非常完整的线性DP及记忆化搜索讲义
基础概念
我们之前的课程当中接触了最基础的动态规划。
动态规划最重要的就是找到一个状态和状态转移方程。
除此之外,动态规划问题分析中还有一些重要性质,如:重叠子问题、最优子结构、无后效性等。
最优子结构 的概念:
1)如果问题的一个最优解包含了子问题的最优解,则该问题具有最优子结构。当一个问题具有最优子结构的时候,我们就可能要用到动态规划(贪心策略也是有可能适用的)。
2)寻找最优子结构时,可以遵循一种共同的模式:
- 问题的一个解可以是一个选择。例如,装配站选择问题。
- 假设对一个给定的问题,已知的是一个可以导致最优解的选择。不必关心如何确定这个选择,假定他是已知的。
- 在已知这个选择之后,要确定那些子问题会随之发生,以及如何最好的描述所的得到的子问题空间。
- 利用一种“剪贴”技术,来证明在问题的一个最优解中,使用的子问题的解本身也必须是最优的。
3)最优子结构在问题域中以两种方式变化:
- 有多少个子问题被使用在原问题的一个最优解中,以及
- 在决定一个最优解中使用那些子问题时有多少个选择
在装配线调度问题中,一个最优解只使用了一个子问题,但是,为确定一个最优解,我们必须考虑两种选择。
4)动态规划与贪心算法的区别
- 动态规划以自底向上的方式来利用最优子结构。也就是说,首先找到子问题的最优解,解决的子问题,然后找到问题的一个最优解。寻找问题的一个最优解需要首先在子问题中做出选择,即选择用哪一个来求解问题。问题解的代价通常是子问题的代价加上选择本身带来的开销。
- 在贪心算法中是以自顶向下的方式使用最优子结构。贪心算法会先做选怎,在当时看来是最优的选择,然后在求解一个结果子问题,而不是现寻找子问题的最优解,然后再做选择。
重叠子问题 的概念:
适用于动态规划求解的最优化问题必须具有的第二个要素是子问题的空间要“很小”,也就是用来解原问题的递归算法可以反复的解同样的子问题,而不是总在产生新的子问题。
比如:状态 \(i\) 的求解和状态 \(i-1\) 有关,状态 \(i-1\) 的求解和状态 \(i-2\) 有关,那么当我们计算得到状态 \(i\) 的时候,我们就可以用 \(f[i]\) 来表示状态 \(i\) ,那么当我下一次需要用到状态 \(i\) 的时候,我直接返回 \(f[i]\) 即可。
无后效性 的概念:
某阶段的状态一旦确定,则此后过程的演变不再受此前各种状态及决策的影响,简单的说,就是“未来与过去无关”,当前的状态是此前历史的一个完整总结,此前的历史只能通过当前的状态去影响过程未来的演变。具体地说,如果一个问题被划分各个阶段之后,阶段I中的状态只能由阶段I-1中的状态通过状态转移方程得来,与其它状态没有关系,特别是与未发生的状态没有关系。从图论的角度去考虑,如果把这个问题中的状态定义成图中的顶点,两个状态之间的转移定义为边,转移过程中的权值增量定义为边的权值,则构成一个有向无环加权图,因此,这个图可以进行“拓扑排序”,至少可以按它们拓扑排序的顺序去划分阶段。
我们在这篇讲义中主要讲解最基础的线性DP记忆记忆化解法。
其实我们可以发现,如果一个搜索解法添加上了记忆化,那么他就解决了“最优子结构”和“重叠子问题”,就变成了一个递归版本的动态规划了。
说明:
接下来的例题当中我们会讲解这些问题的for循环解法和记忆化搜索写法。
虽然for循环写法在我们这节课当中写起来更方便且很好理解,但是希望同学们务必了解并掌握 记忆化搜索 写法,因为我们接下来的几节课程会与记忆化搜索有非常重要的关系。
例题1 最长上升子序列
题目大意:
给你一个长度为 \(n\) 的数列 \(a_1,a_2, \cdots , a_n\) ,请你求出它的最长上升子序列的长度。
最长上升子序列:在不交换顺序的情况从序列 \(a\) 中选出一些元素(子序列不需要连续)使得前一个元素必然比后一个元素小。对应的最长的上升子序列就是最长上升子序列。
我们一般简称“最长上升子序列”为 LIS(Longest Increasing Subsequence)。
解题思路:
设状态 \(f[i]\) 表示以 \(a_i\) 结尾(并且包含 \(a_i\))的最长上升子序列长度,则:
- \(f[i]\) 至少为 \(1\);
- \(f[i] = \max (f[j])\) + 1,其中 \(j\) 满足 \(0 \le j \lt i\) 且 \(a[j] \lt a[i]\) 。
代码演示
首先我们定义数组和一些必要的变量:
int n, a[1010], f[1010], ans;
其中:
- \(n\) 表示数组元素个数;
- \(a\) 数组用于存值, \(a[i]\) 表示数组第 \(i\) 个元素的值;
- \(f\) 数组用于存状态, \(f[i]\) 表示以 \(a[i]\) 结尾的LIS长度;
- \(ans\) 用于存放我们最终的答案。
然后我们处理输入:
cin >> n;
for (int i = 1; i <= n; i ++)
cin >> a[i];
然后,我们演示一下用for循环的方式实现求解 \(f[1]\) 到 \(f[n]\):
for (int i = 1; i <= n; i ++) {
f[i] = 1;
for (int j = 1; j < i; j ++) {
if (a[j] < a[i]) {
f[i] = max(f[i], f[j]+1);
