ACM北大暑期课培训第四天
今天讲了几个高级搜索算法:A* ,迭代加深,Alpha-Beta剪枝 以及线段树
A*算法
启发式搜索算法(A算法) :
在BFS算法中,若对每个状态n都设定估价函数 f(n)=g(n)+h(n),并且每次从Open表(队列)中选节点进行扩展时,都选取f值最小的节点,则该搜索算法为启发式搜索算法,又称A算法。
g(n) : 从起始状态到当前状态n的代价
h(n) : 从当前状态n到目标状态的估计代价
A算法中的估价函数若选取不当,则可能找不到解,或找到的解也不是最优解。因此,需要对估价函数做一些限制,使得算法确保找到最优解(步数,即状态转移次数最少的 解)。A*算法即为对估价函数做了特定限制, 且确保找到最优解的A算法。
A*算法:
f*(n) = g*(n) +h*(n)
f*(n) :从初始节点S0出发,经过节点n到达目标节点的最小步数 (真实值)。
g*(n): 从S0出发,到达n的最少步数(真实值)
h*(n): 从n出发,到达目标节点的最少步数(真实值)
估价函数f(n)则是f*(n)的估计值。
f (n)=g(n) +h(n) ,且满足以下限制:
A*算法 g(n)是从s0到n的真实步数(未必是最优的),因此: g(n)>0 且g(n)>=g*(n)
h(n)是从n到目标的估计步数。估计总是过于乐观的,即 h(n)<= h*(n) 且 h(n)相容,则A算法转变为A*算法。A*正确性证明略。
h(n)的相容:
如果h函数对任意状态s1和s2还满足: h(s1) <= h(s2) + c(s1,s2)
c(s1,s2)是s1转移到s2的步数,则称h是相容的。 h相容能确保随着一步步往前走,f递增,这样A*能更高效找 到最优解。
h相容 => g(s1) + h(s1) <= g(s1) + h(s2) +c(s1,s2) = g(s2)+h(S2) => f(s1) <= f(s2) 即f是递增的。
A*算法的搜索效率很大程度上取决于估价函数h(n)。一般说来,在 满足h(n)≤h*(n)的前提下,h(n)的值越大越好。
open=[Start]
closed=[]
while open不为空
{
从open中取出估价值f最小的结点n
if n == Target then
return 从Start到n的路径 // 找到了!!!
else {
for n的每个子结点x {
if x in open {
计算新的f(x)
比较open表中的旧f(x)和新f(x)
if 新f(x) < 旧f(x)
{
删掉open表里的旧f(x),加入新f(x)
}
}
else if x in closed {
计算新的f(x)
比较closed表中的旧f(x)和新f(x)
if 新f(x) < 旧f(x)
{
remove x from closed
add x to open
}
} // 比较新f(x)和旧f(x) 实际上比的就是新旧g(x),因h(x)相等
else {
// x不在open,也不在close,是遇到的新结点
计算f(x) add x to open
}
}
add n to closed
}
}
//open表为空表示搜索结束了,那就意味着无解!
