Celery:小试牛刀
Celery是如何工作的?
Celery 由于 其分布式体系结构,在某种程度上可能难以理解。下图是典型Django-Celery设置的高级示意图(FROM O'REILLY):
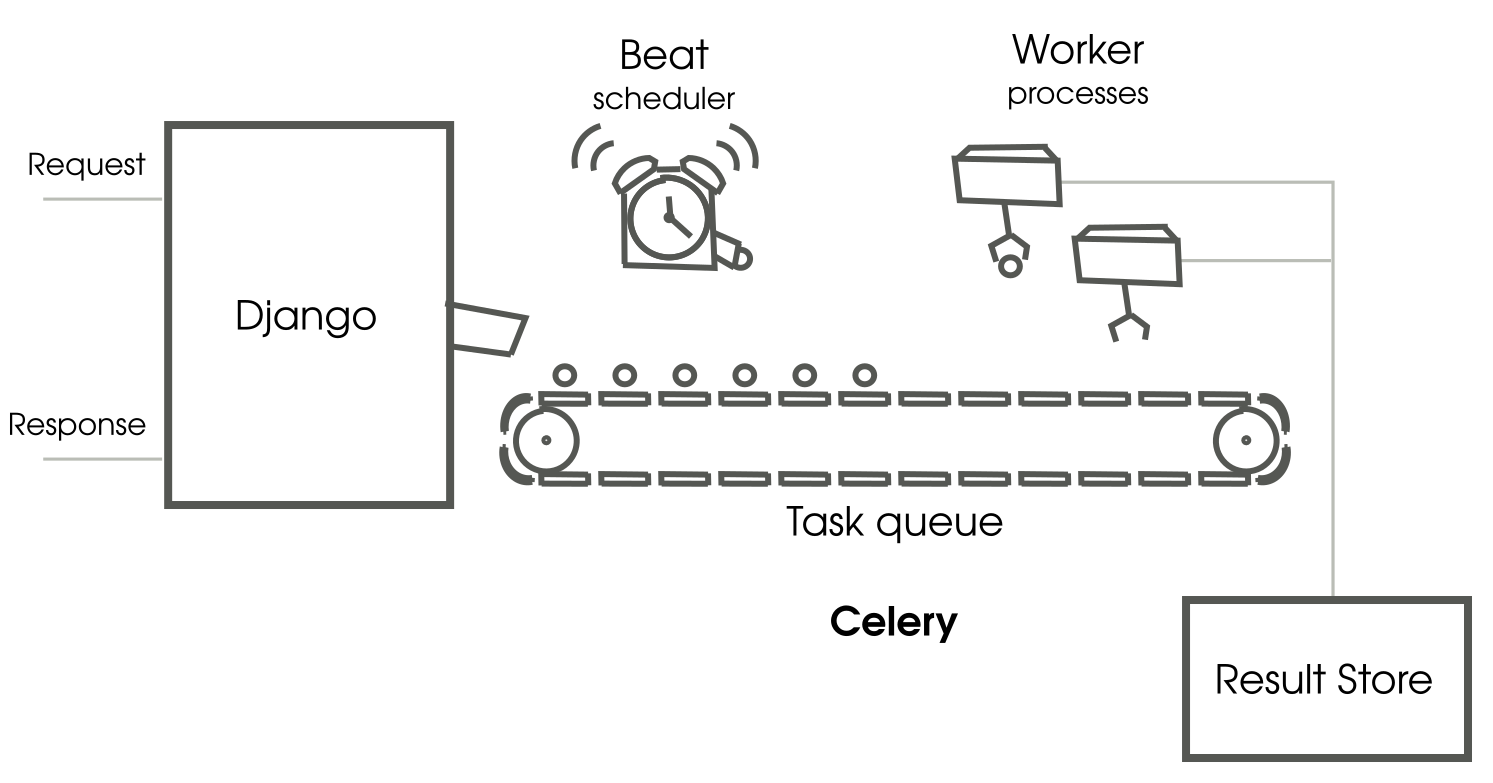
当请求到达时,您可以在处理它时调用Celery任务。调用任务的函数会立即返回,而不会阻塞当前进程。实际上,任务尚未完成执行,但是任务消息已进入任务队列(或许多可能的任务队列之一)。
workers 是独立的进程,用于监视任务队列中是否有新任务并实际执行它们,他们拿起任务消息、处理任务、存储结果。
一、安装一个broker
Celery需要一个发送和接收消息的解决方案,即一个消息代理(message broker)服务,常用的broker包括:

RabbitMQ功能齐全,稳定,耐用且易于安装,是生产环境的绝佳选择。
Ubuntu安装:
$ sudo apt-get install rabbitmq-server
Docker安装:
$ docker run -d -p 5672:5672 rabbitmq
关于RabbitMQ在Celery中的高级配置,见:使用RabbitMQ
其他系统安装RabbitMQ,见:下载并安装RabbitMQ

Redis
Redis也具有完整的功能,但是在突然终止或电源故障的情况下更容易丢失数据。
Ubuntu安装:
$ sudo apt install redis-server
Docker安装:
$ docker run -d -p 6379:6379 redis
关于Redis在Celery中的高级配置:使用Redis
关于Redis的安装:ubuntu 18.04安装Redis
二、安装Celery
$ pip install celery
三、编写Celery任务代码
首先导入Celery,创建一个Celery对象,这个对象将作为一个操作 Celery 的入口,如创建任务,管理workers等。
以下示例会把所有东西都写在一个模块中,但是对于大型项目,您需要创建一个专用模块。
# tasks.py
import time
from celery import Celery
app = Celery('tasks', ,broker='pyamqp://guest@localhost//')
@app.task
def add(x, y):
