为什么MySQL 默认隔离级别是RR,又被阿里设置为RC
我们知道,我们可以通过这个命令查看数据库当前的隔离级别,MySQL 默认隔离级别是RR.
select @@tx_isolation;ANSI/ISO SQL定义的标准隔离级别有四种,从高到底依次为:可序列化(Serializable)、可重复读(Repeatable Reads)、提交读(Read Committed)、未提交读(Read Uncommitted)。

- RU隔离级别下,可能发生脏读、幻读、不可重复读等问题。
未提交读的数据库锁情况(实现原理)
事务在读数据的时候并未对数据加锁。
事务在修改数据的时候只对数据增加行级共享锁。
- RC隔离级别下,解决了脏读的问题,存在幻读、不可重复读的问题。
提交读的数据库锁情况
事务对当前被读取的数据加 行级共享锁(当读到时才加锁),一旦读完该行,立即释放该行级共享锁;
事务在更新某数据的瞬间(就是发生更新的瞬间),必须先对其加 行级排他锁,直到事务结束才释放。
- RR隔离级别下,解决了脏读、不可重复读的问题,存在幻读的问题。
可重复读的数据库锁情况
事务在读取某数据的瞬间(就是开始读取的瞬间),必须先对其加 行级共享锁,直到事务结束才释放;
事务在更新某数据的瞬间(就是发生更新的瞬间),必须先对其加 行级排他锁,直到事务结束才释放。
- Serializable隔离级别下,解决了脏读、幻读、不可重复读的问题。
可序列化的数据库锁情况
事务在读取数据时,必须先对其加 表级共享锁 ,直到事务结束才释放;
事务在更新数据时,必须先对其加 表级排他锁 ,直到事务结束才释放。
虽然可序列化解决了脏读、不可重复读、幻读等读现象。但是序列化事务会产生以下效果:
1.无法读取其它事务已修改但未提交的记录。
2.在当前事务完成之前,其它事务不能修改目前事务已读取的记录。
3.在当前事务完成之前,其它事务所插入的新记录,其索引键值不能在当前事务的任何语句所读取的索引键范围中。
这四种隔离级别是ANSI/ISO SQL定义的标准定义的,我们比较常用的MySQL对这四种隔离级别是都支持的。
Oracle默认的隔离级别是 RC,而MySQL默认的隔离级别是 RR。那么,你知道为什么吗?
Oracle 的隔离级别
前面我们说过,Oracle只只支持ANSI/ISO SQL定义的Serializable和Read Committed,其实,根据Oracle官方文档给出的介绍,Oracle支持三种隔离级别:
即Oracle支持Read Committed、Serializable和Read-Only。
Read-Only只读隔离级别类似于可序列化隔离级别,但是只读事务不允许在事务中修改数据,除非用户是SYS。
在Oracle这三种隔离级别中,Serializable和Read-Only显然都是不适合作为默认隔离级别的,那么就只剩Read Committed这个唯一的选择了。
MySQL 的隔离级别
在MySQL设计之处,他的定位就是提供一个稳定的关系型数据库。而为了要解决MySQL单点故障带来的问题,MySQL采用主从复制的机制。
所谓主从复制,其实就是通过搭建MySQL集群,整体对外提供服务,集群中的机器分为主服务器(Master)和从服务器(Slave),主服务器提供写服务,从服务器提供读服务。
为了保证主从服务器之间的数据的一致性,就需要进行数据同步.
MySQL在主从复制的过程中,数据的同步是通过bin log进行的,简单理解就是主服务器把数据变更记录到bin log中,然后再把bin log同步传输给从服务器,从服务器接收到bin log之后,再把其中的数据恢复到自己的数据库存储中。
那么,binlog里面记录的是什么内容呢?格式是怎样的呢?
MySQL的bin log主要支持三种格式,分别是statement、row以及mixed。MySQL是在5.1.5版本开始支持row的、在5.1.8版本中开始支持mixed。
statement和row最大的区别,当binlog的格式为statemen时,binlog 里面记录的就是 SQL 语句的原文(这句话很重要!!!后面会用的到)。
关于这几种格式的区别,就不在这里详细展开了,之所以要支持row格式,主要是因为statement格式中存在很多问题,最明显的就是可能会导致主从数据库的数据不一致。
那么,这个主从同步和bin log我们要讲的隔离级别有啥关系呢?
