Spark day02
- Standalone模式两种提交任务方式
- Standalone-client提交任务方式
- Standalone-client提交任务方式
- 提交命令
|
./spark-submit --master spark://node1:7077 --class org.apache.spark.examples.SparkPi ../lib/spark-examples-1.6.0-hadoop2.6.0.jar 1000 |
或者
|
./spark-submit --master spark://node1:7077 --deploy-mode client --class org.apache.spark.examples.SparkPi ../lib/spark-examples-1.6.0-hadoop2.6.0.jar 100 |
- 执行原理图解
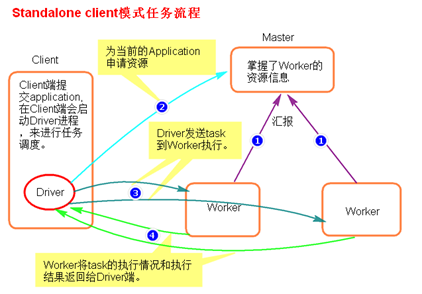
- 执行流程
- client模式提交任务后,会在客户端启动Driver进程。
- Driver会向Master申请启动Application启动的资源。
- 资源申请成功,Driver端将task发送到worker端执行。
- worker将task执行结果返回到Driver端。
- 总结
client模式适用于测试调试程序。Driver进程是在客户端启动的,这里的客户端就是指提交应用程序的当前节点。个application到集群运行,Driver每次都会在client端启动,那么就会导致客户端100次网卡流量暴增的问题。
- Standalone-cluster提交任务方式
- 提交命令
|
./spark-submit --master spark://node1:7077 --deploy-mode cluster --class org.apache.spark.examples.SparkPi ../lib/spark-examples-1.6.0-hadoop2.6.0.jar 100 |
- 执行原理图解

- 执行流程
- cluster模式提交应用程序后,会向Master请求启动Driver.
- Master接受请求,随机在集群一台节点启动Driver进程。
- Driver启动后为当前的应用程序申请资源。
- Driver端发送task到worker节点上执行。
- worker将执行情况和执行结果返回给Driver端。
- 总结
Driver进程是在集群某一台Worker上启动的,在客户端是无法查看task的执行情况的。假设要提交100个application到集群运行,每次Driver会随机在集群中某一台Worker上启动,那么这100次网卡流量暴增的问题就散布在集群上。
- 总结Standalone两种方式提交任务,Driver与集群的通信包括:
1. Driver负责应用程序资源的申请
2. 任务的分发。
3. 结果的回收。
4. 监控task执行情况。
- Yarn模式两种提交任务方式
- yarn-client提交任务方式
- yarn-client提交任务方式
- 提交命令
|
./spark-submit --master yarn --class org.apache.spark.examples.SparkPi ../lib/spark-examples-1.6.0-hadoop2.6.0.jar 100 |
或者
|
./spark-submit --master yarn–client --class org.apache.spark.examples.SparkPi ../lib/spark-examples-1.6.0-hadoop2.6.0.jar 100 |
或者
|
./spark-submit --master yarn --deploy-mode client --class org.apache.spark.examples.SparkPi ../lib/spark-examples-1.6.0-hadoop2.6.0.jar 100 |
- 执行原理图解
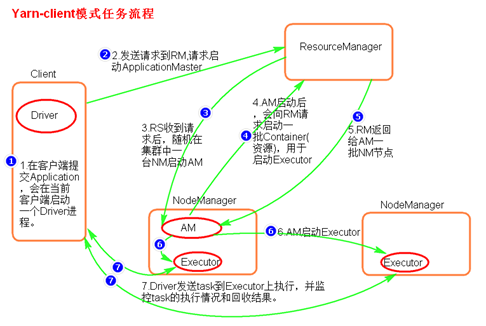
- 执行流程
- 客户端提交一个Application,在客户端启动一个Driver进程。
- 应用程序启动后会向RS(ResourceManager)发送请求,启动AM(ApplicationMaster)的资源。
- RS收到请求,随机选择一台NM(NodeManager)启动AM。这里的NM相当于Standalone中的Worker节点。
- AM启动后,会向RS请求一批container资源,用于启动Executor.
