【DevCloud · 敏捷智库】两种你必须了解的常见敏捷估算方法
背景
在某开发团队辅导的回顾会议上,团队成员对于优化估计具体方法上达成了一致意见。询问是否有什么具体的估计方法来做估算。
问题分析
回顾意见上大家对本次Sprint的效果做回顾,其中80%的成员对于本次Sprint的估算效果不满意,最终团队希望在下一个Sprint中,估算活动能有所改善。
经了解,团队目前的估算方法很简单,基本上是架构师和团队中有丰富开发经验的成员一言堂。估算的速度也很快。对于有些有疑问的需求,开发成员也是保持沉默,草草认领了任务。
团队迫切希望学习新的估算方法来优化目前的估算活动,因此分享几个具体的估算方法给团队实践,让他们自己选择适合、喜欢的估算方法是解决问题的关键。
解决措施
我们来学习下具体的故事点估算的实践,感受一下估算。这里介绍最常用的两种估算方法:一个是计划扑克估算,另一个是敏捷估算2.0。下表内容展示了这两种估算方法在什么情形下选择。

计划扑克估算
在敏捷开发中,最典型的使用故事点做估算的方法是计划扑克(Planning Poker)。

计划扑克由James Grenning在2002年首次提出。计划扑克集合了专家意见(Expert Opinion),类比(Analogy)以及分解(Disaggregation)这三种常用的估算方法,使团队通过一个愉快的过程快速而准确的得出估算结果。
计划扑克的参与者是团队的所有成员。典型的敏捷团队规模推荐为7±2人,如规模比较大可以考虑拆分成为多个小团队各自独立进行估算。Product Owner也需要参加,但不参与估算。
计划扑克开始时,每个参与估算的组员都会得到一副计划扑克,每一张牌上写有一个Fibonacci数字 (典型的计划扑克由12张牌组成:?,0, ½,1, 2, 3, 5, 8, 13, 20, 40, 100,∞,其中?代表信息不够无法估算,∞代表该用户故事太大)。
开始对一个用户故事进行估算时,首先由Product Owner介绍这个用户故事的描述。过程中Product Owner回答组员任何关于该用户故事的问题。展开讨论时主持人(通常由Scrum Master担任)应注意控制时间与细节程度,只要团队觉得对用户故事信息已经了解到可以估算了,就应当中止讨论开始估算。
所有问题都被澄清后,每一个组员从 扑克中挑选他/她觉得可以表达这个用户故事大小的一张牌,但是不亮牌,也不让别的组员知道自己的分数。所有人都准备好后,主持人发口令让所有人同时亮牌,并保证每个人的估算值都可以被其他人清楚的看到。
经常会出现不同组员亮出的分值差距很大的现象。当出现有很多不同分值的时候,出分最高的人和出分最低的人需要向整个团队解释出分的依据。(主持人需要注意控制会议氛围,避免出现意见不一导致的攻击性言论。)所有的讨论应集中于出分者的想法是否值得团队其他成员进行更深入的思考。
随后全组可以针对这些想法进行几分钟的自由讨论。讨论之后,团队进行下一轮的全组估算。一般来说,很多用户故事在进行第二轮估算的时候就能得到一个全组统一的分值,但是如果不能达到全组意见一致,那么就重复的进行下一轮直到得到统一结论。
敏捷估算2.0(Agile Estimating 2.0)
计划扑克是Scrum团队应用最广泛的敏捷估算方法,但是有时候计划扑克玩起来耗费比较多的时间,尤其是在十人左右的团队中。Ken Schwaber在他的书《Agile Project Management with Scrum》中指出,在进行迭代规划时,迭代计划环节应该控制为一个4小时的固定时间,但是从战术的角度看,如果一个会议持续4小时,大部分的参会者会有精疲力竭的感觉,并且很难保持持久的注意力。
