白日梦的Elasticsearch笔记(一)基础篇
一、导读

Hi All!我们一起学点有意思的!NoSQL!欢迎订阅白日梦Elasticsearch专题系列文章。按计划这个专题一共有四篇文章。所有文章公众号首发。
所有文章公众号首发!
所有文章公众号首发!
所有文章公众号首发!
所有文章公众号首发!
Notice!!!白日梦并不能保证通过这四篇文章让你掌握ES,但是!我会用大白话串讲ES的一些概念、和花哨的玩法。起码可以把你对Elasticsearch的陌生度降到最低,等有一天你自己业务需要使用ES时,会因为提前读了白日梦的ES笔记而快速上手。

为写这篇文章我还华为云上购置了一台2C4G的服务器,欢迎关注白日梦,我们一起学点实用的!有趣的技术!
1.1、认识ES
关系型数据库:
像MySQL这种数据库就是传统的关系型数据库。它有个很直观的特点:每一张数据表的列在创建表的时候就需要确定下来。比如你创建一个user表,定义了3列id、username、password。这时如果你的实体类中多了一个age的字段,那这个实体是不能保存进user表的。(当然后续你可以通过DDL修改添加列或者减少列。让实体类的属性和表中的列一一对应)。
非关系型数据库:
非关系型数据库也就是我们常听说的NoSQL。常见的有:MongoDB、Redis、Elasticsearch。
且不说性能方面,单说使用方面NoSQL这种非关系类型的数据库都支持你往它里面存储一个json对象,这个json有多少个字段并不是它关系的,拿上面的例子来说,只要你给他一个对象,不管有没有age、它都能帮你存储进去。
关于ES更多的知识点我们在下文中展开,再说一下ES常见的使用场景和特性:
站内搜索:
如果你的公司想做自己的站内搜索,那ES再合适不过了。作为非关系型数据库的ES允许你往它里面存储各种格式不确定的Json对象,还为你提供了全文本搜索和分析引擎。它使您可以快速,近乎实时地(1 s)存储,搜索和分析大量数据。一个字:快!
日志采集系统:
Elasticsearch是Elastic公司的核技术,并且Elastic公司还有其他诸如:Logstash、Filebeat、Kibana等技术栈。常见的公司里面使用的日志管理系统就可以使用ELK+Filebeat搭建起来,Filebeat收集日志推送到Logstash做处理,然后Logstash将数据存储入ES,最终通过Kibana展示日志。
可扩展性:
Elasticsearch天生就是分布式的,既能以单机的形式运行一台性能很差的服务器上。它也可以形成一个成百上千节点的集群。并且它自己会管理集群中的节点,在ES中我们可以随意的添加、摘除节点,集群自己会将数据均摊在各个节点上。
1.2、安装、启动ES、Kibana、IK分词器
- 安装很简单,所以详细过程不会写到文章中。
- 安装启动教程、ES、Kibana、IK分词器安装包都以百度网盘的方式分享给大家,后台回复:es 可领取
二、核心概念
因为这是第一篇基础篇,对小白友好一些,所以需要先了解一些基本概念,你可以耐折性子读一下,都不难理解的哈。
2.1、Near Realtime (NRT)
ES号称对外提供的是近实时的搜索服务,意思是数据从写入ES到可以被Searchable仅仅需要1秒钟,所以说基于ES执行的搜索和分析可以达到秒级。
2.2、Cluster
集群:集群是一个或多个node的集合,它们一起保存你存放进去的数据,用户可以在所有的node之间进行检索,一般的每个集群都会有一个唯一的名称标识,默认的名称标识为 elasticsearch ,这个名字很重要,因为node想加入cluster时,需要这个名称信息。
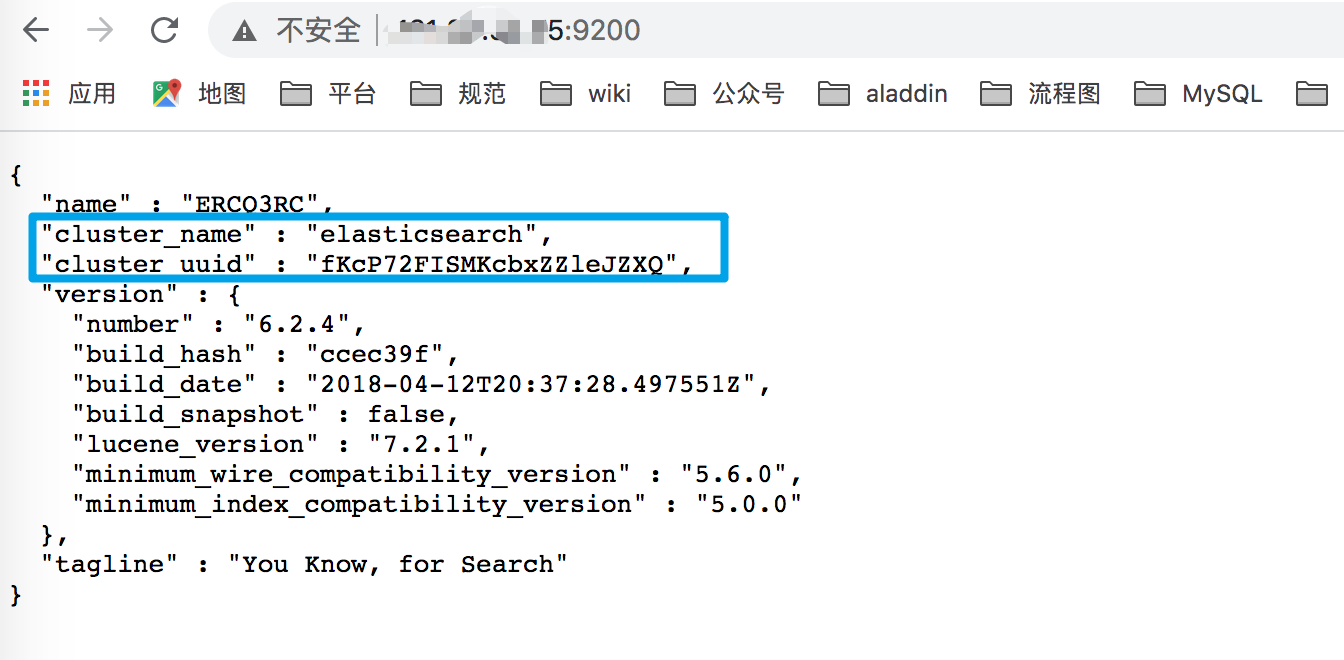
