springboot笔记-2-.核心的上下文以及配置扫描解析(上)
前言
上一节中简要说明了下springboot自动化配置的关键,那么本节看下springboot真正的初始化过程,如何创建上下文并解析配置,加载我们注册到容器管理中的类。上节已经成功的创建了SpringApplication,那我们就看下其run方法究竟做了些什么
正文
我们从SpringApplication的run方法开始入手,只看核心代码,其他省略
public ConfigurableApplicationContext run(String... args) {
...//省略代码
//声明spring上下文
ConfigurableApplicationContext context = null;
try {
..//省略代码
//2.新建应用上下文
context = createApplicationContext();
..//省略代码
//3.刷新上下文
refreshContext(context);
//4.完成刷新上下文后调用(目前空白)
afterRefresh(context, applicationArguments);
..//省略代码
}
return context;
}
通过上面我们可以发现,run方法核心步骤就是创建ApplicatonContext,这儿主要的步骤有两个 1.创建应用上下文 2.刷新上下文。我们从创建开始看
1.创建spring的核心 ApplicationContext
查看createApplicationContext方法
public static final String DEFAULT_WEB_CONTEXT_CLASS = "org.springframework.boot."
+ "web.servlet.context.AnnotationConfigServletWebServerApplicationContext";
protected ConfigurableApplicationContext createApplicationContext() {
Class<?> contextClass = this.applicationContextClass;
if (contextClass == null) {
try {
switch (this.webApplicationType) {
case SERVLET:
//我们使用这个
contextClass = Class.forName(DEFAULT_WEB_CONTEXT_CLASS);
break;
case REACTIVE:
contextClass = Class.forName(DEFAULT_REACTIVE_WEB_CONTEXT_CLASS);
break;
default:
contextClass = Class.forName(DEFAULT_CONTEXT_CLASS);
}
}
..//省略
}
//反射生成实例
return (ConfigurableApplicationContext) BeanUtils.instantiateClass(contextClass);
}
这儿其实看着是很简单的逻辑,就是根据类型,选择与一个合适的创建,这儿我们就用常见的servlet来说明。servlet对应的上下文为AnnotationConfigServletWebServerApplicationContext。然后最后会根据反射来生成一个实例并返回。我们可以看下这个上下文的类图
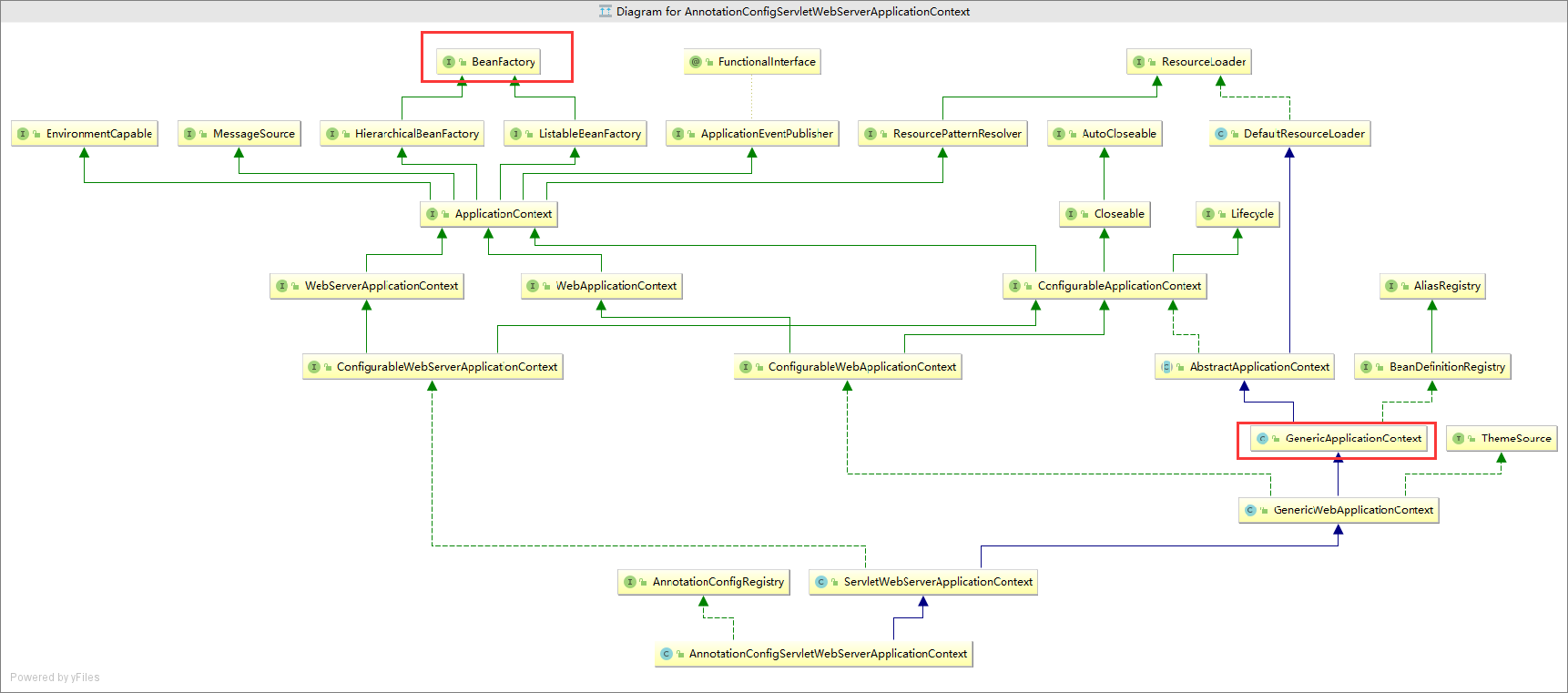
相信这个类继承结构大家都看着比较头痛,毕竟作为核心类。这儿就挑两个个重要的说下。
第一。 其最终实现了BeanFactory接口,并继承了GenericApplicationContext。并且我们查看其构造函数会传入一个BeanFactory
public AnnotationConfigServletWebServerApplicationContext(DefaultListableBeanFactory beanFactory) {
super(beanFactory);
this.reader = new AnnotatedBeanDefinitionReader(this);
this.scanner = new ClassPathBeanDefinitionScanner(this);
}
最终在GenericApplicationContext中有如下代码
private final DefaultListableBeanFactory beanFactory;
public GenericApplicationContext() {
this.beanFactory = new DefaultListableBeanFactory();
}
public GenericApplicationContext(DefaultListableBeanFactory beanFactory) {
Assert.notNull(beanFactory, "BeanFactory must not be null");
this.beanFactory = beanFactory;
}
