Flink-v1.12官方网站翻译-P003-Real Time Reporting with the Table API

利用表格API进行实时报告
Apache Flink提供的Table API是一个统一的、关系型的API,用于批处理和流处理,即在无边界的、实时的流或有边界的、批处理的数据集上以相同的语义执行查询,并产生相同的结果。Flink中的Table API通常用于简化数据分析、数据管道化和ETL应用的定义。
你将建设什么?
在本教程中,您将学习如何构建一个实时的仪表盘,以按账户跟踪金融交易。该管道将从Kafka读取数据,并将结果写入MySQL,通过Grafana可视化。
先决条件
本演练假设你对Java或Scala有一定的熟悉,但即使你来自不同的编程语言,你也应该能够跟上。它还假设你熟悉基本的关系概念,如SELECT和GROUP BY子句。
救命,我被卡住了!
如果你遇到困难,请查看社区支持资源。特别是Apache Flink的用户邮件列表,一直是Apache项目中最活跃的一个,也是快速获得帮助的好方法。
如果在windows上运行docker,而你的数据生成器容器却无法启动,那么请确保你使用的shell是正确的。例如docker-entrypoint.sh for table-walkthrough_data-generator_1容器需要使用bash。如果不可用,它会抛出一个错误standard_init_linux.go:211: exec用户进程引起 "no such file or directory"。一个变通的方法是在docker-entrypoint.sh的第一行将shell切换为sh。
如何跟进
如果你想跟着走,你需要一台电脑与。
Java 8或11
Maven
Docker
所需的配置文件可在flink-playgrounds资源库中获得。下载后,在IDE中打开项目flink-playground/table-walkthrough,并导航到文件SpendReport。
EnvironmentSettings settings = EnvironmentSettings.newInstance().build();
TableEnvironment tEnv = TableEnvironment.create(settings); tEnv.executeSql("CREATE TABLE transactions (\n" +
" account_id BIGINT,\n" +
" amount BIGINT,\n" +
" transaction_time TIMESTAMP(3),\n" +
" WATERMARK FOR transaction_time AS transaction_time - INTERVAL '5' SECOND\n" +
") WITH (\n" +
" 'connector' = 'kafka',\n" +
" 'topic' = 'transactions',\n" +
" 'properties.bootstrap.servers' = 'kafka:9092',\n" +
" 'format' = 'csv'\n" +
")"); tEnv.executeSql("CREATE TABLE spend_report (\n" +
" account_id BIGINT,\n" +
" log_ts TIMESTAMP(3),\n" +
" amount BIGINT\n," +
" PRIMARY KEY (account_id, log_ts) NOT ENFORCED" +
") WITH (\n" +
" 'connector' = 'jdbc',\n" +
" 'url' = 'jdbc:mysql://mysql:3306/sql-demo',\n" +
" 'table-name' = 'spend_report',\n" +
" 'driver' = 'com.mysql.jdbc.Driver',\n" +
" 'username' = 'sql-demo',\n" +
