巨杉内核笔记(一)| SequoiaDB 会话(session)简介
SequoiaDB 会话(session)简介
会话(Session)的基本概念
容易弄混淆的两个概念是会话与连接。
通俗来讲,会话(Session) 是通信双方从开始通信到通信结束期间的一个上下文(Context)。这个上下 文是一段位于服务器端的内存:记录了本次连接的客户端机器、通过哪个应用程序、哪个用户登录等信息。
而连接(Connection):连接是从客户端到数据库实例的一条物理路径。连接可以在网络上建立,或者在本机通过IPC机制建立。通常会在客户 端进程与一个专用服务器或一个调度器之间建立连接。
SequoiaDB 中的会话设计
SequoiaDB 中的会话有很多种,不同的会话对应不同的服务。会话的主要任务是处理通信的对端发过来的请求。各种类型的会话能处理的请求不一样。
通信平面
为了提供不同类型的服务,并使各服务之间隔离,SequoiaDB 的节点提供了多个通信平面。简单来讲,一个通信平面对应一个服务端口,不同 的端口提供不同类型的服务,这也就是在安装 SequoiaDB 时,要求一定范围内的端口号预留的原因。
SequoiaDB 中当前提供了如下几个通信平面:
- local 平面(local service): 使用基础服务端口号 svcname
- repl 平面(repl service):使用端口号 svcname + 1
- shard 平面(shard service):使用端口号 svcname + 2
- cat 平面(cat service):使用端口号 svcname + 3
- rest 平面(rest service):使用端口号 svcname + 4
- om 平面(om service):使用端口号 svcname + 5
不同的节点上开启的服务平面不一样。节点上通过不同平面提供不同的服务,就像同一间屋子开了几个门,被访问的数据就如同屋子里面的东 西,是大家所共享的。每一个平面都可能有一个或多个用户来进行访问,因此,在系统内部要做好它们的并发控制。
本地会话(Local Session)
本地会话是在直连节点(即配置的 svcname)时创建。这里的直连含义比较宽泛,连接任意节点的本地服务端口即是直连,无论是单机,还是 集群中的任意节点。客户端连接到协调节点时,协调节点上也是创建的本地会话。 本地端口上的监听接收到新的连接请求时,会创建一个新的 会话(内存结构)及一个服务线程(执行单元),将它们绑定(attach)起来。后续客户端直接与这个新的服务线程进行交互。
代码导读
1. SequoiaDB 中各类型的会话继承关系如下图所示。
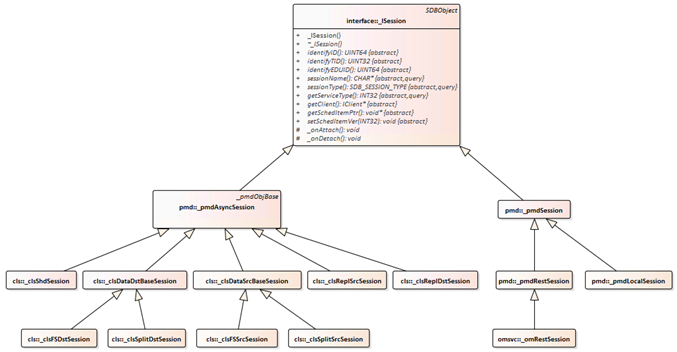
从图中可以看到,本地会话、增量/全量同步会话、复制会话等,都是继承自同一个基类 _ISession。下面结合组网对其中几个关键的会话进行介绍,主要是会话建立/销毁的时机、会话的结构、操作等。
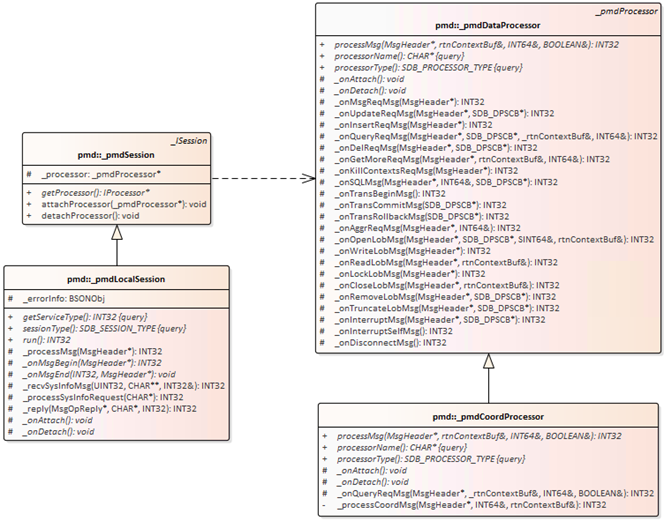
2.本地会话对应数据结构是类 _pmdLocalSession,线程的主函数是 _pmdLocalSession::run(),会话线程启动后,就在这个函数里循环, 接收及处理消息,直到会话需要结束时退出该循环。
3. 本地会话能绑定不同的 processor,以执行不同的处理流程。对于协调节点,绑定的是 _pmdCoordProcessor,对于编目节点和数据节点,绑定的是 _pmdDataProcessor。对于协调节点,会先调用 _pmdCoordProcessor 的接口进行消息处理,在无法识别请求类型时,则会再次调用 _pmdDataProcessor 的接口进行处理。
分区会话(Shard Session)
