有用户权限
rabbitmqctl list_permissions
# 查看指定用户权限
rabbitmqctl list_user_permissions username
# 清除用户权限
rabbitmqctl clear_permissions [-p vhostpath] username
# 设置用户权限
rabbitmqctl set_permissions [-p vhostpath] username conf write read
conf: 一个正则匹配哪些资源能被该用户访问
write:一个正则匹配哪些资源能被该用户写入
read: 一个正则匹配哪些资源能被该用户读取
Go操作RabbitMQ
Hello World
send.go
package main
import (
"fmt"
"github.com/streadway/amqp"
"log"
)
func main() {
//1.与RabbitMQ建立连接,该连接抽象了套接字连接,并为我们处理协议版本协商和认证等。
conn, err := amqp.Dial("amqp://root:itbsl2021.@39.105.15.108:5672/")
if err != nil {
log.Fatalf("连接RabbitMQ失败,错误为:%v\n", err)
}
defer conn.Close()
fmt.Println("成功连接RabbitMQ!")
//2.创建通道,大多数API都是通过该通道操作的
ch, err := conn.Channel()
if err != nil {
log.Fatalf("打开channel失败,错误为:%v\n", err)
}
defer ch.Close()
fmt.Println("成功打开channel!")
//3.声明队列(要发送,我们必须得声明消息要发送到的度列,然后我们可以将消息发布到队列中)
//声明队列是幂等的,仅当队列不存在时才创建,消息内容是一个字节数组,因此您可以在此处编码任何内容
q, err := ch.QueueDeclare(
"hello", //队列名称
false, //消息持久化(不持久化重启后未消费的消息会丢失)
false,//是否自动删除(当最后一个消费者断开连接以后,是否把我们的消息从队列中删除)
false, //是否具有排他性
false, //是否阻塞
nil, //额外参数
)
if err != nil {
log.Fatalf("声明队列失败,错误为:%v\n", err)
}
fmt.Println("成功声明队列!")
//4.将消息发布到队列
body := "Hello World!"
err = ch.Publish(
"",
q.Name,
false, //如果为true,根据exchange类型和routingKey规则,如果无法找到符合条件的队列,那么就会把发送的消息返还发送者
false, //如果为true,当exchange发送消息到队列后发现队列上没有绑定消费者,则会把消息返还给发送者
amqp.Publishing{
ContentType: "text/plain",
Body: []byte(body),
})
if err != nil {
log.Fatalf("消息发送失败,错误为:%v\n", err)
}
fmt.Println("成功发送消息!")
}
receive.go
package main
import (
"fmt"
"github.com/streadway/amqp"
"log"
)
func main() {
//1.与RabbitMQ建立连接,该连接抽象了套接字连接,并为我们处理协议版本协商和认证等。
conn, err := amqp.Dial("amqp://root:itbsl2021.@39.105.15.108:5672/")
if err != nil {
log.Fatalf("连接RabbitMQ失败,错误为:%v\n", err)
}
defer conn.Close()
fmt.Println("成功连接RabbitMQ!")
//2.创建通道,大多数API都是通过该通道操作的
ch, err := conn.Channel()
if err != nil {
log.Fatalf("打开channel失败,错误为:%v\n", err)
}
defer ch.Close()
fmt.Println("成功打开channel!")
//3.声明队列
//请注意,我们也在这里声明队列。因为我们可能在发布者之前启动消费者,所以我们希望在尝试使用队列中的消息之前确保队列存在
q, err := ch.QueueDeclare(
"hello", //队列名称
false, //持久化队列
false,//是否自动删除
false,
false,
nil,
)
if err != nil {
log.Fatalf("声明队列失败,错误为:%v\n", err)
}
fmt.Println("成功声明队列!")
