Locust、Jemter、Loadrunner三种工具的分布式压测
前言:
最近公司接了一个云上展会项目,合同里签订的是6w并发连接数和2w QPS的性能指标,还有监理单位,第三方评测单位。
唉,先吐槽一下,有了监理和评测,文档tmd一堆堆,严格按照软件开发来执行,写文档都得累死,对于经常只有概要设计,有时候概要设计都舍了的研发流程,哈哈 ~慢慢体会!
再加上一点,如果评测单位技术很牛皮,那确实能对项目有所帮组,但评测单位技术不行的话,那简直就是来捣乱,平添很多无用工作。
讲讲并发数的理解:
6w并发,也是无语,签合同时也没想到后续有多麻烦,估计当时没理解透彻并发连接数与连接数的概念。
并发连接数:每时刻连接到服务器的请求数,并没有时间单位,没有秒,毫秒的度量单位。比如6万并发,你服务器无时无刻都有6万请求连接。
所以1000并发连接数,可以有2w多的QPS或TPS。因为QPS或TPS是以秒为单位的,1秒内无时无刻的1000并发请求,就可以完成好几万的请求次数。
到这里,是不是认为6w并发很难完成,确实,到项目初验完成,我们只做了3w的并发,QPS倒可以轻松完成。
进入正题:
1. Locust的分布式压测,看过我博客之前的文章,应该了解,locust的分布式压测其实就是启动命令不同而已,和jemter、loadrunner不同的是,locust的master端不会主动把脚本
推送到slave服务器,需要自己把要执行的脚本拷贝到slave服务器上。
针对这点的话,可以在master执行脚本里把远程推送文件与远程执行命令加上,就可以搞定了,不用一台台服务器拷贝,再启动命令。
分布式执行命令:
master:
locust -f D:\thecover_project\api_locust\locust_view\kbh_api\locust_api\locust_bot_search.py --master --master-bind-port 9800 --headless -u 100 -r 20 --expect-worker 1 -t 2m -s 10 --step-load --step-users 100 --step-time 2m --csv D:\thecover_project\api_locust\resource\csv\locust_bot_search.py0922115120
slave:
locust -f D:\thecover_project\api_locust\locust_view\kbh_api\locust_api\locust_bot_search.py --master-host 10.111.53.123 --master-port 9800 --headless --worker
这里的ip就是master机器的ip(一般都是局域网内网IP)
执行压测的测试机部署图:

上面服务器CPU配置为8核16线程,非16核。一般locust一个CPU线程可以启动一个slave。一台机子可以启动16个,当然,启动12,到15个最好,都启动的话,电脑后边很卡,cpu90%会主动丢失该slave。
执行完成后自动生成报告(之前文章有介绍报告生成)。
通过这样的分布式压测,页面的QPS一般很轻松达到5w左右,接口的看服务器配置和接口业务复杂度,一般也能达到3w的qps。
其实研究透locust后,你会发现命令参数里-U也可以叫做并发数,前提是wait time要设置为0,不设置等待时间(思考时间)。这样才能保证无时无刻发起-U后的用户数。
2. Jemter的分布式压测
jemter的自带有分布式压测:Controller(主控机)、Agent(代理机),我用的是最新版(5.3)版本,分布式配置和4.x略有区别。
在Controller主机上修改jmeter.properties配置文件:
