scrapy 基础组件专题(三):爬虫中间件
一、爬虫中间件简介
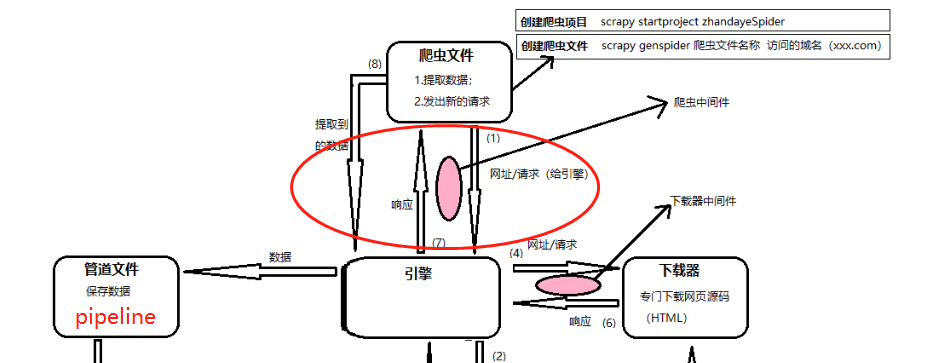
图 1-1

图 1-2
开始这一张之前需要先梳理一下这张图, 需要明白下载器中间件和爬虫中间件所在的位置
- 下载器中间件是在引擎(ENGINE)将请求推送给下载器(DOWNLOADER)时会执行到的
- 当下载器(DOWNLOADER)完成下载后, 将下载的Response对象传回给引擎(ENGLIE)时也会经过下载器中间件
- 当爬虫(SPIDER)把任务给引擎(ENGINE)的时候, 会经过爬虫中间件
- 当引擎(ENGINE)把数据传回给爬虫(SPIDER)的时候, 会经过爬虫中间件
此外:
图1-2中,4、5表示下载器中间件,6、7表示爬虫中间件。爬虫中间件会在以下几种情况被调用。
- 当运行到
yield scrapy.Request()或者yield item的时候,爬虫中间件的process_spider_output()方法被调用。 - 当爬虫本身的代码出现了
Exception的时候,爬虫中间件的process_spider_exception()方法被调用。 - 当爬虫里面的某一个回调函数
parse_xxx()被调用之前,爬虫中间件的process_spider_input()方法被调用。 - 当运行到
start_requests()的时候,爬虫中间件的process_start_requests()方法被调用。
所以, 下载器中间件是引擎和下载器之间处理数据所使用的, 爬虫中间件是爬虫和引擎之间处理数据时使用的
二、爬虫中间件类与方法
process_spider_input(response,spider)
当response通过spider中间件时,该方法被调用,处理该response。
应该返回一个None或者抛出一个异常(exception)。
- 如果其返回None,Scrapy将会继续处理该response,调用所有其他中间件直到spider处理该response。
- 如果其抛出一个异常(exception),Scrapy将不会调用任何其他中间件的process_spider_input()方法,并调用request的errback。errback的输出将会以另一个方向被输入到中间链中,使用
process_spider_output()方法来处理,当其抛出异常时则带调用process_spider_exception()。
参数:
response(Response对象) - 被处理的response
spider(Spider对象) - 该response对应的spider
process_spider_out(response, result, spider)
当Spider处理response返回result时,该方法被调用。(即spider处理response返回结果后)
process_spider_output()必须返回包含Request或Item对象的可迭代对象(iterable)。
response(Response对象) - 生成该输出的response
result(包含Reques或Item对象的可迭代对象(iterable)) - spider返回的result
spider(Spider对象) - 其结果被处理的spider
process_spider_exception(response, exception, spider)
当spider或(其它spider中间件的)process_spider_input()抛出异常时,该方法被调用
process_spider_exception()必须要么返回None,要么返回一个包含Response或Item对象的可迭代对象(iterable)。
通过其返回None,Scrapy将继续处理该异常,调用中间件链中的其它中间件的process_spider_exception()
如果其返回一个可迭代对象,则中间件链的process_spider_output()方法被调用,其他的process_spider_exception()将不会被调用。
参数:
response(Response对象) - 异常被抛出时被处理的response
exception(Exception对象) - 被抛出的异常
spider(Spider对象) - 抛出异常的spiderprocess_start_requests(start_requests, spider)
该方法以spider启动的request为参数被调用,执行的过程类似于process_spider_output(),只不过其没有相关联的response并且必须返回request(不是item)。
其接受一个可迭代的对象(start_requests参数)且必须返回一个包含Request对象的可迭代对象。
当在您的spider中间件实现该方法时,您必须返回一个可迭代对象(类似于参数start_requests)且不要遍历所有的start_requests。
该迭代器会很大(甚至是无限),进而导致内存溢出。
Scrapy引擎再其具有能力处理start_requests时将会拉起request,因此start_requests迭代器会变得无限,而由其它参数来停止spider(例如时间限制或者item/page计数)。
参数:
start_requests(b包含Request的可迭代对象)
- start requests
spider(Spider对象)
- start request所属的spider
三、编写自己的爬虫中间件
编写一个简单的爬虫, 实现两个需求
- 将所有返回的Response(响应)的响应码改为500
- 统计解析出来的item的数量
# spider.py
# -*- coding: utf-8 -*-
import scrapy
from ccidcom.items import CcidcomItem class CcidcomspiderSpider(scrapy.Spider):
name = 'ccidcomSpider' def start_requests(self):
self.logger.info('-----------spider.start_requests----------')
yield scrapy.Request('http://www.ccidcom.com/yaowen/index.html') def parse(self, response):
self.logger.info('--------spider.parse--------')
article_list = response.css('div.article-item')
for article in article_list:
item = CcidcomItem()
item['title'] = article.css('a font::text').get()
item['url'] = response.url
