小爬爬4:selenium操作
1.selenium是什么?
selenium:
- 概念:是一个基于浏览器自动化的模块。
- 和爬虫之间的关联?
- 帮我我们便捷的爬取到页面中动态加载出来的数据
- 实现模拟登陆
- 基本使用流程:
- pip install selenium
- 下载对应的驱动程序:http://chromedriver.storage.googleapis.com/index.html - 实例化一个浏览器对象(将浏览器的驱动程序加载到该对象中)
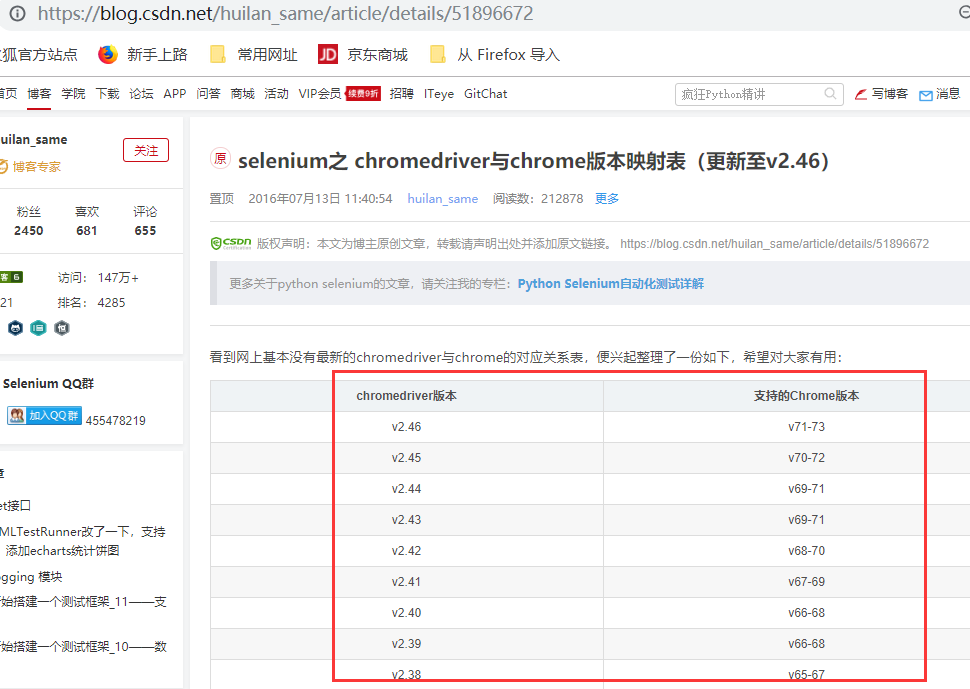
查看驱动和浏览器版本的映射关系:
- http://blog.csdn.net/huilan_same/article/details/51896672
- 无头浏览器:
- phantomJs #一般不用这个
- 谷歌无头 重头戏在这个地方 - 如何规避网站对selenium监测的风险
(1)演示程序
前戏:加载驱动程序(下载),下载之前先看一下对应关系
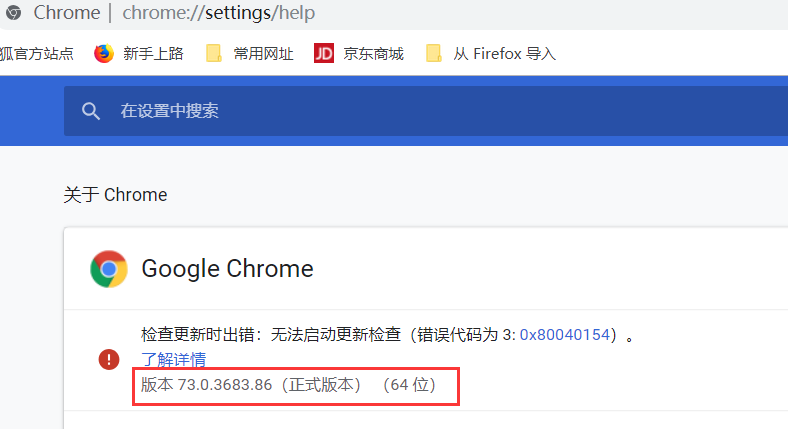
A.选择右上角的三个点

B.选择"帮助",===>3.关于google chrome得到的结果,版本是73,因此我们需要下载驱动v2.46
下载第三个

这个可能需要"蓝灯"进行安装
将下载解压后的文件,放在同级目录下边,

这个时候,我们再次运行同级目录下的文件,就可以实现一个自动化操作了
from selenium import webdriver
from time import sleep # 后面是你的浏览器驱动位置,记得前面加r'','r'是防止字符转义的
driver = webdriver.Chrome(r'./chromedriver.exe')
# 用get打开百度页面
driver.get("http://www.baidu.com")
# 查找页面的“设置”选项,并进行点击
driver.find_elements_by_link_text('设置')[].click()
sleep()
# # 打开设置后找到“搜索设置”选项,设置为每页显示50条
driver.find_elements_by_link_text('搜索设置')[].click()
sleep() # 选中每页显示50条
m = driver.find_element_by_id('nr')
sleep()
m.find_element_by_xpath('//*[@id="nr"]/option[3]').click()
m.find_element_by_xpath('.//option[3]').click()
sleep() # 点击保存设置
driver.find_elements_by_class_name("prefpanelgo")[].click()
sleep() # 处理弹出的警告页面 确定accept() 和 取消dismiss()
driver.switch_to_alert().accept()
sleep()
# 找到百度的输入框,并输入 美女
driver.find_element_by_id('kw').send_keys('美女')
sleep()
# 点击搜索按钮
driver.find_element_by_id('su').click()
sleep()
# 在打开的页面中找到“Selenium - 开源中国社区”,并打开这个页面
driver.find_elements_by_link_text('美女_百度图片')[].click()
sleep() # 关闭浏览器
driver.quit()
2.
pip install lxml
from selenium import webdriver
from lxml import etree #这个地方报红没有问题
import time
bro = webdriver.Chrome(executable_path='./chromedriver.exe') #打开一个空白页
#让浏览器对指定url发起访问
bro.get('http://125.35.6.84:81/xk/') #访问药监总局的网站 #获取浏览器当前打开页面的页面源码数据(可见即可得)
