一文带你了解Redis持久化完整版本
本文讲解知识点
持久化的简介
RDB
AOF
RDB与AOF的区别
持久化应用场景
对于持久化这个功能点,其实很简单没有那么复杂
演示环境
centos7.0
redis4.0
redis存放目录:/usr/local/redis
redis.conf存放目录:/usr/local/redis/data
1. 持久化简介
redis的所有数据都是保存在内存中,redis崩掉数据会丢失。redis持久化就是把数据保存在磁盘上。利用永久性存储介质将数据进程保存,在特定的时间将保存的数据进行恢复的工作机制称为持久化。
持久化过程保存的是什么呢?
第一种快照形式,存储数据结果,关注点在数据,也就是下文会讲到的RDB
第二种操作过程,存储操作过程,存储结构复杂,关注点在数据的操作过程,也就是下文会讲到的AOF
2. RDB
2-1 RDB启动方式 -- save命令
下图是redis.conf的配置信息,在执行完save后会生成一个dump.rdb的文件
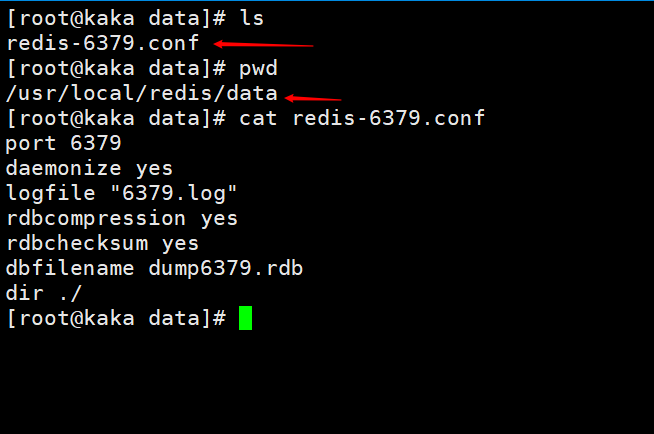
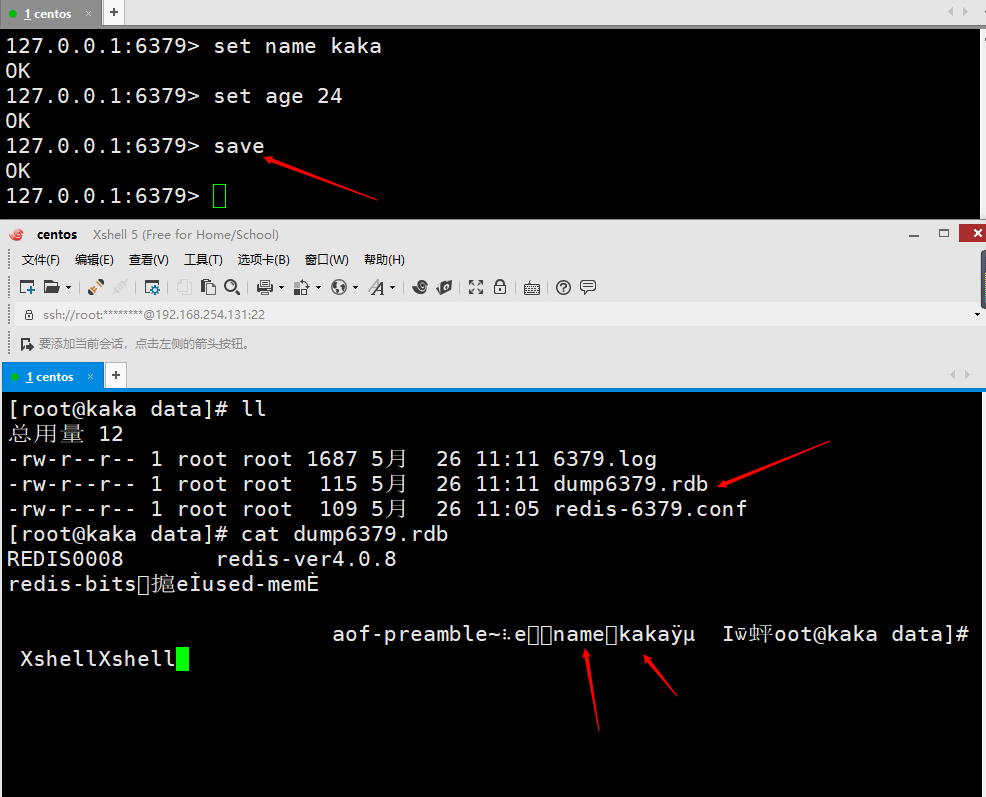
现在我们设置一个值,然后save一下,在/usr/local/redis/data下就会有一个dump6379.rdb的一个文件
2-2 RDB启动方式 -- save指令相关配置
- dbfilename dump6379.rdb :设置本地数据库文件名,默认值为dump.rdb
- dir:存储rdb文件的路径
- rdbcompression yes :设置存储至本地数据库时是否压缩数据,默认为yes,采用lzf压缩
- rdbchecksum yes:设置是否进程RDB文件格式校验,该校验过程在写文件和读文件过程均进行
2-3 RDB数据恢复
其实这个数据恢复相对于其他关系型数据库恢复基本就不用操作什么。只需要重新在启动就好了