yield item def parse_baidu(self, response):
pass # items.py
import scrapy class CcidcomItem(scrapy.Item):
title = scrapy.Field()
url = scrapy.Field()
编写爬虫中间件
# middlewares.py
from scrapy import signals
from ccidcom.items import CcidcomItem class CcidcomSpiderMiddleware(object):
item_number = 0 ... def process_spider_input(self, response, spider):
spider.logger.info('--------spider_input-----------')
# 将响应码强制改为500
response.status = 500
return None def process_spider_output(self, response, result, spider):
spider.logger.info('--------spider_output-start-----------')
for i in result:
if type(i) == CcidcomItem:
self.item_number += 1
yield i
spider.logger.info('--------spider_output-end-----------')
spider.logger.info('item抓取到的数量:{}'.format(self.item_number)) def process_spider_exception(self, response, exception, spider):
pass def process_start_requests(self, start_requests, spider):
spider.logger.info('--------start_requests-----------')
for r in start_requests:
yield r
...
启用爬虫中间件
# settings.py
SPIDER_MIDDLEWARES = {
'ccidcom.middlewares.CcidcomSpiderMiddleware': 543,
}
执行的顺序
- 1.爬虫中间件的
process_start_requests方法 - 2.爬虫的
start_requests方法 - 3.爬虫中间件的
process_spider_input方法 - 4.爬虫中间件的
process_spider_output方法 - 5.爬虫的
parse方法 - 6.爬虫中间件的
process_spider_output方法
好像有点乱, 为啥process_spider_output会被运行了两次呢?而且还是第一次只输出了spider_output-start, 最后才输出了spider_output-end?
其实咱们跟着代码走一遍,就很好理解了
- 代码执行到了爬虫中间件的
process_start_requests方法, 输出了start_requests, 但是参数start_requests其实是spider的start_requests方法的生成器, 所以只有执行到for r in start_requests, 才真正开始执行spider的start_requests方法 - 交给下载器完成下载
- 下载后引擎将Response传给爬虫中间件的
process_spider_input方法 process_spider_input方法会调用process_spider_output方法, 并且将发起请求时Request的callback指定的方法, 变为process_spider_output的result参数, 这时也输出了spider_output-start- 当
process_spider_output方法运行到for i in result:时, 则真正开始执行Request对象指定的callback方法, 并且变为了生成器, yield回引擎 - 当
process_spider_output执行完result后, 就输出了spider_output-end.
以上就是整个爬虫中间件的运行流程。
# middlewares.py
from scrapy import signals
from ccidcom.items import CcidcomItem class CcidcomSpiderMiddleware(object):
item_number = 0 ... def process_spider_input(self, response, spider):
spider.logger.info('--------spider_input-----------')
# 将响应码强制改为500
response.status = 500
return None def process_spider_output(self, response, result, spider):
spider.logger.info('--------spider_output-start-----------')
for i in result:
if type(i) == CcidcomItem:
self.item_number += 1
yield i
spider.logger.info('--------spider_output-end-----------')
spider.logger.info('item抓取到的数量:{}'.format(self.item_number)) def process_spider_exception(self, response, exception, spider):
pass def process_start_requests(self, start_requests, spider):
spider.logger.info('--------start_requests-----------')
for r in start_requests:
yield r
...
scrapy 基础组件专题(三):爬虫中间件的更多相关文章
- scrapy 基础组件专题(八):scrapy-redis 框架分析
scrapy-redis简介 scrapy-redis是scrapy框架基于redis数据库的组件,用于scrapy项目的分布式开发和部署. 有如下特征: 分布式爬取 您可以启动多个spider工 ...
- scrapy 基础组件专题(一):scrapy框架中各组件的工作流程
Scrapy 使用了 Twisted 异步非阻塞网络库来处理网络通讯,整体架构大致如下(绿线是数据流向): Scrapy主要包括了以下组件: 引擎(Scrapy)用来处理整个系统的数据流处理, 触发事 ...