有关系,而且关系很大。
因为MySQL早期只有statement这种bin log格式,这时候,如果使用提交读(Read Committed)、未提交读(Read Uncommitted)这两种隔离级别会出现问题。
比如,在MySQL官网上,有人就给官方曾经提过一个相关的Bug
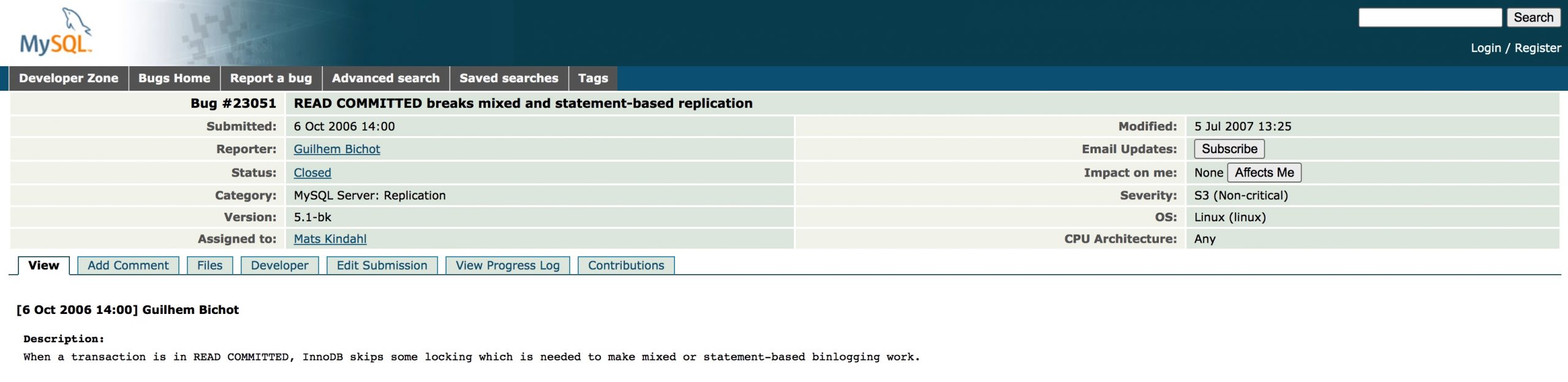
这个bug的复现过程如下:
有一个数据库表t1,表中有如下两条记录:
CREATE TABLE `t1` (
`a` int(11) DEFAULT NULL,
`b` int(11) DEFAULT NULL,
KEY `a` (`a`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
insert into t1 values(10,2),(20,1);接着开始执行两个事务的写操作:

以上两个事务执行之后,数据库里面的记录会变成(11,2)和(20,2),这个发上在主库的数据变更大家都能理解。
因为事务的隔离级别是read committed,所以,事务1在更新时,只会对b=2这行加上行级锁,不会影响到事务2对b=1这行的写操作。
以上两个事务执行之后,会在bin log中记录两条记录,因为事务2先提交,所以UPDATE t1 SET b=2 where b=1;会被优先记录,然后再记录UPDATE t1 SET a=11 where b=2;(再次提醒:statement格式的bin log记录的是SQL语句的原文)
这样bin log同步到备库之后,SQL语句回放时,会先执行UPDATE t1 SET b=2 where b=1;,再执行UPDATE t1 SET a=11 where b=2;。
这时候,数据库中的数据就会变成(11,2)和(11,2)。这就导致主库和备库的数据不一致了!!!
为了避免这样的问题发生。MySQL就把数据库的默认隔离级别设置成了Repetable Read,那么,Repetable Read的隔离级别下是如何解决这样问题的那?
那是因为Repetable Read这种隔离级别,会在更新数据的时候不仅对更新的行加行级锁,还会增加GAP lock。上面的例子,在事务2执行的时候,因为事务1增加了GAP lock,就会导致事务执行被卡住,需要等事务1提交或者回滚后才能继续执行。
除了设置默认的隔离级别外,MySQL还禁止在使用statement格式的bin log的情况下,使用READ COMMITTED作为事务隔离级别。
一旦用户主动修改隔离级别,尝试更新时,会报错:
ERROR 1598 (HY000): Binary logging not possible. Message: Transaction level 'READ-COMMITTED' in InnoDB is not safe for binlog mode 'STATEMENT'小结
所以,为什么MySQL选择RR作为默认的数据库隔离级别,其实就是为了兼容历史上的那种statement格式的bin log。
那么,为啥阿里要把这个数据库隔离级别修改成 RC 呢,背后有什么思考吗?
