Distributed | ZooKeeper
ZooKeeper与之前看的论文不太一样,它主要是描述了一个分布式协调服务,提供了wait-free的api,可以让用户自己设计要求更高的原语。通过Zab协议保证sever之间的一致性,同时让读请求在本地执行,极大地优化了读取速度。
在看完论文之后对ZooKeeper的两个保证有些疑惑,在看了6.824中有关zk的讲解和一些博客之后,总结了我对着两个保证的理解。同时对论文内容也进行了部分总结。
关于ZooKeeper的思考
Linearizable
首先,ZooKeeper实现了写请求的线性一致性 - Linearizable,那什么是线性一致性?
教授认为Linearizable就是strong consistency 的同义词。即保证对于一个对象的写操作,一旦写完成,需要立即被后续的读操作看到。读操作读到的一定是这个对象的最新的值。
一种根据日志来判断强一致性的方法:
- 如果操作A在操作B开始前结束,则线性序列中A一定在B之前
- 某个读请求看到了一个特定的写入值,则线性序列中该读请求一定在该写请求之后
- 所有的client要看到同样的线性序列,不允许不同的client看到不同的历史记录或者是同一时刻下所保存系统内的数据不同
- 一旦数据被修改,后续的读操作必须读到最新的值
如果能将日志中的并发请求连接成 线性序列,则说明这些请求是线性一致性的。
写请求Linearizable
那么是什么是写线性一致性呢?由于ZooKeeper中每个写请求都是重定向给leader执行,多个clinet可能并发地提交写请求。但leader服务器按顺序处理写操作,不并发处理其他写或读操作,保证了线性一致性。
client请求FIFO
这部分比较难理解。问题在于,客户端发出的写请求需要由leader先写入,再执行一致性协议由超过半数的服务器确认后才能提交。这个操作需要花费一定的时间。而读请求是在服务器本地执行,这个服务器可能没有被写入该数据(因为只要有半数以上服务器写入就算写操作成功)。那么如果Client写请求之后立即读,岂不是会读到旧值?违反了FIFO order
为了解决这个问题,保证 per client 的FIFO,在每次client发出写操作之后,ZooKeeper返回一个唯一自增 zxid,代表此时写入的事务ID。当client读取数据时,server会将自己的最大zxid和client的zxid进行比较,如果client的zxid比sever的大,则该server拒绝和client通信,client重新寻找具有最新数据的server进行读取。
但是这只是per client的一致性。如果 client A 写入数据,此时 client B 读取该数据,并不保证 Client B 能够读到最新的数据。如果想要获取全局最新数据,需要通过 sync 同步原语,更新server数据。
下面是对论文的部分总结。
概述
ZooKeeper旨在提供一个简单而高性能的分布式协调服务,以在客户端构建更复杂的协调原语。ZooKeeper公开的接口具有共享寄存器的无等待(wait free)特性,并保证
- 每个客户端请求按FIFO顺序执行
- 所有的ZooKeeper状态改变线性化
介绍
大部分应用程序需要不同形式的协调(coordination)
- 配置(configuration)是最基本的协调形式之一。包括系统过程的操作参数和更复杂系统中的动态配置参数
- 成员关系(Group membership)
- 领导选举(Leader election)
进程需要知道哪些其他进程仍在运行,以及这些进程负责什么。
解决上述coordination的一种方案是为每个不同的coordination开发专门的服务。因此在设计coordination时,不再服务器端实现特定的原语(primitives),而是提供通用的API满足个性化的primitives,这样做的结果是
- 实现了一个协调内核,无需更改服务核心,就可以实现新的原语
- 满足了应用程序对多种形式的协调的需求
