存储系列之 LUN 和 LVM
一、LUN
1、LUN的由来
上一篇文章已经介绍了RAID技术的原理,那么RAID的实现呢?有两种方式,RAID软件和RAID硬件。但是因软件RAID占用主机CPU和主机内存,而且RAID功能不易实现,一般较少使用。所以一般通过硬件RAID,即RAID卡。
上上篇有提到过SCSI卡,人们一般在这个SCSI卡上增加额外的芯片实现RAID功能。这样实现了RAID功能的板卡就叫做RAID卡。当然也可以在南桥芯片上实现RAID的功能,集成在主板上,某些主板广告中所谓的“板载”RAID芯片就是这种方式。
RAID卡带有CPU、ROM、RAM、XOR等主要的芯片,同时也有自己的总线和IO接口,所以RAID卡就是一个小的计算机系统。
所以,操作系统不用做任何改动,除了RAID驱动程序外,不用安装额外的任何软件,可以直接识别已经经过RAID处理生成的虚拟磁盘。
RAID生成虚拟磁盘,包含条带化,是经过一系列运算的。虚拟盘提供给外面操作系统的文件系统仍然像物理盘,寻址仍然是LBA块。
这种虚拟盘或者逻辑盘就叫做LUN,Logic Unit Number。
2、LUN管理
LUN对上层OS操作系统而言相当于一块“物理盘”,OS在这个盘上可以进行分区和格式化。
而这些逻辑盘是如何划分的,信息是否可以保存?系统重启后,操作系统安装后,是否还存在?
RAID卡可以针对总线上的N块磁盘进行分组,RAID Group。每组可以做成自己的RAID级别,不必相同。LUN必须是同一个RG中划分出来的,不能跨RG。
每个磁盘上保留了一个区域,专门记录了逻辑盘划分信息、RAID类型以及组内其他磁盘信息,这些信息称为RAID信息。SNIA委员会为了统一各个厂家的信息格式,定义了一种叫做DDF的标准。很多公司在磁盘最末1MB的空间写入这些信息。而且即使将这些磁盘打乱顺序,或者拿到其他支持这个标准的控制器上,也照样能识别出划分好的逻辑盘所需的信息。
3、为什么要划分LUN
前面章节描述过SCSI总线可以连接16个设备(32位的SCSI可以连接32个),每个设备有一个SCSI ID号,也叫Target ID。但是对于大型磁盘阵列,可以生成几百甚至上千个虚拟磁盘,为每个虚拟磁盘分配一个Target ID是远远不够的。于是将每个Target ID下再划分更多的 LUN ID(视ID字段长度而定),即LUN是一个次级寻址ID,虚拟磁盘也就变成了Target x LUN y,所以LUN ID的作用是扩充了Target ID。
LUN是SCSI协议中的名字,后面人们把硬件层次生成的虚拟磁盘统一称为”LUN“,不管是不是在SCSI环境下。而由软件生成的虚拟磁盘,统一称为”卷“,比如各种卷管理软件、软RAID软件等所生成的虚拟磁盘。
二、LVM
LVM是 Logical Volume Manager(逻辑卷管理)的简写,它由Heinz Mauelshagen在Linux 2.4内核上实现。Microsoft叫做VM。都是基于OS层面,将OS识别到的物理磁盘(或者RAID的虚拟化的逻辑磁盘LUN)进行组合,并分配的软件。
1、基本概念
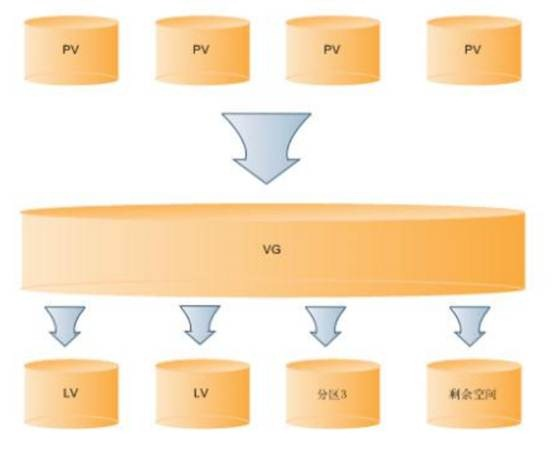
PV:Physical Volume,物理卷,操作系统识别到的物理盘或者LUN。
VG:Volume Group,卷组,多个PV可以逻辑地放在一个VG中。VG是一个虚拟的大存储空间,将多个PV首位相连,组成一个逻辑上的连续编址的存储池。
LV:Logical Volume,逻辑卷,VG经过分区生成很多个逻辑卷,最终给OS使用。
LVM将一个或多个硬盘的分区在逻辑上集合,相当于一个大硬盘来使用,当硬盘的空间不够使用的时候,可以继续将其它的硬盘的分区加入其中,这样可以实现磁盘空间的动态管理,相对于普通的磁盘分区有很大的灵活性。
如下图所示PV、VG、LV三者关系:
以上描述了LVM最主要的几个概念和分区的过程。但是还有一些相关的知识,例如OS使用的最小单位是什么,LVM又该如何寻址。所以补充几个相关的概念:
PP: Physical Partition,物理区块, 有些资料上描述为PE(physical extent),它是在逻辑上将一个VG分割成连续的小块,逻辑上的分割。LVM会记录PE的大小(由几个扇区组成),PE大小可配置,默认是4MB。每个PE具有唯一的编号,是LVM寻址的最小单元。