" 'password' = 'demo-sql'\n" +
")"); Table transactions = tEnv.from("transactions");
report(transactions).executeInsert("spend_report");
拆解代码
执行环境
前两行设置了你的表环境(TableEnvironment)。表环境是你如何为你的Job设置属性,指定你是在写批处理还是流式应用,以及创建你的源。本演练创建了一个使用流式执行的标准表环境。
EnvironmentSettings settings = EnvironmentSettings.newInstance().build();
TableEnvironment tEnv = TableEnvironment.create(settings);
注册表格
接下来,在当前目录中注册了表,您可以使用这些表连接到外部系统,以便读写批处理和流数据。表源提供对存储在外部系统中的数据的访问,如数据库、键值存储、消息队列或文件系统。表汇向外部存储系统发出一个表。根据源和汇的类型,它们支持不同的格式,如CSV、JSON、Avro或Parquet。
tEnv.executeSql("CREATE TABLE transactions (\n" +
" account_id BIGINT,\n" +
" amount BIGINT,\n" +
" transaction_time TIMESTAMP(3),\n" +
" WATERMARK FOR transaction_time AS transaction_time - INTERVAL '5' SECOND\n" +
") WITH (\n" +
" 'connector' = 'kafka',\n" +
" 'topic' = 'transactions',\n" +
" 'properties.bootstrap.servers' = 'kafka:9092',\n" +
" 'format' = 'csv'\n" +
")");
注册了两个表:一个是交易输入表,一个是消费报告输出表。交易(transaction)表让我们可以读取信用卡交易,其中包含账户ID(account_id)、时间戳(transaction_time)和美元金额(金额)。该表是在一个名为transaction的Kafka主题上的逻辑视图,包含CSV数据。
tEnv.executeSql("CREATE TABLE spend_report (\n" +
" account_id BIGINT,\n" +
" log_ts TIMESTAMP(3),\n" +
" amount BIGINT\n," +
" PRIMARY KEY (account_id, log_ts) NOT ENFORCED" +
") WITH (\n" +
" 'connector' = 'jdbc',\n" +
" 'url' = 'jdbc:mysql://mysql:3306/sql-demo',\n" +
" 'table-name' = 'spend_report',\n" +
" 'driver' = 'com.mysql.jdbc.Driver',\n" +
" 'username' = 'sql-demo',\n" +
" 'password' = 'demo-sql'\n" +
")");
第二张表spend_report,存储了最终的汇总结果。其底层存储是MySql数据库中的一张表。
查询
配置好环境和注册好表后,你就可以构建你的第一个应用程序了。从TableEnvironment中,你可以从一个输入表中读取它的行,然后使用executeInsert将这些结果写入一个输出表。报表函数是你实现业务逻辑的地方。它目前还没有被实现。
Table transactions = tEnv.from("transactions");
report(transactions).executeInsert("spend_report");
测试