确保别在不同的环境中使用相同的集群名称,进而避免node加错集群的情况,一颗考虑下面的集群命名风格logging-stage和logging-dev和logging-pro。
2.3、Node
单台server就是一个node,它和cluster一样,也存在一个默认的名称。但是它的名称是通过UUID生成的随机串,当然用户也可以定制不同的名称,但是这个名字最好别重复。这个名称对于管理来说很在乎要,因为需要确定,当前网络中的哪台服务器,对应这个集群中的哪个节点。
node存在一个默认的设置,默认的,当每一个node在启动时都会自动的去加入一个叫elasticsearch的节点,这就意味着,如果用户在网络中启动了多个node,它们会彼此发现,然后组成集群。
在单个的cluster中,你可以拥有任意多的node。假如说你的网络上没有其它正在运行的节点,然后你启动一个新的节点,这个新的节点自己会组建一个集群。
2.4、Index
Index是一类拥有相似属性的document的集合,比如你可以为消费者的数据创建一个index,为产品创建一个index,为订单创建一个index。
index名称(必须是小写的字符), 当需要对index中的文档执行索引、搜索、更新、删除、等操作时,都需要用到这个index。
理论上:你可以在一个集群中创建任意数量的index。
2.5、Type
Type可以作为index中的逻辑类别。为了更细的划分,比如用户数据type、评论数据type、博客数据type
在设计时尽最大努力让拥有更多相同field的document划分到同一个type下。
2.6、Document
document就是ES中存储的一条数据,就像mysql中的一行记录一样。它可以是一条用户的记录、一个商品的记录等等
2.7、一个不严谨的小结:
为什么说这是不严谨的小结呢? 就是说下面三个对应关系只能说的从表面上看起来比较相似。但是ES中的type其实是一个逻辑上的划分。数据在存储是时候依然是混在一起存储的(往下看下文中有写),而mysql中的不同表的两个列是绝对没有关系的。
| Elasticsearch | 关系型数据库 |
|---|---|
| Document | 行 |
| type | 表 |
| index | 数据库 |
2.8、Shards & Replicas
2.8.1、问题引入:
如果让一个Index自己存储1TB的数据,响应的速度就会下降。为了解决这个问题,ES提供了一种将用户的Index进行subdivide的骚操作,就是将index分片,每一片都叫一个Shards,进而实现了将整体庞大的数据分布在不同的服务器上存储。
2.8.2、什么是shard?
shard分成replica shard和primary shard。顾名思义一个是主shard、一个是备份shard, 负责容错以及承担部分读请求。
shard可以理解成是ES中最小的工作单元。所有shard中的数据之和,才是整个ES中存储的数据。 可以把shard理解成是一个luncene的实现,拥有完整的创建索引,处理请求的能力。
下图是两个node,6个shard的组成的集群的划分情况:
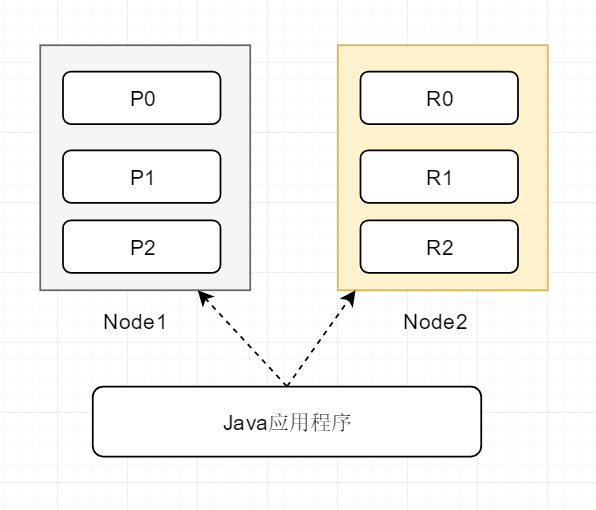
你可以看一下上面的图,图中无论java应用程序访问的是node1还是node2,其实都能获取到数据。
2.8.3、shard的默认数量
新创建的节点会存在5个primary shard,注意!后续不然能再改动primary shard的值,如果每一个primary shard都对应一个replica shard,按理说单台es启动就会存在10个分片,但是现实是,同一个节点的replica shard和primary shard不能存在于一个server中,因此单台es默认启动后的分片数量还是5个。