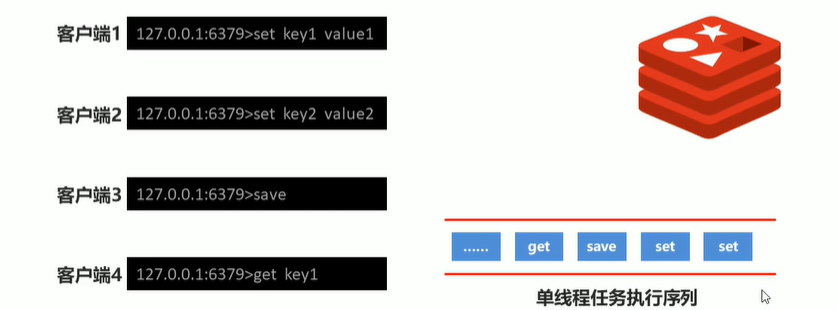
2-4 RDB -- save指令工作原理
此图来源于网络视频。
save指令的执行会阻塞当前redis服务器,直到当前RDB过程完为止,有可能会造成长时间的阻塞。这个指令在工作过程中基本以被废弃不在使用。会以bgsave全部代替
2-5 RDB -- bgsave指令工作原理
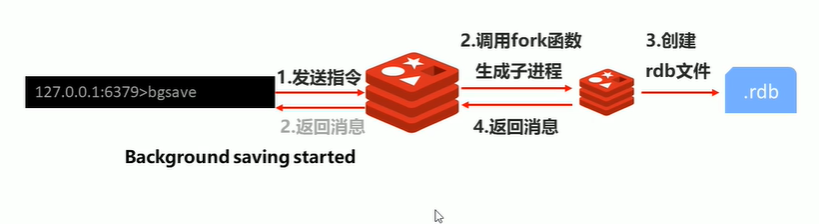
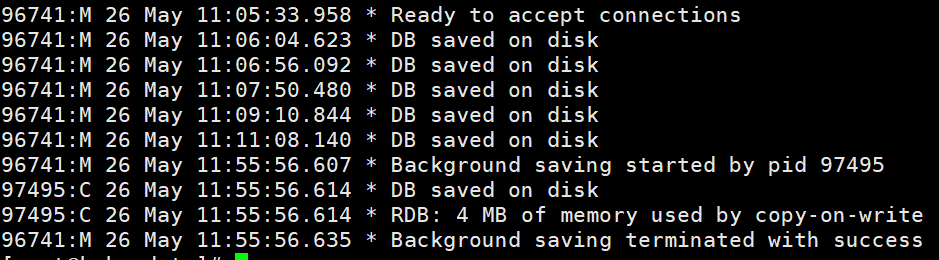
当在redis执行了bgsave后会直接返回一个Background saving started
这个时候我们在看一下日志文件,bgsave命令是针对save阻塞问题做的优化
2-5 RDB -- 配置文件自启动
save 900 1
save 300 10
save 60 10000
stop-writes-on-bgsave-error yes
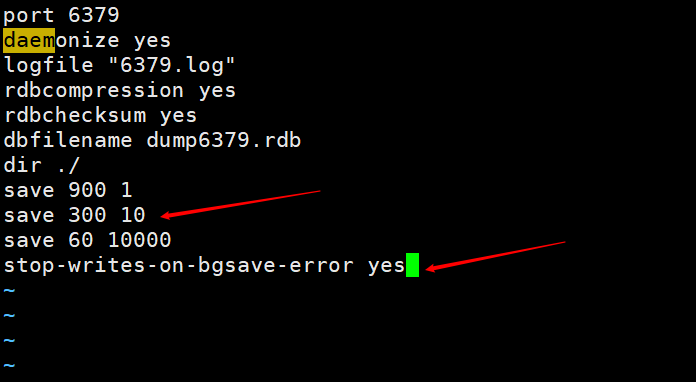
save 【时间】 【key改变数量】
也就是说在300秒有10个key值发生变化了,就会在后台执行bgsave
3. AOF
3-1 AOF概念
AOF持久化:以独立日志的方式记录每次写命令,重启时在重新执行AOF文件中命令达到数据恢复的目的。与RDB相比可以简单描述为记录数据产生的过程
AOF的主要作用是解决了数据持久化的实时性,目前已经是redis持久化的主流方式
3-2 AOF写数据过程
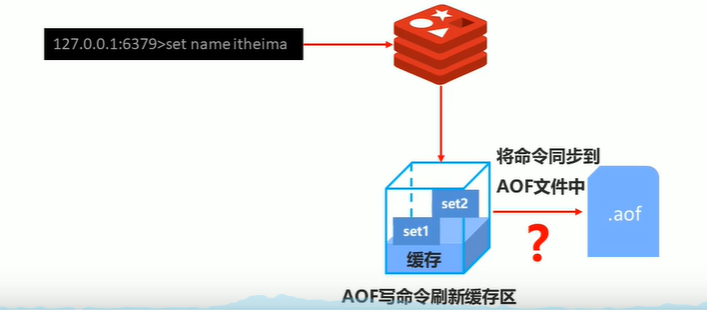
执行一条redis命令
redis的AOF会把命令刷新缓冲区
然后根据一定的策略同步的到redis.conf配置的.aof文件中
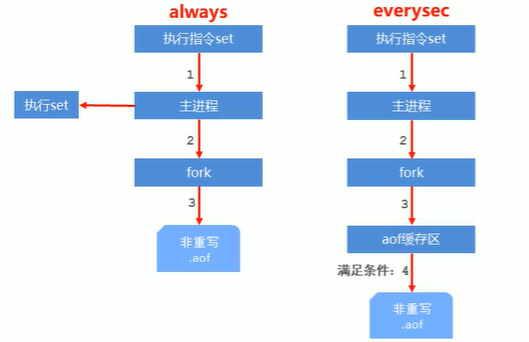
