Linux 进程调度之schdule主调度器
考虑到文章篇幅,在这里我只讨论普通进程,其调度算法采用的是CFS(完全公平)调度算法。
至于CFS调度算法的实现后面后专门写一篇文章,这里只要记住调度时选择一个优先级最高的任务执行
一、调度单位简介
1.1 task_struct 结构体简介
对于Linux内核来说,调度的基本单位是任务,用 struct task_struct 表示,定义在include/linux/sched.h文件中,这个结构体包含一个任务的所有信息,结构体成员很多,在这里我只列出与本章内容有关的成员:
struct task_struct {
......
(1)
volatile long state;
(2)
const struct sched_class *sched_class;
(3)
void *stack;
struct thread_struct thread;
struct mm_struct *mm, *active_mm;
......
}
(1)state :表示任务当前的状态,当state为TASK_RUNNING时,表示任务处于可运行的状态,并不一定表示目前正在占有CPU,也许在等待调度,调度器只会选择在该状态下的任务进行调度。该状态确保任务可以立即运行,而不需要等待外部事件。
简单来说就是:任务调度的对象是处于TASK_RUNNING状态的任务。
处于TASK_RUNNING状态的任务,可能正在执行用户态代码,也可能正在执行内核态的代码。
(2)sched_class :表示任务所属的调度器类,我们这里只讲CFS调度类。
// kernel/sched/sched.h
struct sched_class {
......
//将任务加入可运行的队列中
void (*enqueue_task) (struct rq *rq, struct task_struct *p, int flags);
//将任务移除可运行的队列中
void (*dequeue_task) (struct rq *rq, struct task_struct *p, int flags);
//选择一下将要运行的任务
struct task_struct * (*pick_next_task) (struct rq *rq,
struct task_struct *prev,
struct pin_cookie cookie);
......
}
extern const struct sched_class fair_sched_class;
// kernel/sched/fair.c
const struct sched_class fair_sched_class;
/*
* All the scheduling class methods:
*/
const struct sched_class fair_sched_class = {
......
.enqueue_task = enqueue_task_fair, //CFS 的 enqueue_task 实例
.dequeue_task = dequeue_task_fair, //CFS 的 dequeue_task 实例
.pick_next_task = pick_next_task_fair, //CFS 的 pick_next_task 实例
......
}
(3)任务上下文:表示任务调度时要切换的任务上下文(任务切换只发生在内核态)。
stack:当前任务的内核态堆栈(用户态的sp,用户态的ip,在内核栈顶部的 pt_regs 结构里面)
thread :也叫任务的硬件上下文,主要包含了大部分CPU寄存器(如:内核栈sp)。
struct mm_struct *mm :切换每个任务用户态的虚拟地址空间(每个任务的用户栈都是独立的,都在内存空间里面,切换任务的虚拟地址空间,也就切换了任务的用户栈)。
1.2 task_struct 结构体的产生
任务(task_struct) 的来源有三处:
(1) fork():该函数是一个系统调用,可以复制一个现有的进程来创建一个全新的进程,产生一个 task_struct,然后调用wake_up_new_task()唤醒新的进程,使其进入TASK_RUNNING状态。
(2) pthread_create():该函数是Glibc中的函数,然后调用clone()系统调用创建一个线程(又叫轻量级进程),产生一个 task_struct,然后调用wake_up_new_task()唤醒新的线程,使其进入TASK_RUNNING状态。
(3)kthread_create():创建一个新的内核线程,产生一个 task_struct,然后wake_up_new_task(),唤醒新的内核线程,使其进入TASK_RUNNING状态。
其实这三个API最后都会调用 _do_fork(),不同之处是传入给 _do_fork() 的参数不同(clone_flags),最终结果就是进程有独立的地址空间和栈,而用户线程可以自己指定用户栈,地址空间和父进程共享,内核线程则只有和内核共享的同一个栈,同一个地址空间。因此上述三个API最终都会创建一个task_struct结构。
备注:这里没有讨论vfok()。
总结:上述三个方式都产生了一个任务 task_struct,然后唤醒该任务使其处于TASK_RUNNING状态,然后这样调度器就可以调度 任务(task_struct)了。
还有一个来源就是0号进程(又叫 idle 进程),每个逻辑处理器上都有一个,属于内核态线程,只有在没有其他的任务处于TASK_RUNNING状态时(系统此时处于空闲状态),任务调度器才会选择0号进程,然后重复执行 HLT 指令。
HLT 指令 :停止指令执行,并将处理器置于HALT状态。简单来说让该CPU进入休眠状态,低功耗状态。
(该指令只能在 privilege level 0执行,且CPU指的是逻辑CPU而不是物理CPU,每个逻辑CPU都有一个idle进程)。

1.3 struct rq 结构体
目前的x86_64都有多个处理器,那么对于所有处于TASK_RUNNING状态的任务是应该位于一个队列还有每个处理器都有自己的队列?