2.8.4、如何拓容Cluster
首先明确一点: 一旦index创建完成了,primary shard的数量就不可能再发生变化。
因此横向拓展就得添加replica的数量, 因为replica shard的数量后续是可以改动的。也就是说,如果后续我们将它的数量改成了2, 就意味着让每个primary shard都拥有了两个replica shard, 计算一下: 5+5*2=15 集群就会拓展成15个节点。
如果想让每一个shard都有最多的系统的资源就增加服务器的数量,让每一个shard独占一个服务器。
2.8.5、举个例子:
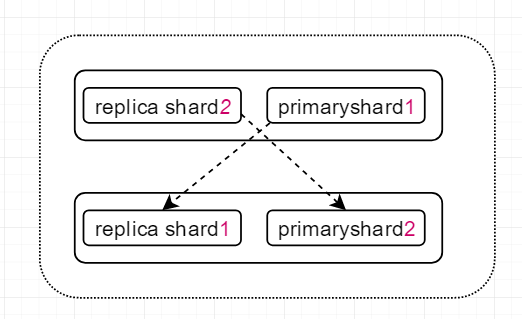
上图中存在上下两个node,每个node中都有一个 自己的primary shard和其它节点的replica shard,为什么是强调自己和其它呢? 因为ES中规定,同一个节点的replica shard和primary shard不能存在于一个server中,而不同节点的primary shard可以存在于同一个server上。
当primary shard宕机时,因为它对应的replicas shard在其它的server没有受到影响,所以ES可以继续响应用户的读请求。通过这种分片的机制,并且分片的地位相当,假设单个shard可以处理2000/s的请求,通过横向拓展可以在此基础上成倍提升系统的吞吐量,天生分布式,高可用。
此外: 每一个document肯定存在于一个primary shard和这个primary shard 对应的replica shard中, 绝对不会出现同一个document同时存在于多个primary shard中的情况。
三、入门探索:
下面的小节中你会看到我使用大量的GET / POST 等等包括什么query。其实你不用诧异为啥整一堆这些东西而不写点代码。
其实这些命令对于ES来说,就像是SQL和MySQL的关系。换句话说,其实你写的代码的底层帮你执行的也是我下面说得的这些命令。所以,别怕麻烦,下面的这些知识点无论如何你都不能直接跨越过去。
3.1、集群的健康状况
GET /_cat/health?v
执行结果如下:
epoch timestamp cluster status node.total node.data shards pri relo init unassign pending_tasks max_task_wait_time active_shards_percent
1572595632 16:07:12 elasticsearch yellow 1 1 5 5 0 0 5 0 - 50.0%
解读上面的信息,默认的集群名是elasticsearch,当前集群的status是yellow,后续列出来的是集群的分片信息,最后一个active_shards_percent表示当前集群中仅有一半shard是可用的。
状态:
存在三种状态分别是:red、green、yellow
- green : 表示当前集群所有的节点全部可用。
- yellow: 表示ES中所有的数据都是可以访问的,但是并不是所有的replica shard都是可以使用的(我现在是默认启动一个node,而ES又不允许同一个node的primary shard和replica shard共存,因此我当前的node中仅仅存在5个primary shard,为status为黄色)。
- red: 集群宕机,数据不可访问。
3.2、集群的索引信息
