minos 1.1 内存虚拟化——hyp
- 首发公号:Rand_cs
minos 1.1 内存虚拟化——hyp
内存虚拟化,目前理解主要两方面:
- 内存管理,没有虚拟化的情况时,对于 Linux 内核运行在物理硬件之上,内核需要管理物理内存,需要管理进程的虚拟内存。类似,type1 类型的 hypervisor/minos 运行在物理硬件上,minos 需要对物理内存管理,需要对虚机使用的内存进行管理。这里的管理,可以简单理解为内存的组织形式,内存分配与回收方式
- 地址转换,这部分主要与硬件相关,围绕页表的一系列的 ARMv8 硬件知识。对于虚拟化,ARMv2 支持硬件的 stage2 地址转换
本文主要就从这两个方面来讲述内存虚拟化的第一节,主要是 hypervisor 一层的内容。这里对后文讲述做一些约定,在本项目中,minos、hypervisor、kernel、host os 指的是同一个东西,指的是直接运行在硬件上,运行在 EL2 异常级别的那一层软件。(没有虚拟化的情况下,minos 本身也可以被编译为运行在 EL1 上的 kernel,某些地方容易引起歧义我再详述)
Address Translation
先讨论没有虚拟化的情况,对于 os 来说,用户态程序和内核使r用不同的页表,用户态的页表存放在 TTBR0_EL1,内核页表存放在 TTBR1_EL1。而 x86 架构下用户态和内核态使用一张页表,存放在 CR3 寄存器中。
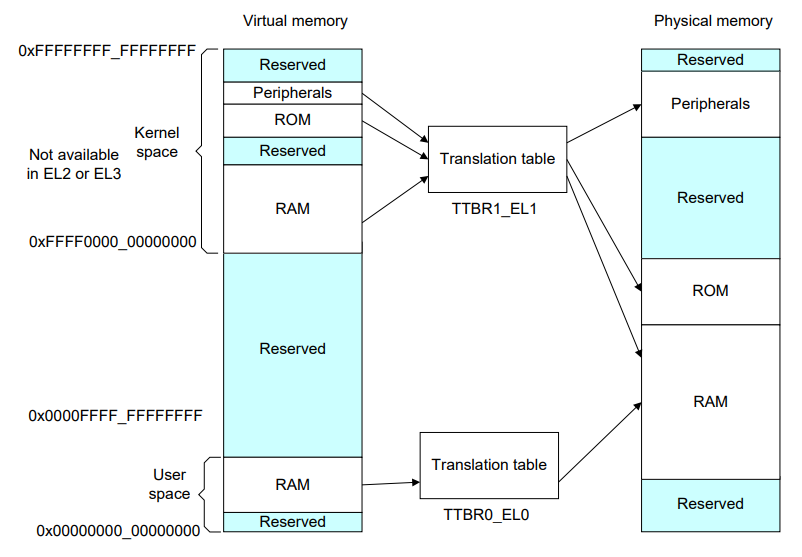
内核位于虚拟地址空间中的高处,其地址都是以 111... 开头,经过 TTBR1_EL1 中的页表转换成物理地址。用户态的应用程序都是位于虚拟地址空间中的低处,其地址以 000... 开头,经过 TTBR0_EL1 中的页表转换成物理地址
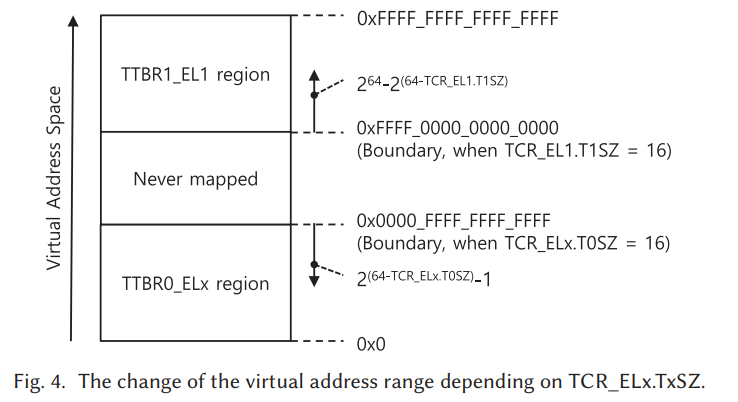
内核地址空间+用户地址空间并不是整个虚拟地址空间,它们的大小由 TCR_EL1.TxSZ 控制。TCR_EL1,Translation Control Register(EL1),顾名思义,专门来控制地址转换的一个寄存器,而且是控制 EL0 和 EL2 的地址转换。
TCR_EL1.TxSZ 用来控制内核/用户虚拟地址空间的大小,T1SZ, bits [21:16] T1SZ,T0SZ, bits [5:0],它们都占据 6 bits,可以简单理解为它们控制最高有效 1/0 的起始位置,举个例子如下图所示:
对于实际的地址转换流程,相信大家已经很熟悉了,直接来看一下 arm 平台地址转换的一个例子:
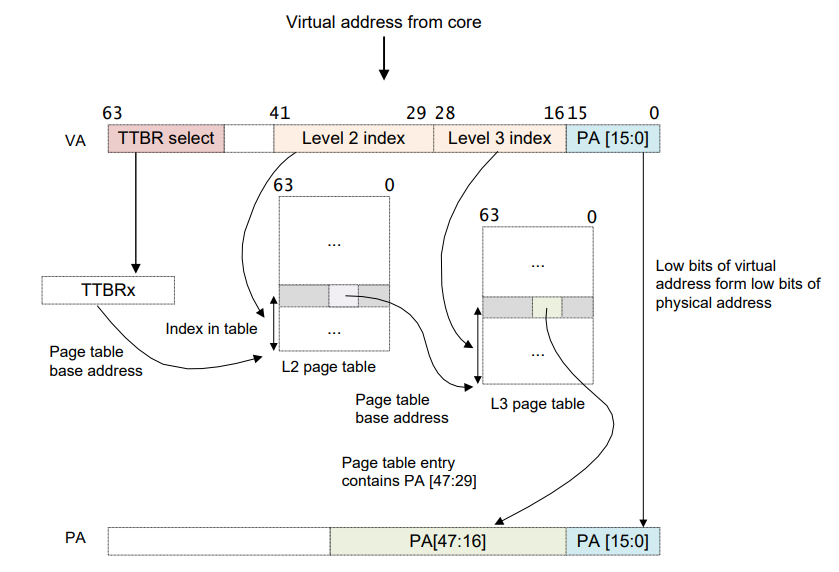
上述是页大小为 64K,虚拟地址为 42 位的情况下,虚拟地址转换到物理地址的流程。对于上图中页大小、TTBR select 的位数等信息都可以通过系统寄存器来设置,具体的后面分析到代码再说,这里只是简单再过一下地址转换的流程。对比以前 x86 架构下地址转换的流程,区别就在于 arm 地址转换时,mmu 会根据地址的最高几位来选取页表基址寄存器,如果最高位以 1 开头那么是内核地址,选取 TTBR1_EL1,反之以 0 开头的地址为用户态地址选取 TTBR0_EL0