1).找到remote_hosts=,把Agent服务器的ip:端口,维护进去,如:192.168.0.1:1099,192.168.0.2:1099,102.168.1.3:1099
2).找到server.rmi.ssl.disable=false,修改为server.rmi.ssl.disable=true
3)找到jmeter.bat,运行启动主控机
在Agent主机上修改jmeter.properties配置文件:
1).找到server.rmi.ssl.disable=false,修改为server.rmi.ssl.disable=true
2)找到jmeter-server.bat,运行启动代理机
Controller机和Agent机,端口默认是1099,若要修改端口,可以在jmeter.properties找到“server_port=”修改端口即可
最后在Controller机jemter上,“运行”-->"远程启动",一台台启动,也可以"运行"-->"远程启动所有",这样分布式压测就启动ok了,压测脚本会自动推送到Agent服务器上执行,不做其他配置。
3.Loadrunner的分布式压测
Loadrunner的分布式压测最简单了,所有机子安装好Loadrunner后,主控机在run load tests 里点击 load generators里添加负载机的ip即可;
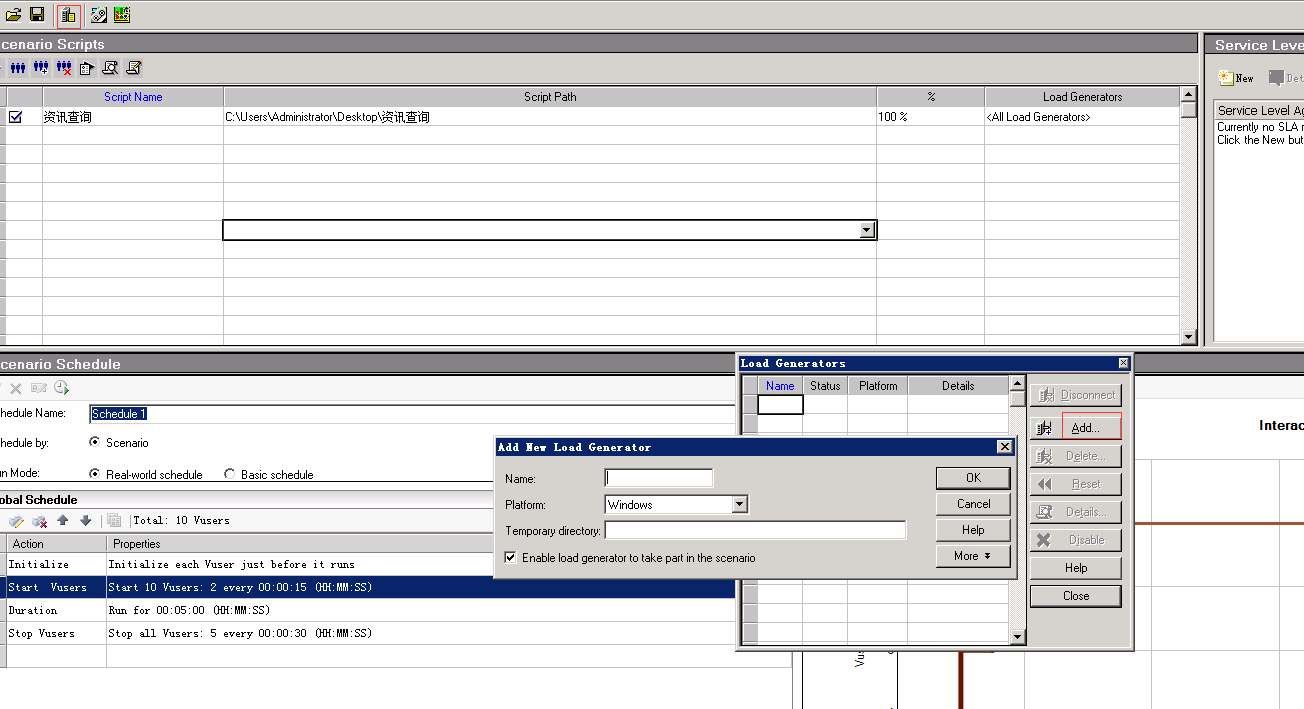
添加完后,选择connect尝试连接,若status状态为ready即认为连接上了,然后你可以灵活配置这些负载机:
在上图的第5列那可以选择具体ip,或者所有ip执行脚本,也可以添加多个脚本,分别在不同的ip上执行,这里都可以灵活配置。
loadrunner的界面操作这些还是很强大的,不愧是性能测试工具里的标杆。但是loadrunner的缺点也很多,比如最大的缺点就是收费,当然,你可以使用破解版,另外就是loadrunner和jemter一样,很耗CPU,
其次就是分析报告生成很慢很慢,如果你压测的数据几亿条,光分析报告生成都需要差不多一个小时。
以上就是目前比较流行的压测工具分布式压测部署配置方法。
总的来说,这几款压测工具都还可以,如果不是被评测公司要求使用loadrunner的话,常规的开源压测工具是首选,loadrunner安装都需要安装大半天,完了还得破解啥的,总之loadrunner感觉太重了。
文末送上loadrunner11的安装包下载地址和破解dll和证书id。
用迅雷下载:http://www.genilogix.com/downloads/loadrunner/loadrunner-11.iso
破解文件:https://download.csdn.net/download/tengdakuaijie1/12880665
有问题的欢迎交流。
Locust QQ 群:

Locust、Jemter、Loadrunner三种工具的分布式压测的更多相关文章
- Loadrunner三种post格式的请求
Loadrunner三种post格式的请求 web_custom_request intweb_custom_request(const char *RequestName, <List of ...
- jemter 分布式压测
1.测试机搭建 首选 压力机A,压力机B,压力机C, 压力机A作为控制台 压力机B,压力机C作为分布式的测试机 压力机Aip:172.16.23.69, 压力机Bip:192.168.184.128 ...
- 案例 | 荔枝微课基于 kubernetes 搭建分布式压测系统
王诚强,荔枝微课基础架构负责人.热衷于基础技术研发推广,致力于提供稳定高效的基础架构,推进了荔枝微课集群化从0到1的发展,云原生架构持续演进的实践者. 本文根据2021年4月10日深圳站举办的[腾讯云 ...