3-3 AOF写数据的三种策略
- always:每次写入操作均同步到AOF文件中,数据零误差,性能较低,不建议使用
- everysec:每秒将缓冲区中的指令同步到AOF文件中,数据准确性较高,性能较高,建议使用,也是默认配置。但是在系统突然宕机的情况下回丢失1秒内的数据
- no:由操作系统控制每次同步到AOF文件的周期,整体过程不可控
3-4 AOF功能开启
- 配置:
appendonly yes|no - 作用:是否开启AOF持久化功能,默认为不开启状态
- 配置:
appendfsync always| everysec | no - 作用:AOF写数据策略
- 配置:appenfilename filename
- 作用:AOF持久化文件名,默认名为appendonly.aof

然后使用重启redis服务,就可以在usr/local/redis/data目录下可以看到appendonly.aof文件了

然后我们在redis客户端执行一条命令,在来查看一下。可以看到数据都会存入appendonly.aof这个文件中。

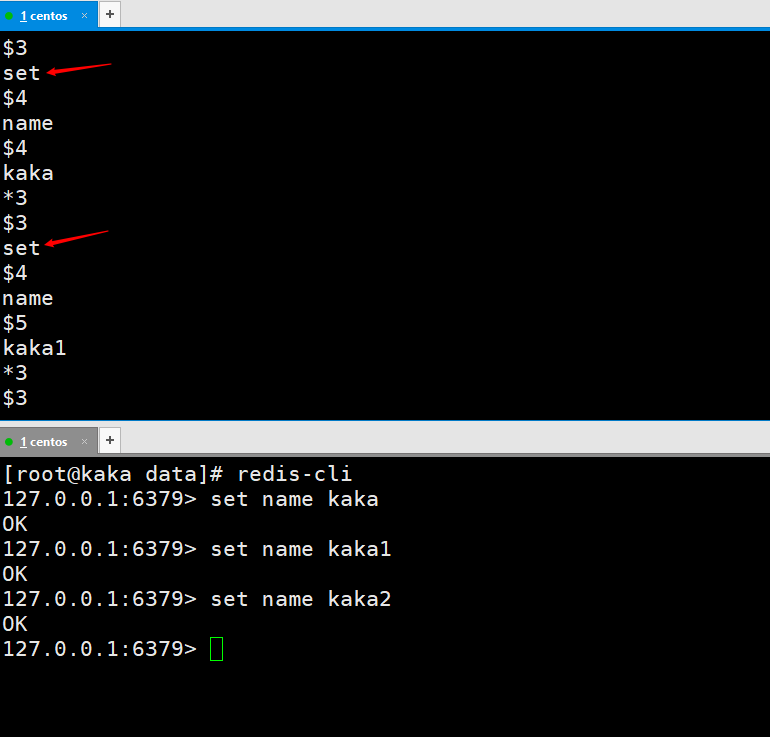
3-5 AOF写数据出现的问题
我们先看一个案例,我们重复设置了name这个key后,打开appendonly.aof文件查看,可以看到有三个操作,但是这三个操作我们都是修改的一个key啊!我们只保存最后一个key不行吗?带着这个疑问,我们在继续往下看
3-6 AOF重写
随着命令不断写入AOF,文件会越来越大,为了解决这个问题,redis引入了AOF重写机制压缩文件体积。AOF文件重写是将redis进程内的数据转化为写命令同步到新AOF文件的过程。简单说就是将对同一个数据的若干条命令执行结果转化为最终结果数据对应指令的执行记录。
如在上边我们执行了三次 set name 指令,但是我们最终就只需要最后一次执行的数据。也就是我们只需要最后一次执行记录即可。