GET /_cat/indices?v
结果:
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
yellow open ai_answer_question cl_oJNRPRV-bdBBBLLL05g 5 1 203459 0 172.3mb 172.3mb
显示状态为yellow,表示存在replica shard不可用, 存在5个primary shard,并且每一个primary shard都有一个replica shard , 一共20多万条文档,未删除过文档,文档占用的空间情况为172.3兆。
3.3、创建index
PUT /customer?pretty
ES 使用的RestfulAPI,新增使用put,这是个很亲民的举动。
3.4、添加 or 修改
如果是ES中没有过下面的数据则添加进去,如果存在了id=1的元素就修改(全量替换)。
- 格式:
PUT /index/type/id
全量替换时,原来的document是没有被删除的!而是被标记为deleted,被标记成的deleted是不会被检索出来的,当ES中数据越来越多时,才会删除它。
PUT /customer/_doc/1?pretty
{
"name": "John Doe"
}
响应:
{
"_index": "customer",
"_type": "_doc",
"_id": "1",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 0,
"_primary_term": 1
}
强制创建,加添_create或者?op_type=create。
PUT /customer/_doc/1?op_type=create
PUT /customer/_doc/1/_create
- 局部更新(Partial Update)
不指定id则新增document。
POST /customer/_doc?pretty
{
"name": "Jane Doe"
}
指定id则进行doc的局部更新操作。
POST /customer/_doc/1?pretty
{
"name": "Jane Doe"
}
并且POST相对于上面的PUT而言,不论是否存在相同内容的doc,只要不指定id,都会使用一个随机的串当成id,完成doc的插入。
Partial Update先获取document,再将传递过来的field更新进document的json中,将老的doc标记为deleted,再将创建document,相对于全量替换中间会省去两次网络请求
3.5、检索
格式: GET /index/type/
GET /customer/_doc/1?pretty
响应:
{
"_index": "customer",
"_type": "_doc",
"_id": "1",
"_version": 1,
"found": true,
"_source": {
"name": "John Doe"
}
}
3.6、删除
删除一条document。
大部分情况下,原来的document不会被立即删除,而是被标记为deleted,被标记成的deleted是不会被检索出来的,当ES中数据越来越多时,才会删除它。
DELETE /customer/_doc/1
响应:
{
"_index": "customer",
"_type": "_doc",
"_id": "1",
"_version": 2,
"result": "deleted",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 1,
"_primary_term": 1
