Go 语言网络库 getty 的那些事
简介: Getty 维护团队不追求无意义的 benchmark 数据,不做无意义的炫技式优化,只根据生产环境需求来进行自身改进。只要维护团队在,Getty 稳定性和性能定会越来越优秀。
个人从事互联网基础架构系统研发十年余,包括我自己在内的很多朋友都是轮子党。
2011 年我在某大厂干活时,很多使用 C 语言进行开发的同事都有一个自己的私人 SDK 库,尤其是网络通信库。个人刚融入这个环境时,觉得不能写一个基于 epoll/iocp/kqueue 接口封装一个异步网络通信库,会在同事面前矮人三分。现在想起来当时很多同事很大胆,把自己封装的通信库直接在测试生产环境上线使用,据说那时候整个公司投入生产环境运行的 RPC 通信库就有 197 个之多。
个人当时耗费两年周末休息时间造了这么一个私人 C 语言 SDK 库:大部分 C++ STL 容器的 C 语言实现、定时器、TCP/UDP 通信库、输出速度可达 150MiB/s 的日志输出库、基于 CAS 实现的各种锁、规避了 ABA 问题的多生产者多消费者无锁队列 等等。自己当时不懂 PHP,其实稍微封装下就可以做出一个类似于 Swoole 的框架。如果一直坚持写下来,可能它也堪媲美老朋友郑树新老师的 ACL 库了。
自己 2014 年开始接触 Go 语言,经过一段时间学习之后,发现了它有 C 语言一样的特点:基础库太少 -- 又可以造轮子了。我清晰地记得自己造出来的第一个轮子每个 element 只使用一个指针的双向链表 xorlist【见参考 1】。
2016 年 6 月我在做一个即时通讯项目时,原始网关是一个基于 netty 实现的 Java 项目,后来使用 Go 语言重构时其 TCP 网路库各个接口实现就直接借鉴了 netty。同年 8 月份在其上添加了 websocket 支持时,觉得 websocket提供的 onopen/onclose/onmessage 网络接口极其方便,就把它的网络接口改为 OnOpen/OnClose/OnMessage/OnClose ,把全部代码放到了 github 上,并在小范围内进行了宣传【见参考 2】。
Getty 分层设计
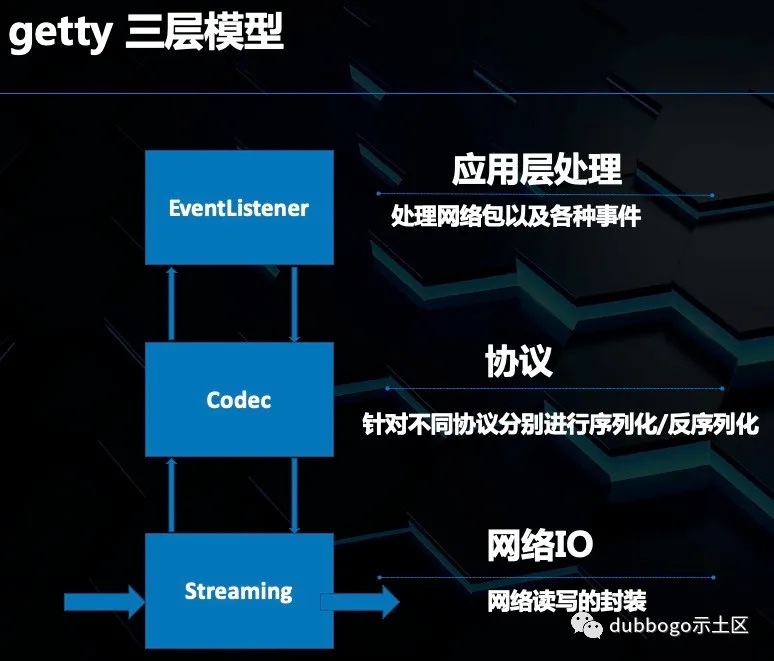
Getty 严格遵循着分层设计的原则。主要分为数据交互层、业务控制层、网络层,同时还提供非常易于扩展的监控接口,其实就是对外暴露的网络库使用接口。
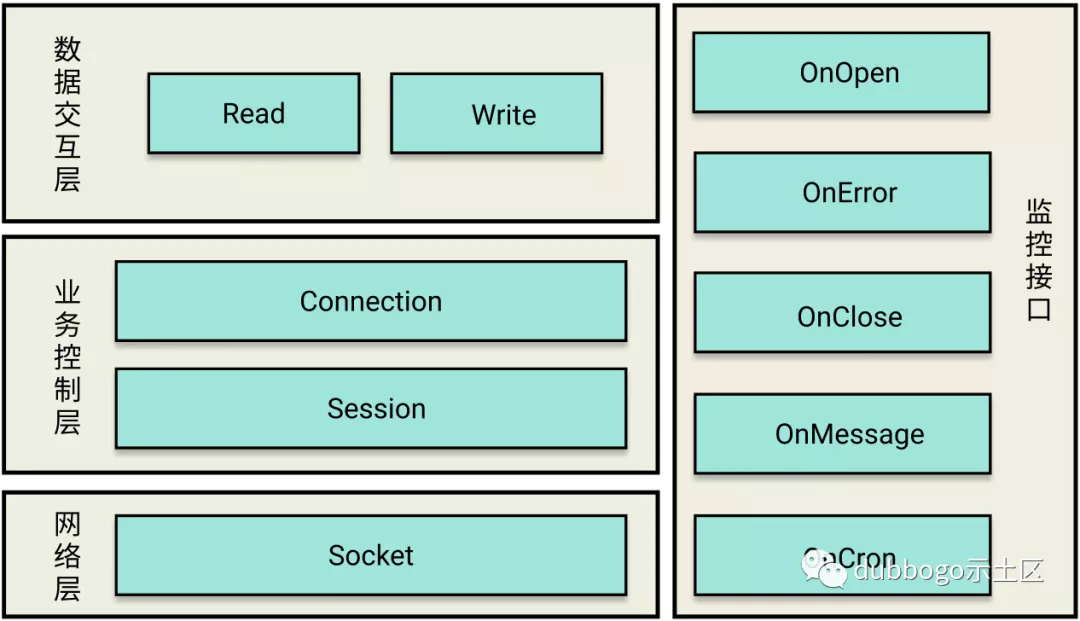
1、数据交互层
很多人提供的网络框架自己定义好了网络协议格式,至少把网络包头部格式定义好,只允许其上层使用者在这个头部以下做扩展,这就限制了其使用范围。Getty 不对上层协议格式做任何假设,而是由使用者自己定义,所以向上提供了数据交互层。
就其自身而言,数据交互层做的事情其实很单一,专门处理客户端与服务器的数据交互,是序列化协议的载体。使用起来也非常简单,只要实现 ReadWriter interface 即可。
Getty 定义了 ReadWriter 接口,具体的序列化/反序列化逻辑 则交给了用户手动实现。当网络连接的一端通过 net.Conn 读取到了 peer 发送来的字节流后,会调用 Read 方法进行反序列化。而 Writer 接口则是在网络发送函数中被调用,一个网络包被发送前,Getty 先调用 Write 方法将发送的数据序列化为字节流,再写入到 net.Conn 中。

ReadWriter 接口定义代码如上。Read 接口之所以有三个返回值,是为了处理 TCP 流粘包情况:
- 如果发生了网络流错误,如协议格式错误,返回 (nil, 0, error)- 如果读到的流很短,其头部 (header) 都无法解析出来,则返回 (nil, 0, nil)- 如果读到的流很短,可以解析出其头部 (header) 但无法解析出整个包 (package),则返回 (nil, pkgLen, nil)- 如果能够解析出一个完整的包 (package),则返回 (pkg, 0, error)
2、业务控制层
业务控制层是 Getty 设计的精华所在,由 Connection 和 Session 组成。
- Connection
负责建立的 Socket 连接的管理,主要包括:连接状态管理、连接超时控制、连接重连控制、数据包的相关处理,如数据包压缩、数据包拼接重组等。
- Session
负责客户端的一次连接建立的管理、记录着本次连接的状态数据、管理 Connection 的创建、关闭、控制数据的发送/接口的处理。
2.1 Session
Session 可以说是 Getty 中最核心的接口了,每个 Session 代表着一次会话连接。
-向下
Session 对 Go 内置的网络库做了完善的封装,包括对 net.Conn 的数据流读写、超时机制等
- 向上
Session 提供了业务可切入的接口,用户只需实现 EventListener 就可以将 Getty 接入到自己的业务逻辑中。
目前 Session 接口的实现只有 session 结构体,Session 作为接口仅仅是提供了对外可见性以及遵循面向编程接口的机制,之后我们谈到 Session,其实都是在讲 session 结构体。
2.2 Connection
Connection 根据不同的通信模式对 Go 内置网络库进行了抽象封装,Connection 分别有三种实现:
- gettyTCPConn:底层是 *net.TCPConn
- gettyUDPConn:底层是 *net.UDPConn
- gettyWSConn:底层使用第三方库实现
2.3 网络 API 接口 EventListener
本文开头提到,Getty 网络 API 接口命名是从 WebSocket 网络 API 接口借鉴而来。Getty 维护者之一 郝洪范 同学喜欢把它称为 “监控接口”,理由是:网络编程最麻烦的地方当出现问题时不知道如何排查,通过这些接口可以知道每个网络连接在每个阶段的状态。
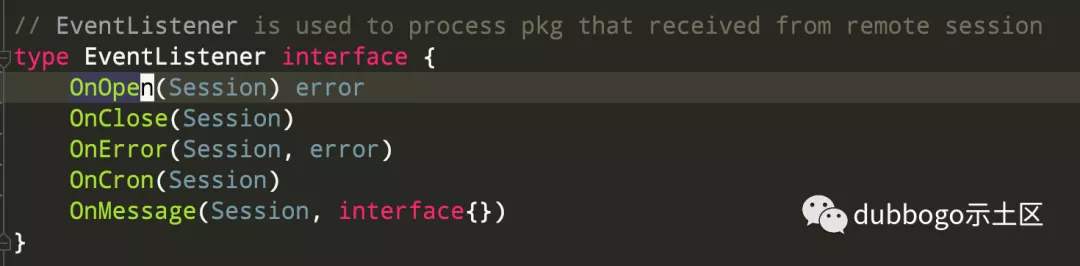
「OnOpen」:连接建立时提供给用户使用,若当前连接总数超过用户设定的连接数,则可以返回一个非 nil 的 error,Getty 就会在初始阶段关闭这个连接。「OnError」:用于连接有异常时的监控,Getty 执行这个接口后关闭连接。「OnClose」:用于连接关闭时的监控,Getty 执行这个接口后关闭连接。「OnMessage」:当 Getty 调用 Reader 接口成功从 TCP流/UDP/WebSocket 网络中解析出一个 package 后,通过这个接口把数据包交给用户处理。「OnCron」:定时接口,用户可以在这里接口函数中执行心跳检测等一些定时逻辑。
这五个接口中最核心的是 OnMessage,该方法有一个 interface{} 类型的参数,用于接收对端发来的数据。
可能大家有个疑惑,网络连接最底层传输的是二进制,到我们使用的协议层一般以字节流的方式对连接进行读写,那这里为什么要使用 interface{} 呢?
