技术分享PPT整理(二):C#常用类型与数据结构
这篇博客起源于我对Dictionary、List、ArrayList这几个类区别的好奇,当时在改造公司的旧系统,发现很多地方使用了ArrayList,但我们平时用的多是泛型集合List,改造的时候要全部替换成泛型集合,原本我对于这几个集合类就有些疑问,所以稍微做了些功课。
装箱与拆箱
在开始分析集合类之前先简单说下装箱拆箱的概念,在实际的开发中,也许我们很少提到这个概念,但它实际上遍布我们的开发过程,并且对性能有很大的影响,首先来了解一下什么是装箱和拆箱:
装箱和拆箱是值类型和引用类型之间相互转换是要执行的操作。
- 装箱在值类型向引用类型转换时发生
- 拆箱在引用类型向值类型转换时发生
int i = 123;
object o = (object)i; // 将int转object,发生装箱
int j = (int)o; // 从object转回原来的类型,解除装箱
通过上面的说明和例子可以看到,这是一个很简单的概念,实际上就是在我们进行类型转换时发生的一种情况,但如果我们再深入一些可以从数据结构的角度来更清晰地解释这个问题,先看下面两个例子:
值类型
int i = 123;
object o = i; // 装箱会把i的值拷贝到o
i = 456; // 改变i的值
// i的变化不会影响到o的值
Console.WriteLine("{0},{1}", i,o);

原始值类型和装箱的对象使用不同的内存位置,因此能够存储不同的值。
引用类型
public class ValueClass
{
public int value = 123;
public void Test()
{
ValueClass b = new ValueClass();
ValueClass a = b;
b.value = 456;
Console.WriteLine("{0},{1}", a.value, b.value);
}
}
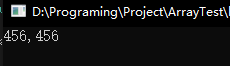
两个变量指向同一块内存数据,当一个变量对内存区数据改变之后,另一个变量指向的数据当然也会改变。
简单地说,值类型的赋值相当于直接将物品交给另一个人,而引用类型的赋值相当于将一个存放了物品的地址复制给另一个人,每当有人来找的时候,再根据地址去找到物品,地址没有发生改变的情况下,将里面的物品替换,那么后面所有顺着线索找过来的人拿到的都是被替换的物品。如果以数据结构的知识来看,引用类型和值类型就是分别存放在堆和栈里面的数据。
堆与栈
我们把内存分为堆空间和栈空间:
- 线程堆栈:简称栈Stack,栈空间比较小,但是读取速度快
- 托管堆:简称堆Heap,堆空间比较大,但是读取速度慢
栈存储的是基本值类型,堆存储的是new出来的对象。引用类型在栈中存储一个引用,其实际的存储位置位于托管堆。
值类型:在C#中,继承自System.ValueType的类型被称为值类型,主要有以下几种:bool、byte、char、decimal、double、enum、float、Int、long、sbyte、short、struct、uint、ulong、ushort
引用类型:以下是引用类型,继承自System.Object:class、interface、delegate、object、string
装箱(Boxing)
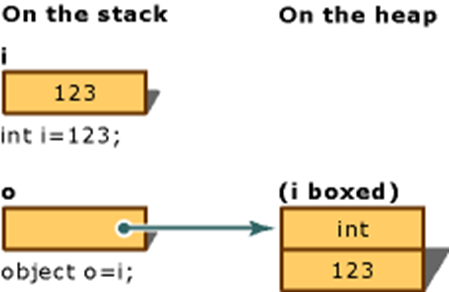
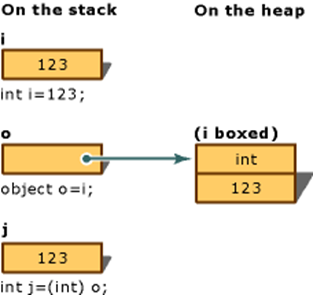
我们再回头看刚才例子的装箱操作,可以用很清晰的图片来表达:
int i = 123;
object o = (object)i;
int i = 123;
object o = i;
int j = (int)o;
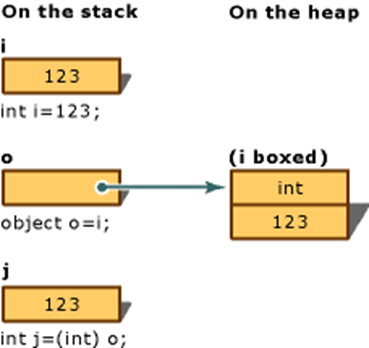
装箱操作是在堆中开辟一个新的空间,再将栈中的数据赋值过去,拆箱操作则相反。
取消装箱(Unboxing)
取消装箱也就是拆箱,是从object类型到值类型或从接口类型到实现该接口的值类型的显式转换。取消装箱操作包括:
- 检查对象实例,以确保它是给定值类型的装箱值。
- 将该值从实例复制到值类型变量中。
要在运行时成功取消装箱值类型,被取消装箱的项必须是对一个对象的引用,该对象是先前通过装箱该值类型的实例创建的。
int i = 123;
object o = i;
try
{
int j = (short)o; // 拆箱
Console.WriteLine("拆箱成功!");
}
catch (InvalidCastException e)
{
Console.WriteLine("{0} 拆箱失败!", e.Message);
}
C#动态数组(ArrayList)