在设计ZooKeeper的API时,不再使用block primitives(阻塞原语),这是因为
- 阻塞原语会导致客户端变慢或故障,从而对速度更快的客户端性能产生负面影响
- 如果处理请求依赖于其他客户端的响应和故障检测,则服务本身的实现将变得更加复杂
因此ZooKeeper实现了一个API操纵wait-free数据对象。这些对象像文件系统一样按层次结构组织。
仅靠wait-free不足以实现coordination,还需要保证操作的有序执行:保证每个客户端操作FIFO,所有写请求Linearizable
ZooKeeper通过pipelined architecture,使得可以同时处理数百上千个请求依旧保持低延迟。客户端同时发出多个请求,异步执行同时保证FIFO。使用异步操作,客户端可以同时拥有多个未完成的操作。
为了保证更新操作linearizable,实现了一个基于领导的原子广播协议(leader-based atomic broadcast protocol) - Zab。但由于ZooKeeper应用程序的典型工作负载是读操作,因此让读操作在服务器本地执行,不用Zab进行组织。
在客户端缓存数据是提高读取性能的一项重要技术。例如,对于一个进程来说,缓存当前leader的标识符是非常有用的,而不是每次需要了解ZooKeeper时都去获取。ZooKeeper使用一种监视(watch)机制使客户端可以缓存数据,而无需直接管理客户端缓存。 使用此机制,客户端可以监视对给定数据对象的更新,并在更新时接收通知。
ZooKeeper服务
ZooKeeper提供了client library来访问服务,client library主要做两件事:
- 管理client和ZooKeeper之间的网络连接
- 提供ZooKeeper的api
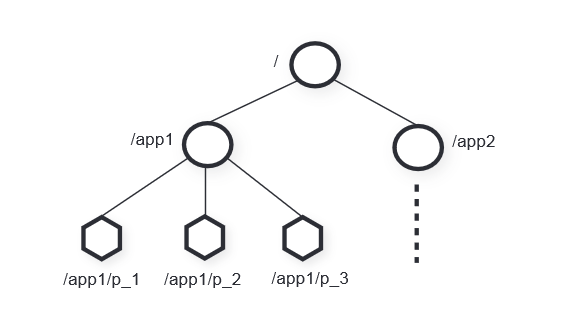
ZooKeeper给客户端提供了znode的抽象,客户端通过api来操作znode中存储的数据,znode的地址类似文件系统中的path,像上图中节点p_1就通过路径/app1/p_1来访问,客户端可以创建两种znode:
- Regular: 需要客户端显式的创建和删除
- ephemeral: 客户端创建,也可以删除,也可以当会话终止时候让系统自动删除
此外,创建新znode的时候可以设置一个顺序标志,使用顺序标志集创建的节点的名称后面附加了一个单调递增的计数器的值。如果n是新的znode, p是父znode,那么n的序列值永远不会小于在p下创建的任何其他顺序znode的名称中的值。
ZooKeeper实现了监视器(Watcher),允许客户端不需要轮询能够及时接收更改通知。当客户端发送带有监视标志的读取操作时,该操作会正常完成,并且服务器保证在返回的信息已更改时通知客户端。监视器(Watcher)是一次性触发的;一旦触发或会话关闭,监视器就会被移除。监视器只会通知更改的发生,不会提供更改的内容。
znode 不是为常规数据存储设计的。 相反,znode映射到客户端应用程序的抽象,通常对应于用于协调目的的元数据。
虽然 znodes 并不是为通用数据存储而设计的,但是ZooKeeper确实允许客户端存储一些信息,用于分布式计算中的元数据或配置。
ZooKeeper保证
ZooKeeper具有两个基本的顺序保证:
- Linearizable writes:所有更新ZooKeeper状态的请求都是可线性化,并且遵守优先级
- FIFO client order:来自给定客户端的所有请求都按照客户端发送的顺序执行。
A-linearizability (异步线性化):允许一个客户端有多个未完成的操作
一个由多个进程组成的系统会选择一个 leader 来指挥工作进程。当一个新的领导接管系统,它必须改变大量的配置参数,并在它结束时通知其他进程。我们有两个重要的要求:
- 当新领导开始进行更改时,我们不希望其他进程使用正在更改的配置
- 如果新的leader在配置完全更新之前死亡,我们不希望进程使用这个部分配置