这是 Getty 为了让我们能够专注编写业务逻辑,将序列化和反序列化的逻辑抽取到了 EventListener 外面,也就是前面提到的 Reader/Writer 接口,session 在运行过程中,会先从 net.Conn 中读取字节流,并通过 Reader 接口进行反序列化,再将反序列化的结果传递给 OnMessage 方法。
如果想把对应的指标接入到 Prometheus,在这些 EventListener 接口中很容易添加各种 metrics 的收集。
Getty 网络端数据流程
下图是 Getty 核心结构的类图,囊括了整个 Getty 框架的设计。
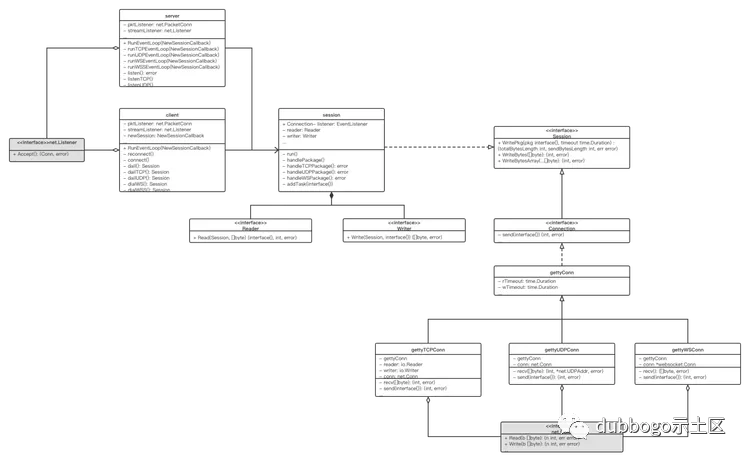
|说明:图中灰色部分为 Go 内置库
下面以 TCP 为例介绍下 Getty 如何使用以及该类图里各个接口或对象的作用。其中 server/client 是提供给用户使用的封装好的结构,client 的逻辑与 server 很多程度上一致,因此本章只讲 server。
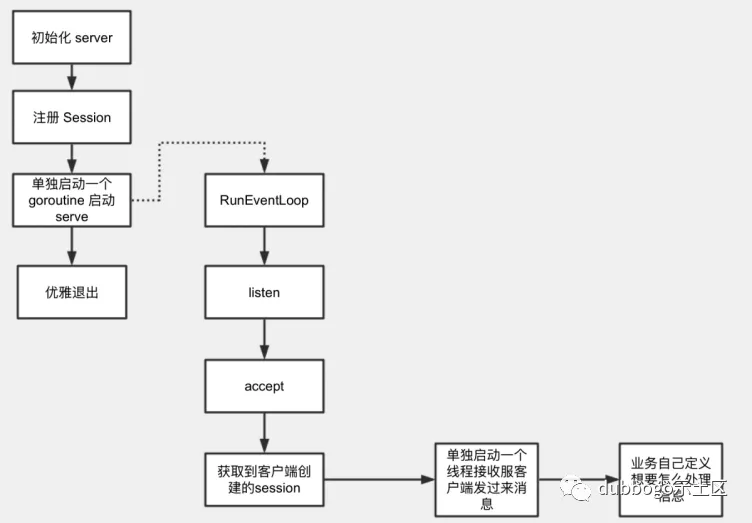
Getty server 启动代码流程图如上。在 Getty 中,server 服务的启动流程只需要两行代码:

第一行非常明显是一个创建 server 的过程,options 是一个 func (*ServerOptions) 函数,用于给 server 添加一些额外功能设置,如启用 ssl,使用任务队列提交任务的形式执行任务等。
第二行的server.RunEventLoop(NewHelloServerSession) 则是启动 server,同时也是整个 server 服务的入口,它的作用是监听某个端口(具体监听哪个端口可以通过 options 指定),并处理 client 发来的数据。RunEventLoop 方法需要提供一个参数 NewSessionCallback,该参数的类型定义如下:

这是一个回调函数,将在成功建立和 client 的连接后被调用,一般提供给用户用于设置网络参数,如设置连接的 keepAlive 参数、缓冲区大小、最大消息长度、read/write 超时时间等,但最重要的是,用户需要通过该函数,为 session 设置好要用的 Reader、Writer 以及 EventListener。
至此,Getty 中 server 的处理流程大体如下图:
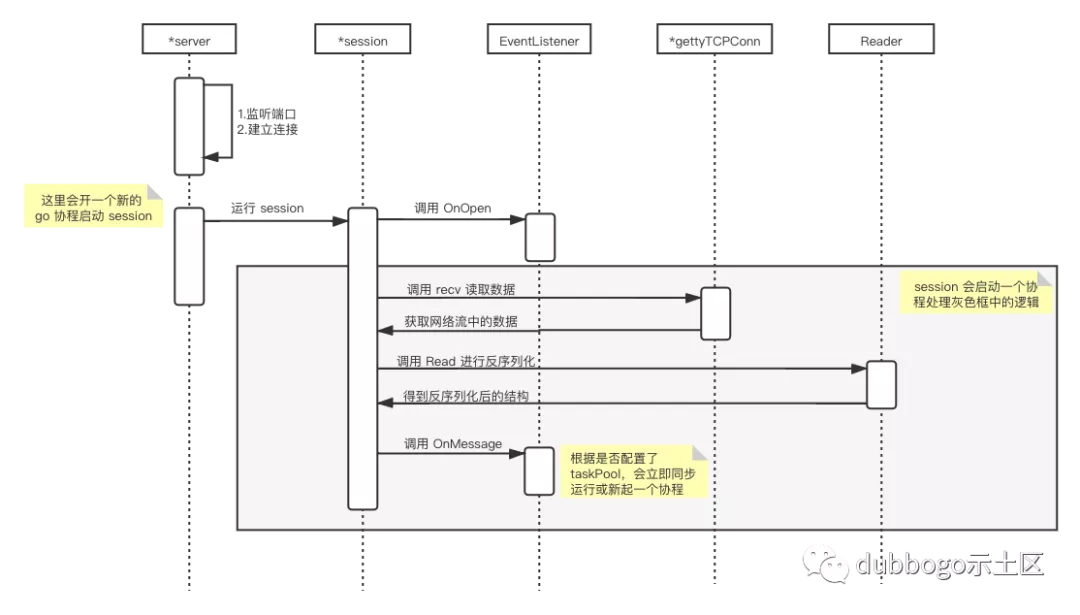
对于这些接口的使用,除了 getty 自身提供的代码示例外,另一篇极好的例子就是 seata-golang,感兴趣的朋友可参阅 《分布式事务框架 seata-golang 通信模型》一文【参考 6】。
优化
软件开发一条经验法则是:“Make it work, make it right, make it fast”,过早优化是万恶之源。
比较早期的一个例子是 erlang 的发明者 Joe Armstrong 早年花费了相当多的精力去熬夜加班改进 erlang 性能,其后果之一是他在后期发现早期做的一些优化工作很多是无用功,其二是过早优化损坏了 Joe 的健康,导致 2019 年在他 68 岁的年纪便挂掉了。
把时间单位拉长到五年甚至是十年,可能会发现早期所做的一些优化工作在后期会成为维护工作的累赘。2006 年时很多专家还在推荐大家只用 Java 做 ERP 开发,不要在互联网后台编程中使用 Java,理由是在当时的单核 CPU 机器上与 C/C++ 相比其性能确实不行,理由当然可以怪罪于其解释语言的本质和 JVM GC,但是 2010 年之后就几乎很少听见有人再抱怨其性能了。
2014 年在一次饭局上碰到支付宝前架构师周爱民老师,周老师当时还调侃道,如果支付宝把主要业务编程语言从 Java 切换到 C++,大概服务器数量可以省掉 2/3。
类比之,作为一个比 Java 年轻很多的新语言,Go 语言定义了一种编程范式,编程效率是其首要考虑,至于其程序性能尤其是网络 IO 性能,这类问题可以交给时间,五年之后当前大家抱怨的很多问题可能就不是问题了。如果程序真的遇到网络 IO 性能瓶颈且机器预算紧张,可以考虑换成更低级的语言如 C/C++/Rust。