Stage2 Translation
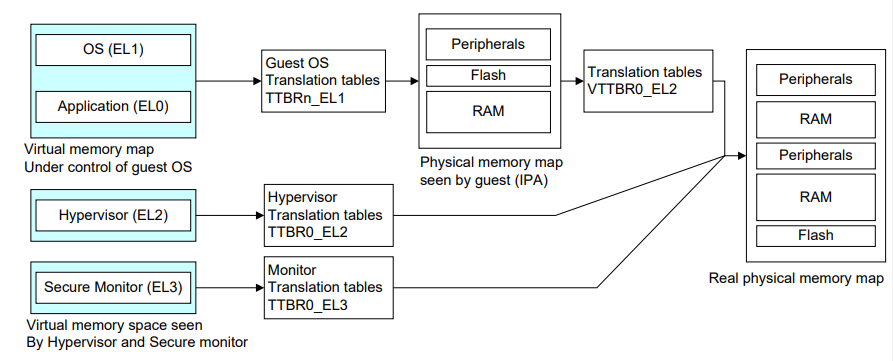
上述讲述的是无虚拟化的情况,如果存在虚拟化的话。前面所说的 os 为 guest os,其内的虚拟地址 va 不变,但是经过 TTBRx_EL1 转换的地址并不是真实的物理地址,这里我们称为 ipa(Intermediate Physical Address,中间物理地址),要再经过存放在 VTTBR0_EL2 中的页表(Virtula Tranlation Table Base Register,虚拟页表基址寄存器)的转换,才是最后真正的物理地址 pa。也就是会经过 va->ipa->pa 的转换
每个进程有自己的页表,每次切换进程的时候由 guest os 将其页表基址写进 TTBR0_EL1。而虚拟页表是每个虚拟机一个,切换虚拟机的时候,由 Hyp 将该虚拟机的虚拟页表基址写到 VTTBR_EL2.
对于 EL2 层的 hypervisor 和 EL3 层的 Secure Monitor 来说,没有 stage2 translation。如果当前位于 EL2,Hyp 中的虚拟地址经过位于 TTBR0_EL2 中存放的页表直接就转换为了物理地址。EL3 的 Secure Monitor 同理。
内存概览
minos 是 type1 类型的虚拟机,minos 这个 hyp 是直接运行在物理硬件上的,它就相当于没有虚拟化时候的操作系统,需要实现内存管理,进程管理等等。
在 boot 阶段首先需要对整个物理内存进行初始化(分析设备树节点,记录内存起始位置,建立初始映射等等操作),但本文我们先略过 boot 阶段对内存的初始化,直接来看初始化后的结果,具体初始化流程放在后面启动来讲述。
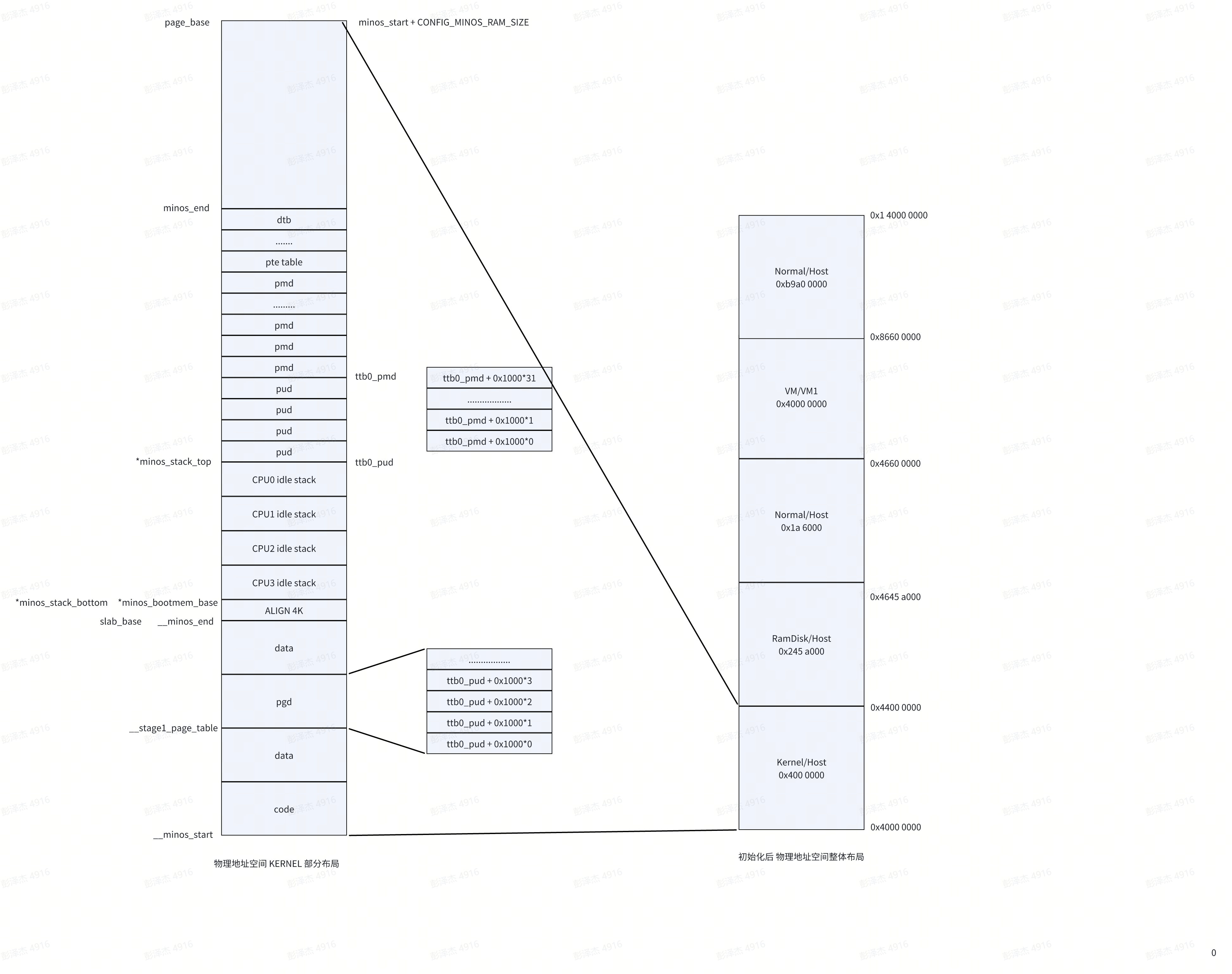
这是内存初始化后,物理内存总览图。
memory@40000000 {
reg = < 0x00 0x40000000 0x01 0x00 >;
device_type = "memory";
};
上述代码是 minos 运行在 qemu 平台上使用的设备树文件中关于内存节点的描述,我们可以知道该物理内存的起始地址为 $$0x00 << 32 + 0x4000\ 0000$$ ,大小为 $$0x01 << 32 + 0x00 = 0x1\ 0000\ 0000$$,也就是 4 个 G,但实际大小还要看 qemu 的启动参数,比如说我现在启动时通过 -m 2G 指定内存大小为 2G,实际的大小以这个 qemu 启动时的参数为准。
然后这 2G 的内存在初始化后又被分为 5 个部分:
- 0x4000 0000 ~ 0x4400 0000 是 minos 本身所处区域,其中包括了 minos 镜像、dtb 镜像,以及预留了一部分内存用来分配页表,minos 相关数据结构等等。简单来说,minos 的 malloc 会从中分配内存