print('--------start---------')
for i in range(5):
print(f'第{i}秒')
print('--------over----------')
return x + y
第一个参数是当前模块的名称,这是唯一的必需参数。
第二个参数指定要使用的消息代理的URL。这里使用RabbitMQ(也是默认选项)。
若使用Redis:
app = Celery('tasks', broker='redis://localhost:6379/0')
四、启动 worker 进程
$ celery -A tasks worker --loglevel=INFO
在生产环境中,需要在后台将工作程序作为守护程序运行。为此,需要使用 平台提供的工具 或 类似supervisord的工具
五、调用任务
调用任务需要导入带有celery示例的模块,这里没有重新创建一个模块导入,而是使用命令行模式。要调用我们定义的任务,可以使用delay()(详情参阅 调用任务):
>>> from tasks import add
>>> add.delay(4, 4)
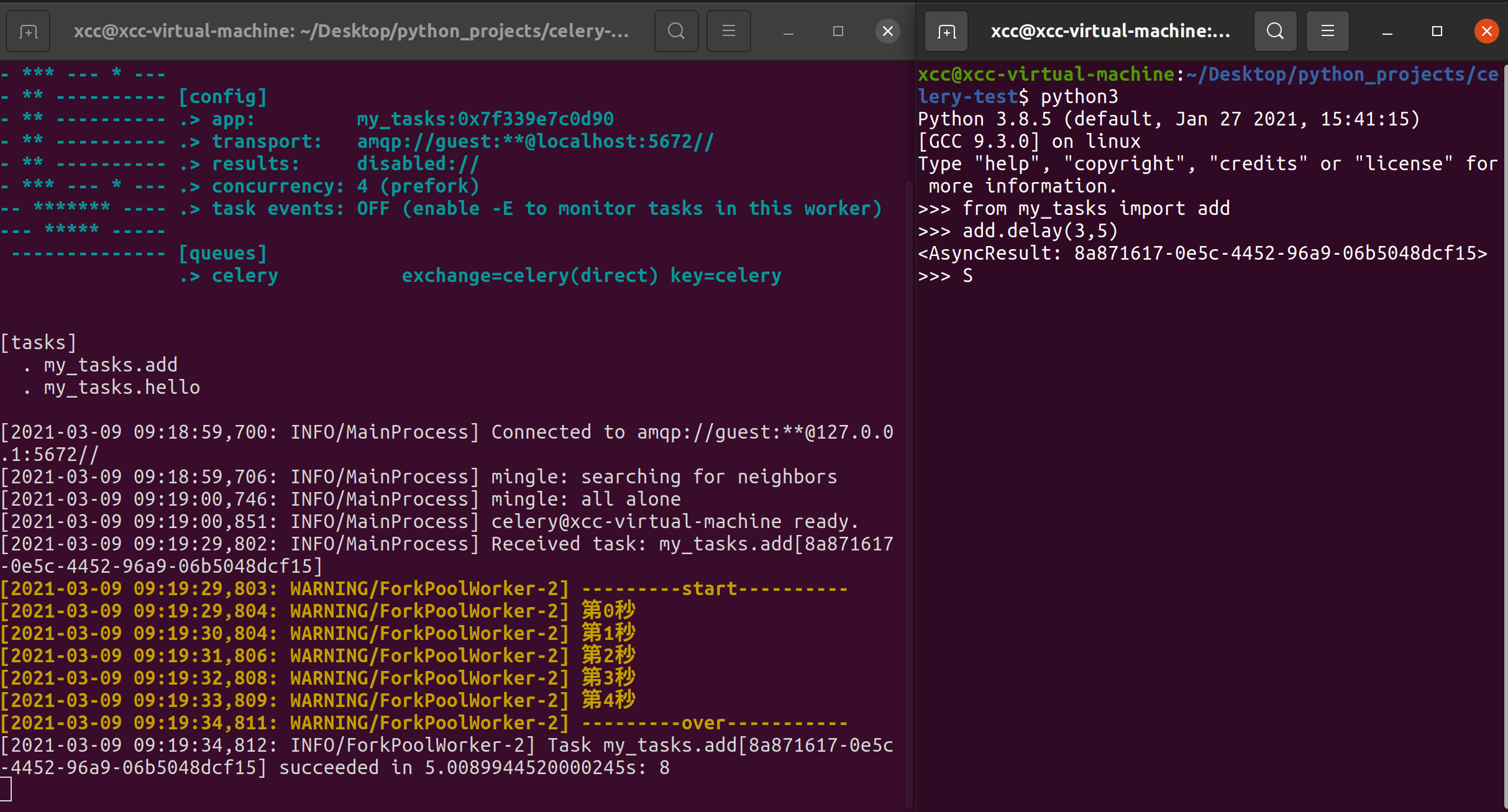
调用任务将返回一个AsyncResult实例,这可用于检查任务的状态,等待任务完成或获取其返回值(或者如果任务失败,则获取异常和回溯)
默认情况下执行任务不返回结果。为了执行远程过程调用或跟踪数据库中的任务结果,需要配置result backend。
六、获取运行结果
如果要跟踪任务的状态,Celery需要将状态存储或发送到某个地方。有多个result backend可供选择:SQLAlchemy / Django ORM, MongoDB,Memcached,Redis,RPC(RabbitMQ / AMQP)等。
下面使用 RPC 作为result backend,该后端将状态作为瞬态消息发送回去。使用backend参数配置Celery对象的result backend:
app = Celery('tasks', backend='rpc://', broker='pyamqp://')
或者,如果使用 Redis 作为result backend,但仍然使用 RabbitMQ 作为 broker(流行的组合):
app = Celery('tasks', backend='redis://localhost', broker='pyamqp://')
更多