2019 年时 MOSN 的底层网络库使用了 Go 语言原生网络库,每个 TCP 网络连接使用了两个 goroutine 分别处理网络收发,当然后来经优化后做到了单个 TCP 连接做到了单 TCP 仅使用一个 goroutine,并没有采用 epoll 系统调用的方式进行优化。
再举个例子。
字节跳动从 2020 年便在知乎开始发文宣传其 Go 语言网络框架 kitex 的优秀性能【见参考 3】,说是基于原生的 epoll 后 “性能已远超官方 net 库”云云。当时它没开源代码,大家也只能姑妄信之。2021 年年初,头条又开始出来宣传了一把【见参考 4】,宣称 “测试数据表明,当前版本(2020.12) 相比于上次分享时 (2020.05),吞吐能力 ↑30%,延迟 AVG ↓25%,TP99 ↓67%,性能已远超官方 net 库”。然后终于把代码开源了。8 月初鸟窝大佬经过测试,并在《2021年Go生态圈rpc框架benchmark》(链接见 参考5)一文中给出了测试结论。
说了这么多,收回话题,总结一句话就是:Getty 只考虑使用 Go 语言原生的网络接口,如果遇到网络性能瓶颈也只会在自身层面寻找优化突破点。
Getty 每年都会一次重大的升级,本文给出 Getty 近年的几次重大升级。
1、Goroutine Pool
Getty 初始版本针对一个网络连接启用两个 goroutine:一个 goroutine 进行网络字节流的接收、调用 Reader 接口拆解出网络包 (package)、调用 EventListener.OnMessage() 接口进行逻辑处理;另一个 goroutine 负责发送网络字节流、调用 EventListener.OnCron() 执行定时逻辑。
后来出于提升网络吞吐的需要,Getty 进行了一次大的优化:将逻辑处理这步逻辑从第一个 goroutine 任务中分离,添加 Goroutine Pool【下文简称 Gr pool】专门处理网络逻辑。
即网络字节流接收、逻辑处理和网络字节流发送都有单独的 goroutine 处理。
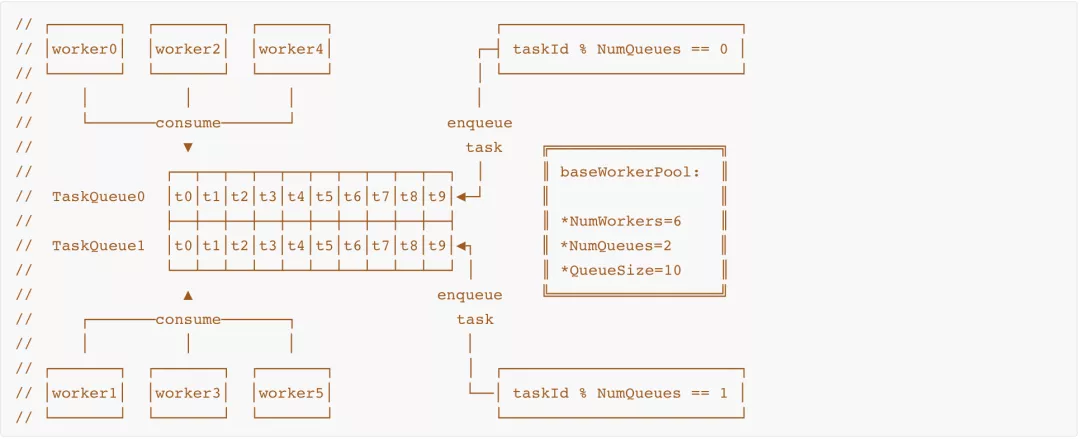

Gr Pool 成员有任务队列【其数目为 M】和 Gr 数组【其数目为 N】以及任务【或者称之为消息】,根据 N 的数目变化其类型分为可伸缩 Gr pool 与固定大小 Gr pool。可伸缩 Gr Pool 好处是可以随着任务数目变化增减 N 以节约 CPU 和内存资源。
1.1 固定大小 Gr Pool
按照 M 与 N 的比例,固定大小 Gr Pool 又区分为 1:1、1:N、M:N 三类。
1:N 类型的 Gr Pool 最易实现,个人 2017 年在项目 kafka-connect-elasticsearch 中实现过此类型的 Gr Pool:作为消费者从 kafka 读取数据然后放入消息队列,然后各个 worker gr 从此队列中取出任务进行消费处理。
这种模型的 Gr pool 整个 pool 只创建一个 chan, 所有 Gr 去读取这一个 chan,其缺点是:队列读写模型是 一写多读,因为 go channel 的低效率【整体使用一个 mutex lock】造成竞争激烈,当然其网络包处理顺序更无从保证。
Getty 初始版本的 Gr pool 模型为 1:1,每个 Gr 多有自己的 chan,其读写模型是一写一读,其优点是可保证网络包处理顺序性, 如读取 kafka 消息时候,按照 kafka message 的 key 的 hash 值以取余方式【hash(message key) % N】将其投递到某个 task queue,则同一 key 的消息都可以保证处理有序。但这种模型的缺陷:每个 task 处理要有时间,此方案会造成某个 Gr 的 chan 里面有 task 堵塞,就算其他 Gr 闲着,也没办法处理之【任务处理“饥饿”】。
更进一步的 1:1 模型的改进方案:每个 Gr 一个 chan,如果 Gr 发现自己的 chan 没有请求,就去找别的 chan,发送方也尽量发往消费快的协程。这个方案类似于 go runtime 内部的 MPG 调度算法使用的 goroutine 队列,但其算法和实现会过于复杂。