- 0x4400 0000 ~ 0x4645 a000 是 ramdisk 区域,minos 设计了一个 ramdisk,里面存放的是 host vm 的 kernel 镜像和 dtb 镜像。当我们创建 hvm 的时候,就会从中读取镜像数据,然后加载到内存特定位置
- 0x4645 a000 ~ 0x4660 0000、0x8660 0000 ~ 0x1 4000 0000 两部分区域内存可以看作是空闲内存,后面我们会了解到,这两部分内存会全部转换成 block 的形式,当创建普通 vm 的时候,就会从中分配内存
- 0x4660 0000 -> 0x8660 0000,这部分内存分配给了 hvm,hvm 也是启动时期就创建了
这一部分都是物理地址空间的布局,虚拟地址空间呢?我们知道启动的时候会开启 MMU,在这之前肯定需要先创建一张页表(启动的时候位于 EL2,创建了一张 EL2 的页表给 minos 使用),然后将其基址赋值给 TTBR_EL2,最后再使能 MMU,随后便会使用虚拟地址来访问物理内存。
minos 的映射关系很简单,物理内存直接映射到虚拟内存,比如说 0x4000 0000 这个虚拟地址就是对应着物理地址 0x4000 0000。其他几大区域基本上也是直接映射,具体情况我们后面再讨论,只要知道 minos 区域是直接映射的。
左侧图片,则是关于第一部分 minos 区域的详细布局,这里暂不具体展开,同样待到启动的时候讲述,这里只需要注意 page_base 与 minos_end 两个指针所指位置。另外上面所说建立 minos 区域直接映射,这个页表就是左侧图中的 pgd pud pmd pte。
mem_region
上面提到了 mem_region,在 minos 中,mem_region 是最大的“内存单位”
#define MAX_MEMORY_REGION 16
static struct memory_region memory_regions[MAX_MEMORY_REGION];
// 下一个空闲 memory_region 下标
static int current_region_id;
// 使用中的 memory_region 组成了一个链表,mem_list 是其头节点
LIST_HEAD(mem_list);
enum {
MEMORY_REGION_TYPE_NORMAL = 0,
MEMORY_REGION_TYPE_DMA,
MEMORY_REGION_TYPE_RSV,
MEMORY_REGION_TYPE_VM,
MEMORY_REGION_TYPE_DTB,
MEMORY_REGION_TYPE_KERNEL,
MEMORY_REGION_TYPE_RAMDISK,
MEMORY_REGION_TYPE_MAX
};
struct memory_region {
int type;
int vmid; // 0 is host
phy_addr_t phy_base;
size_t size;
struct list_head list;