为了解决这个问题,Brad Swanson 和 Björn Jensen在上海Scrum Gathering (2010/4/19)上介绍了Agile Estimating 2.0技术。这个新的估算技术同样基于的专家意见,类比和分解,同样适用Fibonacci数列,但是它可以显著地缩短会议时间。它的估算过程大致分为主要四步,如下图所示:
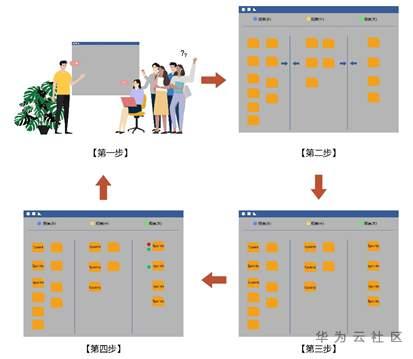
第一步:由Product Owner向团队介绍每一个用户故事,确保所有需求相关的问题都在做估算前得到解决。

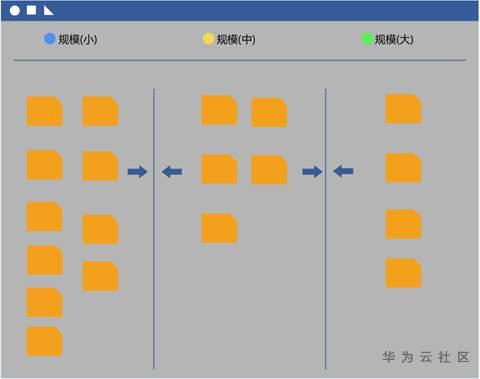
第二步:整个团队一起参与这个游戏。
只有一个简单的游戏规则:一次仅由一个人将一个用户故事卡放在白板的合适位置上:规模小的故事在左,大的在右,一样大的竖向排成一列。整个团队轮流移动故事卡,直到整个团队都认同白板上的故事卡的排序为止。
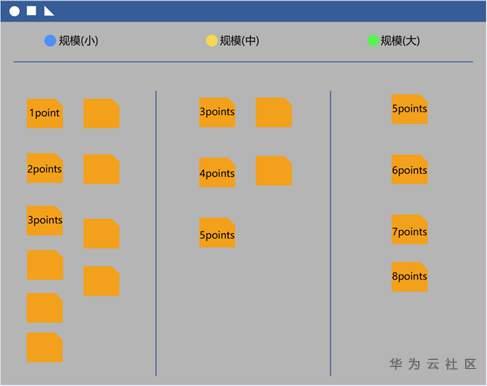
第三步:团队将故事点(Story Point)分配给每个用户故事(列)。
最简单的做法是使用投票来决定每个用户故事分配到哪一个Fibonacci数字。
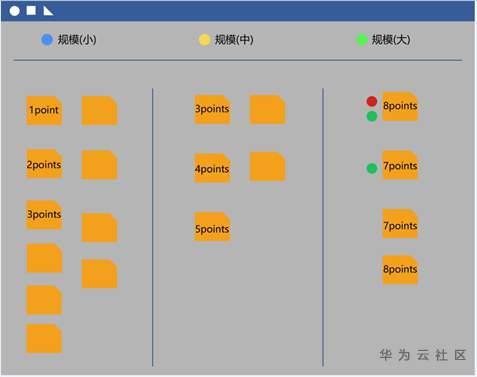
最后一步:使用不同颜色来区分影响估算大小的不同方面,并且重新考虑是否需要修改估算值。
例如,我们使用红色来表示那些无法被自动化测试脚本覆盖的用户故事,因此那些用户故事需要一个更大的数字来容纳手工回归测试的代价。
在国内一些企业多次实践Agile Estimating 2.0之后,反馈的结果还是令人兴奋。据称,团队对于估算的准确性更有信心了,并且只耗费原先的1/2时间。
通过以上介绍,相信了解了如何使用用户故事来分析了解需求。在学习了估算的核心概念及故事点后,对于估算方法的实践也有了更深的体会。不论是计划扑克估算还是敏捷估算2.0都只是估算的一种实践,不是固定的唯一方法。只要理解估算的意义和核心概念,选择适合的方法就是没有问题的。另外补充一下,这里讲的估算偏重于用故事点估算,如果团队成员一致达成共识,用工时或理想人天效果更好,便可以尝试,给予团队试错的机会,说不定也有意想不到的收获。
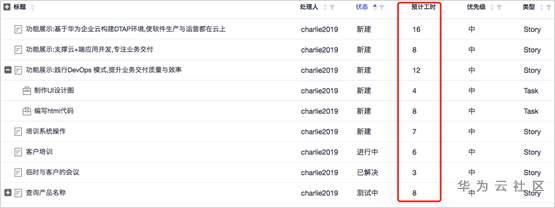
完成了估算后,我们需要对估算的内容进行管理。华为云DevCloud在用户故事或者Task中均有一个记录估算结果的属性,比如预计工时。所有工作项估算结果记录以后就可以以列表的方式进行查看。可以按处理人排序,查看每个成员认领的任务是否饱和。
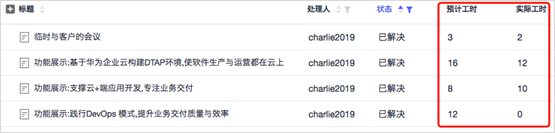
开发团队完成的工作内容可以时时更新实际数据,这样每轮迭代也可以就估算准确度进行统计和分析。看看估算结果和实际结果的差别,以便可以后续做估算调整和改善。
参考附录
- Kenneth S. Rubin. Scrum精髓[M].北京:清华大学出版社。
- Mark C. Layton. 敏捷项目管理[M].北京:人民邮电出版社。
估算系列文章
【DevCloud · 敏捷智库】估算第一篇:利用用户故事了解需求
【DevCloud · 敏捷智库】估算第二篇:利用核心概念解决估算常见问题
【DevCloud · 敏捷智库】估算第三篇:利用故事点做估算
【DevCloud · 敏捷智库】两种你必须了解的常见敏捷估算方法的更多相关文章
- linux两种增加交换分区(swap)的方法
在安装Oracle后,为使Oracle流畅运行,需要手动增加linux的交换分区(相当于Windows下的虚拟内存)的大小,本文介绍两种增加交换分区(swap)的方法. 第一种方法:新建分区 1.fd ...
