Deeplab
Deeplab系列是谷歌团队的分割网络.
DeepLab V1
CNN处理图像分割的两个问题
- 下采样导致信息丢失
maxpool造成feature map尺寸减小,细节信息丢失. - 空间不变性
所谓空间不变性,就是说比如一张狗的图,狗位于图片正中还是某一个角,都不影响模型识别出这是一个狗. 即模型对于输入图像的空间位置不敏感,不管这个图片旋转,平移等,都能够识别. 对分类来说,这是ok的.但是对于分割来说,这就不OK了,图片旋转以后,每一个像素所属的分类当然就改变了.
究其原因,分类处理的是更"高级"的特征,而分割是对每一个像素做分类,需要更多的细节.
deeplab v1采用2个方法解决这两个问题
- 空洞卷积
- 条件随机场CRF
空洞卷积
为什么要有maxpool?
一方面是为了减小feature map尺寸.一方面也是为了增大feature map中的每一个元素的感受野.
FCN是怎么做的?
得到特征图后,用deconv的方式上采样将feature map恢复到原始图像尺寸.但是这种先max pool下采样再deconv上采样的过程势必会损失掉一部分信息.
deeplab如何解决这个问题?
deeplab提出了一种dilated conv(空洞卷积)的卷积方式,去替代max pool,但同时感受野不丢失.
dilated的好处是不做pooling损失信息的情况下,加大了感受野,让每个卷积输出都包含较大范围的信息。,对图像分割这种对空间位置,细节信息很敏感的任务而言,空洞卷积是一种很好的方式.
空洞卷积的卷积方式如下图所示:
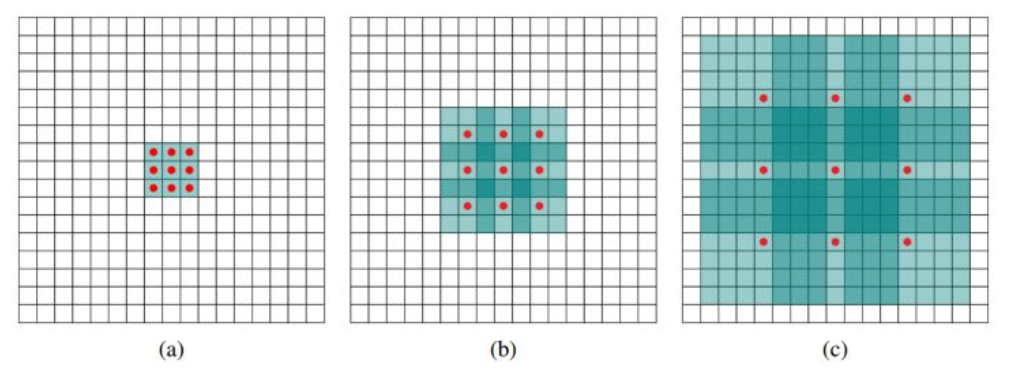
(a)图对应3x3的1-dilated conv,和普通的卷积操作一样,(b)图对应3x3的2-dilated conv,实际的卷积kernel size还是3x3,但是空洞为1,也就是对于一个7x7的图像patch,只有9个红色的点和3x3的kernel发生卷积操作,其余的点略过。也可以理解为kernel的size为7x7,但是只有图中的9个点的权重不为0,其余都为0。 可以看到虽然kernel size只有3x3,但是这个卷积的感受野已经增大到了7x7(如果考虑到这个2-dilated conv的前一层是一个1-dilated conv的话,那么每个红点就是1-dilated的卷积输出,所以感受野为3x3,所以1-dilated和2-dilated合起来就能达到7x7的conv),(c)图是4-dilated conv操作,同理跟在两个1-dilated和2-dilated conv的后面,能达到15x15的感受野。对比传统的conv操作,3层3x3的卷积加起来,stride为1的话,只能达到(kernel-1)*layer+1=7的感受野,也就是和层数layer成线性关系,而dilated conv的感受野是指数级的增长。
CRF
由于CNN天然的空间不变性,使得对分割任务而言,CNN提取到的特征不够精细.所以在特征提取后,我们再加一个CRF,达到更精细的特征提取目的.
以前写过一篇条件随机场笔记
说白了,就是一堆特征提取函数(相当于CNN中的卷积核),对不同的特征提取函数赋以不同的权重(相当于全连接层),再做指数化和正则化(相当于softmax)得到一个概率值.
https://blog.csdn.net/hjimce/article/details/50888915
DeepLab V2
相较于v1
- ASPP
- 基础特征提取网络由vgg替换为resnet
重点是ASPP
ASPP(Atrous Spatial Pyramid Pooling)
看名字就知道了,空间金字塔.用以解决多尺度问题.即对同一个物体,不管其在图像中是大或小都可以准确识别.