};
整个系统最多定义 16 个 memory_region,全局静态定义,memory_region 目前总共 7 种类型。struct memory_region 主要就是记录了内存段的起始位置和大小。
所有正使用的 memory_region 组成一个链表,头节点为 mem_list
add_memory_region 函数将会新增一个 memory_region,然后注册到 mem_list(就是申请一个 memory_region,记录信息,然后链接到 mem_list 当中去)
split_memory_region 将会从现有的 memory_region 中分割出一个新的 memory_region,然后注册到 mem_list。
在当前的 minos 整个系统中,add_memory_region 函数实际只会调用一次,就是在启动分析设备树 memory 节点时,将这个内存节点信息记录在第一个 memory_region 中,然后注册到 mem_list。后续的所有 memory_region,都是从第一个 memory_region 中分割出来的。
如果 minos 这个 hypervisor 后续继续迭代,应该会有内存热插拔等功能,到时候可能就有 delete_memory_region,add_memory_region 也会在增加内存的时候调用。
minos KERNEL 区域内存管理
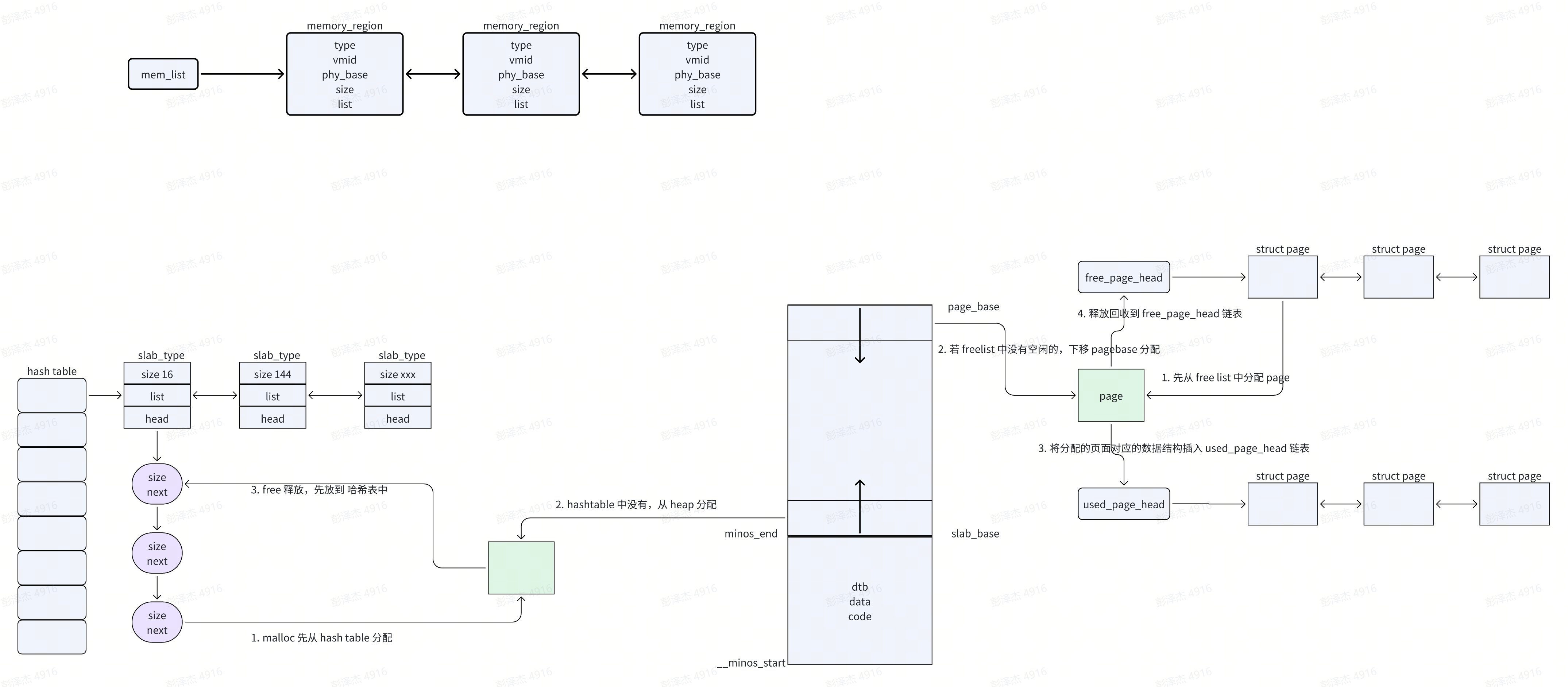
minos 对 KERNEL 区域的内存管理主要几种在 memory.c 文件中,对于此部分的内存管理很简单
- malloc 和 free 接口,minos 使用哈希表来维护了一个简易的内存池,当使用 malloc 分配内存时,先从哈希表中分配,如果没有,那么上移 slab_base 指针来分配内存。释放的时候直接释放到哈希表中
- alloc_page 和 free_page 用来分配整页(4096 整数倍),同样的使用 used_page_head、free_page_head 来维护了一个简易的内存池。当使用 alloc_page 分配整页内存的时候,先从 free_page_head 链表中查看是否有空闲页,如果没有下移 page_base 指针来分配。释放的时候直接将相关信息记录到 struct page,然后将其插入到 free_page_head 链表当中
逻辑很简单,我们快速过一下这部分代码
// 从 hashtable 中分配内存
static void *malloc_from_hash_table(size_t size)
{
// 当前分配的 size 属于哪一个 hash 桶
int id = hash_id(size);
struct slab_type *st;
struct slab_header *sh;
/*
* find the related slab mem id and try to fetch
* a free slab memory from the hash cache.