- JAVA 中两种判断输入的是否是数字的方法__正则化_
JAVA 中两种判断输入的是否是数字的方法 package t0806; import java.io.*; import java.util.regex.*; public class zhengz ...
- 两种常用的jquery事件加载的方法 的区别
两种常用的jquery事件加载的方法 $(function(){}); window.onload=function(){} 第一个呢,是在DOM结构渲染完成以后调用的,这时候网页中一些资源还 ...
- Android中两种设置全屏或者无标题的方法
在开发中我们经常需要把我们的应用设置为全屏或者不想要title, 这里是有两种方法的,一种是在代码中设置,另一种方法是在配置文件里改: 一.在代码中设置: package jason.tutor; i ...
- JSONP和CORS两种跨域方式的优缺点及使用方法原理介绍
随着软件开发分工趋于精细,前后端开发分离成为趋势,前端同事负责前端页面的展示及页面逻辑处理,服务端同事负责业务逻辑处理同时通过API为前端提供数据也为前端提供数据的持久化能力,考虑到前后端同事开发工具 ...
- 两种解决IE6不支持固定定位的方法
有两种让IE6支持position:fixed1.用CSS执行表达式 *{margin:0;padding:0;} * html,* html body{ background-image:url(a ...
- 两种从 TensorFlow 的 checkpoint生成 frozenpb 的方法
1. 从 ckpt-.data,ckpt-.index 和 .meta 生成 frozenpb import os import tensorflow as tf from tensorflow.py ...
- Django—Form两种解决表单数据无法动态刷新的方法
一.无法动态更新数据的实例 1. 如下,数据库中创建了班级表和教师表,两张表的对应关系为“多对多” from django.db import models class Classes(models. ...
- 【Django】Django—Form两种解决表单数据无法动态刷新的方法
一.无法动态更新数据的实例 1. 如下,数据库中创建了班级表和教师表,两张表的对应关系为“多对多” from django.db import models class Classes(models. ...
随机推荐
- protected关键字对父子成员变量的影响
include<iostream> #include<string> using namespace std; class parent{ protected: int mv; ...
- ubuntu12.04 串口登录系统配置
原文转自:http://blog.csdn.net/g__gle/article/details/8663239 1) Create a file called /etc/init/ttyS0.con ...
- DedeCms 首页、列表页调用文章body内容的方法
[第一种方法] arclist标签使用如下: {dede:arclist row='1' typeid='1' addfields='body' idlist='1' channelid='1'} [ ...
- YAML语法:
1.基本语法 k:(空格)v:表示一对键值对(空格必须有): 以空格的缩进来控制层级关系:只要是左对齐的一列数据,都是同一个层级的 server: port: 8081 path: /hello 属性 ...
- Apache(httpd)详解
httpd详解(思维导图) 1. httpd服务 ASF 服务器类型 http服务器 应用程序服务器 httpd的特性 高度模块化 DSO机制 MPM httpd的并发响应模型 prefork wor ...
- JSR133提案-修复Java内存模型
目录 1. 什么是内存模型? 2. JSR 133是关于什么的? 3. 再谈指令重排序 4.同步都做了什么? 5. final字段在旧的内存模型中为什么可以改变? 6."初始化安全" ...
- 用OpenPyXL处理Excel表格 - 向sheet读取、写入数据
假设一个名叫"模板"的excel表格里有四个sheet,名字分别是['平台', '制冷', '洗衣机', '空调'] 1.读取 from openpyxl import load_ ...
- zip矩阵转至
list01=[1,2,3,4] list02=["a","b","c","d"] for itme in zip(li ...
- Docker图形界面管理
之前都是使用命令行进行Docker的管理,这里简单介绍一下Docker的图形界面管理.之所以说简单介绍,是因为在生产环境都是集群,很少使用图形界面管理单台Docker主机,所以就演示记录一下,在个人测 ...
- v-forv-for指令的三种使用方法
1.迭代数组 <p v-for="(item,i) in list">id:{{item.id}}---名字:{{item.name}}---索引{{item.age} ...