Linux采用的是每个CPU都有自己的运行队列,这样做的好处:
(1)每个CPU在自己的运行队列上选择任务降低了竞争
(2)某个任务位于一个CPU的运行队列上,经过多次调度后,内核趋于选择相同的CPU执行该任务,那么上次任务运行的变量很可能仍然在这个CPU缓存上,提高运行效率。
在这里我只讨论普通任务的调度,因为linux大部分情况下都是在运行普通任务,普通任务选择的调度器是CFS完全调度。
在调度时,调度器去 CFS 运行队列找是否有任务需要运行。
DEFINE_PER_CPU_SHARED_ALIGNED(struct rq, runqueues);
struct rq {
.......
unsigned int nr_running; //运行队列上可运行任务的个数
struct cfs_rq cfs; // CFS 运行队列
struct task_struct *curr, //当前正在运行任务的 task_struct 实例
struct task_struct *idle, //指向idle任务的实例,在没有其它可运行任务的时候执行
......
}
二、schedule函数详解
2.1 schedule函数简介
上文说到任务调度器是对于可运行状态(TASK_RUNNING)的任务进行调度,如果任务的状态不是TASK_RUNNING,那么该任务是不会被调度的。
调度的入口点是schedule()函数,定义在 kernel/sched/core.c 文件中,这里删掉了很多代码,只留了重要的代码:
asmlinkage __visible void __sched schedule(void)
{
......
preempt_disable(); //禁止内核抢占
__schedule(false); //任务开始调度,调度的过程中禁止其它任务抢占
sched_preempt_enable_no_resched(); //开启内核抢占
......
}
这里注意schedule调用__schedule函数是传入的是false参数,表示schedule函数主调度器。
调度分为主动调度和抢占调度。
__schedule的参数preempt是bool类型,表示本次调度是否为抢占调度:
__schedule的参数preempt等于0表示不是抢占调度,即主动调度,代表此次调度是该进程主动请求调度,主动调用了schedule函数(任务主动让出处理器),比如该进程进入了阻塞态。
而schedule函数参数固定传入的参数是false,也就是0,就是调用schedule函数就是主动发起调度,不是抢占调度,因此schedule函数称为主调度器。
直接调用主调度器schdule函数的场景有3种:
(1)当前进程需要等待某个条件满足才能继续运行时,调用一个wait_event()类函数将自己的状态设为TASK_INTERRUPTIBLE或者TASK_UNINTERRUPTIBLE,挂接到某个等待队列,然后根据情况设置一个合适的唤醒定时器,最后调用schedule()发起调度;
/*
* The below macro ___wait_event() has an explicit shadow of the __ret
* variable when used from the wait_event_*() macros.
*
* This is so that both can use the ___wait_cond_timeout() construct
* to wrap the condition.
*
* The type inconsistency of the wait_event_*() __ret variable is also
* on purpose; we use long where we can return timeout values and int
* otherwise.