RR 和 RC 的区别
想要搞清楚这个问题,我们需要先弄清楚 RR 和 RC 的区别,分析下各自的优缺点。
一致性读
一致性读,又称为快照读。快照即当前行数据之前的历史版本。快照读就是使用快照信息显示基于某个时间点的查询结果,而不考虑与此同时运行的其他事务所执行的更改。
在MySQL 中,只有READ COMMITTED 和 REPEATABLE READ这两种事务隔离级别才会使用一致性读。
在 RC 中,每次读取都会重新生成一个快照,总是读取行的最新版本。
在 RR 中,快照会在事务中第一次SELECT语句执行时生成,只有在本事务中对数据进行更改才会更新快照。
在数据库的 RC 这种隔离级别中,还支持"半一致读" ,一条update语句,如果 where 条件匹配到的记录已经加锁,那么InnoDB会返回记录最近提交的版本,由MySQL上层判断此是否需要真的加锁。
锁机制
数据库的锁,在不同的事务隔离级别下,是采用了不同的机制的。在 MySQL 中,有三种类型的锁,分别是Record Lock、Gap Lock和 Next-Key Lock。
Record Lock表示记录锁,锁的是索引记录。
Gap Lock是间隙锁,锁的是索引记录之间的间隙。
Next-Key Lock是Record Lock和Gap Lock的组合,同时锁索引记录和间隙。他的范围是左开右闭的。
在 RC 中,只会对索引增加Record Lock,不会添加Gap Lock和Next-Key Lock。
在 RR 中,为了解决幻读的问题,在支持Record Lock的同时,还支持Gap Lock和Next-Key Lock;
主从同步
在数据主从同步时,不同格式的 binlog 也对事务隔离级别有要求。
MySQL的binlog主要支持三种格式,分别是statement、row以及mixed,但是,RC 隔离级别只支持row格式的binlog。如果指定了mixed作为 binlog 格式,那么如果使用RC,服务器会自动使用基于row 格式的日志记录。
而 RR 的隔离级别同时支持statement、row以及mixed三种。
为什么互联网公司选择使用 RC
提升并发
互联网公司和传统企业最大的区别是什么?
高并发!
没错,互联网业务的并发度比传统企业要高处很多。2020年双十一当天,订单创建峰值达到 58.3 万笔/秒。
要怎么做才能扛得住这么大的并发量,要做的、可以做的事情实在是太多了。
而有一个是通过修改数据库的隔离级别来提升并发度。
为什么 RC 比 RR 的并发度要好呢?
首先,RC 在加锁的过程中,是不需要添加Gap Lock和 Next-Key Lock 的,只对要修改的记录添加行级锁就行了。
这就使得并发度要比 RR 高很多。
另外,因为 RC 还支持"半一致读",可以大大的减少了更新语句时行锁的冲突;对于不满足更新条件的记录,可以提前释放锁,提升并发度。
减少死锁
因为RR这种事务隔离级别会增加Gap Lock和 Next-Key Lock,这就使得锁的粒度变大,那么就会使得死锁的概率增大。
死锁:一个事务锁住了表A,然后又访问表B;另一个事务锁住了表B,然后企图访问表A;这时就会互相等待对方释放锁,就导致了死锁。
总结
MySQL数据库的 RR 和 RC 两种事务隔离级别,主要在加锁机制、主从同步以及一致性读方面存在一些差异。
而很多大厂,为了提升并发度和降低死锁发生的概率,会把数据库的隔离级别从默认的 RR 调整成 RC。
当然,这样做也不是完全没有问题,首先使用 RC 之后,就需要自己解决幻读的问题,这个很多时候幻读问题其实是可以忽略的,或者可以用其他手段解决。
还有就是使用 RC 的时候,不能使用statement格式的 binlog,这种影响其实可以忽略不计了,因为MySQL是在5.1.5版本开始支持row的、在5.1.8版本中开始支持mixed,后面这两种可以代替 statement格式。
那么我们回答了以下问题,
1、RR和RC到底有什么区别?RR是如何解决不可重复读问题的?
2、既然MySQL数据库默认选择了RR,那么,为啥大的互联网公司会把默认的隔离级别改成RC?
然而你或许还会有以下问题:
1、row格式和statement有什么区别?使用row的情况下,可以使用RR吗?