LP: Logical Partition,逻辑区块, 有些资料上描述为LE(logical extent),一个LE可以对应一个PE,也可以对应多个PE。前者对应前后没有区别,后者则可以对应RAID 0或RAID 1的机制。一般采用前者一一对应的关系。
2、LVM的实现
LVM实现了磁盘的逻辑管理,其实也就是磁盘的物理的信息的映射。例如PE是多少?VG有多大,从哪个PV到哪个PV?LV又是对应VG哪块区域?这些信息都将记录在磁盘上的某个区域,这个区域叫做VGDA(Volume Group Descriptor Area)。
VGDA存放在每块物理磁盘上的某块区域(一般最开头),记录LVM的配置信息,例如PE大小、初始偏移、PV的数量和信息、排列顺序、LV的数量和信息,以及PV和LV之间的映射关系。LVM初始化的时候读取这些信息,然后在缓存中生成映射公式,从而完成LV的挂载。挂载之后,就可以接受IO了。
LVM可以随时在线扩容,也可以对磁盘再划分、再组合,非常灵活。底层磁盘扩容后,(磁盘控制器)会通知LVM,LVM可以直接对某个卷进行扩容,所以LVM可以屏蔽底层的变化。收缩逻辑卷也是同样可以做到。
而旧的MBR分区方式是一种最简单的分区管理方式,分区信息保存在MBR分区表中,分区表或者说MBR位于磁盘0磁道0磁头的0号扇区上,即LBA1地址上。后续文件系统相关的章节再作详细说明。
不管是MBR还是VGDA,一旦信息丢失,整个系统数据就不能被访问。
在磁盘分区时候,会更新MBR的分区表;同样LVM做逻辑卷的时候,也会更新VGDA的数据。事实上高级的LVM,还是保留了MBR,所以MBR和VGDA会同时更新。
以前在安装Linux的时候,必须单独划分一个/boot分区,用于启动基本操作系统,一般100~200MB。目前很多新版的OS也可以不用。
3、LVM快照
LVM可以给系统创建一个快照,由于使用了写入时复制(copy-on-write) 策略,相比传统的备份更有效率。
初始的快照只有关联到实际数据的inode的实体链接(hark-link)而已。只要实际的数据没有改变,快照就只会包含指向数据的inode的指针,而非数据本身。
快照会跟踪原始卷中块的改变,一旦你更改了快照对应的文件或目录,这个时候原始卷上将要改变的数据会在改变之前拷贝到快照预留的空间。
这样的话,只要你修改的数据(包括原始的和快照的)不超过2G,你就可以只使用2G的空间对一个有35G数据的系统创建快照。
要创建快照,在卷组中必须有未被分配的空间。和其他逻辑卷一样,快照也会占用卷组中的空间。所以,如果你计划使用快照来备份你的根(root)分区,不要将整个卷组的空间都分配给根(root)逻辑卷。
(1)配置,可以像创建普通逻辑卷一样创建快照逻辑卷
# lvcreate --size 100M --snapshot --name snap01 /dev/vg0/lv
你可以修改少于100M的数据,直到该快照逻辑卷空间不足为止。
(2)恢复(合并),要将逻辑卷卷'lv' 恢复到创建快照'snap01'时的状态
# lvconvert --merge /dev/vg0/snap01
注意: 合并后快照将被删除。
也可以拍摄多个快照,每个快照都可以任意与对应的逻辑卷合并。
快照也可以被挂载,并可用dd或者tar备份。使用dd备份的快照的大小为拍摄快照后对应逻辑卷中变更过文件的大小。 要使用备份,只需创建并挂载一个快照,并将备份写入或解压到其中。再将快照合并到对应逻辑卷即可。
快照主要用于提供一个文件系统的拷贝,以用来备份; 比起直接备份分区,使用快照备份可以提供一个更符合原文件系统的镜像。
参考:
LVM 快照
而以下链接有更多的对快照进行分类和一致性问题进行分析,有兴趣的可以参考:
https://blog.csdn.net/erhei0317/article/details/52551610
通过连续几篇文档,我们从下往上介绍了磁盘、阵列和LUN、LVM以及LVM快照,存储的底层知识告一段落。再往上就是文件系统,在介绍文件系统之前,我将先介绍下存储常见的三种架构。
参考资料:《大话存储II》。
存储系列之 LUN 和 LVM的更多相关文章
- 存储系列之 从ext2到ext3、ext4 的变化与区别
引言:ext3 和 ext4 对 ext2 进行了增强,但是其核心设计并没有发生变化.所以建议先查看上上篇的<存储系列之 Linux ext2 概述 >,有了ext2的基础,看这篇就是so ...