result backend配置参阅“result backend。
我们再次调用该任务:
>>> result = add.delay(4, 4)
>>> result.ready() # 检查是否完成任务,返回布尔值
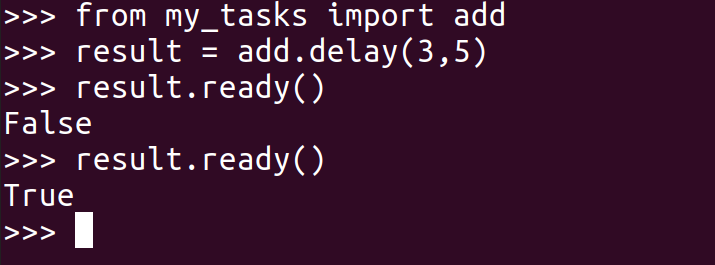
详情见有关
celery.result对象的完整参考
七、配置Celery
对于大多数使用情况,默认配置就够了,但是可以配置更多选项使Celery根据需要工作。详细配置见“配置和默认值”。
可以直接在应用程序上设置配置,也可以使用专用的配置模块设置配置。例如配置用于序列化任务负载的默认序列化器:
# 配置一个设置:
app.conf.task_serializer = 'json'
# 一次配置许多设置,则可以使用update
app.conf.update(
task_serializer='json',
accept_content=['json'], # Ignore other content
result_serializer='json',
timezone='Europe/Oslo',
enable_utc=True,
)
对于较大的项目,建议使用专用的配置模块。
app.config_from_object('celeryconfig')
celeryconfig.py必须可用于从当前目录或Python路径中加载
celeryconfig.py
broker_url = 'pyamqp://'
result_backend = 'rpc://'
task_serializer = 'json'
result_serializer = 'json'
accept_content = ['json']
timezone = 'Europe/Oslo'
enable_utc = True
参考
- First Steps with Celery
- How Celery works
- How To Use Celery with RabbitMQ to Queue Tasks on an Ubuntu VPS
Celery:小试牛刀的更多相关文章
- Celery 基本使用
1. 认识 Celery Celery 是一个 基于 Python 开发的分布式异步消息任务队列,可以实现任务异步处理,制定定时任务等. 异步消息队列:执行异步任务时,会返回一个任务 ID 给你,过一 ...
