scrapy 当当网 爬虫
前言
好久没有写实战博客了,因为前几个月在公司实习,博客更新就耽搁了下来,现在又受疫情影响无法返校,但是技能还是不能丢的,今天就写一篇使用scrapy爬取当当网的实战练习吧。
创建scrapy项目
目标站点: http://search.dangdang.com/?key=python&category_path=01.00.00.00.00.00&page_index=1 这是在当当网搜索关键字python得到的页面
第一步仍然是使用命令行切换到工作目录创建scrapy项目
- D:\pythonwork\cnblog>scrapy startproject cnblog_dangdang

然后使用cd命令进入项目中的spiders文件夹使用命令创建爬虫文件(注意:该命令后的网址跟的是目标网址域名,而不是整个网址)
- D:\pythonwork\cnblog\cnblog_dangdang\cnblog_dangdang\spiders>scrapy genspider dangdang_spider dangdang.com

此时我们的项目与基础爬虫文件已经创建完毕,接下来编写代码使用pycharm打开项目
内容分析
打开目标站点分析我们需要爬取什么内容
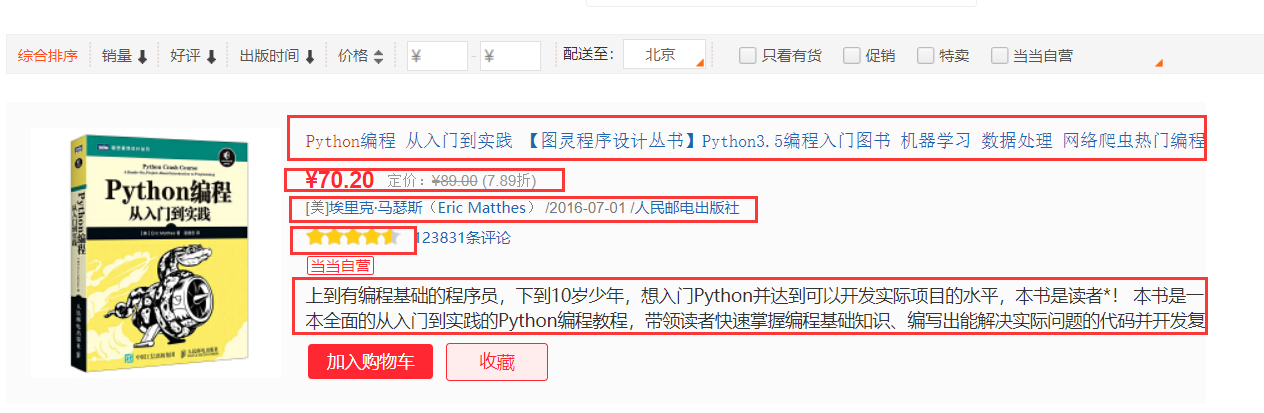
对于目标站点的商品图书而言,我们需要爬取它的标题、价格、作者、评分和概括五个部分
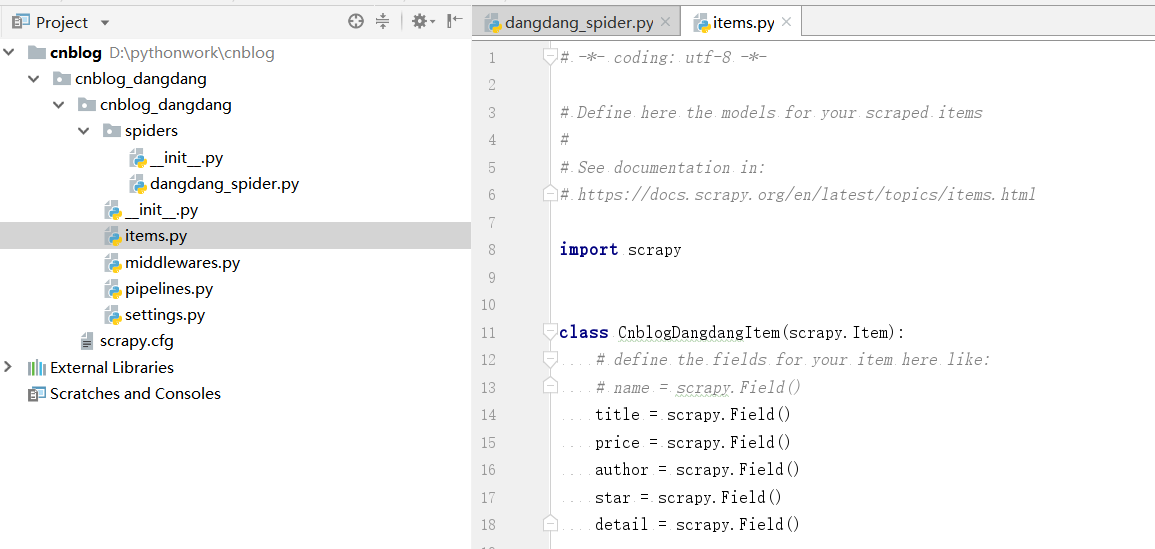
因此首先我们在项目的items.py文件中声明我们需要爬取的内容。
items.py
# -*- coding: utf-8 -*- # Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html import scrapy class CnblogDangdangItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
price = scrapy.Field()
author = scrapy.Field()
star = scrapy.Field()
detail = scrapy.Field()
因此我们的数据表的sql语句创建如下:
CREATE TABLE IF NOT EXISTS dangdang_item (
id INT UNSIGNED AUTO_INCREMENT,
title CHAR(100) NOT NULL,
price CHAR(100) NOT NULL,
author CHAR(100) NOT NULL,
star CHAR(10) NOT NULL,
detail VARCHAR(1000),
PRIMARY KEY (id)
)ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
爬虫文件编写
内容分析完成之后我们到了最关键的爬虫文件编写部分,首先我们要测试下该网站有没有反爬措施。