*/
#define ___wait_event(wq, condition, state, exclusive, ret, cmd) \
({ \
__label__ __out; \
wait_queue_t __wait; \
long __ret = ret; /* explicit shadow */ \
\
init_wait_entry(&__wait, exclusive ? WQ_FLAG_EXCLUSIVE : 0); \
for (;;) { \
long __int = prepare_to_wait_event(&wq, &__wait, state);\
\
if (condition) \
break; \
\
if (___wait_is_interruptible(state) && __int) { \
__ret = __int; \
goto __out; \
} \
\
cmd; \
} \
finish_wait(&wq, &__wait); \
__out: __ret; \
})
#define __wait_event(wq, condition) \
(void)___wait_event(wq, condition, TASK_UNINTERRUPTIBLE, 0, 0, \
schedule())
/**
* wait_event - sleep until a condition gets true
* @wq: the waitqueue to wait on
* @condition: a C expression for the event to wait for
*
* The process is put to sleep (TASK_UNINTERRUPTIBLE) until the
* @condition evaluates to true. The @condition is checked each time
* the waitqueue @wq is woken up.
*
* wake_up() has to be called after changing any variable that could
* change the result of the wait condition.
*/
#define wait_event(wq, condition) \
do { \
might_sleep(); \
if (condition) \
break; \
__wait_event(wq, condition); \
} while (0)
(2)当前进程需要睡眠一段特定的时间(不等待任何事件)时,调用一个sleep()类函数将自己的状态设为TASK_INTERRUPTIBLE或者TASK_UNINTERRUPTIBLE但不进入任何等待队列,然后设置一个合适的唤醒定时器,最后调用schedule()发起调度;
(3)当前进程单纯地想要让出CPU控制权时,调用yield()函数将自己的状态设为TASK_RUNNING并依旧处于运行队列,然后执行特定调度类的yield_task()操作,最后调用schedule()发起自愿调度。
/**
* sys_sched_yield - yield the current processor to other threads.
*
* This function yields the current CPU to other tasks. If there are no
* other threads running on this CPU then this function will return.
*
* Return: 0.
*/
SYSCALL_DEFINE0(sched_yield)
{
struct rq *rq = this_rq_lock();
schedstat_inc(rq->yld_count);
current->sched_class->yield_task(rq);
/*
* Since we are going to call schedule() anyway, there's
* no need to preempt or enable interrupts:
*/
__release(rq->lock);
spin_release(&rq->lock.dep_map, 1, _THIS_IP_);
do_raw_spin_unlock(&rq->lock);
sched_preempt_enable_no_resched();
schedule();
return 0;
}
__schedule的参数preempt等于1表示是抢占调度,有处于运行态的任务发起的抢占调度。
例举几处发起抢占调度的地方:
static void __sched notrace preempt_schedule_common(void)
{
do {
/*
* Because the function tracer can trace preempt_count_sub()
* and it also uses preempt_enable/disable_notrace(), if
* NEED_RESCHED is set, the preempt_enable_notrace() called
* by the function tracer will call this function again and
* cause infinite recursion.
*
* Preemption must be disabled here before the function
* tracer can trace. Break up preempt_disable() into two
* calls. One to disable preemption without fear of being
* traced. The other to still record the preemption latency,
* which can also be traced by the function tracer.
*/
preempt_disable_notrace();
preempt_latency_start(1);
//抢占调度
__schedule(true);
preempt_latency_stop(1);
preempt_enable_no_resched_notrace();
/*
* Check again in case we missed a preemption opportunity
* between schedule and now.
*/
} while (need_resched());
}
#ifdef CONFIG_PREEMPT
/*
* this is the entry point to schedule() from in-kernel preemption
* off of preempt_enable. Kernel preemptions off return from interrupt
* occur there and call schedule directly.
*/
asmlinkage __visible void __sched notrace preempt_schedule(void)
{
/*
* If there is a non-zero preempt_count or interrupts are disabled,
* we do not want to preempt the current task. Just return..
*/
if (likely(!preemptible()))
return;
preempt_schedule_common();
}
NOKPROBE_SYMBOL(preempt_schedule);
EXPORT_SYMBOL(preempt_schedule);
/**
* preempt_schedule_notrace - preempt_schedule called by tracing
*
* The tracing infrastructure uses preempt_enable_notrace to prevent
* recursion and tracing preempt enabling caused by the tracing
* infrastructure itself. But as tracing can happen in areas coming
* from userspace or just about to enter userspace, a preempt enable
* can occur before user_exit() is called. This will cause the scheduler
* to be called when the system is still in usermode.