具体如下:
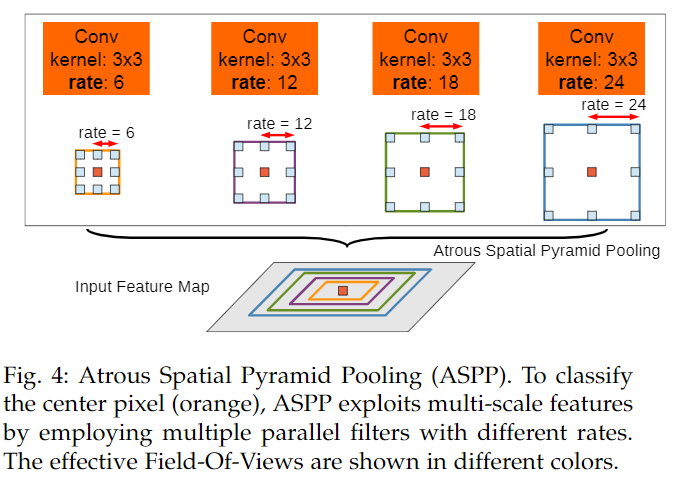
用不同的空洞卷积对输入做卷积,再融合不同的feature map.
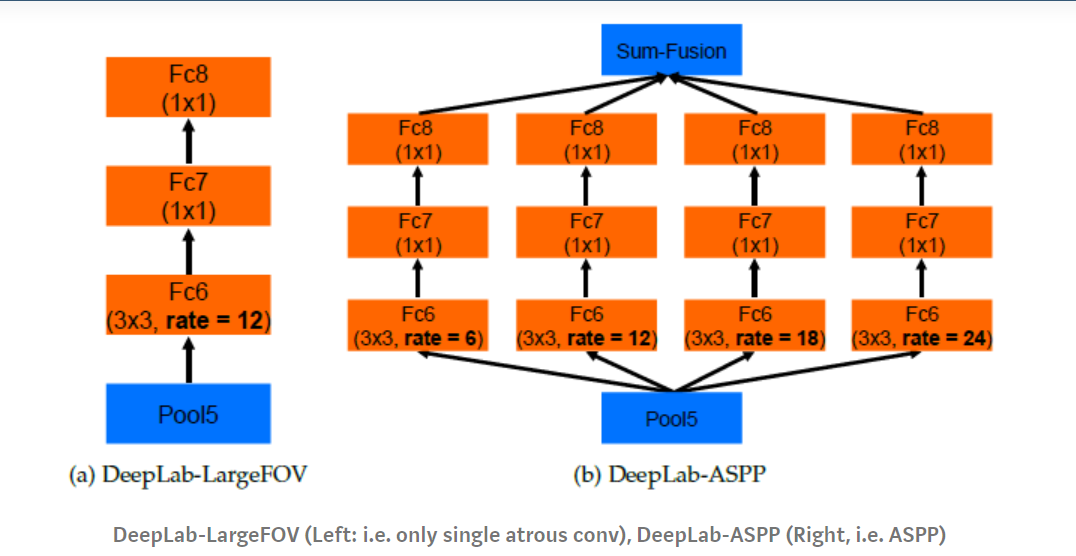
如上图所示,(a)是没有用ASPP的,(b)是用了ASPP的结构.
DeepLab V3
论文地址:https://arxiv.org/abs/1706.05587
v3对网络结构做了比较大的改变,主要是:
- 去掉了crf.
