pytorch入门2.2构建回归模型初体验(开始训练)
pytorch入门2.x构建回归模型系列:
pytorch入门2.0构建回归模型初体验(数据生成)
pytorch入门2.1构建回归模型初体验(模型构建)
pytorch入门2.2构建回归模型初体验(开始训练)
经过上面两个部分,我们完成了数据生成、网络结构定义,下面我们终于可以小试牛刀,训练模型了!
首先,我们先定义一些训练时要用到的参数:
EPOCH = 1000 # 就是要把数据用几遍LR = 0.1 # 优化器的学习率,类似爬山的时候应该迈多大的步子。BATCH_SIZE=50
其次,按照定义的模型类实例化一个网络:
if torch.cuda.is_available(): # 检查机器是否支持GPU计算,如果支持GPU计算,那么就用GPU啦,快!model = LinearRegression().cuda() # 这里的这个.cuda操作就是把模型放到GPU上else:model = LinearRegression() # 如果不支持,那么用cpu也可以哦# 定义损失函数,要有个函数让模型的输出知道他做的对、还是错,对到什么程度或者错到什么程度,这就是损失函数。loss_fun = nn.MSELoss() # loss function# 定义优化器,就是告诉模型,改如何优化内部的参数、还有该迈多大的步子(学习率LR)。optimizer = torch.optim.SGD(model.parameters(), lr=LR) # opimizer
下面终于可以开始训练了,但是训练之前解释一下EPOCH,比如我们有300个样本,训练的时候我们不会把300个样本放到模型里面训练一遍,就停止了。即在模型中我们每个样本不会只用一次,而是会使用多次。这300个样本到底要用多少次呢,就是EPOCH的值的意义。
for epoch in range(EPOCH):# 此处类似前面实例化模型是,我们把模型放到GPU上来跑道理是一样的。此处,我们要把变量放到GPU上,跑的快!如果不行, 那就放到CPU上吧。# 其中x是输入数据,y是训练集的groundtruth。为什么要有y呢?因为我们要知道我们算的对不对,到底有多对(这里由损失函数控制)if torch.cuda.is_available():x = Variable(x_train).cuda()y = Variable(y_train).cuda()else:x = Variable(x_train)y = Variable(y_train)# 我们把x丢进模型,得到输出y。哇,是不是好简单,这样我们就得到结果了呢?但是不要高兴的太早,我们只是把输入数据放到一个啥都不懂(参数没有训练)的模型中,得到的结果肯定不准啊。不准的结果怎么办,看下一步。out = model(x)# 拿到模型输出的结果,我们就要看看模型算的准不准,就是计算损失函数了。loss = loss_fun(out,y)# 好了好了,我已经知道模型算的准不准了,那么就该让模型自己去朝着好的方向优化了。模型,你已经是个大孩子了,应该会自己优化的。optimizer.zero_grad() # 在优化之前,我们首先要清空优化器的梯度。因为每次循环都要靠这个优化器呢,不能翻旧账,就只算这次我们怎么优化。loss.backward() # 优化开始,首先,我们要把算出来的误差、损失倒着传回去。(是你们这些模块给我算的这个值,现在这个值有错误,错了这么多,返回给你们,你们自己看看自己错哪了)optimizer.step() # 按照优化器的方式,一步一步优化吧。if (epoch+1)%100==0: # 中间每循环100次,偷偷看看结果咋样。print('Epoch[{}/{}],loss:{:.6f}'.format(epoch+1,EPOCH,loss.data.item()))
上面我们训练了1000(EPOCH=1000)次,应该差不多了。是时候看看训练的咋样啦!其实我们已经知道训练的咋样了,就是上面输出的损失值,只不过是在训练集上的。
下面我们就要看看在测试集上表现咋样呢?
model.eval() # 开启模型的测试模式# 拿到测试集中x的值,放到GPU上if torch.cuda.is_available():x = x_test.cuda()#通过把x的值输入模型,得到预测结果predict = model(x)# 那预测结果的值取出来,因为预测结果是封装好的,现在h只要它的值。predict = predict.cpu().data.numpy()#画个图看看,到底拟合成啥样了?plt.plot(x.cpu().numpy(),y_test.cpu().numpy(),'ro',label='original data')plt.plot(sorted(x.cpu().numpy()),sorted(predict),label='fitting line')plt.show()
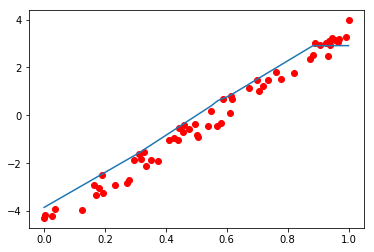
看看图,结果还凑合吧,要想结果更好需要进一步对模型的结构、超参数进行设置,我们之后在学。
到此为止,我们用pytorch就已经建立完,并且训练完一个线性回归模型了,我们可以回顾下,多看几遍,仔细回想一下这里面到底发生了什么。
pytorch入门2.2构建回归模型初体验(开始训练)的更多相关文章
- pytorch入门2.0构建回归模型初体验(数据生成)
pytorch入门2.x构建回归模型系列: pytorch入门2.0构建回归模型初体验(数据生成) pytorch入门2.1构建回归模型初体验(模型构建) pytorch入门2.2构建回归模型初体验( ...
