Spark学习笔记(三)—— Standalone模式
上篇笔记记录了Local模式的一些内容,但是实际的应用中很少有使用Local模式的,只是为了我们方便学习和测试。真实的生产环境中,Standalone模式更加合适一点。
1、基础概述
Standalone不是单机模式,它是集群,但是是基于Spark独立调度器的集群,也就是说它是Spark特有的运行模式。有Client和Cluster两种模式,主要区别在于:Driver程序的运行节点。怎么理解呢?哪里提交任务哪里启动Driver,这个叫做Client模式;随便找台机器启动Driver,这个叫做Cluster模式。
说白了就是只有Spark自己负责调度自己的集群,不用什么Yarn、Mesos。那么这样就没有Yarn的ResourceManager 、 NodeManager和Container了,它俩对应到Spark的概念是Master、Worker和Executor。
画了张图,解释Standalone运行模式:
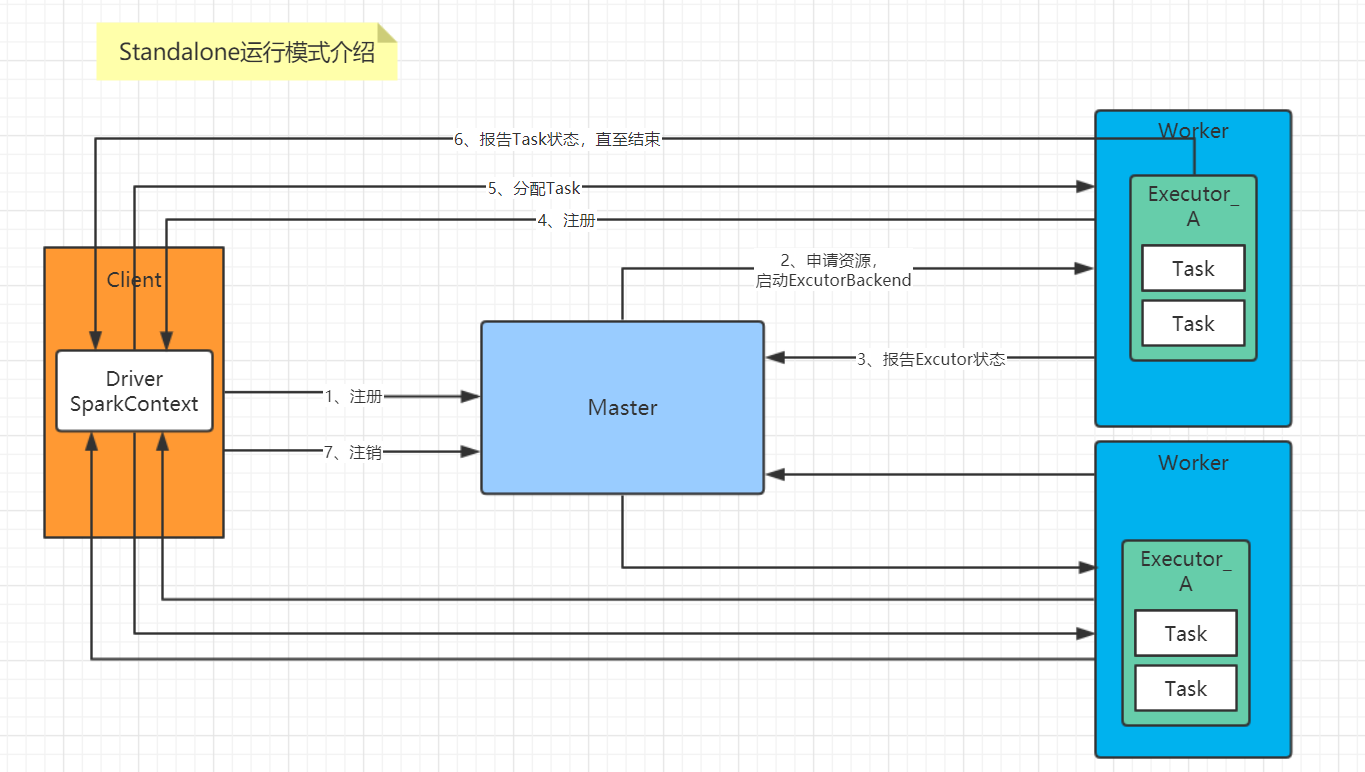
2、安装使用
1)修改slave文件,添加work节点:
[simon@hadoop102 conf]$ vim slaves
hadoop102
hadoop103
hadoop104
2)修改spark-env.sh文件,添加如下配置:
[simon@hadoop102 conf]$ vim spark-env.sh
SPARK_MASTER_HOST=hadoop102
SPARK_MASTER_PORT=7077
3)分发spark包
[simon@hadoop102 module]$ xsync spark/
4)启动集群
[simon@hadoop102 spark]$ sbin/start-all.sh
#查看启动信息
hadoop103: JAVA_HOME is not set
hadoop103: full log in /opt/module/spark/logs/spark-simon-org.apache.spark.deploy.worker.Worker-1-hadoop103.out
报了异常信息:JAVA_HOME is not set,可以在sbin目录下的spark-config.sh 文件中加入如下配置:
export JAVA_HOME=/opt/module/jdk1.8.0_144
然后重新启动集群:
[simon@hadoop102 spark]$ sbin/start-all.sh
#查看启动信息
[simon@hadoop102 spark]$ jpsall
--------------------- hadoop102 -------------------------------
4755 NameNode
4900 DataNode
5704 NodeManager
6333 Master
6623 Worker
--------------------- hadoop103 -------------------------------
8342 DataNode