//4.注册消费者
//我们将告诉服务器将队列中的消息传递给我们。
//由于它将异步地向我们发送消息,因此我们将在goroutine中从通道(由amqp :: Consume返回)中读取消息。
msgs, err := ch.Consume(
q.Name, //队列名称
"", //用来区分多个消费者
true, //是否自动应答
false, //是否具有排他性
false, //如果设置为true,表示不能将同一个connection中发送的消息传递给这个connection中的消费者
false, //队列消费是否阻塞
nil, //额外参数
)
if err != nil {
log.Fatalf("注册消费者失败,错误为:%v\n", err)
}
forever := make(chan bool)
go func() {
for data := range msgs {
//实现我们要处理的逻辑函数
fmt.Printf("收到一条消息:%s\n", data.Body)
}
}()
fmt.Printf("[*] 等待消息,使用Ctrl+C退出\n")
<-forever
}
Work queues
Publish/Subscribe
在上一教程中,我们创建了一个工作队列。 工作队列背后的假设是,每个任务都恰好交付给一个消费者。 在这一部分中,我们将做一些完全不同的事情-我们将消息传达给多个消费者。 这种模式称为“发布/订阅”。
为了说明这种模式,我们将构建一个简单的日志记录系统。 它包含两个程序-第一个程序将发出日志消息,第二个程序将接收并打印它们。
在我们的日志系统中,接收器程序的每个运行副本都将获取消息。 这样,我们将能够运行一个接收器并将日志定向到磁盘。 同时我们将能够运行其他接收器并在屏幕上查看日志。
本质上,已发布的日志消息将被广播到所有接收者。
在本教程的前面部分中,我们向队列发送消息和从队列接收消息。 现在是时候在Rabbit中引入完整的消息传递模型了。
让我们快速回顾一下先前教程中介绍的内容:
- 生产者是发送消息的用户应用程序。
- 队列是存储消息的缓冲区。
- 消费者是接收消息的用户应用程序。
RabbitMQ消息传递模型中的核心思想是生产者从不将任何消息直接发送到队列。 实际上,生产者经常甚至根本不知道是否将消息传递到任何队列。
相反,生产者只能将消息发送到交换机。 交换机做的事很简单。 一方面,它接收来自生产者的消息,另一方面,将它们推入队列。 交换机必须确切知道如何处理收到的消息。 是否应将其附加到特定队列? 是否应该将其附加到许多队列中? 还是应该丢弃它。 规则由交换机类型定义。
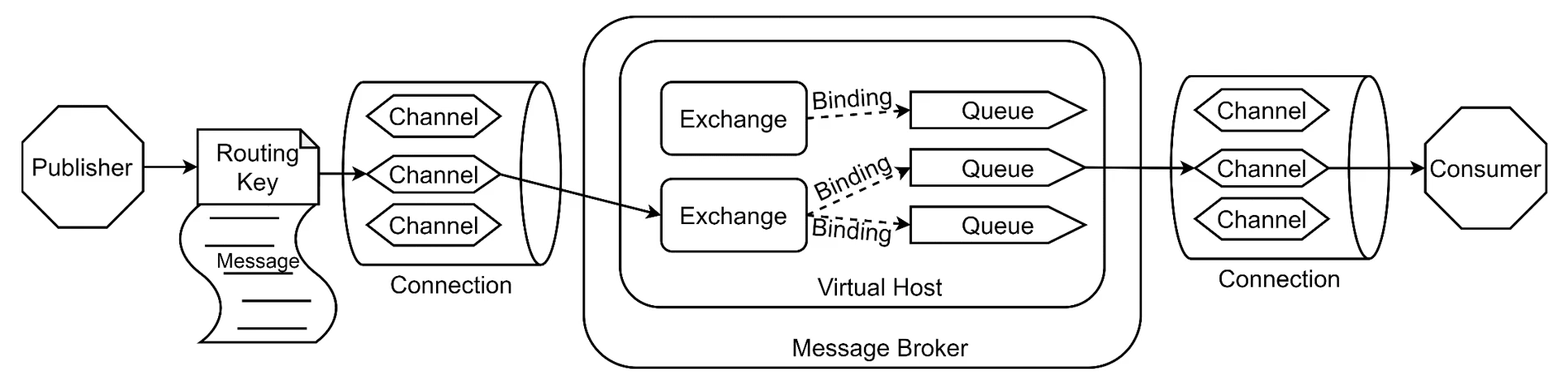
前面已经介绍过交换机有四种类型,direct、topic、fanout和headers。在发布/订阅模式下,我们需要使用fanout类型。
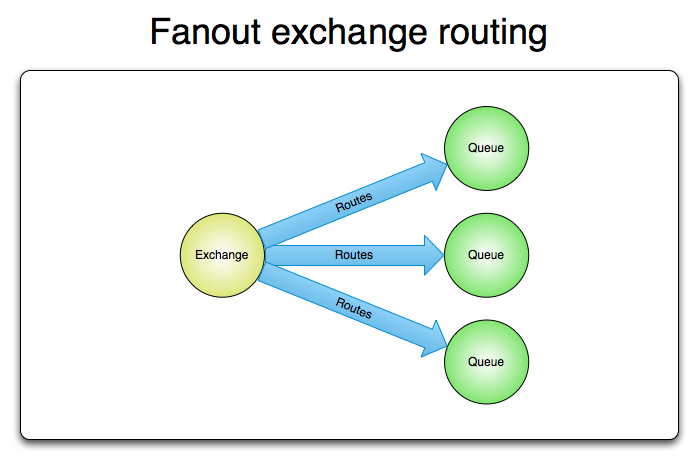
扇型交换机(funout exchange)将消息路由给绑定到它身上的所有队列,而不理会绑定的路由键。如果N个队列绑定到某个扇型交换机上,当有消息发送给此扇型交换机时,交换机会将消息的拷贝分别发送给这所有的N个队列。扇型用来交换机处理消息的广播路由(broadcast routing)。
因为扇型交换机投递消息的拷贝到所有绑定到它的队列,所以他的应用案例都极其相似:
- 大规模多用户在线(MMO)游戏可以使用它来处理排行榜更新等全局事件
- 体育新闻网站可以用它来近乎实时地将比分更新分发给移动客户端
- 分发系统使用它来广播各种状态和配置更新
- 在群聊的时候,它被用来分发消息给参与群聊的用户。(AMQP没有内置presence的概念,因此XMPP可能会是个更好的选择)
扇型交换机图例:
在本教程的前面部分中,我们对交换机一无所知,但仍然能够将消息发送到队列。 这是可能的,因为我们使用的是默认交换机,该交换由空字符串(“”)标识。我们使用默认或无名称交换:消息被路由到具有routing_key参数指定的名称的队列(如果存在)。
现在,我们可以改为发布到我们命名的交换机中:
集成/封装
