数据可视化之DAX篇(十九)值得你深入了解的函数:SUMMARIZE
https://zhuanlan.zhihu.com/p/66424209
SUMMARIZE函数非常强大,掌握以后表面上看也非常好用,所以我专门写篇文章介绍一下这个函数,至于是否一定要使用该函数,请看完再决定。
SUMMARIZE,单纯从英文语义上看,是汇总、总结的意思,而它的功能,确实也就是汇总,它可以返回一个汇总表。
你可以从官方的文档中查询到该函数的说明,
https://docs.microsoft.com/en-us/dax/summarize-function-dax
它的参数非常复杂和难以理解,参数很多,并且有些参数都是可选的、可重复的。直接靠文档不容易理解,我们可以根据实例来理解它的用法。
它的参数很多是可选的,让我们按参数由少到多逐步看看它的功能。
01 | 提取不重复值
以下表达式,会提取不重复的产品名称:
维度表1 = SUMMARIZE('订单','订单'[产品名称])
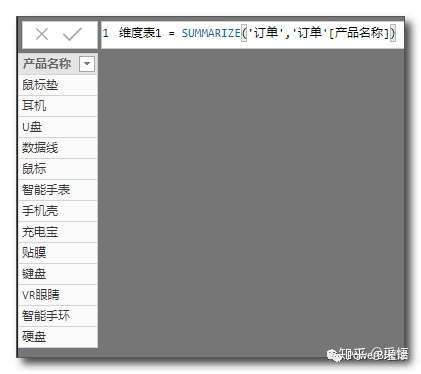
SUMMARIZE函数的第一个参数是表,第二个参数是列时,会返回该列的不重复列表,其功能与VALUES相似。
不过SUMMARIZE函数还可以继续添加第三个、第四个参数列…,看以下表达式的返回结果,
维度表2 = SUMMARIZE('订单','订单'[产品名称],'日期表'[年度])
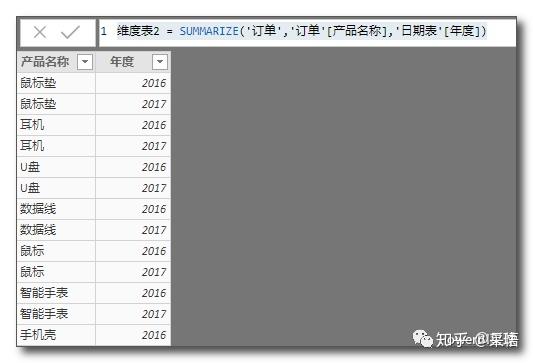
SUMMARIZE参数表后面跟多个列时,它会返回这些列的有效组合,类似于笛卡尔积,与笛卡尔积稍微不同的是,如果在订单表中不存在这个组合,则返回的列表中,就不会出现这一行。
举个例子,假如2016年如果没有卖过智能手表,则上述的表达式不会有2016 智能手表这一行。
02 | 返回汇总表
在上述表达式的基础上,我们继续添加参数如下:
汇总表1 =
SUMMARIZE(
'订单',
'日期表'[年度],
'订单'[产品名称],
"销售额合计",SUM('订单'[销售额])
)
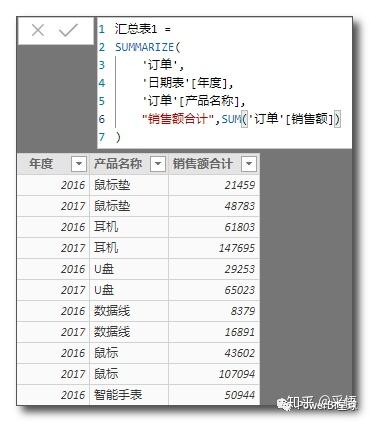
SUMMARIZE参数后面带上列名和表达式时,它会自动计算并返回分组的汇总表,这才是该函数的本质功能,也切合它的字面意义。
这个功能非常好用,也是我们使用它最普遍的地方。
03 | 返回带合计的汇总表
这是SUMMARIZE的高级功能,在上面的表达式中的分组列外面套一层ROLLUP,看看是什么效果?