page_text = bro.page_source time.sleep()
tree = etree.HTML(page_text)
name = tree.xpath('//*[@id="gzlist"]/li[1]/dl/a/text()')[] # 获取第一个名字
print(name)
time.sleep()
bro.quit()
得到结果:爬取第一条数据
广州市科馨生物科技有限公司
3.selenium相关的行为动作制定
from selenium import webdriver
import time
bro = webdriver.Chrome(executable_path='./chromedriver.exe') bro.get('https://www.taobao.com') #()节点定位 find系列的方法,定位到标签或者节点
input_text = bro.find_element_by_id('q')
#()节点交互
input_text.send_keys('苹果')
time.sleep() #()执行js程序(js注入) #滚轮的拖动1屏幕的高度
bro.execute_script('window.scrollTo(0,document.body.scrollHeight)') #()点击搜索按钮事件
btn = bro.find_element_by_css_selector('.btn-search')
btn.click() time.sleep()
bro.quit()
4.动作链

from selenium import webdriver
#导入动作链对应的模块,具体用到再查看
from selenium.webdriver import ActionChains
import time
bro = webdriver.Chrome(executable_path='./chromedriver.exe') bro.get('https://www.runoob.com/try/try.php?filename=jqueryui-api-droppable')
#如果定位的节点是被包含在iframes节点之中的,则必须使用switch_to进行frame的切换
bro.switch_to.frame('iframeResult') #通过id进行定位
div_tag = bro.find_element_by_id('draggable') #实例化一个动作链对象(需要将浏览器对象作为参数传递给该对象的构造方法)
action = ActionChains(bro)
#单击且长按
action.click_and_hold(div_tag) for i in range():
#让div向右移动,移动偏移
action.move_by_offset(,).perform()
#perform()立即执行动作链
time.sleep(0.5) time.sleep()
bro.quit()
5.谷歌无头浏览器
from selenium import webdriver
from lxml import etree
import time from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu') bro = webdriver.Chrome(executable_path='./chromedriver.exe',chrome_options=chrome_options)
#让浏览器对指定url发起访问
bro.get('http://125.35.6.84:81/xk/') #获取浏览器当前打开页面的页面源码数据(可见即可得)
page_text = bro.page_source
time.sleep()
tree = etree.HTML(page_text)
name = tree.xpath('//*[@id="gzlist"]/li[1]/dl/a/text()')[]
print(name)
time.sleep()
bro.quit()
示例结果:
广州市科馨生物科技有限公司
6.如何规避网站对selenium检测的风险?