使用ZooKeeper,新的leader可以指定一个路径为ready znode,其他进程只会在该znode存在时使用该配置。
- 新leader改变前删除 ready znode
- 改变配置
- 新建 ready znode
所有这些更改都可以被流水线化,并异步发布以快速更新配置状态。
由于排序保证,如果一个进程看到了ready znode,它也必须看到由新的leader所做的所有配置更改。如果新的 leader 在ready znode创建之前死亡,其他进程知道这个配置还没有完成,所以不会使用它。
A和B在ZooKeeper上有共享数据,A改变数据后,通过其他通信手段告诉B数据改变了,此时B去读取数据,可能会读取不到改变的数据,因为ZooKeeper集群可能存在的主从延迟,解决方案是:B读之前先发个sync请求,类似于文件系统中的flush操作,让数据同步给各个server。
ZooKeeper实现
ZooKeeper通过在组成服务的每个服务器上复制ZooKeeper数据来提供高可用性。对于写请求,需要在服务器之间进行coordination,需要使用一致性协议。然后服务器将更改提交给ZooKeeper数据库,并将其复制到全体服务器。而对于读请求,服务器只需读取本地数据库。
每个ZooKeeper服务器都向客户端提供服务。客户端只需要连接到一个服务器来提交它的请求。就像前面说的,读取请求来自每个服务器数据库的本地副本。更改服务状态的请求(写请求)由一致性协议处理。
作为一致性协议的一部分,写请求被转发到称为leader的单个服务器。其他的ZooKeeper服务器称为followers,接收来自leader的包含状态改变的proposals(提案)信息,并就状态改变达成一致。
请求处理器(Request Processor)
由于消息传递是原子的,可以保证本地副本永远不会发生分歧,但在某些时刻一些服务器可能应用了更多的事务。但和客户端请求不同,事务是幂等的。
当leader接收到一个写请求时,它会计算应用写请求时系统的状态,并将其转换为捕获这个新状态的事务。因为可能有未完成的事务尚未应用到数据库,所以必须计算将来的状态。
原子广播(Atomic Broadcast)
所有更新ZooKeeper状态的请求都会转发给leader。leader执行请求,并通过原子广播协议Zab将状态更改广播到ZooKeeper。接收客户端请求的服务器在提交相应状态更改时会响应给客户端。Zab默认使用简单的多数服务器来决定一个提案,因此在\(2f+1\)个服务器中,可以容忍 \(f\) 个服务器故障。
由于状态更改依赖于之前的状态,Zab提供了比一般原子广播协议更强的顺序保证。Zab保证leader的变更广播是按照发送的顺序传递的,并且所有来自前任leader的变更都是在它广播自己的变更之前,先发送给新的leader
ZooKeeper用TCP进行传输,避免了网络维护。使用Zab选择的leader作为ZooKeeper leader,由同一个进程创建和提出事务。使用日志来跟踪提案,将其作为内存数据库的预写日志,这样就不必将消息两次写入磁盘。
由于事务是幂等的,在恢复时只要按顺序发送事务,多次传递信息也是可以接受的。
复制数据库(Relicated Database)
每个副本在内存中都有一个 ZooKeeper 状态的拷贝。当 ZooKeeper 服务器从崩溃中恢复时,它需要恢复这个内部状态。在服务器运行一段时间后,重放所有已发送的消息以恢复状态将花费非常长的时间,因此 ZooKeeper 使用定期快照,并且只需要在快照开始后重新发送消息。
ZooKeeper使用模糊快照,在获取快照时不锁定 ZooKeeper 状态。而是对树进行深度优先扫描,原子地读取每个 znode 的数据和元数据,并将它们写入磁盘。由于产生的模糊快照可能应用了在生成快照期间交付的状态更改的某个子集,因此结果可能在任何时间点上都不对应于 ZooKeeper 的状态。
然而,由于状态更改是幂等的,因此只要按顺序应用状态更改,我们就可以应用它们两次。
客户端-服务器交互
