SparkStreaming个人记录
一、SparkStreaming概述
SparkStreaming是一种构建在Spark基础上的实时计算框架,它扩展了Spark处理大规模流式数据的能力,以吞吐量高和容错能力强著称。

SparkStreaming会将源数据以batch为单位来进行处理,每一批数据封装为一个DStream。即SparkStreaming处理的就是一个一个的DStream,而DStream底层就是RDD。
二、架构及原理
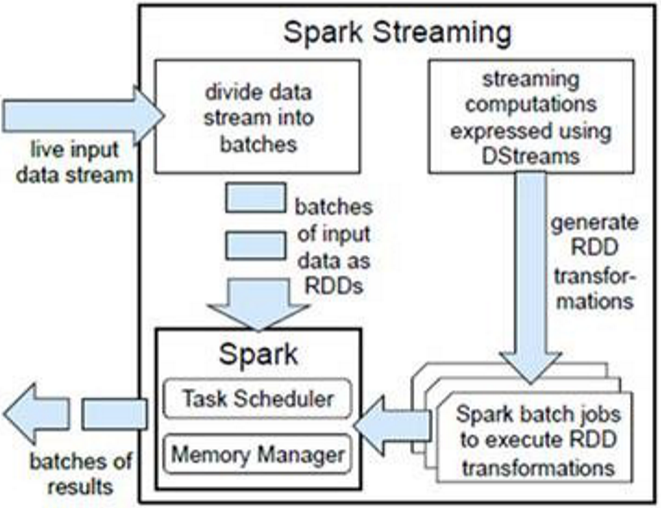
SparkStreaming是一个对实时数据流进行高通量、容错处理的流式处理系统,可以对接多种数据源(如Kafka、Flume、Twitter、ZeroMQ、TCP套接字等)进行类似的Map、Reduce和Join等复杂操作,并将结果保存到外部系统、数据库或应用到实时仪表盘。
SparkStreaming是将流式计算分解成一系列短小的批处理作业,也就是SparkStreaming的输入数据按照batch size(如1秒)分成一段一段的数据DStream(Discretized-离散化Stream),每一段数据都转换成Spark中的RDD(Resilient Distributed Dataset),然后将SparkStreaming中对DStream的Transformation操作变为针对Spark的RDD的Transformations操作,将RDD经过操作变成中间结果保存在内存中。整个流式计算根据业务需求可以对中间的结果进行叠加或存储到外部设备。
