Docker安装InfluxDB1.x和InfluxDB2.x以及与SpringBoot整合
两者区别:
1.x 版本使用 influxQL 查询语言,2.x 和 1.8+(beta) 使用 flux 查询语法;相比V1 移除了database 和 RP,增加了bucket。
V2具有以下几个概念:
timestamp、field key、field value、field set、tag key、tag value、tag set、measurement、series、point、bucket、bucket schema、organization
新增的概念:
bucket:所有 InfluxDB 数据都存储在一个存储桶中。一个桶结合了数据库的概念和存储周期(时间每个数据点仍然存在持续时间)。一个桶属于一个组织
bucket schema:具有明确的schema-type的存储桶需要为每个度量指定显式架构。测量包含标签、字段和时间戳。显式模式限制了可以写入该度量的数据的形状。
organization:InfluxDB组织是一组用户的工作区。所有仪表板、任务、存储桶和用户都属于一个组织。
一、InfluxDB1.x Docker安装以及与Boot整合
A、docker安装InfluxDB1.x (influxdb1.8.4)
1、安装:
docker run -d --name influxdb -p 8086:8086 influxdb:1.8.4
2、查看
docker ps -a
3、进入docker的influx中
docker exec -it daf88772adc9 /bin/bash
influx
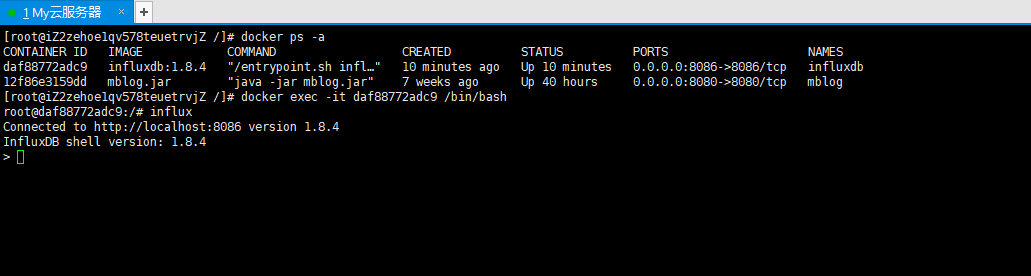
5、修改账户密码
# 显示用户
SHOW USERS
# 创建用户
CREATE USER "username" WITH PASSWORD 'password'
# 赋予用户管理员权限
GRANT ALL PRIVILEGES TO username
# 创建管理员权限的用户
CREATE USER <username> WITH PASSWORD '<password>' WITH ALL PRIVILEGES
# 修改用户密码
SET PASSWORD FOR username = 'password'
# 撤消权限
REVOKE ALL ON mydb FROM username
# 查看权限
SHOW GRANTS FOR username
# 删除用户
DROP USER "username"
6、在配置文件启用认证
7、设置保存策略(多长时间之前的数据需要删除)---默认为 autogen 永久不删除
a、查看数据库的保存策略
show retention policies on 数据库名
例子:
# 选择使用telegraf数据库
> use influx_test;
Using database influx_test
# 查询数据保存策略
> show retention policies on influx_test
name duration shardGroupDuration replicaN default
---- -------- ------------------ -------- -------
autogen 0s 168h0m0s 1 true
b、设置保存策略
# 新建一个策略
CREATE RETENTION POLICY "策略名称" ON 数据库名 DURATION 时长 REPLICATION 副本个数;
# 新建一个策略并且直接设置为默认策略
CREATE RETENTION POLICY "策略名称" ON 数据库名 DURATION 时长 REPLICATION 副本个数 DEFAULT;
例子:
# 创建新的默认策略role_01保留数据时长1小时
> CREATE RETENTION POLICY "1hour" ON influx_test DURATION 1h REPLICATION 1 DEFAULT;
c、修改保存策略
ALTER RETENTION POLICY "策略名称" ON "数据库名" DURATION 时长
ALTER RETENTION POLICY "策略名称" ON "数据库名" DURATION 时长 DEFAULT
d、删除保存策略
drop retention POLICY "策略名" ON "数据库名"
8、使用桌面可视化工具连接数据库
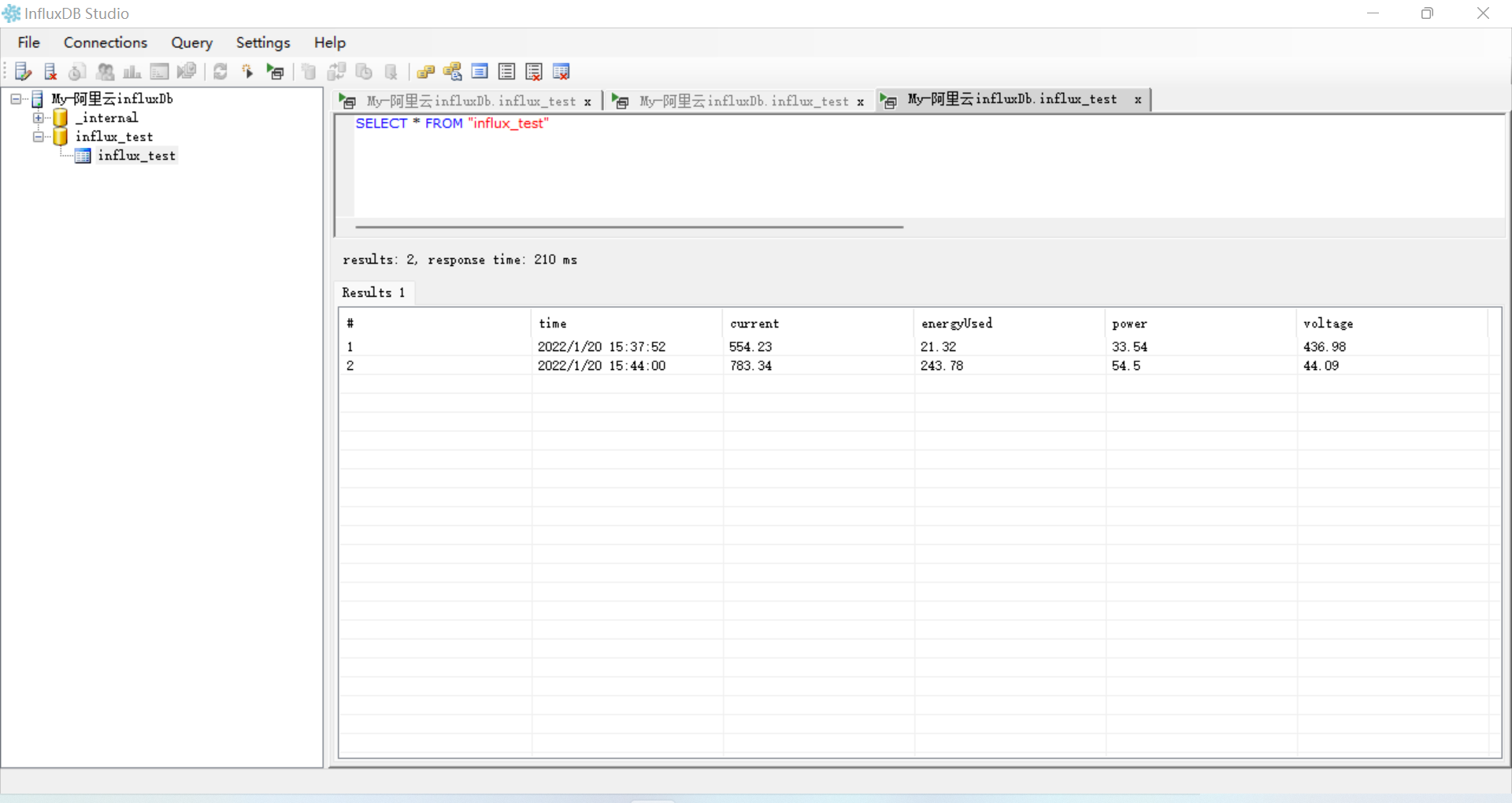
B、InfluxDB1.x与Spring整合(只列举部分代码,后面会放上整个项目的GitHub地址)