当服务器处理写请求时,它还会发送和清除与该更新相对应的任何watch的通知。服务器按顺序处理写操作,而不并发处理其他写操作或读操作。这确保了通知的严格连续性。
读请求在服务器本地处理,每个读请求使用 zxid 标记,对应服务器看到的最后一个事务。zxid 定义了读请求相对于写请求的部分顺序。 通过本地读取,ZooKeeper 获得了优异的的读取性能,只在内存操作,避免了磁盘活动和一致性协议。
使用这种快速读取的方式可能导致读操作返回一个过时的值。对于需要读取最新值的应用,ZooKeeper实现了 sync 同步原语。 sync 异步执行,在所有待写入的操作完成之后,由leader进行组织。为了保证给定的读操作返回最新的更新值,客户端先调用 sync 然后执行 read 操作。客户端操作的FIFO顺序保证和全局同步保证使读操作的结果能够反映发出同步之前发生的任何更改。
在我们的实现中,我们不需要原子广播 sync,因为我们使用基于leader的算法,我们只是将 sync 操作放在 leader 和执行 sync 调用的服务器之间的请求队列的末尾。(就是从leader向该服务器进行同步)
为了做到这一点,follower必须确保领导者仍然是领导者。如果存在提交的挂起事务,则服务器不会怀疑 leader 。如果挂起队列为空,leader需要发出一个 null 事务来提交,并在该事务之后组织 sync 。这样做的好处是,当 leader 处于负载时,不会产生额外的广播流量。在我们的实现中,设置了超时,以便领导者在 follower 抛弃它们之前意识到它不是领导者,不会发出null 事务。
ZooKeeper服务器按照FIFO顺序处理来自客户端的请求。响应包括响应相对的zxid。即使在没有活动的间隔期间,心跳消息也包括客户端所连接的服务器所看到的最后一个zxid。如果客户端连接到一个新服务器,新服务器通过检查客户端的最后一个 zxid 和它的最后一个 zxid 来确保它的 ZooKeeper 数据视图至少与客户端的视图一样新。如果客户端的视图比服务器的更新,服务器在服务器跟上之前不会重新建立与客户端的会话。客户端保证能够找到另一个具有系统最新视图的服务器,因为客户端只能看到已经复制到大多数 ZooKeeper 服务器上的更改。
Distributed | ZooKeeper的更多相关文章
- [Big Data - ZooKeeper] ZooKeeper: A Distributed Coordination Service for Distributed Applications
ZooKeeper ZooKeeper: A Distributed Coordination Service for Distributed Applications Design Goals Da ...
- ZooKeeper Distributed lock
https://segmentfault.com/a/1190000016351095 http://www.dengshenyu.com/java/%E5%88%86%E5%B8%83%E5%BC% ...
- 【分布式】Zookeeper序列化及通信协议
一.前言 前面介绍了Zookeeper的系统模型,下面进一步学习Zookeeper的底层序列化机制,Zookeeper的客户端与服务端之间会进行一系列的网络通信来实现数据传输,Zookeeper使用J ...
- 【分布式】Zookeeper在大型分布式系统中的应用
一.前言 上一篇博文讲解了Zookeeper的典型应用场景,在大数据时代,各种分布式系统层出不穷,其中,有很多系统都直接或间接使用了Zookeeper,用来解决诸如配置管理.分布式通知/协调.集群管理 ...
- 搭建zookeeper集群
简介: Zookeeper 分布式服务框架是 Apache Hadoop 的一个子项目,它主要是用来解决分布式应用中经常遇到的一些数据管理问题,如:统一命名服务.状态同步服务.集群管理.分布式应用配置 ...