*
* To prevent this, the preempt_enable_notrace will use this function
* instead of preempt_schedule() to exit user context if needed before
* calling the scheduler.
*/
asmlinkage __visible void __sched notrace preempt_schedule_notrace(void)
{
enum ctx_state prev_ctx;
if (likely(!preemptible()))
return;
do {
/*
* Because the function tracer can trace preempt_count_sub()
* and it also uses preempt_enable/disable_notrace(), if
* NEED_RESCHED is set, the preempt_enable_notrace() called
* by the function tracer will call this function again and
* cause infinite recursion.
*
* Preemption must be disabled here before the function
* tracer can trace. Break up preempt_disable() into two
* calls. One to disable preemption without fear of being
* traced. The other to still record the preemption latency,
* which can also be traced by the function tracer.
*/
preempt_disable_notrace();
preempt_latency_start(1);
/*
* Needs preempt disabled in case user_exit() is traced
* and the tracer calls preempt_enable_notrace() causing
* an infinite recursion.
*/
prev_ctx = exception_enter();
//抢占调度
__schedule(true);
exception_exit(prev_ctx);
preempt_latency_stop(1);
preempt_enable_no_resched_notrace();
} while (need_resched());
}
EXPORT_SYMBOL_GPL(preempt_schedule_notrace);
#endif /* CONFIG_PREEMPT */
/*
* this is the entry point to schedule() from kernel preemption
* off of irq context.
* Note, that this is called and return with irqs disabled. This will
* protect us against recursive calling from irq.
*/
asmlinkage __visible void __sched preempt_schedule_irq(void)
{
enum ctx_state prev_state;
/* Catch callers which need to be fixed */
BUG_ON(preempt_count() || !irqs_disabled());
prev_state = exception_enter();
do {
preempt_disable();
local_irq_enable();
//抢占调度
__schedule(true);
local_irq_disable();
sched_preempt_enable_no_resched();
} while (need_resched());
exception_exit(prev_state);
}
__schedule()是主调度器的主要函数,__schedule在内核源码中有很多注释,如下所示:
驱使调度器并因此进入此函数的主要方法有:
1.显式阻塞:互斥、信号量、等待队列等。
2.中断和用户空间返回路径上检查TIF_NEED_RESCHED标志。例如,请参考arch/x86/entry_64.S。
为了驱动任务之间的抢占,调度程序在定时器中断处理程序scheduler_tick()中设置标志。
3.唤醒不会真正马上调用schedule(),只是将一个任务添加到运行队列中,设置任务标志位为TIF_NED_RESCHED,也就是将唤醒的进程加入的CFS就绪队列中(将唤醒的进程调度实体加入到红黑树中),仅此而已。
现在,如果添加到运行队列的新任务抢占了当前任务,则设置TIF_NED_RESCHED,并在以下的可能情况下调用schedule(),也就是唤醒的进程什么时候调用schedule()函数,分为以下两种情况:
(1)如果内核可抢占(CONFIG_PREMPT=y):
在系统调用或异常上下文中,在下一次调用preempt_enable()时检查是否需要抢占调度。
在IRQ上下文中,从中断处理程序返回到可抢占上下文。硬件中断处理返回前会检查是否要抢占当前进程。
(2)如果内核不可抢占(未设置CONFIG_PREMPT)
调用cond_resched()。
显式调用schedule()。
从syscall或异常返回到用户空间。
从中断处理程序返回到用户空间。
2.2 __schedule 代码解图
//__schedule() is the main scheduler function.
