龙书相关知识点总结
//*************************引论***********************************//
1. 编译器(compiler):从一中语言(源程序)等级的翻译成另外一种语言(目标语言)编写的程序过程。如果目标语言是可执行的机器语言,那么它就可以被用户调用,处理输入并产生输出。
2. 解释器(interpreter):一般可以认为是编译器过程的前半部分,其不生成目标语言。
3. 常见的语言处理系统流程图:
上面是宏观的解释编译器,微观来说编译器属于整个“编译过程”的中间一个环节
过程:
源程序→(预处理器)→经过预处理的源程序→(编译器)→目标汇编程序→(汇编器)→可重定位机器代码→(连接器/加载器)→目标机器代码
3.1 预处理(preprocessor):负责把那些成为宏的缩写形式转换为源语言的语句。
3.2 宏(mirco):编译好的一些指令集合或者程序集合。
3.3 汇编器(assembler):把远程汇编成伪代码或者机器代码的工作。
3.4 重定位:把程序的逻辑地址空间转换为内存中实际物理空间的过程,也就是在装入时对目标程序中的指令和数据进行修改的过程。
3.5 链接器(linker):可重定位的机器代码有必要和其他可重定位的目标文件以及库文件链接到一起,形成真正的机器上运行的代码。一个文件中的代码可能指向另一个文件中的位置,而链接器就是可重定位的操作方式。(到这一步才是真正实现语言对于机器语言的转换,形成一个exe或者其他的可执行文件)
3.6 加载器(loader):把所有的可执行目标文件放到内存中执行。
4. 编译器逻辑结构:
把编译器看做一个黑箱的话,接收到经过预处理的源程序后,会经过如下步骤,生成目标汇编程序(也叫目标及其语言),扔给编译器:
(符号表(symbol table))
字符流→(词法分析器)→符号流→(语法分析器)→语法树→(语义分析器)→语法树→(中间代码生成器)→中间表示形式→(机器无关代码优化器)→中间表示形式→(代码生成器)→目标机器语言→(机器相关代码优化器)→目标机器语言
其中红色部分叫做前端(front end),蓝色表示部分也叫后端(back end);这两部分也分为分析和综合。是通过中间代码进行分割的。
5. 符号表(symbol table)的简单说明:
编译器的第一个步骤词法分析或者叫扫描,把他们组织成有意义的词素(lexeme),其实符号表就是类似于一种“火星文”或者载体的形式,把字符流拆分成一个一个的词法单元(token,有的教材叫做记号或者符号),作为输出到下面,组织完成后字符流就变成符号流了。
符号表一般有如下这么样的定义:
<token-name,attribute-value>
<标识符(identifier),标识符属性>
教材例子:
position = initial + rate * 60
通过用符号表中的词法单元表示如下,生成一串符号流:
<id,1><=><id,2><+><id,3><*><60>,每一个尖括号里面的都是一个词素(lexeme),id叫做标识符,有时候数字本身就是标识符,或者记号。
6. 面向对象的主要思想:数据抽象和特性的继承、模块化
7. 并行(parallelism)和内存层次结构(memory hierarchy)
并行:CPU
内存层次结构:cache缓存
8. RISC和CISC
精简指令集计算机和复杂指令集计算机,现在的intel大多是复杂指令集计算机,但是发热大,功耗高。x86机器。
9. SQL
structured Query Language,结构化查询语言
10. 环境和状态
环境:一个名字到存储位置的映射。因为变量就是指内存位置,我们还可以换一种方法,把环境定义为从名字到变量的映射。
状态:是内存位置到他们的映射
C语言中环境是左值,状态是右值
11. 静态作用域和块结构
块:最直观的在C中就是用{ }来界定,作用域:变量在那个区域起作用。
12. 声明和定义
声明一般指规定变量类型,定义一般是变量的赋值过程。
13. 动态作用域和静态作用域的类比
虽然可以有各种各样的动态或者静态作用域的策略,在通常的(块结构的)静态作用域规则和通常的动态策略之间有一个有趣的关系。从某种意义上来说,动态规则处理时间的方法类似于静态作用域处理空间的方法。静态规则让我们寻找声明位与最内层、包含变量使用位置的单元(块)中;而动态规则扔我们寻找声明位于最内层的、包含了变量使用时间的单元(过程调用)中。
位置和时间
空间和过程
14. 值调用和引用调用
值调用(call-by-value):对实参求值(如果它是表达式)或拷贝(如果它是变量)
引用调用(call-by-Reference):实参的地址作为相应形参的值被传递给调用者。
这就像在高级语言中,引用调用,在使用函数的时候,把实参的地址发送给函数的形参,形参拿到实参的地址去调用相关的表达式或者变量。
15. 别名
这个问题最常见的是在浅拷贝和深拷贝的上面。两个形式参数会指向同一个对象,造成一个变量的修改改变了另一个变量的值。另外,在声明变量的时候,切记尽量不要重名。(在某些特性环境也是可以的)
16. 正则式是一种算法
//*************************一个简单的语法制导翻译器***********************************//
1. 前端解惑:词法分析、语法分析、语义分析等:
1.1 这些分析的步骤就是把某些高级语言一步一步的纳入到一个语言规范的逻辑体系中,这个体系也叫语言的语法分析,编译也叫翻译,跟现实中的翻译的过程是一样的,机器(或者说硬件CPU,内存等)就是听众,源程序(比如C语言、java等)就是演说者,编译就是那个翻译官,正如现实语言,比如英语,也有自己的单词,语法,语义等,这个过程其实就是一种抽象的翻译过程,但是机器有不同于人类,不具备逻辑思考的能力,但且只能想安装摆放好的螺丝和螺母,给他对应好的插槽他会挨个进行组合,编译器的这个翻译官就是摆放螺母的工人,等待着机器(螺丝)来插入。
1.2 一般编译的的前端都要涉及词法分析、语法分析、语义分析这三个阶段,有的时候这三个阶段是组合到一起的相互作用。
阶段一:词法分析(lexical analysis 或者 scanning)和词法分析程序(lexical analyzer 或 scanner)
为什么用scanning,因为这些分解语言的过程是暂存于内存当中,一次一次的扫描内存内容。词法分析是编译的第一个阶段。这个阶段的任务是从左到右一个字符一个字符的读入源程序(当然现在大多数时候,前面还有一个预处理宏的阶段),即对构成源程序的字符流进行扫描然后根据构词规则识别单词(也称为单词符号或者符号,token)。词法分析程序实现这个任务。词法分析程序可以使用lex等工具自动生成。***这个阶段的工作就是拆机器***
阶段二:语法分析(syntax analysis或者parsing)和语法分析程序(parser)
为什么用parsing,因为这个时候就开始组合插件了。语法分析是编译过程的一个逻辑阶段,所谓逻辑阶段也就是说这个阶段比较复杂。语法分析的任务是在词法分析的基础上将单词序列组合成各类语法短语,如“程序”“语句”“表达式”等等。语法分析程序判断源程序在结构上是否正确,源程序的结构是由上下文无关文法描述,这个时候就出现了想“分析树”等这类逻辑图或者说分析图的东西来阐述和描述这个语法,最终形成一条一条的短语或者块,这里的语言形式和之前的就不一样了,但是还没完成,因此这个阶段叫做“中间过程”。
***这个阶段的工作就是简单再组合***
阶段三:语义分析(semantics analysis)
语义分析是编译的一个逻辑阶段,语义分析的任务是对结构上正确的源程序进行上线文有关性质的深层,进行类型审查。语义分析将审查类型并报告错误:不能再表达式中使用一个数组变量,赋值语句的右端和左端的类型不匹配。
1.3 词法分析的编码:
词法分析生成符号流,源程序被切分成一段一段的表示,这种表示其实是写到内存当中的,对应每一个词素或者符号,有的语言根据ASCII码进行编码写到内存当中,有的用Unicode编码写到内存当中,然后一遍一遍的扫描。C是ASCII , JAVA是Unicode。如果没有形成最终的机器代码让CPU去执行,前面的过程就很像拿着笔写东西写在纸上,这张纸就是“内存”,笔就像这些转换语言的魔法笔,不断转换写在纸上,然后不合适再擦去重新写,直到满意了,扔给CPU去计算去。
2. 文法(Grammars也叫语法)
文法是用于描述语言语法结构的形式。
文法也叫语法分析由著名语言学家Noam Chomsky定义了四类文法和四种形式语言类。
2.1 知道文法定义前的几个概念:
*** “→”:这个箭头表示或者可读作“可具有如下形式”
*** “产生式(production)”:箭头左边的表达式或者关键字等,可以产生或者具有右边的形式,这样一个过程叫做产生式或者叫这种形式规则。比如stmt→if(expr) stmt else stmt。这就是说明,语句(stmt)可以有if......的形式,这个规则过程叫产生式,也叫推导式。
*** 终结符号(terminal):像关键字if和括号这样的词法元素叫做终结符号。
*** 非终结符号(nonterminal):像expr和stmt这样的叫非终结符号。
*** 问题1:像expr,stmt生成的这样的字符流的字符,都是哪里来的?
回答1:这就是在符合表当中,规定好的,并表示这个代表什么意思,并有的后面跟上具有什么属性。
*** 问题2:什么是终结符号和非终结符号
回答2:为什么文法当中会经常出现终结符号和非终结符号。先看龙书上面的一个解释:
“词法单元和终结符号”
在编译器中,词法分析器读入源程序中的字符序列,将他们组织为具有词法含义的词素,并生成并输入代码这些词素的词法单元序列。词法单元有两部分组成(这个上面说过<token-name, attribute-value>)名字和属性值。词法单元的名字是词法分析器进行语法分析时使用的抽象符号。我们常常把这些词法单元名字成为终结符号,因为它们描述程序设计语言的文法中是以终结符号的形式出现的。如果词法单元具有属性值,那么这个值就是一个指向符号表的指针,符号表中包含了该次非单元的附加信息。这些附加信息不是文法组成的,因此我们在讨论文法分析时,通常将此房单元和终结符号当做同义词。
*** 词法单元其实就是等于终结符号
*** 非终结符号和终结符号通俗来说:终结符号不能出现在产生式(推导式),而非终结符号可以出现做左边,非终结符号可以理解为可再拆分的词素,而终结符号是不可拆分的最小词素。
2.2 一个上下文无关文法(context-free grammar)的四元素:
上下文无关文法是在语法分析阶段用的语法(文法语法一个意思,后面用语法吧),有四元素组成:
元素1:一个终结符号集合,终结符号是该语法所定义的语言的基本符号的集合。
元素2:一个非终结符号集合,它们有时也称为语法变量。
元素3:一个产生式(推导式一个概念,后面用推导式),非终结符号做头部(也就是左部)
元素4:指定一个非终结符号作为开始符号。
2.3 著名语言学家Noam Chomsky关于四类文法和四类形式语言(了解)
0型文法(短语结构文法)——0型语言
1型文法(上线文有关文法)——1型语言
2型文法(上线文无关文法)——2型语言(****在语法分析阶段这里用的是人家的2型文法)
3型文法(正规文法)——3型语言。
3. 语法分析树
4. 二义性(ambiguous):
在画语法分析树的时候,同样一件事,可以存在两种推导过程形成的分析树,得出的结果不一样。
5. 左结合和右结合,以及运算符的优先级
6. 因子(factor)——项(term)——表达式(expr)
*** “ | ” :这个符号表示或的意思,因此构成运算优先级的推导式如下:
expr→ expr + term | expr - term | term
term→ term * factor | term / factor | factor
factor→ digit | (expr)
7. *** “ || ”: 表示字符串的链接运算符
*** “ * ” :星号表示零个或多个意思
8. 语义动作:
通常用花括号就行括起来,这是在语义分析时候所用的表示方式
*** “ { } ”:表示语义动作
*** . :语义表示通常用非终结符加.点表示语义内容
//*************************词法分析***********************************//
1. 词法分析器作用:
词法分析是编译的第一阶段。词法分析器的主要任务是读入源程序的输入字符、将它们组成词素,生成并输出一个词法单元序列,每个词法单元对应一个词素。
2. 词法分析器的两个任务:
任务一:过滤掉源程序中的注释和空白(空白、换行符、制表符以及在输入中用于分割词法单元的其他字符)
任务二:将编译器生成的错误消息与源程序的位置联系起来。
第一处理阶段:扫描阶段——主要负责完成一些不需要生成词法单元的简单处理,比如删除注释和将多个连续空白字符压缩成一个字符。
第二处理阶段:词法分析阶段——较为负责的部分,它处理扫描阶段的输出并生成词法单元。
3. 为什么要划分词法分析和语法分析两个阶段?
*** 最重要的考虑是简化编译器的设计。
*** 提高编译的效率
*** 增强编译器的可移植性
4. 词法单元、模式和词素
词法单元:由一个词法单元名和一个可选的属性值组成。通常用黑体字给出词法单元名。
模式:描述了一个词法单元的词素可能具有的形式。
词素:源程序中的一个字符序列,它和某个词法单元的模式匹配,并被词法分析器识别为该词法单元的一个实例。
举例:C语句:printf("Total = % d\n", score);
printf和score都是和词法单元id的模式匹配的词素,而括号里面的适合literal匹配的词素。
词法单元对应词素实例
if if
else else
comparison <=,!=
id pi,score,D2
number 3.14159,0,6.02e23
literal "core dumped"
*** 常见的认识:每一个关键字有一个词法单元,表示运算符的词法单元可以表示单个运算符像comparison,一个表示所有标识符的词法单元,一个或多个表示常量的词法单元,每一个标点符号有一个词法单元。
5. 词法单元具有属性
