doReleaseShared源码分析及唤醒后继节点的过程分析
文章结构
- 源码:对
doReleaseShared()方法的源码进行一些注释 - 使用场景:介绍
doReleaseShared()使用位置,及目的 - 以写锁开始的队列:分析写锁开始得同步等待队列在唤醒后续读锁节点的过程
- 以读锁开始的队列
- 总结
源码
具体解析见注释
/**
* Release action for shared mode -- signals successor and ensures
* propagation. (Note: For exclusive mode, release just amounts
* to calling unparkSuccessor of head if it needs signal.)
*/
private void doReleaseShared() {
/*
* Ensure that a release propagates, even if there are other
* in-progress acquires/releases. This proceeds in the usual
* way of trying to unparkSuccessor of head if it needs
* signal. But if it does not, status is set to PROPAGATE to
* ensure that upon release, propagation continues.
* Additionally, we must loop in case a new node is added
* while we are doing this. Also, unlike other uses of
* unparkSuccessor, we need to know if CAS to reset status
* fails, if so rechecking.
*/
for (;;) {
Node h = head;
if (h != null && h != tail) {
int ws = h.waitStatus;
if (ws == Node.SIGNAL) {
if (!compareAndSetWaitStatus(h, Node.SIGNAL, 0))
continue; // loop to recheck cases
unparkSuccessor(h);
}
//在队列中的节点对应的线程阻塞之前,将前驱节点的waitStatus状态设置为SIGNAL
//所以这块ws==0,其实是当前线程通过第一次循环将状态设置为了0,
//第二次循环进入的时候头节点还没有被改变
//cas操作失败的话会直接continue,为什么会失败,
//可能是唤醒得其他节点在唤醒后续节点的时候已经进行了修改
//修改失败则代表头节点已经修改,则进入下一次循环
else if (ws == 0 &&
!compareAndSetWaitStatus(h, 0, Node.PROPAGATE))
continue; // loop on failed CAS
}
//特别注意这个出口判断
//唤醒后继节点之后,后继节点没有更换头节点才会退出,整个后继节点可以是一个读锁,或者写锁
//在唤醒到队列尾之后头节点将不再改变,可以结束
if (h == head) // loop if head changed
break;
}
}
使用场景
doReleaseShared()的作用唤醒其后后继节点,具体的说是需要唤醒其后到下一个尝试获取锁的的节点之间的所有尝试获取
读锁的线程。
在AQS中一共有两处使用到了doReleaseShared()方法,分别是:
在
setHeadAndPropagate()中,setHeadAndPropagate()方法用于同步等待队列中获取共享锁的节点
在成功获取共享锁之后判断其是否有后继节点,以及后继节点是否是尝试获取共享锁,如果是则调用doReleaseShared()完成唤醒操作在
releaseShared()中当前线程释放完读锁后,读锁归零则调用doReleaseShared()方法唤醒后及线程
总之来说,doReleaseShared()就是用来唤醒后继节点的,但是这个方法体式一个死循环,而出口条件却不是很好理解;
//方法出口
if (h == head) // loop if head changed
break;
如何能满足这个条件呢,以读锁为例说明:
以写锁开始的队列
假设当前读锁被线程A获取,考虑获取读锁的进入队列的条件,非公平模式下队列中头结点的后继节点尝试获取写锁,则会加入到队列中;