该项目包含一个二次测试类SpendReportTest,用于验证报表的逻辑。它以批处理模式创建了一个表格环境。
EnvironmentSettings settings = EnvironmentSettings.newInstance().inBatchMode().build();
TableEnvironment tEnv = TableEnvironment.create(settings);
Flink的独特属性之一是它在批处理和流式处理之间提供一致的语义。这意味着您可以在静态数据集上以批处理模式开发和测试应用程序,并以流式应用程序的形式部署到生产中。
尝试一
现在有了Job设置的骨架,你就可以添加一些业务逻辑了。目标是建立一个报告,显示每个账户在一天中每个小时的总支出。这意味着时间戳列需要从毫秒到小时的颗粒度进行舍入。
Flink支持用纯SQL或使用Table API开发关系型应用。Table API是一个受SQL启发的流畅的DSL,可以用Python、Java或Scala编写,并支持强大的IDE集成。就像SQL查询一样,Table程序可以选择所需的字段,并通过你的键进行分组。这些功能,加上内置的函数,如floor和sum,你可以写这个报告。
public static Table report(Table transactions) {
return transactions.select(
$("account_id"),
$("transaction_time").floor(TimeIntervalUnit.HOUR).as("log_ts"),
$("amount"))
.groupBy($("account_id"), $("log_ts"))
.select(
$("account_id"),
$("log_ts"),
$("amount").sum().as("amount"));
}
用户自定义函数
Flink包含有限的内置函数,有时你需要用用户定义的函数来扩展它。如果地板不是预定义的,你可以自己实现它。
import java.time.LocalDateTime;
import java.time.temporal.ChronoUnit; import org.apache.flink.table.annotation.DataTypeHint;
import org.apache.flink.table.functions.ScalarFunction; public class MyFloor extends ScalarFunction { public @DataTypeHint("TIMESTAMP(3)") LocalDateTime eval(
@DataTypeHint("TIMESTAMP(3)") LocalDateTime timestamp) { return timestamp.truncatedTo(ChronoUnit.HOURS);
}
}
然后迅速将其集成到你的应用程序中。
public static Table report(Table transactions) {
return transactions.select(
$("account_id"),
call(MyFloor.class, $("transaction_time")).as("log_ts"),
$("amount"))
.groupBy($("account_id"), $("log_ts"))
.select(
$("account_id"),
$("log_ts"),
$("amount").sum().as("amount"));
}
这个查询会消耗事务表的所有记录,计算报表,并以高效、可扩展的方式输出结果。使用该实现运行测试将通过。
添加窗口
基于时间的数据分组是数据处理中的典型操作,尤其是在处理无限流时。基于时间的分组被称为窗口,Flink提供了灵活的窗口语义。最基本的窗口类型称为Tumble窗口,它有一个固定的大小,其桶不重叠。
public static Table report(Table transactions) {
return transactions