static void __sched notrace __schedule(bool preempt)
{
(1)
struct task_struct *prev, *next;
unsigned long *switch_count;
struct pin_cookie cookie;
struct rq *rq;
int cpu;
(2)
cpu = smp_processor_id();
rq = cpu_rq(cpu);
prev = rq->curr;
(3)
if (!preempt && prev->state) {
if (unlikely(signal_pending_state(prev->state, prev))) {
prev->state = TASK_RUNNING;
} else {
deactivate_task(rq, prev, DEQUEUE_SLEEP);
prev->on_rq = 0;
}
}
(4)
next = pick_next_task(rq, prev, cookie);
clear_tsk_need_resched(prev);
clear_preempt_need_resched();
(5)
if (likely(prev != next)) {
rq->nr_switches++;
rq->curr = next;
++*switch_count;
rq = context_switch(rq, prev, next, cookie); /* unlocks the rq */
} else {
lockdep_unpin_lock(&rq->lock, cookie);
raw_spin_unlock_irq(&rq->lock);
}
}
(1)prev局部变量表示要切换出去的任务,next局部变量表示要切换进来的任务。
struct task_struct *prev, *next;
(2)找到当前CPU的运行队列 struct rq,把当前正在运行的任务curr 赋值给 prev。
int cpu = smp_processor_id();
struct rq = cpu_rq(cpu);
struct task_struct *prev = rq->curr;
(3)
preempt 用于判断本次调度是否为抢占调度,如果发生了调度抢占(preempt =1),那么直接跳过,不参与判断,直接调用pick_next_task。抢占调度通常都是处于运行态的任务发起的抢占调度。
如果本次调度不是抢占调度(preempt = 0),并且该进程的state不等于 TASK_RUNNING (0),也就是不是运行态,处于其他状态。代表此次调度是该进程主动请求调度,主动调用了schedule函数,比如该进程进入了阻塞态。
进程在操作外部设备的时候(网络和存储则多是和外部设备的合作),往往需要让出 CPU,发起主动调度。
由于进程不是运行态:TASK_RUNNING了,那么就不能在CFS就绪队列中了,那么就调用 deactivate_task 将陷入阻塞态的进程移除CFS就绪队列,并将进程调度实体的 on_rq 成员置0,表示不在CFS就绪队列中了。
通常主动请求调用之前会提前设置当前进程的运行状态为 TASK_INTERRUPTIBLE 或者 TASK_UNINTERRUPTIBLE。
#define TASK_RUNNING 0
#define TASK_INTERRUPTIBLE 1
#define TASK_UNINTERRUPTIBLE 2
......
if (!preempt && prev->state) {
if (unlikely(signal_pending_state(prev->state, prev))) {
prev->state = TASK_RUNNING;
} else {
deactivate_task(rq, prev, DEQUEUE_SLEEP);
prev->on_rq = 0;
}
}
(4)选择下一个将要执行的任务,通过CFS调度算法选择优先级最高的一个任务。
clear_tsk_need_resched将被抢占的任务prev(也就是当前的任务)需要被调度的标志位(TIF_NEED_RESCHED)给清除掉,表示 prev 接下来不会被调度。
clear_preempt_need_resched 被抢占的任务prev(也就是当前的任务)的 PREEMPT_NEED_RESCHED 标志位给清除掉。
if (likely(prev != next)) {
//大概率事件,进行任务切换
rq->nr_switches++; //可运行队列切换次数更新
rq->curr = next; //将当前任务curr设置为将要运行的下一个任务 next
++*switch_count; //任务切换次数更新
//任务上下文切换
rq = context_switch(rq, prev, next, cookie); /* unlocks the rq */
} else {
//小概率事件,不进行任务切换
lockdep_unpin_lock(&rq->lock, cookie);
raw_spin_unlock_irq(&rq->lock);
}
(5)如果选择的任务next和 原任务prev不是同一个任务,则进行任务上下文切换
如果是同一个任务,则不进行上下文切换。
注意这里是 用 likely()修饰(这是gcc内建的一条指令用于优化,编译器可以根据这条指令对分支选择进行优化),表示有很大的概率 选择的任务next 和 原任务prev不是同一个任务。
由我们程序员来指明指令最可能的分支走向,以达到优化性能的效果。
if (likely(prev != next)) {
//大概率事件,进行任务切换
rq->nr_switches++; //可运行队列切换次数更新
rq->curr = next; //将当前任务curr设置为将要运行的下一个任务 next
++*switch_count; //任务切换次数更新
//任务上下文切换
rq = context_switch(rq, prev, next, cookie); /* unlocks the rq */
} else {
//小概率事件,不进行任务切换
lockdep_unpin_lock(&rq->lock, cookie);
raw_spin_unlock_irq(&rq->lock);
}
2.3 context_switch 代码解读
任务切换主要是任务空间即虚拟内存(用户态的虚拟地址空间,包括了用户态的堆栈)、CPU寄存器、内核态堆栈。
后面context_switch 还会专门一篇进行描述,这里限于篇幅,只是简单描述一下。
用伪代码表示:
switch_mm();
switch_to(){
switch_register();
switch_stack();
}
/*
* context_switch - switch to the new MM and the new thread's register state.