- 改造了resnet,在resnet中使用空洞卷积和金字塔空洞卷积
对resnet的改造体现在两点:
- 使用空洞卷积,去掉下采样,如此,保证感受野与feature map尺寸不变
- 在残差块内部使用ASPP,保证对多尺度的敏感
使用空洞卷积
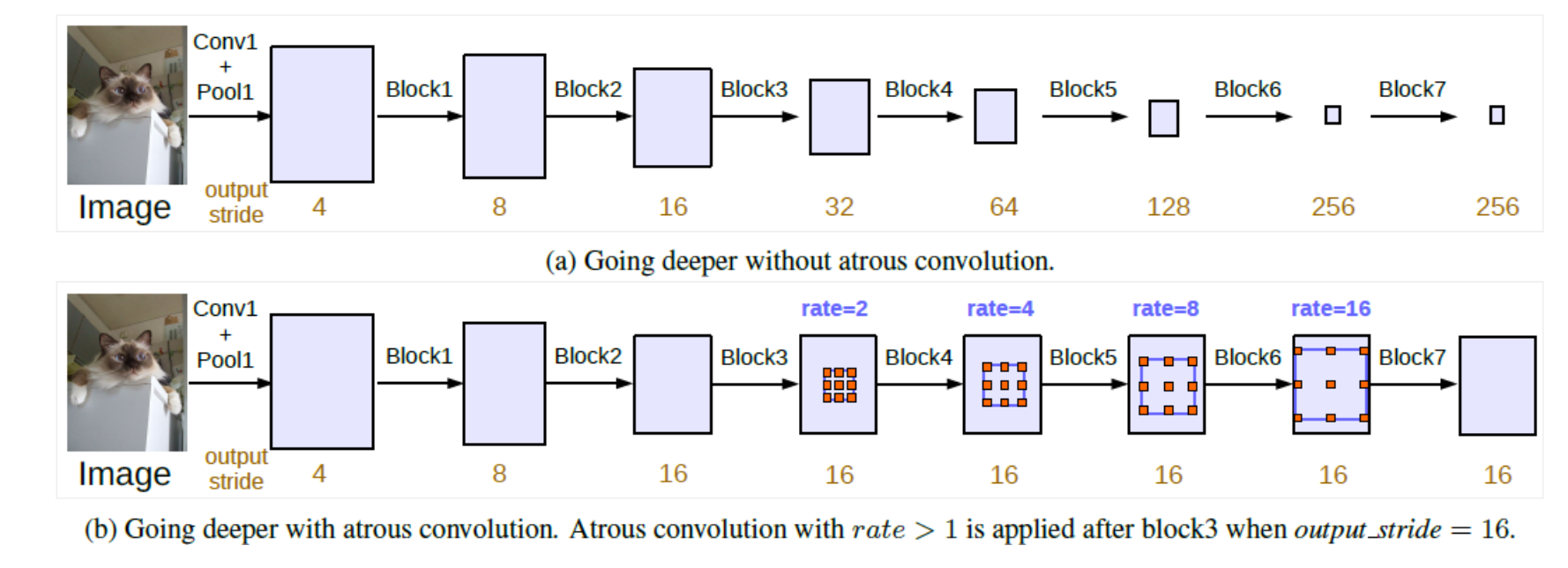
feature map的尺寸减小的同时,相当于空间信息的丢失.图像分割对空间信息很敏感,所以保持feature map的size是非常重要的,deeplab系列的设计思路也是如此,即在保留感受野的情况下,同时保持feature map的size不变
(a)是普通的不带空洞卷积的方式,(b)通过空洞卷积的方式,在保持了感受野的同时,还没有减小feature map的尺寸.
aspp
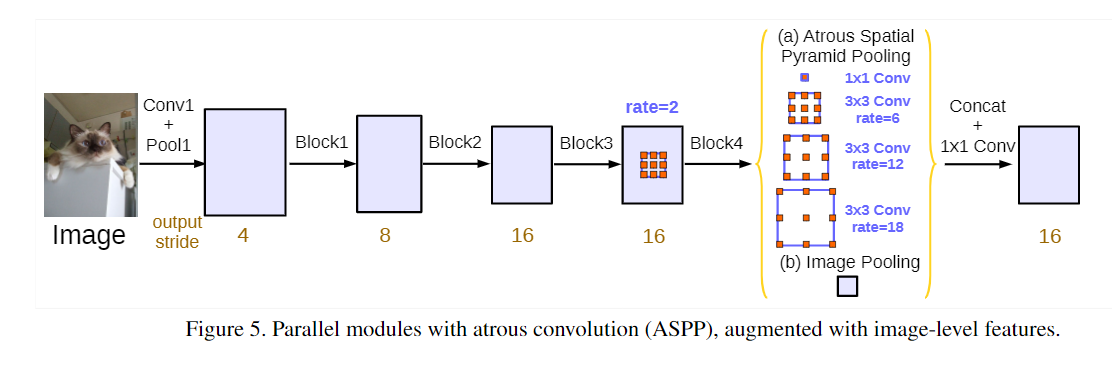
在block内部使用rate不同的空洞卷积并行地做卷积,再对得到的feature做融合.
google团队的网络风格就是这样,总是喜欢在一种卷积方式上不断演化,inception系列如此,deeplab系列也是如此.
Deeplab的更多相关文章
- 第一章 DeepLab的创作动机
这一段时间一直在做深度学习方面的研究,目前市场上的深度学习工具主要分为两大块.一块是基于Python语言的theano:另一块是可以在多个语言上使用并能够在GPU和CPU之间随意切换的Caffe.但是 ...
