Kaggle-pandas(3)
Summary-functions-and-maps
教程
在上一教程中,我们学习了如何从DataFrame或Series中选择相关数据。 正如我们在练习中所展示的,从我们的数据表示中提取正确的数据对于完成工作至关重要。
但是,数据并非总是以我们想要的格式从内存中出来的。 有时,我们必须自己做一些工作以将其重新格式化以解决当前的任务。 本教程将介绍我们可以应用于数据以获取“恰到好处”输入的各种操作。
Pandas提供了许多简单的“摘要功能”(不是官方名称),它们以某种有用的方式重组了数据。 例如,考虑一下describe()方法:
reviews.points.describe()
Output:
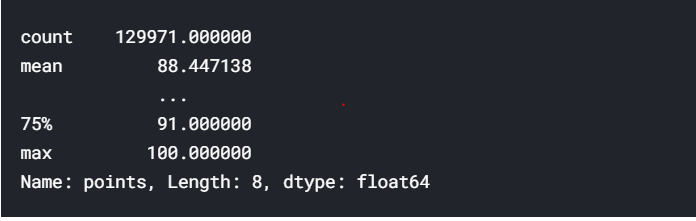
此方法生成给定列的属性的高级摘要。 它可识别类型,这意味着其输出根据输入的数据类型而变化。 上面的输出仅对数字数据有意义; 对于字符串数据,这是我们得到的:
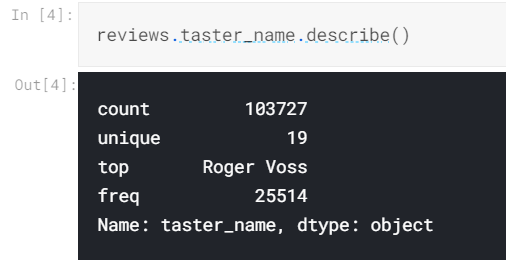
如果要获取有关DataFrame或Series中某一列的某些特定的简单摘要统计信息,通常有一个有用的pandas函数可以实现此目的。
例如,要查看分配的分数的平均值(例如,平均评级的葡萄酒表现如何),我们可以使用mean()函数:
reviews.points.mean()
要查看唯一值的列表,我们可以使用unique()函数:
reviews.taster_name.unique()
要查看唯一值的列表以及它们在数据集中出现的频率,我们可以使用value_counts()方法:
reviews.taster_name.value_counts()
Maps
映射是一个从数学中借来的术语,表示一个函数,该函数采用一组值并将它们“映射”到另一组值。 在数据科学中,我们经常需要根据现有数据创建新的表示形式,或者将数据从现在的格式转换为我们希望其在以后使用的格式。 地图是处理这项工作的要素,这对完成工作极为重要!
您将经常使用两种映射方法。
map()是第一个,并且稍微简单一些。 例如,假设我们想将收到的葡萄酒的分数修正为0。我们可以这样做:
review_points_mean = reviews.points.mean()
reviews.points.map(lambda p: p - review_points_mean)
传递给map()的函数应该期望Series中的单个值(在上面的示例中为点值),并返回该值的转换版本。 map()返回一个新的Series,其中所有值都已由您的函数转换。
如果我们要通过在每一行上调用自定义方法来转换整个DataFrame,则apply()是等效的方法。
如:
def remean_points(row):
row.points = row.points - review_points_mean
return row reviews.apply(remean_points, axis='columns')
如果我们使用axis ='index'调用了reviews.apply(),则需要传递一个函数来转换每一列,而不是传递函数来转换每一行。
请注意,map()和apply()分别返回新的,转换后的Series和DataFrames。 他们不会修改被调用的原始数据。 如果我们查看评论的第一行,我们可以看到它仍然具有其原始积分值。
练习
1.
What is the median of the points column in the reviews DataFrame?
median_points = reviews["points"].median() # Check your answer
q1.check()
2.
