FCIS:Fully Convolutional Instance-aware Semantic Segmentation
论文:Fully Convolutional Instance-aware Semantic Segmentation
0.简介
如果不懂 instance-sensitive score maps 或者说 position-sensitive score maps,建议先去看《Instance-sensitive Fully Convolutional Networks》这篇文章,或者看上一篇梳理https://www.cnblogs.com/importGPX/p/13514977.html,因为FCIS就是(应该是自家研究团队,清华+微软)在那篇的基础上研究的。
下面都按已经看过上篇来说。
我把这篇的改进贡献分为两部分。
一是算法原创性改进:
- 通过引入位置敏感的内/外分数图(position-senstive inside/outside score maps)联合解决检测+分割问题,底层的卷积表达被两个子任务以及所有的感兴趣区域完全地共享。
二是时代发展出的通用方法改进:
- 不再用slide window,而是用RPN网络来产生ROI
作者认为当时流行的实例分割模型存在以下问题:
- 用ROI pooling,造成mis-alignment问题,位置精度丢失。
- 参数过多。不适用局部参数共享,全连接层参数过多。
- 每个ROI单独计算,效率低。
作者提出解决方案:
- 不适用ROI pooling,组合一组位置敏感分数图,得到ROI特征。
- 使用局部参数共享的FCN,不使用全连接层,解决问题2和3。
1.Position-sensitive Score Map

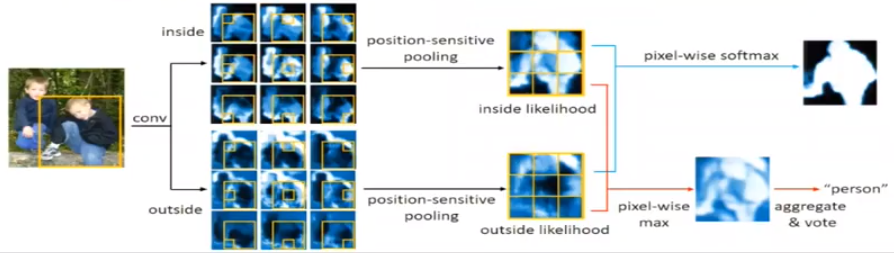
卷积操作是平移不变的(translation invariant)的——同一个像素会得到相同的结果,与它的相对位置及上下文无关,但在实例分割中,相同的一个点在不同情况可能应该得到不同的结果,如上图的前两行中的红点,在原图中在相同的位置,是同一个点,但在不同的实例框应该得到不同的结果,第一行的图红点应该属于实例部分,第二行是对于右边的男孩,此点就不应该属于此实例。所以应该引入平移应变性(translation-variant property)。
position sensitive score maps就是《Instance Sensitive FCNs》那篇中的Instance Sensitive score maps,不再重复,不同的是引入了inside/outside来联合解决检测与分割问题。见下节。
2.Joint Mask Prediction and Classification
如果只用position sensitive score maps是不能确定物理类别的,就像《Insatnce sensitive FCNs》一样,为了解决这一问题,经常在后面加一个分类的分支网络。
在本文的方法下,ROI区域内的每个像素有以下两个任务:
- 检测,它是否属于某一个目标的bounding box(detection+/detection-);
- 分割,它是否属于某个实例,即是否在实例边界内(segmentation+/segmentation-)。
简单的方式就是训练两个独立分类器,本文的一种baseline FCIS(separate score maps),就是用了两个1×1卷积层当分类器。