- 分布式框架Celery(转)
一.简介 Celery是一个异步任务的调度工具. Celery 是 Distributed Task Queue,分布式任务队列,分布式决定了可以有多个 worker 的存在,队列表示其是异步操作,即 ...
- 异步任务队列Celery在Django中的使用
前段时间在Django Web平台开发中,碰到一些请求执行的任务时间较长(几分钟),为了加快用户的响应时间,因此决定采用异步任务的方式在后台执行这些任务.在同事的指引下接触了Celery这个异步任务队 ...
- Xamarin+Prism小试牛刀:定制跨平台Outlook邮箱应用(后续)
在[Xamarin+Prism小试牛刀:定制跨平台Outlook邮箱应用]里面提到了Microsoft 身份认证,其实这也是一大块需要注意的地方,特作为后续补充这些知识点.上章是使用了Microsof ...
- celery使用的一些小坑和技巧(非从无到有的过程)
纯粹是记录一下自己在刚开始使用的时候遇到的一些坑,以及自己是怎样通过配合redis来解决问题的.文章分为三个部分,一是怎样跑起来,并且怎样监控相关的队列和任务:二是遇到的几个坑:三是给一些自己配合re ...
- tornado+sqlalchemy+celery,数据库连接消耗在哪里
随着公司业务的发展,网站的日活数也逐渐增多,以前只需要考虑将所需要的功能实现就行了,当日活越来越大的时候,就需要考虑对服务器的资源使用消耗情况有一个清楚的认知. 最近老是发现数据库的连接数如果 ...
- celery 框架
转自:http://www.cnblogs.com/forward-wang/p/5970806.html 生产者消费者模式 在实际的软件开发过程中,经常会碰到如下场景:某个模块负责产生数据,这些数据 ...
- celery使用方法
1.celery4.0以上不支持windows,用pip安装celery 2.启动redis-server.exe服务 3.编辑运行celery_blog2.py !/usr/bin/python c ...
- Celery的实践指南
http://www.cnblogs.com/ToDoToTry/p/5453149.html Celery的实践指南 Celery的实践指南 celery原理: celery实际上是实现了一个典 ...
随机推荐
- 力扣567.字符串的排列—C语言实现
题目 来源:力扣(LeetCode)
- SOHO 程序员
SOHO 程序员:从事程序开发.维护的家居办公人员. 一.自由程序员 SOHO程序员代表一种自由.弹性而新型的工作方式.SOHO,代表一种新经济.新概念. 是一些热爱软件开发的一族. SOHO程序员 ...
- 获取txt编码方式
在操作txt的时候,有时会出现乱码,这是因为没有使用正确的编码方式来操作txt,我们需要先获取txt的编码方式,再进行读写操作.下面是获取txt编码的方法: /// <summary> / ...
- UML类图设计神器 AmaterasUML 的配置及使用
最近写论文需要用到UML类图,但是自己画又太复杂,干脆找了个插件,是Eclipse的,也有IDEA的,在这里我简单说下Eclipse的插件AmaterasUML 的配置与使用吧. 点击这里下载Amat ...
- PAT l2-010 排座位 【并查集】
L2-010. 排座位 时间限制 150 ms 内存限制 65536 kB 代码长度限制 8000 B 判题程序 Standard 作者 陈越 布置宴席最微妙的事情,就是给前来参宴的各位宾客安排座位. ...
- IFIX 5.9 历史数据 曲线 (非SQL模式)
装完 ifix 5.9 默认是没有Hist 开头的 历史数据源的,没存,至少我装的版本是这样. 那个Historian 也没有安装包,好像还要授权,自己研究不了. 1 先把数据存本地 在你的安装包里 ...
- C++ part2
为什么析构函数必须是虚函数?为什么C++默认的析构函数不是虚函数? references: nowcoder 将可能会被继承的父类的析构函数设置为虚函数,可以保证当我们new一个子类,然后使用基类指针 ...
- Linux内核实现透视---软中断&Tasklet
软中断 首先明确一个概念软中断(不是软件中断int n).总来来说软中断就是内核在启动时为每一个内核创建了一个特殊的进程,这个进程会不停的poll检查是否有软中断需要执行,如果需要执行则调用注册的接口 ...
- TensorFlow & Machine Learning
TensorFlow & Machine Learning TensorFlow 实战 传统方式 规则 + 数据集 => 答案 无监督学习 机器学习 神经元网络 答案 + 数据集 =&g ...
- React Big Changes All in One
React Big Changes All in One React 重大更新 React Versions React 版本变更 https://reactjs.org/versions/ sema ...