整个项目结构如下:
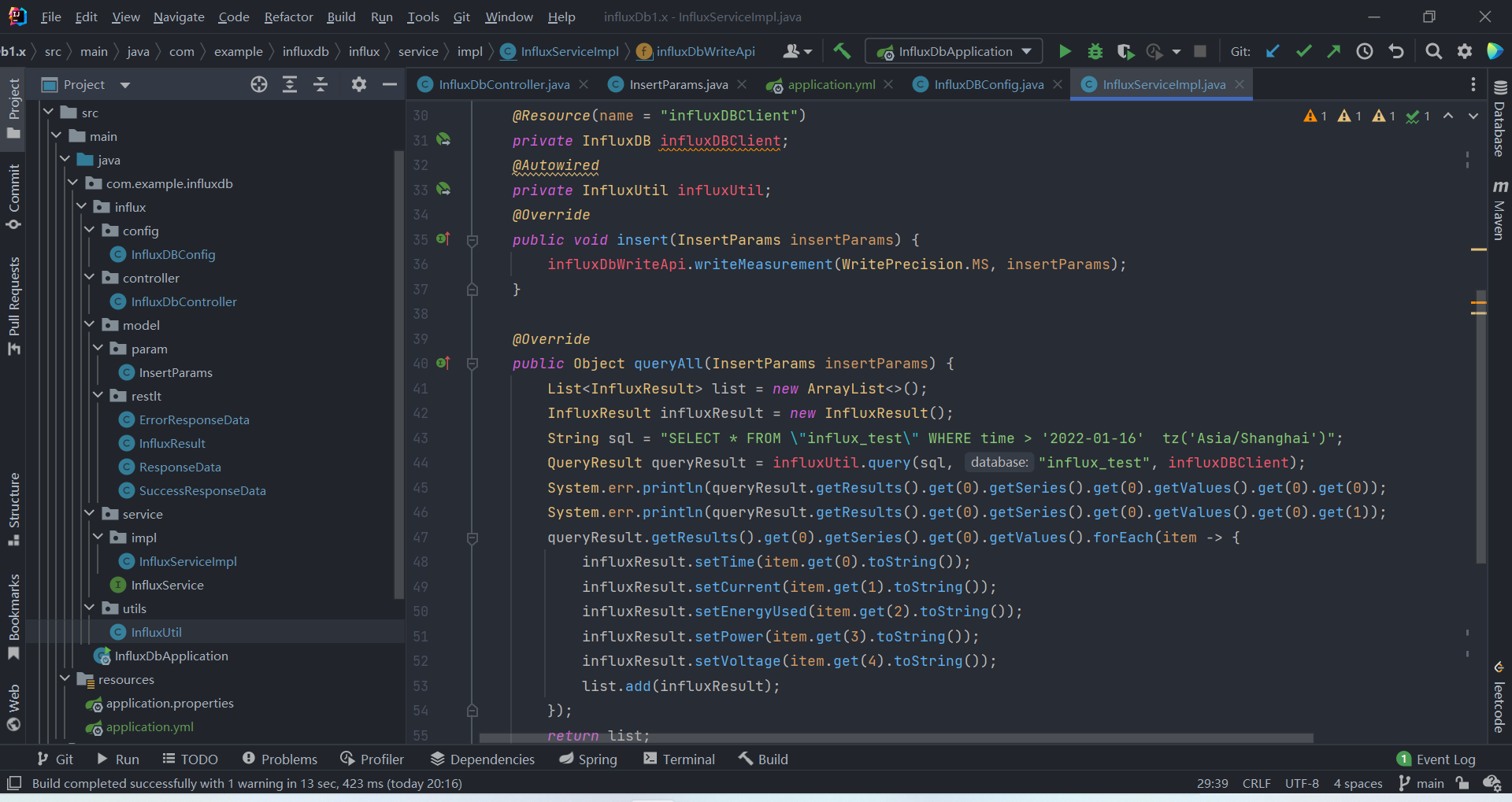
1、引入依赖 (其他依赖未显示全,后面会放上整个项目的GitHub地址)
<dependency>
<groupId>com.influxdb</groupId>
<artifactId>influxdb-client-java</artifactId>
<version>4.0.0</version>
</dependency>
<dependency>
<groupId>org.influxdb</groupId>
<artifactId>influxdb-java</artifactId>
<version>2.20</version>
</dependency>
2、新建yml文件
influx:
url: 'http://xxx.xx.xxx.xx:8086'
password: 'password'
username: 'username'
3、连接配置 InfluxDBConfig
@Data
@Configuration
@ConfigurationProperties(prefix = "influx")
public class InfluxDBConfig {
private String url;
private String username;
private String password;
/**
* description: 用于查询
* date: 2022/1/20 23:11
* author: zhouhong
* @param * @param null
* @return
*/
@Bean(destroyMethod = "close")
public InfluxDB influxDBClient(){
return InfluxDBFactory.connect(this.url, this.username, this.password);
}
/**
* description: 用于写入
* date: 2022/1/20 23:12
* author: zhouhong
* @param * @param null
* @return
*/
@Bean(name = "influxDbWriteApi",destroyMethod = "close")
public WriteApi influxDbWriteApi(){
InfluxDBClient influxDBClient = InfluxDBClientFactory.createV1(this.url, this.username,
this.password.toCharArray(), "influx_test", "autogen");
return influxDBClient.getWriteApi();
}
}
4、封装用于查询的方法
@Component
public class InfluxUtil {
/**
* description: 通用查询
* date: 2022/1/20 23:13
* author: zhouhong
* @param * @param null
* @return
*/
public QueryResult query(String command, String database, InfluxDB influxDB) {
Query query = new Query(command, database);
return influxDB.query(query);
}
}
5、新建需要写入的数据的实体类、需要返回的类(省略,具体参考github示例)InsertParams.java InfluxResult.java
6、新建server层和impl实现类
/**
* description: 时序数据库Impl
* date: 2022/1/16 20:47
* author: zhouhong
*/
@Service
@Slf4j
public class InfluxServiceImpl implements InfluxService {
@Resource(name = "influxDbWriteApi")
private WriteApi influxDbWriteApi;
@Resource(name = "influxDBClient")
private InfluxDB influxDBClient;
@Autowired
private InfluxUtil influxUtil;
@Override