- deeplab hole algorithm
最近看了几篇文章,其中均用到了hole algorithm. 最早用的就是deeplab的文章了,Semantic Image Segmentation with Deep Convolutional ...
- 从FCN到DeepLab
图像语义分割,简单而言就是给定一张图片,对图片上的每一个像素点分类. 图像语义分割,从FCN把深度学习引入这个任务,一个通用的框架事:前端使用FCN全卷积网络输出粗糙的label map,后端使用CR ...
- 完整工程,deeplab v3+(tensorflow)代码全理解及其运行过程,长期更新
前提:ubuntu+tensorflow-gpu+python3.6 各种环境提前配好 1.下载工程源码 网址:https://github.com/tensorflow/models 下载时会遇到速 ...
- 论文阅读笔记十:DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs (DeepLabv2)(CVPR2016)
论文链接:https://arxiv.org/pdf/1606.00915.pdf 摘要 该文主要对基于深度学习的分割任务做了三个贡献,(1)使用空洞卷积来进行上采样来进行密集的预测任务.空洞卷积可以 ...
- Deeplab v3+中的骨干模型resnet(加入atrous)的源码解析,以及普通resnet整个结构的构建过程
加入带洞卷积的resnet结构的构建,以及普通resnet如何通过模块的组合来堆砌深层卷积网络. 第一段代码为deeplab v3+(pytorch版本)中的基本模型改进版resnet的构建过程, 第 ...
- Deeplab v3+的结构的理解,图像分割最新成果
Deeplab v3+ 结构的精髓: 1.继续使用ASPP结构, SPP 利用对多种比例(rates)和多种有效感受野的不同分辨率特征处理,来挖掘多尺度的上下文内容信息. 解编码结构逐步重构空间信息来 ...
- DeepLab 使用 Cityscapes 数据集训练模型
原文地址:DeepLab 使用 Cityscapes 数据集训练模型 0x00 操作环境 OS: Ubuntu 16.04 LTS CPU: Intel® Core™ i7-4790K GPU: Ge ...
- ubuntu——caffe配置deeplab
1. 下载deeplab 2. 安装matio sudo apt-get install libmatio-dev 3. 修改Makefile文件 LIBRARIES += glog gflags p ...
- 封装caffe版的deeplab为库供第三方使用
1.解决deeplab编译问题 http://m.2cto.com/kf/201612/579545.html
随机推荐
- Spark学习笔记(二)—— Local模式
Spark 的运行模式有 Local(也称单节点模式),Standalone(集群模式),Spark on Yarn(运行在Yarn上),Mesos以及K8s等常用模式,本文介绍第一种模式. 1.Lo ...
- 【转】线性插值(Linear Interpolation)基本原理
转:https://blog.csdn.net/u010312937/article/details/82055431 今天在阅读大牛代码的时候,发现了Linear Interpolation一次,百 ...
- ubuntu下使用APT安装和卸载MySQL5.7
安装方式一: 向系统的软件仓库中列表中添加MySQL APT 仓库 去http://dev.mysql.com/downloads/repo/apt/.下载MySQL APT repository ...
- 大白话原型模式(Prototype Pattern)
意图 原型模式是创建型设计模式,可以复制已存在的对象而无需依赖它的类. 问题 假如现在有一个对象,我们想完全复制一份新的,我们该如何做? 创建同一个类的新对象 遍历所有已存在对象的值,然后将他们的值复 ...
- Django CBV方法装饰器
from django.utils.decorators import method_decorator 1.在post 或 get方法 添加 @method_decorator(装饰器) 2.给类添 ...
- DSSA特定领域软件体系结构
一.何为DSSA 特定领域软件架构(Domain Specific Software Architecture,DSSA)是一种有效实现特定领域软件重用的手段.简单地说,DSSA就是在一个特定应用领域 ...
- maven常用的远程仓库地址
<mirror> <id>nexus-aliyun</id> <name>Nexus aliyun</name> <url>ht ...
- java面试|精选基础(1)
以下题目是从面试经历和常考面试题中选出有点儿意思的题目,参考答案如有错误,请联系小编指正,感谢! 1.反射 1.1定义 JAVA反射机制是在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法 ...
- A complex 16-Level XSS Challenge
A complex 16-Level XSS Challenge, held in summer 2014 (+1 Hidden Level) Index Level 0 Level 1 Level ...
- C语言寒假大作战02
2.2.1 寒假大作战 问题 回答 这个作业属于哪个课程 2019软件四班C语言寒假作业大作战 这个作业要求在哪里 作业要求 我在这个课程的目标是 用switch完成一个menu基本框架 这个作业在那 ...