6. 输入缓冲区
知道lexemBegin指针(表示词素开始处)和forward指针(向前扫描)
7. 哨兵标记
哨兵“sentinel”
当每次向前移动forward指针时,都必须检测是否达到了缓冲区的末尾(因为观察内存,向前移动时向尾部来移动),需要做两次测试:一次是是否达到达缓冲区的末尾,一次是确定读入的字符时什么。如果扩展每个缓冲区,使他们在末尾包含一个哨兵字符,我们就可以把缓冲区末端的测试和对当前字符的测试和唯一。这个哨兵符必须是一个不会再源程序中出现的特殊字符,一个自然的选择就是eof,因此eof是哨兵标记,或者叫哨兵字符。哨兵标记很像挡板,把一个一个的识别区在内存的缓冲区进行分开。
8. 串和语言
串(string):比如banana是一个长度为6的串,|s| = |6|,空串的长度为0,或者用希腊字母ε来表示
语言(language):是某个给定字母表上一个任意的可数的串的集合。
*** 这里为什么要说串,串是字母表中符号的有序集合,这个字母表不是传统意义上的字符表,比如ASCII码表就是一个字母表,Unicode也是一个字母表,包含大约100000个来自世界各地的字符。这里的单个串又不同于词素lexeme。词素是针对词法分析而言的最小单词单位,串是词法分析所用的元素来表示这些内容所在字母表中的最小单位。这里要有空集合空串的概念,串是一个非常广义的概念。
串的各部分的术语:
前缀prefix,是从串的尾部删除0个或多个符号后得到的串。例如ban、bannana和e是banana的前缀。
后缀suffix,是串从开始处删除0个或多个符号后得到的串。
子串substring,删除串的某个前缀和某个后缀得到的串。
子序列subsequence,是从串中删除0个或多个符号后得到的串,这些被删除的符号不可能相邻。
举例,比如x = dog,y=house把这连个串链接起来就是xy=doghouse,对于任何一个串都可以和空串进行链接:se = es = s
再比如两个串的乘积,或者指数运算。s0 为 空串,对于 i > 0 , si si-1s因此s1 = s, s2 =ss,s3 = sss...
9. 语言上的运算
我们常见的运算加减乘除等是数字的运算,数字也是语言,在这里的语言上的运算是一种更广义的运算。有并运算、链接运算和闭包运算(kleene闭包和正闭包),这个概念比较抽象,举例:
比如L是一个字母集合{A,B,C...a,b,..},D是数位集合{0,1,...9}
做并的元素是:长度为62长度为1的串,每个串是一个字母或者一个数位(a,1,b,4,3,2,4,z....)
做链接的元素是:长度为520,2个的串,每个串是一个字母跟一个位数(A2,b3,....)
L4,是由四个字母构成的串的集合。前面说过(ABCD,BCad,....)
L*,是有字母构成的串的集合,包括空串(ABCDE...)
L(L∪D)*,所有已字母开头的,由字母和位数组成的串的集合。(Ab3,b3...)
D+是一个或多个位数构成的串的集合。(123,321,23232,.....)
10. 正则表达式
正则实际来说是一种算法,首先可以用语言的并、链接和闭包这些运算符来描述标识符。正则可以描述所有通过某个字母表上的符号引用这些运算符而得到的语言。
比如:letter_ (letter_ | digit) *
竖线表示并运算,这个表示将letter_和表达式的其余部分并列表示链接运算,这个式子可以表示为AA这样是可以的A1这样也是可以的,后面任意。
11. 正则上面的并、链接和闭包:
(r) | (s) 是一个正则表达式,表示语言 L(r) ∪ L(s)。并运算
(r) (s) 是一个正则表达式,表示语言L(r) L(s)。链接运算
(r) * 是一个正则表达式,表示语言(L(r) )*。闭包运算
(r) 是一个正则表达式,表示语言L(r)。这个说明在表达式的两倍加上括号并不影响表达式所表示的语言。
*** 优先级:
* 最高优先级,左结合
链接次高优先级,左结合
| 并优先级最低,也是左结合
举几个例子:
a | b ,表示语言{a,b}
(a|b)(a|b),表示语言{aa,ab,ba,bb}
a * 表示所有由零个或多个a组成的串的集合,这个签名说过,等于幂运算的表示{e,a,aa,aaa}
(a|b) * 表示由零个或者多个a或者b的实例构成的串的集合,由a和b构成的所有串的集合{e,a,b,aa,ab,ba,bb,aaa,...}另外还可以(a*b*)*来表示,上面意思相同,这里打不打括号,意思相同。
a|a*b 表示语言{a,b,ab,aaab,....}
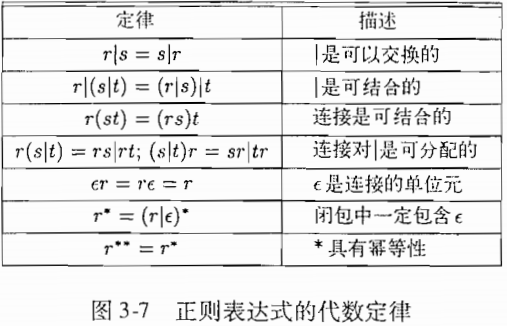
12. 正则定律
12. 对应C语言一些正则的表达方式:
*** 正则式在汇编,高级语言等各个方面渗透到的,其最重要的作用是通过正则的一些表述,来做“匹配”,因此在编译阶段,正则用于匹配高级语言对应中间语言,在词义分析、语法分析各个方面都非常广泛。正则一个重要的概念,记住就是“匹配”!
举例:正则对C语言的匹配实例(按照惯例用斜体字来表示正则定义中定义的符号)
标识符类:由字母、数字、下划线组成的串。
letter_ → A | B | ... | Z | a | b | ... | z | ...
digit → 0 | 1 | ... | 9
id → letter _ (letter _ | digit) *
上面这段:id标识符是由 letter 加 下划线 组成的,组成可以是letter下划线加letter加数字或者数字加letter,例如letter_letter或者letter_digit
其中letter由字母组成,digit由数字组成,任意。这段就是对于C,大多数语言对于变量名的一个定义的正则表达,不允许以数字开头...像这类一般从下往上看进行逐步分解比较直观
无符号数(整型或浮点型):5280、0.01234、6.336E4或1.89E-4的串,用正则定义给出这类符号串的精确归约(为了方便小写西格玛用e代替)
digit → 0 | 1 | ... | 9 //数字标识符“可有以下形式”:数字有0到9任意一个数字。
digits → digit digit* //可选digits标识符“可有以下形式”: 数字链接数字*,后面这个数字上面有个星号,表示可以链接零个或多个数字
optionalFraction → . digits | e //可选浮点型“可有以下形式”:1.单独e表示啥都没有,2.加一个点后面跟上digits标识符。
optionalExponent → ( E ( + | - | e) digits) | e //可选指数“可有以下形式”:1.单独一个e,表示没有,2.E选项中至少有一个+或者-或者啥都没有,在加一个digits标识符。
number → digits optionalFraction optionalExponent //数字“可有以下形式”:digits标识符,optionalFraction标识符,optionalExponent标识符。
通过正则式可以看到用非常方便的方式把词法单元非常容易分解出来,通过正则的匹配逻辑。
13. Stephen Cole Kleene:斯蒂芬.科尔.可莱尼,美国著名的数学家,逻辑学加,他的递归理论奠定了现代计算机的科学基础。丫又一美国人。
14. 对现阶段正则所用符号的小结:
*** “ id ” :表示标识符(identifier)
*** “ → ” :表示“可以具有如下形式”
*** expr : 表示表达式,加下标表示还可扩展
*** stmt : 表示语句
*** optparams : 表示可选参数
*** params : 表示参数
*** call :符号串
*** letter :表示字母
*** digits :表示数字集合
*** digit : 表示数字
*** right : 表示右端
*** left : 表示左端
*** term : 表示项
*** factor : 表示因子
*** number : 表示数值、数字
*** “ || ” :表示字符串的链接运算符
*** “ { } ” :表示程序片段或者语义动作,或者集合
*** ε:表示空串
*** assign : 表示赋值等号 =
*** cond : 表示字符串连接运算符,等于逻辑或 ||,或者 逻辑与&& 之类的
*** rel :表示== != < <= >= > 之类
*** op :表示 加减乘除余等运算符
*** not :表示非 !
*** minus : 表示最小,上划线unary
*** “ [ ] ” :表示[ ]入口,放置,范围,比如[abc],在正则中表示a|b|c,表示a到c的一个范围
*** “ * ” :星号表示零个或者多个
*** “ ? ” :问号表示至少有一个或者没有
*** “ | ” :表示或者
*** “ < > ”:表示词法单元,里面一般包括词法名和词法属性
*** comparison:也是拜师大小关系等于上面的rel
*** literal:在两个“之间,除”以外的任何字符。
*** if :关键字,终结符
*** else :关键字,终结符
*** do :关键字,终结符
*** while:关键字,终结符
*** eof :表示地址终结符,哨兵记号,哨兵标记
*** “ ( ) ” :表示优先级
*** “ + ” :加号在符号右上角表示正则表达式及其语言的正闭包,也就是说,如果r是一个正则表达式,那么(r) + 就是语言(L(r))+。运算符+和运算符*具有同样的优先级和结合性。
*** “ — ” :连词符,表示从什么到什么,写出第一个和最后一个符号,链接词的符号:[a - z] 就等于a|b|...|z的缩写,其实也是范围的意思
*** “ ^ ” :表示一行的开头
*** “ $ ” :表示行的结尾
15. 正则式的扩展表示:
前面都已经提到了:
一个或者多个的实例,其实就是*或者+号右上角的表示
零个或者一个实例,?号
字符类用[ ]表示范围,连词符表示从哪儿到哪儿,例如[a-c e-g]这个表示a|b|c|e|f|g
如下是Lex常用的正则表达式,其实很多都是跟这个一样,这个很古老也沿用至今的
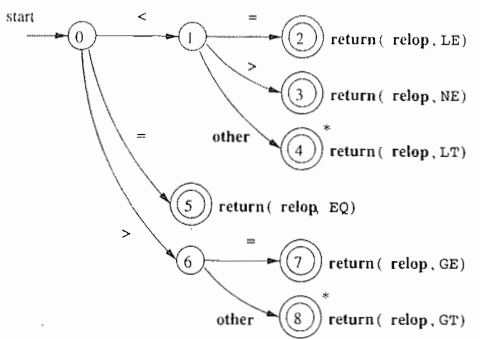
16. 状态转换图(transition diagram):
有一组被称为“状态”(state)的节点或圆圈。词法分析器在扫描输入串的过程中寻找和某个模式匹配的词素,而状态转换图中的每个状态代表一个可能在这个过程中出现的情况。状态图中的边(edge)从图的一个状态指向另一个状态。
状态转换图的约定:
约定1:某些装成为接受状态或最终状态。这些状态表明已经找到了一个词素。我们用双层的圆圈来表示一个接受状态。
约定2:如果需要将forward回退一个位置,那么将在该接受状态的附加加上一个*。
约定3:有一个状态被指定为开始状态,也叫初始状态。
图示:
17. 保留字和标识符的区别:
初始化时就将各个保留字填入符号表中。当找到一个标识符时,如果该标识符尚未出现在符号表中,就会调用installID将此标识符放在符号表中,并返回一个指针,指向这个刚找到的词素所应对的符号表条目。为每个关键字单独建立状态转换图。
对应上面的无符号数的正则推导式,用状态转换图来表示出来。
例子1:
无符号数(整型或浮点型):5280、0.01234、6.336E4或1.89E-4的串,用正则定义给出这类符号串的精确归约(为了方便小写西格玛用e代替)
digit → 0 | 1 | ... | 9 //数字标识符“可有以下形式”:数字有0到9任意一个数字。
digits → digit digit* //可选digits标识符“可有以下形式”: 数字链接数字*,后面这个数字上面有个星号,表示可以链接零个或多个数字
optionalFraction → . digits | e //可选浮点型“可有以下形式”:1.单独e表示啥都没有,2.加一个点后面跟上digits标识符。
optionalExponent → ( E ( + | - | e) digits) | e //可选指数“可有以下形式”:1.单独一个e,表示没有,2.E选项中至少有一个+或者-或者啥都没有,在加一个digits标识符。
number → digits optionalFraction optionalExponent //数字“可有以下形式”:digits标识符,optionalFraction标识符,optionalExponent标识符。
对应的状态转换图:
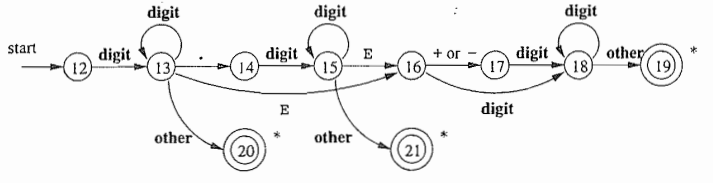
例子2:对应空白符的状态转换图
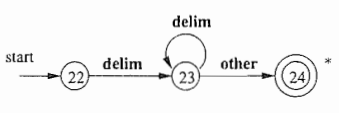
17. 有穷自动机(finite automata):
定义:
有穷自动机:FA,有穷自动机是识别器(recognizer),他们只能对每个可能的输入串简单的回答是或者否。
不确定的有穷自动机:NFA,是对边上的标号没有任何限制。
确定的有穷自动机:DFA,是有气质有一条离开状态、以该富豪为标号的边。
17.1 确定的有穷自动机和不确定的有穷自动机的区别:
确定的有穷自动机就是说当一个状态面对一个输入符号的时候,它所转换到的是一个唯一确定的状态;
不确定的有穷自动机是说当一个状态面对一个输入符号的时候,它所转换到的可能不只一个状态,可以是一个状态集合.
这就是两者的主要区别.还有就是DFA的开始状态是唯一的,而NFA的开始状态是一个开始状态集。
最重要的区别就是状态是不是唯一,确不确定。DFA应该有一个死状态
18. 从正则到有穷自动机
//*************************语法分析***********************************//
1. 语法分析器的作用和分类:
语法分析器会生成一个语法分析树,与词法分析器不同,可以狭义的理解为:词法分析器是匹配过程,语法分析器是纠错过程。
语法分析器大体上可分为三类:通用型、自顶向下和自底向上三种
2. LL文法和LR文法
LL文法是自顶向下的方法,属于左推导
LR文法是自底向上的方法,属于右推导。
如下图是将一个右推导的LR文法,变成LL文法的左推导形式