对DStream的处理,每个DStream都要按照数据流到达的先后顺序依次进行处理。即SparkStreaming天然确保了数据处理的顺序性。这样使所有的批处理具有了一个顺序的特性,其本质是转换成RDD的血缘关系。所以,SparkStreaming对数据天然具有容错性保证。
为了提高SparkStreaming的工作效率,应合理配置批的时间间隔,最好能够实现上一个批处理完某个算子,下一个批算子刚好到来。
三、SparkStreaming入门案例
以下案例代码:https://github.com/Simple-Coder/sparkstreaming-demo
1、案例一
监控指定文件夹处理其中产生的新的文件
1.1 案例代码
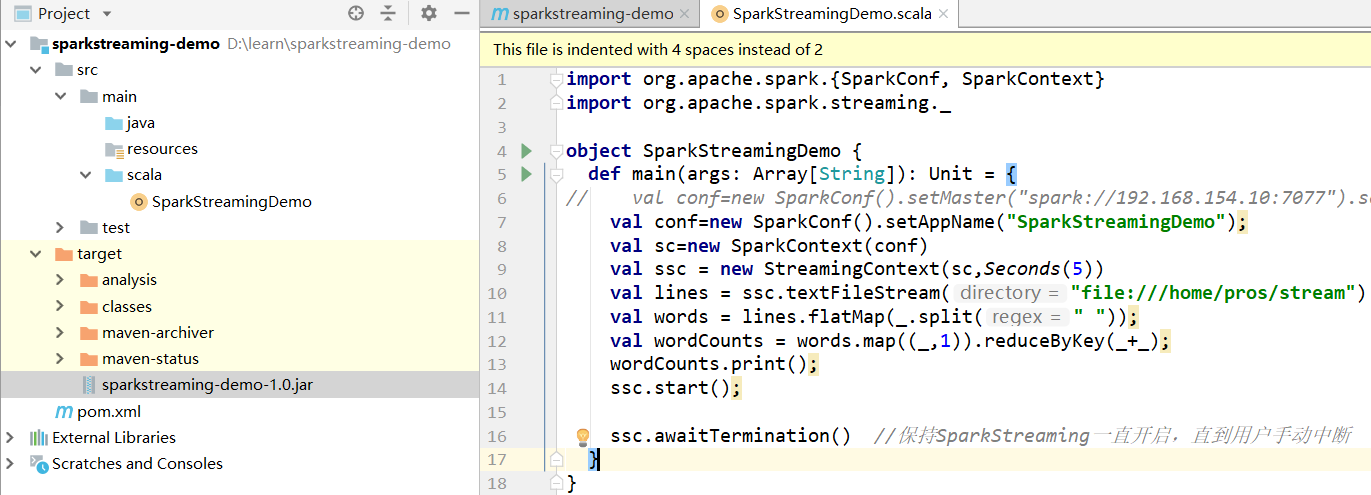
1.2 提交jar包

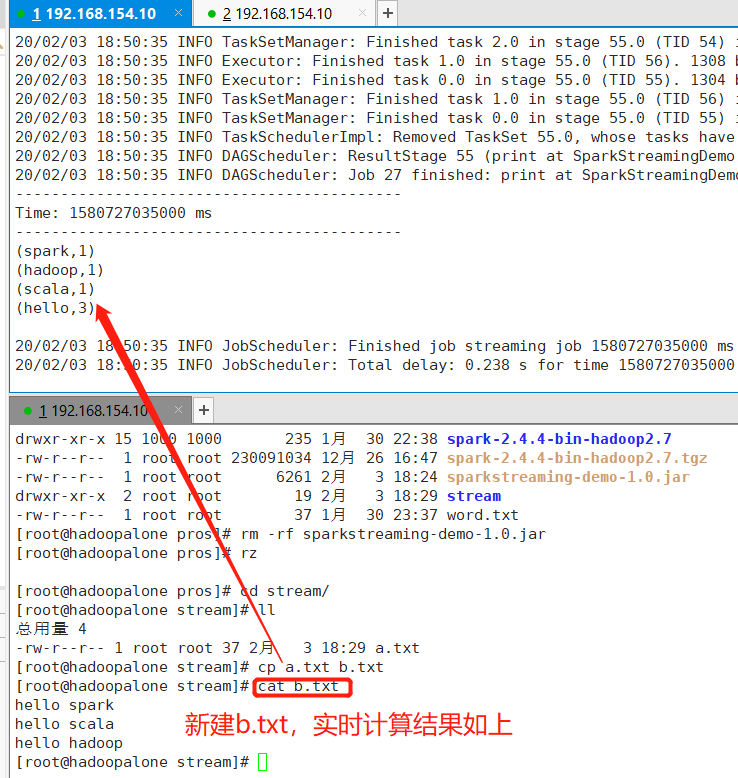
1.3 新增文件测试
2、案例二
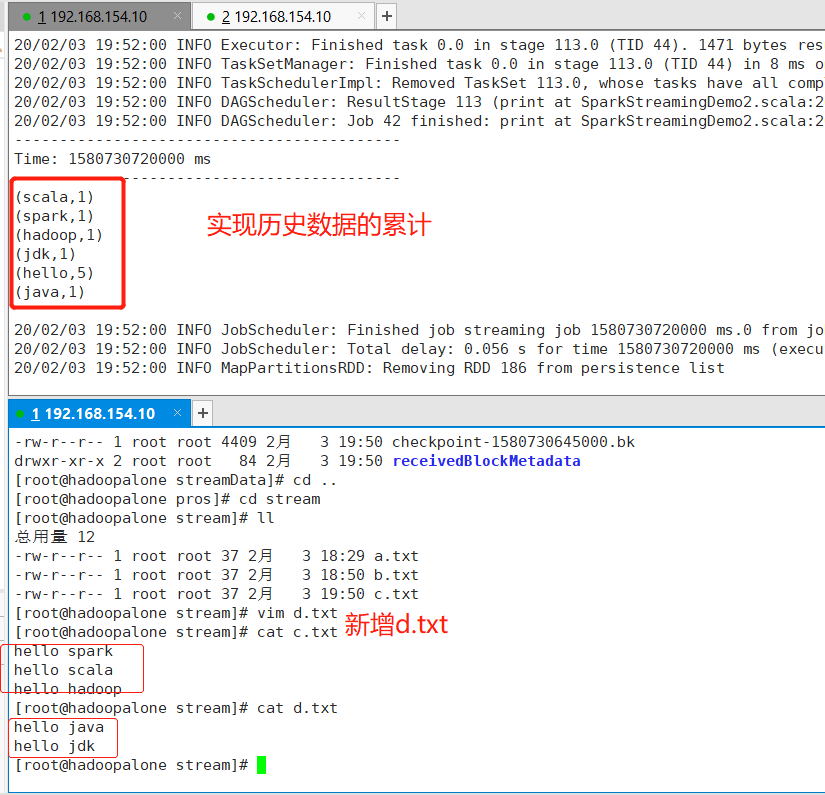
实现:SparkStreaming对历史数据的累加处理
经过测试,案例一的代码确实可以监控指定的文件夹,处理其中产生的新的文件,但是数据在每个周期到来后,都会重新进行计算,而如果需要对历史数据进行累计处理,这时就用到了Spark的CheckPoint机制,首先需要设置一个检查点目录,在这个目录,存储了历史周期数据。通过在临时文件夹中存储中间数据,为历史数据累计处理提供了可能性。