*/
// 遍历该 hash 桶指向的链表
list_for_each_entry(st, &slab_hash_table[id], list) {
//寻找大小相等的节点
if (st->size != size)
continue;
if (st->head == NULL)
return NULL;
sh = st->head;
st->head = sh->next;
sh->magic = SLAB_MAGIC;
// 返回给“用户”使用的内存起点
return ((void *)sh + SLAB_HEADER_SIZE);
}
return NULL;
}
从 hash 表中分配内存,分配的每个大小内存都属于一个哈希桶,然后从中寻找是否有空闲的内存
// 从 slab_heap 中分配内存
static void *malloc_from_slab_heap(size_t size)
{
unsigned long slab_size;
struct slab_header *sh;
if (ULONG(slab_base) >= ULONG(page_base)) {
pr_err("no more memory for slab\n");
return NULL;
}
// 计算当前 slab size 总大小
slab_size = ULONG(page_base) - ULONG(slab_base);
size += SLAB_HEADER_SIZE;
// 如果小于要分配的大小,返回空
if (slab_size < size) {
pr_err("no enough memory for slab 0x%x 0x%x\n",
size, slab_size);
return NULL;
}
sh = (struct slab_header *)slab_base;
sh->magic = SLAB_MAGIC;
sh->size = size - SLAB_HEADER_SIZE;
slab_base += size;
return ((void *)sh + SLAB_HEADER_SIZE);
}
从 slab base 分配内存,更简单了,就是一个上移指针的操作
// malloc 分配内存,先从 hash table 里面分配,再从 slab heap 中分配
static void *__malloc(size_t size)
{
void *mem;
// 先从 hash table 里面分配
mem = malloc_from_hash_table(size);
if (mem != NULL)
return mem;
// 没有,再从 slab heap 里面分配
return malloc_from_slab_heap(size);
}
void *malloc(size_t size)
{
void *mem;
ASSERT(size != 0);
// 对齐
size = get_slab_alloc_size(size);
spin_lock(&mm_lock);
// 分配
mem = __malloc(size);
spin_unlock(&mm_lock);
// 检查
if (!mem) {
pr_err("malloc fail for 0x%x\n");
dump_stack(NULL, NULL);
}
// 返回
return mem;
}
malloc 接口,首先对齐,然后尝试从 hash table 里面分配,没分配到再从 slab_heap 分配。
void free(void *addr)
{
ASSERT(addr != NULL);
spin_lock(&mm_lock);
free_slab(addr);
spin_unlock(&mm_lock);
}
// 释放 addr 处的内存,释放到 hash table
static void free_slab(void *addr)
{
struct slab_header *header;
struct slab_type *st;
int id;
ASSERT(ULONG(addr) < ULONG(slab_base));
header = (struct slab_header *)((unsigned long)addr -
SLAB_HEADER_SIZE);
ASSERT(header->magic == SLAB_MAGIC);
id = hash_id(header->size);
list_for_each_entry(st, &slab_hash_table[id], list) {
if (st->size != header->size)
continue;
header->next = st->head;
st->head = header;
return;
}
/*
* create new slab type and add the new slab header
* to the slab cache.
*/
// 创建新的 描述符,然后插入到哈希表中
st = malloc_from_slab_heap(sizeof(struct slab_type));
if (!st) {
pr_err("alloc memory for slab type failed\n");
return;
}
st->size = header->size;
st->head = NULL;
list_add_tail(&slab_hash_table[id], &st->list);
header->next = st->head;
st->head = header;
}
释放内存的操作,找到该内存大小对应的哈希桶,然后插入到相关链表就行了。另外有意思的是在释放内存的时候,可能需要上移 slab_base 指针分配一个 struct slab_type 结构来记录将要释放的这块内存信息
// page_base 向下移来分配实际的页面
static struct page *alloc_new_pages(int pages, unsigned long align)
{
unsigned long tmp = (unsigned long)page_base;
struct page *recycle = NULL;
unsigned long base, rbase;
struct page *page;
// page base 向下移动来实际分配页面
base = tmp - pages * PAGE_SIZE;
base = ALIGN(base, align);
// 这种情况是说内存不够了,如果分配的话,page_base 和 slab_base 都相撞了
if (base < (unsigned long)slab_base) {
pr_err("no more pages %d 0x%x\n", pages, align);
return NULL;
}
// 这种情况应是 page_base 的对齐级别和 align 要求有差,比如说 align 要求 8K 对齐
// 但是 page_base 只是 4K 对齐,这样 rbase 的值就会小于初始的 page_base
// 此时对于 [rabse, page_base] 之间的内存我们放入 free_list_head
rbase = base + pages * PAGE_SIZE;
if (rbase != tmp) {
recycle = __malloc(sizeof(struct page));
if (!recycle) {
pr_err("can not allocate memory for page\n");
return NULL;
}
recycle->pfn = rbase >> PAGE_SHIFT;
recycle->flags = 0;
recycle->align = 1;
recycle->cnt = (tmp - rbase) >> PAGE_SHIFT;
recycle->next = NULL;
__free_page(recycle);
}
// 分配 page 结构体来记录页属性
page = __malloc(sizeof(struct page));
if (!page) {
pr_err("can not allocate memory for page\n");
if (recycle)
free_slab(recycle);
return NULL;
}
page->pfn = base >> PAGE_SHIFT; //页号
page->flags = 0; //也属性
page->cnt = pages; //共几页
page->align = align >> PAGE_SHIFT; //几页对齐
page->next = NULL;
page_base = (void *)base; // 更新 page_base 指针
return page;
}
下移 page_base 的方式来分配整页内存
static struct page *__alloc_pages(int pages, int align)
{
struct page *page = NULL;
struct page *tmp, *prev = NULL;
switch (align) {
case 1:
case 2:
case 4:
case 8:
break;
default:
pr_err("%s:unsupport align value %d\n", __func__, align);
return NULL;
}
spin_lock(&mm_lock);
tmp = free_page_head;
/*
* try to get the free page from the free list.