9079 NodeManager
10008 Worker
8893 ResourceManager
--------------------- hadoop104 -------------------------------
8882 NodeManager
8423 SecondaryNameNode
9560 Worker
8347 DataNode
可以看到Spark集群已经启动成功了,Hadoop102是Master节点,两外两个是Worker节点
5)执行一一个官方案例:
[simon@hadoop102 spark]$ bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://hadoop102:7077 \
--executor-memory 1G \
--total-executor-cores 2 \
./examples/jars/spark-examples_2.11-2.1.1.jar \
100
和local模式的区别就在于指定了master节点
执行结果:

3、JobHistoryServer配置
如果我们想看任务执行的日志信息,我们还需要配置历史服务器
1)修改spark-default.conf文件,开启Log:
[simon@hadoop102 conf]$ vi spark-defaults.conf
spark.eventLog.enabled true
#directory要事先创建好
spark.eventLog.dir hdfs://hadoop102:9000/directory
2)在HDFS上创建文件夹
[simon@hadoop102 hadoop]$ hadoop fs –mkdir /directory
3)修改spark-env.sh文件,添加如下配置:
[simon@hadoop102 conf]$ vi spark-env.sh
export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=18080
-Dspark.history.retainedApplications=30
-Dspark.history.fs.logDirectory=hdfs://hadoop102:9000/directory"
#参数描述:
spark.eventLog.dir:Application在运行过程中所有的信息均记录在该属性指定的路径下;
spark.history.ui.port=18080 WEBUI访问的端口号为18080
spark.history.fs.logDirectory=hdfs://hadoop102:9000/directory 配置了该属性后,在start-history-server.sh时就无需再显式的指定路径,Spark History Server页面只展示该指定路径下的信息
spark.history.retainedApplications=30指定保存Application历史记录的个数,如果超过这个值,旧的应用程序信息将被删除,这个是内存中的应用数,而不是页面上显示的应用数。