A * 算法伪代码(在节点信息中记录了其父节点):
标准的启发式函数是曼哈顿距离(Manhattan distance)。考虑你的代价函数并找到从一个位置移动到邻近位置的最小代价D。
曼哈顿距离——两点在南北方向上的距离加上在东西方向上的距离,即D(I,J)=|XI-XJ|+|YI-YJ|。
对于一个具有正南正北、正东正西方向规则布局的城镇街道,从一点到达另一点的距离正是在南北方向上旅行的距离加上在东西方向上旅行的距离因此曼哈顿距离又称为出租车距离,曼哈顿距离不是距离不变量,当坐标轴变动时,点间的距离就会不同
推荐一个博客:https://blog.csdn.net/u013630349/article/details/53954164
例题:八数码问题
POJ上可用A*算法解决的题:1376 1324 1084 2449 1475
迭代加深搜索算法
算法思路 : 总体上按照深度优先算法方法进行
对搜索深度需要给出一个深度限制dm,当深度达到 了dm的时候,如果还没有找到解答,就停止对该分 支的搜索,换到另外一个分支继续进行搜索。 dm从1开始,从小到大依次增大(因此称为迭代加深 )(多次从起点出发)
迭代加深搜索是最优的,也是完备的,它能找到最优解又能节省空间(费时间)还可以不用判重。
例题:POJ 2286 The Rotation Game
Alpha-Beta剪枝 (极大极小搜索法)
假设:MAX和MIN对弈,轮到MAX走棋了,那么我们会遍历MAX的 每一个可能走棋方法,然后对于前面MAX的每一个走棋方法,遍历MIN的每一个走棋方法,然后接着遍历MAX的每一个走棋方法, …… 直到分出胜负或者达到了搜索深度的限制。若达到搜索深度限制时尚未分出胜负,则根据当前局面的形式,给出一个得分 ,计算得分的方法被称为估价函数,不同游戏的估价函数如何设 计和具体游戏相关。
在搜索树中,轮到MAX走棋的节点即为极大节点,轮到MIN走棋 的节点为极小节点。
方法:
1) 确定估价值函数,来计算每个棋局节点的估价值。对MAX方有利,估价值为正,对MAX方越有利,估价值越大。对MIN方有利,估价值为负, 对MIN方越有利,估价值越小。
2) 从当前棋局的节点要决定下一步如何走时,以当前棋局节点为根,生成一棵深度为n的搜索树。不妨总是假设当前棋局节点是MAX节点。
3) 用局面估价函数计算出每个叶子节点的估价值
4) 若某个非叶子节点是极大节点,则其估价值为其子节点中估价值最大的 那个节点的估价值
若某个非叶子节点是极小节点,则其估价值为其子节点中估价值最小 的那个节点的估价值
5) 选当前棋局节点的估价值最大的那个子节点,作为此步行棋的走法。
若结点x是Min节点,其兄弟节点(父节点相同的节点)中,已经求到的最大估价值是b(有些兄弟节点的估价值,可能还没有算出来),那么在对x的子节点进行考查的过程中,如果一旦发现某子节点的估价值 <=b,则不必再考查后面的x的子节点了。
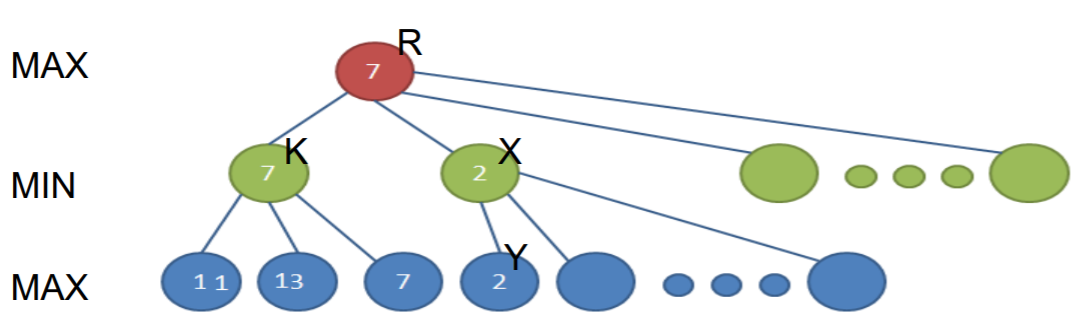
alpha剪枝
当搜索节点X时,若已求得某子节点Y的值为2,因为X是一个极小节点,那 么X节点得到的值肯定不大于2。因此X节点的子节点即使都搜索了,X节点 值也不会超过2。而节点K的值为7,由于R是一个Max节点,那么R的取值已 经可以肯定不会选X的取值了。因此X节点的Y后面子节点可以忽略,即图中 第三层没有数字的节点可被忽略。此即为alpha剪枝 ---- 因被剪掉的节点 是极大节点。相应的也有beta剪枝,即被剪掉的节点是极小节点。
beta剪枝
若结点x是Max节点,其兄弟节点(父节点相同的节点)中,已经求到的最小 估价值是a(有些兄弟节点的估价值,可能还没有算出来) 那么在对x的子节点进行考查的过程中,如果一旦发现某子节点的估价值 >= a,则不必再考查后面的x的子节点了。
function minimax(node, depth) // 指定当前节点和还要搜索的深度
// 如果胜负已分或者深度为零,使用评估函数返回局面得分
{
if node is a terminal node or depth =
return the heuristic value of node
// 如果轮到对手走棋,即node是极小节点,选择一个得分最小的走法
if the adversary is to play at node
let α : = +∞
foreach child of node
α : = min(α, minimax(child, depth-))
// 如果轮到自己走棋,是极大节点,选择一个得分最大的走法
else{we are to play at node }