from selenium import webdriver
from lxml import etree
import time from selenium.webdriver import ChromeOptions
option = ChromeOptions()
option.add_experimental_option('excludeSwitches', ['enable-automation']) bro = webdriver.Chrome(executable_path='./chromedriver.exe',options=option)
#让浏览器对指定url发起访问
bro.get('http://125.35.6.84:81/xk/') #获取浏览器当前打开页面的页面源码数据(可见即可得)
page_text = bro.page_source
time.sleep()
tree = etree.HTML(page_text)
name = tree.xpath('//*[@id="gzlist"]/li[1]/dl/a/text()')[]
print(name)
time.sleep()
bro.quit()
代码启动,不要轻易再动鼠标
7.qq空间模拟登陆
# Author: studybrother sun
import requests
from selenium import webdriver
from lxml import etree
import time driver = webdriver.Chrome(executable_path='./chromedriver.exe')
driver.get('https://qzone.qq.com/')
# 在web 应用中经常会遇到frame 嵌套页面的应用,使用WebDriver 每次只能在一个页面上识别元素,对于frame 嵌套内的页面上的元素,直接定位是定位是定位不到的。这个时候就需要通过switch_to_frame()方法将当前定位的主体切换了frame 里。
driver.switch_to.frame('login_frame')
driver.find_element_by_id('switcher_plogin').click() # driver.find_element_by_id('u').clear()
driver.find_element_by_id('u').send_keys('*******') # 这里填写你的QQ号
# driver.find_element_by_id('p').clear()
driver.find_element_by_id('p').send_keys('********') # 这里填写你的QQ密码 driver.find_element_by_id('login_button').click()
time.sleep()
# driver.execute_script('window.scrollTo(0,document.body.scrollHeight)')
# time.sleep()
# driver.execute_script('window.scrollTo(0,document.body.scrollHeight)')
# time.sleep()
# driver.execute_script('window.scrollTo(0,document.body.scrollHeight)')
# time.sleep()
# page_text = driver.page_source
#
# tree = etree.HTML(page_text)
# # 执行解析操作
# li_list = tree.xpath('//ul[@id="feed_friend_list"]/li')
# for li in li_list:
# text_list = li.xpath('.//div[@class="f-info"]//text()|.//div[@class="f-info qz_info_cut"]//text()')
# text = ''.join(text_list)
# print(text + '\n\n\n') driver.close()
小爬爬4:selenium操作的更多相关文章
- selenium操作下拉滚动条的几种方法
数据采集中,经常遇到动态加载的数据,我们经常使用selenium模拟浏览器操作,需要多次下拉刷新页面才能采集到所有的数据,就此总结了几种selenium操作下拉滚动条的几种方法 我这里演示的是Java ...
- 『心善渊』Selenium3.0基础 — 19、使用Selenium操作文件的上传和下载
目录 1.Selenium实现文件上传 (1)页面中的文件上传说明 (2)文件上传示例 (3)总结 2.Selenium实现文件下载 (1)Firefox浏览器文件下载 1)操作步骤: 2)文件下载示 ...
- [Python爬虫]使用Selenium操作浏览器订购火车票
这个专题主要说的是Python在爬虫方面的应用,包括爬取和处理部分 [Python爬虫]使用Python爬取动态网页-腾讯动漫(Selenium) [Python爬虫]使用Python爬取静态网页-斗 ...