- scrapy 基础组件专题(七):scrapy 调度器、调度器中间件、自定义调度器
一.调度器 配置 SCHEDULER = 'scrapy.core.scheduler.Scheduler' #表示scrapy包下core文件夹scheduler文件Scheduler类# 可以通过 ...
- scrapy 基础组件专题(二):下载中间件
下载器中间件是介于Scrapy的request/response处理的钩子框架,是用于全局修改Scrapy request和response的一个轻量.底层的系统. 1.激活Downloader Mi ...
- scrapy 基础组件专题(九):scrapy-redis 源码分析
下面我们来看看,scrapy-redis的每一个源代码文件都实现了什么功能,最后如何实现分布式的爬虫系统: connection.py 连接得配置文件 defaults.py 默认得配置文件 dupe ...
- scrapy 基础组件专题(五):自定义扩展
通过scrapy提供的扩展功能, 我们可以编写一些自定义的功能, 插入到scrapy的机制中 一.编写一个简单的扩展 我们现在编写一个扩展, 统计一共获取到的item的条数我们可以新建一个extens ...
- scrapy 基础组件专题(四):信号运用
一.scrapy信号使用的简单实例 import scrapy from scrapy import signals from ccidcom.items import CcidcomItem cla ...
- scrapy 基础组件专题(十四):scrapy CookiesMiddleware源码
一 Scrapy框架--cookie的获取/传递/本地保存 1. 完成模拟登陆2. 登陆成功后提取出cookie,然后保存到本地cookie.txt文件中3. 再次使用时从本地的cookie.txt中 ...
- scrapy 基础组件专题(十二):scrapy 模拟登录
1. scrapy有三种方法模拟登陆 1.1直接携带cookies 1.2找url地址,发送post请求存储cookie 1.3找到对应的form表单,自动解析input标签,自动解析post请求的u ...
随机推荐
- CSS里盒子模型中【margin垂直方向边界叠加】问题及解决方案
边界重叠是指两个或多个盒子(可能相邻也可能嵌套)的相邻边界(其间没有任何非空内容.补白.边框)重合在一起而形成一个单一边界. 两个或多个块级盒子的垂直相邻边界会重合. 如果都是正边界,结果的边界宽度是 ...
- [每日一题2020.06.16] leetcode双周赛T3 5423 找两个和为目标值且不重叠的子数组 DP, 前缀和
题目链接 给你一个整数数组 arr 和一个整数值 target . 请你在 arr 中找 两个互不重叠的子数组 且它们的和都等于 target .可能会有多种方案,请你返回满足要求的两个子数组长度和的 ...
- Java 多线程基础(九)join() 方法
Java 多线程基础(九)join 方法 一.join() 方法介绍 join() 定义 Thread 类中的,作用是:把指定的线程加入到当前线程,可以将两个交替执行的线程合并为顺序执行的线程.如:线 ...
- Domain Adaptive Faster R-CNN:经典域自适应目标检测算法,解决现实中痛点,代码开源 | CVPR2018
论文从理论的角度出发,对目标检测的域自适应问题进行了深入的研究,基于H-divergence的对抗训练提出了DA Faster R-CNN,从图片级和实例级两种角度进行域对齐,并且加入一致性正则化来学 ...
- css样式学习笔记
视频参见php中文网玉女心经视频教程 讲解的相当的清楚和明白 第1章 :css快速入门 1.1 什么是css 改变html框架的样式. 1.2 css的三种引入形式 第一种形式 ...
- TCP实战二(半连接队列、全连接队列)
TCP实验一我们利用了tcpdump以及Wireshark对TCP三次握手.四次挥手.流量控制做了深入的分析,今天就让我们一同深入理解TCP三次握手中两个重要的结构:半连接队列.全连接队列. 参考文献 ...
- 弹性盒模型中flex-grow 和flex的区别
在flex弹性盒模型体系中,flex-grow和flex都有对子元素进行放大的作用,但是这两个属性在放大时的计算方法不同,在使用时候要注意,使用正确的放大属性,从而达到自己想要的效果. 先来看下两个属 ...
- JDK8--08:Optional
在程序运行时,空指针异常应该是最常见的异常之一,因此JDK8提供了Optional来避免空指针异常. 首先说明JDK8新增的Optional及相关方法的使用 Optional的常用操作: Option ...
- MongoDB快速入门教程 (4.3)
4.3.Mongoose模块化 4.3.1.为什么要进行模块化拆分? 模块化拆分的目的是为了代码的复用,让整个项目的结构更加清晰,举个例子:当数据库中的集合变多的时候,例如有课程.订单.分类.教师等多 ...
- Vue 封装axios(四种请求)及相关介绍(十三)
Vue 封装axios(四种请求)及相关介绍 首先axios是基于promise的http库 promise是什么? 1.主要用于异步计算 2.可以将异步操作队列化,按照期望的顺序执行,返回符合预期的 ...