4)分发配置文件
[simon@hadoop102 conf]$ xsync spark-defaults.conf
[simon@hadoop102 conf]$ xsync spark-env.sh
5)启动历史服务器
[simon@hadoop102 spark]$ sbin/start-history-server.sh
6)再次执行任务
[simon@hadoop102 spark]$ bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://hadoop102:7077 \
--executor-memory 1G \
--total-executor-cores 2 \
./examples/jars/spark-examples_2.11-2.1.1.jar \
100
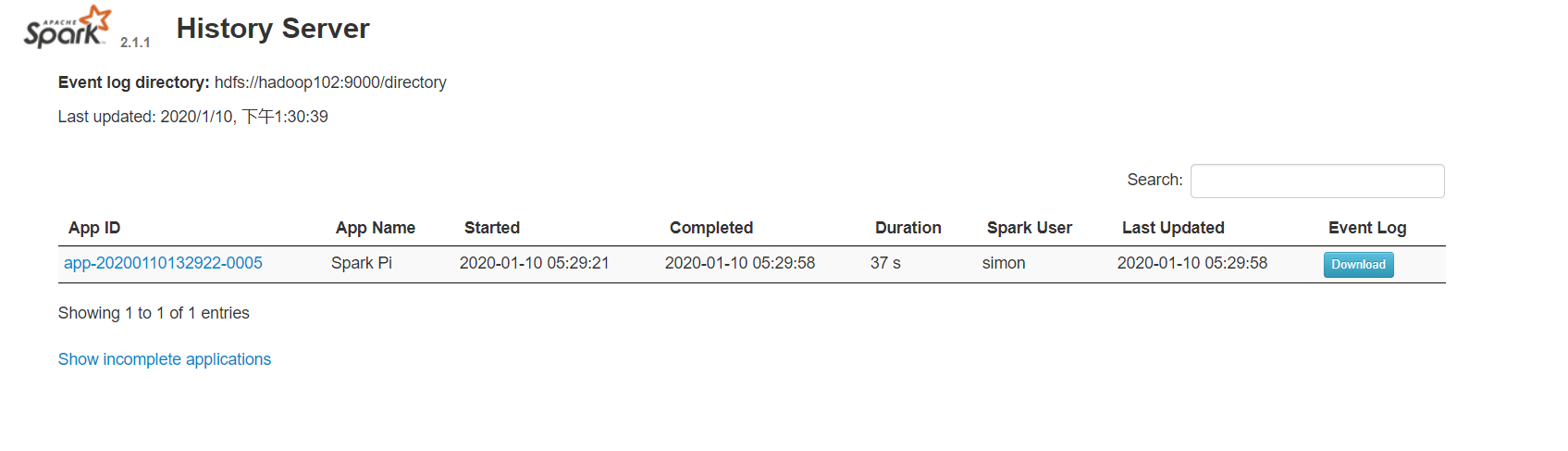
7)查看历史任务日志
hadoop102:18080
4、HA配置
Spark集群部署完了,但是有一个很大的问题,那就是 Master 节点存在单点故障,要解决此问题,就要借助 zookeeper,并且启动至少两个 Master 节点来实现高可靠,配置方式也比较简单。
HA模式的整体架构图:
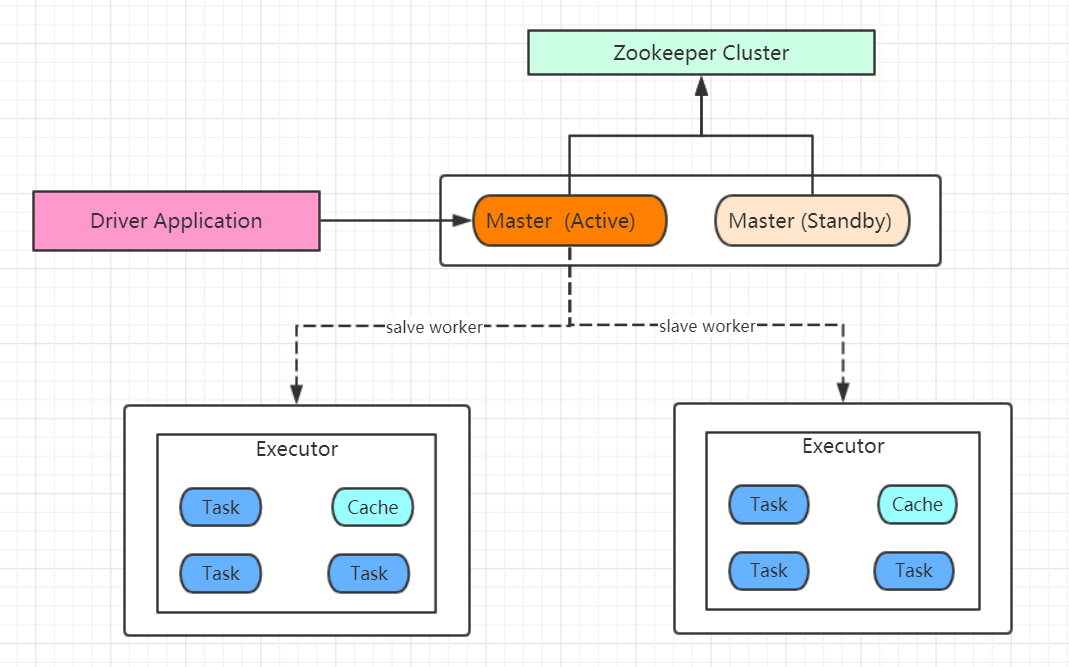
可以看到依赖了Zookeeper,其实和HDFS的HA运行模式差不多,那么开始着手配置。
1)zookeeper正常安装并启动
[simon@hadoop102 spark]$ zk-start.sh
[simon@hadoop102 spark]$ jpsall
--------------------- hadoop102 -------------------------------
8498 HistoryServer
4755 NameNode
4900 DataNode
5704 NodeManager
6333 Master
9231 QuorumPeerMain
6623 Worker
--------------------- hadoop103 -------------------------------
8342 DataNode
9079 NodeManager
10008 Worker
10940 QuorumPeerMain
8893 ResourceManager
--------------------- hadoop104 -------------------------------
11073 QuorumPeerMain
8882 NodeManager
8423 SecondaryNameNode
9560 Worker
8347 DataNode
QuorumPeerMain就是zookeeper的进程,可以看到已经正常启动了。
2)修改spark-env.sh文件添加如下配置:
[simon@hadoop102 conf]$ vi spark-env.sh
注释掉如下内容:
#SPARK_MASTER_HOST=hadoop102