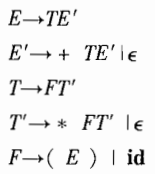
都是简写,E等于expr,其他同。
3. 语言常见的四种错误:
错误1:词法错误,单词拼错了,这个错误容易发现
错误2:语法错误
错误3:语义错误
错误4:逻辑错误:这个比较重要难以发现,大多数编程或者语言的错误在这里。
4. 语法分析中一个重要的语法——上下文无关的语法:
4.1 一个正式定义:
组成四部分:终结符号、非终结符号、一个开始符号和一组推导式(产生式)
终结符号:是组成串的基本符号。“词法单元名” 与 “终结符号”是同义词。
非终结符号:是表示串的集合的语法变量。
开始符号:某个非终结符号被指定为开始符号,这个符号表示的串集合就是这个文法生成的语言。按照惯例,首先李处开始符号的推导式。
推导式由下面元素组成:
第一:一个被称为推导式的头部或者左部的非终结符号。这个推导式定义了这个头所代表的串的集合的一部分。
第二:符号 →。有时也使用 :: = 来替代箭头。
第三:一个由零个或多个终结符与非终结符号组成的推导式体或右部。推导式体中的成分描述了推导式头上的非终结符号所对应的串的某种构造方式。
4.2 一个算术表达式例子说明这四部分的组成:
已知:终结符号是:id + - * / ( )
非终结符符号是:expression、term和factor。
找出上下文无关的语法,在推导式当中的,那些是终结符号,那些是非终结符号,分别表示什么意思
expression → expression + term
expression → expression - term
expression → term
term → term * factor
term → term / factor
term → factor
factor → (expression)
factor → id
4.3 符号表示的约定:(7个约定)
1.*** 下面符号是终结符号:
1.字母表里排在前面的小写字母,比如a、b、c
2. 运算符号,比如+ - * /等
3.标点符号,比如括号、逗号等
4.数字0、1、...、9
5.黑体字符串,比如id或if,每个这样的字符串表示终结符号。
2.*** 下面符号是非终结符号:
1. 在字母表中排在前面的大写字母,比如A、B、C
2. 字母S。他出现通常表示开始符号,start
3.小写、斜体的名字,比如expr或stmt
4. 当讨论程序设计语言的构造时,大写字母可以用于表示代表程序构造的非终结符号。比如表达式、项、因子,他们分别是E、T、F,说白了他们也是expression、term、factor字母的缩略表示,因此也是非终结符号。
3.*** 在字母表中排在后面的大小字母(比如X、Y、Z)表示语法符号,也就是说,表示非终结符号或终结符号。
4.*** 在字母表中排在后面的小写字母(主要是u、v ....z)表示(可能为空的)终结符号串。
5.*** 小写希腊字母,A → α,A是推导式的头,α是推导式的体。
6.*** 具有相同的头的一组推导式,比如A → α1,A → α2,A → α3...A → αk,A推导式也可以写做A → α1|α2|...|αk|。我们把α的这些称作A的不同可选体。
7.*** 除法特别说明,第一个推导式的头就是开始符号。
说明:其实这7个约定是针对来自不同语言的源程序而言的,有的源程序经过词法分析后形成的短语用的缩写,有的用的斜体等等,针对不同的源程序,可以用不同的表述,但是这种自上而下的语法,肯定是包含着4个部分的。
4.4 推导更精确的表述:
“ =>” :这个符号记做“推导出”,其实前面用的→箭头是“可具有下面的形式”。一个叫推导式,一个叫产生式。其实意思差不多,但是更精确些。因此推导分为左推导lm,和右推导rm,也就是终结符号在左,还是在右。
4.5 语法分析树和推导:
其实语法分析树是推导的图形表示,用两张图来说明一下:
设:有这么一个推导过程:
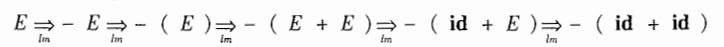
生成语法分析树:

它是由那几步进行推导的
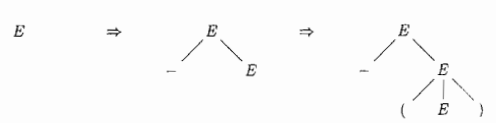
E 可以推导出 E 可以是一个负号 + E的形式。也就是看到的第一步。E拆分成 - 和 E ,也就是E => - E这两部分。
E 还可以推导出,符号 + E,后面这个E可以由三部分组成,( 左括号,E,)右括号。

这个就不说了。其实发现一点,每一个节点E,knot上面都是有两种可能性:
可能1:不可再分也就结束
可能2:如果可以再分通过这个结点再往下分。
这就像在某一个knot位置上面写了一个E+号的形式,如果有加号可以打开再往下。这就是一个典型的树型结构,也是看这种属性结构的技巧,也要注意每一个最小不可再分的factor是那些。
4.6 二义性(ambiguous):
所谓二义性也很好理解,就是一个推导过程可以有两种推导的可能性,也就是“条条大路通罗马”,这里是“两条大陆通罗马”。其实多说一点儿,这些所谓的语法分析什么词法分析,他们构成这类思想的核心就是逻辑性,如果一个人具有很好的逻辑性看这些问题也变得简单了。
大部分语法分析器都是期望文法是五二义性的,否则,我们就不能为一个句子唯一的选定语法分析器。在某些情况下,使用经过精心选择的二义性文法也可以带来方便。但是同时使用消二义性规则(disambiguating rule)来“抛弃”不想要的语法书,只是为了每个句子留下一棵语法分析树,二义性好还是不好,这个事儿要就事论事。
贴张书上的图,说明一下二义性:
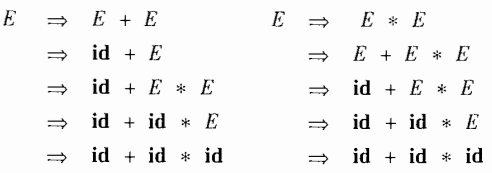
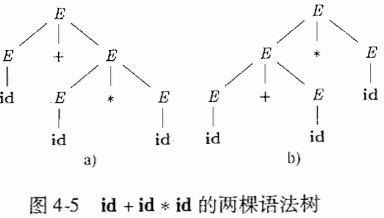
4.7 正则表达式和上下文无关的文法
前面说过一个正则表达式和有穷自动机的关系,现在再把正则表达式和上下文无关文法再结合起来看看。
设有这么一个正则表达式(a | b) * abb。这个式子很容易理解的是 a b前面随意组合不限制次数和个数,但是结尾是abb的形式。
5. 消除二义性:
前面提到了二义性的问题,有时,一个二义性文法可以被改写成无二义性的文法。
关于一个常用的条件控制流语句如何去消除二义性。if...then...else的语句形式:
“每个else和最近的尚未匹配的then匹配”
6. 消除左递归
如果一个文法中有一个非终结符号A使得对某个串α存在一个推导A=>Aα,那么这个文法就是左递归的(left recursive)。自上而下的语法分析方法不能处理左递归的文法,因此需要一个转换方法来消除左递归。
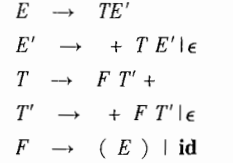
这是通过消除表达式文法中的立即左递归而得到的。
7. 提取左公因子
提取左公因子是一种文法转换方法,它可以产生适用于预测分析技术或自顶向下的分析技术文法。当不清楚在两个A产生式中如何选择时,我们可以通过改写产生式推后这个决定,等我们读入了足够多的输入,获取足够信息后再做出正确选择。
举个例子:
输入:文法G
输出:一个等价的提取公因子的文法。
方法:对于每个非终结符号A,找出它的两个或多个选项直接的最长公共前缀α,α不是空串e,即存在一个非平凡的公共前缀,那么所有的A产生式A → αβ1 |αβ2|...|αβn|,γ替换为:
A → α A‘ | γ
A’ → β1 | β2 | ... | βn
(这里β类编程A’的一个合集)
其中gamma表示不以α开头的产生式体;A’ 是一个新添加进来的非终结符号,不断应用这个转换,直到每个非终结符号的任意两个产生提都没有公共前缀为止。
再举个例子:
上面的if...then...else
S → i E t S | i E t S e S| a
E → b
用i表示if,用t表示then,用e表示else,E和S表示条件表达式和语句。提取公因子的文法变为
S → i E t S S ’ | a
S’ → e S | ε
E → b
如果我们在输入i的时候将S展开为i E t S S ’ ,并处理i E t S 后才决定将S’ 展开为eS 还是空串。
8. 非上下文无关语言的构造:
在语义阶段进行详细说明
*** 小备注:+ 号有时表示字符串的连接 区别 |
9. 自顶向下的语法分析:
自顶向下的语法分析可以被看做是为输入串构造语法分析树的问题,它从语法分析树的根节点开始,按照先根次序创建这颗语法分析树的各个节点。自定向下的语法分析也可以被看作寻找输入串的最左推导过程。
9.1 递归下降的语法分析
一个递归下降语法分析程序由一组过程组成,每个非终结符号都有一个对应的过程。程序的执行从开始符号对应的过程开始,如果这个过程的过程扫描了整个输入串,它就停止执行并宣布语法分析完成。
9.2 FIRST 和 FOLLOW
自顶向下和自底向上的语法分析器的构造可以使用和文法G相关的两个函数FIRST和FOLLOW来实现。在自定向下的语法分析过程中,FIRST和FOLLOW使得我们可以根据下一个输入符号来选择引用那个产生式。在恐慌模式的错误恢复中,由FOLLOW产生的词法单元集合可以作为同步词法单元。这属于一种预测分析的方式,预测那一时刻选择什么样的产生式。
9.3 LL(1)文法:
第一个L表示从左向右扫描输入,第二个L表示产生最左推导,1表示每一步只需要向前看1个输入符号来决定语法分析动作。
9.2和9.3 讲的是一种预测分析的方法,是到哪一步应该做出什么样的动作,进行相关资料的深入了解:
1. FIRST和FOLLOW是一个集合。
2. 首先要知道这两个集合的求法
S → ABc
A → a | ε
B → b | ε
3. FIRST集合求法:
能由非终结符号推导出的所有的开头符号或可能的空串,但要求这个开头符号是终结符号。如上面,A可以推导出小a和ε,所以FIRST(A)的集合应该是{a,ε};同理FIRST(B)的集合是{b,ε},S可以推导出aBc,还可以推导出bc,还可以推导出c,所以整个这个大的FIRST(S)就是{a,b,c}
4. FOLLOW集合的求法:
紧跟随其后面的终结符号或#。但文法的识别符号包含#,在求的时候还要考虑到ε。具体做法就是把所有包含你要求的符号的产生式都找出来,再看看那个有用
FOLLOW(S) = {#}
如求A的,产生式:S → ABc A→a|ε,但只有S → ABc有用。跟随在A后面的终结符号是FIRST(B) = {b,ε},当FIRST的元素为ε时,跟随在A后面的符号就是c,所以FOLLOW(A)={b,c},FOLLOW(B)={c}
5. 看起来有时候还是萌萌的,通过如下的例子,还有后面的原则进行推导。可以翻阅往下一点儿的原则,拿着原则来进行推导,遇到那个问题看适应那个原则:
例题1:FIRST例题
S → B A
A → B S | d
B → a A | b S |c
FIRST(S) = FIRST(B) + FIRST(A) = FIRST(B) 是一个非终结符,且推导不出ε来,结束,因此 = FIRST(B)
FIRST(A) = FIRST(B) + FIRST(S) + FIRST(d) = 非终结符,且推导不出ε来,保留,且第二部分是一个d保留,因此={FIRST(B),d}
FIRST(B) = 终结符结束+终结符结束+终结符结束 = {a,b,c}
把FIRST(B)全部反向带入回去,得到如下:
FIRST(S) = {a,b,c}
FIRST(A) = {a,b,c,d}
FIRST(B) = {a,b,c}
例题2:FIRST例题
S → ABc
A → a | ε
B → b | ε
FIRST(S) = A非终结,且推导出ε,保留;B非终结,且推导出ε,保留;c终结符,结束={FIRST(A),FIRST(B),c}
FIRST(A) = a终结符,第二部分ε ;= {a,ε}
FIRST(B) = b终结符,第二部分ε ;= {b,ε}
把FIRST(A)和FIRST(B),全部带入回去,得到如下:
FIRST(S) = {a,b,c}
FIRST(A) = {a,ε}
FIRST(B) = {b,ε}
例题3:FIRST例题。稍微复杂点儿的。
1.E → TE'
2.E' → +TE'
3.E' → ε
4.T → FT'
5.T' → *FT'
6.T' → ε
7.F → i
8.F → (E)
解:按照傻瓜办法全部列出,打印速度FIRST用小写的
first(E)= 保留 + 去除(因为可推导出ε)= first(T)
first(E')= 终结符 + 非终结符 + 可推导出ε的非终结符 = {+}
first(E')= ε = {ε}
first(T)= 非终结符 + 可推导出ε的非终结符 = first(F)
first(T')= 终结符+非终结符+可推导出ε的非终结符 = {*}
first(T')= {ε}
first(F)= 终结符 = {i}
first(F)= 终结符 + 非终结符 + 终结符 = {(}
因此全部反向带入得到:
FIRST(E) = {i,(}
FIRST(E') = {+,ε}
FIRST(T) = {i,(,}
FIRST(T') = {*,ε}
FIRST(F) ={i,(}
例题4:FOLLOW例题。
1.E → TE'
2.E' → +TE'
3.E' → ε
4.T → FT'
5.T' → *FT'
6.T' → ε
7.F → i
8.F → (E)
解:1.按照开始求FOLLOW集合
首先加入$终结符,FOLLOW(E) = {$}
其次,观察下面在产生式的右边出现了E,跟在E后面的,最后一个F→(E),follow后面的是终结符,反括号,因此FOLLOW(E) = { ) , $ }
2.再求E'
FOLLOW(E'),同样观察产生式的右边出现E'的位置,跟在E'后面的。一共两次,TE'和+TE',因此这是一种 αA的形式,右边啥都没有了,因此等于自身。因此
FOLLOW(E') = FOLLOW(E)= { ) , $ }
3.再求T
FOLLOW(T),同样观察产生式的右边跟在,T后面的。一共两次TE'和+TE',这样是一种αAβ的形式,因此β要用first形式代替,因此就是 = first(E') = {+,ε},又因为里面有ε,所以TE'和+TE' 变为 T和+T,因此FOLLOW(T)的形式变为2的形式αA了,所以里面的空串是和FOLLOW(E)一样了,所以就是{+,),$}。
3.再求T'
FOLLOW(T’),同样观察产生式右边跟在T'后面的。FT'和*FT',这是第一种αA的形式,右边啥都没有,因此等于自身。= {+,),$}。
4. 再求F
FOLLOW(F),同样观察产生式右边跟在F后面的。FT'和*FT',还是上面那个,属于αAβ形式的,让β变为first,因此first(T‘) ={*,ε},同样出现ε,然后在变形为F和*F,变为αA的形式了,等于自身,因此等于FOLLOW(T)。最终这个等于{*,+,),$}
总结:
1.关于FIRST集合
*** 共分为3个基本原则分为:一个产生式能推导出终结符、一个产生式推导不出终结符(也就是推导出非终结符)、一个产生式可以推导出ε,这样三种情况。
*** FIRST集合顾名思义,是FIRST,什么的FIRST?也就是说找到第一个终结符的FIRST。
*** 三种基本情况如下:
*** 原则1:X→ 可以推导出终结符的情况。因此可以适应如下几种情形:
1.1 如果遇到第一个位置就是终结符,结束,加入集合。
eg:E = a,FIRST(E) = {a}
E = abc,FRIST(E) = {a}
E = +aB,FRIST(E) = {+}
以此类推。
1.2 如果遇到遇到推导式后面有 “ | ”,且,这个符号的时候,分两段进行处理,如果有终结符,结束,加入集合。
eg:E = a | b,FIRST(E) = {a,b}
E = a | B,FIRST(E) = {a}
E = + | c,FIRST(E) = {+,c}
E = B | c,FIRST(E) = {c}
以此类推。
*** 原则2:X → 可以推导出非终结符的情况。因此可以适应如下几种情形:
2.1 简单说叫遇ε继续,遇终结符停止(要结合下文看),结束,加入集合。
eg:E = ABc FIRST(E) = 1) 遇到A,下文看A可以推导出一个ε,保留,继续;2)遇到B,下文看可以推导出一个ε,保留,继续;3)遇到终结符结束
A = a | ε
B = b | ε
*** 原则3:X → 可以推导出一个ε的情况。因此可以适应如下情形:
3.1 一般把这个ε加入到下面的FIRST集合。
eg:还比如上面那个例子。通过推导的式子如下:
FIRST(E) = {a,b,c}
FIRST(A) = {a,ε}
FIRST(B) = {b,ε}
根据这三个原则,FIRST集合都可以全部推导出来!关于这些集合包括FOLLOW,SELECT集合等,都是根据原则来列出所有的集合来。
2.关于FOLLOW集合
*** 也是共分为3个原则:找到开始符,先把$终止符加进去、如果是A → αB 的形式,就等于自身、如果是 A → αBβ的形式,先把β变为first(β)的形式,找到first集合加入,然后变形为αB的形式,再等于自身加入。
**** 原则分析1:最终的每一个FOLLOW集合最后一个元素都是$符号作为终止符(有的材料用#,一样道理)
eg. FOLLOW(X) = {(,$}
*** 原则分析2:与FIRST集不同,是要求哪一个产生式左边的FOLLOW集,去右边找在产生式左边出现这个符号的都是那些,在进行分析。
eg.通过上面的计算实例。比如我求FOLLOW(E)的跟随集,要找式子右边出现E的情况都是那些列出。
*** 原则分析3:在原则分析2的基础上,可能出现找到的位置出现这样两种情形的表达,一种是αAβ,还有一种是αA;如果出现第二种就等于本身也是等于产生式左边对应的FOLLOW集合的总和。如果出现第一种情况,β变形为FIRST(β)的形式,里面有空串,把除了空串的FIRST(β)加入到本FOLLOW集合当中,原先的第一种形式变形为第二种形式,在求本身FOLLOW集合的总和。
*** 原则总体:FOLLOW就是查要找的FOLLOW集的非终结符在所有右边产生式出现的状态,分为αAβ和αA两种形式。第一种是变形为FIRST再等于本身,第二种直接等于本身,就是在这里略有不同。如果出现 “ | ”,这样的且的符号,不用分段看,是看当下一段即可。
因此FOLLOW集合要抓住一个原则就是分段观察,出现右侧不同形式,对应化简然后在等于本身。
6. LL(1)文法:
对于称为LL(1)文法,可以构造出预测分析器,即不需要回搠的递归下降语法分析器。LL(1)中的第一个L表示从左向右扫描输入,第二个L表示产生最左推导,而1则表示在每一步中只需要向前看衣蛾输入符号来决定语法分析动作。
7. 预测分析器:
预测分析器的转换图和词法分析器的转换图是不同的。分析器的转换图对每个非终结符号都有一个图。途中边的标号可以是词法单元,也可以是非终结符号。词法单元上的转换表示当该词法单元时下一个输入符号时我们应该执行这个转换。非终结符号A上的转换表示对A的过程的一次调用。
8.非递归的预测分析
9. 自底向上的语法分析
一个自底向上的语法分析过程对应于每一个输入串构造语法分析树的过程,它从叶子节点底部开始逐渐向上到达根节点(顶部)。如下是一个自底向上呈现分析树的图示:
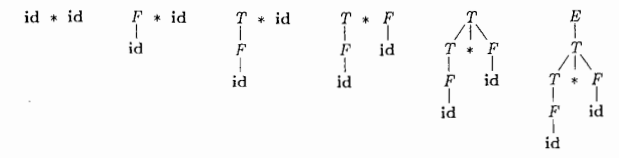
9. 移入——归约(自底向上语法分析通用框架)
9.1 归约(reduction)
这个单词是减少的意思,何为归约?将自底向上语法分析过程看成将一个串w归约为文法开始符号的过程。在每个步骤中,一个与欧产生提相匹配的特定淄川被替换为该产生式头部的非终结符号。问题是:何时归约,用那个产生式进行归约。
还是有点儿懵懂,何为归约?通过下面的符号串序列来进行讨论这个归约过程:
id * id , F * id, T * id, T * F, T , E
这个序列中的符号串由快照中各相应子树的根节点组成。这个序列从输入串id * id 开始。第一次归约使用产生式 F → id,将最左边的id归约为F,得到串F * id(备注:其实这里也是一个LL(1)文法),第二次归约将F归约为T,生成 T * id。以此类推,最后将T归约为开始符号E,从而结束整个语法分析过程。实际是一个右推导。
其实龙书中很多都是让人看得懵逼的语言,归约其实就是数学当中的等量代换,通过代还的方式,使得原来从左向右书写的方式,变为从右像左书写。
9.2 句柄剪枝
9.3 语法分析技术
它使用一个栈来保存文法符号,并用一个输入缓冲区来存放要进行语法分析的其余符号。我们将看到,句柄在被识别之前,总是出现在栈的顶部。
因此要进行四个动作:
1)移入(shift):讲下一个输入符号移到栈的顶端。
2)归约(reduce):被归约的符号串的右端比如是栈顶。语法分析器的栈中确定这个串的左端,并决定用按个非终结符号来替换这个串。
3)接受(accept):宣布语法分析过程完成。
4)报错(error):发现一个语法错误,并调用一个错误恢复子例程。

