【57】目标检测之Anchor Boxes
Anchor Boxes
到目前为止,对象检测中存在的一个问题是每个格子只能检测出一个对象,如果你想让一个格子检测出多个对象,你可以这么做,就是使用anchor box这个概念。
我们还是先吃一颗栗子:

假设你有这样一张图片,对于这个例子,我们继续使用3×3网格,注意行人的中点和汽车的中点几乎在同一个地方,两者都落入到同一个格子中。
所以对于那个格子,如果 y 输出这个向量y

你可以检测这三个类别,行人、汽车和摩托车,它将无法输出检测结果,所以我必须从两个检测结果中选一个。
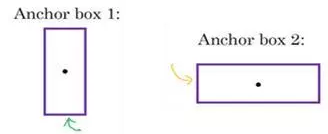
而anchor box的思路是:预先定义两个不同形状的anchor box,或者anchor box形状,你要做的是把预测结果和这两个anchor box关联起来。一般来说,你可能会用更多的anchor box,可能要5个甚至更多,但对于这个笔记中,我们就用两个anchor box,这样介绍起来简单一些。
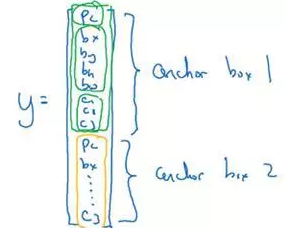
你要做的是定义类别标签,用的向量不再是上面这个:
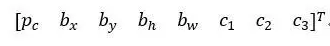
而是重复两次:

前面的p_c,b_x,b_y,b_h,b_w,c_1,c_2,c_3(绿色方框标记的参数)是和anchor box 1关联的8个参数,后面的8个参数(橙色方框标记的元素)是和anchor box 2相关联。
因为行人的形状更类似于anchor box 1的形状,而不是anchor box 2的形状,所以你可以用这8个数值(前8个参数),这么编码p_c=1,是的,代表有个行人,用b_x,b_y,b_h和b_w来编码包住行人的边界框,然后用c_1,c_2,c_3(c_1=1,c_2=0,c_3=0)来说明这个对象是个行人。
然后是车子,因为车子的边界框比起anchor box 1更像anchor box 2的形状,你就可以这么编码,这里第二个对象是汽车,然后有这样的边界框等等,这里所有参数都和检测汽车相关(p_c=1,b_x,b_y,b_h,b_w,c_1=0,c_2=1,c_3=0)。

总结一下,用anchor box之前,你做的是这个,对于训练集图像中的每个对象,都根据那个对象中点位置分配到对应的格子中,所以输出y就是3×3×8,因为是3×3网格,对于每个网格位置,我们有输出向量,包含p_c,然后边界框参数b_x,b_y,b_h和b_w,然后c_1,c_2,c_3。
现在用到anchor box这个概念,是这么做的。
现在每个对象都和之前一样分配到同一个格子中,分配到对象中点所在的格子中,以及分配到和对象形状交并比最高的anchor box中。所以这里有两个anchor box,你就取这个对象,如果你的对象形状是这样的(编号1,红色框),你就看看这两个anchor box,anchor box 1形状是这样(编号2,紫色框),anchor box 2形状是这样(编号3,紫色框),然后你观察哪一个anchor box和实际边界框(编号1,红色框)的交并比更高,不管选的是哪一个,这个对象不只分配到一个格子,而是分配到一对,即(grid cell,anchor box)对,这就是对象在目标标签中的编码方式。
所以现在输出 y 就是3×3×16,上一张幻灯片中你们看到 y 现在是16维的,或者你也可以看成是3×3×2×8,因为现在这里有2个anchor box,而 y 是8维的。y 维度是8,因为我们有3个对象类别,如果你有更多对象,那么y 的维度会更高。
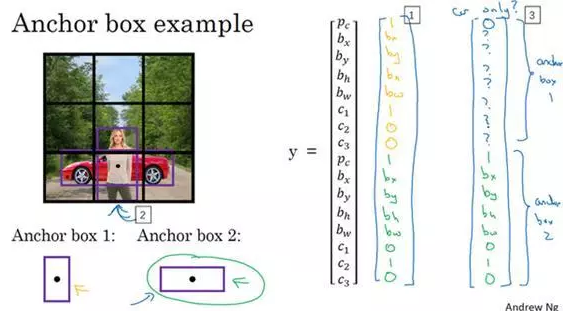
所以我们来看一个具体的例子,对于这个格子(编号2),我们定义一下y,:
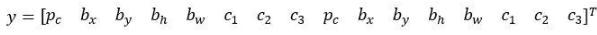