What countries are represented in the dataset? (Your answer should not include any duplicates.)
countries = reviews["country"].unique() # Check your answer
q2.check()
3.
How often does each country appear in the dataset? Create a Series reviews_per_country mapping countries to the count of reviews of wines from that country.
reviews_per_country = reviews["country"].value_counts ()
print(reviews_per_country)
# Check your answer
q3.check()
4.
Create variable centered_price containing a version of the price column with the mean price subtracted.
(Note: this 'centering' transformation is a common preprocessing step before applying various machine learning algorithms.)
mid=reviews["price"].mean()
centered_price = reviews["price"].map(lambda x: x-mid) # Check your answer
q4.check()
5.
I'm an economical wine buyer. Which wine is the "best bargain"? Create a variable bargain_wine with the title of the wine with the highest points-to-price ratio in the dataset.
bargain_idx = (reviews.points / reviews.price).idxmax()
bargain_wine = reviews.loc[bargain_idx, 'title']
# Check your answer
q5.check()
6.
There are only so many words you can use when describing a bottle of wine. Is a wine more likely to be "tropical" or "fruity"? Create a Series descriptor_counts counting how many times each of these two words appears in the description column in the dataset.
n_trop = reviews.description.map(lambda desc: "tropical" in desc).sum()
n_fruity = reviews.description.map(lambda desc: "fruity" in desc).sum()
descriptor_counts = pd.Series([n_trop, n_fruity], index=['tropical', 'fruity'])
print(descriptor_counts)
# Check your answer
q6.check()
7.
We'd like to host these wine reviews on our website, but a rating system ranging from 80 to 100 points is too hard to understand - we'd like to translate them into simple star ratings. A score of 95 or higher counts as 3 stars, a score of at least 85 but less than 95 is 2 stars. Any other score is 1 star.
Also, the Canadian Vintners Association bought a lot of ads on the site, so any wines from Canada should automatically get 3 stars, regardless of points.
Create a series star_ratings with the number of stars corresponding to each review in the dataset.
def help(row):
if(row["country"]=="Canada"):
return 3
if(row["points"]>=95):
return 3
elif(row["points"]>=85):
return 2
else:
return 1 star_ratings = reviews.apply(help,axis='columns') print(star_ratings) # Check your answer
q7.check()
Kaggle-pandas(3)的更多相关文章
- 由Kaggle竞赛wiki文章流量预测引发的pandas内存优化过程分享
pandas内存优化分享 缘由 最近在做Kaggle上的wiki文章流量预测项目,这里由于个人电脑配置问题,我一直都是用的Kaggle的kernel,但是我们知道kernel的内存限制是16G,如下: ...
- kaggle入门2——改进特征
1:改进我们的特征 在上一个任务中,我们完成了我们在Kaggle上一个机器学习比赛的第一个比赛提交泰坦尼克号:灾难中的机器学习. 可是我们提交的分数并不是非常高.有三种主要的方法可以让我们能够提高他: ...
- Kaggle入门教程
此为中文翻译版 1:竞赛 我们将学习如何为Kaggle竞赛生成一个提交答案(submisson).Kaggle是一个你通过完成算法和全世界机器学习从业者进行竞赛的网站.如果你的算法精度是给出数据集中最 ...
- 如何使用Python在Kaggle竞赛中成为Top15
如何使用Python在Kaggle竞赛中成为Top15 Kaggle比赛是一个学习数据科学和投资时间的非常的方式,我自己通过Kaggle学习到了很多数据科学的概念和思想,在我学习编程之后的几个月就开始 ...
- kaggle数据挖掘竞赛初步--Titanic<原始数据分析&缺失值处理>
Titanic是kaggle上的一道just for fun的题,没有奖金,但是数据整洁,拿来练手最好不过啦. 这道题给的数据是泰坦尼克号上的乘客的信息,预测乘客是否幸存.这是个二元分类的机器学习问题 ...