公平模式下,队列中有等候的节点就会加入到队列中排队,但是读锁是非阻塞式获取的,当一个线程获取读锁后,
其他线程也可以获取读锁,CAS操作放在一个死循环中完成,不会被加入到队列,所以第一个放到队列中的也是一个写锁的获取线程。
若当前是写锁被获取,则统统会被加入到队列中。
假设有这样一个队列(如下图)

当写锁被获取并刚释放的瞬间,还没有唤醒读锁1,则队列变为下面的样子

此时读锁1被阻塞再doAcquireShared方法上,这时唤醒读锁1,读锁1线程获取读锁成功后会调用setHeadAndPropagate()方法
,判断出其后面还有等待的线程读锁2则调用doReleaseShared()方法。现在再来看doReleaseShared()方法,
这里分为两种情况:
在读锁1判断头节点之前,读锁2线程替换头节点成功
读锁1将自身的
waitStatus字段设置为0(compareAndSetWaitStatus(h, Node.SIGNAL, 0设置失败则循环设置),
并唤醒读锁2之后,读锁2立刻加锁成功,会将头节点设置为自身节点(thread字段置空,如下图),读锁1的h会与头节点不同
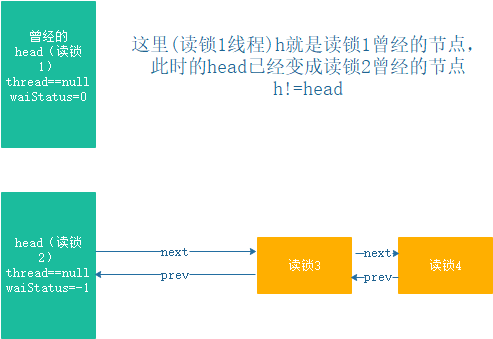
那么读锁1线程会在这个循环里不能退出,第二次循环的时候
h字段会变成曾经的读锁2线程对应的节点,
读锁2线程此时是被唤醒的,读锁2线程也会调用
setHeadAndPropagate()方法去唤醒读锁3线程。
假设是读锁2线程唤醒了读锁3,读锁3线程会将头节点设置为自身节点,而读锁1线程的h字段保存的头节点还没更改依然是
读锁线程2的情况下,CAS更改头节点的waitStatus状态操作将会失败,会进入到else if (ws == 0 && !compareAndSetWaitStatus(h, 0, Node.PROPAGATE))当中执行下一次循环,还是不能结束。由于读锁1在循环,所以有可能是读锁1唤醒了读锁3,读锁2对应的线程
CAS更改头节点的waitStatus状态操作将会失败,
会进入到else if (ws == 0 && !compareAndSetWaitStatus(h, 0, Node.PROPAGATE))当中执行下一次循环,还是不能结束。假设读锁3对应的线程由读锁2唤醒,读锁三完成了设置头节点的操作,此时读锁1刚好进行一次循环,并且没有竞争,那么读锁1可以立刻唤醒读锁4
假设队列长度足够,那么就会产生一个唤醒的风暴,前面的线程都在唤醒后面的线程,这样可以快速的唤醒起队列中下一个写锁之前的所有申请读锁的线程。
这样的风暴会在碰到一个申请写锁的线程或者一直到队列尾都没有写锁,唤醒了所有的线程之后结束,当然中间可能存在部分的线程已经停止了唤醒操作(
在判断h==head完成之前,头节点没有被替换)
碰到写锁:由于读锁已经被获取,唤醒一个写锁线程后,并不能完成加锁操作,因此头节点不会被替换,直到所有的读锁被释放,写锁才能尝试加锁
所以在这个位置将会结束这场风暴。到达队尾:到达队尾后头节点将不会变化,风暴结束
在读锁1判断头节点完成之前,读锁2线程都没有替换头节点
读锁1唤醒读锁2对应的线程,但是读锁2处于某些原因并没有立刻加锁成功,或者加锁成功但是换么有用自身节点将头节点替换,此时
if (h == head)
将被满足,从而读锁1线程退出,后面的线程依然会被唤醒,因为读锁2线程已经被唤醒,可以继续后面的唤醒操作
以读锁开始的队列
就是以写锁开始得队列得写锁执行完成后得唤醒过程,(当前锁状态中读锁被获取,且队列的头节点得后继节点不存在写锁申请,不知道那种情况读锁会入队列)
总结
doReleaseShared()方法会以一种风暴的形式唤醒后续的第一个获取写锁之前的所有获取读锁的节点,没有写锁将会唤醒整个队列
doReleaseShared源码分析及唤醒后继节点的过程分析的更多相关文章
- Universal-Image-Loader源码分析(二)——载入图片的过程分析
之前的文章,在上面建立完config之后,UIl通过ImageLoader.getInstance().init(config.build());来初始化ImageLoader对象,之后就可以用Ima ...
- 源码分析:升级版的读写锁 StampedLock
简介 StampedLock 是JDK1.8 开始提供的一种锁, 是对之前介绍的读写锁 ReentrantReadWriteLock 的功能增强.StampedLock 有三种模式:Writing(读 ...
- 死磕 java集合之ConcurrentLinkedQueue源码分析
问题 (1)ConcurrentLinkedQueue是阻塞队列吗? (2)ConcurrentLinkedQueue如何保证并发安全? (3)ConcurrentLinkedQueue能用于线程池吗 ...