分区会话存在于编目节点与数据节点上,因为是在这两种节点上真正分布式存储数据,真正与分片这个概念相关。协调节点上不存储数据,不 涉及到分片,因此它上面没有分片会话。在代码实现上,分片会话的管理整合到了 clsCB 中(它还管理着复制会话)。
当通过 shard 平面连接到节点时,在节点上就会创建一个分区会话。 shard 平面与本地平面存在一些差异:
shard 平面看不到节点上的系统集合空间,本地平面可以 通过 shard 平面进行的操作会写复制日志,通过本地平面的不会(这也就是为什么直连数据节点下进行数据操作会造成主备数据不一致 的原因,如果是通过 shard 平面连接数据节点操作,则数据变更会被同步到备节点上)
分区会话是继承自统一的异步会话框架,包含一个分区会话管理器,由它来负责分区会话的创建等工作。会话的主要工作则是在被创建后,处 理客户的请求。关于异步会话的机制,详见相关的介绍。
当协调节点通过 shard 平面连接到数据节点时,新创建的会话接收到的第一个消息是 init session(在 3.0 后的版本中是 package 消息,它将 init session 及部分其它消息打包到一个消息包中)。
代码导读
1. 分区会话管理器类是 _clsShardSessionMgr,分区会话类是 _clsShdSession
2. 通过异步会话管理器( _clsShardSessionMgr 的父类) 的 getSession() 接口来获取已有 session,或者创建一个新的异步会话
3. _clsShdSession 的主消息处理入口是 _clsShdSession::_onOPMsg,它根据消息码,调用对应的消息处理函数,并发送应答消息
同步(或复制)会话(Repl Session)
分区组内的节点间,通过同步动作来保证数据的一致性,分为正常运行状态下的增量同步,和异常情况下的全量同步。同步也是通过对应的同 步会话与同步线程来处理的。由于同步涉及到两个节点,数据生产方称为源端,数据消费方称为目标端。由于只有数据节点与编目节点上会进 行数据复制,因此只有在这两种类型的节点上,才会存在同步会话。
1)增量同步会话
增量同步会话在复制组正常运行期间存在,分为增量同步源端会话和目标端会话。在数据/编目节点的启动过程中,就会开启增量同步的监听, 而无论其是主节点还是从节点。同时,它也会主动启动一个增量复制目标端会话,并向它选定的源端发送同步请求。源端节点上会被动创建一 个增量同步源端会话。然后,这两个会话开始进行交互,完成数据同步。详见 增量同步 相关章节。
2)全量同步会话
全量同步会话是进行全量同步时存在,在集群正常运行期间及全量同步完成后不存在,也分为源端和目标端。需要全量同步的场景有三种:
- 节点的重放速度跟不上主节点,主节点上复制日志绕接,导致备节点还未获取到的复制日志被覆盖,备节点无法继续增量同步。
- 节点异常重启,启动后根据读取到的异常启动状态决定全量同步。
- 节点正常停止后正常重启,但停的时间较长,期间其它节点上的日志已经发生了绕接。
无论是上述哪种情况,都是先有增量复制会话,然后由于这些原因导致增量同步无法继续进行的时候,就会在目标节点上主动创建一个全量同 步会话(以及对应的线程),且当前的增量复制线程退出。全量同步会话一旦启动之后,就会向源端发送一个全量同步开始的消息。此时源端 上会被动创建一个全量同步源端会话。至此,全量同步的会话创建完成,然后,这两个会话之间开始进行交互,完成数据同步。详见 全量同步 相关章节。
代码导读
1. 同步相关的会话,都是异步会话,这四种会话,使用同一个会话管理器来进行管理:_clsReplSessionMgr
2. 四种会话对应的类为:_clsReplSrcSession,_clsReplDstSession,_clsFSSrcSession,_clsFSDstSession
3. 异步会话响应的消息类型及对应的处理函数,一般在对应的类中通过 OBJ_MSG_MAP 等宏进行定义,请参考代码。
会话的查看