我们可以基于streadway/amqp自己封装一下操作RabbitMQ的代码,使其使用起来更方便,下面是我封装的一个库,使用起来很简单,代码地址是https://github.com/itbsl/rabbitmq
安装
go get github.com/itbsl/rabbitmq
推荐使用go module
使用
github.com/itbsl/rabbitmq,使用起来很方便,只有8个方法,分别是创建五个不同类型的RabbitMQ实例的方法,一个关闭连接的方法,以及一个生产消息的方法和消费消息的方法。
如下:
创建RabbitMQ实例方法(5个)
//创建普通类型的rabbitmq实例,消息没有持久化
rabbitmq.NewSimpleRabbitMQ()
//创建工作队列模式的RabbitMQ实例:消息持久化,需要手动应答
rabbitmq.NewWorkQueueRabbitMQ()
//创建发布/订阅模式的RabbitMQ实例:消息持久化,自动应答
rabbitmq.NewPubSubRabbitMQ()
//创建路由模式的RabbitMQ实例:消息持久化,手动应答
rabbitmq.NewRouteRabbitMQ()
//创建话题模式的RabbitMQ实例:消息持久化,手动应答
rabbitmq.NewTopicRabbitMQ()
生产者客户端:
1.创建RabbitMQ实例
2.发送消息
package main
import (
"github.com/itbsl/rabbitmq"
"log"
)
func main() {
//连接RabbitMQ
url := "amqp://root:root@127.0.0.1:5672/"
mq, err := rabbitmq.NewWorkQueueRabbitMQ(url, "hello")
if err != nil {
log.Fatalf("连接RabbitMQ出错,错误为:%v\n", err)
}
defer mq.Close()
//发送消息
err = mq.Send("hello world!")
if err != nil {
log.Fatalf("发送消息失败,错误为:%v\n", err)
}
}
消费者客户端:
1.创建所需类型的RabbitMQ实例
2.消费消息,业务代码写在回调函数里
package main
import (
"github.com/itbsl/rabbitmq"
"log"
)
func main() {
//连接RabbitMQ
url := "amqp://root:root@127.0.0.1:5672/"
mq, err := rabbitmq.NewWorkQueueRabbitMQ(url, "hello")
if err != nil {
log.Fatalf("连接RabbitMQ出错,错误为:%v\n", err)
}
defer mq.Close()
//消费消息
err = mq.Consume(func(msg string) bool {
//这里写业务处理代码,业务处理成功,返回true用于手动应答,失败返回false,消息会被重新放入队列
return true
})
if err != nil {
log.Fatalf("消费失败,错误为:%v\n", err)
}
}
RabbitMQ基础教程的更多相关文章
- RabbitMQ基础教程之基本使用篇
RabbitMQ基础教程之基本使用篇 最近因为工作原因使用到RabbitMQ,之前也接触过其他的mq消息中间件,从实际使用感觉来看,却不太一样,正好趁着周末,可以好好看一下RabbitMQ的相关知识点 ...
- RabbitMq基础教程之基本概念
RabbitMq基础教程之基本概念 RabbitMQ是一个消息队列,和Kafka以及阿里的ActiveMQ从属性来讲,干的都是一回事.消息队列的主要目的实现消息的生产者和消费者之间的解耦,支持多应用之 ...
- RabbitMQ基础教程之使用进阶篇
RabbitMQ基础教程之使用进阶篇 相关博文,推荐查看: RabbitMq基础教程之安装与测试 RabbitMq基础教程之基本概念 RabbitMQ基础教程之基本使用篇 I. 背景 前一篇基本使用篇 ...
