Mongodb集群形式探究-一主一从一仲裁。
主节点(primary)与从节点(secondary)和仲裁节点(arbiter)
具有存储数据的两个成员的三个成员副本集具有:
●一个主节点。
●一个从节点。 从节点可以在选举中成为主节点。
●一个仲裁节点 仲裁节点只在选举中投票。
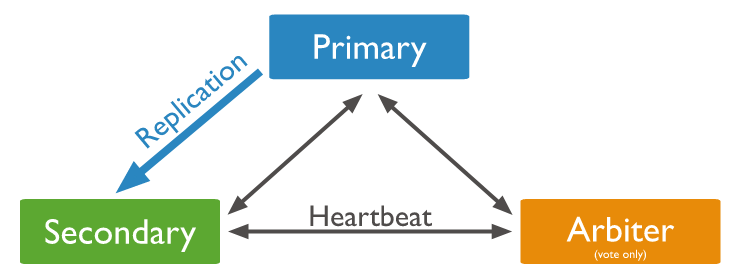
由于仲裁节点不保存数据副本,因此这种部署只提供一个完整的数据副本(secondary)。 仲裁节点需要更少的资源,牺牲更多有限的冗余和容错能力。
但是,使用主节点,从节点和仲裁及诶单的部署可确保如果主服务器或从服务器不可用,副本集仍将保持可用。
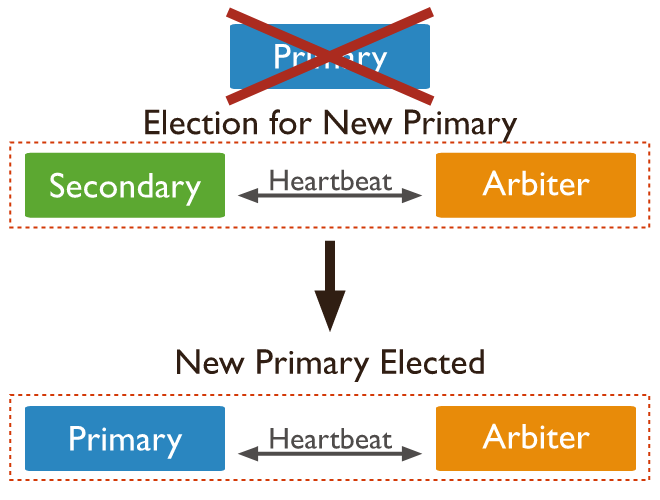
如果主服务器不可用,则副本集将选择从节点服务器为主服务器。
我是通过openstack的trove组件部署出来了一个一主两从组成的一个副本集的集群形式。
通过将其中一个从节点停掉,移出集群,然后将他变为仲裁节点的方式进行测试的,具体方法可以参照:
https://docs.mongodb.com/v3.2/tutorial/convert-secondary-into-arbiter/index.html
需要主要的是,由于trove创建的cluster开启了身份认证,所以在启动的时候需要keyfile来完成仲裁节点与主从节点之间的通信。
命令:
mongod --port 27017 --dbpath /data --replSet rs1 --config /etc/mongod.conf
rs1:SECONDARY> db.isMaster()
{
"hosts" : [
"192.168.111.173:27017",
"192.168.111.174:27017"
],
"arbiters" : [
"192.168.111.172:27017"
],
"setName" : "rs1",
"setVersion" : ,
"ismaster" : false,
"secondary" : true,
"primary" : "192.168.111.173:27017",
"me" : "192.168.111.174:27017",
"maxBsonObjectSize" : ,
"maxMessageSizeBytes" : ,
"maxWriteBatchSize" : ,
"localTime" : ISODate("2017-10-24T09:16:11.858Z"),
"maxWireVersion" : ,
"minWireVersion" : ,
"ok" :
} kill掉主节点上的mongodb进程 rs1:SECONDARY> db.isMaster()
{
"hosts" : [
"192.168.111.173:27017",
"192.168.111.174:27017"
],
"arbiters" : [
"192.168.111.172:27017"
],
"setName" : "rs1",
"setVersion" : ,
"ismaster" : true,
"secondary" : false,
"primary" : "192.168.111.174:27017",
"me" : "192.168.111.174:27017",
"electionId" : ObjectId("7fffffff0000000000000006"),
"maxBsonObjectSize" : ,
"maxMessageSizeBytes" : ,
"maxWriteBatchSize" : ,
"localTime" : ISODate("2017-10-24T09:16:49.220Z"),
"maxWireVersion" : ,
"minWireVersion" : ,
"ok" : ,
"$gleStats" : {
"lastOpTime" : Timestamp(, ),
"electionId" : ObjectId("7fffffff0000000000000006")
}
}
总结:
1.当我们只使用一主一从的方式进行部署的时候,如果主节点down机,从节点不会提升为主节点。
(1):当重启主节点的时候,会发生两种可能性。1.主节点变为从节点,从节点选举为新的主节点。2.主从节点不变(推测这是由于)
2.当在一主一从中加入一个仲裁节点后,
(1):主节点down机,从节点提升为主节点。
(2):从节点重启之后会变为当前主节点的从节点。
Mongodb集群形式探究-一主一从一仲裁。的更多相关文章
- 搭建高可用mongodb集群(一)——配置mongodb
在大数据的时代,传统的关系型数据库要能更高的服务必须要解决高并发读写.海量数据高效存储.高可扩展性和高可用性这些难题.不过就是因为这些问题Nosql诞生了. NOSQL有这些优势: 大数据量,可以通过 ...