- RS会找到一批NM返回给AM,用于启动Executor。
- AM会向NM发送命令启动Executor。
- Executor启动后,会反向注册给Driver,Driver发送task到Executor,执行情况和结果返回给Driver端。
- 总结
Yarn-client模式同样是适用于测试,因为Driver运行在本地,Driver会与yarn集群中的Executor进行大量的通信,会造成客户机网卡流量的大量增加.
- ApplicationMaster的作用:
- 为当前的Application申请资源
- 给NameNode发送消息启动Executor。
注意:ApplicationMaster有launchExecutor和申请资源的功能,并没有作业调度的功能。
- yarn-cluster提交任务方式
- 提交命令
|
./spark-submit --master yarn --deploy-mode cluster --class org.apache.spark.examples.SparkPi ../lib/spark-examples-1.6.0-hadoop2.6.0.jar 100 |
或者
|
./spark-submit --master yarn-cluster --class org.apache.spark.examples.SparkPi ../lib/spark-examples-1.6.0-hadoop2.6.0.jar 100 |
- 执行原理图解
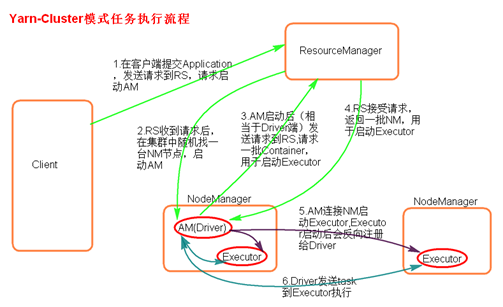
- 执行流程
- 客户机提交Application应用程序,发送请求到RS(ResourceManager),请求启动AM(ApplicationMaster)。
- RS收到请求后随机在一台NM(NodeManager)上启动AM(相当于Driver端)。
- AM启动,AM发送请求到RS,请求一批container用于启动Executor。
- RS返回一批NM节点给AM。
- AM连接到NM,发送请求到NM启动Executor。
- Executor反向注册到AM所在的节点的Driver。Driver发送task到Executor。
- 总结
Yarn-Cluster主要用于生产环境中,因为Driver运行在Yarn集群中某一台nodeManager中,每次提交任务的Driver所在的机器都是随机的,不会产生某一台机器网卡流量激增的现象,缺点是任务提交后不能看到日志。只能通过yarn查看日志。
- ApplicationMaster的作用:
- 为当前的Application申请资源
- 给NameNode发送消息启动Excutor。
- 任务调度。
- 停止集群任务命令:yarn application -kill applicationID
- 补充部分算子