- RabbitMQ基础教程系列
Ubuntu16.04下,erlang安装和rabbitmq安装步骤 Ubuntu16.04下,rabbimq集群搭建 C# .net 环境下使用rabbitmq消息队列 .net core使用rab ...
- RabbitMQ基础教程之Spring&JavaConfig使用篇
RabbitMQ基础教程之Spring使用篇 相关博文,推荐查看: RabbitMq基础教程之安装与测试 RabbitMq基础教程之基本概念 RabbitMQ基础教程之基本使用篇 RabbitMQ基础 ...
- [转]RabbitMQ入门教程(概念,应用场景,安装,使用)
原文地址:https://www.jianshu.com/p/dae5bbed39b1 RabbitMQ 简介 RabbitMQ是一个在AMQP(Advanced Message Queuing Pr ...
- RabbitMQ,Apache的ActiveMQ,阿里RocketMQ,Kafka,ZeroMQ,MetaMQ,Redis也可实现消息队列,RabbitMQ的应用场景以及基本原理介绍,RabbitMQ基础知识详解,RabbitMQ布曙
消息队列及常见消息队列介绍 2017-10-10 09:35操作系统/客户端/人脸识别 一.消息队列(MQ)概述 消息队列(Message Queue),是分布式系统中重要的组件,其通用的使用场景可以 ...
- spring cloud 2.x版本 Spring Cloud Stream消息驱动组件基础教程(kafaka篇)
本文采用Spring cloud本文为2.1.8RELEASE,version=Greenwich.SR3 本文基于前两篇文章eureka-server.eureka-client.eureka-ri ...
- Spring Boot 2.x基础教程:使用Redis的发布订阅功能
通过前面一篇集中式缓存的使用教程,我们已经了解了Redis的核心功能:作为K.V存储的高性能缓存. 接下来我们会分几篇来继续讲讲Redis的一些其他强大用法!如果你对此感兴趣,一定要关注收藏我哦! 发 ...
随机推荐
- [译]Rxjs&Angular-退订可观察对象的n中方式
原文/出处: RxJS & Angular - Unsubscribe Like a Pro 在angular项目中我们不可避免的要使用RxJS可观察对象(Observables)来进行订阅( ...
- Java工作中的并发问题处理方法总结
Java工作中常见的并发问题处理方法总结 好像挺久没有写博客了,趁着这段时间比较闲,特来总结一下在业务系统开发过程中遇到的并发问题及解决办法,希望能帮到大家 问题复现 1. "设备Aの奇怪分 ...
- The Preliminary Contest for ICPC Asia Shanghai 2019 F. Rhyme scheme(dp)
题意:给你一个n和k 要你找到长度为n 字典序第k小的字符串 定义一个字符串合法:第i的字符的范围只能是前i-1个字符中的最大值+1 思路:我们dp[n][i][j]表示长度为n 在第i位 最大值为 ...
- 最短Hamilton路径(状压dp)
最短Hamilton路径实际上就是状压dp,而且这是一道作为一个初学状压dp的我应该必做的题目 题目描述 给定一张 n(n≤20) 个点的带权无向图,点从 0~n-1 标号,求起点 0 到终点 n-1 ...
- 【noi 2.2_8758】2的幂次方表示(递归)
题意:将正整数N用2的幂次方表示(彻底分解至2(0),2). 解法:将层次间和每层的操作理清楚,母问题分成子问题就简单了.但说得容易,操作没那么容易,我就打得挺纠结的......下面附上2个代码,都借 ...
- hdu5432 Pyramid Split
Problem Description Xiao Ming is a citizen who's good at playing,he has lot's of gold cones which ha ...
- Educational Codeforces Round 89 (Rated for Div. 2) C. Palindromic Paths (思维)
题意:有一个\(n\)x\(m\)的矩阵,从\((1,1)\)出发走到\((n,m)\),问最少修改多少个数,使得所有路径上的数对应相等(e.g:\((1,2)\)和\((n-1,m)\)或\((2, ...
- C# TCP应用编程二 同步TCP应用编程
不论是多么复杂的TCP 应用程序,双方通信的最基本前提就是客户端要先和服务器端进行TCP 连接,然后才可以在此基础上相互收发数据.由于服务器需要对多个客户端同时服务,因此程序相对复杂一些.在服务器端, ...
- Python+Appium实现自动抢微信红包
前言 过年的时候总是少不了红包,不知从何时开始微信红包横空出世,对于网速和手速慢的人只能在一旁观望,做为python的学习者就是要运用编程解决生活和工作上的事情. 于是我用python解决我们的手速问 ...
- [Golang]-4 错误处理、Panic、Defer
目录 错误和异常 案例 Panic Defer 使用 defer+recover 来处理错误 参考文章: Go 语言使用一个独立的·明确的返回值来传递错误信息的.这与使用异常的 Java 和 Ruby ...