3-7 AOF重写作用
- 降低磁盘占用量,提高磁盘利用率
- 提高持久化效率,降低持久化写时间,提高IO性能
- 降低数据恢复用时,提高数据恢复效率
3-8 AOF重写规则
- 进程内已超时的数据不再写入文件
- 忽略无效指令,重写时使用进程内数据直接生成,这样新的AOF文件值保留最终数据的写入命令。如del指令,
hdel,srem。 多次设置一个key值等 - 对同一数据的多条写入命令合并为一条命令:如
lpush list a lpush lsit b lpush list c可以转化为lpush list a b c。但是为了方式数据量过大造成客户端缓冲区溢出,对list,set,hash,zset类型每条指令最多写入64个元素
3-9 AOF手动重写
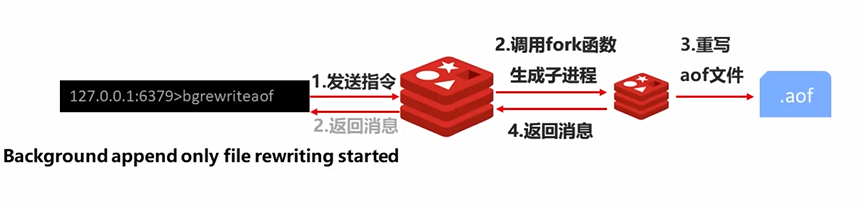
指令:bgrewriteaof
接着我们3-5的问题,我们在命令行执行bgrewriteaof指令然后查看appendonly.aof文件
当执行完后会发现文件变小了,文件里也就只有一条指令了

3-10 AOF手动重写工作原理
3-11 AOF自动重写
配置:auto-aof-rewrite-percentage 100 | auto-aof-rewrite-min-size 64mb
触发对比参数:aof_current_size | aof_base_size
当aof_current_size > auto-aof-rewrite-min-size 64mb 会启动重写
此图来源于网络

3-11 AOF工作流程和重写流=流程

4. RDB和AOF区别
- 对数据非常敏感,建议使用默认的AOF持久化方案
- AOF持久化策略使用everysecond, 每 秒 钟fsync-次•该策略redis仍可以保持很好的处理性能,当出现问题时, 最 多丢失0-1秒内的数据.
- 注意:由于AO文件存储体积较大,且恢复速度较慢