Getty 后来实现了 M:N 模型版本的 Gr pool,每个 task queue 被 N/M 个 Gr 消费,这种模型的优点是兼顾处理效率和锁压力平衡,可以做到总体层面的任务处理均衡,Task 派发采用 RoundRobin 方式。
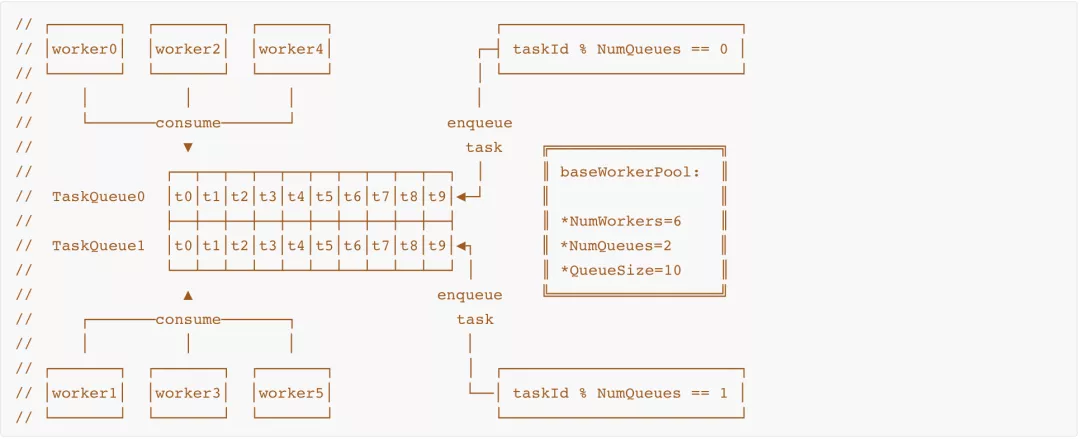
其整体实现如上图所示。具体代码实现请参见 gr pool【参考 7】连接中的 TaskPool 实现。
1.2 无限制 Gr Pool
使用固定量资源的 Gr pool,在请求量加大的情况下无法保证吞吐和 RT,有些场景下用户希望尽可能用尽所有的资源保证吞吐和 RT。
后来借鉴 "A Million WebSockets and Go" 一文【参考 8】中的 “Goroutine pool” 实现了一个 可无限扩容的 gr pool。
具体代码实现请参见 gr pool【参考 7】 连接中的 taskPoolSimple 实现。
1.3 网络包处理顺序
固定大小的 gr pool 优点是限定了逻辑处理流程对机器 CPU/MEMORY 等资源的使用,而 无限制 Gr Pool 虽然保持了弹性但有可能耗尽机器的资源导致容器被内核杀掉。但无论使用何种形式的 gr pool,getty 无法保证网络包的处理顺序。
譬如 Getty 服务端收到了同一个客户端发来的 A 和 B 两个网络包,Gr pool 模型可能造成服户端先处理 B 包后处理 A 包。同样,客户端也可能先收到服务端对 B 包的 response,然后才收到 A 包的 response。
如果客户端的每次请求都是独立的,没有前后顺序关系,则带有 Gr pool 特性的 Getty 不考虑顺序关系是没有问题的。如果上层用户关注 A 和 B 请求处理的前后顺序,则可以把 A 和 B 两个请求合并为一个请求,或者把 gr pool 特性关闭。
2、Lazy Reconnect
Getty 中 session 代表一个网络连接,client 其实是一个网络连接池,维护一定数量的连接 session,这个数量当然是用户设定的。Getty client 初始版本【2018 年以前的版本】中,每个 client 单独启动一个 goroutine 轮询检测其连接池中 session 数量,如果没有达到用户设定的连接数量就向 server 发起新连接。
当 client 与 server 连接断开时,server 可能是被下线了,可能是意外退出,也有可能是假死。如果上层用户判定对端 server 确实不存在【如收到注册中心发来的 server 下线通知】后,调用 client.Close() 接口把连接池关闭掉。如果上层用户没有调用这个接口把连接池关闭掉,client 就认为对端地址还有效,就会不断尝试发起重连,维护连接池。
综上,从一个旧 session 关闭到创建一个新 session,getty client 初始版本的重连处理流程是:
- 旧 session 关闭
网络接收 goroutine; - 旧 session
网络发送 goroutine探测到网络接收 goroutine退出后终止网络发送,进行资源回收后设定当前 session 无效; - client 的轮询 goroutine 检测到无效 session 后把它从 session 连接池删除;
- client 的轮询 goroutine 检测到有效 session 数目少于 getty 上层使用者设定的数目 且 getty 上层使用者没有通过
client.Close()接口关闭连接池时,就调用连接接口发起新连接。
上面这种通过定时轮询方式不断查验 client 中 session pool 中每个 session 有效性的方式,可称之为主动连接。主动连接的缺点显然是每个 client 都需要单独启用一个 goroutine。当然,其进一步优化手段之一是可以启动一个全局的 goroutine,定时轮询检测所有 client 的 session pool,不必每个 client 单独启动一个 goroutine。但是个人从 2016 年开始一直在思考一个问题:能否换一种 session pool 维护方式,去掉定时轮询机制,完全不使用任何的 goroutine 维护每个 client 的 session pool?