*/
static __always_inline struct rq *
context_switch(struct rq *rq, struct task_struct *prev,
struct task_struct *next, struct pin_cookie cookie)
{
struct mm_struct *mm, *oldmm;
(1)
prepare_task_switch(rq, prev, next);
(2)
mm = next->mm;
oldmm = prev->active_mm;
if (!mm) {
next->active_mm = oldmm;
atomic_inc(&oldmm->mm_count);
enter_lazy_tlb(oldmm, next);
} else
switch_mm_irqs_off(oldmm, mm, next);
(3)
/* Here we just switch the register state and the stack. */
switch_to(prev, next, prev);
(4)
return finish_task_switch(prev);
}
(1)开始任务切换前,需要做的准备工作,这里主要是提供了2个接口给我们内核开发者,当任务切换时我们可以自己添加一些操作进去,任务被重新调度时我们也可以自己添加一些操作进去。
同时通知我们任务被抢占(sched_out)。
prepare_task_switch(rq, prev, next);
-->fire_sched_out_preempt_notifiers(prev, next);
-->__fire_sched_out_preempt_notifiers(curr, next);
-->hlist_for_each_entry(notifier, &curr->preempt_notifiers, link)
notifier->ops->sched_out(notifier, next);
这里的 sched_in()函数和 sched_out函数是内核提供给我们开发者的接口。我们可以通过在这两个接口里面添加一些操作。
sched_in :任务重新调度时会通知我们。
sched_out:任务被抢占时会通知我们。
备注:调度器运行调度相关的代码,但其自身并不作为一个单独的 process 存在,在进程切换时,执行 switch out 的代码就是在被换出的 process 中,执行 switch in 的代码就是在被换入的 process 中,因此 scheduler 没有一个对应的 PID。
具体请参考:Linux 进程调度通知机制
struct preempt_ops {
void (*sched_in)(struct preempt_notifier *notifier, int cpu);
void (*sched_out)(struct preempt_notifier *notifier,
struct task_struct *next);
};
struct preempt_notifier {
struct hlist_node link;
struct preempt_ops *ops;
};
(2) 切换任务的用户虚拟态地址(不切换内核态的虚拟地址),也包括了用户态的栈,主要就是切换了任务的CR3, CR3寄存器放的是 页目录表物理内存基地址。
mm = next->mm;
oldmm = prev->active_mm;
if (!mm) {
// mm == NULL,代表任务是内核线程
// 直接用 被切换进程prev的active_mm
next->active_mm = oldmm;
atomic_inc(&oldmm->mm_count);
//通知处理器不需要切换虚拟地址空间的用户空间部分,用来加速上下文切换