.window(Tumble.over(lit(1).hour()).on($("transaction_time")).as("log_ts"))
.groupBy($("account_id"), $("log_ts"))
.select(
$("account_id"),
$("log_ts").start().as("log_ts"),
$("amount").sum().as("amount"));
}
这就定义了你的应用程序使用基于时间戳列的一小时翻滚窗口。因此,时间戳为2019-06-01 01:23:47的行被放在2019-06-01 01:00:00窗口中。
基于时间的聚合是独一无二的,因为在连续流应用中,时间与其他属性不同,一般是向前移动的。与 floor 和你的 UDF 不同,窗口函数是内在的,它允许运行时应用额外的优化。在批处理上下文中,窗口提供了一个方便的API,用于通过时间戳属性对记录进行分组。
用这个实现运行测试也会通过。
再一次,用流处理
就是这样,一个功能齐全、有状态的分布式流式应用! 查询持续消耗Kafka的事务流,计算每小时的花费,并在结果准备好后立即发出。由于输入是无限制的,所以查询一直在运行,直到手动停止。而且由于Job使用了基于时间窗口的聚合,所以当框架知道某个窗口不会再有记录到达时,Flink可以进行特定的优化,比如状态清理。
表游乐场是完全docker化的,可以作为流媒体应用在本地运行。该环境包含一个Kafka主题、一个连续数据生成器、MySql和Grafana。
从table-walkthrough文件夹内启动docker-compose脚本。
$ docker-compose build
$ docker-compose up -d你可以通过Flink控制台查看正在运行的作业信息。
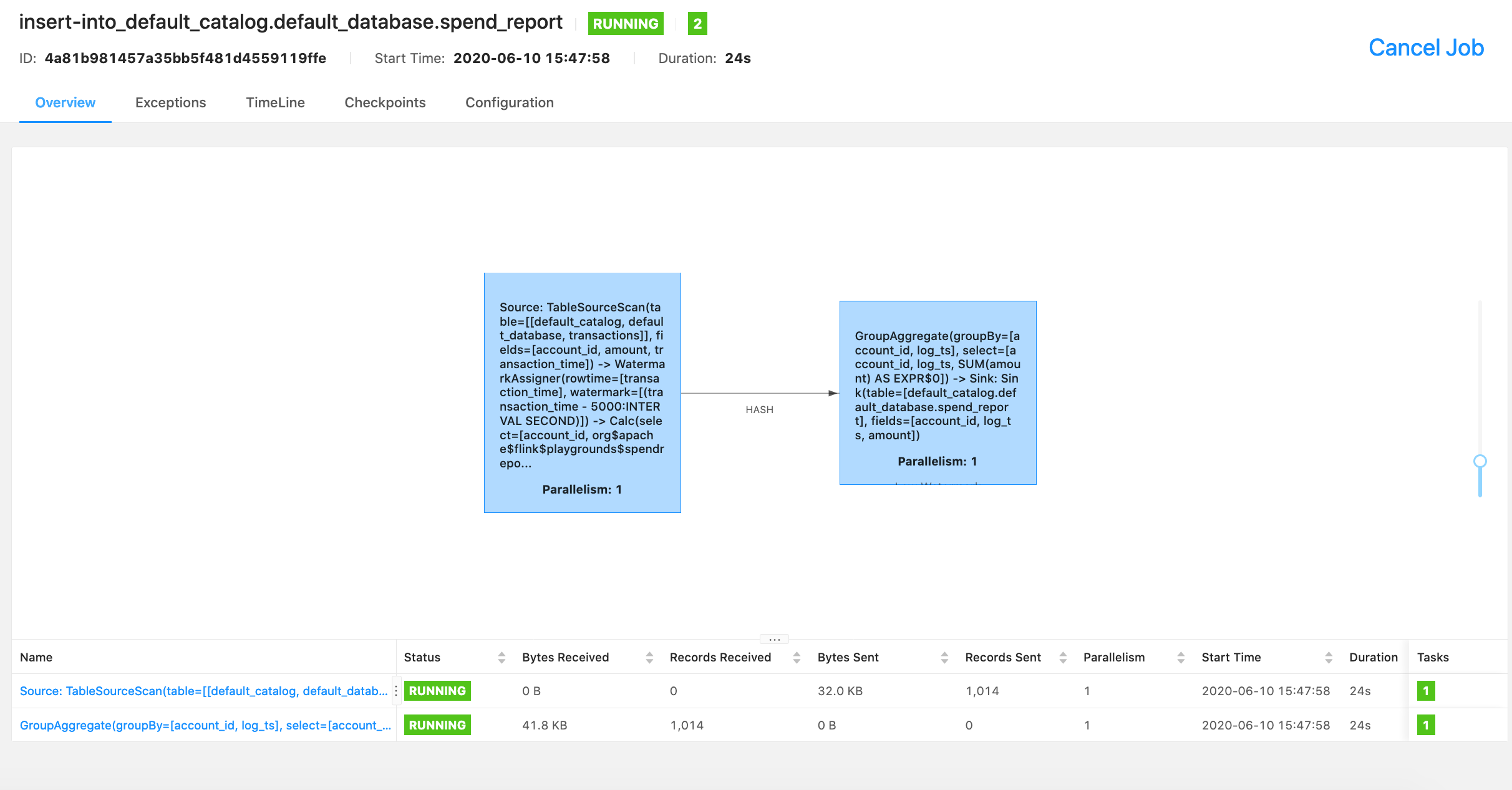
从MySQL内部探究结果。
$ docker-compose exec mysql mysql -Dsql-demo -usql-demo -pdemo-sql mysql> use sql-demo;
Database changed mysql> select count(*) from spend_report;
+----------+
| count(*) |
+----------+
| 110 |
+----------+
最后,去Grafana看看完全可视化的结果吧!

Flink-v1.12官方网站翻译-P003-Real Time Reporting with the Table API的更多相关文章
- Flink-v1.12官方网站翻译-P028-Custom Serialization for Managed State
管理状态的自定义序列化 本页面的目标是为需要使用自定义状态序列化的用户提供指导,涵盖了如何提供自定义状态序列化器,以及实现允许状态模式演化的序列化器的指南和最佳实践. 如果你只是简单地使用Flink自 ...
- Flink-v1.12官方网站翻译-P011-Concepts-Overview
概念-概览 实践培训解释了作为Flink的API基础的有状态和及时流处理的基本概念,并提供了这些机制如何在应用中使用的例子.有状态的流处理是在数据管道和ETL的背景下介绍的,并在容错部分进一步发展.在 ...
- Flink-v1.12官方网站翻译-P005-Learn Flink: Hands-on Training
学习Flink:实践培训 本次培训的目标和范围 本培训介绍了Apache Flink,包括足够的内容让你开始编写可扩展的流式ETL,分析和事件驱动的应用程序,同时省略了很多(最终重要的)细节.本书的重 ...
- Flink-v1.12官方网站翻译-P025-Queryable State Beta
可查询的状态 注意:可查询状态的客户端API目前处于不断发展的状态,对所提供接口的稳定性不做保证.在即将到来的Flink版本中,客户端的API很可能会有突破性的变化. 简而言之,该功能将Flink的托 ...