2018 年 5 月个人在一次午饭后遛弯时,把 getty client 的重连逻辑又重新梳理了一遍,突然想到了另一种方法,在步骤 2 中完全可以对 网络发送 goroutine 进行 “废物利用”,在这个 goroutine 标记当前 session 无效的逻辑步骤之后再加上一个逻辑:
- 如果当前 session 的维护者是一个 client【因为 session 的使用者也可能是 server】;
- 且如果其当前 session pool 的 session 数量少于上层使用者设定的 session number;
- 且如果上层使用者还没有通过
client.Close()设定当前 session pool 无效【即当前 session pool 有效,或者说是对端 server 有效】 - 满足上面三个条件,
网络发送 goroutine执行连接重连即可; - 新网络连接 session 建立成功且被加入 client 的 session pool 后,
网络发送 goroutine使命完成直接退出。
我把这种重连方式称之为 lazy reconnect,网络发送 goroutine 在其生命周期的最后阶段应该被称之为 网络重连 goroutine。通过 lazy reconnect这种方式,上述重连步骤 3 和 步骤 4 的逻辑被合入了步骤 2,client 当然也就没必要再启动一个额外的 goroutine 通过定时轮询的方式维护其 session pool 了。
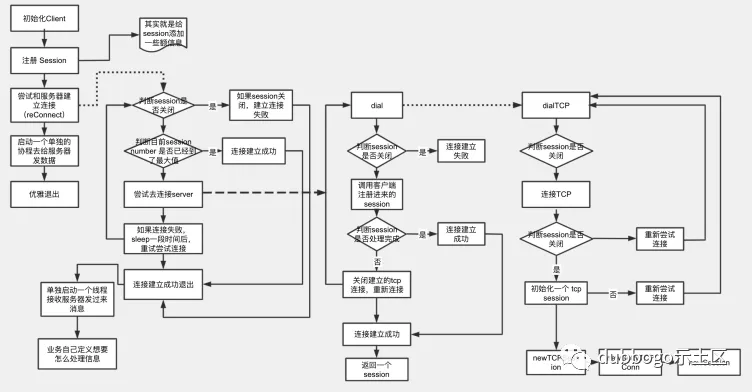
lazy reconnect 整体流程图如上。如果对相关代码流程感兴趣,请移步 "参考 13" 给出的链接,很容易自行分析出来。
3、定时器
在引入 Gr pool 后,一个网络连接至少使用三个 goroutine:
- 一个 goroutine 进行网络字节流的接收、调用 Reader 接口拆解出网络包 (package)
- 第二个 goroutine 调用
EventListener.OnMessage()接口进行逻辑处理 - 第三个 goroutine 负责发送网络字节流、调用
EventListener.OnCron()执行定时逻辑以及lazy reconnect
在连接较少的情况下这个模型尚可稳定运行。但当集群规模到了一定规模,譬如每个服务端的连接数达 1k 以上时,单单网络连接就至少使用 3k 个 goroutine,这是对 CPU 计算资源和内存资源极大地浪费。上面三个 goroutine 中,第一个 goroutine 无可拆解,第二个 goroutine 实际是 gr pool 一部分,可优化的对象就是第三个 goroutine 的任务。
2020 年底 Getty 维护团队首先把网络字节流任务放入了第二个 goroutine:处理完逻辑任务后立即进行同步网络发送。此处改进后,第三个 goroutine 就只剩下一个 EventListener.OnCron() 定时处理任务。这个定时逻辑其实可以抛给 Getty 上层调用者处理,但出于方便用户和向后兼容的考虑,我们使用了另一种优化思路:引入时间轮管理定时心跳检测。
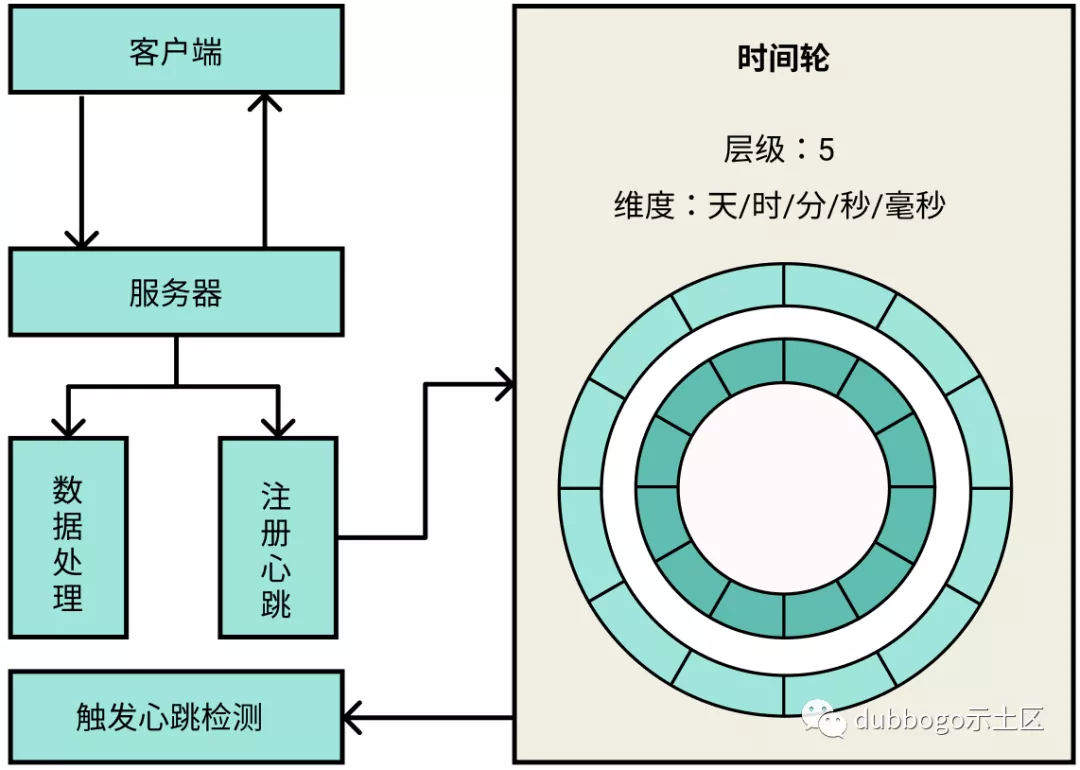
2017 年 9 月时,我曾实现了一个 Go 语言 timer 时间轮库 timer wheel(链接见参考 10),兼容 Go 的 timer 所有原生接口,其优点是所有时间任务都在一个 goroutine 内执行。2020 年 12 月把它引入 getty 后,getty 所有的EventListener.OnCron() 定时处理任务均交由 timer wheel 处理,第三个 goroutine 就可以完美地消失了【后续:两个月后发现 timer 库被另一个擅长拉 star 的 rpc 项目 “借鉴” 走了^+^】。
此时第三个 goroutine 就剩下最后一个任务:lazy reconnect。当第三个 goroutine 不存在后,这个任务完全可以放入第一个 goroutine:在当网络字节流接收 goroutine 检测到网络错误退出前的最后一个步骤,执行 lazy reconnect。
优化改进后的一个网络连接最多只使用两个 goroutine:
