hadoop3.2+Centos7+5个节点主从模式配置
准备工作:
hadoop3.2.0+jdk1.8+centos7+zookeeper3.4.5
以上是我搭建集群使用的基础包
一、环境准备
| master1 | master2 | slave1 | slave2 | slave3 |
| jdk、NameNode、DFSZKFailoverController(zkfc) | jdk、NameNode、DFSZKFailoverController(zkfc) | jdk、hadoop、zookeeper DataNode、NodeManager、JournalNode、QuorumPeerMain | jdk、hadoop、zookeeper DataNode、NodeManager、JournalNode、QuorumPeerMain | jdk、hadoop、zookeeper DataNode、NodeManager、JournalNode、QuorumPeerMain |
说明:
在hadoop集群中通常由两个namenode组成,一个处于active状态,一个处于stanbdy状态,Active NameNode对外提供服务,而Standby NameNode则不对外提供服务,仅同步active namenode的状态,以便能够在它失败时快速进行切换。
hadoop官方提供了两种HDFS HA的解决方案,一种是NFS,另一种是QJM。这里我们使用简单的QJM。在该方案中,主备NameNode之间通过一组JournalNode同步元数据信息,一条数据只要成功写入多数JournalNode即认为写入成功。通常配置奇数个JournalNode这里还配置了一个zookeeper集群,用于ZKFC(DFSZKFailoverController)故障转移,当Active NameNode挂掉了,会自动切换Standby NameNode为standby状态。
hadoop中依然存在一个问题,就是ResourceManager只有一个,存在单点故障,hadoop-3.2.0解决了这个问题,有两个ResourceManager,一个是Active,一个是Standby,状态由zookeeper进行协调。
将五个虚拟机分别关闭防火墙,更改主机名:
systemctl stop firewalld
systemctl disabled firewalld vim /etc/hostname
在五台虚拟机依次修改,保存
master1
master2
slave1
slave2
slave3
配置hosts文件:
vim /etc/hosts
#添加内容
master1 192.168.60.10
master2 192.168.60.11
slave1 192.168.60.12
slave2 192.168.60.13
slave3 192.168.60.14
配置免密登录:
ssh-keygen -t rsa #在每台虚拟机执行
cd /root/.ssh/
cat id_rsa.pub >> authorized_keys
scp authorized_keys root@master2:/root/.ssh/
#一次执行上述步骤,最后分发 authorized_keys 文件到各个节点
二、安装步骤
jdk1.8安装:
1.解压文件
tar -zxvf jdk1.8.tar.gz -C /usr/local #自己定义目录
2.配置环境变量
vim /etc/profile export JAVA_HOME=/usr/local/jdk
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$JAVA_HOME/bin:$PATH
source /etc/profile #更新资源
java -version #验证
zookeeper安装:
1.解压zookeeper
tar -zxvf zookeeper-3.4.5.tar.gz -C /usr/local/soft #自己定义目录
2.修改配置文件
cd /usr/local/zookeeper-3.4.5/conf/
cp zoo_sample.cfg zoo.cfg
vim zoo.cfg
#修改一下内容
dataDir=/usr/local/soft/zookeeper-3.4.5/tmp
在后面添加:
server.1=slave1:2888:3888
server.2=slave2:2888:3888
server.3=slave3:2888:3888
#保存退出
3.在zookeeper目录下创建tmp文件夹
mkdir /usr/local/soft/zookeeper-3.4.5/tmp
再创建一个空文件
touch /usr/local/soft/zookeeper-3.4.5/tmp/myid
最后向该文件写入ID
echo 1 > /usr/local/soft/zookeeper-3.4.5/tmp/myid
4.将配置好的zookeeper拷贝到其他节点(首先分别在slave2、slave3根目录下创建一个soft目录:mkdir /usr/local/soft/)
scp -r /usr/local/soft/zookeeper-3.4.5/ itcast06:/usr/local/soft
scp -r /usr/local/soft/zookeeper-3.4.5/ itcast07:/usr/local/soft
5.注意要修改myid内容
slave2:
echo 2 > /usr/local/soft/zookeeper-3.4.5/tmp/myid
slave3:
echo 3 > /usr/local/soft/zookeeper-3.4.5/tmp/myid
6.启动zookeeperokeeper集群(三台机器都要启动)
cd 到zookeeper/conf下
./zdServer.sh start
hadoop集群配置:
1.解压文件
tar -zxvf hadoop-3.2.0.tar.gz -C /usr/local/soft/
2.添加环境变量
vim /etc/profile export HADOOP_HOME=/usr/local/soft/hadoop-3.2.0
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/bin:$PATH source /etc/profile #更新资源