}
}
}
然后我们的答案就是 \(f[i]\) 的最大值:
for (int i = 1; i <= n; i ++)
ans = max(ans, f[i]);
cout << ans << endl;
那么,使用搜索+记忆化的方式怎么实现呢?如下:
int dfs(int i) {
if (f[i]) return f[i];
f[i] = 1;
for (int j = 1; j < i; j ++)
if (a[j] < a[i])
f[i] = max(f[i], dfs(j)+1);
return f[i];
}
记忆化搜索 又被称为 备忘录 ,而我们这里的备忘录就是我们的 \(f[i]\) 。
- 如果
dfs(i)是第一次被调用,\(f[i]=0\),会执行一系列的计算; - 但是如果
dfs(i)不是第一次被调用,则必然 \(f[i] \gt 0\),所以dfs(i)会直接返回 \(f[i]\) 的值,这样就避免了子问题的重读计算。
所以我在函数的最开始就进行了判断:
如果 \(f[i]\) 不为零,则直接返回 \(f[i]\)。
否则再进行计算。
然后,我们在可以通过如下方式计算答案:
for (int i = 1; i <= n; i ++)
ans = max(ans, dfs(i));
cout << ans << endl;
一般形式的完整代码:
#include <bits/stdc++.h>
using namespace std;
int n, a[1010], f[1010], ans;
int main() {
cin >> n;
for (int i = 1; i <= n; i ++) cin >> a[i];
for (int i = 1; i <= n; i ++) {
f[i] = 1;
for (int j = 1; j < i; j ++) {
if (a[j] < a[i])
f[i] = max(f[i], f[j]+1);
}
}
for (int i = 1; i <= n; i ++)
ans = max(ans, f[i]);
cout << ans << endl;
return 0;
}
记忆化搜索形式的完整代码:
#include <bits/stdc++.h>
using namespace std;
int n, a[1010], f[1010], ans;
int dfs(int i) {
if (f[i]) return f[i];
f[i] = 1;
for (int j = 1; j < i; j ++)
if (a[j] < a[i])
f[i] = max(f[i], dfs(j)+1);
return f[i];
}
int main() {
cin >> n;
for (int i = 1; i <= n; i ++) cin >> a[i];
for (int i = 1; i <= n; i ++)
ans = max(ans, dfs(i));
cout << ans << endl;
return 0;
}
例题2 最大字段和
题目大意:
我们可以把“字段”理解为“连续子序列”。
最大字段和问题就是求解所有连续子序列的和当中最大的那个和。
解题思路:
首先我们定义状态 \(f[i]\) 表示以 \(a[i]\) 结尾(并且包含\(a[i]\))的最大字段和。
那么我们可以得到状态转移方程:
\(f[i] = \max(f[i-1], 0) + a[i]\)
首先我们初始化及输入的部分如下(坐标从\(1\)到\(n\)):
int n, a[1010], f[1010], ans;
cin >> n;
for (int i = 1; i <= n; i ++)
cin >> a[i];
然后以一般方式求解的方式如下:
for (int i = 1; i <= n; i ++)
f[i] = max(f[i-1], 0) + a[i];
然后我们的答案就是所有 \(f[i]\) 的最大值:
for (int i = 1; i <= n; i ++)
ans = max(ans, f[i]);
cout << ans << endl;
递归形式,我们同样开一个函数 dfs(i) 用于返回 \(f[i]\) 的值。
但是这里我们无法通过 \(f[i]\) 的值确定 \(f[i]\) 是否已经求出来,所以我再开一个bool类型的 \(vis\) 数组,通过 \(vis[i]\) 来判断 \(f[i]\) 是否已经求过了。
bool vis[1010];
记忆化搜索实现如下:
int dfs(int i) {
if (i == 0) return 0; // 边界条件
if (vis[i]) return f[i];
vis[i] = true;
return f[i] = max(dfs(i-1), 0) + a[i];
}
注意:搜索/递归一定要注意边界条件。
然后,答案的求解方式1如下:
ans = dfs(1);
for (int i = 2; i <= n; i ++)
ans = max(ans, dfs(i));
cout << ans << endl;
答案的另一种求解方式如下:
dfs(n);
ans = f[1];
for (int i = 2; i <= n; i ++)
ans = max(ans, f[i]);