}
删除index
DELETE /index1
DELETE /index1,index2
DELETE /index*
DELETE /_all
可以在elasticsearch.yml中将下面这个设置置为ture,表示禁止使用 DELETE /_all
action.destructive_required_name:true
响应
{
"acknowledged": true
}
3.6、更新文档
上面说了POST关键字,可以实现不指定id就完成document的插入, POST + _update关键字可以实现更新的操作。
POST /customer/_doc/1/_update?pretty
{
"doc": { "name": "changwu" }
}
POST+_update进行更新的动作依然需要指定id, 但是相对于PUT来说,当使用POST进行更新时,id不存在的话会报错,而PUT则会认为这是在新增。
此外: 针对这种更新操作,ES会先删除原来的doc,然后插入这个新的doc。
四、document api
4.1、search
- 检索所有索引下面的所有数据
/_search
- 搜索指定索引下的所有数据
/index/_search
- 更多模式
/index1/index2/_search
/*1/*2/_search
/index1/index2/type1/type2/_search
/_all/type1/type2/_search
4.2、_mget api 批量查询
mget是ES为我们提供的批量查询的API,我们只需要制定好 index、type、id。ES会将命中的记录批量返回给我们。
- 在docs中指定
_index,_type,_id
GET /_mget
{
"docs" : [
{
"_index" : "test",
"_type" : "_doc",
"_id" : "1"
},
{
"_index" : "test",
"_type" : "_doc",
"_id" : "2"
}
]
}
- 在URL中指定index
GET /test/_mget
{
"docs" : [
{
"_type" : "_doc",
"_id" : "1"
},
{
"_type" : "_doc",
"_id" : "2"
}
]
}
- 在URL中指定 index和type
GET /test/type/_mget
{
"docs" : [
{
"_id" : "1"
},
{
"_id" : "2"
}
- 在URL中指定index和type,并使用ids指定id范围
GET /test/type/_mget
{
"ids" : ["1", "2"]
}
- 为不同的doc指定不同的过滤规则
GET /_mget
{
"docs" : [
{
"_index" : "test",
"_type" : "_doc",
"_id" : "1",
"_source" : false
},
{
"_index" : "test",
"_type" : "_doc",
"_id" : "2",
"_source" : ["field3", "field4"]
},
{
"_index" : "test",
"_type" : "_doc",
"_id" : "3",
"_source" : {
"include": ["user"],
"exclude": ["user.location"]
}
}
]
}
4.3、_bulk api 批量增删改
4.3.1、基本语法
{"action":{"metadata"}}\n
{"data"}\n
存在哪些类型的操作可以执行呢?