会发现上下文不论如何都会持有一个beanFactory,很多人被问到过ApplicationContext和beanFactory的区别与联系。其实这儿就能看出来是一个很典型的静态代理的案例。既然是代理,就说明了肯定ApplicationContext在保持Beanfactory的原有功能时又扩展了很多功能。这样就可以做到既兼容旧版本,又增强很多功能。当然了,具体的区别有兴趣的可以去看下二者的源代码。
第二。我们在AnnotationConfigServletWebServerApplicationContext的构造函数中发现了有如下步骤
this.reader = new AnnotatedBeanDefinitionReader(this);
这儿新建了一个注解bean的解析器。我们一路跟着源码看下
public AnnotatedBeanDefinitionReader(BeanDefinitionRegistry registry, Environment environment) {
Assert.notNull(registry, "BeanDefinitionRegistry must not be null");
Assert.notNull(environment, "Environment must not be null");
this.registry = registry;
this.conditionEvaluator = new ConditionEvaluator(registry, environment, null);
AnnotationConfigUtils.registerAnnotationConfigProcessors(this.registry);
}
这儿我们会发现该方法最后会为registry注册一些解析器,我们看下AnnotationConfigUtils.registerAnnotationConfigProcessors(this.registry);该方法会为Beanfactory设置一系列的BeanDefinition,以及其他的一些东西,
public static Set<BeanDefinitionHolder> registerAnnotationConfigProcessors(
BeanDefinitionRegistry registry, @Nullable Object source) { DefaultListableBeanFactory beanFactory = unwrapDefaultListableBeanFactory(registry);
if (beanFactory != null) {
if (!(beanFactory.getDependencyComparator() instanceof AnnotationAwareOrderComparator)) {
beanFactory.setDependencyComparator(AnnotationAwareOrderComparator.INSTANCE);
}
if (!(beanFactory.getAutowireCandidateResolver() instanceof ContextAnnotationAutowireCandidateResolver)) {
beanFactory.setAutowireCandidateResolver(new ContextAnnotationAutowireCandidateResolver());
}
} Set<BeanDefinitionHolder> beanDefs = new LinkedHashSet<>(4); // 处理@Configuration @ComponentScans @Component @Bean等注解 @PropertySources @ImportResource 等
if (!registry.containsBeanDefinition(CONFIGURATION_ANNOTATION_PROCESSOR_BEAN_NAME)) {
RootBeanDefinition def = new RootBeanDefinition(ConfigurationClassPostProcessor.class);
def.setSource(source);
beanDefs.add(registerPostProcessor(registry, def, CONFIGURATION_ANNOTATION_PROCESSOR_BEAN_NAME));
}
// 处理 @Autowired @Value 等
if (!registry.containsBeanDefinition(AUTOWIRED_ANNOTATION_PROCESSOR_BEAN_NAME)) {
RootBeanDefinition def = new RootBeanDefinition(AutowiredAnnotationBeanPostProcessor.class);
def.setSource(source);
beanDefs.add(registerPostProcessor(registry, def, AUTOWIRED_ANNOTATION_PROCESSOR_BEAN_NAME));
}
// 处理@Required @