FCIS设计了一个联合规则,可以融合这两个任务。首先明确上面提到的inside/outside的含义:
- inside score map:像素在某个相对位置属于某个目标实例,且在目标边界内。
- outside score map:像素在某个相对位置属于某个目标实例,且在目标边界外。
设计的联合规则为,对于ROI中的一个像素:
- 高的inside分数 & 低的outside分数:detection+ & segmentation+
- 低的inside分数 & 高的outside分数:detection+ & segmentation-
- 低的inside分数 & 低的outside分数:detection- & segmentation-
不可能有第四种 高inside& 高outside(在框内且在框外)。
对于检测:使用逐像素的max操作区分前第1、2种情况和第三种情况。然后通过对所有像素的概率进行平均池化,最后做一个在所有类别上的softmax,,得到整个ROI的检测分数。
对于分割:对于每个像素进行softmax区分第1种情况和第2种情况。
检测和分割这两个分数图来自两个1x1卷积层。inside/outside分类器被联合训练,因为它们接收来自于分割和检测损失的梯度。FCN的局部权重共享特性被保持,且作为一种正则化机制。
3.Networks architecture
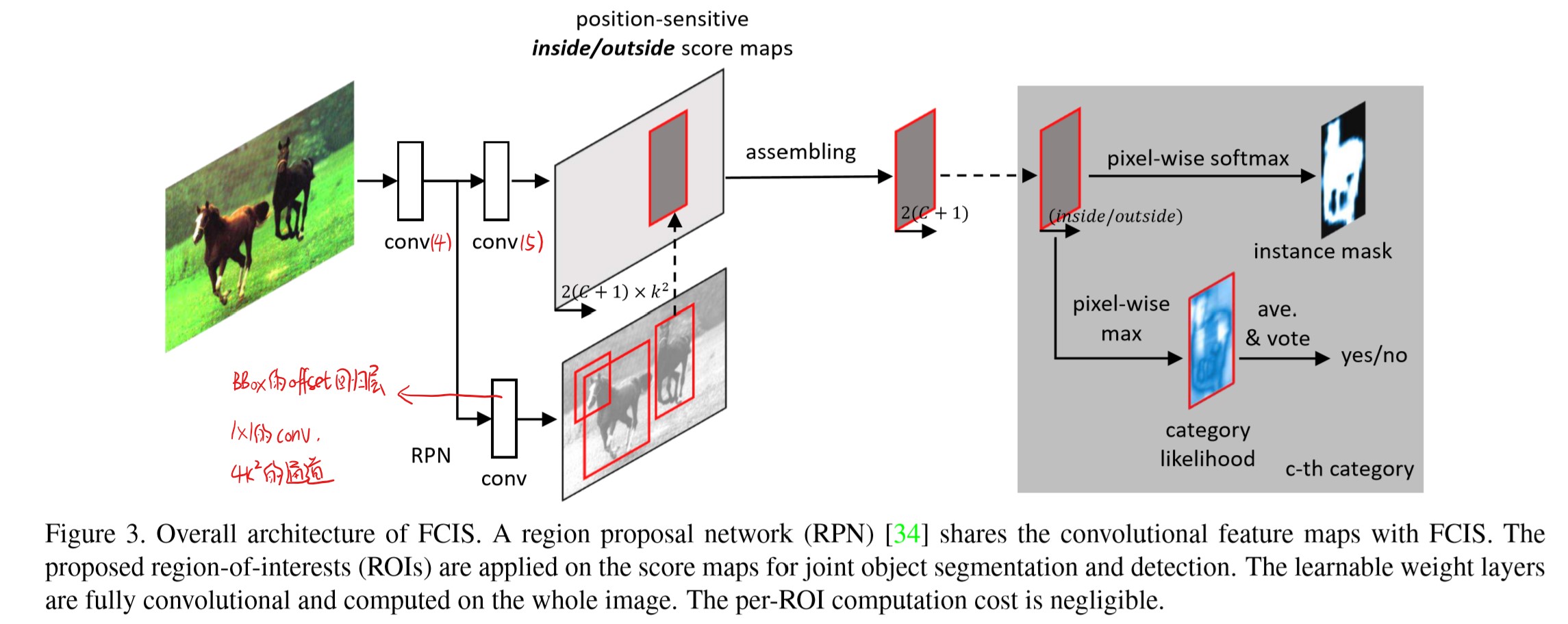
主干网络用ResNet-101,去掉最后用于分类的全连接层,只训练前面的卷积层,最后的特征图是2048通道的,通过1x1的卷积降维到1024。因为是分割要用分辨率更高的feature map,所以把stride从32降到16:conv5第一个block的stride从2降到1。为了保持感受野,使用空洞卷积,conv5所有的卷积层dilation都设置为2。
上分支:使用1x1的卷积从conv5的特征图生成\(2K^2×(C+1)\)个分数图:C类+1个背景类;默认地,k=7(因为最终的特征图相比原始图像缩小了16倍,所以在特征图上,每一个RoI相当于被投影进小16倍的区域中)。然后组装成2×(C+1)个inside/outside分数图。最后进行第二节中所述操作分别得到ROI的mask和检测分类结果。(网络预测阶段时,RPN产生、调整出300个分数最高的ROI,对每个ROI的每个类别都产生分类分数、前景mask,然后再做NMS,保留下最终的结果。)
下分支:在conv4后面接RPN网络,然后再接BBox的offset回归层(1×1的卷积,\(4K^2\)个通道),调整ROI框。
FCIS:Fully Convolutional Instance-aware Semantic Segmentation的更多相关文章
- 论文学习:Fully Convolutional Networks for Semantic Segmentation
发表于2015年这篇<Fully Convolutional Networks for Semantic Segmentation>在图像语义分割领域举足轻重. 1 CNN 与 FCN 通 ...
- 论文笔记(4):Fully Convolutional Networks for Semantic Segmentation
一.FCN中的CNN 首先回顾CNN测试图片类别的过程,如下图: 主要由卷积,pool与全连接构成,这里把卷积与pool都看作图中绿色的convolution,全连接为图中蓝色的fully conne ...