- 一个 goroutine 进行网络字节流的接收、调用 Reader 接口拆解出网络包 (package)、
lazy reconnect - 第二个 goroutine 调用
EventListener.OnMessage()接口进行逻辑处理、发送网络字节流
第二个 goroutine 来自 gr pool。考虑到 gr pool 中的 goroutine 都是可复用的公共资源,单个连接实际上只单独占用了第一个 goroutine。
4、Getty 压测
Getty 维护团队的郝洪范同学,借鉴了 rpcx 的 benchmark 程序后实现了 getty benchmark 【参考 11】,对优化后的 v1.4.3 版本进行过压测。
「压测环境」:

「压测结果」:

压测结果如上,服务端 TPS 数达 12556,网络吞吐可达 12556 * 915 B/s ≈ 11219 KiB/s ≈ 11 MiB/s。
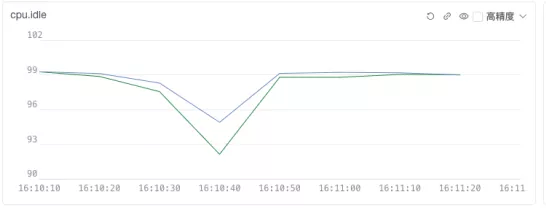
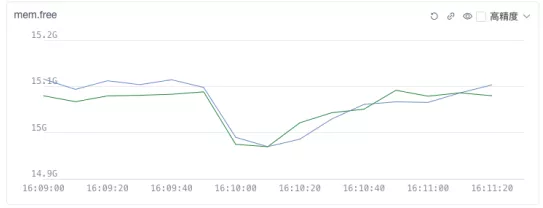
如上图,可见网络压测前后服务单的 CPU/MEMORY 资源变化,getty 服务端仅仅使用了 6% 的 CPU,内存占用也仅越 100MiB,且在测试压力去掉后很快就把资源还给了系统。
测试时 getty 服务端的 goroutine 使用见下图:单个 TCP 连接仅使用一个 goroutine。

整个测试结果以及相关代码请参加 benmark result (链接见【参考 12】)。这个压测当然没有压出 Getty 的极限性能,但已经能够满足阿里主要场景下的使用需求。
发展 timeline
从我个人 2016 年时写 Getty 开始,到目前有一个专门的开源团队维护 Getty,Getty 一路走来殊为不易。
梳理其 timeline,其主要发展时间节点如下:
- 2016 年 6 月份开发出第一个生产可用版本,支持 TCP/websocket 两种通信协议,同年 10 月在 gocn 上发帖 兼容tcp和websocket的一个简洁网络框架getty · GoCN社区 推广;
- 2017 年 9 月时,实现了一个 Go 语言 timer 时间轮库 timer wheelhttps://github.com/AlexStocks/goext/blob/master/time/time.go
- 2018 年 3 月在其上加入 UDP 通信支持;
- 2018 年 5 月支持基于 protobuf 和 json 的 RPC;
- 2018 年 8 月加入基于 zookeeper 和 etcd 的服务注册和发现功能,取名 micro;
- 2019 年 5 月 getty 的底层 tcp 通信实现被独立拆出迁入 github.com/dubbogo,后迁入 github.com/apache/dubbo-getty;
- 2019月5月 Getty RPC 包被携程的两位同学迁入 [https://github.com/apache/dubbo-go/tree/master/protocol/dubbo](https://github.com/apache/dubbo-go/tree/master/protocol/dubbo), 构建了 dubbogo 基于 hessian2 协议的 RPC 层;、
- 2019 年 5 月,加入固定大小 goroutine pool;
- 2019 年底,刘晓敏同学告知其基于 Getty 实现了 seata-golang;
- 2020 年 11 月,把网络发送与逻辑处理合并放入 gr pool 中处理;
- 2021 年 5 月,完成定时器优化;
最后,还是如第三节优化开头部分所说,Getty 维护团队不追求无意义的 benchmark 数据,不做无意义的炫技式优化,只根据生产环境需求来进行自身改进。只要维护团队在,Getty 稳定性和性能定会越来越优秀。
本文为阿里云原创内容,未经允许不得转载。
Go 语言网络库 getty 的那些事的更多相关文章
- boost.ASIO-可能是下一代C++标准的网络库
曾几何时,Boost中有一个Socket库,但后来没有了下文,C++社区一直在翘首盼望一个标准网络库的出现,网络上开源的网络库也有不少,例如Apache Portable Runtime就是比较著名的 ...