delete: 删除文档。
create: _create 强制创建。
index: 表示普通的put操作,可以是创建文档也可以是全量替换文档。
update: 局部替换。
上面的语法中并不是人们习惯阅读的json格式,但是这种单行形式的json更具备高效的优势。
ES如何处理普通的json如下:
- 将json数组转换为JSONArray对象,这就意味着内存中会出现一份一模一样的拷贝,一份是json文本,一份是JSONArray对象。
但是如果上面的单行JSON,ES直接进行切割使用,不会在内存中整一个数据拷贝出来。
4.3.2、delete
delete比较好看仅仅需要一行json就ok
{ "delete" : { "_index" : "test", "_type" : "_doc", "_id" : "2" } }
4.3.3、create
两行json,第一行指明我们要创建的json的index,type以及id
第二行指明我们要创建的doc的数据
{ "create" : { "_index" : "test", "_type" : "_doc", "_id" : "3" } }
{ "field1" : "value3" }
4.3.4、index
相当于是PUT,可以实现新建或者是全量替换,同样是两行json。
第一行表示将要新建或者是全量替换的json的index type 以及 id。
第二行是具体的数据。
{ "index" : { "_index" : "test", "_type" : "_doc", "_id" : "1" } }
{ "field1" : "value1" }
4.3.5、update
表示 parcial update,局部替换。
它可以指定一个retry_on_conflict的特性,表示可以重试3次。
POST _bulk
{ "update" : {"_id" : "1", "_type" : "_doc", "_index" : "index1", "retry_on_conflict" : 3} }
{ "doc" : {"field" : "value"} }
{ "update" : { "_id" : "0", "_type" : "_doc", "_index" : "index1", "retry_on_conflict" : 3} }
{ "script" : { "source": "ctx._source.counter += params.param1", "lang" : "painless", "params" : {"param1" : 1}}, "upsert" : {"counter" : 1}}
{ "update" : {"_id" : "2", "_type" : "_doc", "_index" : "index1", "retry_on_conflict" : 3} }
{ "doc" : {"field" : "value"}, "doc_as_upsert" : true }
{ "update" : {"_id" : "3", "_type" : "_doc", "_index" : "index1", "_source" : true} }
{ "doc" : {"field" : "value"} }
{ "update" : {"_id" : "4", "_type" : "_doc", "_index" : "index1"} }
{ "doc" : {"field" : "value"}, "_source": true}
4.4、滚动查询技术
如果你想一次性查询好几万条数据,这么庞大的数据量,ES性能肯定会受到影响。这时可以选择使用滚动查询(scroll)。一批一批的查询,直到所有的数据被查询完成。也就是说它会先搜索一批数据再搜索一批数据。
示例如下:每次发送一次scroll请求,我们还需要指定一个scroll需要的参数:一个时间窗口,每次搜索只要在这个时间窗口内完成就ok。
GET /index/type/_search?scroll=1m
{
"query":{
"match_all":{}
},
"sort":["_doc"],
"size":3
}
响应
{
"_scroll_id": "DnF1ZXJ5VGhlbkZldGNoBQAAAAAAAACNFlJmWHZLTkFhU0plbzlHX01LU2VzUXcAAAAAAAAAkRZSZlh2S05BYVNKZW85R19NS1Nlc1F3AAAAAAAAAI8WUmZYdktOQWFTSmVvOUdfTUtTZXNRdwAAAAAAAACQFlJmWHZLTkFhU0plbzlHX01LU2VzUXcAAAAAAAAAjhZSZlh2S05BYVNKZW85R19NS1Nlc1F3",
"took": 9,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 2,
"max_score": null,