if (!registry.containsBeanDefinition(REQUIRED_ANNOTATION_PROCESSOR_BEAN_NAME)) {
RootBeanDefinition def = new RootBeanDefinition(RequiredAnnotationBeanPostProcessor.class);
def.setSource(source);
beanDefs.add(registerPostProcessor(registry, def, REQUIRED_ANNOTATION_PROCESSOR_BEAN_NAME));
} // 处理类似@PostConstruct 和@PreDestroy
if (jsr250Present && !registry.containsBeanDefinition(COMMON_ANNOTATION_PROCESSOR_BEAN_NAME)) {
RootBeanDefinition def = new RootBeanDefinition(CommonAnnotationBeanPostProcessor.class);
def.setSource(source);
beanDefs.add(registerPostProcessor(registry, def, COMMON_ANNOTATION_PROCESSOR_BEAN_NAME));
} // 如果有jpa的话这里有处理的 例如@Selevt
if (jpaPresent && !registry.containsBeanDefinition(PERSISTENCE_ANNOTATION_PROCESSOR_BEAN_NAME)) {
RootBeanDefinition def = new RootBeanDefinition();
try {
def.setBeanClass(ClassUtils.forName(PERSISTENCE_ANNOTATION_PROCESSOR_CLASS_NAME,
AnnotationConfigUtils.class.getClassLoader()));
}
catch (ClassNotFoundException ex) {
throw new IllegalStateException(
"Cannot load optional framework class: " + PERSISTENCE_ANNOTATION_PROCESSOR_CLASS_NAME, ex);
}
def.setSource(source);
beanDefs.add(registerPostProcessor(registry, def, PERSISTENCE_ANNOTATION_PROCESSOR_BEAN_NAME));
}
// 处理类似@EventListener的注解
if (!registry.containsBeanDefinition(EVENT_LISTENER_PROCESSOR_BEAN_NAME)) {
RootBeanDefinition def = new RootBeanDefinition(EventListenerMethodProcessor.class);
def.setSource(source);
beanDefs.add(registerPostProcessor(registry, def, EVENT_LISTENER_PROCESSOR_BEAN_NAME));
}
if (!registry.containsBeanDefinition(EVENT_LISTENER_FACTORY_BEAN_NAME)) {
RootBeanDefinition def = new RootBeanDefinition(DefaultEventListenerFactory.class);
def.setSource(source);
beanDefs.add(registerPostProcessor(registry, def, EVENT_LISTENER_FACTORY_BEAN_NAME));
} return beanDefs;
}
可以发现这儿设置了很多BeanDefinition,尤其是是ConfigurationClassPostProcessor,AutowiredAnnotationBeanPostProcessor这两可以说是相当核心的两个后置处理器,在后面spring进行配置解析的时候会相当的有用。
到此,创建ApplicationContext就完成了,我们看系统刷新上下文的时候做了些什么
2. refreshContext spring的核心加载方法
该方法可以说占据了springboot启动的绝大部分时间,也是springboot启动中最为核心的方法。
private void refreshContext(ConfigurableApplicationContext context) {
refresh(context);
if (this.registerShutdownHook) {
try {
context.registerShutdownHook();
}
catch (AccessControlException ex) {
// Not allowed in some environments.