cout << ans << endl;
有没有发现,在这里我就调用了一次 \(dfs(n)\) ,所有的 \(f[i](1 \le i \le n)\) 的值就都求出来了呢。
因为我在第一次求 \(dfs(n)\) 的时候,会调用 \(dfs(n-1)\) ,而第一次 \(dfs(n-1)\) 会调用 \(dfs(n-2)\) ,……,第一次 \(dfs(2)\) 会调用 \(dfs(1)\)。
所以调用一下 \(dfs(n)\) ,我就把所有的 \(f[i]\) 都求出来了。
一般形式的完整实现代码如下:
#include <bits/stdc++.h>
using namespace std;
int n, a[1010], f[1010], ans;
int main() {
cin >> n;
for (int i = 1; i <= n; i ++) cin >> a[i];
for (int i = 1; i <= n; i ++)
f[i] = max(f[i-1], 0) + a[i];
for (int i = 1; i <= n; i ++)
ans = max(ans, f[i]);
cout << ans << endl;
return 0;
}
记忆化搜索的完整实现代码如下:
#include <bits/stdc++.h>
using namespace std;
int n, a[1010], f[1010], ans;
bool vis[1010];
int dfs(int i) {
if (i == 0) return 0; // 边界条件
if (vis[i]) return f[i];
vis[i] = true;
return f[i] = max(dfs(i-1), 0) + a[i];
}
int main() {
cin >> n;
for (int i = 1; i <= n; i ++) cin >> a[i];
// ans = dfs(1);
// for (int i = 2; i <= n; i ++)
// ans = max(ans, dfs(i));
dfs(n);
ans = f[1];
for (int i = 1; i <= n; i ++)
ans = max(ans, f[i]);
cout << ans << endl;
return 0;
}
例题3 数塔问题
题目大意:
有如下所示的数塔,要求从顶层走到底层,若每一步只能走到相邻的结点,则经过的结点的数字之和最大是多少?
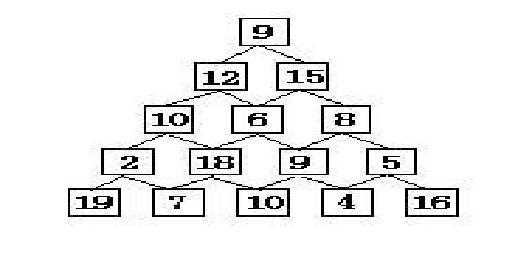
解题思路:
首先我们做一些假设:总共有 \(n\) 行,最上面的那行是第 \(1\) 行,最下面的那行是第 \(n\) 行,我们用 \((i,j)\) 来表示第 \(i\) 行第 \(j\) 个格子,用 \(a[i][j]\) 表示 \((i,j)\) 格子存放的值。
我们可以发现,从 \((i,j)\) 往下走走到最底层的最大数字和与从最下面的格子往上走走到 \((i,j)\) 的最大数字和是相等的。
所以我们可以把问题变成:求从最底下任意一个格子往上走走到 (1,1) 的最大数字和。
可以发现,经过这样一下思维的转换,我们就把一个“自顶向上”的问题转换成了一个“自底向上”的问题。
(请好好体会 “自顶向下” 和 “自底向上” 这两个概念,因为我们这道题接下来还会在另一个情景中讨论这两个概念)
我们可以发现,除了最底层(第 \(i\) 层)是直接走到的意外,上层的所有 \((i,j)\) 不是从 \((i+1,j)\) 走上来的,就是从 \((i+1, j+1)\) 走上来的。
所以我们不妨设 \(f[i][j]\) 表示从最底层任意一个位置往上走走到 \((i,j)\) 位置的最大数字和。
可以推导出:
- 当 \(i=n\) 时,\(f[i][j] = a[i][j]\);
- 当 \(i \lt n\) 时, \(f[i][j] = \max(f[i+1][j], f[i+1][j+1]) + a[i][j]\)
在推导的过程中,记得从 \(n\) 到 \(1\) 遍历 \(i\) ,因为高层的状态要先通过低层的状态推导出来。
一般形式的主要实现代码段如下:
for (int i = n; i >= 1; i --) { // 自底向上
for (int j = 1; j <= n; j ++) {
if (i == n)
f[i][j] = a[i][j];
else
f[i][j] = max(f[i+1][j], f[i+1][j+1]) + a[i][j];
}
}
可以发现,我们采用一般形式的写法,是先求解较低层的转态,然后通过低层的转态推导出高层的状态,所以我们也说这种实现思想是 自底向上 的。
讲完一般形式的实现方式,我们再来讲解使用 记忆化搜索 的形式进行求解的实现方式。
我们同样还是要定义一个状态 \(f[i][j]\) 表示从最底层任何一个位置走到 \((i,j)\) 的最大数字和(和上面的描述一样)。
但是我们不是以上面的一般形式来求解 \(f[i][j]\) ,而是开一个函数 dfs(int i, int j) 来求解 \(f[i][j]\)。
那么,我们怎么样来进行 记忆化 :即:判断当前的 \(f[i][j]\) 已经访问过呢?