public void insert(InsertParams insertParams) {
influxDbWriteApi.writeMeasurement(WritePrecision.MS, insertParams);
}
@Override
public Object queryAll(InsertParams insertParams) {
List<InfluxResult> list = new ArrayList<>();
InfluxResult influxResult = new InfluxResult();
String sql = "SELECT * FROM \"influx_test\" WHERE time > '2022-01-16' tz('Asia/Shanghai')";
QueryResult queryResult = influxUtil.query(sql, "influx_test", influxDBClient);
queryResult.getResults().get(0).getSeries().get(0).getValues().forEach(item -> {
influxResult.setTime(item.get(0).toString());
influxResult.setCurrent(item.get(1).toString());
influxResult.setEnergyUsed(item.get(2).toString());
influxResult.setPower(item.get(3).toString());
influxResult.setVoltage(item.get(4).toString());
list.add(influxResult);
});
return list;
}
@Override
public Object querySumByOneDay(InsertParams insertParams) {
String sql = "SELECT SUM(voltage) FROM \"influx_test\" WHERE time > '2022-01-18' GROUP BY time(1d) tz('Asia/Shanghai')";
QueryResult queryResult = influxUtil.query(sql, "influx_test", influxDBClient);
return queryResult.getResults().get(0).getSeries().get(0);
}
}
7、controller层 InfluxDbController.java(返回结果是封装过后的,详情见github示例)
@RestController
public class InfluxDbController {
@Autowired
private InfluxService influxService;
/**
* description: 时序数据库插入测试
* date: 2022/1/16 23:00
* author: zhouhong
* @param * @param null
* @return
*/
@PostMapping("/influxdb/insert")
public ResponseData insert(@RequestBody InsertParams insertParams) {
influxService.insert(insertParams);
return new SuccessResponseData();
}
/**
* description: 时序数据库查询全部数据测试
* date: 2022/1/16 23:00
* author: zhouhong
* @param * @param null
* @return
*/
@PostMapping("/influxdb/queryAll")
public ResponseData query(@RequestBody InsertParams insertParams) {
return new SuccessResponseData(influxService.queryAll(insertParams));
}
/**
* description: 时序数据库按天查询当前电压总和测试
* date: 2022/1/16 23:00
* author: zhouhong
* @param * @param null
* @return
*/
@PostMapping("/influxdb/queryByOneDay")