enter_lazy_tlb(oldmm, next);
} else
//不是内核线程,那么就要切换用户态的虚拟地址空间,也就是切换任务的CR3
switch_mm_irqs_off(oldmm, mm, next);
-->load_cr3(next->pgd); //加载下一个任务的CR3
(3)切换任务的寄存器和内核态堆栈,保存原任务(prev)的所有寄存器信息,恢复新任务(next)的所有寄存器信息,当切换完之后,并执行新的任务。
switch_to(prev, next, prev);
-->__switch_to_asm((prev), (next)))
-->ENTRY(__switch_to_asm)
/* switch stack */
movq %rsp, TASK_threadsp(%rdi)
movq TASK_threadsp(%rsi), %rsp
jmp __switch_to
END(__switch_to_asm)
-->__switch_to()
(4) 完成一些清理工作,使其能够正确的释放锁。这个清理工作的完成是第三个任务,系统中随机的某个其它任务。同时通知我们任务被重新调度(sched_in)。
这里其实也有点复杂,我们后面在 context_switch 篇重点描述。
finish_task_switch(prev)
-->fire_sched_in_preempt_notifiers(current);
-->__fire_sched_in_preempt_notifiers(curr)
-->hlist_for_each_entry(notifier, &curr->preempt_notifiers, link)
notifier->ops->sched_in(notifier, raw_smp_processor_id());
总结
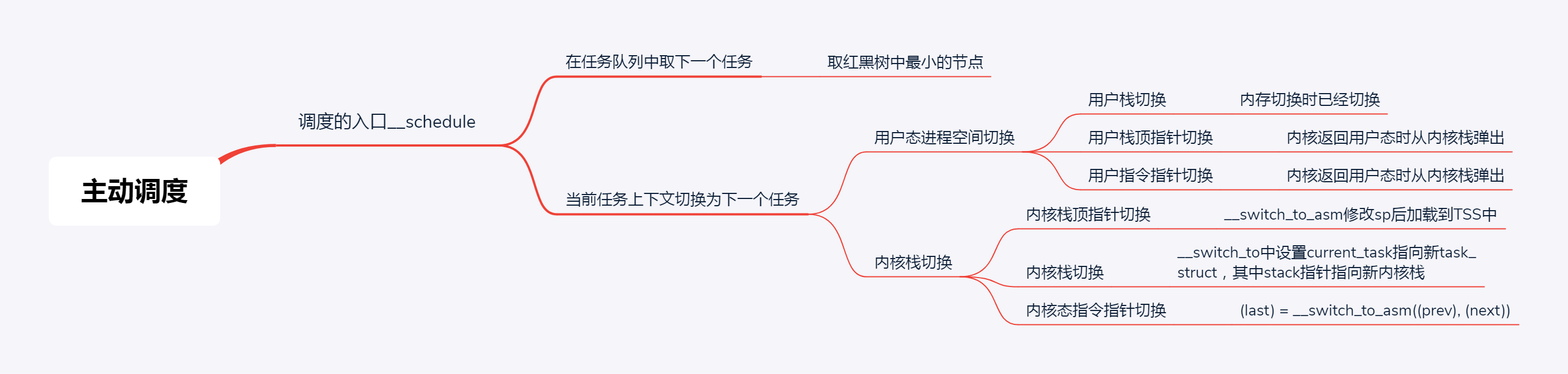
这篇文章主要讲了schdule主调度器的工作流程,即一个运行中的进程主动调用 _schedule 让出 CPU,总结来说就是:
(1)通过调度算法选择一个优先级最高的任务。
(2)进行任务上下文切换,上下文切换又分用户态进程空间的切换和内核态的切换。
保存原任务的所有寄存器信息,恢复新任务的所有寄存器信息,并执行新的任务。
(3)上下文切换完后,新的任务投入运行。
如下图所示:
Linux 进程调度之schdule主调度器的更多相关文章
- Linux进程管理 (2)CFS调度器
关键词: 目录: Linux进程管理 (1)进程的诞生 Linux进程管理 (2)CFS调度器 Linux进程管理 (3)SMP负载均衡 Linux进程管理 (4)HMP调度器 Linux进程管理 ( ...
- 主调度器schedule
中断处理完毕后,系统有三种执行流向: 1)直 ...
- Linux进程核心调度器之主调度器schedule--Linux进程的管理与调度(十九)
主调度器 在内核中的许多地方, 如果要将CPU分配给与当前活动进程不同的另一个进程, 都会直接调用主调度器函数schedule, 从系统调用返回后, 内核也会检查当前进程是否设置了重调度标志TLF_N ...
- Linux进程调度器的设计--Linux进程的管理与调度(十七)
1 前景回顾 1.1 进程调度 内存中保存了对每个进程的唯一描述, 并通过若干结构与其他进程连接起来. 调度器面对的情形就是这样, 其任务是在程序之间共享CPU时间, 创造并行执行的错觉, 该任务分为 ...
- Linux进程调度器概述--Linux进程的管理与调度(十五)
调度器面对的情形就是这样, 其任务是在程序之间共享CPU时间, 创造并行执行的错觉, 该任务分为两个不同的部分, 其中一个涉及调度策略, 另外一个涉及上下文切换. 1 背景知识 1.1 什么是调度器 ...