经过这个步骤,句柄总是出现在栈的顶端,绝不会出现在栈的中间。后面有一个LR文法就是专门将这个的。就是有一些上下文无关的文法找不到相关的句柄。
10. LR语法分析技术之简单LR技术
目前最流行的自底向下语法分析器都基于所谓LR(k)语法分析的概念,其中L表示对输入进行从左向右的扫描,R表示反向构造出一个最右推导序列,而k表示在做语法分析决定时向前看k个输入符号。k =0 和 k =1这两种情况具有实践意义,因此这里我们将只考虑k<=1的情况。当k省略时,我们假设k=1。简单LR也叫SLR,后面还有两种更加复杂的方法,规范LR和LALR。他们被用于大多数LR语法分析中。
10.1 简单解说:
只要存在这样一个从左到右扫描的移动-归约语法分析器,它总是能够在某文法的最右句型的句柄出现在栈顶时识别出这个句柄,那么这个文法就是LR的。
优点:
1) 对于几乎所有的程序设计语言构造,只要能够写出该构造的上下文无关文法,就能够构造出识别该构造的LR语法分析器。确实存在非LR的上下文无关文法,但是一般来说,常见的程序设计语言构造都可以比喵使用这样的文法。
2) LR语法分析方法是已知的最通用的无回搠移入-归约分析技术,并且它的实现可以和其他更原始的移入-归约方法一样高兴。
3) 一个LR语法分析分析器可以在对输入进行从左到右扫描时尽可能早地检测到错误。
4) 可以使用LR方法进行语法分析的文法类可以使用预测方法或LL方法进行语法分析的文法类的真超集。
缺点:
LR方法的主要缺点是为一个典型的程序设计语言文法手工构造LR分析器的工作量非常大。当然有Yacc常用分析工具。
10.2 项和LR(0)自动机
10.3 GOTO函数
GOTO(I,X),其中I是一个项集而X是一个文法符号。GOTO【当前状态,A】 = 下一个状态
举个例子:
如果I项集是两个项的集合{[E' → E ·],[E → E · + T]},那么GOTO(I,+)函数包含的项如下:
E → E + · T
T → · T * F
T → · F
F → · (E)
F → · id
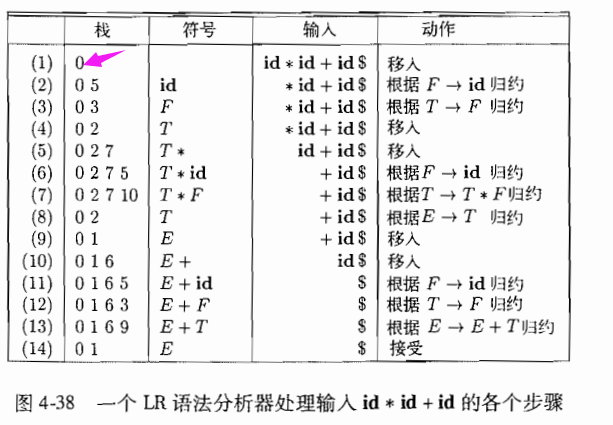
10.4 LR语法分析算法。如图示意:一个输入、一个输出、一个栈、一个驱动程序和一个语法分析表组成。这个分析表包括ACTION 和 GOTO两部分

其中ACTION是一个动作函数,GOTO是一个转换函数
10.4 ACTION函数
有两个参数ACTION[i,a],
1.移入j,其中j是一个状态。语法分析器采取的动作是把输入符号a高效的移入栈中,但是实用状态j来代表a。
2.归约A → β。语法分析器的动作是把栈顶的β高效的归约为产生式头部A
3.接受。语法分析器接受收入并完成语法分析过程。
4.报错。语法分析器在它的输入中发现了一个错误并执行某个纠正动作。
10.5 一个LR语法分析程序图示:

这里用到了2个函数,一个是ACTION,另外一个是GOTO函数,一个是动作移栈,另一个是变换函数。
编码过程如下:
1.ACTION[Si,a]表示移入并将状态i压栈。
2.rj 表示按照编号位j的产生式进行归约。
3.acc表示接受
3.空白表示报错。
请注意,对于终结符号a,GOTO[s,a]的值在ACTION 表项中给出,这个值和在输入a上对应于状态s的移入动作一起给出,这个值在和输入a上对应状态s的移入动作一起给出。
我们可以看到基本上属于移入-归约的方式。
10.6 构造SLR语法分析表
10.7 构造LALR语法分析表
LALR为向前看-LR技术。
10.8 LR语法分析表的压缩
一个典型的具有50-100个终结符号和100个产生式的程序设计语言文法的LALR语法分析表中可能包含几百个状态。肥西表的动作函数常常包含20000多个条目,乜咯条目至少需要8个二进制进行编码。对于小型设备,有一个比二维数组更加高效的编码方法是很重要的。
一个可用于压缩动作字段的技术所基于的原理是动作表中通常有很多相同的行。如果我们为每个状态创建一个指向一维数组的指针,我们就可以节省客观的空间,而付出的时间代价却很小。具有相同动作的的状态的指针指向相同的位置。为了从这个数组获取信息,我们给每个终结符号赋予一个编号,编号范围为从零开始到终结符号总数减一。对于每个状态,这个整数编号将作为指针开始偏移量。在给定的状态中,第i个终结符号对应的语法分析动作可以在该状态的指针值滞后的第i个位置上找到。
如果为每个状态创建一个动作列表,我们可以获得更高的空间效率,但语法分析器会变慢。这个列表由(终结符号,动作)对组成。一个状态的最频繁的动作可以放到列表的结尾处,并且我们可以在这个对中原本放终结符号的地方放上符号“any”,表示如果没有在列表中找到当前输入,那么不管这个输入是什么,我们都选择这个动作。不仅如此,为了使得每一行中的内容更加一致,我们可以把报错条目安全地替换为归约动作。对错误的检测会稍有延后,但仍可以在执行下一个移入动作之前发现错误。
11. 使用二义性文法
11.1 使用优先级和结核性解决冲突
通过运算符的优先级,去规定E在栈的位置,从而进行从顶之下的运算方式。
12. 语法分析器生成工具
讲了这么多对于内存的不断扫描通过语法分析,归根结底会要生成一个语法分析生成工具。这里你对于常用的语法生成工具进行简介。
12.1 经典的Yacc
Yacc的全名叫“yet another compiler-compiler”,叫做:又一个编译器的编译器。最早是S.C.Johnson在20世纪70年代最早创建Yacc第一个版本。Yacc在UNIX系统中是以命令的方式出现的,它已经用于实现多个编译器产品。
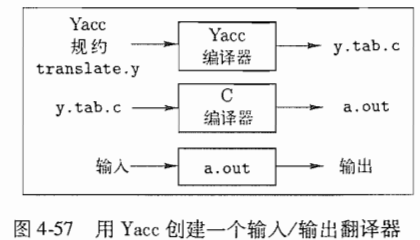
Yacc源程序由三部分组成:
声明
%%
翻译规则
%%
辅助性C语言例程
12.2 C语言的是一个Yacc翻译归约

最后一部分是辅助性C语言例程,前面两部分在C语言中编写时都被隐去,所以看不到
12.3 经典Lex创建Yacc的词法分析器。
Lex是生成的词法分析器,Yacc是生成的语法分析器,别搞混。一般Lex的作用是生成可以和Yacc一起使用的词法分析器。Lex库II将提供一个名为yylex( )的驱动程序。Yacc要求它的词法分析器的名字为yylex( )。如果Lex来生成地方分析器,那么我们可以将Yacc归约的第三部分例程yylex( ),替换为语句
# include "lex.yy.c"
并令每个Lex动作都返回Yacc已知的终结符号。因此Lex的输出文件是作为Yacc的输出文件y.tab.c的一部分被编译的。
13. 小结
*** 语法分析器。语法分析器的输入是来自词法分析器的词法单元序列。它将词法单元的名字作为一个上下文无关文法的终结符。然后,语法分析器为它的词法单元输入序列构造出一颗语法分析树。其实这个语法分析树是象征性的,其实是仅仅遍历相应的推导步骤。
*** 上下文无关文法。一个文法描述了一个终结符号集合(输入),另一个非终结符号集合(表示语法构造的符号)和一组产生式。每个产生式说明了如何从一些部件构造出某个非终结符号所代表的符号串。这些部件可以是终结符号,也可以是另外一些非终结符所代表的串。上下文无关的文法是一个产生式由头部和产生式体所组成的。
*** 推导。从文法的开始非终结符除法,不断将某个非终结符号替换为它的某个产生式体的过程称为推导。如果总是替换最左(最右)的非终结符号,那么这个推导就称为最左推导(最右推导)。
*** 语法分析树。一棵语法分析树是一个推导的图形表示。在推导中出现的每一个非终结符号都在树中有一个对应的结点knot。一个结点的子节点sub-knot就是在推导中用来替换该结点对应的非终结符号的文法符号串。在同一个非终结符号串的语法分析树、最左推导、最右推导之间存在一一对应关系。
*** 二义性。如果一个文法的某些终结符号串又两棵或多颗语法分析树,或者等价的说有两个或多个最左推导/最右推导,那么这个文法就称为二义性文法。在实践中,大多数情况下,我们可以对一个二义性文法进行重新设计,使它变成一个描述相同语言的无二义性文法。然后,有时使用二义性文法并应用一些技巧可以得到更加高效的语法分析器。
*** 自顶向下和自底向上的语法分析。语法分析器通常可以按照它们的工作方式可以有这两种方式。因此产生了LL语法分析器和LR语法分析器。
*** 文法的设计。自底向上的语法分析器比自顶向下的语法分析的文法设计难。我们必须要消除文法的左递归,即一个非终结符号推导出以整个非终结符号开头的符号串的情况。我们还必须提取左公因子--也就是对同一个非终结符号的具有相同的产生式体前缀的多个产生式进行分组。
*** 递归下降语法分析。
*** LL语法分析器
*** 移入-归约语法分析技术。整个也是自底向上的语法分析器,一般按照如下方式运行:根据下一个输入的符号(向前看符号)和栈中的内容,选择是将下一个输入移入栈中,还是将栈顶部的某些符号进行归约,归约的步骤将栈顶部的一个产生式体替换为这个产生式的头。
*** 可行前缀。在移入-归约语法分析中,栈中的内容总是一个可行前缀-也就是某个最右句型的前缀,且这个前缀的结尾不会比这个句型的句柄的结尾更靠右。句柄是在这个句型的最右推导过程中在最后一步加入此句型中的淄川。
*** 有效项。就是在产生式的体中某处加入一个点就得到一个项。其实就是一个。这个项对某个可行前缀有效的条件是该项的产生式被用来生成可行前缀对应的句型的句柄,且这个可行前缀中包括项中位与点左边的所有符号,但是不包含右边的认可符号。
*** LR语法分析器.
*** SLR简单的语法分析器。
*** 规范LR语法分析器
*** 向前看LR语法分析器
*** 二义性文法的自底向上语法分析。
*** Yacc。语法分析工具
*** Lex。前面一章有这个说明,是词法分析器。
//*************************语法制导的翻译***********************************//
1. 梗概:
本章将继续词法分析的主体。在第二章中讨论我们把一些属性附加到所代表语言构造的文法符号上,从而把信息和一个语言构造联系起来。语法制导定义通过与文法产生式相关语义规则来描述属性值。语法制导是描述词法分析中的属性值的。

其中E1下标表示是在产生体中出现的非终结符,对应E和E1可以看到都有对应的属性code值。
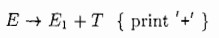
花括号都知道是表示语义动作的。对于作为文法符号出现的花括号,我们将用单引号把它们括起来,比如'{'和'}'。一个语义动作在产生体中的位置决定了这个动作的执行顺序。
1.1 L属性翻译和S属性翻译
L属性翻译,L代表从左到右的语法制导翻译方案,这一类方案实际上包含了所有可以在语法分析过程中完成的翻译方案。S代表综合,这类方案可以很容易和自底向上语法分析过程联系起来。
2. 语法制导定义
英文叫Syntax-Directed Definition,SDD,是一个上下文无关文法和属性及其规则的结合。这里注意第一个:Syntax和Grammar,前面叫语法,后面叫Grammar,这里找了一下翻译。Syntax一般指的是句法,也是句子的顺序,比较狭义。grammar比较广义,比如主谓宾等等。因此这里的语法制导用的Syntax指的是句子舒心的意思。因此在词法拆分就用这个比较多。对于像编译原理这类的学问,很多东西都用到了语言学当中的知识。
这个比较好理解。
平时大家观察我们的文件名的定义,比如aaa.txt。都要加一个·,这个点其实就是前面指的是符号,后面指的是属性code值,这里和我们平时习惯是一样的。后面关于属性定义很多用到点。
2.1 继承属性和综合属性。
1.继承属性(synthesized attribute):在分析树结点N上的非终结符号B的集成属性是由N的父结点上的产生式所关联的语义来定义的。
2.综合属性(inherited attribute):在分析树结点N上的非终结符号A的总和属性是由N上的产生式所关联的语义规定来定义的。
这个很像作用域的关系。
2.2 属性文法(attribute grammar)。一个属性文法的规则仅仅通过其他属性值和常量值来定义一个属性值。
2.3 在语法分析树的结点上对SDD求值
在语法分析树上进行求值有助于将SDD所描述的翻译方案可视化,虽然翻译器实际上不需要构建语法分析树。这里的语法分析树成为注释语法分析树(annotated parse tree)。

这些规则是循环定义的。不可能首先求出结点N上的A.s或N的子结点上的B.i中的一个值,然后再求出另一个值。一棵语法分析树的某个结点上的B.i中的一个值,然后再求出另一个值。一棵语法分析树的某个结点对上的A.s和B.i之间的循环依赖关系:
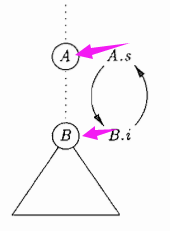
从计算的角度看,给定一个SDD,很难确定是否存在某棵语法分析树使得SDD的属性值之间具有循环依赖关系。幸运的是,存在一个SDD的有用子类,它们能够保证对每棵语法分析树都存在一个求值顺序。