}
}
}
protected void refresh(ApplicationContext applicationContext) {
Assert.isInstanceOf(AbstractApplicationContext.class, applicationContext);
((AbstractApplicationContext) applicationContext).refresh();
}
跟着代码一路走,发现其最终调用的是上下文的refresh方法。由于其被强转为AbstractApplicationContext,所以我们直接看其refresh方法,到此就进入ApplicationContext类中了。
3.ApplicationContext中refresh方法
该方法里面有很多初始化方法,我们也选择核心的说明
@Override
public void refresh() throws BeansException, IllegalStateException {
synchronized (this.startupShutdownMonitor) {
//初始化之前的一些准备,例如设置开始标记等
prepareRefresh(); // 获取到上面提到的beanFactory
ConfigurableListableBeanFactory beanFactory = obtainFreshBeanFactory(); // 初始注册一些要用到的类
prepareBeanFactory(beanFactory); try {
// 添加一些BeanFactory的postProcess
postProcessBeanFactory(beanFactory); // 执行BeanFactory的PostProcessors
invokeBeanFactoryPostProcessors(beanFactory); // 注册一些BeanPostProcessors
registerBeanPostProcessors(beanFactory); ../略过 // 一些特殊的操作,例如
//本案例中是AnnotationConfigServletWebServerApplicationContext 那么这儿会开始创建servlet容器
onRefresh(); ../略过 // 实例化容器中未设置懒加载的类
finishBeanFactoryInitialization(beanFactory); ../略过
} }
}
这儿我们我们主要看两个方法 一是invokeBeanFactoryPostProcessors,该方法会找出所有需要加载的bean。然后是finishBeanFactoryInitialization方法,该方法会将需要加载的bean进行实例化并装载属性。
4.invokeBeanFactoryPostProcessors方法
该方法我们跟着源代码走,最终会走到PostProcessorRegistrationDelegate.invokeBeanFactoryPostProcessors方法,由于该方法过长。所以我们分段说明
4.1 无所不在的PostProcesser
不得不说spring将切面应用到了极致啊。。基本每初始化某个东西都会有其对应的PostProcessor,虽然看着略显繁琐,但是却极大的增加了我们的扩展点
public static void invokeBeanFactoryPostProcessors(
ConfigurableListableBeanFactory beanFactory, List<BeanFactoryPostProcessor> beanFactoryPostProcessors) { // Invoke BeanDefinitionRegistryPostProcessors first, if any.
Set<String> processedBeans = new HashSet<>(); if (beanFactory instanceof BeanDefinitionRegistry) {
//将我们的BeanFactory强转为BeanDefinitionRegistry
BeanDefinitionRegistry registry = (BeanDefinitionRegistry) beanFactory;
List<BeanFactoryPostProcessor> regularPostProcessors = new LinkedList<>();
List<BeanDefinitionRegistryPostProcessor> registryProcessors = new LinkedList<>();
//循环我们传入的BeanFactoryPostProcessor 如果其是BeanDefinitionRegistryPostProcessor
//那么这儿执行其postProcessBeanDefinitionRegistry方法
for (BeanFactoryPostProcessor postProcessor : beanFactoryPostProcessors) {
if (postProcessor instanceof BeanDefinitionRegistryPostProcessor) {
BeanDefinitionRegistryPostProcessor registryProcessor =
(BeanDefinitionRegistryPostProcessor) postProcessor;
registryProcessor.postProcessBeanDefinitionRegistry(registry);
registryProcessors.add(registryProcessor);
}
else {
regularPostProcessors.add(postProcessor);
}
}
上述代码也是执行了传入的Proccessor类型为BeanDefinitionRegistryPostProcessor的postProcessBeanDefinitionRegistry方法。
4.2 第一级BeanDefinitionRegistryPostProcessor执行(即实现了PriorityOrdered接口)
List<BeanDefinitionRegistryPostProcessor> currentRegistryProcessors = new ArrayList<>(); // 找到系统所有实现了PriorityOrdered接口的BeanDefinitionRegistryPostProcessor接口实现类
// 这儿会找到我们刚刚的 ConfigurationClassPostProcessor
String[] postProcessorNames =
beanFactory.getBeanNamesForType(BeanDefinitionRegistryPostProcessor.class, true, false);
for (String ppName : postProcessorNames) {
if (beanFactory.isTypeMatch(ppName, PriorityOrdered.class)) {
currentRegistryProcessors.add(beanFactory.getBean(ppName, BeanDefinitionRegistryPostProcessor.class));
processedBeans.add(ppName);
}
}
//排序
sortPostProcessors(currentRegistryProcessors, beanFactory);
//将刚找到的BeanDefinitionRegistryPostProcessor加入registryProcessors
registryProcessors.addAll(currentRegistryProcessors);
//执行刚找到的BeanDefinitionRegistryPostProcessor