- 基于ZooKeeper的分布式锁和队列
在分布式系统中,往往需要一些分布式同步原语来做一些协同工作,上一篇文章介绍了Zookeeper的基本原理,本文介绍下基于Zookeeper的Lock和Queue的实现,主要代码都来自Zookeeper ...
- ZooKeeper基本原理
ZooKeeper简介 ZooKeeper是一个开放源码的分布式应用程序协调服务,它包含一个简单的原语集,分布式应用程序可以基于它实现同步服务,配置维护和命名服务等. ZooKeeper设计目的 1. ...
- hadoop2.6.2+hbase+zookeeper环境搭建
1.hadoop环境搭建,版本:2.6.2,参考:http://www.cnblogs.com/bookwed/p/5251393.html 启动服务:在master机器上,进入hadoop安装目录, ...
- zookeeper学习系列:四、Paxos算法和zookeeper的关系
一.问题起源 淘宝搜索的博客 http://www.searchtb.com/2011/01/zookeeper-research.html 提到Paxos是zookeeper的灵魂 有一篇文章标题 ...
随机推荐
- Web API & Element & DOM
Web API & Element & DOM Element https://developer.mozilla.org/en-US/docs/Web/API/Element HTM ...
- 新手如何通过内存和NGK DeFi Baccarat进行组合投资?
区块链市场在2020年迎来了大爆发,资本市场异常火热.无论是内存,还是DeFi,都无疑是这个火爆的区块链市场中的佼佼者.通过投资内存和DeFi,很多投资者都已经获取了非常可观的收益,尝到了资本市场带来 ...
- 修改yapf中的列宽限制值
yapf是一款由Google开源的Python代码自动格式化工具,它根据PEP 8规范可以帮我们自动格式化我们的代码,让代码更规范.更漂亮.但是其中最大列宽被限制为80,如果超过80,在格式化时就会被 ...
- Java开发工程师最新面试题库系列——Spring部分(附答案)
Spring Spring框架是什么? 答:Spring是轻量级的面向切面和控制反转的框架.初代版本为2002年发布的interface21,Spring框架是为了解决企业级应用开发的复杂性的出现的, ...
- IDEA如何快速查看类中的属性和方法?
在idea中,当需要快速的查看一个类的所有属性和方法时,直接去代码中查看,就显得非常的麻烦,idea是有快捷键的,可显示所有的属性和方法,方法如下. 打开一个类,使用快捷键ALT+7,就可以在左侧看到 ...
- Go的包
目录 go的包 一.包的创建规则 二.包的导入规则 三.包的函数调用 go的包 一.包的创建规则 一个包就是一个文件夹. 同一个包(文件夹)下,所有go文件都只能用同一个package,也就是每个文件 ...
- Centos7安装Docker&镜像加速
目录 Docker Docker安装 方式一 方式二 docker 镜像加速 Docker Docker安装 Docker安装 方式一 step1: 删除老版本(Uninstall old versi ...
- 【图像处理】使用OpenCV+Python进行图像处理入门教程(二)
这篇随笔介绍使用OpenCV进行图像处理的第二章 图像的运算,让我们踏上继续回顾OpenCV进行图像处理的奇妙之旅,不断地总结.回顾,以新的视角快速融入计算机视觉的奥秘世界. 2 图像的运算 复杂的 ...
- 03----python入门----函数相关
一.前期知识储备 函数定义 你可以定义一个由自己想要功能的函数,以下是简单的规则: 函数代码块以 def 关键词开头,后接函数标识符名称和圆括号 () 任何传入参数和自变量必须放在圆括号中间,圆括号 ...
- windows 之间内网开启远程桌面连接
win7设置远程桌面1.找到我的电脑\计算机图标,右键"属性"如图2.进入系统和安全设置-选项卡中,找到"远程设置"右上角位置点击打开3.在随后的"系 ...