- Linux核心调度器之周期性调度器scheduler_tick--Linux进程的管理与调度(十八)
我们前面提到linux有两种方法激活调度器:核心调度器和 周期调度器 一种是直接的, 比如进程打算睡眠或出于其他原因放弃CPU 另一种是通过周期性的机制, 以固定的频率运行, 不时的检测是否有必要 因 ...
- linux cfs调度器_理论模型
参考资料:<调度器笔记>Kevin.Liu <Linux kernel development> <深入Linux内核架构> version: 2.6.32.9 下 ...
- 转: 调整 Linux I/O 调度器优化系统性能
转自:https://www.ibm.com/developerworks/cn/linux/l-lo-io-scheduler-optimize-performance/index.html 调整 ...
- Linux调度器 - deadline调度器
一.概述 实时系统是这样的一种计算系统:当事件发生后,它必须在确定的时间范围内做出响应.在实时系统中,产生正确的结果不仅依赖于系统正确的逻辑动作,而且依赖于逻辑动作的时序.换句话说,当系统收到某个请求 ...
- Linux CFS调度器之pick_next_task_fair选择下一个被调度的进程--Linux进程的管理与调度(二十八)
1. CFS如何选择最合适的进程 每个调度器类sched_class都必须提供一个pick_next_task函数用以在就绪队列中选择一个最优的进程来等待调度, 而我们的CFS调度器类中, 选择下一个 ...
随机推荐
- 低代码如何借助 K8s 实现高并发支持?
引言 在当今这个数字化时代,互联网的普及和技术的飞速发展使得应用程序面临着前所未有的挑战,其中最为显著的就是高并发访问的需求.随着用户数量的激增和业务规模的扩大,如何确保应用在高并发场景下依然能够稳定 ...
- 【Kafka】01 基于Docker环境的单例Kafka搭建
安装参考: https://www.cnblogs.com/vipsoft/p/13233045.html 环境安装需要 Zookeeper + Kafka 要学习Kafka还需要繁琐的安装配置,所以 ...
- 【CentOS】 8版本 Cannot update read-only repo 问题
GUI界面应用市场无法访问 https://blog.csdn.net/hm0406120201/article/details/104553205/
- 【PowerDesigner】快速上手
破解下载地址: https://www.onlinedown.net/soft/577763.htm 安装点试用,完成安装后把破解的dll库文件替换即可 学习参考自: https://www.bili ...
- 台式机电脑散热之狂想曲——主机机箱散热的另类方法(纯空想中ing)
本博文是一篇狂想曲,之所以叫狂想曲是因为本文只是博主在无聊时突发奇想,而且仅停留于想的阶段,所以本文内容不用太过认真. 事情是这样的,博主有一台式机,有事没事的就喜欢宅在宿舍里面,有时候还能偶然用这台 ...
- 多节点高性能计算GPU集群的构建
建议参考原文: https://www.volcengine.com/docs/6535/78310 ============================================= 一直都 ...
- 【转载】WSL 的基本命令
参考: https://learn.microsoft.com/zh-cn/windows/wsl/basic-commands https://blog.csdn.net/u010099177/ar ...
- 武汉市委郭元强书记、盛阅春代市长会见白鲸开源CEO郭炜等嘉宾代表
2024年6月14日,第二届软件创新发展大会在中国武汉举行.大会云集了来自全国的书数百位院士.专家.知名软件企业负责人,包括中国工程院院士倪光南.中国科学院院士陈十一.国家工业信息安全发展研究中心总工 ...
- grpc断路器之sentinel
荐
背景 为了防止下游服务雪崩,这里考虑使用断路器 技术选型 由于是springboot服务且集成了istio,这里考虑三种方案 istio hystrix sentinel 这里分别有这几种方案的对比 ...
- 2021 CCPC 哈尔滨
gym 开场 zsy 签了 J,gjk 签了 B,我读错了 E 的题意,gjk 读对后过了 zsy 读了 K 给我,我记得是模拟赛原题,跟欧拉定理有关,但很难.他俩过了 D I,我大概会了 G 但不会 ...