let α : = -∞
foreach child of node
α : = max(α, minimax(child, depth-))
return α;
} 具体的做法:
int MinMax(int depth) //函数的评估都是以MAX方的角度来评估的
{
if (SideToMove() == MAX_SIDE)
return Max(depth);
else
return Min(depth);
}
int Max(int depth)
{
int best = -INFINITY;
if (depth <= ) return Evaluate();
GenerateLegalMoves();
while (MovesLeft()) //可以走
{
MakeNextMove();
val = Min(depth - );
UnmakeMove();
if (val > best) best = val;
}
return best;
} int Min(int depth)
{
int best = INFINITY; // 注意这里不同于“最大”算法
if (depth <= )
return Evaluate();
GenerateLegalMoves();
while (MovesLeft())
{
MakeNextMove();
val = Max(depth - );
UnmakeMove();
if (val < best) // 注意这里不同于“最大”算法
best = val;
}
return best;
}
伪代码
PS:红色字母处,随便写什么值都可以
在搜到底的情况下,infinity不一定是无穷大 infinity应该是主角赢的那 个状态(胜负已分的状态)的估价值,而-infinity应该是主角输的那个状态( 胜负已分的状态)的估价值。
必胜是指无论对方怎么走己方最后都能找到获胜方法,而不是不是自己怎么走都能获胜。
线段树
同一层的节点所代表的区间,相互不会重叠。同 一层节点所代表的区间,加起来是个连续的区间。
线段树是一棵二叉树,树中的每一个结 点表示了一个区间[a,b]。a,b通常是整数。
每一个叶子节点表示了一个单位区间(长度为1)。对于每一个非叶结点所表示的结点[a,b],其左儿子表示的区间为 [a,(a+b)/2],右儿子表示的区间为 [(a+b)/2+1,b](除法去尾取整)。
线段树的平分构造,实际上是用了二分的方法。若根节 点对应的区间是[a,b],那么它的深度为log2 (b-a+1) +1 (向上 取整)。
叶子节点的数目和根节点表示区间的长度相同.
线段树节点要么0度,要么2度, 因此若叶子节点数目为N, 则线段树总结点数目为2N-1
区间分解的时候,每层最多2个“终止节点”, 所以 终止节点总数也是log(n)量级的
线段树的深度不超过log2 (n)+1(向上取整,n是根节点 对应区间的长度)
线段树上,任意一个区间被分解后得到的“终止 节点”数目都是log(n)量级。线段树上更新叶子节点和进行区间分解时间 复杂度都是O(log(n))的
线段树的基本用途:线段树适用于和区间统计有关的问题。比如某些数据 可以按区间进行划分,按区间动态进行修改,而且还 需要按区间多次进行查询,那么使用线段树可以达到 较快查询速度。
用线段树解题,关键是要想清楚每个节点要存哪些信息 (当然区间起终点,以及左右子节点指针是必须的), 以及这些信息如何高效更新,维护,查询。不要一更新 就更新到叶子节点,那样更新效率最坏就可能变成O(n) 的了。
先建树,然后插入数据,然后更新,查询。
当数据太大时注意离散化:有时,区间的端点不是整数,或者区间太 大导致建树内存开销过大MLE ,那么就需要 进行“离散化”后再建树。
例题:1.POJ 3264 Balanced Lineup
2.POJ 3468 A Simple Problem with Integers
3.POJ 2528 Mayor's posters
ACM北大暑期课培训第四天的更多相关文章
- ACM北大暑期课培训第一天
今天是ACM北大暑期课开课的第一天,很幸运能参加这次暑期课,接下来的几天我将会每天写博客来总结我每天所学的内容.好吧下面开始进入正题: 今天第一节课,郭炜老师给我们讲了二分分治贪心和动态规划. 1.二 ...
- ACM北大暑期课培训第七天
昨天没时间写,今天补下. 昨天学的强连通分支,桥和割点,基本的网络流算法以及Dinic算法: 强连通分支 定义:在有向图G中,如果任意两个不同的顶点 相互可达,则称该有向图是强连通的. 有向图G的极大 ...