这一步我们只需要简单的将spiders文件夹中的dangdang_spider.py文件进行简单的修改让其输出目标站点的响应内容即可
dangdang_spider.py
# -*- coding: utf-8 -*-
import scrapy class DangdangSpiderSpider(scrapy.Spider):
name = 'dangdang_spider'
allowed_domains = ['dangdang.com']
start_urls = ['http://search.dangdang.com/?key=python&category_path=01.00.00.00.00.00&page_index=1'] def parse(self, response):
print(response.text)
pass
为了方便我们进行调试,我们在项目下创建一个main.py文件用于启动爬虫,不然我们每次启动都需要在命令行中使用scrapy命令。
main.py
from scrapy import cmdline
cmdline.execute('scrapy crawl dangdang_spider'.split())
然后直接运行main.py文件,发现输出了目标网站的html源代码,所以目标网站并没有反爬措施,我们可以直接拿取内容,接下来就开始拿取内容了。
五部分内容使用xpath拿取,网页结构很简单,直接从源码分析xpath即可。
开始实际编写爬虫文件dangdang_spider.py
# -*- coding: utf-8 -*-
import scrapy
import re
from cnblog_dangdang.items import CnblogDangdangItem str_re = re.compile('\d+') class DangdangSpiderSpider(scrapy.Spider):
name = 'dangdang_spider'
allowed_domains = ['dangdang.com']
start_urls = ['http://search.dangdang.com/?key=python&category_path=01.00.00.00.00.00&page_index=1'] def parse(self, response):
book_item = CnblogDangdangItem()
items = response.xpath("//ul[@class='bigimg']/li")#不用加get 因为此步骤为了拿到一个xpath对象
for item in items:
book_item['title'] = item.xpath("./a/@title").get()
book_item['price'] = item.xpath("./p[@class='price']").xpath("string(.)").get()#使用string(.)方法为了拿取目标节点下的所有子节点文本