hadoop version #验证
3.配置hadoop-env.sh,添加JAVA_HOME
export JAVA_HOME=/usr/local/jdk
4.配置core-site.xml
<configuration>
<!-- 指定hdfs的nameservice为ns1 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://ns1</value>
</property>
<!-- 指定hadoop临时目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/soft/hadoop-3.2.0/tmp</value>
</property>
<!-- 指定zookeeper地址 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>slave1:2181,slave2:2181,slave3:2181</value>
</property>
</configuration>
5.配置hdfs-site.xml
<configuration>
<!--指定hdfs的nameservice为ns1,需要和core-site.xml中的保持一致 -->
<property>
<name>dfs.nameservices</name>
<value>ns1</value>
</property>
<!-- ns1下面有两个NameNode,分别是nn1,nn2 -->
<property>
<name>dfs.ha.namenodes.ns1</name>
<value>nn1,nn2</value>
</property>
<!-- nn1的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns1.nn1</name>
<value>master1:9000</value>
</property>
<!-- nn1的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns1.nn1</name>
<value>master1:50070</value>
</property>
<!-- nn2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns1.nn2</name>
<value>master2:9000</value>
</property>
<!-- nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns1.nn2</name>
<value>master2:50070</value>
</property>
<!-- 指定NameNode的元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://slave1:8485;slave2:8485;slave3:8485/ns1</value>
</property>
<!-- 指定JournalNode在本地磁盘存放数据的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/usr/local/soft/hadoop-3.2.0/journal</value>
</property>
<!-- 开启NameNode失败自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 配置失败自动切换实现方式 -->
<property>
<name>dfs.client.failover.proxy.provider.ns1</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制方法,多个机制用换行分割,即每个机制暂用一行-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
<!-- 使用sshfence隔离机制时需要ssh免登陆 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
</property>
<!-- 配置sshfence隔离机制超时时间 -->
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
</configuration>
6.配置mapred-site.xml
<configuration>
<!-- 指定mr框架为yarn方式 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
7.配置yarn-site.xml
<configuration>
<!-- 开启RM高可靠 -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 指定RM的cluster id -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yrc</value>
</property>
<!-- 指定RM的名字 -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2,rm3</value>
</property>
<!-- 分别指定RM的地址 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>slave1</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>slave2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm3</name>
<value>slave3</value>
</property>
<!-- 指定zk集群地址 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>slave1:2181,slave2:2181,slave3:2181</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 防止运行mapreduce出错根据hadoop classpath输出决定value -->