2.1 案例代码
2.2 测试结果
3、案例三
案例二的数据不停的累计下去,有些时候业务需求却是:每隔一段时间重新统计下一段时间的数据,并且能够对设置的批时间进行更细粒度的控制,这样的功能可以通过滑动窗口的方式来实现
Spark的滑动窗口机制:每隔一段时间(滑动区间)计算下一个段时间(窗口长度)的数据
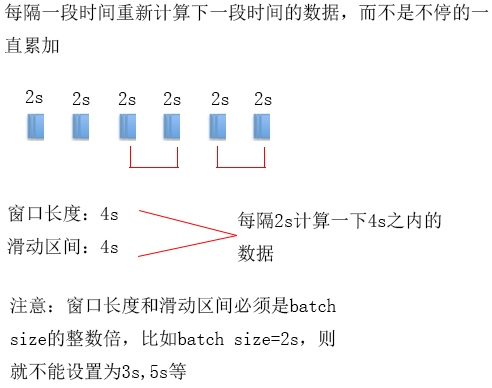
注:窗口长度和滑动区间必须是batch size的整数倍
3.1 案例代码

SparkStreaming个人记录的更多相关文章
- SparkStreaming updateStateByKey 保存记录信息
)(_+_) ) 查看是否存在,如果存在直接获取 )) ssc.checkpoint() )) //使用updateStateByKey 来更新状态 val stateDstream = wordDs ...
- 记录一下SparkStreaming中因为使用redis做数据验证而导致数据结果不对的问题
业务背景: 需要通过redis判断当前用户是否是新用户.当出现新用户后,会将该用户放入到redis中,以标明该用户已不是新用户啦. 出现问题: 发现入库时,并没有新用户入库,但我看了数据了,确实应该是 ...
- SparkStreaming 源码分析
SparkStreaming 分析 (基于1.5版本源码) SparkStreaming 介绍 SparkStreaming是一个流式批处理框架,它的核心执行引擎是Spark,适合处理实时数据与历史数 ...