book_item['author'] = item.xpath("./p[@class='search_book_author']").xpath("string(.)").get()
book_item['star'] = int(str_re.findall(item.xpath("./p[@class='search_star_line']/span/span/@style").get())[0])/20
book_item['detail'] = item.xpath("./p[@class='detail']//text()").get()
print(book_item)
yield book_item next_url_end = response.xpath("//li[@class='next']/a/@href").get()
#如果拿到了下一页链接,则访问
if next_url_end:
next_url ='http://search.dangdang.com/'+ next_url_end
yield scrapy.Request(next_url,callback=self.parse)
再次运行爬虫,发现现在已经可以输出拿取到的信息

说明我们的爬虫文件编写成功,接下来就是对我们拿取到的数据进行处理。
数据的存储
此次我们选择使用mysql进行数据的存储,那么我们首先要干什么呢?是直接编写pipeline.py文件吗?并不是,我们还有一个很重要的地方没有弄,就是settings.py文件。
我们想要通过pipeline.py文件来处理爬取到的数据,首先就需要去settings.py中开启我们的pipeline选项,很简单只需要在settings.py中将ITEM_PIPELINES的注释消掉即可如下图

接下来就可以编写pipeline.py文件来对我们的数据进行操作了
pipeline.py
# -*- coding: utf-8 -*- # Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html import pymysql number = 0
class DangdangPipeline(object): # open_spider()爬虫开启时执行一次
def open_spider(self,spider):
# 连接数据库
print("连接数据库,准备写入数据")
self.db = pymysql.connect('localhost', '你的mysql账户', '你的mysql密码', '你的数据库名称')
self.cursor = self.db.cursor() def process_item(self, item, spider):
global number
number = number+1
print('当前写入第'+str(number)+'个商品数据')
#使用replace是为了避免数据中存在引号与sql语句冲突
title=str(item['title']).replace("'","\\'").replace('"','\\"')