public ResponseData queryByOneDay(@RequestBody InsertParams insertParams) {
return new SuccessResponseData(influxService.querySumByOneDay(insertParams));
}
}
8、PostMan测试(注意需要先新建一个 数据库---influx_test)
8.1 插入测试 localhost:9998/influxdb/insert
入参:
{
"energyUsed":243.78,
"power":54.50,
"current":783.34,
"voltage":44.09
}
返回:
{
"success": true,
"code": 200,
"message": "请求成功",
"localizedMsg": "请求成功",
"data": null
}
8.2、查询全部(注意,这里返回结果我封装了一下)localhost:9998/influxdb/queryAll
入参:
{
}
返回:
{
"success": true,
"code": 200,
"message": "请求成功",
"localizedMsg": "请求成功",
"data": [
{
"energyUsed": "243.78",
"power": "54.5",
"current": "783.34",
"voltage": "44.09",
"time": "2022-01-20T23:44:00.626+08:00"
},
{
"energyUsed": "243.78",
"power": "54.5",
"current": "783.34",
"voltage": "44.09",
"time": "2022-01-20T23:44:00.626+08:00"
}
]
}
8.3聚合查询(统计2022-01-18到现在,以天为单位每天的用电量之和) localhost:9998/influxdb/queryByOneDay 精度问题暂时没处理
入参:
{ }
返回:
{
"success": true,
"code": 200,
"message": "请求成功",
"localizedMsg": "请求成功",
"data": {
"name": "influx_test",
"tags": null,
"columns": [
"time",
"sum"
],
"values": [
[
"2022-01-18T00:00:00+08:00",
null
],
[
"2022-01-19T00:00:00+08:00",
null
],
[
"2022-01-20T00:00:00+08:00",
481.07000000000005
]
]
}
}
C、常见的查询SQL 后面加上 tz('Asia/Shanghai') 解决时区差
1、查所指定时间之后的所有
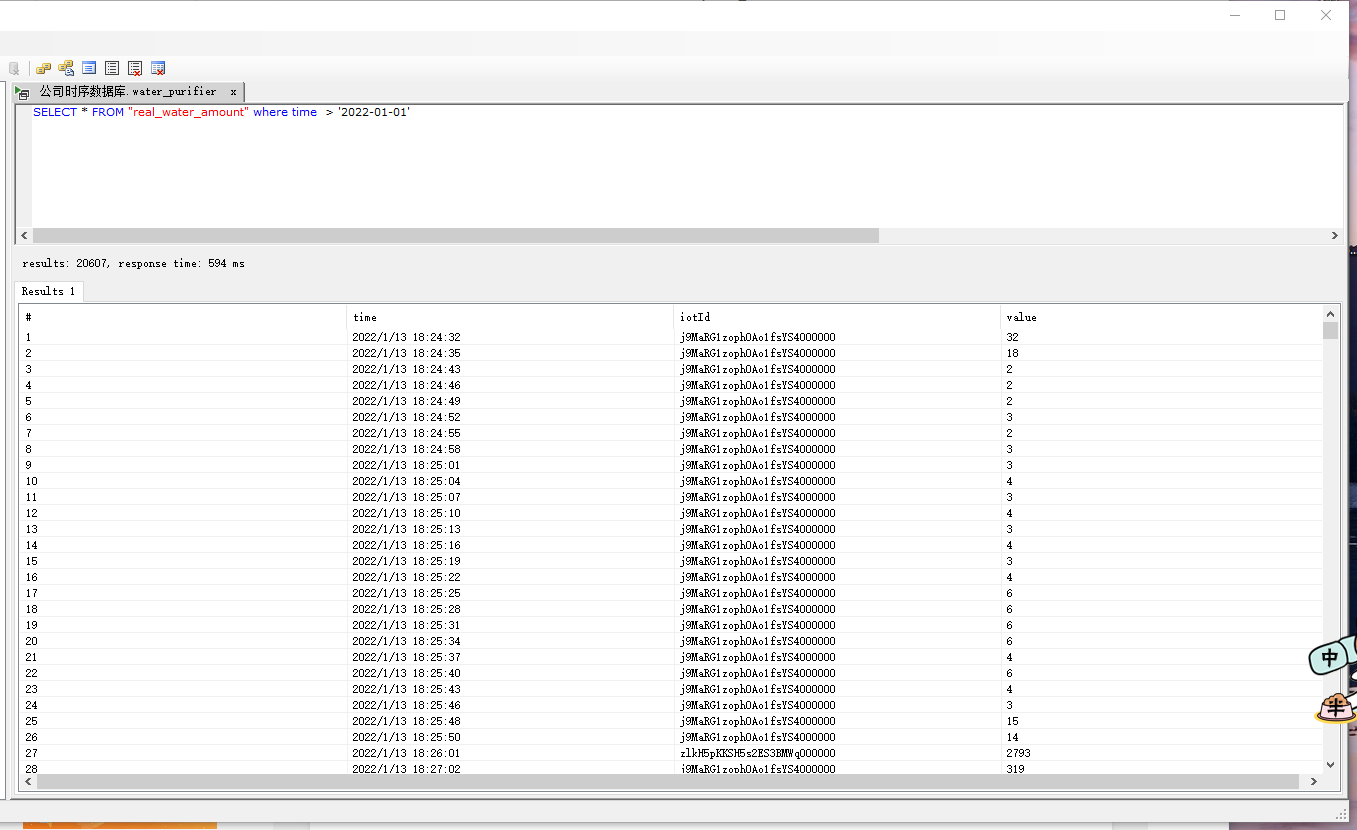
SELECT * FROM "real_water_amount" where time > '2022-01-01' tz('Asia/Shanghai')
2、查询平均值 mean()
SELECT mean(value) FROM "real_water_amount" where time > '2022-01-01' tz('Asia/Shanghai')

3、查询最大最小值 max() min()
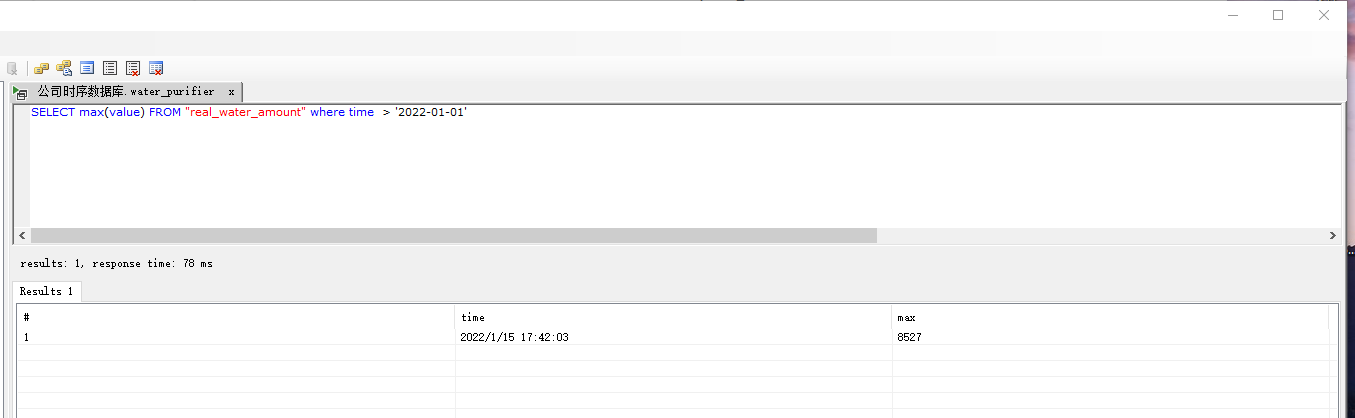
SELECT max(value) FROM "real_water_amount" where time > '2022-01-01' tz('Asia/Shanghai')
4、按年、月、天、周、小时、分钟、秒统计
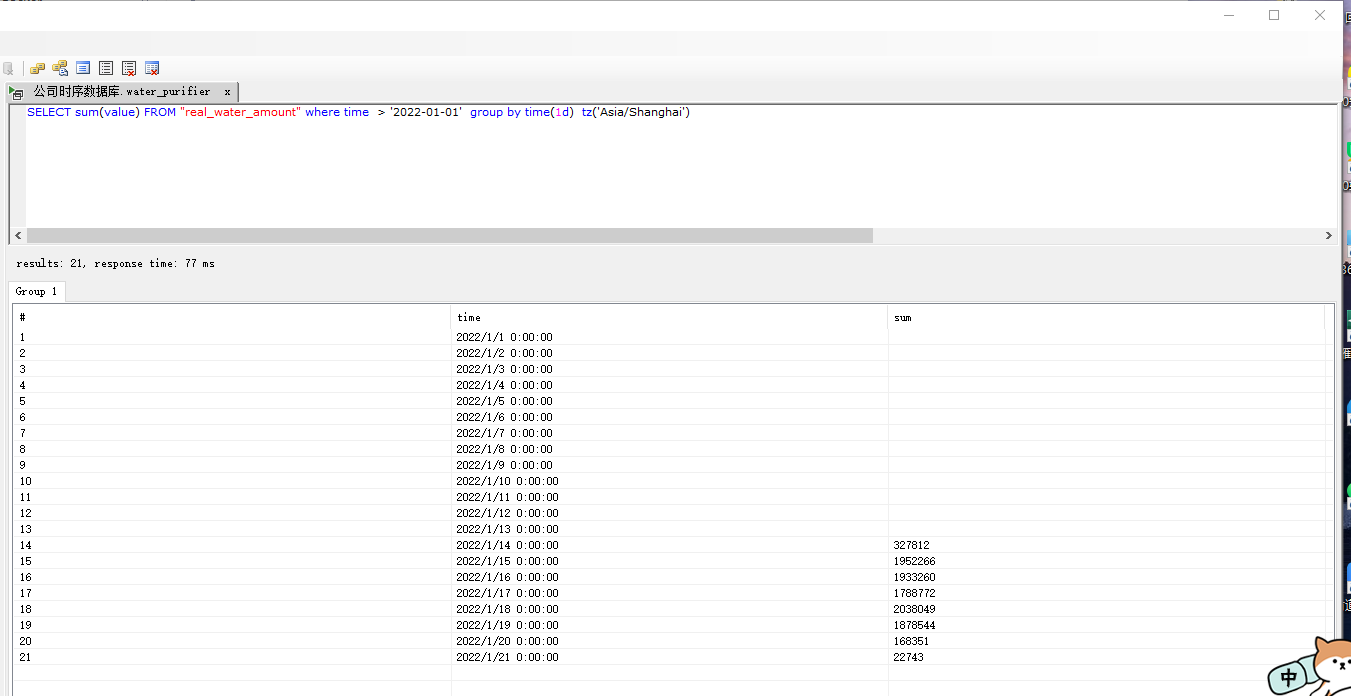
SELECT sum(value) FROM "real_water_amount" where time > '2022-01-01' group by time(1d) tz('Asia/Shanghai')
5、按照列过滤
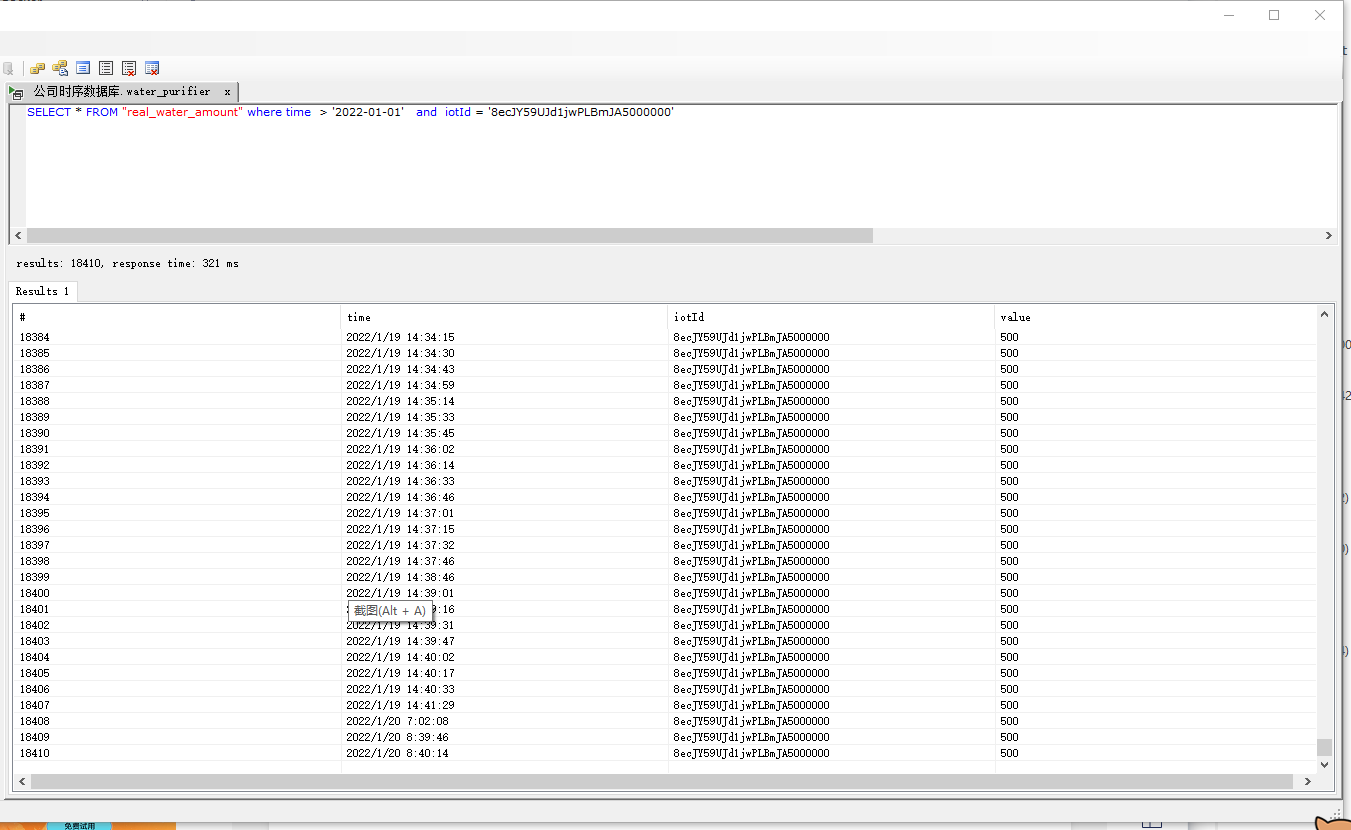
SELECT * FROM "real_water_amount" where time > '2022-01-01' and iotId = '8ecJY59UJd1jwPLBmJA5000000'
二、InfluxDB2.x Docker安装以及与Boot整合
A、Docker安装InfluxDB2.x
1、安装:默认拉取最新版本