*/
// 先从 free_page_head 中寻找是否有合适的 page 页面
while (tmp) {
if ((tmp->cnt == pages) && (tmp->align == align)) {
page = tmp;
break;
}
prev = tmp;
tmp = tmp->next;
}
// 没有找到的话,直接使得 page_base 向下移动来分配页面
if (!page) {
page = alloc_new_pages(pages, PAGE_SIZE * align);
// 如果在 free_page_head 中找到了合适的 page,直接返回
} else {
if (prev != NULL) {
prev->next = page->next;
page->next = NULL;
} else {
free_page_head = NULL;
}
}
// 向 used_page_head 中记录分配出去的页面
add_used_page(page);
spin_unlock(&mm_lock);
return page;
}
此函数便会先尝试在 free_page_head 中分配内存,没有分配到的话,下移 page_base 指针分配,并将其对应的 struct page 插入到 used_page_head
void *__get_free_pages(int pages, int align)
{
struct page *page = NULL;
page = __alloc_pages(pages, align);
if (!page)
return NULL;
return (void *)ptov(pfn2phy(page->pfn));
}
static inline void *get_free_pages(int pages)
{
return __get_free_pages(pages, 1);
}
static void *stage1_get_free_page(unsigned long flags)
{
return get_free_page();
}
minos 中会有很多类似 get_free_page 来获取一页内存,底层都是调用 __alloc_pages
页表
这部分来看一下 ARMv8 架构下的页表结构,以及如何建立虚拟地址到物理地址的映射关系。
页表结构
页表结构主要就是了解页表项,在 ARM 平台有 4 种页表项,如下图所示:
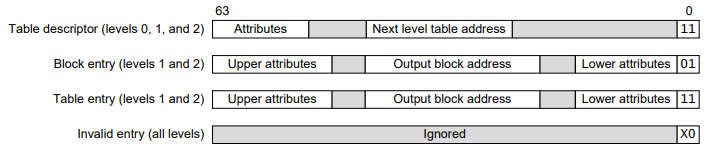
现在 64 位系统几乎都使用 4 级页表,从高到低(level 0 ~ level 3)我们通常称为 PGD(Page Global Directory)、 PUD(Page Upper Directory)、PMD(Page Middle Directory)、PT(Page Table),页表每一项称作 PTE(page table entry)。
页表项有 4 种,以结尾 bit0-1 来区分,如上图所示。level0 只能是 Table Descriptor,输出下一级页表的物理地址
页表操作
有关页表的操作函数存放在 stage1.c 文件里面,这里说明一下 minos 中的 stage1 的含义,根据我的理解,stage1 转换指的是虚拟机中的 “虚拟地址”(va) 到 “物理地址”(ipa)的转换,stage2 是 “中间物理地址”(ipa)到 “真正物理地址”(pa)的转换。
但是 minos 项目中所述的 stage1 应当不是此含义,minos 中的 stage1 指的是 hypervisor 层级地址转换,也就是说当 cpu 运行在 el2 时的地址转换,此时使用 TTBR_EL2。反过来想,stage1 的地址转换相关函数应该位于 guest,也就是 Linux 内核代码,不应该出现于 minos 代码中。所以 minos 的 stage1 转换实际指的是 hypervisor 层级的地址转换,这也恰好对应这 host 这个词汇
从 create_host_mapping 可以看出,host 的 mapping,然后调用 stage1 相关函数
下面我们直接来看相关的页表操作相关函数的实现
// 建立 level3 页表映射,pte 级别,对 start ~ end 之间所有的页进行映射
static int stage1_map_pte_range(struct vspace *vs, pte_t *ptep, unsigned long start,
unsigned long end, unsigned long physical, unsigned long flags)
{
unsigned long pte_attr;
pte_t *pte;
pte_t old_pte;
// 获取地址 start 对应的 pte
// ((pte_t *)(ptep) + (((((unsigned long)start) & 0x0000fffffffff000UL) >> 12) & (512 - 1)))
pte = stage1_pte_offset(ptep, start);
// 根据 flags 参数设置页表项属性
pte_attr = stage1_pte_attr(0, flags);
do {
old_pte = *pte;
if (old_pte)
pr_err("error: pte remaped 0x%x\n", start);
// 写 pte,pte 的数据就是 属性+物理地址
stage1_set_pte(pte, pte_attr | physical);
// 循环,知道 start ~ end 区间内的页面都映射了
} while (pte++, start += PAGE_SIZE, physical += PAGE_SIZE, start != end);
return 0;
}
// 建立 pmd 级别的页表映射
static int stage1_map_pmd_range(struct vspace *vs, pmd_t *pmdp, unsigned long start,
unsigned long end, unsigned long physical, unsigned long flags)
{
unsigned long next;
unsigned long attr;
pmd_t *pmd;
pmd_t old_pmd;
pte_t *ptep;
size_t size;
int ret;
// 获取 addr 对应的 pmd 表项
pmd = stage1_pmd_offset(pmdp, start);
do {
next = stage1_pmd_addr_end(start, end);
size = next - start;
old_pmd = *pmd;
/*
* virtual memory need to map as PMD huge page
*/
// 如果要映射成大页,直接设置 pmd 表项完事儿
if (stage1_pmd_huge_page(old_pmd, start, physical, size, flags)) {
attr = stage1_pmd_attr(physical, flags);
stage1_set_pmd(pmd, attr);
//
} else {
// 如果原来的 pmd 表项是空的
if (stage1_pmd_none(old_pmd)) {
// 获取一页
ptep = (pte_t *)stage1_get_free_page(flags);
if (!ptep)
return -ENOMEM;
// 初始化清零
memset(ptep, 0, PAGE_SIZE);
// 填充 pmd 表项,地址指向新分配的页面
stage1_pmd_populate(pmd, (unsigned long)ptep, flags);
// 否则原来的pmd 表项非空
} else {
// 直接获取 pmd 指向的 pte 级页表地址
ptep = (pte_t *)ptov(stage1_pte_table_addr(old_pmd));
}
// 调用 stage1_map_pte_range,对 start ~ next 之间的所有页面建立映射
ret = stage1_map_pte_range(vs, ptep, start, next, physical, flags);
if (ret)
return ret;
}
} while (pmd++, physical += size, start = next, start != end);
return 0;
}