transformation
- join,leftOuterJoin,rightOuterJoin,fullOuterJoin
作用在K,V格式的RDD上。根据K进行连接,对(K,V)join(K,W)返回(K,(V,W))
- join后的分区数与父RDD分区数多的那一个相同。
- union
合并两个数据集。两个数据集的类型要一致。
- 返回新的RDD的分区数是合并RDD分区数的总和。
- intersection
取两个数据集的交集
- subtract
取两个数据集的差集
- mapPartition
与map类似,遍历的单位是每个partition上的数据。
- distinct(map+reduceByKey+map)
- cogroup
当调用类型(K,V)和(K,W)的数据上时,返回一个数据集(K,(Iterable<V>,Iterable<W>))
action
- foreachPartition
遍历的数据是每个partition的数据。
- 术语解释

- 窄依赖和宽依赖
RDD之间有一系列的依赖关系,依赖关系又分为窄依赖和宽依赖。
- 窄依赖
父RDD和子RDD partition之间的关系是一对一的。或者父RDD一个partition只对应一个子RDD的partition情况下的父RDD和子RDD partition关系是多对一的。不会有shuffle的产生。
- 宽依赖
父RDD与子RDD partition之间的关系是一对多。会有shuffle的产生。
- 宽窄依赖图理解
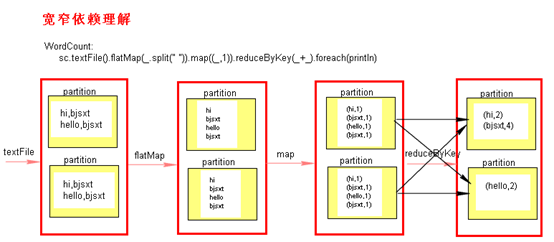
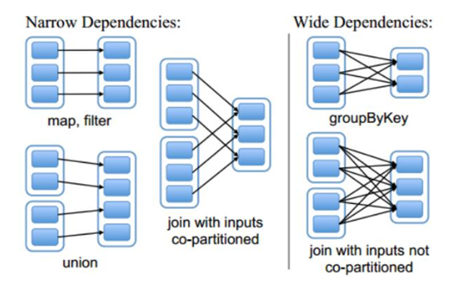
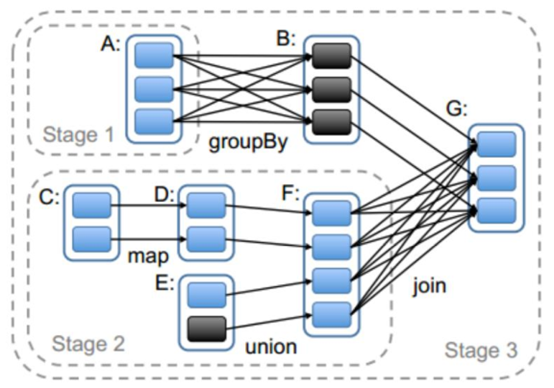
- Stage
Spark任务会根据RDD之间的依赖关系,形成一个DAG有向无环图,DAG会提交给DAGScheduler,DAGScheduler会把DAG划分相互依赖的多个stage,划分stage的依据就是RDD之间的宽窄依赖。遇到宽依赖就划分stage,每个stage包含一个或多个task任务。然后将这些task以taskSet的形式提交给TaskScheduler运行。
stage是由一组并行的task组成。
- stage切割规则
切割规则:从后往前,遇到宽依赖就切割stage。
- stage计算模式
pipeline管道计算模式,pipeline只是一种计算思想,模式。
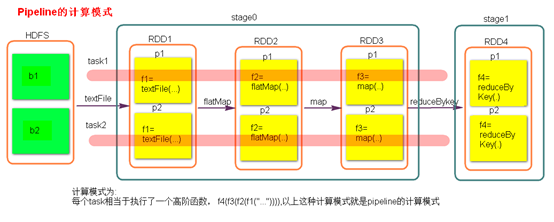
- 数据一直在管道里面什么时候数据会落地?
- 对RDD进行持久化。
- shuffle write的时候。
- Stage的task并行度是由stage的最后一个RDD的分区数来决定的 。
- 如何改变RDD的分区数?