price=str(item['price']).replace("'","\\'").replace('"','\\"')
author=str(item['author']).replace("'","\\'").replace('"','\\"')
star=str(item['star']).replace("'","\\'").replace('"','\\"')
detail=str(item['detail']).replace("'","\\'").replace('"','\\"')
sql = f'INSERT INTO dangdang_item (title,price,author,star,detail) VALUES (\'{title}\',\'{price}\',\'{author}\',\'{star}\',\'{detail}\');'
#执行sql语句
self.cursor.execute(sql)
#数据库提交修改
self.db.commit()
return item # close_spider()爬虫关闭后执行
def close_spider(self,spider):
print('写入完成,一共'+str(number)+'个数据')
# 关闭连接
self.cursor.close()
self.db.close()
接下来再次运行main.py文件,看看爬虫效果。

我们去数据库中看一下我们刚刚爬取的数据
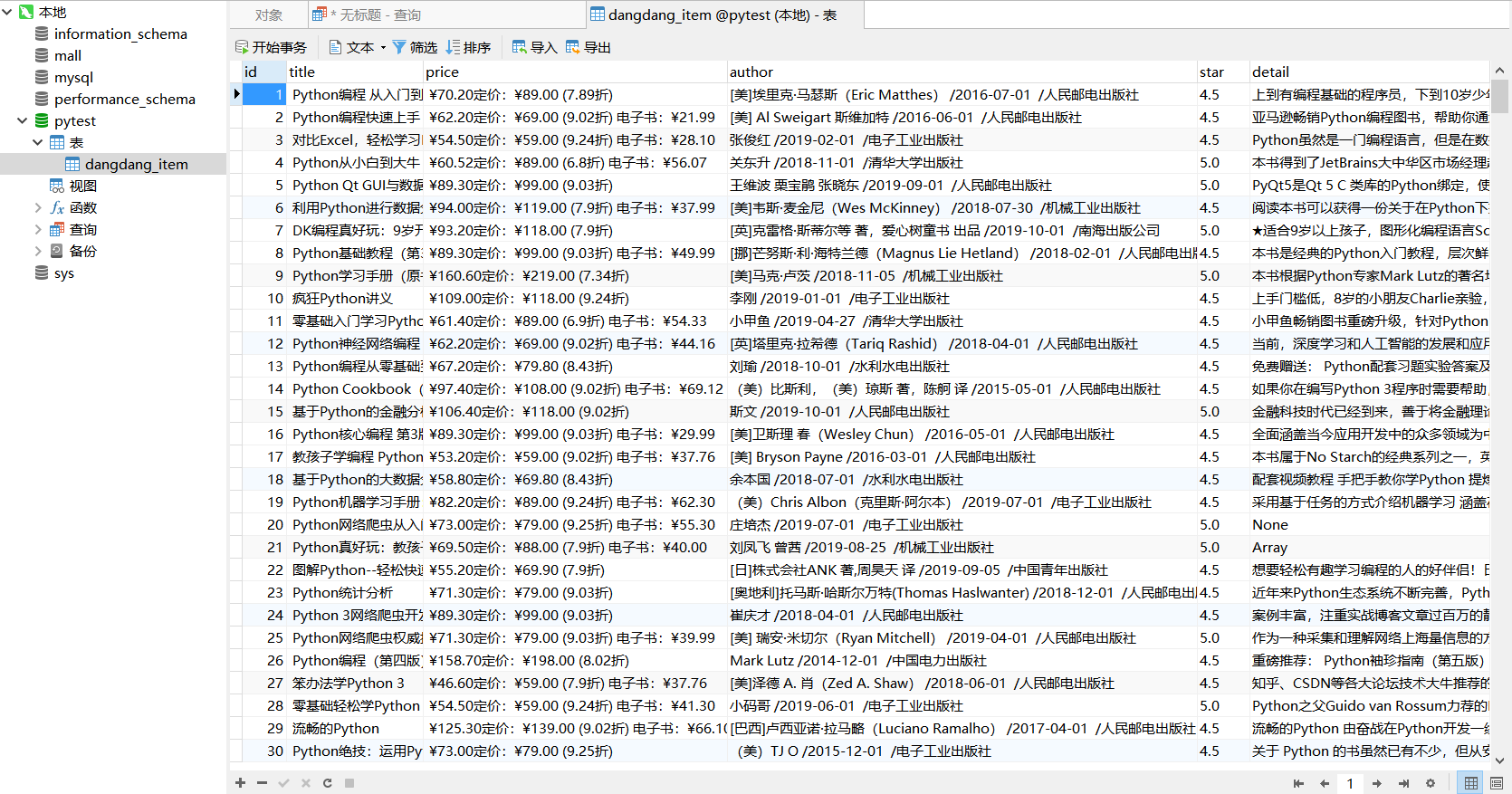
ok,大功完成了,我们的当当网scrapy爬虫就编写好了。
scrapy 当当网 爬虫的更多相关文章
- Python爬虫库Scrapy入门1--爬取当当网商品数据
1.关于scrapy库的介绍,可以查看其官方文档:http://scrapy-chs.readthedocs.io/zh_CN/latest/ 2.安装:pip install scrapy 注意这 ...
- Scrapy爬虫(5)爬取当当网图书畅销榜
本次将会使用Scrapy来爬取当当网的图书畅销榜,其网页截图如下: 我们的爬虫将会把每本书的排名,书名,作者,出版社,价格以及评论数爬取出来,并保存为csv格式的文件.项目的具体创建就不再多讲 ...
- Python 爬虫 当当网图书 scrapy
目标站点需求分析 获取当当网每个图书名字和评论数 涉及的库 scrapy,mysql 获取解析单页源码 保存到数据库中 结果
- scrapy项目3:爬取当当网中机器学习的数据及价格(spider类)
1.网页解析 当当网中,人工智能数据的首页url如下为http://category.dangdang.com/cp01.54.12.00.00.00.html 点击下方的链接,一次观察各个页面的ur ...
- scrapy获取当当网中数据
yield 1. 带有 yield 的函数不再是一个普通函数,而是一个生成器generator,可用于迭代 2. yield 是一个类似 return 的关键字,迭代一次遇到yield时就返回yiel ...