docker run -d --name influxdb -p 8086:8086 influxdb
2、查看
docker ps -a
3、浏览器访问 IP:8086 (注意:部署在远程服务器上需要开启8086端口安全组)设置账号密码
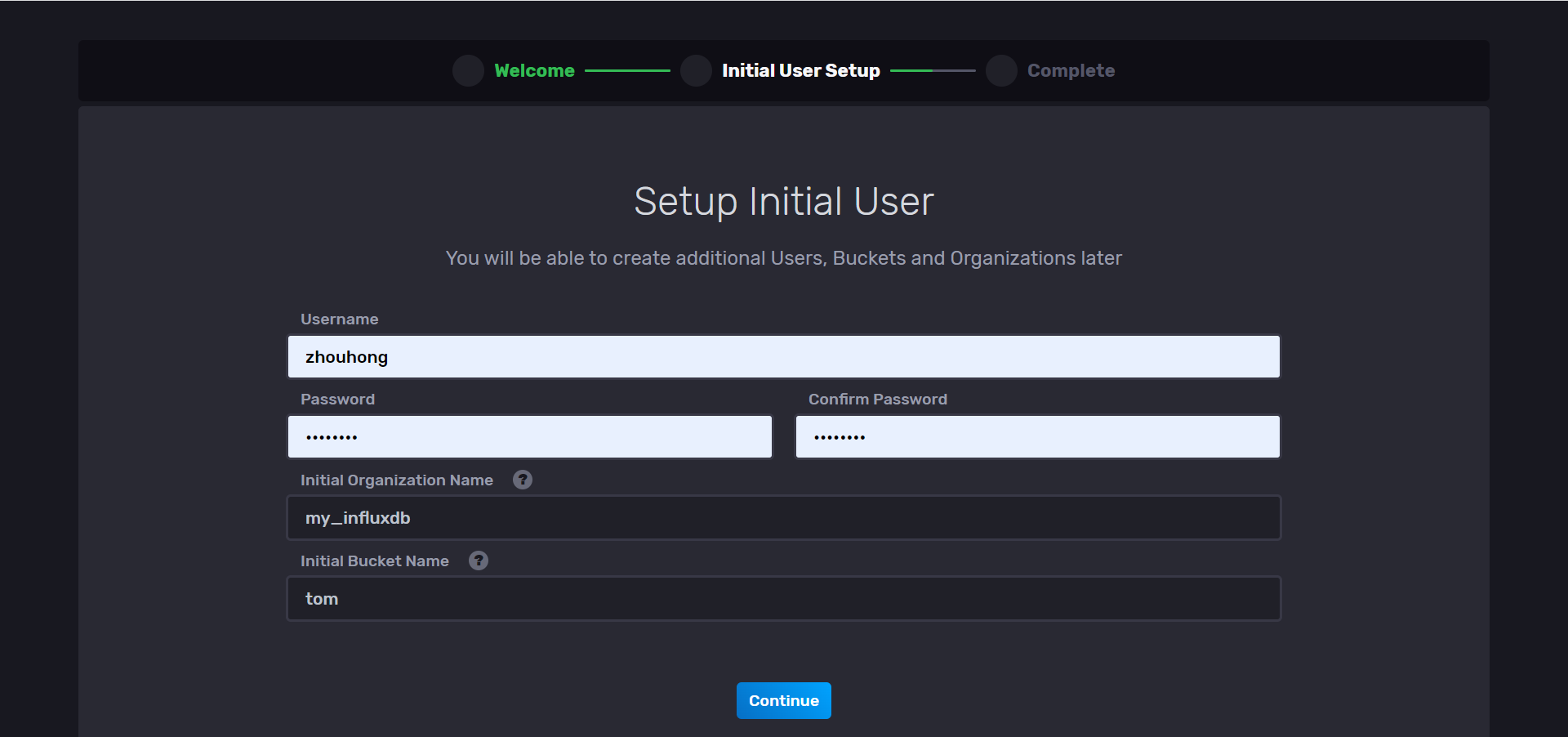
4、然后点击 Data -- > Buucket 就可以看到我们刚才创建的 名字为 Tom 的 Buucket了
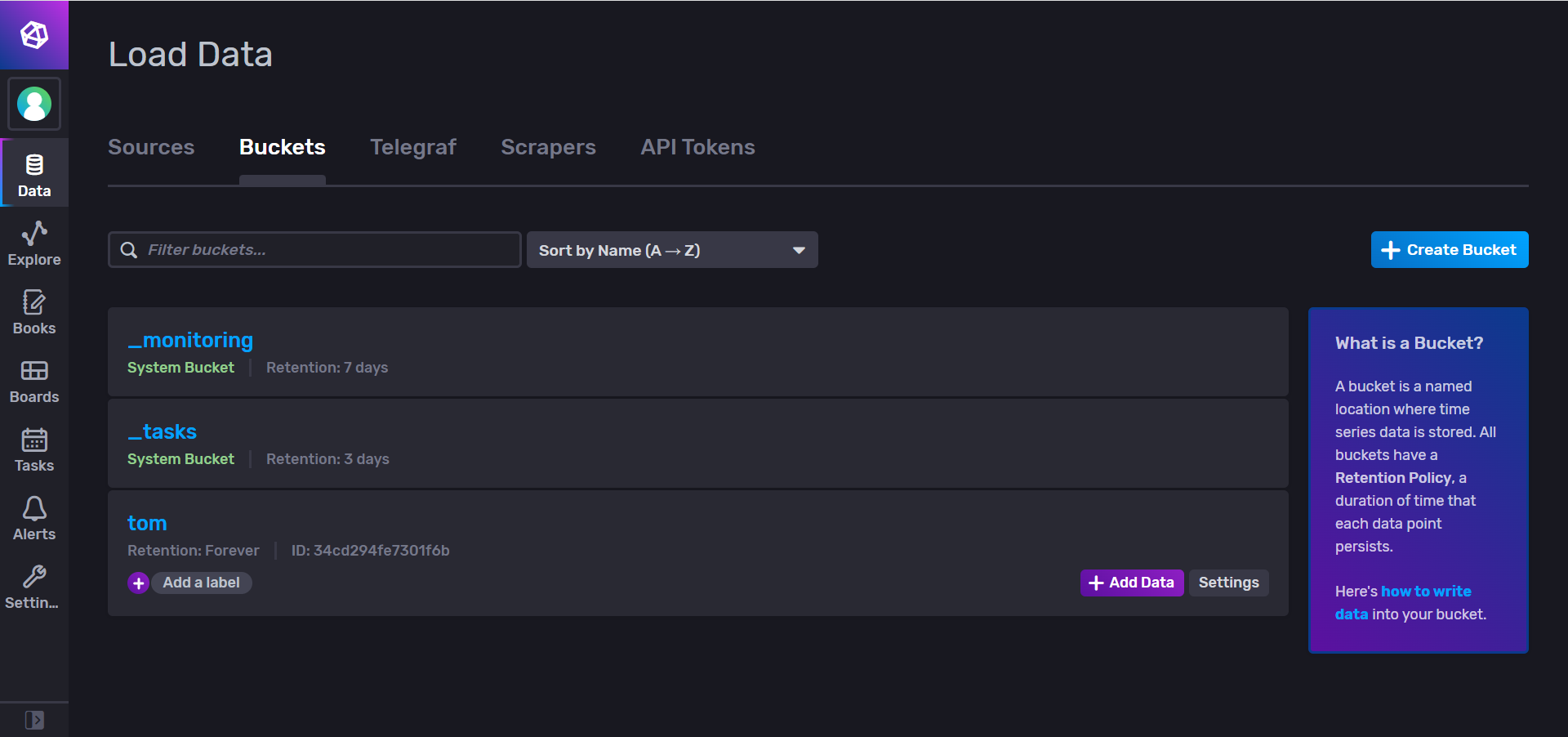
5、点击 API Tokens 获取当前用户的 Token(整合时需要)
6、设置Bucket的保存策略

B、InfluxDB2.x与SpringBoot整合
1、依赖
<dependency>
<groupId>com.influxdb</groupId>
<artifactId>influxdb-client-java</artifactId>
<version>4.0.0</version>
</dependency>
<dependency>
<groupId>org.influxdb</groupId>
<artifactId>influxdb-java</artifactId>
<version>2.20</version>
</dependency>
2、yml配置文件
influx:
influxUrl: 'http://XXX.XX.XXX.XX:8086'
bucket: 'tom'
org: 'my_influxdb'
token: 'Rt23UemGI_cfS-lFDrurtjh46P1enfhrji-KrZYR04wUR1Yxw_oBCZPL6GmFYSDn20Q9gM_P9DIBhHc2RJjNkA=='
3、配置类
@Setter
@Getter
public class InfluxBean{
/**
* 数据库url地址
*/
private String influxUrl;
/**
* 桶(表)
*/
private String bucket;
/**
* 组织
*/
private String org;
/**
* token
*/
private String token;
/**
* 数据库连接
*/
private InfluxDBClient client;
/**
* 构造方法
*/
public InfluxBean(String influxUrl, String bucket, String org, String token) {
this.influxUrl = influxUrl;
this.bucket = bucket;
this.org = org;
this.token = token;
this.client = getClient();
}
/**
* 获取连接
*/
private InfluxDBClient getClient() {
if (client == null) {
client = InfluxDBClientFactory.create(influxUrl, token.toCharArray());
}
return client;
}
/**
* 写入数据(以秒为时间单位)
*/
public void write(Object object){
try (WriteApi writeApi = client.getWriteApi()) {
writeApi.writeMeasurement(bucket, org, WritePrecision.NS, object);
}
}
/**
* 读取数据
*/
public List<FluxTable> queryTable(String fluxQuery){
return client.getQueryApi().query(fluxQuery, org);
}
}
@Data
@Configuration
@ConfigurationProperties(prefix = "influx")
public class InfluxConfig {
/**
* url地址
*/
private String influxUrl;
/**
* 桶(表)
*/
private String bucket;
/**
* 组织
*/
private String org;
/**
* token
*/
private String token;
/**
* 初始化bean
*/
@Bean(name = "influx")
public InfluxBean InfluxBean() {