汇总表2 =
SUMMARIZE(
'订单',
ROLLUP('日期表'[年度],'订单'[产品名称]),
"销售额合计",SUM('订单'[销售额])
)
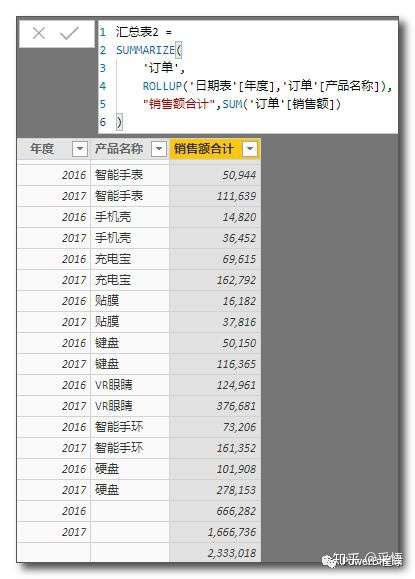
看到在汇总表的下面还多了几行合计数,这就是ROLLUP参数的作用。它只在SUMMARIZE内部使用,用于为子类别计算小计和总计。
SUMMARIZE内部还可以使用一个参数是ROLLUPGROUP,使用ROLLUPGROUP代替上面表达式中的ROLLUP,可以返回相同的结果。
不过如果在上面表达式ROLLUP里面再套一层ROLLUPGROUP,
汇总表3 =
SUMMARIZE(
'订单',
ROLLUP(ROLLUPGROUP('日期表'[年度],'订单'[产品名称])),
"销售额合计",SUM('订单'[销售额])
)
分组的小计不见了,只返回了总计, ROLLUP和ROLLUPGROUP组合可以避免出现小计,而只返回总计。这样使汇总表看起来更像是Excel中的透视表。
关于ROLLUP和ROLLUPGROUP参数,其实它们的合计功能并不常用,但是却导致很多人觉得SUMMARIZE很复杂,你如果也是这种感觉,完全可以不用深究这两个参数的用法,因为你基本上也不会用到它们。
SUMMARIZE最常用的还是上面的第二种功能,让我们回头再来看看这种用法,返回一个汇总表确实非常实用,但是这是最优的写法吗?
使用ADDCOLUMNS返回汇总表
02示例中的表达式,还可以用以下表达式代替,
汇总表4 =
ADDCOLUMNS(
SUMMARIZE(
'订单',
‘日期表'[年度],
'订单'[产品名称]
),
"销售额合计",CALCULATE(SUM('订单'[销售额]))
)
即通过ADDCOLUMNS函数,在SUMMARIZE生成分组的基础上添加列,来计算销售额汇总,可以返回相同的结果,但是在性能上,要比单纯的使用SUMMARIZE更优。
SUMMARIZE函数由于性能和内部兼容性等方面的原因,并不建议使用它来进行汇总,可以使用上面的ADDCOLUMNS和SUMMARIZE组合来代替,另外还有个新函数性能更优:SUMMARIZECOLUMNS。
使用SUMMARIZECOLUMNS返回汇总表
依然是生成上面的汇总表,SUMMARIZECOLUMNS的写法:
汇总表5 =
SUMMARIZECOLUMNS(
'日期表'[年度],
'订单'[产品名称],
"销售额合计",CALCULATE(SUM('订单'[销售额]))
)
是不是看起来更加简洁,它的第一个参数不再需要表,而是直接是分组列,实践上看,它的性能要优于ADDCOLUMNS和SUMMARIZE组合,当然也远优于SUMMARIZE,生成汇总表时建议直接用SUMMARIZECOLUMNS(关于性能,你可以使用DAX Studio进行测试)。
SUMMARIZECOLUMNS应该就是为了替代SUMMARIZE而出现的,它可以实现SUMMARIZE的功能;SUMMARIZE的内部参数,比如ROLLUPGROUP等,SUMMARIZECOLUMNS同样也有,并且还有更多其他内部参数可以调用,不过对于普通DAX使用者来说,可能并不会使用到,就不再介绍了,想深入理解的请自行查阅该函数文档。
总结
- 提取多列的有效组合时,可以使用SUMMARIZE
- 返回汇总表时,推荐使用SUMMARIZECOLUMNS
数据可视化之DAX篇(十九)值得你深入了解的函数:SUMMARIZE的更多相关文章
- 数据可视化之DAX篇(一)Power BI时间智能函数如何处理2月29日的?
https://zhuanlan.zhihu.com/p/109964336 今年是闰年,有星友问我,在Power BI中,2月29日的上年同期是怎么计算的? 这是个好问题,正好梳理一下,Power ...
- 数据可视化之DAX篇(九) 关于DAX中的VAR,你应该避免的一个常见错误
https://zhuanlan.zhihu.com/p/67803111 本文源于微博上一位朋友的问题,在计算同比增长率时,以下两种DAX代码有什么不同? -------------------- ...
- 数据可视化之DAX篇(十六)如何快速理解一个复杂的DAX?这个方法告诉你
https://zhuanlan.zhihu.com/p/64422393 经常有朋友提出一个问题,然后我给出一个DAX之后,TA又不是很理解,反复多次沟通才能把一个表达式讲清楚.或者TA自己写了一个 ...