2、文中提到的RC的GAP lock到底是什么?Next-key Lock
数据库使用锁是为了支持更好的并发,提供数据的完整性和一致性。InnoDB是一个支持行锁的存储引擎,锁的类型有:共享锁(S)、排他锁(X)、意向共享(IS)、意向排他(IX)。为了提供更好的并发,InnoDB提供了非锁定读:不需要等待访问行上的锁释放,读取行的一个快照。该方法是通过InnoDB的一个特性:MVCC来实现的。
InnoDB有三种行锁的算法:
1,Record Lock:单个行记录上的锁。
2,Gap Lock:间隙锁,锁定一个范围,但不包括记录本身。GAP锁的目的,是为了防止同一事务的两次当前读,出现幻读的情况。
3,Next-Key Lock:1+2,锁定一个范围,并且锁定记录本身。对于行的查询,都是采用该方法,主要目的是解决幻读的问题。
mysql binlog的三种格式简单概括总结
1、三种格式:row、statement、mixed
2、区别:row格式文件比较大,statement比较小,row格式保存的是一行一行的数据,statement保存的是sql语句,mixed格式介于二者之间,statement容易丢数据,row格式则不会
3、statement容易丢数据原因是,有时候,SQL语句里面会用到一些函数,比如说取当前日期的函数sysdate,你要是用statement,binlog里同步过去的就是这个带有函数的SQL语句,而主库的当前日期,和binlog同步到slave上的当前日期,肯定是有差异的,这样两条数据就不一致了,所以这样同步的数据,就会有问题
4、row是直接把表插入到备份库中,statement是导出主库语句后,导入到备份库中,存在时间差。
每种格式的概括
STATEMENT
记录的是执行的SQL语句
优点:
日志记录量相对较小, 节约磁盘及网络IO
缺点:
可能造成MySQL复制的主备服务器数据不一致
必须记录上下文信息, 以保证语句在从服务器上执行结果相同
对于特定函数如 UUID(), user() 这种非确定性函数是无法正确复制
ROW
记录的是每一行数据的修改, MySQL5.7+的默认ROW格式.
优点:
可以避免MySQL复制中出现主从不一致的问题
对每一行数据的修改比STATEMENT模式高效
可在误删改数据后, 同时无备份可以恢复时, 通过分析binlog日志进行反向处理达到恢复数据目的
缺点:
由于记录每一行数据的修改, 所以日志量比较大
可通过binlog_row_image=FULL | MINIMAL | NOBLOB 设置日志记录的方式.
FULL: 记录行中所有列修改前后的数据.
MINIMAL: 记录行中所有列修改前的数据+被修改列修改后的数据.
NOBLOB: 记录行中所有列修改前的数据+(未对行中TEXT和BLOB类型列修改时, 记录TEXT和BLOB类型以外的列的数据.)
MIXED
混合STATEMENT和ROW两种格式, MySQL会根据执行的SQL语句自动选择.
一般的复制使用STATEMENT格式,对于STATEMENT格式无法复制的操作使用ROW格式.
如何选择binlog日志格式?
在同一个IDC机房中, 建议使用MIXED或ROW格式, 当使用ROW格式时, 建议设置binlog_row_image=MINIMAL
关于以上几个问题,你对哪个更感兴趣呢?
talk is easy, show me the code
为什么MySQL 默认隔离级别是RR,又被阿里设置为RC的更多相关文章
- MySQL 默认隔离级别是RR,为什么阿里这种大厂会改成RC?
我之前写过一篇文章<为什么MySQL选择REPEATABLE READ作为默认隔离级别?>介绍过MySQL 的默认隔离级别是 Repeatable Reads以及背后的原因. 主要是因为M ...
- MySQL 日志之 binlog 格式 → 关于 MySQL 默认隔离级别的探讨
开心一刻 产品还没测试直接投入生产时,这尼玛... 背景问题 在讲 binlog 之前,我们先来回顾下主流关系型数据库的默认隔离级别,是默认隔离级别,不是事务有哪几种隔离级别,别会错题意了 1.Ora ...
- MySQL使用可重复读作为默认隔离级别的原因
一般的DBMS系统,默认都会使用读提交(Read-Comitted,RC)作为默认隔离级别,如Oracle.SQL Server等,而MySQL却使用可重复读(Read-Repeatable,RR). ...
- 事务的隔离级别,mysql默认的隔离级别是什么?
读未提交(Read uncommitted),一个事务可以读取另一个未提交事务的数据,最低级别,任何情况都无法保证. (1)所有事务都可以看到其他未提交事务的执行结果 (2)本隔离级别很少用于实际应用 ...