return new InfluxBean(influxUrl, bucket, org, token);
}
}
4、实现类
@Service
@Slf4j
public class InfluxServiceImpl implements InfluxService {
@Resource
private InfluxBean influxBean;
@Override
public void insert(InsertParams insertParams) {
insertParams.setTime(Instant.now());
influxBean.write(insertParams);
}
@Override
public List<InfluxResult> queue(){
// 下面两个 private 方法 赋值给 list 查询对应的数据
List<FluxTable> list = queryInfluxAll();
List<InfluxResult> results = new ArrayList<>();
for (int i = 0; i < list.size(); i++) {
for (int j = 0; j < list.get(i).getRecords().size(); j++) {
InfluxResult influxResult = new InfluxResult();
influxResult.setCurrent(list.get(i).getRecords().get(j).getValues().get("current").toString());
influxResult.setEnergyUsed(list.get(i).getRecords().get(j).getValues().get("energyUsed").toString());
influxResult.setPower(list.get(i).getRecords().get(j).getValues().get("power").toString());
influxResult.setVoltage(list.get(i).getRecords().get(j).getValues().get("voltage").toString());
influxResult.setTime(list.get(i).getRecords().get(j).getValues().get("_time").toString());
System.err.println(list.get(i).getRecords().get(j).getValues().toString());
results.add(influxResult);
}
}
return results;
}
/**
* description: 查询一小时内的InsertParams所有数据
* date: 2022/1/21 13:44
* author: zhouhong
* @param * @param null
* @return
*/
private List<FluxTable> queryInfluxAll(){
String query = " from(bucket: \"tom\")" +
" |> range(start: -60m, stop: now())" +
" |> filter(fn: (r) => r[\"_measurement\"] == \"influx_test\")" +
" |> pivot( rowKey:[\"_time\"], columnKey: [\"_field\"], valueColumn: \"_value\" )";
return influxBean.queryTable(query);
}
/**
* description: 根据某一个字段的值过滤(查询 用电量 energyUsed 为 322 的那条记录)
* date: 2022/1/21 12:44
* author: zhouhong
* @param * @param null
* @return
*/
public List<FluxTable> queryFilterByEnergyUsed(){
String query = " from(bucket: \"tom\")" +
" |> range(start: -60m, stop: now())" +
" |> filter(fn: (r) => r[\"_measurement\"] == \"influx_test\")" +
" |> filter(fn: (r) => r[\"energyUsed\"] == \"322\")" +