invokeBeanDefinitionRegistryPostProcessors(currentRegistryProcessors, registry);
//清空
currentRegistryProcessors.clear();
这儿即找实现了BeanDefinitionRegistryPostProcessor,PriorityOrdered的类。而我们在第一节中最后提到的ConfigurationClassPostProcessor刚好是满足的,我们可以在回顾一下

这儿我们进入invokeBeanDefinitionRegistryPostProcessors方法看下
private static void invokeBeanDefinitionRegistryPostProcessors(
Collection<? extends BeanDefinitionRegistryPostProcessor> postProcessors, BeanDefinitionRegistry registry) { for (BeanDefinitionRegistryPostProcessor postProcessor : postProcessors) {
postProcessor.postProcessBeanDefinitionRegistry(registry);
}
}
可以看到是迭代所有BeanDefinitionRegistryPostProcessor并执行其postProcessBeanDefinitionRegistry方法。而上面说到我们会拿到ConfigurationClassPostProcessor,所以这儿我们直接看ConfigurationClassPostProcessor的方法,由于该方法是spring进行配置解析的重中之重,所以篇幅较长
4.2.1 校验并为本次解析设置id,防止重复加载
第一步则是设置了本次解析的id,防止重复解析
public void postProcessBeanDefinitionRegistry(BeanDefinitionRegistry registry) {
//得到registry的hash码作为id
int registryId = System.identityHashCode(registry);
//校验id
if (this.registriesPostProcessed.contains(registryId)) {
throw new IllegalStateException(
"postProcessBeanDefinitionRegistry already called on this post-processor against " + registry);
}
if (this.factoriesPostProcessed.contains(registryId)) {
throw new IllegalStateException(
"postProcessBeanFactory already called on this post-processor against " + registry);
}
this.registriesPostProcessed.add(registryId);
//正式解析
processConfigBeanDefinitions(registry);
}
4.2.2 正式解析
这儿我们依旧一段一段的看
List<BeanDefinitionHolder> configCandidates = new ArrayList<>();
//找到该registry所有的candidateNames 也就是我们第一步结尾添加的那些
String[] candidateNames = registry.getBeanDefinitionNames(); for (String beanName : candidateNames) {
BeanDefinition beanDef = registry.getBeanDefinition(beanName);
//isFullConfigurationClass 判断是否是带有@Configuration
//isLiteConfigurationClass 判断是否带有@Component,@ComponentScan,@Import,@ImportResource,@Bean 5个注解中的任一个
// 具体可以查看 https://blog.csdn.net/u011624903/article/details/102564491
if (ConfigurationClassUtils.isFullConfigurationClass(beanDef) ||
ConfigurationClassUtils.isLiteConfigurationClass(beanDef)) {
if (logger.isDebugEnabled()) {
logger.debug("Bean definition has already been processed as a configuration class: " + beanDef);
}
}
// 这儿由于我们的主启动类中@SpringbootApplication带@Configuration注解 所以主类满足
else if (ConfigurationClassUtils.checkConfigurationClassCandidate(beanDef, this.metadataReaderFactory)) {
configCandidates.add(new BeanDefinitionHolder(beanDef, beanName));
}
} // Return immediately if no @Configuration classes were found
if (configCandidates.isEmpty()) {
return;
}
// 排序
configCandidates.sort((bd1, bd2) -> {
int i1 = ConfigurationClassUtils.getOrder(bd1.getBeanDefinition());
int i2 = ConfigurationClassUtils.getOrder(bd2.getBeanDefinition());
return Integer.compare(i1, i2);
});
这儿会将BeanFactory中已经存在的BeanDefinitionName全部查出来并获取其BeanDefinition,由于我们的启动类@SpringbootApplication中已经带有@Configuration 所以这里是满足的(第一节中讲组合注解的时候讲过)
然后接下来会有查看是否有BeanNameGenerator和environment
SingletonBeanRegistry sbr = null;
if (registry instanceof SingletonBeanRegistry) {
sbr = (SingletonBeanRegistry) registry;
if (!this.localBeanNameGeneratorSet) {
BeanNameGenerator generator = (BeanNameGenerator) sbr.getSingleton(CONFIGURATION_BEAN_NAME_GENERATOR);
if (generator != null) {
this.componentScanBeanNameGenerator = generator;
this.importBeanNameGenerator = generator;
}
}
} if (this.environment == null) {
this.environment = new StandardEnvironment();
}
然后我们就看到了本文最核心的代码了,也就是解析代码。
我们看下这个解析流程
// 构建一个ConfigurationClassParser 也就是解析器