- python3+django2 开发易语言网络验证(上)
创作背景: 在某论坛中下载到一套php开发易语言网络验证的教程,照着看下来,花了两天的时间,结果发现教程里开发的网络验证,以及随着教程一起给学员的源码,都存在着根本用不了的bug!我想要看看能不能在原 ...
- python3+django2 开发易语言网络验证(中)
第四步:网络验证的逻辑开发 1.将model注册到adminx.py中 1.在apps/yanzheng目录下新建admin.py 文件,添加代码: import xadmin from xadmin ...
- R语言网络爬虫学习 基于rvest包
R语言网络爬虫学习 基于rvest包 龙君蛋君:2015年3月26日 1.背景介绍: 前几天看到有人写了一篇用R爬虫的文章,感兴趣,于是自己学习了.好吧,其实我和那篇文章R语言爬虫初尝试-基于RVES ...
- 网络库libevent、libev、libuv对比
Libevent.libev.libuv三个网络库,都是c语言实现的异步事件库Asynchronousevent library). 异步事件库本质上是提供异步事件通知(Asynchronous Ev ...
- 13. Go 语言网络爬虫
Go 语言网络爬虫 本章将完整地展示一个应用程序的设计.编写和简单试用的全过程,从而把前面讲到的所有 Go 知识贯穿起来.在这个过程中,加深对这些知识的记忆和理解,以及再次说明怎样把它们用到实处.由本 ...
- 《Linux多线程服务端编程:使用muduo C++网络库》上市半年重印两次,总印数达到了9000册
<Linux多线程服务端编程:使用muduo C++网络库>这本书自今年一月上市以来,半年之内已经重印两次(加上首印,一共是三次印刷),总印数达到了9000册,这在技术书里已经算是相当不错 ...
- 转载~kxcfzyk:Linux C语言多线程库Pthread中条件变量的的正确用法逐步详解
Linux C语言多线程库Pthread中条件变量的的正确用法逐步详解 多线程c语言linuxsemaphore条件变量 (本文的读者定位是了解Pthread常用多线程API和Pthread互斥锁 ...
- 【转】开源C/C++网络库比较
在开源的C/C++网络库中, 常用的就那么几个, 在业界知名度最高的, 应该是ACE了, 不过是个重量级的大家伙, 轻量级的有libevent, libev, 还有 Boost的ASIO. ACE是一 ...
- 开源C/C++网络库比较
在开源的C/C++网络库中, 常用的就那么几个, 在业界知名度最高的, 应该是ACE了, 不过是个重量级的大家伙, 轻量级的有libevent, libev, 还有 Boost的ASIO. ACE是一 ...
随机推荐
- 虚幻引擎UE4如何实现打包后播放片头?其实超简单!
虚幻引擎作为一款全球性的3D实时开发工具,不仅在游戏行业,其在建筑.影视.医疗等行业也被广泛使用.作为开发人员,有时开发的UE虚幻引擎项目比较大,开始运行项目时需要等待较长的时间,还有些公司要求添加片 ...
- 直播预告:面对技术带来的新机遇,CG人如何腾飞?
"新锐先锋,玩转未来"--首届实时染3D动画创作大赛由瑞云科技主办,英伟达.青椒云.3DCAT实时渲染云协办,戴尔科技集团.Reallusion.英迈.万生华态.D5渲染器.中视典 ...
- Walrus 0.6发布:预览资源变更、丰富公有云支持,满足企业多云需求
近日,数澈软件Seal(以下简称"Seal")宣布基于 IaC 的开源应用管理平台 Walrus 0.6 正式发布! 在之前的版本中,Walrus 引入应用模型并优化了应用部署体验 ...
- Android富文本开发
基础概念目录介绍 01.业务需求简单介绍 02.实现的方案介绍 03.异常状态下保存状态信息 04.处理软键盘回删按钮逻辑 05.在指定位置插入图片 06.在指定位置插入输入文字 07.如果对选中文字 ...
- 记录--vue中动态引入图片为什么要是require, 你不知道的那些事
这里给大家分享我在网上总结出来的一些知识,希望对大家有所帮助 相信用过vue的小伙伴,肯定被面试官问过这样一个问题:在vue中动态的引入图片为什么要使用require 有些小伙伴,可能会轻蔑一笑:呵, ...
- 超详细的彻底卸载VMware虚拟机方法
一.在卸载VMware虚拟机之前,要先把与VMware相关的服务和进程终止 1.在windows中按下[Windows键],搜索[服务]设置,然后打开: 2.找到以VM打头命名的服务,然后右键停止这些 ...
- Redis源码学习(1)──字符串
redis 版本:5.0 本文代码在Redis源码中的位置:redis/src/sds.c.redis/src/sds.h 源码整体结构 src:核心实现代码,用 C 语言编写 tests:单元测试代 ...
- .net 开源混淆器 ConfuserEx
官网:http://yck1509.github.io/ConfuserEx/ 下载地址:https://github.com/yck1509/ConfuserEx/releases 使用参考:htt ...
- Modbus报文详解
Modbus是一种串行通信协议,最初由Modicon公司(现为施耐德电气的一部分)在1979年为使用其PLC(可编程逻辑控制器)而开发.Modbus已成为工业领域内广泛使用的一种通信协议,特别是对于监 ...
- Java面试题【2】
11)abstract class 和 interface 有什么区别? 含有 abstract 修饰符的 class 即为抽象类,abstract 类不能创建的实例对象.含有 abstract 方法 ...