" |> pivot( rowKey:[\"_time\"], columnKey: [\"_field\"], valueColumn: \"_value\" )";
return influxBean.queryTable(query);
}
}
C、测试
1、插入 localhost:9998/inlfuxdb/insert
入参:
{
"energyUsed":"23.12",
"power":"321.60",
"current":"782.72",
"voltage":"67.43"
}
返回:
{
"success": true,
"code": 200,
"message": "请求成功",
"localizedMsg": "请求成功",
"data": null
}
2、查询所有
入参:
{}
返回:
{
"success": true,
"code": 200,
"message": "请求成功",
"localizedMsg": "请求成功",
"data": [
{
"energyUsed": "23.12",
"power": "321.60",
"current": "782.72",
"voltage": "67.43",
"time": "2022-01-20T17:51:01.819Z"
},
{
"energyUsed": "243.78",
"power": "541.50",
"current": "32.34",
"voltage": "89.09",
"time": "2022-01-20T17:33:47.246Z"
}
]
}
D、Flux常见查询语句
1、指定数据源:from(bucket:"tom")
//使用绝对时间
from(bucket:"tom")
|> range(start: 2022-01-05T23:30:00Z, stop: 2022-01-21T00:00:00Z)
//过去十五天的数据
from(bucket:"tom")
|> range(start: -15d)
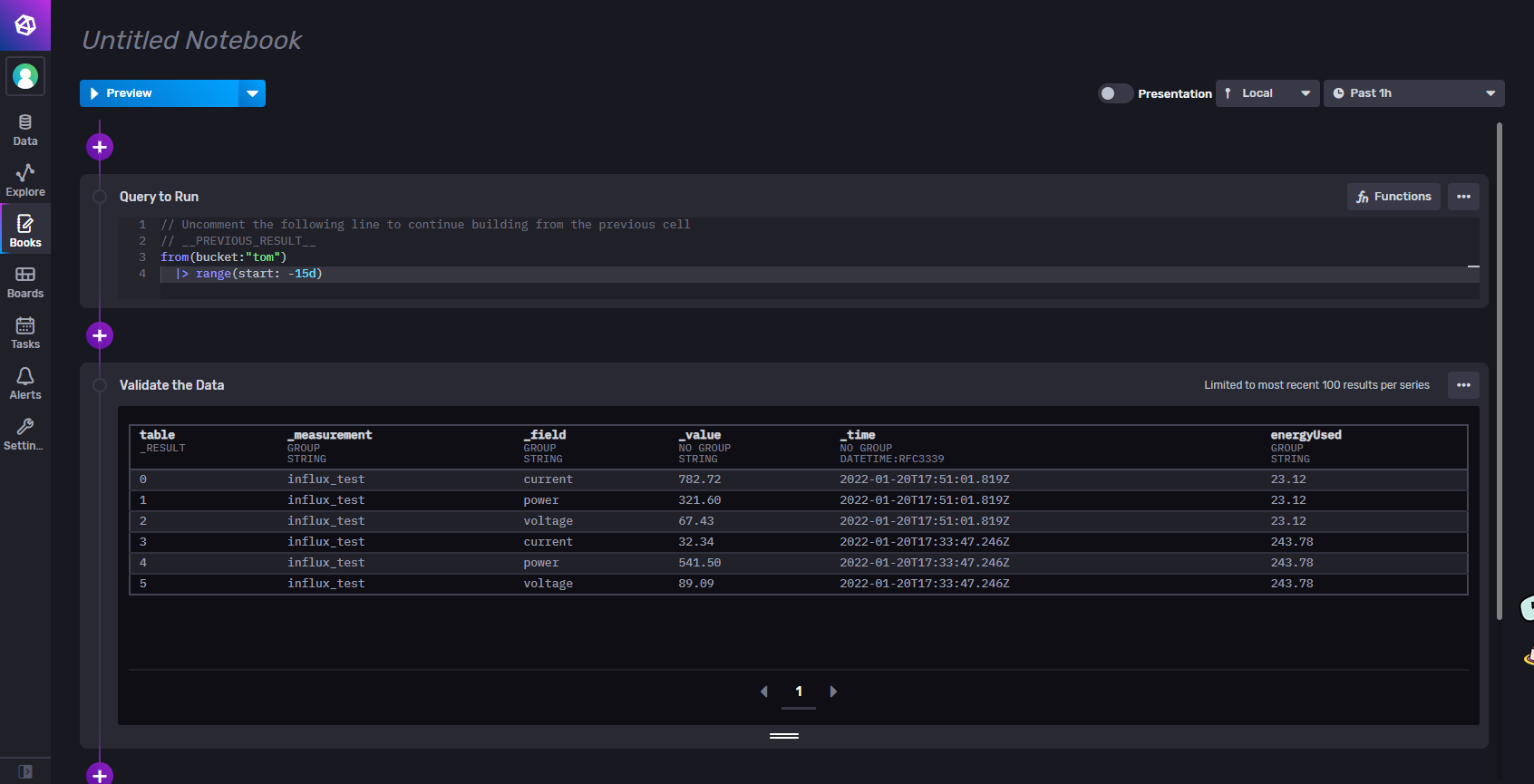
2、数据过滤
// 根据 _measurement 和 _field 过滤
from(bucket:"tom")
|> range(start: -15d)
|> filter(fn: (r) =>
r._measurement == "influx_test" and
r._field == "power" and
r.energyUsed == "23.12"
)

3、数据转换
from(bucket:"tom")
|> range(start: -15d)
|> filter(fn: (r) =>
r._measurement == "influx_test"
)
|> window(every: 10m) from(bucket:"tom")
|> range(start: -15d)
|> filter(fn: (r) =>
r._measurement == "influx_test"
)
|> window(every: 10m)
|> mean()
Docker安装InfluxDB1.x和InfluxDB2.x以及与SpringBoot整合的更多相关文章
- Docker安装Jenkins 从GitLab上拉取代码打包SpringBoot项目并部署到服务器
1. 安装Jenkins 采用 Docker 方式安装 jenkins 首先,宿主机上需要安装java和maven,这里我的安装目录如下: 由于是docker安装,jenkins将来是在容器里面运行 ...
- 理解Docker(1):Docker 安装和基础用法
本系列文章将介绍Docker的有关知识: (1)Docker 安装及基本用法 (2)Docker 镜像 (3)Docker 容器的隔离性 - 使用 Linux namespace 隔离容器的运行环境 ...
- docker安装
系统要求:需要一个64位的centos7操作系统和版本3.10或更高版本的Linux内核 开始安装: uname -r //查看内核版本yum -y update //更新系统更新到最新 #安装d ...
- 2. Docker - 安装
一.Docker介绍 1. Docker是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的容器中,然后发布到任何流行的Linux机器上, 也可以实现虚拟化. 容器时完全使用沙 ...
- Docker 安装部署