- Flink-v1.12官方网站翻译-P002-Fraud Detection with the DataStream API
使用DataStream API进行欺诈检测 Apache Flink提供了一个DataStream API,用于构建强大的.有状态的流式应用.它提供了对状态和时间的精细控制,这使得高级事件驱动系统的 ...
- Flink-v1.12官方网站翻译-P015-Glossary
术语表 Flink Application Cluster Flink应用集群是一个专用的Flink集群,它只执行一个Flink应用的Flink作业.Flink集群的寿命与Flink应用的寿命绑定. ...
- Flink-v1.12官方网站翻译-P008-Streaming Analytics
流式分析 事件时间和水印 介绍 Flink明确支持三种不同的时间概念. 事件时间:事件发生的时间,由产生(或存储)该事件的设备记录的时间 摄取时间:Flink在摄取事件时记录的时间戳. 处理时间:您的 ...
- Flink-v1.12官方网站翻译-P004-Flink Operations Playground
Flink操作训练场 在各种环境中部署和操作Apache Flink的方法有很多.无论这种多样性如何,Flink集群的基本构件保持不变,类似的操作原则也适用. 在这个操场上,你将学习如何管理和运行Fl ...
- Flink-v1.12官方网站翻译-P001-Local Installation
本地安装 按照以下几个步骤下载最新的稳定版本并开始使用. 第一步:下载 为了能够运行Flink,唯一的要求是安装了一个有效的Java 8或11.你可以通过以下命令检查Java的正确安装. java - ...
随机推荐
- centos7.5安装Oracle11gR2
centos7.5安装Oracle11gR2 说明:由于上一台旧的笔记本电脑(CPU:i5-7200,内存:8G,硬盘:128SSD+1T机械)卸任,所以打算在家搭建一个个人服务器(主要是换不锈钢盆不 ...
- 一道有趣的golang排错题
很久没写博客了,不得不说go语言爱好者周刊是个宝贝,本来想随便看看打发时间的,没想到一下子给了我久违的灵感. go语言爱好者周刊78期出了一道非常有意思的题目. 我们来看看题目.先给出如下的代码: p ...
- 关于 percona monitoring plugins插件报slave is stoped on ip地址
思路:肯定是某个item触发了触发器 去看触发器,找到 slave is stoped,如下图 看到键是mysql.running-slave ,然后去定义key的文件中查看该键对应的脚本,修改脚本. ...
- stat filename
查看文件的mtime,atime,ctime 3个时间
- 分布式系统:xxl-job改造spring-cloud
目录 改造原因 主要改造思路 调度中心 调度中心 执行器侧 总结 修改后的源码仓库地址:GitHub. : 改造原因 原有的xxl-job使用自己实现的http协议进行注册以及调度等,与目前框架中本身 ...
- STGAN: A Unified Selective Transfer Network for Arbitrary Image Attribute Editing 阅读笔记和pytorch代码解读
一.论文采用的新方法 1.AttGan中skip connect的局限性 由于encoder中对特征的下采样实际上可能损失部分特征,我们在decoder中进行上采样和转置卷积也无法恢复所有特征,因此A ...
- qt for webassembly环境搭建图文教程
一.前言 从Qt5.14开始,官方的在线安装提供了qt for webassembly构建套件,这对很多小白来说绝对是个好消息,也绝对是个好东西,好消息是不用再去交叉编译自己生成qt for weba ...
- win32 修改Edit控件文本颜色与背景色
#define WM_CTLCOLORMSGBOX 0x0132 #define WM_CTLCOLOREDIT 0x0133 //编辑控件Edit #define WM_CTLCOLORLISTBO ...
- IE浏览器的卸载操作
1.首先进入打开这个 C:\Windows\TEMP\ 文件夹,将里面的所有文件都清空了. 2.依次点击"开始"-"所有程序"-"附件",右 ...
- Jmeter接口自动化测试系列之函数使用及扩展
介绍一下Jmeter自带函数的使用和 函数扩展,来满足测试工作中的各种需求! Jmeter自带函数 点击函数帮助助手图标,弹出函数助手框,可以选择各种各样的函数 举例: _Random 获取随机数,可 ...