ConfigurationClassParser parser = new ConfigurationClassParser(
this.metadataReaderFactory, this.problemReporter, this.environment,
this.resourceLoader, this.componentScanBeanNameGenerator, registry); //拿到我们解析的配置类 这儿的话是主启动类
Set<BeanDefinitionHolder> candidates = new LinkedHashSet<>(configCandidates);
//已经解析的ConfigurationClass集合
Set<ConfigurationClass> alreadyParsed = new HashSet<>(configCandidates.size());
do {
//开始解析
parser.parse(candidates);
//验证
parser.validate();
//找到本次解析后发现的所有ConfigurationClass
Set<ConfigurationClass> configClasses = new LinkedHashSet<>(parser.getConfigurationClasses());
//移除掉已经解析的
configClasses.removeAll(alreadyParsed); // 如果没有 则创建一个新的ConfigurationClassBeanDefinitionReader
if (this.reader == null) {
this.reader = new ConfigurationClassBeanDefinitionReader(
registry, this.sourceExtractor, this.resourceLoader, this.environment,
this.importBeanNameGenerator, parser.getImportRegistry());
}
//将这些发现的找到本次解析后发现的所有ConfigurationClass再次解析掉
this.reader.loadBeanDefinitions(configClasses);
//将其添加到已解析的集合中
alreadyParsed.addAll(configClasses);
//清空candidates
candidates.clear();
//如果registry中的BeanDefinition数量大于candidateNames 也就是一开始进入方法时的数量
//即找到的新的需要加入容器的bean了
if (registry.getBeanDefinitionCount() > candidateNames.length) {
//拿到所有的已经存在的BeanDefinitionName
String[] newCandidateNames = registry.getBeanDefinitionNames();
//初始进来的BeanDefinitionName
Set<String> oldCandidateNames = new HashSet<>(Arrays.asList(candidateNames));
//创建已经解析的Class的名字的集合
Set<String> alreadyParsedClasses = new HashSet<>();
for (ConfigurationClass configurationClass : alreadyParsed) {
//将已经解析的添加到集合中
alreadyParsedClasses.add(configurationClass.getMetadata().getClassName());
}
//循环遍历 所有的BeanDefinition 看看有没有configuration被遗漏的
for (String candidateName : newCandidateNames) {
//即不是初始化进来时的BeanDefinition
if (!oldCandidateNames.contains(candidateName)) {
//拿到这个BeanDefinition
BeanDefinition bd = registry.getBeanDefinition(candidateName);
//如果该BeanDefinition也是一个配置类并且没有存在于alreadyParsed 即被遗漏了
//那么将其添加到candidates方法 然后再进行
if (ConfigurationClassUtils.checkConfigurationClassCandidate(bd, this.metadataReaderFactory) &&
!alreadyParsedClasses.contains(bd.getBeanClassName())) {
//则再将其添加进去 循环进行解析
candidates.add(new BeanDefinitionHolder(bd, candidateName));
}
}
}
candidateNames = newCandidateNames;
}
}
while (!candidates.isEmpty());
这段代码较长,逻辑还是较为清晰,其实通过这段代码我们就大概明白了springboot进行配置加载的流程了。即根据主启动类进行配置解析,并且将所有遇到的ConfigurationClass全部返回,然后再进行二次解析,最后对所有的BeanDefinition进行校验,如果发现其为ConfigurationClass但是却没有在已解析的集合中,那么久循环一下,再次进行解析。
篇幅有限,具体的解析流程放到下一篇, 解析完第一级BeanDefinitionRegistryPostProcessor后我们开始解析第二级
4.3 第二级BeanDefinitionRegistryPostProcessor(即实现了Ordered接口)
// Next, invoke the BeanDefinitionRegistryPostProcessors that implement Ordered.
postProcessorNames = beanFactory.getBeanNamesForType(BeanDefinitionRegistryPostProcessor.class, true, false);
for (String ppName : postProcessorNames) {
//过滤了第一级中存在的
if (!processedBeans.contains(ppName) && beanFactory.isTypeMatch(ppName, Ordered.class)) {
currentRegistryProcessors.add(beanFactory.getBean(ppName, BeanDefinitionRegistryPostProcessor.class));
processedBeans.add(ppName);
}
}
sortPostProcessors(currentRegistryProcessors, beanFactory);
registryProcessors.addAll(currentRegistryProcessors);
invokeBeanDefinitionRegistryPostProcessors(currentRegistryProcessors, registry);
currentRegistryProcessors.clear();
可以发现其流程和第一级几乎一致,只是增加了一个过滤掉了第一级,所以这儿不讲,如果有自定义的BeanDefinitionRegistryPostProcessor可以测试一下。
4.4 第三级BeanDefinitionRegistryPostProcessor
// Finally, invoke all other BeanDefinitionRegistryPostProcessors until no further ones appear.