- 数据可视化之DAX篇(十)在PowerBI中累计求和的两种方式
https://zhuanlan.zhihu.com/p/64418286 假设有一组数据, 已知每一个产品贡献的利润,如果要计算前几名产品的贡献利润总和,或者每一个产品和利润更高产品的累计贡献占总体 ...
- 数据可视化之DAX篇(二十)Think in DAX 之报表自动化实践
https://zhuanlan.zhihu.com/p/107672198 本文来自星友袁佳林的实践分享,他参加了PowerBI星球中的DAX圣经第二版100天学习打卡活动,已持续分享近100天, ...
- 数据可视化之DAX篇(十五)Power BI按表筛选的思路
https://zhuanlan.zhihu.com/p/121773967 数据分析就是筛选.分组.聚合的过程,关于筛选,可以按一个维度来筛选,也可以按多个维度筛选,还有种常见的方式是,利用几个特 ...
- 数据可视化之DAX篇(十四)DAX函数:RELATED和RELATEDTABLE
https://zhuanlan.zhihu.com/p/64421378 Excel中知名度最高的函数当属VLOOKUP,它的确很有用,可以在两个表之间进行匹配数据,使工作效率大大提升,虽然它也有很 ...
- 数据可视化之DAX篇(十二)掌握时间智能函数,同比环比各种比,轻松搞定!
https://zhuanlan.zhihu.com/p/55841964 时间可以说是数据分析中最常用的独立变量,工作中也常常会遇到对时间数据的对比分析.假设要计算上年同期的销量,在PowerBI中 ...
- 数据可视化之DAX篇(二十八)Power BI时间序列分析用到的度量值,一次全给你
https://zhuanlan.zhihu.com/p/88528732 在各种经营分析报告中,我们常常会看到YTD,YOY这样的统计指标,这样的数据计算并不难,尤其是在PowerBI中,因为有时间 ...
随机推荐
- Clear Writer v1.8 更新
拖更了这么久之后,Clear Writer 诈尸啦(bushi 下载链接:https://linhongping.lanzous.com/ikF2Udmf7if Clear Writer v1.8 更 ...
- excel如何快速统计出某一分类的最大值?
问题:如何统计出某一分类的最大值? 解答:利用分类汇总或透视表快速搞定! 思路1:利用分类汇总功能 具体操作方法如下: 选中数据区任意一个单元格,然后点击“数据-分类汇总”按钮.(下图 1 处). 在 ...
- LeetCode 77,组合挑战,你能想出不用递归的解法吗?
本文始发于个人公众号:TechFlow,原创不易,求个关注 今天是LeetCode第46篇文章,我们一起来LeetCode中的77题,Combinations(组合). 这个题目可以说是很精辟了,仅仅 ...
- Homebrew命令总结
brew又叫homebrew,是macos上的一个包管理工具,能够在mac中方便的进行包管理,类似于ubuntu系统下的apt-get,记得自己第一次接触brew是为了在mac上安装一个独立绿色的视频 ...
- 这一次搞懂Spring自定义标签以及注解解析原理
前言 在上一篇文章中分析了Spring是如何解析默认标签的,并封装为BeanDefinition注册到缓存中,这一篇就来看看对于像context这种自定义标签是如何解析的.同时我们常用的注解如:@Se ...
- 7.kubernetes集群版本升级
1.查看原集群的Node节点的版本号 [root@hdss7-22 opt]# kubectl get node -o wide 2.将要升级的kubernetes版本上传到node节点上并解压(v1 ...
- Spring Boot 分离资源文件打包
Spring Boot项目默认的会打包成单一的jar文件,但是有时候我们并不想让配置文件.依赖包都跟可执行文件打包到一起.这时候可以在pom.xml文件中进行配置,从而使资源文件.依赖包和可执行文件分 ...
- powershell代码混淆绕过
目前大多数攻击者已经将PowerShell 利用在了各种攻击场景中,如内网渗透,APT攻击甚至包括现在流行的勒索软件中.powershell的功能强大且调用方式十分灵活,灵活使用powershell可 ...
- 线程间配合:Condition、Semaphore、CountDownLatch、CyclicBarrier
1 重入锁的好搭档:Condition条件 如果大家理解了Object.wait()和Object.notify()方法的话,那么就能很容易理解Condition接口了.它和wait()和notify ...
- MongoDB副本集replica set (二)--副本集环境搭建
(一)主机信息 操作系统版本:centos7 64-bit 数据库版本 :MongoDB 4.2 社区版 ip hostname 192.168.10.41 mongoserver1 192.16 ...