因为一开始 \(f[i][j]\) 均为 \(0\),如果所有的数塔中的元素 \(a[i][j]\) 均 \(\gt 0\) ,那么 \(f[i][j]\) 一旦求过则 \(f[i][j]\) 必然也 \(\gt 0\)。
但是如果 \(a[i][j] \ge 0\)(即 \(a[i][j]\) 可以为 \(0\))或者 \(a[i][j]\) 可以是负数的情况下,我们就不能靠 \(f[i][j]\) 是否为 \(0\) 来判断 \((i,j)\) 这个格子有没有访问过了( 仔细思考一下为什么 )。
所以最靠谱,最不容易错的方式就是跟采用跟例2一样的方式,开一个二维 \(vis\) 数组, 用 \(vis[i][j]\) 来标识 \((i, j)\) 是否访问过。
记忆化搜索形式的主要代码片段如下:
int dfs(int i, int j) { // dfs(i,j)用于计算并返回f[i][j]的值
if (vis[i][j]) return f[i][j];
vis[i][j] = true;
if (i == n) // 边界条件——最底层
return f[i][j] = a[i][j];
return f[i][j] = max(dfs(i+1, j), dfs(i+1, j+1)) + a[i][j];
}
一般形式的完整代码如下:
#include <bits/stdc++.h>
using namespace std;
const int maxn = 101;
int n, a[maxn][maxn], f[maxn][maxn];
int main() {
cin >> n;
for (int i = 1; i <= n; i ++)
for (int j = 1; j <= i; j ++)
cin >> a[i][j];
for (int i = n; i >= 1; i --) { // 自底向上
for (int j = 1; j <= n; j ++) {
if (i == n) f[i][j] = a[i][j];
else f[i][j] = max(f[i+1][j], f[i+1][j+1]) + a[i][j];
}
}
cout << f[1][1] << endl;
return 0;
}
记忆化搜索的完整代码如下:
#include <bits/stdc++.h>
using namespace std;
const int maxn = 101;
int n, a[maxn][maxn], f[maxn][maxn];
bool vis[maxn][maxn];
int dfs(int i, int j) { // dfs(i,j)用于计算并返回f[i][j]的值
if (vis[i][j]) return f[i][j];
vis[i][j] = true;
if (i == n) // 边界条件——最底层
return f[i][j] = a[i][j];
return f[i][j] = max(dfs(i+1, j), dfs(i+1, j+1)) + a[i][j];
}
int main() {
cin >> n;
for (int i = 1; i <= n; i ++)
for (int j = 1; j <= i; j ++)
cin >> a[i][j];
cout << dfs(1, 1) << endl;
return 0;
}
非常完整的线性DP及记忆化搜索讲义的更多相关文章
- 蓝桥杯历届试题 地宫取宝 dp or 记忆化搜索
问题描述 X 国王有一个地宫宝库.是 n x m 个格子的矩阵.每个格子放一件宝贝.每个宝贝贴着价值标签. 地宫的入口在左上角,出口在右下角. 小明被带到地宫的入口,国王要求他只能向右或向下行走. 走 ...
- 【bzoj1415】【聪聪和可可】期望dp(记忆化搜索)+最短路
[pixiv] https://www.pixiv.net/member_illust.php?mode=medium&illust_id=57148470 Descrition 首先很明显是 ...