boolean reiterate = true;
while (reiterate) {
reiterate = false;
postProcessorNames = beanFactory.getBeanNamesForType(BeanDefinitionRegistryPostProcessor.class, true, false);
for (String ppName : postProcessorNames) {
if (!processedBeans.contains(ppName)) {
currentRegistryProcessors.add(beanFactory.getBean(ppName, BeanDefinitionRegistryPostProcessor.class));
processedBeans.add(ppName);
reiterate = true;
}
}
sortPostProcessors(currentRegistryProcessors, beanFactory);
registryProcessors.addAll(currentRegistryProcessors);
invokeBeanDefinitionRegistryPostProcessors(currentRegistryProcessors, registry);
currentRegistryProcessors.clear();
}
处理流程也和前两级几乎一致,这儿也不讲了
4.4 BeanFactoryPostProcessor的执行
即找到系统存在的BeanFactoryPostProcessor,同样按照三级的形式根据优先级来执行。具体的逻辑也和上面详细讲的那个一级是一致的。
String[] postProcessorNames =
beanFactory.getBeanNamesForType(BeanFactoryPostProcessor.class, true, false); //找到所有的BeanFactoryPostProcessor 并根据其级别进行归类
List<BeanFactoryPostProcessor> priorityOrderedPostProcessors = new ArrayList<>();
List<String> orderedPostProcessorNames = new ArrayList<>();
List<String> nonOrderedPostProcessorNames = new ArrayList<>();
for (String ppName : postProcessorNames) {
if (processedBeans.contains(ppName)) {
// skip - already processed in first phase above
}
else if (beanFactory.isTypeMatch(ppName, PriorityOrdered.class)) {
priorityOrderedPostProcessors.add(beanFactory.getBean(ppName, BeanFactoryPostProcessor.class));
}
else if (beanFactory.isTypeMatch(ppName, Ordered.class)) {
orderedPostProcessorNames.add(ppName);
}
else {
nonOrderedPostProcessorNames.add(ppName);
}
} // 执行优先级最高的 即实现了PriorityOrdered接口的
sortPostProcessors(priorityOrderedPostProcessors, beanFactory);
invokeBeanFactoryPostProcessors(priorityOrderedPostProcessors, beanFactory); // 执行第二级的的 即实现了Ordered接口的
List<BeanFactoryPostProcessor> orderedPostProcessors = new ArrayList<>();
for (String postProcessorName : orderedPostProcessorNames) {
orderedPostProcessors.add(beanFactory.getBean(postProcessorName, BeanFactoryPostProcessor.class));
} // 执行第三级的的 即啥都没实现的
sortPostProcessors(orderedPostProcessors, beanFactory);
invokeBeanFactoryPostProcessors(orderedPostProcessors, beanFactory); // Finally, invoke all other BeanFactoryPostProcessors.
List<BeanFactoryPostProcessor> nonOrderedPostProcessors = new ArrayList<>();
for (String postProcessorName : nonOrderedPostProcessorNames) {
nonOrderedPostProcessors.add(beanFactory.getBean(postProcessorName, BeanFactoryPostProcessor.class));
}
invokeBeanFactoryPostProcessors(nonOrderedPostProcessors, beanFactory);
//清除缓存
beanFactory.clearMetadataCache();
到此,refresh方法中的两个重要方法第一个 invokeBeanFactoryPostProcessors,已经完成,而其中的ConfigurationClassPostProcessor(也就是BeanDefinitionRegistryPostProcessor的一种)负责了最为核心的容器类加载,也就是主要分析的类也分析完成。(详细的类解析过程篇幅问题放在下章)
总结
本文主要分为了两个部分,创建Spring应用上下文,和执行了其refresh方法中的invokeBeanFactoryPostProcessors方法。
创建应用上下文的同时也会创建一个DefaultListableBeanFactory,这个也是静态代理的体现。而在执行ApplicationContext的构造函数时,会创建一个AnnotatedBeanDefinitionReader,而这个类中会有一个BeanDefinitionRegistry属性,并将我们一些必须的BeanDefinition添加进去,例如最为核心的 ConfigurationClassPostProcessor也就是在这个时候被添加进去的。
执行invokeBeanFactoryPostProcessors方法则主要分为三个步骤
- 执行所有传入的BeanFactoryPostProcessor(如果为BeanFactoryPostProcessor)的postProcessBeanDefinitionRegistry方法
- 找到BeanFactory中所有的BeanDefinitionRegistryPostProcessor类型的类并按照三级标准执行(实现了PriorityOrdered接口,实现了Ordered接口,啥都没实现 );
- 找到BeanFactory中所有的BeanFactoryPostProcessor类型的类并按照三级标准执行(实现了PriorityOrdered接口,实现了Ordered接口,啥都没实现 );
而其第二步则执行了核心的ConfigurationClassPostProcessor,并且是以最优先级执行,该processer会加载系统中所有需要加入容器的类,并且会解析所有的Configuration class
springboot笔记-2-.核心的上下文以及配置扫描解析(上)的更多相关文章
- 这一次搞懂SpringBoot核心原理(自动配置、事件驱动、Condition)
@ 目录 前言 正文 启动原理 事件驱动 自动配置原理 Condition注解原理 总结 前言 SpringBoot是Spring的包装,通过自动配置使得SpringBoot可以做到开箱即用,上手成本 ...