- 故据呈现阶段有效性,建议使用RDB持久化方案
- 数据可以良好的做到阶段内无丟失(该阶段理开发者成运维人手工维护的),且恢复速度较快,阶段点数据恢复通常采用RDB方案
- 注 意 : 利 用RDB实现紧促的数据持久化会使Redis降的很低
- 总和对比
- RDB与AOF的选择实际上是在做一种权衡,每种都有利有弊
- 如不能承受数分钟以内的数据丢失,对业努数据非常敏感,选用A0F
- 如能承受数分钟以内的玫据丟失,旦追求大数据集的恢复速度,选用RDB
- 灾难恢复使用RDB
- 双保险策略,同时幵启RDB和AOF, 重启后,Redis优先使用A0F来恢复数据,降低丢失数据的量
一文带你了解Redis持久化完整版本的更多相关文章
- 一文让你明白Redis持久化
网上虽然已经有很多类似的介绍了,但我还是自己总结归纳了一下,自认为内容和细节都是比较齐全的. 文章篇幅有 4k 多字,货有点干,断断续续写了好几天,希望对大家有帮助.不出意外地话,今后会陆续更新 Re ...
- 一文让你明白Redis持久化(RDB、AOF)
为什么要持久化 Redis是内存数据库,如果不将内存中的数据库状态保存到磁盘中,那么一旦服务器进程退出,服务器的数据库状态就会消失(即断电即失).为了保证数据不丢失,我们需要将 内存中的数据存储到磁盘 ...
- 一文带你了解 Redis 的发布与订阅的底层原理
01.前言 发布订阅系统在我们日常的工作中经常会使用到,这种场景大部分情况我们都是使用消息队列的,常用的消息队列有 Kafka,RocketMQ,RabbitMQ,每一种消息队列都有其特性,关于 Ka ...
- 一文让你明白Redis主从同步
今天想和大家分享有关 Redis 主从同步(也称「复制」)的内容. 我们知道,当有多台 Redis 服务器时,肯定就有一台主服务器和多台从服务器.一般来说,主服务器进行写操作,从服务器进行读操作. 那 ...