了解了装箱和拆箱的数据结构,让我们把目光拉回开篇,讨论的问题是集合类的区别,先从C#的动态数组ArrayList开始说明。
动态数组(ArrayList)代表了可被单独索引的对象的有序集合。它基本上可以替代一个数组。但是,与数组不同的是,您可以使用索引在指定的位置添加和移除项目,动态数组会自动重新调整它的大小。它也允许在列表中进行动态内存分配、增加、搜索、排序各项。
ArrayList al = new ArrayList();
al.Add(45);
al.Add(78);
al.Add(33);
al.Add(56);
al.Add(12);
al.Add(23);
al.Add(9);
foreach (short i in al)
{
Console.Write(i + " ");
}
而我们现在平时比较常用的是命名空间同为System.Collections.Generic的泛型集合List<T>,使用这个类可通过索引访问对象的强类型列表,提供用于对列表进行搜索、排序和操作的方法。
这两种集合类的功能看上去差不多,但为什么现在都使用后者呢?这里先看个简单的例子:
// ArrayList
private static void TestArrayListAddByValue()
{
for (int i = 0; i < testValue; i++)
{
arrayListValue.Add(0);
}
description = "ArrayList值类型";
}
private static void TestArrayListAddByReference()
{
for (int i = 0; i < testValue; i++)
{
arrayListReference.Add("0");
}
description = "ArrayList引用类型";
}
// List<T>
private static void TestListAddByValue()
{
for (int i = 0; i < testValue; i++)
{
listReference.Add(0);
}
description = "List添加值类型";
}
private static void TestListAddByReference()
{
for (int i = 0; i < testValue; i++)
{
listValue.Add("0");
}
description = "List添加引用类型";
}
程序执行的结果:
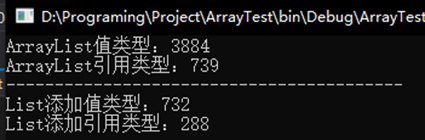
性能上的差异显而易见,那么为什么会有这样的结果呢?我们再带上其他集合类一起说明。
HashTable、Dictionary和List
- HashTable 散列表(也叫哈希表),是根据关键字(Key value)而直接访问在内存存储位置的数据结构。
- Dictionary<TKey, TValue> 泛型类提供了从一组键到一组值的映射。字典中的每个添加项都由一个值及其相关联的键组成。通过键来检索值,实质其内部也是散列表
- List 是针对特定类型、任意长度的一个泛型集合,实质其内部是一个数组。
ICollection和ICollection
这三个是我现在还比较有疑问的类,我们可以先观察一下这张关系表,发现在结构上似乎有所对应,ArrayList和HashTable实现ICollection接口,List和Dictionary<T,k>实现ICollection接口,并且看起来List好像是ArrayList的升级版,另外两个类也是一样的,多了一个泛型有什么区别呢?

还是刚才的代码,我又引入新的类执行了一遍,并且这次还加入了遍历数据的时间:

看一看出List与Dictionary的差距好像不是特别大,暂且不谈,主要还是HashTable的表现欠佳,其实也就是ICollection和ICollection的比较,这一个“T”差了有多少,其实刚好就是一次装箱或拆箱,在数千次的循环中,这个差距逐渐被放大了,实现ICollection的类在每一次添加值类型的时候都是先转换为ArrayList引用类型,也就是装箱,引用类型转换即使没有发生装箱,也发生了一次地址的变更。而实现ICollection的类进行添加操作则是向数组中添加了一个新的元素,类型其实没有发生改变,自然也就没有花费那么长的时间。
除了装箱会消耗时间外,在测试的时候发现当循环的次数超过某个值的时候,使用HashTable的程序发生了可以复现的崩溃,个人猜测应该是内存溢出,由于测试的具体环境不同,这里就不写出具体的值了,感兴趣可以自己测试一下。
Dictionary与List
横向的比较可以得出是装箱造成了性能损耗这个结果,那么纵向比较ICollection内的两个类,它们之间为什么也会有性能差异呢?
