机器学习笔记·adaboost
一、算法简介
Adaboost算法是一种集成算法,所谓集成算法就是将多个弱的分类器组合在一起变成一个强的分类器。弱分类器通常是指分类效果比随机分类稍微好一点的分类器。就像我们在做一个重要决定的时候,通常会请教多个人的意见而不是一个人的意见,我们会综合考虑多个方面最终才会下决定。假如此时远处走来一个人,你要判断他是否是你的朋友。这时候你会从他的穿着,身高,走路姿势等多个特征来进行判断,如果仅仅是看其中一个特征都是很难做出正确判断的。这就是adaboost算法的主要思想了,下面我们来看一看计算机是怎样实现这个过程的。
二、算法原理
实现adaboost算法的基分类器有很多中,这里我们采用单层决策树作为基分类器。因为只有一层,这个决策树可以看成是一个树桩。首先我们对所有样本赋予1/n的权重,然后构建一个单层分类器,使得该分类器分类效果最好。假如下一次我们还继续在原来的数据集上进行分类的话,那么我们选出的分类器一定和之前是一样的。所以这次我们需要对数据进行一下处理,我们改变每个样本的权重,让上一次分类错误的样本我们让它的权重高一点,这样再次训练的时候,那些被分类错误的样本被分类正确的概率就高一些。第t次迭代的权重向量Dt的计算方式如下:
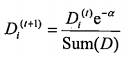
如果分类正确:

如果分类错误:
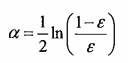
a为分类器的权重:其中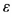 为分类器的错误率。迭代n次之后,我们就能得到n个分类器h(x)。接下来我们给每一个分类器赋予一个权重,然后将所有分类器组合在一起,这样我们就形成了一个最终的分类器H(x).这样分类出来的效果是不是类似于将数据集所在的(超)平面分成了许多个小区域呢。在理论上可以证明这样做是合理的,下面我们通过一个简单例子对adaboost算法过程进行说明。
为分类器的错误率。迭代n次之后,我们就能得到n个分类器h(x)。接下来我们给每一个分类器赋予一个权重,然后将所有分类器组合在一起,这样我们就形成了一个最终的分类器H(x).这样分类出来的效果是不是类似于将数据集所在的(超)平面分成了许多个小区域呢。在理论上可以证明这样做是合理的,下面我们通过一个简单例子对adaboost算法过程进行说明。
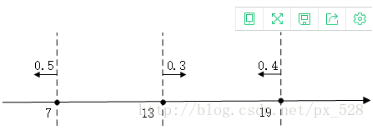
首先我们可以举一个例子,这是一个一维特征的数据。假如按照上述分类之后得出的结果如下,共有三个分类器,分别为以7,13,19作为阈值。箭头所指向的方向表示的是被分类为+1的区域,数字代表分类器的权重。以把7作为阈值的那个分类器为例,当分类的样本x小于7的时候,它就被分类成+1而大于7的时候它就会被分类成-1.这样就有了三个分类器h1,h2,h3,接下来我们把这三个分类器进行整合。方法如下:当x小于7的时候,h1(x)=0.5,h2(x)=-0.3,h3(x)=0.4,因此H(x)=sign(h1(x)+h2(x)+h3(x))=sign(0.6)=1.所以小于7的点就被分类成+1,同理可以计算其他区域的分类结果。如果数据在更高维度上,计算方式也类似。到这里,对于adaboost算法的工作过程应该能够理解清楚了。
接下来本来打算再从数学上说明为什么这样做,但是因为网上已经有大量的相关知识,而且公式编辑的过程太过复杂,因此这一步就省掉了。如果希望深入了解其中的数学推导过程,我建议参考一下周志华《机器学习》p172,其中解释地非常详细,也很容易明白。
三、adaboost算法的应用
为了检验adaboost算法的效果,我们需要将该算法应用到实际数据上。这里我找了一个利用声呐判断物体的数据集,其中包含208个样本,每个样本都有60个特征,分别表示从60个不同的角度测出的回声强度。由于数据集中在一起,因此我们首先向数据进行随机打乱,然后选择其中的160个作为训练集,另外48个作为测试集。这里选了迭代次数为1000次,多次修改迭代次数之后,测试的错误为16%左右。这个结果对该数据集来说已经非常不错了,据网上所说该数据集的准确率在其他算法上一般为为60-70%左右。
Roc曲线如下:

四、程序python代码
|
from numpy import * def stumpClassify(dataMatrix,dimen,threshVal,threshIneq):#对数据进行分类,根据阈值划分数据 def buildStump(dataArr,classLabels,D):#弱分类器的构建,基于输入的权重向量寻找最好错误率最小的分类方法 def adaBoostTrainDS(dataArr,classLabels,numIt=40):#迭代次数默认为40 |
|
from adaboost import* |
参考文献:
[1]Adaboost入门教程——最通俗易懂的原理介绍(图文实例)
https://blog.csdn.net/px_528/article/details/72963977
[2] 机器学习实战 peter Harrington
[3] 周志华《机器学习》
机器学习笔记·adaboost的更多相关文章
- Python机器学习笔记:sklearn库的学习
网上有很多关于sklearn的学习教程,大部分都是简单的讲清楚某一方面,其实最好的教程就是官方文档. 官方文档地址:https://scikit-learn.org/stable/ (可是官方文档非常 ...