- 一文带你深入了解 Redis 的持久化方式及其原理
Redis 提供了两种持久化方式,一种是基于快照形式的 RDB,另一种是基于日志形式的 AOF,每种方式都有自己的优缺点,本文将介绍 Redis 这两种持久化方式,希望阅读本文后你对 Redis 的这 ...
- [翻译自官方]什么是RDB和AOF? 一文了解Redis持久化!
概述 本文提供Redis持久化技术说明, 建议所有Redis用户阅读. 如果您想更深入了解Redis持久性原理机制和底层持久性保证, 请参考文章 揭秘Redis持久化: http://antire ...
- 一文读懂Redis持久化
Redis 是一个开源( BSD 许可)的,内存中的数据结构存储系统,它可以用作数据库.缓存和消息中间件.它支持的数据类型很丰富,如字符串.链表.集合.以及散列等,并且还支持多种排序功能. 什么叫持久 ...
- 一文带你深入了解 redis 复制技术及主从架构
主从架构可以说是互联网必备的架构了,第一是为了保证服务的高可用,第二是为了实现读写分离,你可能熟悉我们常用的 MySQL 数据库的主从架构,对于我们 redis 来说也不意外,redis 数据库也有各 ...
- redis持久化详述
本来打算根据自己搜索的一些文章写些总结,后来发现了一篇好文,这里转载下,在自己博客里面记录下. 原文链接:https://www.cnblogs.com/kismetv/p/9137897.html ...
随机推荐
- Java 对象的继承,抽象类,接口
子父级继承 关键字 extends 首先创建一个父类 class Fu { String name; int a=1; public void word() { System.out.println( ...
- Layui 改变数据表格样式覆盖
改变表格行高.layui-table-cell{ height:40px; line-height: 36px; } 改变复选框高宽和定位等等.layui-table-view .layui-form ...
- 利用pandas进行数据子集的获取
- 基于 kubeadm 搭建高可用的kubernetes 1.18.2 (k8s)集群二 搭建高可用集群
1. 部署keepalived - apiserver高可用(任选两个master节点) 1.1 安装keepalived # 在两个主节点上安装keepalived(一主一备) $ yum inst ...
- 【Gabor】基于多尺度多方向Gabor融合+分块直方图的表情识别
Topic:表情识别Env: win10 + Pycharm2018 + Python3.6.8Date: 2019/6/23~25 by hw_Chen2018 ...
- Could not find the Qt platform plugin windows错误解决方法
在PyCharm中运行PyQt5窗口程序时,出现了下图所有的错误提示. 出现该问题的原因是环境变量没有添加. 解决方法:在环境变量中增加:QT_QPA_PLATFORM_PLUGIN_PATH 路径: ...
- abp(net core)+easyui+efcore实现仓储管理系统——出库管理之一(四十九)
abp(net core)+easyui+efcore实现仓储管理系统目录 abp(net core)+easyui+efcore实现仓储管理系统——ABP总体介绍(一) abp(net core)+ ...
- 02 . Tomcat多实例并用Nginx反代
Tomcat虚拟主机 一个应用程序在某一个端口启动运行产生了一系列的进程就是一个实例,让tomcat启动两个不同的相互独立的进程,产生两个不同的套接字,分别运行在不同的端口,让不同的端口响应不同的 ...
- PAT1033 旧键盘打字 (20分) (关于测试点4超时问题)
1033 旧键盘打字 (20分) 旧键盘上坏了几个键,于是在敲一段文字的时候,对应的字符就不会出现.现在给出应该输入的一段文字.以及坏掉的那些键,打出的结果文字会是怎样? 输入格式: 输入在 2 ...
- 【jQuery】全功能轮播图的实现(本文结尾也有javascript版)
轮播图 图片自动切换(定时器): 鼠标悬停在图片上图片不切换(清除定时器) 鼠标悬停在按钮上时显示对应的图片(鼠标悬停事件) 鼠标悬停在图片上是现实左右箭头 点击左键切换到上一张图片,但图片为第一张时 ...