可通过 snapshot 查看会话快照,可查看当前会话或系统中的所有会话。这个命令实现的其实是与线程对应,可返回所有线程的信息,包括系 统后台线程。查询会话的详细结果见相关文档。
代码导读
session 的导出动作在类 _monSessionFetcher 类中实现,在其 init() 函数中准备好数据。可选择查看当前会话(使用当前线程的 eduCB 接口 导出)或所有会话(使用 _pmdEDUMgr 的接口导出)。 在准备好数据后,由上层统一的 context 框架调用该类的 fetch 接口获取数据。
SequoiaDB简介:
SequoiaDB 巨杉数据库是一款金融级分布式关系型数据库, 其自研的原生分布式存储引擎支持完整 ACID,具备弹性扩展、高并发和高可用特性,支持 MySQL、PostgreSQL 和 SparkSQL 等多种 SQL 访问形式,适用于核心交易、数据中台、内容管理等应用场景。
标准SQL支持,MySQL协议级兼容
SequoiaDB目前支持 MySQL、PostgreSQL 和 SparkSQL 等多种 SQL 访问形式。SequoiaDB还提供了类S3对象访问以及Posix文件系统接口、MongoDB兼容的原生JSON引擎以及深度数据压缩等多项全新功能。
金融级分布式OLTP
SequoiaDB使用其自研的开源数据库存储引擎,全面支持ACID(原子性、一致性、隔离性与持久性)、分布式跨表跨节点事务能力、可配置强一致与最终一致性保证、同时在优化器端支持CBO(Cost-Based Optimization)、多维度数据分区、以及HTAP等多种技术特性。
分布式架构
SequoiaDB数据存储引擎采用原生分布式架构,数据完全打散在分布式节点间存储,自动化数据分布和管理,数据可以按需灵活扩展,目前生产环境实测支持超过1000个节点集群。
Multi-Model多模数据引擎
SequoiaDB灵活的数据存储类型,支持非结构化、结构化和半结构化数据全覆盖,实现多模(Multi-Model)数据统一管理,更符合云化数据架构下对于多样化业务数据的统一管理和运维要求。
HTAP混合事务/分析处理
SequoiaDB通过SQL的完全支持以及Spark的整合,实现HTAP混合事务和分析处理,快速实现业务应用的弹性开发,应对更多复杂应用场景。同时,通过分布式数据库多副本机制,将在线交易和离线分析业务物理隔离,实现同一组数据在应对不同类型业务时互不干扰。
数据安全与多活容灾
SequoiaDB巨杉数据库原生支持数据库内核级别的高可用以及跨数据中心灾备能力,目前已经实现异地容灾备份,可满足“三地五中心”的容灾支持。同时,巨杉数据库在异地容灾基础上,实现了数据异地多活,目前已经实现双中心同时读写,中心切换RPO为0和RTO达到秒级,提供了“超金融级”的数据安全保障。
扩展阅读
会话快照
http://doc.sequoiadb.com/cn/index-cat_id-1479173713-edition_id-302
当前会话快照
http://doc.sequoiadb.com/cn/index-cat_id-1479173714-edition_id-302
会话列表
http://doc.sequoiadb.com/cn/index-cat_id-1479173733-edition_id-300
巨杉内核笔记(一)| SequoiaDB 会话(session)简介的更多相关文章
- 巨杉内核笔记 | 会话(Session)
SequoiaDB 巨杉数据库是一款金融级分布式关系型数据库,坚持从零开始打造分布式开源数据库引擎.“内核笔记系列”旨在分享交流 SequoiaDB 巨杉数据库引擎的设计思路和代码解析,帮助社区用户深 ...
- [terry笔记]Oracle会话追踪(二):TKPROF
接上一笔记[terry笔记]Oracle会话追踪(一):SQL_TRACE&EVENT 10046 http://www.cnblogs.com/kkterry/p/3279282.html ...