我们要从存储结构和操作系统的原理谈起。
首先我们清楚List是对数组做了一层包装,我们在数据结构上称之为线性表,而线性表的概念是,在内存中的连续区域,除了首节点和尾节点外,每个节点都有着其唯一的前驱结点和后续节点。我们在这里关注的是连续这个概念。(List插入效率高的原因)
而HashTable或者Dictionary,他是根据Key而根据Hash算法分析产生的内存地址,因此在宏观上是不连续的,虽然微软对其算法也进行了很大的优化。
由于这样的不连续,在遍历时,Dictionary必然会产生大量的内存换页操作,而List只需要进行最少的内存换页即可,这就是List和Dictionary在遍历时效率差异的根本原因。
除了刚才的遍历问题,还要提到Dictionary的存储空间问题,在Dictionary中,除了要存储我们实际需要的Value外,还需要一个辅助变量Key,这就造成了内存空间的双重浪费。
而且在尾部插入时,List只需要在其原有的地址基础上向后延续存储即可,而Dictionary却需要经过复杂的Hash计算,这也是性能损耗的地方。
(Dictionary插入效率低的原因)
综上所述,List在插入数据时更有优势,而Dictionary则因为有哈希表的存在,这就相当于有一个目录,可以根据Key值更快地定位到需要的Value,只不过在数据量不大的情况下难以体现出差异,我们可以提升一下程序的数据精度:
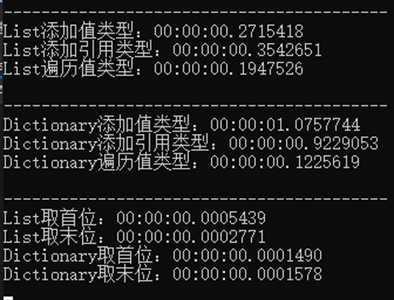
可以看出,在取出某个数据时,Dictionary<T,K>更具优势。
哈希冲突
在查资料的时候也顺便学习了一下哈希冲突相关的知识,上文提到Hashtable和Dictionary从数据结构上来说都属于Hashtable(哈希表),都是对关键字(键值)进行散列操作,将关键字散列到Hashtable的某一个槽位中去,不同的是处理碰撞的方法。散列函数有可能将不同的关键字散列到Hashtable中的同一个槽中去,这个时候我们称发生了碰撞,为了将数据插入进去,我们需要另外的方法来解决这个问题。这里举两个常见的例子:开放寻址法和链表法。
开放寻址法
开放寻址法中也有很多分类,这里以比较容易的线性探测为例,有这样一组数字:12,67,56,16,25,37,22,29,15,47,48,34,前五个已经被分别存放在下标为0,1,4,7,8的这五个位置,这时按顺序要将37也插入这个集合,那么就从0开始找,发现0的位置已经被占用了,再看1也被占用了,当搜索到2的时候发现是空的,那么37就被存放在了下标为2的这个位置,依次类推,这样就可以将所有数字存入集合,过程如下图:
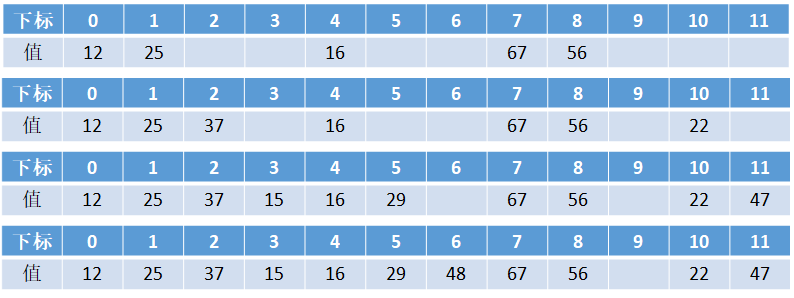
开放寻址法只用数组一种数据结构存储,继承了数组的优点,对CPU缓冲友好,易于序列化。但是对内存的利⽤率并不如链表法,且冲突的代价更高。当数据量比较小、装载因子小的时候,适合采⽤开放寻址法。这也是Java中的ThreadLocalMap使⽤开放寻址法解决散列冲突的原因。
链表法
开放寻址法很好理解,其实就是一间间地开门看过去,有人就换下一间,直到找到没人的房间,再看链表法,就相对巧妙一些,还是刚才那组数字,我们现在有12个位置,那么我们就让每一个数字以12为除数取余,再通过链表将他们安放到对应的位置,一旦发生冲突就在链表后面再加一节,因为链表的特性,地址永远不会冲突,只不过当我们需要找到对应的数据时要对单个链表进行遍历。
链表法对内存的利⽤率比开放寻址法要高。因为链表结点可以在需要的时候再创建,并不需要像开放寻址法那样事先申请好。链表法比起开放寻址法,对大装载因⼦的容忍度更⾼。基于链表的散列冲突处理⽅法比较适合存储大对象、大数据量的散列表,而且,比起开放寻址法,它更加灵活,支持更多的优化策略,比如⽤红黑树代替链表。

技术分享PPT整理(二):C#常用类型与数据结构的更多相关文章
- 技术分享PPT整理(一):Bootstrap基础与应用
最近在复习的时候总感觉有些知识点总结过,但是翻了一下博客没有找到,才想起来有一些内容是放在部门的技术分享里的,趁这个时候跳了几篇相对有价值的梳理一下,因为都是PPT,所以内容相对零散,以要点和图片为主 ...