#SPARK_MASTER_PORT=7077
添加上如下内容:
export SPARK_DAEMON_JAVA_OPTS="
-Dspark.deploy.recoveryMode=ZOOKEEPER
-Dspark.deploy.zookeeper.url=hadoop102,hadoop103,hadoop104
-Dspark.deploy.zookeeper.dir=/spark"
3)分发配置文件
[simon@hadoop102 conf]$ xsync spark-env.sh
4)在hadoop102上启动全部节点
[simon@hadoop102 spark]$ sbin/start-all.sh
5)在hadoop103上单独启动master节点
[simon@hadoop103 spark]$ sbin/start-master.sh
6)spark HA集群访问
/opt/module/spark/bin/spark-shell \
--master spark://hadoop102:7077,hadoop103:7077 \
--executor-memory 2g \
--total-executor-cores 2
在学习测试过程中并不常用,配起来测试一下就行了。Hadoop102、Hadoop103都是master,关闭Active的master,看到Master自动切换即可。
参考资料:
[1] 李海波. 大数据技术之Spark
Spark学习笔记(三)—— Standalone模式的更多相关文章
- Spark学习笔记-三种属性配置详细说明【转】
相关资料:Spark属性配置 http://www.cnblogs.com/chengxin1982/p/4023111.html 本文出处:转载自过往记忆(http://www.iteblog.c ...
- Spark 学习笔记之 Standalone与Yarn启动和运行时间测试
Standalone与Yarn启动和运行时间测试: 写一个简单的wordcount: 打包上传运行: Standalone启动: 运行时间: Yarn启动: 运行时间: 测试结果: Standalon ...
- Spark进阶之路-Standalone模式搭建
Spark进阶之路-Standalone模式搭建 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.Spark的集群的准备环境 1>.master节点信息(s101) 2&g ...
- Spark学习(三): 基本架构及原理
Apache Spark是一个围绕速度.易用性和复杂分析构建的大数据处理框架,最初在2009年由加州大学伯克利分校的AMPLab开发,并于2010年成为Apache的开源项目之一,与Hadoop和St ...
- Spark学习笔记之SparkRDD
Spark学习笔记之SparkRDD 一. 基本概念 RDD(resilient distributed datasets)弹性分布式数据集. 来自于两方面 ① 内存集合和外部存储系统 ② ...