例如:reduceByKey(XXX,3),GroupByKey(4)
- 测试验证pipeline计算模式
|
val conf.setMaster("local").setAppName("pipeline"); val val val println("map--------"+x) x }} val println("fliter********"+x) true } } rdd2.collect() sc.stop() |
- Spark资源调度和任务调度
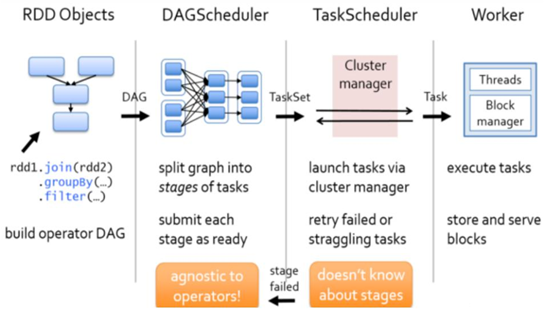
- Spark资源调度和任务调度的流程:
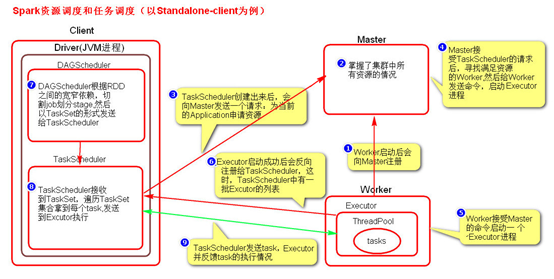
启动集群后,Worker节点会向Master节点汇报资源情况,Master掌握了集群资源情况。当Spark提交一个Application后,根据RDD之间的依赖关系将Application形成一个DAG有向无环图。任务提交后,Spark会在Driver端创建两个对象:DAGScheduler和TaskScheduler,DAGScheduler是任务调度的高层调度器,是一个对象。DAGScheduler的主要作用就是将DAG根据RDD之间的宽窄依赖关系划分为一个个的Stage,然后将这些Stage以TaskSet的形式提交给TaskScheduler(TaskScheduler是任务调度的低层调度器,这里TaskSet其实就是一个集合,里面封装的就是一个个的task任务,也就是stage中的并行度task任务),TaskSchedule会遍历TaskSet集合,拿到每个task后会将task发送到计算节点Executor中去执行(其实就是发送到Executor中的线程池ThreadPool去执行)。task在Executor线程池中的运行情况会向TaskScheduler反馈,当task执行失败时,则由TaskScheduler负责重试,将task重新发送给Executor去执行,默认重试3次。如果重试3次依然失败,那么这个task所在的stage就失败了。stage失败了则由DAGScheduler来负责重试,重新发送TaskSet到TaskSchdeuler,Stage默认重试4次。如果重试4次以后依然失败,那么这个job就失败了。job失败了,Application就失败了。
TaskScheduler不仅能重试失败的task,还会重试straggling(落后,缓慢)task(也就是执行速度比其他task慢太多的task)。如果有运行缓慢的task那么TaskScheduler会启动一个新的task来与这个运行缓慢的task执行相同的处理逻辑。两个task哪个先执行完,就以哪个task的执行结果为准。这就是Spark的推测执行机制。在Spark中推测执行默认是关闭的。推测执行可以通过spark.speculation属性来配置。
注意:
- 对于ETL类型要入数据库的业务要关闭推测执行机制,这样就不会有重复的数据入库。
- 如果遇到数据倾斜的情况,开启推测执行则有可能导致一直会有task重新启动处理相同的逻辑,任务可能一直处于处理不完的状态。
- 图解Spark资源调度和任务调度的流程
- 粗粒度资源申请和细粒度资源申请
- 粗粒度资源申请(Spark)
在Application执行之前,将所有的资源申请完毕,当资源申请成功后,才会进行任务的调度,当所有的task执行完成后,才会释放这部分资源。
优点:在Application执行之前,所有的资源都申请完毕,每一个task直接使用资源就可以了,不需要task在执行前自己去申请资源,task启动就快了,task执行快了,stage执行就快了,job就快了,application执行就快了。
缺点:直到最后一个task执行完成才会释放资源,集群的资源无法充分利用。
- 细粒度资源申请(MapReduce)
Application执行之前不需要先去申请资源,而是直接执行,让job中的每一个task在执行前自己去申请资源,task执行完成就释放资源。
优点:集群的资源可以充分利用。
缺点:task自己去申请资源,task启动变慢,Application的运行就相应的变慢了。
Spark day02的更多相关文章
- spark基于win上面的操作
自己前面的小练习一直都是在linux上面写的,可是最近由于要把他迁移到win上面,我在自己的csdn博客有对如何在win上面搭建spark环境做出说明,好了,我们还是先看看 今天的内容吧 1.假如你有 ...