- 每次用 selenium 操作浏览器都还原了 (比如没有浏览器历史记录)
每次用 selenium 操作浏览器都还原了 (比如没有浏览器历史记录)
- 微信小程序弹出操作菜单
微信小程序弹出操作菜单 比如在页面上放一个按钮,点击按钮弹出操作菜单,那么在按钮的 bindtap 事件里,执行下面的代码即可: wx.showActionSheet({ itemList: ['A' ...
- 第三百五十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—将selenium操作谷歌浏览器集成到scrapy中
第三百五十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—将selenium操作谷歌浏览器集成到scrapy中 1.爬虫文件 dispatcher.connect()信号分发器,第一个参数信 ...
- 图解微信小程序---调用API操作步骤
图解微信小程序---调用API操作步骤 什么是API API(Application Programming Interface,应用程序编程接口:是一些预先定义的函数,目的是提供应用程序与开发人员基 ...
- Selenium操作Chrome模拟手机浏览器
目录 使用指定设备 使用自定义设备 在使用Chrome浏览网页时,我们可以使用Chrome开发者工具模拟手机浏览器,在使用Selenium操作Chrome时同样也可以模拟手机浏览器.主要有以下两种用途 ...
- ELK之开心小爬爬
1.开心小爬爬 在爬取之前需要先安装requests模块和BeautifulSoup这两个模块 ''' https://www.autohome.com.cn/all/ 爬取图片和链接 写入数据库里边 ...
随机推荐
- 【DM8168学习笔记1】帮您快速入门 TI 的 Codec Engine
http://www.ti.com.cn/general/cn/docs/gencontent.tsp?contentId=61575 德州仪器半导体技术(上海)有限公司 通用DSP 技术应用工程师 ...
- java的堆栈通俗理解
java内存模型有堆内存和栈内存, 初学者可能看官方解释很模糊 堆:new 出来的对象或者数组都存放在堆中: List <String> list =new ArrayList<St ...
- Leetcode492.Construct the Rectangle构造矩形
作为一位web开发者, 懂得怎样去规划一个页面的尺寸是很重要的. 现给定一个具体的矩形页面面积,你的任务是设计一个长度为 L 和宽度为 W 且满足以下要求的矩形的页面.要求: 1. 你设计的矩形页面必 ...
- []==![] 为什么等于true?
最近碰到这样一个问题: []==![] 为什么等于true? 首先分析 !的优先级较==高,先运算==两侧的操作数: typeof []; //"object" typeof ...
- Spring的IoC容器(转)BeanFactory
Spring的IoC容器 Spring读书笔记-----Spring的Bean之Bean的基本概念 加菲猫 Just have a little faith. Spring的IoC容器 (用户持久化类 ...
- spring四种依赖注入方式(转)
spring四种依赖注入方式!! 平常的java开发中,程序员在某个类中需要依赖其它类的方法,则通常是new一个依赖类再调用类实例的方法,这种开发存在的问题是new的类实例不好统一管理,spring提 ...
- python基础--包、logging、hashlib、openpyxl、深浅拷贝
包:它是一系列模块文件的结合体,表现形式就是一个文件夹,该文件夹内部通常会有一个__init__.py文件,包的本质还是一个模块. 首次导入包:(在导入语句中中 . 号的左边肯定是一个包(文件夹)) ...
- leetcode 350 easy
350. Intersection of Two Arrays II class Solution { public: vector<int> intersect(vector<in ...
- Hadoop 无法启动的问题
最近乱搞把本来就快要挂了的hdfs又给弄坏了.问题如下, 应该是节点没有启动. [hadoop@namenode hadoop]$ hadoop dfsadmin -report Configured ...
- Facebook iOS App如何优化启动时间
http://www.cocoachina.com/ios/20160105/14870.html 提高 Facebook 应用的性能已经成为 Facebook 持续关注的领域.因为我们相信一个高性能 ...