- 论文阅读笔记六:FCN:Fully Convolutional Networks for Semantic Segmentation(CVPR2015)
今天来看一看一个比较经典的语义分割网络,那就是FCN,全称如题,原英文论文网址:https://people.eecs.berkeley.edu/~jonlong/long_shelhamer_fcn ...
- Fully Convolutional Networks for Semantic Segmentation 译文
Fully Convolutional Networks for Semantic Segmentation 译文 Abstract Convolutional networks are powe ...
- Fully Convolutional Networks for semantic Segmentation(深度学习经典论文翻译)
摘要 卷积网络在特征分层领域是非常强大的视觉模型.我们证明了经过端到端.像素到像素训练的卷积网络超过语义分割中最先进的技术.我们的核心观点是建立"全卷积"网络,输入任意尺寸,经过有 ...
- 【Semantic segmentation】Fully Convolutional Networks for Semantic Segmentation 论文解析
目录 0. 论文链接 1. 概述 2. Adapting classifiers for dense prediction 3. upsampling 3.1 Shift-and-stitch 3.2 ...
- 论文笔记《Fully Convolutional Networks for Semantic Segmentation》
一.Abstract 提出了一种end-to-end的做semantic segmentation的方法,也就是FCN,是我个人觉得非常厉害的一个方法. 二.亮点 1.提出了全卷积网络的概念,将Ale ...
- 论文阅读笔记十三:The One Hundred Layers Tiramisu: Fully Convolutional DenseNets for Semantic Segmentation(FC-DenseNets)(CVPR2016)
论文链接:https://arxiv.org/pdf/1611.09326.pdf tensorflow代码:https://github.com/HasnainRaz/FC-DenseNet-Ten ...
- 论文笔记之:Fully Convolutional Attention Localization Networks: Efficient Attention Localization for Fine-Grained Recognition
Fully Convolutional Attention Localization Networks: Efficient Attention Localization for Fine-Grain ...
随机推荐
- 【日常摘要】- RabbitMq实现延时队列
简介 什么是延时队列? 一种带有延迟功能的消息队列 过程: 使用场景 比如存在某个业务场景 发起一个订单,但是处于未支付的状态?如何及时的关闭订单并退还库存? 如何定期检查处于退款订单是否已经成功退款 ...
- Linux字符集的查看及修改[转]
一·查看字符集字符集在系统中体现形式是一个环境变量,以CentOS6.5为例,其查看当前终端使用字符集的方式可以有以下几种方式: 1.[root@david ~]# echo $LANGzh_CN.G ...
- OFDM通信系统的MATLAB仿真(2)
关于OFDM系统的MATLAB仿真实现的第二篇随笔,在第一篇中,我们讨论的是信号经过AWGN信道的情况,只用添加固定噪声功率的高斯白噪声就好了.但在实际无线信道中,信道干扰常常是加性噪声.多径衰落的结 ...
- 如何阅读一本书——分析阅读Pre
如何阅读一本书--分析阅读Pre 前情介绍 作者: 莫提默.艾德勒 查尔斯.范多伦 初版:1940年,一出版就是全美畅销书榜首一年多.钢铁侠Elon.Musk学过. 需要注意的句子: 成功的阅读牵涉到 ...
- 使用 eval(input()) 的便利
输入列表或者字典时使用eval可以自动转换为其类型 2020-06-18
- Composer 安装与使用
Composer 安装与使用 分类 编程技术高佣联盟 www.cgewang.com Composer 是 PHP 的一个依赖管理工具.我们可以在项目中声明所依赖的外部工具库,Composer 会帮你 ...
- 获取判断IE版本 TypeError: Cannot read property 'msie' of undefined
注意:以下方法只适用于IE11 以下: TypeError: Cannot read property 'msie' of undefined jquery1.9去掉了 $.browser 所以报错 ...
- Asp.Net项目发布 到 IIS、 Core3.1 发布到 IIS CentOS8.x
摘要:发布项目到IIS或者.Net Core 项目发布到IIS服务器或者CentOS记录一下,后面忘了又来看看. 1.服务器安装IIS 1.1.不管你是本地的电脑还是网上购买的服务器,只要是能通过远程 ...
- day14.推导式与生成器
一.列表推导式 '''通过一行循环判断,遍历一系列数据的方式''' """ 推导式的语法: val for val in Iterable 三种方式: [val for ...
- .Net Core 3.0依赖注入替换 Autofac
今天早上,喜庆的更新VS2019,终于3.0正式版了呀~ 有小伙伴问了一句Autofac怎么接入,因为Startup.ConfigureServices不能再把返回值改成IServiceProvide ...