- 网络爬虫之定向爬虫:爬取当当网2015年图书销售排行榜信息(Crawler)
做了个爬虫,爬取当当网--2015年图书销售排行榜 TOP500 爬取的基本思想是:通过浏览网页,列出你所想要获取的信息,然后通过浏览网页的源码和检查(这里用的是chrome)来获相关信息的节点,最后 ...
- java爬虫,爬取当当网数据
背景:女票快毕业了(没错!我是有女票的!!!),写论文,主题是儿童性教育,查看儿童性教育绘本数据死活找不到,没办法,就去当当网查询下数据,但是数据怎么弄下来呢,首先想到用Python,但是不会!!百 ...
- python爬虫06 | 你的第一个爬虫,爬取当当网 Top 500 本五星好评书籍
来啦,老弟 我们已经知道怎么使用 Requests 进行各种请求骚操作 也知道了对服务器返回的数据如何使用 正则表达式 来过滤我们想要的内容 ... 那么接下来 我们就使用 requests 和 re ...
- 【转】java爬虫,爬取当当网数据
背景:女票快毕业了(没错!我是有女票的!!!),写论文,主题是儿童性教育,查看儿童性教育绘本数据死活找不到,没办法,就去当当网查询下数据,但是数据怎么弄下来呢,首先想到用Python,但是不会!!百 ...
随机推荐
- eclipse android ndk开发遇到的问题.
1. error:parameter name omitted 用javah生成的.h文件中,方法是没有指定形参的,实现的时候需要我们在实现的方法定义中加上形参. 2. 'NewStringUTF' ...
- 你可能不知道的 Python 技巧
英文 | Python Tips and Trick, You Haven't Already Seen 原作 | Martin Heinz (https://martinheinz.dev) 译者 ...
- influxdb基础那些事儿
InfluxDB是一个开源的时序数据库,使用GO语言开发,特别适合用于处理和分析资源监控数据这种时序相关数据.而InfluxDB自带的各种特殊函数如求标准差,随机取样数据,统计数据变化比等,使数据统计 ...
- 浅谈openresty
浅谈openresty 为什么会有OpenResty? 我们都知道Nginx有很多的特性和好处,但是在Nginx上开发成了一个难题,Nginx模块需要用C开发,而且必须符合一系列复杂的规则,最重要的用 ...
- 使用AOP和Semaphore对项目中具体的某一个接口进行限流
整体思路: 一 具体接口,可以自定义一个注解,配置限流量,然后对需要限流的方法加上注解即可! 二 容器初始化的时候扫描所有所有controller,并找出需要限流的接口方法,获取对应的限流量 三 使用 ...
- Lambda 表达式入门,看这篇就够了
说出来怕你们不相信,刚接到物业通知,疫情防控升级了,车辆只能出不能进,每户家庭每天可指派 1 名成员上街采购生活用品.这不是谣言,截个图自证清白,出自洛阳市湖北路街道处. 看来事态严峻,这样看似好心, ...
- SQL Server 常用的数据类型
1. 字符串数据类型 char 此数据类型可存储1~8000个定长字符串,字符串长度在创建时指定:如未指定,默认为char(1).每个字符占用1byte存储空间. nchar ...
- FFMPEG学习----分离视频里的H.264与YUV数据
#include <stdio.h> extern "C" { #include "libavcodec/avcodec.h" #include & ...
- 批处理版MPlayer播放器(甲兵时代原创批处理)(下)
注意,由于空间不支持显示退格键,需要自己手动补上,方法如上图: 接上篇: 批处理版音视频播放器上(甲兵时代原创批处理) :Bc cls COLOR 2F echo. call :colour &quo ...
- 《Android Studio实战 快速、高效地构建Android应用》--Android Studio操作
前言 摩尔定律:CPU的处理能力大约18个月翻一倍 Android&Java:想要在Android Studio中开发Android App,必须以充分了解Java为前提(Java流行的原因: ...