- MongoDB集群
高可用的MongoDB集群 1.序言 MongoDB 是一个可扩展的高性能,开源,模式自由,面向文档的数据库. 它使用 C++编写.MongoDB 包含一下特点: l 面向集合的存储:适合存储 ...
- Mongodb集群【三】
Mongodb常用三种集群 1 主从(Master/Slave) 不推荐,但是mongodb依然保留有.一主多从,不支持链式结构.简单主从,没有裁仲者不能自动恢复. 2 副本集(Relica Set) ...
- 高可用的MongoDB集群
1.序言 MongoDB 是一个可扩展的高性能,开源,模式自由,面向文档的数据库. 它使用 C++编写.MongoDB 包含一下特点: l 面向集合的存储:适合存储对象及JSON形式的数据. l ...
- centos7下安装部署mongodb集群(副本集模式)
环境需求:Mongodb集群有三种模式: Replica Set, Sharding,Master-Slaver. 这里部署的是Replica Set模式. 测试环境: 这里副本集(Replica ...
- MongoDB集群运维笔记
前面的文章介绍了MongoDB副本集和分片集群的做法,下面对MongoDB集群的日常维护操作进行小总结: MongDB副本集故障转移功能得益于它的选举机制.选举机制采用了Bully算法,可以很方便从分 ...
- 【转载】高可用的MongoDB集群详解
1.序言 MongoDB 是一个可扩展的高性能,开源,模式自由,面向文档的数据库. 它使用 C++编写.MongoDB 包含一下特点: l 面向集合的存储:适合存储对象及JSON形式的数据. l ...
- 搭建高可用mongodb集群(一)——配置mongodb
在大数据的时代,传统的关系型数据库要能更高的服务必须要解决高并发读写.海量数据高效存储.高可扩展性和高可用性这些难题.不过就是因为这些问题Nosql诞生了. NOSQL有这些优势: 大数据量,可以通过 ...
- MongoDB集群跨网络、跨集群同步方案
MongoDB集群跨网络.跨集群数据同步有以下几个方案,此处只是简单介绍,不过详细描述. 1.MongoDB自带的复制方案 优点:实施简单,不需要额外的技术栈 缺点:网络双向可连通. 2.CDC同步方 ...
随机推荐
- 072、Java面向对象之定义构造方法
01.代码如下: package TIANPAN; class Book { // 定义一个新的类 public Book() { // 构造方法 System.out.println("* ...
- JAVA 集合 List 分组的两种方法
CSDN日报20170219--<程序员的沟通之痛> [技术直播]揭开人工智能神秘的面纱 程序员1月书讯 云端应用征文大赛,秀绝招,赢无人机! JAVA 集合 List 分组的两种方法 2 ...
- 修改Xshell字体大小和颜色
博客专区 > XManager的博客 > 博客详情 修改Xshell字体大小和颜色 XManager 发表于7个月前 分享到: 一键分享 QQ空间 微信 腾讯微博 新浪微博 QQ好友 有道 ...
- instance与可变参数合用,多态性
public class Doubt { public static void main(String[] args) { Dog d1=new Dog(); Dog d2=new Zangao(); ...
- 配置antMatchers(HttpMethod.GET,"/**").permitAll()当时仍然会校验
.antMatchers(HttpMethod.GET,"/**").permitAll() .anyRequest().authenticated() .and() .addFi ...
- Emergency
题意:有N个点,M条边,每个点有权值,问从起点到终点最短路的个数以及权值最大的最短路的权值. 分析:修改Dijstra模板. #include<bits/stdc++.h> using n ...
- RIOT笔记
RIOT笔记 2016-04-25 [资源] 维基 https://github.com/RIOT-OS/RIOT/wiki 代码 https://github.com/RIOT-OS/RIOT 网页 ...
- Koa原理和封装
相关文章 最基础 实现一个简单的koa2框架 实现一个简版koa koa实践及其手撸 Koa源码只有4个js文件 application.js:简单封装http.createServer()并整合co ...
- println 与 print区别
------------恢复内容开始------------ println 与 print区别: 1.print输出之后不换行,如下: public class Newstart { publ ...
- mysql合并结果集