- pytorch入门2.1构建回归模型初体验(模型构建)
pytorch入门2.x构建回归模型系列: pytorch入门2.0构建回归模型初体验(数据生成) pytorch入门2.1构建回归模型初体验(模型构建) pytorch入门2.2构建回归模型初体验( ...
- 2,turicreate入门 - 一个简单的回归模型
turicreate入门系列文章目录 1,turicreate入门 - jupyter & turicreate安装 2,turicreate入门 - 一个简单的回归模型 3,turicrea ...
- cucumber java从入门到精通(1)初体验
cucumber java从入门到精通(1)初体验 cucumber在ruby环境下表现让人惊叹,作为BDD框架的先驱,cucumber后来被移植到了多平台,有cucumber-js以及我们今天要介绍 ...
- python--爬虫入门(七)urllib库初体验以及中文编码问题的探讨
python系列均基于python3.4环境 ---------@_@? --------------------------------------------------------------- ...
- 【小白学PyTorch】18 TF2构建自定义模型
[机器学习炼丹术]的炼丹总群已经快满了,要加入的快联系炼丹兄WX:cyx645016617 参考目录: 目录 1 创建自定义网络层 2 创建一个完整的CNN 2.1 keras.Model vs ke ...
- 3,turicreate入门 - 优化回归模型,使得预测更准确
turicreate入门系列文章目录 1,turicreate入门 - jupyter & turicreate安装 2,turicreate入门 - 一个简单的回归模型 3,turicrea ...
- 吴裕雄 python 神经网络——TensorFlow实现回归模型训练预测MNIST手写数据集
import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data mnist = input_dat ...
- weka实际操作--构建分类、回归模型
weka提供了几种处理数据的方式,其中分类和回归是平时用到最多的,也是非常容易理解的,分类就是在已有的数据基础上学习出一个分类函数或者构造出一个分类模型.这个函数或模型能够把数据集中地映射到某个给定的 ...
随机推荐
- 「雕爷学编程」Arduino动手做(26)——4X4矩阵键盘模块
37款传感器与模块的提法,在网络上广泛流传,其实Arduino能够兼容的传感器模块肯定是不止37种的.鉴于本人手头积累了一些传感器和模块,依照实践出真知(一定要动手做)的理念,以学习和交流为目的,这里 ...
- Puppeteer笔记(一):Puppeteer简介
一.Puppeteer简介 Puppeteer是NPM库,它提供了NodeJS高级API来控制Chrome.Puppeteer 默认以无头(无界面)方式运行,但也可以配置为运行有界面的Chrome. ...
- P2444 [POI2000]病毒 AC自动机
P2444 [POI2000]病毒 #include <bits/stdc++.h> using namespace std; ; struct Aho_Corasock_Automato ...
- Js运算符和逻辑结构
1.运算符 (1)赋值运算符 = += -= *= /= %= (2)三目运算符 一目 一个运算符连接一个数据 -- ++ ! 二目 一个运算符连接两个数据 + - * / ...
- 利用logrotate将mysql log截断
https://blog.pythian.com/mysql-log-rotation/ 1.授权用户 CREATE USER 'log_rotate'@'localhost' IDENTIFIED ...
- 使用脚手架 vue-cli 4.0以上版本创建vue项目
1. 什么是 Vue CLI 如果你只是简单写几个Vue的Demo程序, 那么你不需要Vue CLI:如果你在开发大型项目, 那么你需要, 并且必然需要使用Vue CLI. 使用Vue.js开发大型应 ...
- CF894C Marco and GCD Sequence
题目链接:http://codeforces.com/contest/894/problem/C 题目大意: 按照严格递增的顺序给出 \(m\) 个数作为公因数集,请你构造出一个数列,对于数列中的任意 ...
- Java——关键字instanceof
instanceof 判断一个对象是否为一个类的实例,是为true ,否为false class Animal{} class Cat extends Animal{} /**instanceof 判 ...
- Java IO(十一) DataInputStream 和 DataOutputStream
Java IO(十一) DataInputStream 和 DataOutputStream 一.介绍 DataInputStream 和 DataOutputStream 是数据字节流,分别继承自 ...
- Python数据科学利器
每个工具都带有用来创造它的那种精神. -- 海森堡<物理学和哲学> Anaconda Anaconda是一个python的科学计算发行版,其附带了一大批常用的数据科学包,不用再使用pip安 ...