上述是建立 level3 level2 页表的两个函数,应该很简单,看注释就能懂。唯一注意的地方是 next = stage1_pmd_addr_end(start, end);这里是获取大于 start 的下一个 2M 对齐的地址,具体实现见其位操作。
对于该文件中其他级别的 map、unmap 函数,这里也就不细说了,都是类似重复性的操作。如果实在没明白,兄弟回去补一补页表的基本知识,可以走一遍 xv6 中二级页表的流程。
// 获取地址 va 对应的叶子表项
// 如果是大页,那么 pmd 就是叶子节点,否则就是 pte
static int stage1_get_leaf_entry(struct vspace *vs,
unsigned long va, pmd_t **pmdpp, pte_t **ptepp)
{
pud_t *pudp;
pmd_t *pmdp;
pte_t *ptep;
// 查表 pgd,获取地址 va 对应的 pud 指针
pudp = stage1_pud_offset(vs->pgdp, va);
if (stage1_pud_none(*pudp))
return -ENOMEM;
// 查表 pud,再获取地址 va 对应的 pmd 指针
pmdp = stage1_pmd_offset(stage1_pmd_table_addr(*pudp), va);
if (stage1_pmd_none(*pmdp))
return -ENOMEM;
// 如果是大页,说明地址 va 对应的 pmd 就是叶子节点了,返回它的地址
if (stage1_pmd_huge(*pmdp)) {
*pmdpp = pmdp;
return 0;
}
// 否则 pte 肯定是叶子节点了,获取地址 va 对应的 pte 表项
ptep = stage1_pte_offset(stage1_pte_table_addr(*pmdp), va);
*ptepp = ptep;
return 0;
}
参数中出现的 struct vspace 定义如下:
struct vspace {
pgd_t *pgdp;
spinlock_t lock;
};
static struct vspace host_vspace;
该结构体就只有 host_vspace 一个实例,表示 minos 这个 hypervisor 或者说宿主机的虚拟地址空间,由 host_vspace.pgdp 所指向的页表映射
// 将虚拟地址 vir 重新映射到一个新的物理地址 phy,就是将叶子结点表项的内容更改为 phy | flags
int arch_host_change_map(struct vspace *vs, unsigned long vir,
unsigned long phy, unsigned long flags)
{
int ret;
pmd_t *pmdp = NULL;
pte_t *ptep = NULL;
// 获取地址 vir 对应的叶子表项
ret = stage1_get_leaf_entry(vs, vir, &pmdp, &ptep);
if (ret)
return ret;
// 如果是大页,即如果叶子节点是 pmd 表项
if (pmdp && !ptep) {
// 将该 pmd 表项清 0
stage1_set_pmd(pmdp, 0);
// flush tlb
flush_tlb_va_range(vir, S1_PMD_SIZE);
// 重新设置 pmd 表项内容为 phy
stage1_set_pmd(pmdp, stage1_pmd_attr(phy, flags));
return 0;
}
// 否则叶子结点为普通的 pte 表项
stage1_set_pte(ptep, 0);
// flush tlb
flush_tlb_va_range(vir, S1_PTE_SIZE);
// 重新设置 pte 表项内容为 phy
stage1_set_pte(ptep, stage1_pte_attr(phy, flags));
return 0;
}
// hyp/宿主机的地址转换,将 va 转换为 pa
static inline phy_addr_t stage1_va_to_pa(struct vspace *vs, unsigned long va)
{
unsigned long pte_offset = va & ~S1_PTE_MASK;
unsigned long pmd_offset = va & ~S1_PMD_MASK;
unsigned long phy = 0;
pud_t *pudp;
pmd_t *pmdp;
pte_t *ptep;
// 获取地址 va 对应的 pud 指针
pudp = stage1_pud_offset(vs->pgdp, va);
if (stage1_pud_none(*pudp))
return 0;
// 获取地址 va 对应的 pmd 指针
pmdp = stage1_pmd_offset(ptov(stage1_pmd_table_addr(*pudp)), va);
if (stage1_pmd_none(*pmdp))
return 0;
// 如果是大页,那么转换后的物理地址就是 pmd 表项中记录的内容 + 偏移量
if (stage1_pmd_huge(*pmdp)) {
phy = ((*pmdp) & S1_PHYSICAL_MASK) + pmd_offset;
return 0;
}
// 否则是普通的 4K 页面,获取 pte 页表项
ptep = stage1_pte_offset(ptov(stage1_pte_table_addr(*pmdp)), va);
// 转换后的物理地址为 pte 中记录的页框地址 + 偏移量
phy = *ptep & S1_PHYSICAL_MASK;
if (phy == 0)
return 0;
return phy + pte_offset;
}
phy_addr_t arch_translate_va_to_pa(struct vspace *vs, unsigned long va)
{
return stage1_va_to_pa(vs, va);
}
// hyp 将 start~end 的虚拟地址映射到 物理地址为 physical 开始的一段空间
int arch_host_map(struct vspace *vs, unsigned long start, unsigned long end,
unsigned long physical, unsigned long flags)
{
if (end == start)
return -EINVAL;
ASSERT((start < S1_VIRT_MAX) && (end <= S1_VIRT_MAX));
ASSERT(physical < S1_PHYSICAL_MAX);
ASSERT(IS_PAGE_ALIGN(start) && IS_PAGE_ALIGN(end) && IS_PAGE_ALIGN(physical));
// 直接调用 pud 映射
return stage1_map_pud_range(vs, start, end, physical, flags);
}
上述是该文件中其他的一些值得说说的函数,都有详细的注释,不赘述
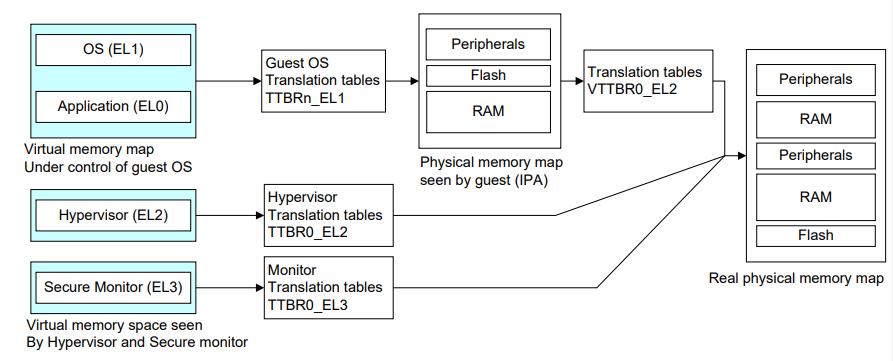
本文主要内容就先到这里,其实就是一张图:
再简单总结下:
- EL0/1 中,ARMv8 的内核页表与用户态页表是分开的,内核页表存放在 TTBR0_EL1,用户态页表存放在 TTBR0_EL0。minos 运行在 EL2,minos 本身使用 TTBR0_EL2 寄存器来存放 minos 本身的页表
- 存在虚拟化的情况下,多了一个页表寄存器 VTTBR_EL2,其中存放虚机 stage2 地址转换使用的页表。地址转换流程为 va->ipa->pa,va 通过 TTBR0/1_EL1 的页表转化 ipa,ipa 通过 VTTBR_EL2 中的页表转换为 pa
- minos 最大的内存单位是
mem_region,本文简单讲述了 mem_region 的组织形式,以及分配回收方式 - 最后本文还讲述了 ARMv8 页表格式,以及各类页表项操作
好了,本文就先到这里,有什么问题欢迎来找我讨论交流
- 首发公号:Rand_cs
minos 1.1 内存虚拟化——hyp的更多相关文章
- 【原创】Linux虚拟化KVM-Qemu分析(五)之内存虚拟化
背景 Read the fucking source code! --By 鲁迅 A picture is worth a thousand words. --By 高尔基 说明: KVM版本:5.9 ...