- 二进制数(dp,记忆化搜索)
二进制数(dp,记忆化搜索) 给定k个<=1e6的正整数x(k不大于10),问最小的,能被x整除且只由01组成的数. 首先,dp很好写.用\(f[i][j]\)表示i位01串,模ki的值是j的数 ...
- poj1179 区间dp(记忆化搜索写法)有巨坑!
http://poj.org/problem?id=1179 Description Polygon is a game for one player that starts on a polygon ...
- 洛谷 P1434 [SHOI2002]滑雪(DP,记忆化搜索)
题目描述 Michael喜欢滑雪.这并不奇怪,因为滑雪的确很刺激.可是为了获得速度,滑的区域必须向下倾斜,而且当你滑到坡底,你不得不再次走上坡或者等待升降机来载你.Michael想知道在一个区域中最长 ...
- UVA1351-----String Compression-----区间DP(记忆化搜索实现)
本文出自:http://blog.csdn.net/dr5459 题目地址: http://uva.onlinejudge.org/index.php?option=com_onlinejudge&a ...
- 2017广东工业大学程序设计竞赛决赛 题解&源码(A,数学解方程,B,贪心博弈,C,递归,D,水,E,贪心,面试题,F,贪心,枚举,LCA,G,dp,记忆化搜索,H,思维题)
心得: 这比赛真的是不要不要的,pending了一下午,也不知道对错,直接做过去就是了,也没有管太多! Problem A: 两只老虎 Description 来,我们先来放松下,听听儿歌,一起“唱” ...
- 树形DP(记忆化搜索) HYSBZ - 1509
题目链接:https://vjudge.net/problem/HYSBZ-1509 我参考的证明的论文:8.陈瑜希<多角度思考 创造性思维>_百度文库 https://wenku.ba ...
- UVA-10118 Free Candies (DP、记忆化搜索)
题目大意:有4堆糖果,每堆有n个,有一只最多能容5个糖果的篮子.现在,要把糖果放到篮子里,如果篮子中有相同颜色的糖果,放的人就可以拿到自己的口袋.如果放的人足够聪明,问他最多能得到多少对糖果. 题目分 ...
随机推荐
- @noi.ac - 170@ 数数
目录 @description@ @solution@ @accepted code@ @details@ @description@ 求有多少对 1 ∼ n 的排列 (a, b) 满足 \(m \l ...
- IE下form表单密码输入框可以输入中文问题
今天遇到了一个问题: 在IE浏览器登录界面,密码输入框,切换到中文输入法,竟然可以输入中文,已经设置过了input的type="password". 解决方法: 可以给input设 ...
- pytorch入坑一 | Tensor及其基本操作
由于之前的草稿都没了,现在只有重写…. 我好痛苦 本章只是对pytorch的常规操作进行一个总结,大家看过有脑子里有印象就好,知道有这么个东西,需要的时候可以再去详细的看,另外也还是需要在实战中多运用 ...
- 精选Pycharm里6大神器插件
http://www.sohu.com/a/306693644_752099 上次写了一篇关于Sublime的精品插件推荐,有小伙伴提议再来一篇Pycharm的主题.相比Sublime,Pycharm ...
- 网易大数据平台的Spark技术实践
网易大数据平台的Spark技术实践 作者 王健宗 网易的实时计算需求 对于大多数的大数据而言,实时性是其所应具备的重要属性,信息的到达和获取应满足实时性的要求,而信息的价值需在其到达那刻展现才能利益最 ...
- H3C 子网划分方法
- linux oops 消息
大部分 bug 以解引用 NULL 指针或者使用其他不正确指针值来表现自己的. 此类 bug 通 常的输出是一个 oops 消息. 处理器使用的任何地址几乎都是一个虚拟地址, 通过一个复杂的页表结构映 ...
- 2018-11-5-win10-uwp-异步转同步
title author date CreateTime categories win10 uwp 异步转同步 lindexi 2018-11-05 10:18:40 +0800 2018-2-13 ...
- CodeForces 906D (欧拉降幂)
Power Tower •题意 求$w_{l}^{w_{l+1}^{w_{l+2}^{w_{l+3}^{w_{l+4}^{w_{l+5}^{...^{w_{r}}}}}}}}$ 对m取模的值 •思路 ...
- HDU6621 K-th Closest Distance HDU2019多校训练第四场 1008(主席树+二分)
HDU6621 K-th Closest Distance HDU2019多校训练第四场 1008(主席树+二分) 传送门:http://acm.hdu.edu.cn/showproblem.php? ...