- [terry笔记]Oracle会话追踪(一):SQL_TRACE&EVENT 10046
SQL_TRACE/10046 事件是 Oracle 提供的用于进行 SQL 跟踪的手段,在日常的数据库问题诊断和解决中是非常常用的方法.但其生成的trace文件需要tkprof工具生成一个可供人 ...
- 请求与上传文件,Session简介,Restful API,Nodemon
作者 | Jeskson 来源 | 达达前端小酒馆 请求与上传文件 GET请求和POST请求 const express = require('express'); const app = expre ...
- Session (简介、、相关方法、流程解析、登录验证)
Session简介 Session的由来 Cookie虽然在一定程度上解决了"保持状态"的需求,但是由于Cookie本身最大支持4096字节,以及Cookie本身保存在客户端,可能 ...
- Linux内核笔记--内存管理之用户态进程内存分配
内核版本:linux-2.6.11 Linux在加载一个可执行程序的时候做了种种复杂的工作,内存分配是其中非常重要的一环,作为一个linux程序员必然会想要知道这个过程到底是怎么样的,内核源码会告诉你 ...
- 简单PHP会话(session)说明
现在程序员愈发的不容易了,想要精通,必然要寻本溯源,这其实与目前泛滥的愈发高级的语言以及众多的框架刚好相反,因为它们在尽可能的掩盖本源使其简单,个人称之为程序员学习悖论. 注:作者接触web开发和ph ...
- 【转载】linux内核笔记之进程地址空间
原文:linux内核笔记之进程地址空间 进程的地址空间由允许进程使用的全部线性地址组成,在32位系统中为0~3GB,每个进程看到的线性地址集合是不同的. 内核通过线性区的资源(数据结构)来表示线性地址 ...
- 【转载】linux内核笔记之高端内存映射
原文:linux内核笔记之高端内存映射 在32位的系统上,内核使用第3GB~第4GB的线性地址空间,共1GB大小.内核将其中的前896MB与物理内存的0~896MB进行直接映射,即线性映射,将剩余的1 ...
随机推荐
- Redis常用命令之操作String类型
场景 Centos中Redis的下载编译与安装(超详细): https://blog.csdn.net/BADAO_LIUMANG_QIZHI/article/details/103967334 Re ...
- centos安装gitlab及汉化
GitLab 是一个用于仓库管理系统的开源项目,使用Git作为代码管理工具,并在此基础上搭建起来的web服务.今天,就记录一下centos部署gitlab及其汉化的操作方法. 1.下载安装 下载地址: ...
- Remoting、WCF、WebAPI、WCFREST、WebService之间的区别与联系
在.net平台下,有大量的技术让你创建一个服务,像Web Service,WCF,Web API,Remoting,我们来对比一下他们的区别与联系 Remoting Web Service WCF W ...
- css3基础-文本与字体+转换+过渡+动画+案例
Css3文本与字体 文本阴影 h1 { text-shadow: 5px 5px 5px red; } word-break换行: h1:nth-child(1) { word-break: no ...
- css权值和优先级+命名规范
选择器权值: 标签选择器:1 类选择器和伪类选择器:10 ID选择器:100 通配符选择器:0 行内样式:1000 !important 在一定条件下,优先级最高 常用的css样式命名 页面结构页头: ...
- java多线程技能-使用多线程-继承Thread类
/* 使用多线程可通过继承Thread类或实现Runnable接口. Thread和Runnable的关系:public class Thread implements Runnable. 使用thr ...
- 【NLP】暑假课作业1 - 中文分词(前向匹配算法实现)
作业任务: 使用98年人民日报语料库进行中文分词训练及测试. 作业输入: 98年人民日报语料库(1998-01-105-带音.txt),用80%的数据作为训练集,20%的数据作为验证集. 运行环境: ...
- Excel创建下拉列表限制数据有效性
方法 选中目标区域,点击菜单栏[数据]-[数据验证]-验证条件选择[序列]-输入所需文本即可
- web服务器的解析漏洞罗列
前言 服务器相关中间件存在一些解析漏洞,攻击者可通过上传一定格式的文件,被服务器的中间件进行了解析,这样就对系统造成一定危害.常见的服务器解析漏洞涉及的中间件有IIS,apache.nginx等.可利 ...
- ubuntu set up 5 - VIM
Edit ~/.vimrc source vimrc: :so ~/.vimrc 1. ctrl - left/right 切换tabs https://vim.fandom.com/wiki/Usi ...