<property>
<name>yarn.application.classpath</name>
<value>/usr/local/soft/hadoop-3.2.0/etc/hadoop:/usr/local/soft/hadoop-3.2.0/share/hadoop/common/lib/*:/usr/local/soft/hadoop-3.2.0/share/hadoop/common/*:/usr/local/soft/hadoop-3.2.0/share/hadoop/hdfs:/usr/local/soft/hadoop-3.2.0/share/hadoop/hdfs/lib/*:/usr/local/soft/hadoop-3.2.0/share/hadoop/hdfs/*:/usr/local/soft/hadoop-3.2.0/share/hadoop/mapreduce/lib/*:/usr/local/soft/hadoop-3.2.0/share/hadoop/mapreduce/*:/usr/local/soft/hadoop-3.2.0/share/hadoop/yarn:/usr/local/soft/hadoop-3.2.0/share/hadoop/yarn/lib/*:/usr/local/soft/hadoop-3.2.0/share/hadoop/yarn/*</value>
</property>
</configuration>
8.配置workers
slave1
slave2
slave3
9.配置sbin/start-yarn.sh、sbin/stop-yarn.sh 和 sbin/start-dfs.sh sbin/stop-dfs.sh
dfs添加:
HDFS_NAMENODE_USER=root
HDFS_DATANODE_USER=root
HDFS_JOURNALNODE_USER=root
HDFS_ZKFC_USER=root
yarn添加:
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
10.将Hadoop3.2.0分发到各个节点
scp -r hadoop3.2.0 root@master2:/usr/local/soft/
scp -r hadoop3.2.0 root@slave1:/usr/local/soft/
scp -r hadoop3.2.0 root@slave2:/usr/local/soft/
scp -r hadoop3.2.0 root@slave3:/usr/local/soft/
三、启动集群
zookeeper集群已经启动
cd /usr/local/soft/zookeeper-3.4.5/bin/
./zkServer.sh start
#查看状态:一个leader,两个follower
./zkServer.sh status




启动journalnode(分别在在slave1、slave2、slave3上执行)
cd /usr/local/soft/hadoop-3.2.0
sbin/hadoop-daemon.sh start journalnode
#运行jps命令检验,多了JournalNode进程
格式化HDFS
#在master1上执行命令:
hdfs namenode -format
#格式化后会在根据core-site.xml中的hadoop.tmp.dir配置生成个文件,这里我配置的是/usr/local/soft/hadoop-3.2.0/tmp,然后将/usr/local/soft/hadoop-3.2.0/tmp拷贝到itcast02的/usr/local/soft/hadoop-3.2.0/tmp下。
scp -r tmp/ root@master2:/usr/local/soft/hadoop-3.2.0 #分发到各个节点
格式化ZK(在master1)上执行
hdfs zkfc -formatZK
启动集群(在master1)执行
sbin/start-dfs.sh
sbin/start-yarn.sh
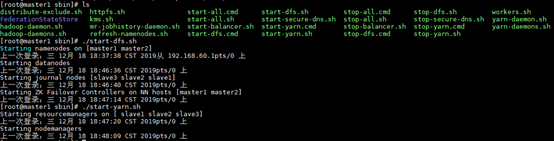
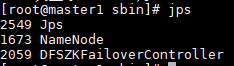
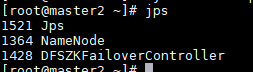

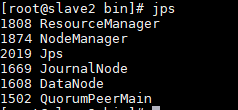
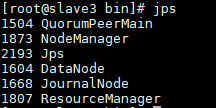
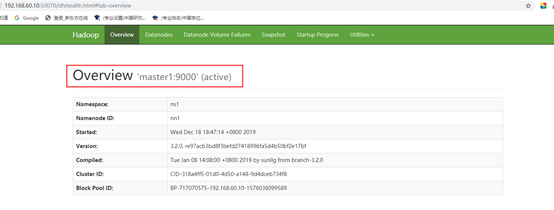

验证YARN:
运行一下hadoop提供的demo中的WordCount程序:
cd到hadoop目录下:
hadoop fs -put /etc/profile /
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.0.jar wordcount /profile /out
hadoop3.2+Centos7+5个节点主从模式配置的更多相关文章
- CentOS7下Mysql5.7主从数据库配置
本文配置主从使用的操作系统是Centos7,数据库版本是mysql5.7. 准备好两台安装有mysql的机器(mysql安装教程链接) 主数据库配置 每个从数据库会使用一个MySQL账号来连接主数据库 ...
- redis的主从模式搭建及注意事项
前言:本文先分享下如何搭建redis的主从模式配置,以及主从模式配置的注意事项.后续会继续分享如何实现一个高可用的redis服务,redis的Sentinel 哨兵模式及集群搭建. 安装: 1,yum ...
- Redis 单例、主从模式、sentinel 以及集群的配置方式及优缺点对比(转)
摘要: redis作为一种NoSql数据库,其提供了一种高效的缓存方案,本文则主要对其单例,主从模式,sentinel以及集群的配置方式进行说明,对比其优缺点,阐述redis作为一种缓存框架的高可用性 ...
- Nginx知多少系列之(十四)Linux下.NET Core项目Nginx+Keepalived高可用(主从模式)
目录 1.前言 2.安装 3.配置文件详解 4.工作原理 5.Linux下托管.NET Core项目 6.Linux下.NET Core项目负载均衡 7.负载均衡策略 8.加权轮询(round rob ...