"hits": [
{
"_index": "my_index",
"_type": "_doc",
"_id": "2",
"_score": null,
"_source": {
"title": "This is another document",
"body": "This document has a body"
},
"sort": [
0
]
},
{
"_index": "my_index",
"_type": "_doc",
"_id": "1",
"_score": null,
"_source": {
"title": "This is a document"
},
"sort": [
0
]
}
· ]
}
}
查询下一批数据时,需要携带上一次scroll返回给我们的_scroll_id再次滚动查询
GET /_search/scroll
{
"scroll":"1m",
"_scroll_id": "DnF1ZXJ5VGhlbkZldGNoBQAAAAAAAACNFlJmWHZLTkFhU0plbzlHX01LU2VzUXcAAAAAAAAAkRZSZlh2S05BYVNKZW85R19NS1Nlc1F3AAAAAAAAAI8WUmZYdktOQWFTSmVvOUdfTUtTZXNRdwAAAAAAAACQFlJmWHZLTkFhU0plbzlHX01LU2VzUXcAAAAAAAAAjhZSZlh2S05BYVNKZW85R19NS1Nlc1F3"
}
滚动查询时,如果采用基于_doc的排序方式会获得较高的性能。
五、下一篇目录:
一、_search api 搜索api
1.1、query string search
1.2、query dsl 20个查询案例
1.3、其它辅助API
1.4、聚合分析
1.4.1、filter aggregate
1.4.2、嵌套聚合-广度优先
1.4.3、global aggregation
1.4.4、Cardinality Aggregate 基数聚合
1.4.5、控制聚合的升降序
1.4.6、Percentiles Aggregation
二、优化相关性得分与查询技巧
2.1、优化技巧1
2.2、优化技巧2
2.3、优化技巧3
2.4、优化技巧4
2.5、优化技巧5
2.6、优化技巧6
2.7、优化技巧7
三、下一篇目录
推荐阅读(公众号首发,欢迎关注白日梦)
- MySQL的修仙之路,图文谈谈如何学MySQL、如何进阶!(已发布)
- 面前突击!33道数据库高频面试题,你值得拥有!(已发布)
- 大家常说的基数是什么?(已发布)
- 讲讲什么是慢查!如何监控?如何排查?(已发布)
- 对NotNull字段插入Null值有啥现象?(已发布)
- 能谈谈 date、datetime、time、timestamp、year的区别吗?(已发布)
- 了解数据库的查询缓存和BufferPool吗?谈谈看!(已发布)
- 你知道数据库缓冲池中的LRU-List吗?(已发布)
- 谈谈数据库缓冲池中的Free-List?(已发布)
- 谈谈数据库缓冲池中的Flush-List?(已发布)
- 了解脏页刷回磁盘的时机吗?(已发布)
- 用十一张图讲清楚,当你CRUD时BufferPool中发生了什么!以及BufferPool的优化!(已发布)
- 听说过表空间没?什么是表空间?什么是数据表?(已发布)
- 谈谈MySQL的:数据区、数据段、数据页、数据页究竟长什么样?了解数据页分裂吗?谈谈看!(已发布)
- 谈谈MySQL的行记录是什么?长啥样?(已发布)
- 了解MySQL的行溢出机制吗?(已发布)
- 说说fsync这个系统调用吧! (已发布)
- 简述undo log、truncate、以及undo log如何帮你回滚事物! (已发布)
- 我劝!这位年轻人不讲MVCC,耗子尾汁! (已发布)
- MySQL的崩溃恢复到底是怎么回事? (已发布)
- MySQL的binlog有啥用?谁写的?在哪里?怎么配置 (已发布)
- MySQL的bin log的写入机制 (已发布)
- 删库后!除了跑路还能干什么?(已发布)
- 全网最牛的事务两阶段提交和分布式事务串讲! (已发布)
参考:
https://www.elastic.co/guide/en/elasticsearch/reference/6.0
白日梦的Elasticsearch笔记(一)基础篇的更多相关文章
- (转)深度学习word2vec笔记之基础篇
深度学习word2vec笔记之基础篇 声明: 1)该博文是多位博主以及多位文档资料的主人所无私奉献的论文资料整理的.具体引用的资料请看参考文献.具体的版本声明也参考原文献 2)本文仅供学术交流,非商用 ...
- 深度学习word2vec笔记之基础篇
作者为falao_beiliu. 作者:杨超链接:http://www.zhihu.com/question/21661274/answer/19331979来源:知乎著作权归作者所有.商业转载请联系 ...