- spark学习笔记总结-spark入门资料精化
Spark学习笔记 Spark简介 spark 可以很容易和yarn结合,直接调用HDFS.Hbase上面的数据,和hadoop结合.配置很容易. spark发展迅猛,框架比hadoop更加灵活实用. ...
- [Firefly引擎][学习笔记三][已完结]所需模块封装
原地址:http://www.9miao.com/question-15-54671.html 学习笔记一传送门学习笔记二传送门 学习笔记三导读: 笔记三主要就是各个模块的封装了,这里贴 ...
- VSTO学习笔记(三) 开发Office 2010 64位COM加载项
原文:VSTO学习笔记(三) 开发Office 2010 64位COM加载项 一.加载项简介 Office提供了多种用于扩展Office应用程序功能的模式,常见的有: 1.Office 自动化程序(A ...
- 学习笔记(三)--->《Java 8编程官方参考教程(第9版).pdf》:第十章到十二章学习笔记
回到顶部 注:本文声明事项. 本博文整理者:刘军 本博文出自于: <Java8 编程官方参考教程>一书 声明:1:转载请标注出处.本文不得作为商业活动.若有违本之,则本人不负法律责任.违法 ...
- muduo网络库学习笔记(三)TimerQueue定时器队列
目录 muduo网络库学习笔记(三)TimerQueue定时器队列 Linux中的时间函数 timerfd简单使用介绍 timerfd示例 muduo中对timerfd的封装 TimerQueue的结 ...
随机推荐
- H3C 总线型以太网拓扑扩展
- mac常用快捷键,Mac文件重命名快捷键,Mac OS快速访问系统根目录, MacOS 10.11重要数据的存储位置大全
command+r,相当于F5,刷新页面 command+F5,启动voiceover command+q 关闭当前程序 在Finder中command+/ 打开底部状态栏,可以查看剩余磁盘空间大小 ...
- java中的常量和变量
变量的概念: 占据着内存中的某一个存储区域; 该区域有自己的名称(变量名)和类型(数据类型); 该区域的数据可以在同一类型范围内不断变化; 为什么要定义变量: 用来不断的存放同一类型的常量,并可以重复 ...
- 【知识小结】Git 个人学习笔记及心得
https://mp.weixin.qq.com/s/D96dXYfu3XAA4ac456qo0g git架构 工作区:就是你在电脑里能看到的目录. 版本库:工作区有一个隐藏目录.git,,而是Git ...
- SQL 常见出现错误(附件、保存表、脱机、自增序列号 )
一.问题如图所示: 当填了某些数据,按“保存”时出现这个问题怎么解决? 1.打开“工具”-“选项”-“Designers” , 2.选择如下去勾: 二.当附加数据库的时候出现如下错误: 在附件文件上选 ...
- Vue的路由Router之导航钩子和元数据及匹配
一.文件结构 二.vue.js 打开此链接 https://cdn.bootcss.com/vue/2.6.10/vue.js 复制粘贴页面的所有内容 三.vue-router.js 打开此链接 h ...
- git卡在Resolving deltas 100%的解决办法
很多同学都有这样的问题.不知道是git的问题,还是tortoisegit的问题. 我的版本: Git-1.8.4-preview20130916 TortoiseGit-1.8.6.0-32bit 已 ...
- 访问HTML可以,访问PHPfile not found
www目录的所有者和所属组都改为nginx用户试一下. 参考命令: chown nginx.nginx /home/www ps aux |grep nginx 看一下您的nginx是以哪个用户的 ...
- linux 在 /proc 里实现文件
所有使用 /proc 的模块应当包含 <linux/proc_fs.h> 来定义正确的函数. 要创建一个只读 /proc 文件, 你的驱动必须实现一个函数来在文件被读时产生数据. 当 某个 ...
- 解决浏览器中点击input输入框时,placeholder的值不消失的方法
版权声明:本文为博主原创文章,遵循CC 4.0 by-sa版权协议,转载请附上原文出处链接和本声明. 本文链接:https://blog.csdn.net/lianwenxiu/article/det ...