- kaggle& titanic代码
这两天报名参加了阿里天池的’公交线路客流预测‘赛,就顺便先把以前看的kaggle的titanic的训练赛代码在熟悉下数据的一些处理.题目根据titanic乘客的信息来预测乘客的生还情况.给了titan ...
- 初窥Kaggle竞赛
初窥Kaggle竞赛 原文地址: https://www.dataquest.io/mission/74/getting-started-with-kaggle 1: Kaggle竞赛 我们接下来将要 ...
- 逻辑回归应用之Kaggle泰坦尼克之灾(转)
正文:14pt 代码:15px 1 初探数据 先看看我们的数据,长什么样吧.在Data下我们train.csv和test.csv两个文件,分别存着官方给的训练和测试数据. import pandas ...
- kaggle之Grupo Bimbo Inventory Demand
Grupo Bimbo Inventory Demand kaggle比赛解决方案集合 Grupo Bimbo Inventory Demand 在这个比赛中,我们需要预测某个产品在某个销售点每周的需 ...
- kaggle之人脸特征识别
Facial_Keypoints_Detection github code facial-keypoints-detection, 这是一个人脸识别任务,任务是识别人脸图片中的眼睛.鼻子.嘴的位置. ...
随机推荐
- 执行ArrayList的remove(object)方法抛异常?
简介 或许有很多小伙伴都尝试过如下的代码: ArrayList<Object> list = ...; for (Object object : list) { if (条件成立) { l ...
- Ubuntu下编译安装postgreSQL 10.5
Ubuntu下编译安装postgreSQL 10.5 ubuntu 16.04 LTS系统postgreSQL 10.5 安装包准备 1.从PostgreSQL官网下载PostgreSQL的安装包 安 ...
- 02-Python运算符
一.简介 以10 - 5为例,‘10 - 5’叫做表达式,表达式可以分解成运算符和操作数.整数10和5被称为操作数.‘-’称为运算符. 二.算术运算符 运算符 描述 示例 结果 + 加 - 两个对象相 ...
- (6)webpack使用babel插件的使用
为什么要使用babel插件? 首先要了解babel插件是干嘛的,随着js的语法规范发展,出现了越来越多的高级语法,但是使用webpack打包的时候,webpack并不能全部理解这些高级语法,需要我们使 ...
- 尝鲜刚发布的 SpringFox 3.0.0,以前造的轮子可以不用了...
最近 SpringFox 3.0.0 发布了,距离上一次大版本2.9.2足足有2年多时间了.可能看到这个名字,很多读者会有点陌生.但是,只要给大家看一下这两个依赖,你就知道了! <depende ...
- STL Queue(队列)学习笔记 + 洛谷 P1540 机器翻译
队(Queue) 队简单来说就是一个先进先出的“栈”,但是不同于标准“栈”的先进后出. 基本操作: push(x) 将x压入队列的末端 pop() 弹出队列的第一个元素(队顶元素),注意此函数并不返回 ...
- 用windbg查看dmp文件,定位bug位置
windbg + .dmp + .pdb + 源代码,可以看到是哪个代码崩溃的 设置符号文件所在路径 File->Symbol File Path... 在输入框中填入.pdb文件所在的文件夹路 ...
- for循环实现Fibonacci数列
Fibonacci数列的递推公式为:Fn=Fn-1+Fn-2,其中F1=F2=1. 当n比较大时,Fn也非常大,现在我们想知道,Fn除以10007的余数是多少. 输入格式 输入包含一个整数n. 输出格 ...
- 如何用Excel进行预测分析?
[面试题] 一个社交APP, 它的新增用户次日留存.7日留存.30日留存分别是52%.25%.14%. 请模拟出来,每天如果日新增6万用户,那么第30天,它的日活数会达到多少?请使用Excel进行 ...
- float对内联元素和块元素的影响
写在前面:附一篇w3s的关于css float的讲解:http://www.w3school.com.cn/css/css_positioning_floating.asp float属性还没有彻底了 ...