- jmeter(二十七)分布式压测注意事项
之前的博客:jemter(二十三):分布式测试简略的介绍了利用jmeter做分布式测试的方法,当时只是介绍了背景和原因,以及基本的配置操作,有同学说写得不够详细. 正好今年双十一,我司的全链路压测,也 ...
- JMeter分布式压测实战(2020年清明假期学习笔记)
一.常用压力测试工具对比 简介:目前用的常用测试工具对比 1.loadrunner 性能稳定,压测结果及颗粒度大,可以自定义脚本进行压测,但是太过于重大,功能比较繁多. 2.Apache ab(单接口 ...
- 分布式压测系列之Jmeter4.0第一季
1)Jmeter4.0介绍 jmeter是个纯java编写的开源压测工具,apache旗下的开源软件,一开始是设计为web测试的软件,由于发展迅猛,现在可以压测许多协议比如:http.https.so ...
- 实现理论上无tps上限的分布式压测(基于Jmeter+InfluxDB+Grafana+Spring Boot)
JMeter自身带有Master-Slave压测框架,对于并发量不是很高的压力情况下(比如tps低于5000),该方案是可行的,并且使用起来非常方便,只要在配置文件或者命令行工具的参数做一些补充,即可 ...
- jmeter进行分布式压测过程与 注意事项
jmeter命令行运行但是是单节点下的, jmeter底层用java开发,耗内存.cpu,如果项目要求大并发去压测服务端的话,jmeter单节点难以完成大并发的请求,这时就需要对jmeter进行分布式 ...
- jmeter分布式压测
stop.sh需要跑Jmeter的服务器上安装Jmeteryum install lrzsz 安装rz.sz命令rz jemter的压缩包 拷贝到/usr/local/tools下面unzip apa ...
- JMeter在linux上分布式压测步骤(二)
哈喽,我又来了~ 前提:三台linux虚拟机,一台作为master,另外两台作为slave. 一.server端 1.修改1099端口,client和server通信的端口,可以不修改,默认就是109 ...
随机推荐
- GaussDB(DWS)集群通信:详解pooler连接池
本文分享自华为云社区<GaussDB(DWS) 集群通信系列一:pooler连接池>,作者:半岛里有个小铁盒. 1.前言 适用版本:[8.1.0(及以上)] GaussDB(DWS) 为M ...
- OpenCV开发笔记(七十七):相机标定(二):通过棋盘标定计算相机内参矩阵矫正畸变摄像头图像
前言 通过相机图片可以识别出棋盘角点了,这时候我们需要通过角点去计算相机内参矩阵,通过上篇得知畸变的原理,所以我们尽可能要全方位都能获取标定图片,全方位意思是提供的多张图综合起来基本覆盖了相机所有 ...
- evalFn 字符串转执行函数 附带JSONParse函数
const evalFn = (fn) => { var Fun = Function // 一个变量指向Function,防止前端编译工具报错 return new Fun('return ' ...
- end_of_line = lf 选择行尾序列 .editorconfig - 老项目不动代码存盘 文件变动 CRLF 的问题 vscode
end_of_line = lf 选择行尾序列 .editorconfig - 老项目不动代码存盘 文件变动 CRLF 的问题 缘由 vscode 老项目代码,没有变动,ctrl + s后 文件有变化 ...
- 流数据库-RisingWave
参考: https://docs.risingwave.com/docs/current/architecture/ https://www.risingwavetutorial.com/docs/i ...
- day06-Java流程控制
Java流程控制 1.用户交互Scanner java.util.Scanner是Java5的新特征,我们可以通过Scannner类来获取用户的输入. 基本语法: Scanner s = new Sc ...
- [mysql/docker] 基于Docker安装MYSQL
0 序 虽然关于 mysql 安装的教程,先前已写过很多期了(参见如下列表),但这期的安装教程所依赖的环境还是大有不同的----基于 docker 环境. [数据库] MySQL之数据库备份与升级:M ...
- JAVA 相关
1. google guava cache 2. presto 3. loadingcache 4. aspect
- Android组件化开发实践和案例分享
目录介绍 1.为什么要组件化 1.1 为什么要组件化 1.2 现阶段遇到的问题 2.组件化的概念 2.1 什么是组件化 2.2 区分模块化与组件化 2.3 组件化优势好处 2.4 区分组件化和插件化 ...
- 三维模型3DTile格式轻量化在数据存储的重要性分析
三维模型3DTile格式轻量化在数据存储的重要性分析 三维模型3DTile格式轻量化在数据存储中占有重要地位.随着科技的不断发展,尤其是空间信息科技的进步,人们对于三维地理空间数据的需求日益增长.然而 ...