- 技术分享,学术报告presentation 常用的承接句
前言 现在即使是搞技术,做科研的,也需要在不同的场合,用ppt来做分享,做汇报,做总结. 如果国际会议,研讨会,或者在外企,国外工作,英文的presentation就更加必不可少.英语的提升需要大家从 ...
- 技术分享会(二):SQLSERVER索引介绍
SQLSERVER索引介绍 一.SQLSERVER索引类型? 1.聚集索引: 2.非聚集索引: 3.包含索引: 4.列存储索引: 5.无索引(堆表): 二.如何创建索引? 索引示例: 建表 creat ...
- 分布式缓存技术redis学习(二)——详细讲解redis数据结构(内存模型)以及常用命令
Redis数据类型 与Memcached仅支持简单的key-value结构的数据记录不同,Redis支持的数据类型要丰富得多,常用的数据类型主要有五种:String.List.Hash.Set和Sor ...
- 分布式缓存技术redis系列(二)——详细讲解redis数据结构(内存模型)以及常用命令
https://www.cnblogs.com/hjwublog/p/5639990.html
- UWA 技术分享连载 转载
技术分享连载1 Q1:Texture占用内存总是双倍,这个是我们自己的问题,还是Unity引擎的机制? Q2:我现在发现两个因素直接影响Overhead,一个是Shader的复杂度,一个是空Updat ...
- 单元测试系列之十:Sonar 常用代码规则整理(二)
摘要:帮助公司部署了一套sonar平台,经过一段时间运行,发现有一些问题出现频率很高,因此有必要将这些问题进行整理总结和分析,避免再次出现类似问题. 作者原创技术文章,转载请注明出处 ======== ...
- C#技术分享【PDF转换成图片——13种方案】(2013-07-25重新整理)
原文:C#技术分享[PDF转换成图片--13种方案](2013-07-25重新整理) 重要说明:本博已迁移到 石佳劼的博客,有疑问请到 文章新地址 留言!!! 写在最前面:为了节约大家时间,撸主把最常 ...
- 社区活动分享PPT:使用微软开源技术开发微服务
上周六在成都中生代技术社区线下活动进行了一个名为"微软爱开源-使用微软开源技术开发微服务"的技术分享. 也算是给很多不熟悉微软开源技术的朋友普及一下微软最近几年在开源方面所做的努力 ...
随机推荐
- git branch All In One
git branch All In One Git Branch Management https://git-scm.com/book/en/v2/Git-Branching-Branch-Mana ...
- Vue 组件之间通信 All in One
Vue 组件之间通信 All in One 组件间通信 1. 父子组件之间通信 https://stackblitz.com/edit/vue-parent-child-commutation?fil ...
- CSS BFC in depth
CSS BFC in depth BFC (Block Formatting Context) https://developer.mozilla.org/en-US/docs/Web/Guide/C ...
- very useful English Acronyms in Programming for Programmer
very useful English Acronyms in Programming for Programmer alias / shorthand / acronyms 别名 / 简写 / 缩略 ...
- Web Share API
Web Share API https://w3c.github.io/web-share/ Web Share API, W3C Editor's Draft 15 April 2020 https ...
- react hooks useEffect 取消 promise
react hooks useEffect 取消 promise cancel promise https://github.com/facebook/react/issues/15006#issue ...
- 一周精彩内容分享(第 3 期):开工大吉的 B 面
这里记录过去一周,我看到的值得分享的东西. 一方面是整理记录一下自己一周的学习,另一方面也是期待自己有更多的输出,有更多的价值. 周刊开源(Github:wmyskxz/weekly),欢迎提交 is ...
- luogu4464:莫比乌斯反演,积性函数和伯努利数
题目链接:https://www.luogu.com.cn/problem/P4464 简记$gcd(x,y)=(x,y)$. 推式子: $\sum_{i=1}^{n}{(i,n)^xlcm(i,n) ...
- Kubernetes中分布式存储Rook-Ceph的使用:一个ASP.NET Core MVC的案例
在<Kubernetes中分布式存储Rook-Ceph部署快速演练>文章中,我快速介绍了Kubernetes中分布式存储Rook-Ceph的部署过程,这里介绍如何在部署于Kubernete ...
- 微信的两种access_token总结,不能混淆
大家需要弄清楚微信的网页授权token和公众号api调用授权token. 1.网页授权access_token 1.有效期:7200ms 2.微信网页授权是通过OAuth2.0机制实现的,在用户授权给 ...