- MySQL的默认隔离级别的实现依赖于MVCC和锁,准确点说就是一致性读和锁。
MySQL的默认隔离级别的实现依赖于MVCC和锁,准确点说就是一致性读和锁.
- MySQL默认隔离级别为什么是RR
曾多次听到“MySQL为什么选择RR为默认隔离级别”的问题,其实这是个历史遗留问题,当前以及解决,但是MySQL的各个版本沿用了原有习惯.历史版本中的问题是什么,本次就通过简单的测试来说明一下. 1. ...
- 【MySQL 读书笔记】RR(REPEATABLE-READ)事务隔离详解
这篇我觉得有点难度,我会更慢的更详细的分析一些 case . MySQL 的默认事务隔离级别和其他几个主流数据库隔离级别不同,他的事务隔离级别是 RR(REPEATABLE-READ) 其他的主流数据 ...
- MySQL事务隔离级别的实现原理
回顾 在MySQL的众多存储引擎中,只有InnoDB支持事务,所有这里说的事务隔离级别指的是InnoDB下的事务隔离级别. 读未提交:一个事务可以读取到另一个事务未提交的修改.这会带来脏读.幻读.不可 ...
- Mysql事务隔离级
转自:http://xm-king.iteye.com/blog/770721 SQL标准定义了4类隔离级别,包括了一些具体规则,用来限定事务内外的哪些改变是可见的,哪些是不可见的.低级别的隔离级一般 ...
- 记一次Mysql事务隔离级别的坑
最近在写代码调试时,遇到了一个问题. 遇到问题 具体操作如下: 1.调用方法A,并且方法A加上了@Transactional事务注解. 2.在方法A内部,查询并更新某个字段F的值. 3.处理其他逻辑. ...
随机推荐
- java springboot监听事件和处理事件
在Spring Boot中,监听和处理事件是一种常用的模式,用于在应用程序的不同部分之间传递信息.Spring 的事件发布/订阅模型允许我们创建自定义事件,并在这些事件发生时由注册的监听器进行处理.这 ...
- Asp .Net Core 系列:基于 T4 模板生成代码
目录 简介 组成部分 分类 Visual Studio 中使用T4模板 创建T4模板文件 2. 编写T4模板 3. 转换模板 中心控制Manager 根据 MySQL 数据生成 实体 简介 T4模板, ...
- RDD入门了解
RDD即resilient distributed dataset 弹性分布式数据集,简单来说就是数据集,可以类比python的list dict:但是数据是分布式存储的,可用于分布式计算:可以存在内 ...
- Python 代码中的 yield 到底是什么?
在Python编程中,有一个强大而神秘的关键字,那就是yield.初学者常常被它搞得晕头转向,而高级开发者则借助它实现高效的代码.到底yield是什么?它又是如何在Python代码中发挥作用的呢?让我 ...
- Ubuntu 20.04 双系统安装完整教程
1.查看电脑的信息 1.1 查看BIOS模式 "win+r"快捷键进入"运行",输入"msinfo32"回车,出现以下界面,可查看BIOS模 ...
- vue pinia sessionstorage 数据存储不上的原因
vue pinia sessionstorage 的坑 默认的配置是开始 localStorage 如果用 sessionstorage 则发现数据存储不上 ,是因为缺少了序列化和反序列化 impor ...
- 【Vue】动态方法调用
JS的动态方法调用是通过eval函数实现 但是在Vue中是通过组件的$options.methods实现, 写这篇的随笔的原因是因为今天为了封装面包屑组件,花了一下午折腾这个动态方法调用 调用DEMO ...
- 【Hibernate】04 主键策略 & CRUD
实体类编写规范: - 每个属性不应该被公开的访问,设置私有 - 提供可以访问和设置的方法,GETTER & SETTER - 必须编写一个主键属性[ID 唯一值] - 建议使用基本类型的包装类 ...
- 【Vue】Re06 组件化
将一个应用页面拆分成若干个可重复使用的组件 一.Vue的组件的使用步骤: 1.创建组件构造器 2.注册组件 3.使用组件 <!DOCTYPE html> <html lang=&qu ...
- 大语言模型(LLM)运行报错:AttributeError: module 'streamlit' has no attribute 'cache_resource'
解决方法: https://blog.csdn.net/javastart/article/details/130785100 (图:https://blog.csdn.net/javastart/a ...