- SequoiaDB 系列之七 :源码分析之catalog节点
这一篇紧接着上一篇SequoiaDB 系列之六 :源码分析之coord节点来讲 在上一篇中,分析了coord转发数据包到catalog节点(也有可能是data节点,视情况而定).这一次,我们继续分析上 ...
- SequoiaDB 系列之六 :源码分析之coord节点
好久不见. 在上一篇SequoiaDB 系列之五 :源码分析之main函数,有讲述进程开始运行时,会根据自身的角色,来初始化不同的CB(控制块,control block). 在之前的一篇Sequ ...
- Hadoop源码分析之数据节点的握手,注册,上报数据块和心跳
转自:http://www.it165.net/admin/html/201402/2382.html 在上一篇文章Hadoop源码分析之DataNode的启动与停止中分析了DataNode节点的启动 ...
- ElasticSearch6.3.2源码分析之节点连接实现
ElasticSearch6.3.2源码分析之节点连接实现 这篇文章主要分析ES节点之间如何维持连接的.在开始之前,先扯一下ES源码阅读的一些心得:在使用ES过程中碰到某个问题,想要深入了解一下,可源 ...
- 死磕以太坊源码分析之p2p节点发现
死磕以太坊源码分析之p2p节点发现 在阅读节点发现源码之前必须要理解kadmilia算法,可以参考:KAD算法详解. 节点发现概述 节点发现,使本地节点得知其他节点的信息,进而加入到p2p网络中. 以 ...
- 鸿蒙内核源码分析(索引节点篇) | 谁是文件系统最重要的概念 | 百篇博客分析OpenHarmony源码 | v64.01
百篇博客系列篇.本篇为: v64.xx 鸿蒙内核源码分析(索引节点篇) | 谁是文件系统最重要的概念 | 51.c.h.o 文件系统相关篇为: v62.xx 鸿蒙内核源码分析(文件概念篇) | 为什么 ...
随机推荐
- Docker安装各种服务
一. centos7设置固定IP 查看当前正在使用的网络情况 [root@localhost ~]# nmcli dev status 显示情况 : DEVICE TYPE STATE C ...
- 博客第一天:Typora和Markown语法初始
------------恢复内容开始------------ Markdown学习 一级标题:#+空格 二级标题:##+空格 三级标题:###+空格 四级标题:####+空格 五级标题:#####+空 ...
- sshd: no hostkeys available — exiting
在开启SSHD服务时报错.sshd re-exec requires execution with an absolute path用绝对路径启动,也报错如下:Could not load host ...
- 一分钟明白MySQL聚簇索引和非聚簇索引
MySQL的InnoDB索引数据结构是B+树,主键索引叶子节点的值存储的就是MySQL的数据行,普通索引的叶子节点的值存储的是主键值,这是了解聚簇索引和非聚簇索引的前提 什么是聚簇索引? 很简单记住一 ...
- Linux从error while loading shared libraries: libxxx.so.x 错误的常规解决思路看程序与动态库的关系
出现这类错误的原因通常是动态库无法被加载,本文介绍了常规的解决方案,适用多种情况: 创作不易,如果本文帮到了您: 如果本文帮到了您,请帮忙点个赞
- Kali:系统安装之后进行所需配置
apt设置源 由于官网的源需要墙或者想使用国内的源,可以修改source.list vi /etc/source.list 打开文件并修改为其他可用的源地址,以下可供参考 deb http://ftp ...
- 5.7.17版本mysqlbinlog实时拉取的二进制日志不完整的原因分析
问题描述: 同事使用mysqlbinlog工具的--read-from-remote-server --raw选项,从远程实例实时拉取二进制日志时,发现得到的二进制日志文件大小与远程实例上的源文件大小 ...
- JDBC05 ResultSet结果集
ResultSet结果集 -Statement执行SQL语句时返回ResultSet结果集 -ResultSet提供的检索不同类型字段的方法,常用的有: getString():获得在数据库里是var ...
- Linux 物理卷(PV)、逻辑卷(LV)、卷组(VG)管理
(一)相关概念 逻辑卷是使用逻辑卷组管理(Logic Volume Manager)创建出来的设备,如果要了解逻辑卷,那么首先需要了解逻辑卷管理中的一些概念. 物理卷(Physical Volume, ...
- leeCode刷题 1078
给出第一个词 first 和第二个词 second,考虑在某些文本 text 中可能以 "first second third" 形式出现的情况,其中 second 紧随 firs ...