Docker学习笔记 一.Ubuntu Docker 安装 (1).获取最新版本Docker安装包 lyn@lyn:/data/docker$ sudo wget -qO- https://get.d ...
- docker 安装
Docker使用了一种叫AUFS的文件系统,这种文件系统可以让你一层一层地叠加修改你的文件,最底下的文件系统是只读的,如果需要修改文件,AUFS会增加一个可写的层(Layer),这样有很多好处,例如不 ...
- Docker安装及基本使用方法
Docker安装 CentOS6上安装Docker # yum -y install epel-release # yum -y install docker-io CentOS7上安装Docker ...
- Mac 下 docker安装
http://www.th7.cn/system/mac/201405/56653.shtml Mac 下 docker安装 以及 处理错误Cannot connect to the Docker d ...
- docker安装caffe
[最近一直想要学习caffe,但是苦苦纠结于环境安装不上,真的是第一步都迈不出去,还好有docker的存在!下面,对本人如何利用docker安装caffe做以简单叙述,不属于教程,只是记录自己都做了什 ...
- Docker安装Gitlab
一.Ubuntu16.4上Docker安装Gitlab 1.安装docker 参见:https://docs.docker.com/engine/installation/linux/ubuntuli ...
随机推荐
- 用 C# 写脚本 如何输出文件夹内所有文件名
大部分在 Windows 下的脚本都是使用 bat 或 cmd 写的,这部分的脚本对我来说可读性不好.这个可读性也是很主观的,对我来说用 C# 写脚本的可读性很强,但是换个小伙伴就不是了.在 .NET ...
- R6_ES在互联网公司应用案例汇总参考
Elasticsearch 是一个实时分布式搜索数据分析引擎,内部使用lucene做索引与搜索,能够解决常规和各种类型数据的存储及检索需求,典型的应用场景有:数据分析,站内搜索,ELK,电商等,主要特 ...
- 【爬虫+情感判定+饼图+Top10高频词+词云图】"王心凌"热门弹幕python舆情分析
目录 一.背景介绍 二.代码讲解-爬虫部分 2.1 分析弹幕接口 2.2 讲解爬虫代码 三.代码讲解-情感分析部分 3.1 整体思路 3.2 情感分析打标 3.3 统计top10高频词 3.4 绘制词 ...
- 04 elasticsearch学习笔记-Rest风格说明
目录 Rest风格说明 关于文档的基本操作 添加数据PUT 查询 修改文档 删除索引或者文档 Rest风格说明 Rest风格说明 method url地址 描述 PUT localhost:9200/ ...
- element Tree 树形控件
文档地址 https://element.eleme.cn/#/zh-CN/component/tree 代码地址 https://gitee.com/wBekvam/vue-shop-admin/b ...
- 使用SQL Server语句统计某年龄段人数占总人数的比例(多层查询语句嵌套-比例分析)
需求:需统计出某个集合内,某个段所占的比例,涉及SELECT查询语句的嵌套,如有疑问可留言. 如下: --按性别进行年度挂号年龄段分析--男SELECT 年龄段,SUM(人数) 数量,cast(cas ...
- HBase Meta 元信息表修复实践
作者:vivo 互联网大数据团队 - Huang Guihu.Chen Shengzun HBase是一款开源高可靠.高可扩展性.高性能的分布式非关系型数据库,广泛应用于大数据处理.实时计算.数据存储 ...
- 几行命令用minikube快速搭建可测试的kubernetes单节点环境
几行命令用minikube快速搭建可测试的kubernetes单节点环境 需要docker环境,https://www.cnblogs.com/xiaofei12/p/17544579.html,网速 ...
- Splashtop Enterprise提供全面的远程访问和远程支持解决方案
全球领先的远程访问和远程支持解决方案领导者 Splashtop Inc. 发布了全新的 Splashtop Enterprise ,这是一个全面的远程访问和远程支持解决方案,满足企业的IT人员,服 ...
- java学习之旅(day.04)
运算符 算术运算符:+ ,- ,* ,/,%(取余或模运算), ++(自增),-- (自减) 赋值运算符:= 关系运算符:>, <,>=, <=, ==, !=(不等于),in ...