- ACM北大暑期课培训第六天
今天讲了DFA,最小生成树以及最短路 DFA(接着昨天讲) 如何高效的构造前缀指针: 步骤为:根据深度一一求出每一个节点的前缀指针.对于当前节点,设他的父节点与他的边上的字符为Ch,如果他的父节点的前 ...
- ACM北大暑期课培训第二天
今天继续讲的动态规划 ... 补充几个要点: 1. 善于利用滚动数组(可减少内存,用法与计算方向有关) 2.升维 3.可利用一些数据结构等方法使代码更优 (比如优先队列) 4.一般看到数值小的 (十 ...
- ACM北大暑期课培训第八天
今天学了有流量下界的网络最大流,最小费用最大流,计算几何. 有流量下界的网络最大流 如果流网络中每条边e对应两个数字B(e)和C(e), 分别表示该边上的流量至少要是B(e),最多 C(e),那么,在 ...
- ACM北大暑期课培训第五天
今天讲的扫描线,树状数组,并查集还有前缀树. 扫描线 扫描线的思路:使用一条垂直于X轴的直线,从左到右来扫描这个图形,明显,只有在碰到矩形的左边界或者右边界的时候,这个线段所扫描到的情况才会改变, ...
- ACM北大暑期课培训第三天
今天讲的内容是深搜和广搜 深搜(DFS) 从起点出发,走过的点要做标记,发现有没走过的点,就随意挑一个往前走,走不 了就回退,此种路径搜索策略就称为“深度优先搜索”,简称“深搜”. bool Dfs( ...
- 牛客网暑期ACM多校训练营(第四场):A Ternary String(欧拉降幂)
链接:牛客网暑期ACM多校训练营(第四场):A Ternary String 题意:给出一段数列 s,只包含 0.1.2 三种数.每秒在每个 2 后面会插入一个 1 ,每个 1 后面会插入一个 0,之 ...
- 2019年ArcGIS规划专业专项培训(四天)
2019年ArcGIS规划专业专项培训(四天) 商务合作,科技咨询,版权转让:向日葵,135-4855__4328,xiexiaokui#qq.com 第一天:GIS入门 第一章 GIS概述及其应 ...
随机推荐
- tensorflow入门——5tensorflow安装
你将把你学到的神经网络的知识,借助 TensorFlow ,一个 Google 开源的深度学习框架,应用在真实的数据集中. 你将使用 TensorFlow 来辨别 notMNIST 数据集.它是一个由 ...
- 关于浏览器ip代理导致定位错乱问题的坑
http://m.welltrend.com.cn/网站在Android手机的qq浏览器或者uc浏览器或者在微信中打开连接访问时,点击右侧的聊天按钮,经常出现手机在北京结果定位到天津的问题,或者广州的 ...
- Python--day60--web框架分类和wsgiref模块使用介绍
- Codeforces Round #529 (Div. 3) E. Almost Regular Bracket Sequence(思维)
传送门 题意: 给你一个只包含 '(' 和 ')' 的长度为 n 字符序列s: 给出一个操作:将第 i 个位置的字符反转('(' ')' 互换): 问有多少位置反转后,可以使得字符串 s 变为&quo ...
- H3C 什么是OSPF
- element 级联选择器使用
<el-cascader v-model="organSelecList" :change-on-select="true" :options=" ...
- javaScript通过URL获取参数
// 函数方法 function GetQueryString(name) { var reg = new RegExp("(^|&)" + name + "=( ...
- Linux 内核同步 urb
不幸的是, 同步 urb 没有一个象中断, 控制, 和块 urb 的初始化函数. 因此它们必须在 驱动中"手动"初始化, 在它们可被提交给 USB 核心之前. 下面是一个如何正确初 ...
- JMeter FTP测试计划
为了演示测试目的,我们将使用公共可用的FTP位置,可以使用它来测试文件的下载. 您可以使用市场上现有的任何可用的演示FTP位置.我们使用URL下的FTP位置: https://dlptest.com/ ...
- 关于在vuejs中动态加载不确定数量和内容的组件的解决方案
在做一个门户项目的时候,客户要求需要进行私人化定制,每个人进入首页的时候可以自定义首页显示的版块 要在4.50个组件中显示随机N个组件按照每个人选定的顺序排列.需求说完了,接下来说说解决方案: htm ...