- Nginx+keepalived双机热备(主从模式)
负载均衡技术对于一个网站尤其是大型网站的web服务器集群来说是至关重要的!做好负载均衡架构,可以实现故障转移和高可用环境,避免单点故障,保证网站健康持续运行.关于负载均衡介绍,可以参考:linux负载 ...
- solr 主从模式和solrcloud集群模式
主从模式 主节点有单点故障问题:没有主从自动切换,没有failover,主机down掉了的话,整个数据变成只读.并且需要一台机单独做索引,浪费资源,所有数据都需要在这台机器上单独存在一份,索引变化较大 ...
- Linux keepalived+nginx实现主从模式
双机高可用方法目前分为两种: 主从模式:一台主服务器和一台从服务器,当配置了虚拟vip的主服务器发送故障时,从服务器将自动接管虚拟ip,服务将不会中断.但主服务器不出现故障的时候,从服务器永远处于浪费 ...
- nginx + keepalived 主从模式
转自:https://www.cnblogs.com/kevingrace/p/6138185.html 负载均衡技术对于一个网站尤其是大型网站的web服务器集群来说是至关重要的!做好负载均衡架构,可 ...
- Nginx+Keeplived双机热备(主从模式)
Nginx+Keeplived双机热备(主从模式) 参考资料: http://www.cnblogs.com/kevingrace/p/6138185.html 双机高可用一般是通过虚拟IP(漂移IP ...
随机推荐
- moviepy音视频剪辑:与大小相关的视频变换函数详解
☞ ░ 前往老猿Python博文目录 ░ 一.引言 在<moviepy音视频剪辑:moviepy中的剪辑基类Clip详解>介绍了剪辑基类的fl.fl_time.fx方法,在<movi ...
- Python基础篇学习感悟:学如不及,犹恐失之
从2019年3月底开始学习Python,4月12日在CSDN发表第一篇博文,时至今日已有4个月零12天. 4个多月的学习,老猿从一个Python小白成长到今天,可以说对Python这门语言已经略知一二 ...
- GYCTF Web区部分WP
目录: Blacklist Easyphp Ezsqli FlaskApp EasyThinking 前言: 这次比赛从第二天开始打的,因为快开学了所以就没怎么看题目(主要还是自己太菜)就只做出一道题 ...
- js- for in 循环 只有一个目的,遍历 对象,通过对象属性的个数 控制循环圈数
for in 循环会返回 原型 以及原型链上面的属性,不会打印系统自带的属性 var obj ={ name:'suan', sex :'male', age:150, height:185, ...
- Day3 Scrum 冲刺博客
·线上会议: 昨天已完成的工作与今天计划完成的工作及工作中遇到的困难: 成员姓名 昨天完成工作 今天计划完成的工作 工作中遇到的困难 纪昂学 创建一个Cell类,用来表示一个小方块 就创建一个Tetr ...
- 使用eslint将项目中的代码修改统一的缩进
背景 继承了组里师兄师姐写的项目的前端代码,但是是两个人写的,有两格缩进的,有四格缩进的,有字符串外用单引号的,有用双引号的. 于是搜索了一下,可以用eslint强制转化. eslint在github ...
- 在iframe中获取另一个iframe中的元素
$(top.parent.iframeId).contents().find("#selector") //iframeId为iframe的id名称
- 【题解】「AT4303」[ABC119D] Lazy Faith
AT4303 [ABC119D] Lazy Faith[题解][二分] AT4303 translation 有 \(a\) 个点 \(s\),有 \(b\) 个点 \(t\),问从点 \(x\) 出 ...
- oracle 11g调优常用语句
1.查询表的基数及选择性 select a.column_name, b.num_rows, a.num_distinct cardinality, round( ...
- SpringBoot集成Swagger2并配置多个包路径扫描
1. 简介 随着现在主流的前后端分离模式开发越来越成熟,接口文档的编写和规范是一件非常重要的事.简单的项目来说,对应的controller在一个包路径下,因此在Swagger配置参数时只需要配置一 ...