- [原] KVM 虚拟化原理探究(4)— 内存虚拟化
KVM 虚拟化原理探究(4)- 内存虚拟化 标签(空格分隔): KVM 内存虚拟化简介 前一章介绍了CPU虚拟化的内容,这一章介绍一下KVM的内存虚拟化原理.可以说内存是除了CPU外最重要的组件,Gu ...
- CPU 和内存虚拟化原理 - 每天5分钟玩转 OpenStack(6)
前面我们成功地把 KVM 跑起来了,有了些感性认识,这个对于初学者非常重要.不过还不够,我们多少得了解一些 KVM 的实现机制,这对以后的工作会有帮助. CPU 虚拟化 KVM 的虚拟化是需要 CPU ...
- KVM 介绍(2):CPU 和内存虚拟化
学习 KVM 的系列文章: (1)介绍和安装 (2)CPU 和 内存虚拟化 (3)I/O QEMU 全虚拟化和准虚拟化(Para-virtulizaiton) (4)I/O PCI/PCIe设备直接分 ...
- KVM 内存虚拟化
内存虚拟化的概念 除了 CPU 虚拟化,另一个关键是内存虚拟化,通过内存虚拟化共享物理系统内存,动态分配给虚拟机.虚拟机的内存虚拟化很象现在的操作系统支持的虚拟内存方式,应用程序看到邻近的内存 ...
- qemu-kvm内存虚拟化1
2017-04-18 记得很早之前分析过KVM内部内存虚拟化的原理,仅仅知道KVM管理一个个slot并以此为基础转换GPA到HVA,却忽略了qemu端最初内存的申请,而今有时间借助于qemu源码分析下 ...
- 2017.4.28 KVM 内存虚拟化及其实现
概述 KVM(Kernel Virtual Machine) , 作为开源的内核虚拟机,越来越受到 IBM,Redhat,HP,Intel 等各大公司的大力支持,基于 KVM 的开源虚拟化生态系统也日 ...
- KVM(二)CPU 和内存虚拟化
1. 为什么需要 CPU 虚拟化 X86 操作系统是设计在直接运行在裸硬件设备上的,因此它们自动认为它们完全占有计算机硬件.x86 架构提供四个特权级别给操作系统和应用程序来访问硬件. Ring 是指 ...
- CPU 和内存虚拟化原理
前面我们成功地把 KVM 跑起来了,有了些感性认识,这个对于初学者非常重要.不过还不够,我们多少得了解一些 KVM 的实现机制,这对以后的工作会有帮助. CPU 虚拟化 KVM 的虚拟化是需要 CPU ...
- O006、CPU和内存虚拟化原理
参考https://www.cnblogs.com/CloudMan6/p/5263981.html 前面我们成功的把KVM跑起来了,有了些感性认识,这个对于初学者非常重要.不过还不够,我们多少要 ...
随机推荐
- 深入理解高级加密标准(Advanced Encryption Standard)
title: 深入理解高级加密标准(Advanced Encryption Standard) date: 2024/4/23 20:04:36 updated: 2024/4/23 20:04:36 ...
- OpenYurt v1.1.0: 新增 DaemonSet 的 OTA 和 Auto 升级策略
简介: 在 OpenYurt v1.1.0 版本中,我们提供了 Auto 和 OTA 的升级策略.Auto 的升级策略重点解决由于节点 NotReady 而导致 DaemonSet升级阻塞的问题,OT ...
- 阿里开源自研工业级稀疏模型高性能训练框架 PAI-HybridBackend
简介:近年来,随着稀疏模型对算力日益增长的需求, CPU集群必须不断扩大集群规模来满足训练的时效需求,这同时也带来了不断上升的资源成本以及实验的调试成本.为了解决这一问题,阿里云机器学习PAI平台开 ...
- Apsara Stack 技术百科 | 数字化业务系统安全工程
简介:数字化平台已经与我们生活紧密结合,其用户规模庞大,一旦系统出现故障,势必会造成一定生活的不便.比如疫情时代,健康码已经成为人们出门必备的条件,一旦提供健康码服务平台出现故障,出行将变得寸步难行 ...
- 基于 Serverless 打造如 Windows 体验的个人专属家庭网盘
简介:虽然现在市面上有些网盘产品, 如果免费试用,或多或少都存在一些问题, 可以参考文章<2020 国内还能用的网盘推荐>.本文旨在使用较低成本打造一个 "个人专享的.无任何限 ...
- [GPT] 用 document.querySelector('.xxx') 选择下级的第二个 div 要怎么写
要选择类名为 .xxx 的元素下的第二个子<div>元素,可以将 querySelectorAll()方法与CSS选择器一起使用. 以下是一个示例: const secondChild ...
- [FAQ] chrome.runtime.onMessage 问题, Unchecked runtime.lastError: The message port closed before a response was received
// quasar background-hook.js chrome.runtime.onMessage.addListener(function (request, sender, sendRes ...
- dotnet CBB 为什么决定推送 Tag 才能打包
通过推送 Tag 才打 NuGet 包的方法的作用不仅仅是让打包方便,让打包这个动作可以完全在本地执行,无需关注其他系统的使用步骤.更重要的是可以强制每个可能被安装的 NuGet 包版本都能有一个和他 ...
- PostMan测试图片上传接口的方法
一.选择POST后添加接口地址 二.选择Body下的from-data 注:Headers不要加参数 三.填写key,再key后的下拉选择file,然后选择文件 注:key并不是图片名称,而是接口接收 ...
- Mybatis逆向工程的2种方法,一键高效快速生成Pojo、Mapper、XML,摆脱大量重复开发
一.写在开头 最近一直在更新<Java成长计划>这个专栏,主要是Java全流程学习的一个记录,目前已经更新到Java并发多线程部分,后续会继续更新:而今天准备开设一个全新的专栏 <E ...