- 【译】Yarn上常驻Spark-Streaming程序调优
作者从容错.性能等方面优化了长时间运行在yarn上的spark-Streaming作业 对于长时间运行的Spark Streaming作业,一旦提交到YARN群集便需要永久运行,直到有意停止.任何中断 ...
- SparkStreaming
Spark Streaming用于流式数据的处理.Spark Streaming支持的数据输入源很多,例如:Kafka.Flume.Twitter.ZeroMQ和简单的TCP套接字等等.数据输入后可以 ...
- 【SparkStreaming学习之四】 SparkStreaming+kafka管理消费offset
环境 虚拟机:VMware 10 Linux版本:CentOS-6.5-x86_64 客户端:Xshell4 FTP:Xftp4 jdk1.8 scala-2.10.4(依赖jdk1.8) spark ...
- sparkStreaming消费kafka-1.0.1方式:direct方式(存储offset到zookeeper)-- 2
参考上篇博文:https://www.cnblogs.com/niutao/p/10547718.html 同样的逻辑,不同的封装 package offsetInZookeeper /** * Cr ...
- sparkStreaming消费kafka-1.0.1方式:direct方式(存储offset到zookeeper)
版本声明: kafka:1.0.1 spark:2.1.0 注意:在使用过程中可能会出现servlet版本不兼容的问题,因此在导入maven的pom文件的时候,需要做适当的排除操作 <?xml ...
- sparkStreaming消费kafka-0.8方式:direct方式(存储offset到zookeeper)
生产中,为了保证kafka的offset的安全性,并且防止丢失数据现象,会手动维护偏移量(offset) 版本:kafka:0.8 其中需要注意的点: 1:获取zookeeper记录的分区偏移量 2: ...
随机推荐
- Linux C++ 单链表添加,删除,输出,逆序操作
/*单链表操作*/#include <iostream>using namespace std; class Node{ public: Node(){ next=0; } Node(in ...
- JAVA并发同步互斥实现方式总结
大家都知道加锁是用来在并发情况防止同一个资源被多方抢占的有效手段,加锁其实就是同步互斥(或称独占)也行,即:同一时间不论有多少并发请求,只有一个能处理,其余要么排队等待,要么放弃执行.关于锁的实现网上 ...
- cli4适配移动端
1.首先在项目中安装以下依赖 npm install px2rem-loader --savenpm install amfe-flexible --savenpm install postcss-p ...
- linux学习之编译-链接
在Windows下使用习惯了IDE,导致我们对程序的编译链接没有一个清晰的认识,甚至混淆了编辑器和编译器的概念.在学习Linux时,这些问题就暴露出来了. 实际上,我们应该严格区分一个程序从产生到执行 ...
- C#依赖注入 简体demo
class Program { static void Main(string[] args) { Dal dal = new MySql(); dal.Add(); Dal dal1 = new ...
- cobbler自动安装linux
1- cobbler简介 cobbler是一个系统启动服务boot server,可以通过pxe得方式用来快速安装.重装系统,支持安装不同linux发行版和windows. 基于python开 ...
- Spark学习之路 (三)Spark之RDD[转]
RDD的概述 什么是RDD? RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变.可分区.里面的元素可并行计算的 ...
- 梯度下降算法&线性回归算法
**机器学习的过程说白了就是让我们编写一个函数使得costfunction最小,并且此时的参数值就是最佳参数值. 定义 假设存在一个代价函数 fun:\(J\left(\theta_{0}, \the ...
- The Number of Inversions(逆序数)
For a given sequence A={a0,a1,...an−1}A={a0,a1,...an−1}, the number of pairs (i,j)(i,j) where ai> ...
- 【你不知道的javaScript 上卷 笔记5】javaScript中的this词法
function foo() { console.log( a ); } function bar() { var a = 3; foo(); } var a = 2; bar(); 上面这段代码为什 ...