- springboot笔记-1.自动化配置的关键
最近发现看过的东西容易忘,但是写一遍之后印象倒是会深刻的多. 总所周知springboot极大的简化了java开发繁琐性,而其最大的优势应该就是自动化配置了.比如要使用redis,我们直接引入相关的包 ...
- 【spring】SpringBoot之Servlet、Filter、Listener配置
转载自 http://blog.csdn.net/king_is_everyone/article/details/53116744 1.介绍 通过之前的文章来看,SpringBoot涵盖了很多配置, ...
- Springboot笔记01——Springboot简介
一.什么是微服务 在了解Springboot之前,首先我们需要了解一下什么是微服务. 微服务是一种架构风格(服务微化),是martin fowler在2014年提出来的.微服务简单地说就是:一个应用应 ...
- Springboot学习:核心配置文件
核心配置文件介绍 SpringBoot使用一个全局配置文件,配置文件名是固定的 application.properties application.yml 配置文件的作用:修改SpringBoot自 ...
- 【SpringBoot 基础系列】实现一个自定义配置加载器(应用篇)
[SpringBoot 基础系列]实现一个自定义配置加载器(应用篇) Spring 中提供了@Value注解,用来绑定配置,可以实现从配置文件中,读取对应的配置并赋值给成员变量:某些时候,我们的配置可 ...
- Linux协议栈代码阅读笔记(二)网络接口的配置
Linux协议栈代码阅读笔记(二)网络接口的配置 (基于linux-2.6.11) (一)用户态通过C库函数ioctl进行网络接口的配置 例如,知名的ifconfig程序,就是通过C库函数sys_io ...
- Git 笔记二-Git安装与初始配置
git 笔记二-Git安装与初始配置 Git的安装 由于我日常生活和工作基本上都是在Windows上,因此此处只说windows上的安装.Windows上的安装和其他程序一样,只需要到http://g ...
- springboot添加多数据源连接池并配置Mybatis
springboot添加多数据源连接池并配置Mybatis 转载请注明出处:https://www.cnblogs.com/funnyzpc/p/9190226.html May 12, 2018 ...
随机推荐
- 关于List比较好玩的操作
作为Java大家庭中的集合类框架,List应该是平时开发中最常用的,可能有这种需求,当集合中的某些元素符合一定条件时,想要删除这个元素.如: public class ListTest { publi ...
- vue里使用elementUI里的下拉树表格,如何定义个性化的子表格?
最近项目写到一个业务,首先需要展示各类分组的基本信息,然后需要点击每个分组展示该分组下子的所有具体信息 一开始我是打算用tab来展示就是首先父分组的名称就是各个不同的tab按钮,然后点击按钮再展示不同 ...
- Spring-Boot-2.0.0-M1版本将默认的数据库连接池从tomcat jdbc pool改为了hikari
spring-configuration-metadata.json spring-boot-autoconfigure-2.0.0.M7.jar!/META-INF/spring-configura ...
- 题解 CF409A 【The Great Game】
题目传送门. 思路: 首先我们定义\(2\)个字符串,分别存放 TEAM 1 与 TEAM 2 的出招顺序.接着再定义\(2\)个变量,存放 TEAM 1 与 TEAM 2 的分数. string s ...
- ActiveMQ分布式事务
一.安装ActiveMQ 1.拷贝apache-activemq-5.14.4-bin.tar.gz到Linux服务器的/opt下 2.解压缩 tar -zxvf apache-activemq-5. ...
- importing-cleaning-data-in-r-case-studies
目录 importing-cleaning-data-in-r-case-studies 导入数据 查看数据结构 下面的一些都是查数据结构的 separate 拆分单元格 读取指定位置的数据 stri ...
- winform常用控件介绍
1.窗体 12.Label 控件 33.TextBox 控件 44.RichTextBox控件 55.NumericUpDown 控件 76.Button 控件 77.GroupBox 控件 78.R ...
- Ajax返回值一直获取不到啊
原理: 同步异步的问题 Return 位置的问题 首先同步异步改为async : false, Return 的值写在ajax外部 function submit_answer(){ ...
- 2019牛客训练赛第七场 C Governing sand 权值线段树+贪心
Governing sand 题意 森林里有m种树木,每种树木有一定高度,并且砍掉他要消耗一定的代价,问消耗最少多少代价可以使得森林中最高的树木大于所有树的一半 分析 复杂度分析:n 1e5种树木,并 ...
- C++-怎样写程序(面向对象)
使用编程语言写好程序是有技巧的. 主要编程技术: 1. 编程风格 2. 算法 3. 数据结构 4. 设计模式 5. 开发方法 编程风格指的是编程的细节,比如变量名的选择方法.函数的写法等. 算法是解决 ...