3. 依赖图(dependency graph):
是一个有用的工具,它可以确定一棵给定的语法分析树中各个属性实例的求值顺序。依赖图描述了某个语法分析树中的属性实例之间的信息流。从一个属性实例到另一个实例的边表示计算第二个属性实例时需要第一个属性实例的值。
一个依赖图的流程图
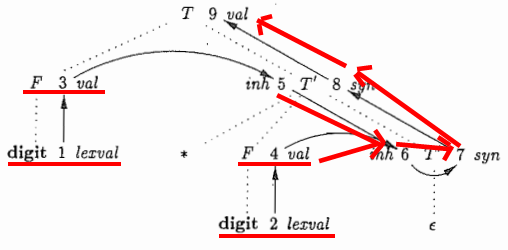
3.1 属性求值的顺序
依赖图刻画了对一棵语法分析树中不同结点上的属性求值时可能采取的顺序。如果依赖图中有一条从结点M到结点N的边,那么先要对M对应的属性求值,再对N对应的属性求值。这种排序规则叫做拓扑排序(topological sort):
因此,所有的可行求值顺序就是满足下列条件的结点顺序N1 ,N2,... Nk:如果有一条从结点Ni到Nj的依赖图的边,那么i<j。这样的排序将一个有向图编程了一个线性排序。
但是如果语法分析树对应的注释语法分析树存在任意一个环,那么就不存在拓扑排序。也就是说没有办法在这个棵语法分析树上对应的SDD求值。同样,如果图中没有环,那么总是至少存在一个拓扑排序。上图因为没有环,因此它的拓扑结构排序就是1到9。
4. S属性的定义
综合属性排序,在底向上练习起来。
因此S属性的定义如下:
*** 如果一个SDD的每个属性都是综合的,那么这个属性就是综合属性。上图的属性都是综合属性。S属性的定义可以在自底向上语法分析的过程中实现,因为一个自底上上的语法分析过程对应于第一次后续变量。后续顺序精确地对应一个LR分析器将一个产生体归约成为它的头的过程。
5. L属性的定义
第二种SDD称为L属性定义(L-attributed definition)。这类SDD的思想是在一个产生体所关联的各个属性之间,依赖图的边总是从左向右,而不能从右到左(因此成为L属性的)。更精确的讲,每个属性必须要么是
** 一个综合属性,要么是
** 一个集成属性。
假设存在一个产生式A → X1,X2 ... Xn,并且有一个通过这个产生式所关联的规则计算得到的继承属性Xi.a。那么这个规则只能使用:
1. 和产生式头A关联的继承属性。
2. 位于Xi左边的文法符号实例X1,X2...Xi-1 相关的继承属性或综合属性。
3. 和这个Xi的实例本身相关的基础属性或综合属性,但是在由这个Xi的全部属性组成依赖图中不存在环。
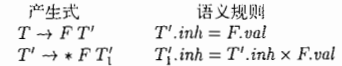
其实很好理解这里的T一撇指的是产生体内的非终结符。因此它的属性是L属性。(这都是第二章的定义)

这些都不是L属性。
5.1 关于受控副作用的语义规则
支持任何与依赖图一致的求值顺序,并允许语义动作包含任何程序片段。
按照下面多的方式来控制SDD中的副作用:
*** 支持那么不会对属性求值产生约束的附带副作用。换句话说,如果按照依赖图的任何拓扑顺序进行属性求值时可都可以产生“正确的”翻译结果,我们就允许副作用的存在。这里“正确”要视具体应用而定。
*** 对运行的求值顺序添加约束,使得以任何允许的顺序求值都会产生相同的翻译结果。这些约束可以被看做隐含加入到依赖图的边。
6. 语法制导翻译的应用
前面为了表达式构造语法树的SDD。第一个是S属性定义:他适合自底向上的语法分析过程中使用。
第二个是L属性定义,它适合在自顶向下的语法分析过程中使用。
6.1 抽象语法树的构造
每个结点代表一个程序构造,这个结点的子结点代表这个构造的有意义的组成部分。如果表达式E1 + E2的语法树结点的标号为 + ,且两个子结点分别代表子表达式E1和E2。我们将使用具有适当数量的字段的对象来实现一棵语法树的各个结点。每个对象将有一个op字段(可选字段),也就是整个结点的标号。
如果结点是一个叶子,那么Leaf(op,val)创建一个叶子对象。我们也可以把结点看做记录,那么Leaf就会返回一个指向与叶子结点对应的新记录的指针。
如果结点时内部结构,那么它的附加字段的个数和该结点再语法树中的子结点个数相同。构造函数Node带有两个或多个参数Node(op,c1,c2,...,ck),该函数创建一个对象,第一个字段的值为op,其余k个字段的值为c1...ck。
举例说明:

这是一个二目运算,只有+和-,具有相同的优先级,并且都是左结合,所有非终结符号都有一个综合属性node。每当使用第一个产生式1)时,它的语义规则就创建出一个结点。创建时使用 + 作为 op(选项),使用E1.node和t.node作为子表达式的两个子结点。第二个产生式也有类似的规则。继续往下看3)表达式:没有任何结点,因为E.node的值和E.node的值相同,因为括号仅仅用于分组。
6.2 类型的结构(数组类型)
以一个C语言为例子,类型int[2][3]可读作“由两个数组组成的数组”,子数组中有三个整数。相应的类型表达式为array(2,array(3,integer))可以有下图来表示:
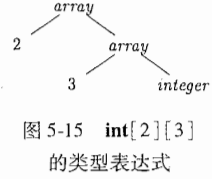

通过语义规则图看到,最终的T生成的是一个基本类型或一个数组类型。为什么这么说?
可以看到C→空串,空串的状态下,C.t = C.b,其中C.t可以看到上面的数组函数类型变为空串了。空串的话只有B.t的方式。为什么这么说C从上下文来说具有两个属性,一个是继承属性.b,一个是综合属性.t,这就是很好理解了。后面两个C的产生式 都可以推导出继承属性。继承属性b将是一个基本类型沿着树下船舶,而综合属性t将手机最终的结果。
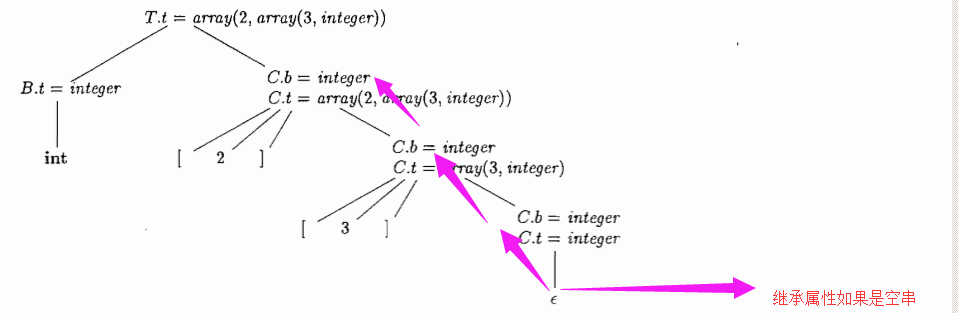
更详细的讲,在产生式T→BC对应的根结点上,非终结符号C使用继承属性C.b从B哪儿继承类型。
6.3 array类型表达式
第一个是数字,第二个是类型。
7. 产生式内部带有语义动作的SDT
动作可以放置在产生体中的任何位置上。当一个动作左边的所有符号都被处理过后,该动作立刻执行。

8. 对于任何SDT都可以按照下列方法实现。
1.忽略语义动作,对输入进行语法分析,并产生一棵语法分析树。
2.然后检查每个内部结点N,假设它的产生式时A→α,将α中的各个动作当做N的附加子结点加入,是的N的子结点从左到右和α中的符号及动作完全一致。
3.对语法树进行前序遍历,并且访问到一个以某个动作作为标号的结点时立刻执行这个动作。