所以行人更类似于anchor box 1的形状,所以对于行人来说,我们将她分配到向量的上半部分。是的,这里存在一个对象,即p_c=1,有一个边界框包住行人,如果行人是类别1,那么 c_1=1,c_2=0,c_3=0(编号1所示的橙色参数)。车子的形状更像anchor box 2,所以这个向量剩下的部分是 p_c=1,然后和车相关的边界框,然后c_1=0,c_2=1,c_3=0(编号1所示的绿色参数)。所以这就是对应中下格子的标签 y,这个箭头指向的格子(编号2所示)。
现在其中一个格子有车,没有行人,如果它里面只有一辆车,那么假设车子的边界框形状是这样,更像anchor box 2,如果这里只有一辆车,行人走开了,那么anchor box 2分量还是一样的,要记住这是向量对应anchor box 2的分量和anchor box 1对应的向量分量,你要填的就是,里面没有任何对象,所以 p_c=0,然后剩下的就是don’t care-s(即?)(编号3所示)。
现在还有一些额外的细节,如果你有两个anchor box,但在同一个格子中有三个对象,这种情况算法处理不好,你希望这种情况不会发生,但如果真的发生了,这个算法并没有很好的处理办法,对于这种情况,我们就引入一些打破僵局的默认手段。
还有这种情况,两个对象都分配到一个格子中,而且它们的anchor box形状也一样,这是算法处理不好的另一种情况,你需要引入一些打破僵局的默认手段,专门处理这种情况,希望你的数据集里不会出现这种情况,其实出现的情况不多,所以对性能的影响应该不会很大。
这就是anchor box的概念,我们建立anchor box这个概念,是为了处理两个对象出现在同一个格子的情况,实践中这种情况很少发生,特别是如果你用的是19×19网格而不是3×3的网格,两个对象中点处于361个格子中同一个格子的概率很低,确实会出现,但出现频率不高。
也许设立anchor box的好处在于anchor box能让你的学习算法能够更有征对性,特别是如果你的数据集有一些很高很瘦的对象,比如说行人,还有像汽车这样很宽的对象,这样你的算法就能更有针对性的处理,这样有一些输出单元可以针对检测很宽很胖的对象,比如说车子,然后输出一些单元,可以针对检测很高很瘦的对象,比如说行人。
最后,你应该怎么选择anchor box呢?
人们一般手工指定anchor box形状,你可以选择5到10个anchor box形状,覆盖到多种不同的形状,可以涵盖你想要检测的对象的各种形状。还有一个更高级的版本,我就简单说一句,你们如果接触过一些机器学习,可能知道后期YOLO论文中有更好的做法,就是所谓的k-平均算法,可以将两类对象形状聚类,如果我们用它来选择一组anchor box,选择最具有代表性的一组anchor box,可以代表你试图检测的十几个对象类别,但这其实是自动选择anchor box的高级方法。如果你就人工选择一些形状,合理的考虑到所有对象的形状,你预计会检测的很高很瘦或者很宽很胖的对象,这应该也不难做。
所以这就是anchor box,在下一个笔记中,我们把学到的所有东西一起融入到YOLO算法中。
【57】目标检测之Anchor Boxes的更多相关文章
- 关于目标检测的anchor问题
关于目标检测其实我一直也在想下面的两个论断: Receptive Field Is Natural Anchor Receptive Field Is All You Need 只是一直没有实验.但是 ...
- 目标检测复习之Anchor Free系列
目标检测之Anchor Free系列 CenterNet(Object as point) 见之前的过的博客 CenterNet笔记 YOLOX 见之前目标检测复习之YOLO系列总结 YOLOX笔记 ...
- Anchor-free目标检测综述 -- Dense Prediction篇
早期目标检测研究以anchor-based为主,设定初始anchor,预测anchor的修正值,分为two-stage目标检测与one-stage目标检测,分别以Faster R-CNN和SSD作 ...