- Python机器学习笔记 集成学习总结
集成学习(Ensemble learning)是使用一系列学习器进行学习,并使用某种规则把各个学习结果进行整合,从而获得比单个学习器显著优越的泛化性能.它不是一种单独的机器学习算法啊,而更像是一种优 ...
- 机器学习笔记:Gradient Descent
机器学习笔记:Gradient Descent http://www.cnblogs.com/uchihaitachi/archive/2012/08/16/2642720.html
- 机器学习笔记5-Tensorflow高级API之tf.estimator
前言 本文接着上一篇继续来聊Tensorflow的接口,上一篇中用较低层的接口实现了线性模型,本篇中将用更高级的API--tf.estimator来改写线性模型. 还记得之前的文章<机器学习笔记 ...
- 机器学习之AdaBoost原理与代码实现
AdaBoost原理与代码实现 本文系作者原创,转载请注明出处: https://www.cnblogs.com/further-further-further/p/9642899.html 基本思路 ...
- Python机器学习笔记:使用Keras进行回归预测
Keras是一个深度学习库,包含高效的数字库Theano和TensorFlow.是一个高度模块化的神经网络库,支持CPU和GPU. 本文学习的目的是学习如何加载CSV文件并使其可供Keras使用,如何 ...
- Python机器学习笔记:不得不了解的机器学习面试知识点(1)
机器学习岗位的面试中通常会对一些常见的机器学习算法和思想进行提问,在平时的学习过程中可能对算法的理论,注意点,区别会有一定的认识,但是这些知识可能不系统,在回答的时候未必能在短时间内答出自己的认识,因 ...
- 机器学习笔记(4):多类逻辑回归-使用gluton
接上一篇机器学习笔记(3):多类逻辑回归继续,这次改用gluton来实现关键处理,原文见这里 ,代码如下: import matplotlib.pyplot as plt import mxnet a ...
- 【转】机器学习笔记之(3)——Logistic回归(逻辑斯蒂回归)
原文链接:https://blog.csdn.net/gwplovekimi/article/details/80288964 本博文为逻辑斯特回归的学习笔记.由于仅仅是学习笔记,水平有限,还望广大读 ...
随机推荐
- 如何实现OSM地图本地发布并自定义配图
目录 1.缘起 2.准备环境 2.1.安装linux系统 2.2.安装docker 2.3.安装Docker Compose 2.4.安装git 3.发布地图 3.1.拉取代码 3.2.测试网络 3. ...
- window+nginx+php
今天在Windows上配置了下nginx,看了不少其他大牛们记录的博客,自己也操作了一番,记录一下备忘. nginx download: http://nginx.org/en/download.ht ...
- C#跳过工作日,计算几个工作日之后到期的方法
需求:消费者投诉企业,企业在2个工作日之内做出应答. 分析:1.工作日要刨去周末和法定节假日,而且每年的节假日不一样. 2.消费者可以在任意时间发起投诉,如果在非工作日发起了投诉,那么计算时间应该从工 ...
- windows上mysql5.7服务启动报错
安装之后,启动服务 net start mysql,无法启动,日志报错缺少一些系统表,mysql.user等表 解决办法: bin目下执行:mysqld --initialize-insecure - ...
- ReentrantReadWriterLock源码(state设计、读写锁、共享锁、独占锁及锁降级)
ReentrantReadWriterLock 读写锁类图(截图来源https://blog.csdn.net/wangbo199308/article/details/108688148) stat ...
- vue第十五单元(熟练使用vue-router插件)
第十五单元(熟练使用vue-router插件) #课程目标 1.掌握路由嵌套 2.掌握导航守卫 #知识点 #一.路由嵌套 很多时候,我们会在一个视口中实现局部页面的切换.这时候就需要到了嵌套路由. 也 ...
- [日常摸鱼][POI2000]病毒-Tire图(AC自动机)+dfs
https://www.luogu.org/problemnew/show/P2444 (没有bzoj权限号T_T) 字符串题对我这种傻逼来说真是太难了x 题意:输入$n$个01组成的模式串串,判断是 ...
- k8s之深入解剖Pod(二)
目录: Pod配置管理:ConfigMap 容器内获取Pod信息:Downward API Pod生命周期和重启策略 Pod健康检查 一.ConfigMap 将应用所需的配置信息与程序进行分离,可以使 ...
- 一场由fork引发的超时,让我们重新探讨了Redis的抖动问题
摘要:一次由fork引发的时延抖动问题. 背景介绍 华为云数据库GaussDB(for Redis) 是一款基于计算存储分离架构,兼容Redis生态的云原生NoSQL数据库:它依靠共享存储池实现了强一 ...
- Java基础进阶:多态与接口重点摘要,类和接口,接口特点,接口详解,多态详解,多态中的成员访问特点,多态的好处和弊端,多态的转型,多态存在的问题,附重难点,代码实现源码,课堂笔记,课后扩展及答案
多态与接口重点摘要 接口特点: 接口用interface修饰 interface 接口名{} 类实现接口用implements表示 class 类名 implements接口名{} 接口不能实例化,可 ...