- Django学习笔记(基础篇)
Django学习笔记(基础篇):http://www.cnblogs.com/wupeiqi/articles/5237704.html
- Python学习笔记之基础篇(-)python介绍与安装
Python学习笔记之基础篇(-)初识python Python的理念:崇尚优美.清晰.简单,是一个优秀并广泛使用的语言. python的历史: 1989年,为了打发圣诞节假期,作者Guido开始写P ...
- Sass-学习笔记【基础篇】
最下边附结构图 在线编辑器网址如下:http://sassmeister.com/ 注意编写的时候,符号千万别用了中文的:.:.....之类的,会报错,Sass也转换不成css. less和sass ...
- mysql学习笔记之基础篇
数据库学习之基础篇 ① 开放数据库互连(Open Database Connectivity,ODBC ② 结构化查询语言(Structured Query Language) ③ 进入mysql:M ...
- Git学习笔记:基础篇
git可以说是所有开发者出开发语言之外的最基本的基本功了,熟悉git可以方便的进行代码版本控制,以及与其他开发者进行合作开发.本文内容是我以往学习git时做的笔记,主要是关于git最基本的操作,但 只 ...
- Python 学习笔记(基础篇)
背景:今年开始搞 Data science ,学了 python 小半年,但一直没时间整理整理.这篇文章很基础,就是根据廖雪峰的 python 教程 整理了一下基础知识,再加上自己的一些拓展,方便自己 ...
- datatables 学习笔记1 基础篇
本文共3部分:基本使用|遇到的问题|属性表 1.DataTables的默认配置 $(document).ready(function() { $('#example').dataTable(); } ...
随机推荐
- js实现转盘抽奖
大转盘抽奖,主要通过css3的"transform:rotate(0deg)"属性来控制元素的旋转角度来实现. 通常,抽奖的过程需要渐进的效果,所以直接通过旋转属性写比较繁琐. 这 ...
- Django Uwsgi Nginx 部署
1.django的settings配置 参照博客 https://www.cnblogs.com/xiaonq/p/8932266.html # 1.修改配置 # 正式上线关闭调试模式, 不会暴露服务 ...
- postgresql修改postgres用户密码
[postgres@pg01 ~]$ psql -Upostgres -dpostgres postgres=# alter user postgres with password 'postgres ...
- 探究 | App Startup真的能减少启动耗时吗
前言 之前我们说了启动优化的一些常用方法,但是有的小伙伴就很不屑了: "这些方法很久之前就知道了,不知道说点新东西?比如App Startup?能对启动优化有帮助吗?" ok,既然 ...
- python k-means聚类实例
port sys reload(sys) sys.setdefaultencoding('utf-8') import matplotlib.pyplot as plt import numpy as ...
- Python将word文档批量转PDF
前面有一篇<Python批量创建word文档(2)- 加图片和表格>的文章,利用这篇文章创建的word文档来批量转PDF文档.代码: 1 ''' 2 #python批量将word文档转换成 ...
- SVN 使用教程 命令 visual studio 使用SVN
首先推荐大家一个应该是国内外最好的SVN仓库,不限私有,不限成员:https://svnbucket.com/ SVN官网 https://tortoisesvn.net/downloads.html ...
- Jquery Ajax如何添加header参数
转自网络 1 $.ajax({ 2 type: "POST", 3 url: "http://192.168.0.88/action.cgi?ActionID=WEB_R ...
- Blogs禁止页面选中复制功能
说明:只需要在博客侧边栏公告(支持HTML代码) (支持 JS 代码)里面添加如下代码 /* 在页面定制 CSS 代码处添加如下样式 */ html,body{ moz-user-select: -m ...
- H3C路由器配置——动态路由OSPF协议
一.介绍 1.OSPF协议介绍 (1).OSPF(Open Shortest Path First,开放最短路径优先)路由协议是用于网际协议(IP)网络的链路状态路由协议.是一个被各厂商设备广泛支持的 ...