- 经典论文系列 | 目标检测--CornerNet & 又名 anchor boxes的缺陷
前言: 目标检测的预测框经过了滑动窗口.selective search.RPN.anchor based等一系列生成方法的发展,到18年开始,开始流行anchor free系列,CornerNe ...
- 目标检测 anchor 理解笔记
anchor在计算机视觉中有锚点或锚框,目标检测中常出现的anchor box是锚框,表示固定的参考框. 目标检测的任务: 在哪里有东西 难点: 目标的类别不确定.数量不确定.位置不确定.尺度不确定 ...
- 目标检测 1 : 目标检测中的Anchor详解
咸鱼了半年,年底了,把这半年做的关于目标的检测的内容总结下. 本文主要有两部分: 目标检测中的边框表示 Anchor相关的问题,R-CNN,SSD,YOLO 中的anchor 目标检测中的边框表示 目 ...
- 目标检测中的anchor-based 和anchor free
目标检测中的anchor-based 和anchor free 1. anchor-free 和 anchor-based 区别 深度学习目标检测通常都被建模成对一些候选区域进行分类和回归的问题.在 ...
- 目标检测网络之 YOLOv3
本文逐步介绍YOLO v1~v3的设计历程. YOLOv1基本思想 YOLO将输入图像分成SxS个格子,若某个物体 Ground truth 的中心位置的坐标落入到某个格子,那么这个格子就负责检测出这 ...
- 目标检测(七)YOLOv3: An Incremental Improvement
项目地址 Abstract 该技术报告主要介绍了作者对 YOLOv1 的一系列改进措施(注意:不是对YOLOv2,但是借鉴了YOLOv2中的部分改进措施).虽然改进后的网络较YOLOv1大一些,但是检 ...
随机推荐
- Hyper-V 搭建独臂路由器(单网卡也可以)
2020年原本难得清闲的春节,由于疫情的原因只能在家里看视频打发时间.打开某奇艺,全是某某公寓的推荐真的是受不了.一群人在那里叽叽喳喳,超前点播更是吃像难看,实在是没意思,所以决定搞一个独臂路由器玩一 ...
- JS-02-js的变量
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title> ...
- Python3-ORM-Sqlalchemy
目录: ORM介绍 sqlalchemy安装 sqlalchemy基本使用 多外键关联 多对多关系 表结构设计作业 1. ORM介绍 orm英文全称object relational mapping, ...
- Day6-Python3基础-面向对象编程
面向过程 VS 面向对象 编程范式 编程是 程序 员 用特定的语法+数据结构+算法组成的代码来告诉计算机如何执行任务的过程 , 一个程序是程序员为了得到一个任务结果而编写的一组指令的集合,正所谓条条大 ...
- 大数据面试题(一)----HADOOP 面试题
1. 下列哪项通常是集群的最主要瓶颈(C) A. CPU B. 网络 C. 磁盘IO D. 内存 2. 下列哪项可以作为集群的管理工具?(C) A.Puppet B.Pdsh C.ClouderaMa ...
- 【Java并发基础】利用面向对象的思想写好并发程序
前言 下面简单总结学习Java并发的笔记,关于如何利用面向对象思想写好并发程序的建议.面向对象的思想和并发编程属于两个领域,但是在Java中这两个领域却可以融合到一起.在Java语言中,面向对象编程的 ...
- Leetcode 题目整理-2 Reverse Integer && String to Integer
今天的两道题关于基本数据类型的探讨,估计也是要考虑各种情况,要细致学习 7. Reverse Integer Reverse digits of an integer. Example1: x = 1 ...
- .net core控制台使用log4net
第一步,Nuget log4net包 第二步,在项目中添加一个新xml文件,我这里是直接从.net framework的项目里复制过来的config文件,不过效果是一样的 内容如下: ?xml ver ...
- 《快乐编程大本营》java语言训练班-第4课:java流程控制
<快乐编程大本营>java语言训练班-第4课:java流程控制 第1节. 顺序执行语句 第2节. 条件分支语句:if条件语句 第3节. 条件分支语句:switch 条件语句 第4节. 条件 ...
- Spring基于XML配置AOP
目录结构: D:\Java\IdeaProjects\JavaProj\SpringHelloWorld\src\cn\edu\bjut\service\StudentService.java pac ...