- LUN 和 LVM 知识
LUN是对存储设备而言的,volume是对主机而言的. lun是指硬件层分出的逻辑盘,如raid卡可以将做好的400G的raid5再分成若干个逻辑盘,以便于使用,每一个逻辑盘对应一个lun号,OS层仍 ...
- 存储5——逻辑卷管理LVM
1. LVM概念 LVM是 Logical Volume Manager(逻辑卷管理)的简写,它由Heinz Mauelshagen在Linux 2.4内核上实现.LVM将一个或多个硬盘的分区在逻辑上 ...
- 存储系列之 Linux ext2 概述
引言:学习经典永不过时. 我们之前介绍过存储介质主要是磁盘,先介绍过物理的,后又介绍了虚拟的.保存在磁盘上的信息一般采用文件(file)为单位,磁盘上的文件必须是持久的,同时文件是通过操作系统管理的, ...
- 存储系列之 硬盘接口与SCSI总线协议
本文主要介绍硬盘的接口.总线和协议,SSD与SATA硬盘一般是兼容的,NVmeSSD除外. 一.磁盘控制器 上一章介绍了存储系统的主要介质硬盘,而硬盘的读写通过磁头臂,磁头臂是由磁盘驱动器来控制的.磁 ...
- 存储系列之 XFS文件系统简介
引言:磁盘容量越来越大,文件系统管理的文件也是越来越大.越来越多,如何破解?唯有快!于是动态分配.B+树开始登上舞台.还记得当年MySQL的索引结构吗,好的作品所见略同. 一.XFS为什么替换Ext4 ...
- 存储系列1-openfiler开源存储管理平台实践
(一)openfiler介绍 Openfiler能把标准x86/64架构的系统变为一个更强大的NAS.SAN存储和IP存储网关,为管理员提供一个强大的管理平台,并能应付未来的存储需求.openfile ...
- 存储系列之 RAID技术原理简介
引言:RAID技术是现代大规模存储的基础,“基础(技术)是拿来革命的”.我查raid相关资料时,查布尔运算,竟然一路查到“香农原理”,这不是有个视频中HW的任总提到的吗,多基础的东西,任总却毫不含糊, ...
- 存储系列之 DAS、SAN、NAS三种常见架构概述
随着主机.磁盘.网络等技术的发展,对于承载大量数据存储的服务器来说,服务器内置存储空间,或者说内置磁盘往往不足以满足存储需要.因此,在内置存储之外,服务器需要采用外置存储的方式扩展存储空间,今天在这里 ...
随机推荐
- Python 基础教程(第二版)笔记 (1)
P22 除非对 input 有特别的需要,否则应该尽可能使用 raw_input 函数. 长字符串,跨多行,用三个引号代替普通引号.并且不需要使用反斜线进行转义. P23 原始字符串 print r' ...
- CSS躬行记(8)——裁剪和遮罩
一. 裁剪 裁剪(clipping)能让元素显示指定形状的区域,在布局时可起点缀的作用,丰富了视觉呈现.注意,裁剪本质上只是让元素的部分区域透明,由此可知,裁剪完后元素所占的空间仍旧会保留.裁剪最早是 ...
- Linux网络管理员:网络概论
1.TCP/IP网络 包是适合通过网络传输的一小段数据,交换发生于网络的每一个链接点.当不同来源的包必须经过同一条线路传输数据时,这些包将被交替传输. 2.TCP/IP协议组 TCP/IP协议簇是In ...
- Libra教程之:Libra protocol的逻辑数据模型
文章目录 Libra protocol简介 逻辑数据模型 账本状态 交易 账本历史 Libra protocol简介 Libra区块链本质上是一个加密数据库,这个数据库是通过Libra protoco ...
- Java反射机制概念及使用
反射机制 —— 将类中的所有成员反射成对于的类. 以“com.test.Person”类为例 转换对应的类 获取方法 ...
- Vue-cli3.0下的雪碧图插件webpack-spritesmith配置方法
在前端项目中,为了减少对图片的请求次数,一般而言需要进行雪碧图的配置.即将多张小图标合并成一张图片,这样页面中的小图标都在一张图片上,只需请求一张图片,就可以通过CSS设置各个小图标的显示,利于节省带 ...
- linux之centos安装jdk以及nginx详细过程
一.安装jdk 1:首先下载jdk到本地,然后通过git 上传到linux服务器上 2:进入目录usr,并创建目录java,将jdk的压缩文件移动到该目录下 cd /usr mkdir java mv ...
- .user.ini 无法修改/删除 怎么办?
首先 了解chattr命令: Linux chattr命令用于改变文件属性. 这项指令可改变存放在ext2文件系统上的文件或目录属性,这些属性共有以下8种模式: a:让文件或目录仅供附加用途.b:不更 ...
- POJ - 2387 Til the Cows Come Home (最短路入门)
Bessie is out in the field and wants to get back to the barn to get as much sleep as possible before ...
- MySQL高级(十三)--- 表锁
前言:锁是计算机协调多个进程或线程并发访问某一资源的机制.在数据库中,除传统的计算机资源(如CPU.RAM.I/O等)的争用外,数据也是一种供许多用户共享的资源.如何保证数据并发访问的一致性.有效性是 ...