- Spark学习笔记3(IDEA编写scala代码并打包上传集群运行)
Spark学习笔记3 IDEA编写scala代码并打包上传集群运行 我们在IDEA上的maven项目已经搭建完成了,现在可以写一个简单的spark代码并且打成jar包 上传至集群,来检验一下我们的sp ...
- spark 省份次数统计实例
//统计access.log文件里面IP地址对应的省份,并把结果存入到mysql package access1 import java.sql.DriverManager import org.ap ...
- spark热门电影
package movies import org.apache.spark.rdd.RDDimport org.apache.spark.{SparkConf, SparkContext} obje ...
- Spark踩坑记——Spark Streaming+Kafka
[TOC] 前言 在WeTest舆情项目中,需要对每天千万级的游戏评论信息进行词频统计,在生产者一端,我们将数据按照每天的拉取时间存入了Kafka当中,而在消费者一端,我们利用了spark strea ...
- Spark RDD 核心总结
摘要: 1.RDD的五大属性 1.1 partitions(分区) 1.2 partitioner(分区方法) 1.3 dependencies(依赖关系) 1.4 compute(获取分区迭代列表) ...
- spark处理大规模语料库统计词汇
最近迷上了spark,写一个专门处理语料库生成词库的项目拿来练练手, github地址:https://github.com/LiuRoy/spark_splitter.代码实现参考wordmaker ...
- Hive on Spark安装配置详解(都是坑啊)
个人主页:http://www.linbingdong.com 简书地址:http://www.jianshu.com/p/a7f75b868568 简介 本文主要记录如何安装配置Hive on Sp ...
- Spark踩坑记——数据库(Hbase+Mysql)
[TOC] 前言 在使用Spark Streaming的过程中对于计算产生结果的进行持久化时,我们往往需要操作数据库,去统计或者改变一些值.最近一个实时消费者处理任务,在使用spark streami ...
随机推荐
- NVIDIA驱动安装、CUDA安装、cudnn安装
1.禁用 nouveau 驱动 sudo vim /etc/modprobe.d/nvidia-installer-disable-nouveau.conf 或者 sudo vim /etc/modp ...
- SAS信用评分之逻辑回归的变量选择
SAS信用评分之逻辑回归的变量选择 关于woe的转化,这一部在之前的这篇文章:sas批量输出变量woe值中已经写了,woe也只是简单的公式转化而已,所以在这系列中就不细究了哈.这次的文章我想来讲逻辑回 ...
- java填坑记录
一.The absolute uri: [http://java.sun.com/jsp/jstl/core] cannot be resolved in either web.xml or the ...
- 百钱白鸡(for循环的练习)
<!doctype html> <html> <head> <meta charset="utf-8"> <title> ...
- PAT甲级——A1058 A+B in Hogwarts
If you are a fan of Harry Potter, you would know the world of magic has its own currency system -- a ...
- [群晖] DSM6.2用winscp通过root权限登录
http://www.nas1.cn/thread-86048-1-1.html 以前DSM6.0的时候可以通过改root密码的方式,来通过winscp来登录nas,这样可以获得最高权限可以任意修改文 ...
- 在Linux中常用的启动引导工具:grub和lilo
在Linux和WINDOWS两系统并存时就需要安装GRUB(Grand Unified Bootloader),GRUB被广泛地用于替代lilo,GRUB支持在启动时使用命令行模式,支持md5加密保护 ...
- Leetcode476.Number Complement数字的补数
给定一个正整数,输出它的补数.补数是对该数的二进制表示取反. 注意: 给定的整数保证在32位带符号整数的范围内. 你可以假定二进制数不包含前导零位. 示例 1: 输入: 5 输出: 2 解释: 5的二 ...
- Centos 设置时区
参考网址: http://jingyan.baidu.com/article/636f38bb268a82d6b84610bd.html //打开设置 tzselect //选择 )Asia → )c ...
- PHP--http_build_query--把数组化成&key=value方式