9. 从SDT中消除左递归
增加一个新非终结符号R
10.再说左递归

左图是一个左递归,右图是消除左递归,这就明白啥叫左递归了。为什么要消除。
11.L属性定义SDT
我们将S属性的SDD转换成后缀SDT,它的动作位于产生式的右端。只要基础文法是LR的,后缀SDT就可以按照自底向上的方法进行语法分析和翻译。
将一个L属性的SDD转换为一个SDT的规则如下:
*** 排序
*** 产生体最右端。
举例1:排版的例子
12. 实现L属性的SDD
13. 总结:这一章其实叫做语义分析片段,前面组成为词法分析、语法分析、语义分析,语义分析最重要的一个概念就是动作
*** 继承属性和综合属性:语法制导的定义可以使用两种属性。一棵语法分析树结点上的总和属性根据该结点的子结点的属性计算得到。一个结点上的继承属性根据它的父结点或兄弟结点的属性计算得到。
*** 依赖图:给定一棵语法分析树和一个SDD,我们在各个语法分析树结点所关联的属性实例之间画上边,以指明位于边的头部的属性值要根据位于边的尾部的属性值计算得到。
*** 循环定义:在一个有问题的SDD中,我们发现存在一些语法分析树,无法找到一个顺序来计算所有结点上的所有属性值。这些语法分析树关联的依赖图中存在环。确定一个SDD是否存在这种带环的依赖图是非常困难的。
*** S属性定义:在一个S属性的SDD中,所有的属性都是综合的。
*** L属性定义:在一个L属性的SDD中,属性可能是继承的,也可能是综合的。然后,一个语法分析树结点上的继承属性只能够依赖于它的父结点的继承属性和位于它左边的兄弟结点的(任意)属性。
*** 抽象语法树:一棵抽象语法树中的每个结点代表一个构造;某个结点的子结点表示该结点所对应的构造时有意义的组成部分。
*** 实现S属性的SDD:一个S属性定义可以通过一个所有动作都在产生式尾部的SDT(后缀SDT)来实现。这些动作通过产生式体中的各个符号的总和属性来计算产生式头部的总和属性。如果基础文法是LR的,那么这个SDT可以在一个LR语法分析器的栈上实现。
*** 从SDT中消除左递归:如果一个SDT只有副作用(即不计算属性值),那么消除文法左递归的标准方法允许我们把语义动作当做终结符号移动到新文法中去。在计算属性时,如果这个SDT是后缀SDT,我们仍然能够消除左递归。
*** 用递归下降语法分析实现L属性的SDD:如果我们有一个L属性定义,且其基础文法可以用自顶向下的方法进行语法分析,我们就可以构造出一个不带回搠的递归下降语法分析以用自定向下的方法进行语法分析,我们就可以构造出一个不带回搠的递归下降语法分析器来实现这个翻译。集成属性变成了非终结符对应的函数的参数,而综合属性由该函数返回。
*** 实现LL文法之上的L属性的SDD:每个以LL文法为基础文法的L属性定义可以在语法分析过程中实现。用于存放一个非终结符号的综合属性的记录被放在栈中这个非终结符号之下,而一个非终结符号的继承属性和这个非终结符号存放在一起。栈中还防止了动作记录,一遍在适当的时候计算属性值。
*** 自底向上的方式实现一个LL文法之上的L属性SDD:一个以LL文法为基础文法的L属性定义可以转换成一个以LR文法为基础文法的翻译方案,且这个翻译可以自底向上语法分析过程一起执行。文法的转换过程中引入了“标记”非终结符号。这些符号出现在自底向上语法分析栈中,并保存了栈中位于它上方的非终结符号的集成属性。在栈中,综合属性和他的非终结符号放在一起。
//*************************中间代码生成***********************************//
1. 不同的编译器对中间表示的选择和设计各有不同。中间表示可以是一种真正的语言,也可以是由编译器的各个处理阶段共享的多个内部数据结构组成。
C语言是一种程序设计语言。它具有很好的灵活性和通用性,可以很方便的把C程序编译成高效的机器代码,并且有很多C的编译器可用。因此C语言也常常被用作中间表示。
(这句话很重要)。早期的C++编译器的前端生成C代码,而把C编译器作为后端。(这就很有意思了,有人经常说C语言是一个承上启下的语言,从编译的这个过程可以看到,C语言多数情况下是可以作为一个中间过程存在的,C的词法分析,语法分析,语义分析,是可以以C为蓝本作为中间过程的)。
2. 静态检查包括类型检查(type checking),加入,静态检验保证了C语言中的一条break指令比如位于while/for/Switch语句之内。
3. DAG(无环有向图):
一个DAG的叶子结点对应于原子分量,而内部结点对应于运算符。与语法数不同的是,如果DAG中的一个结点N表示一个公共子表达式,则N可能有多个父结点。在语法数中,公共子表达式每出现一次,代表该公共子表达式的子树就会被复制一次。
4.散列表(哈希表):
三元组<op,l,r>,op在数组中搜索标号,左子结点为l且右子节点为r的结点M。
如果存在这样的结点,则返回M结点的值编码。若不存在这样的结点,则在数组中添加一个结点N,其标号为op,左右子结点分别为l和r,返回新建结点对应的值编码。
比如字典dictionary,要建立散列函数,h<op,l,r>,一个散列值索引的数组保存桶的头bucket header,每个头指向列表中的第一个单元。一个桶的链表中,链表的各个单元记录了某个被散列函数分配到此桶中的某个结点的值编码。
5. 三地址代码
5.1 地址和指令
名字。为方便起见,我们允许远程的名字作为三地址代码中的地址。
常量。在实践中,编译器往往要处理很多不同类型的常量和变量。
编译器生成的临时变量。在每次需要临时变量时产生了一个新名字是必要的,在优化编译器中更是如此。
5.2 三元式、四元式、间接三元式
5.4 静态单赋值形式(SSA)是另一种中间表达形式,它有利于实现某些类型的代码优化。
6. 类型和声明:
类型检查(type checking)。类型检查利用一组逻辑规则来推理一个程序在运行时刻的行为。
翻译时的应用(translation application)。根据一个名字类型,编译器可以确定这个名字在运行时刻需要多大的存储空间。
6.1 类型表达式(type expression)
6.2 类型等价
两个类型表达式什么时候等价呢?很多类型检查规则具有这样的形式,“如果两个类型表达式相等,那么返回某种类型,否则出错”
结构等价(structurally equivalent):
它们是相同的基本类型。
它们是将相同的类型构造算子应用于结构等价的类型而构造得到。
一个类型是另一个类型表达式名字。
6.3 局部变量名的存储布局
*** 地址对齐:aligned
在相关关于内存的存储当中都提到这个对齐。
这里有三个概念,对齐aligned,补白padding,压缩pack
以前内存空间比较宝贵的时候,一般会用压缩的方式pack
将整数相加的指令往往希望整数能够对齐,也就是说,希望它们被存放在内存中的特定位置上,比如地址能够被4整除的位置上。虽然一个有10个字符的数组只需要足够存放10个字符的字节空间,但编译器常常会给它分配12个字节,下面的2个字节没有被使用,要进行补白的方式。
6.4 声明的序列
像C和Java这样的语言支持将单个过程中的所有声明作为一组进行处理。这些声明可能分布在一个Java过程中,但是仍然能够在分析该过程中处理它们。因此,我们可以使用一个变量,比如offset,来跟踪下一个可用的相对地址。其实这里还有一个相对地址和绝对地址的问题。地址还分为偏移地址+逻辑地址两个部分。在汇编当中一般用cs,ip两个符号表示。
6.5 记录和类中的字段。
一个记录中各个字段的名字必须是互不相同的。也就是说,在由D生产的声明中,同一个名字最多出现一次。
字段名的偏移量,或者相对地址,是相对于该记录的数据区字段而言。
7. 表达式的翻译
7.1 表达式中的运算
E.addr:表示存放E的值的地址
E.code:表示S对应的三地址代码。
7.2 gen函数:表示三段地址代码
gen(x' = ' y' + 'z),来表示三地址命令x = y + z。当被传递给gen时,变量x,y,z的位置上出现表达式将首先被求值,而像' = '这样的引号内的字符串则按照字面值传递。其实这函数应该理解为子函数。
7.3 增量翻译
code属性可能是很长的字符串,因此就像前面讨论的那样,它们通常是用增量的方式生成的。,gen不仅要构造出一个新的三地址指令,还要将它添加到至今为止已生成的指令序列滞后。
E → E1 + E2的予以动作使用构造算子生成新的结点,规则如下:
E → E1 + E2{E.addr = new Node('+', E1.addr,E2.addr);}
这里,属性addr表示的是一个结点的地址,而不是某个变量或常量。
7.4 数组元素的寻址
7.5 base函数:
分配给数组的内存块的相对地址,也就是说,base是A[0]的相对地址
7.6 数组引用的翻译:
L.addr指示一个临时变量
L.array是一个指向数组名字对应的符号表条目的指针
L.type是L生成的子数组的类型。
举例:
L.array.base[L.addr],
L.array给出数组名。L.array.base给出数组的基地址。属性L.addr表示保存偏移量的临时变量。
数组引用的代码将存放在由基地址和偏移量给出的位置中的右值放入E.addr所指的临时变量中。
8. 类型检查
为了进行类型检查,编译器需要给源程序的每一个组成部分赋予一个类型表达式。然后,编译器要确定这些类型表达式是否满足一组逻辑规则。这些规则成为源语言的类型系统(type system)。
类型检查具有发现程序中的错误的潜能。原则上,如果目标代码在保存元素值的同时保存了元素类型的信息,那么任何检查都可以动态进行。
一个健全(sound)的类型系统可以消除对动态类型错误检查的需要,因为它可以帮助我们静态的确定这些错误不会再目标程序运行时候发生。如果编译器可以保证它接受的程序在运行时刻不会发生类型错误,那么该语言的这个实现就被成为强类型。
8.1 类型检查规则
类型检查有两种形式:综合和推导。类型综合*type synthesis,根据子表达式的类型构造出表达式的类型。它要求名字先声明再使用。
类型推导(type inference)根据一个语言结构的使用方式来确定该结构的类型。

8.2 类型转换
t1 = (float)2
t2=t1 * 3.14
这里2被转换成浮点型。
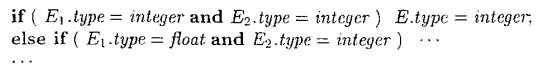
随着需要转换的类型的增多,需要处理的不同情况也急剧增多。因此,在处理大量的类型时,精心组织用于类型转换的语义动作就变得非常重要。
*** Java转换规则区分:
拓宽(widening)转换:保持原有信息
窄化(narrowing)转换:可能丢失信息
隐式转换(coercion):自动完成
显式转换cast:强制类型转换,程序员完成

8.3 多台函数的类型推导
9. 控制流
*** 改变控制流
*** 计算逻辑值
9.1 布尔表达式
9.2 短路代码
10. 回填
为布尔表达式和控制流语句生成目标代码时,关键问题之一是将一个跳转指令和该指令的目标匹配起来。例如,对if(B)S中的布尔表达式B的翻译结果中包含了一条跳转指令。当B为假时,该指令跳转到紧跟在S的代码之后的指令处。在一趟式翻译的过程中,B必须在处理S之前就翻译完毕。那么跳过S的goto指令的目标是什么呢?
本节将介绍一种被称为回填(backpatching)的补充性技术,它把一个由跳转指令组成的列表以综合属性的形式进行船体。明确的将,生成一个跳转指令时暂时不指定该跳转指令的目标。这样的指令都被放入一个由跳转指令注册的列表中。等到能够确定正确的目标标号时才去填充这些指令的目标标号。
10. truelist属性 和 falselist属性
用来管理布尔表达式跳转代码中的标号。特别的,B.truelist将是一个包含跳转或条件跳转指令的列表,我们必须向这些指令中插入适当的标号,也就是当B为真时控制流应当装修的标号。B.falselist也是一样。
11. 新的三个函数
*** makelist(i):创建一个只包含i的列表。这里i是指令数组的下标。函数返回一个指向新创建的列表的指针。
*** merge(p1,p2):将p1和p2指向的列表进行合并,它返回的指针指向合并后的列表。
*** backpatch(p,i):将i作为目标标号插入到p所指列表中的各指令中。
12.布尔表达式的回填
13. 控制转换语句
14. break语句、continue语句和goto语句
比如在C语言中,像goto L这样的语句将控制流转到标号为L的命令——在相应作用域内必须恰好存在一条标号为L的语句。在实现goto语句时,可以为每个标号维护一个未完成跳转指令的列表,然后在知道这些指令的目标之后进行回填。
在Java语言中废除了goto语句。但是Java支持一种规范化的跳转语句,即break语句。它使控制流跳转出外围的语言结构。Java中还可以使用continue语句。这个语句的作用是除法外围循环的下一轮迭代。
上面的这个例子:
如果S表示外围的循环结构,那么一条break语句就是跳转到S代码之后第一条指令处的跳转指令。我们可以按照下面的步骤为break生成代码:
1.跟踪外围循环语句S,
2. 为该break语句生成未完成的跳转指令
3.将这些指令放到S.nextlist中,其中nextlist就是列表。
continue语句的处理方法和break语句的处理方法类似。两者之间的主要区别在于生成跳转指令的目标不同。
我们可以在符号表中将一个特殊的标识符break映射到为表示外围循环语句S的结点,以此来跟踪S。这种方法同样可以处理Java中带标号的break语句,因为同样 可以用符号表来将这个标号映射为对应的标号所指的结构的语法树结点。
15. switch语句
很多语言都使用switch 或者 case语句。一般这个是组合用。对于这个语句的翻译如下:

1. 计算表达式E的值
2.在case列表中寻找与表达式值相同的值Vj。回顾一下,当在case列表中明确列出的值都不和表达式匹配时,就用默认值和表达式匹配
3.执行和匹配值关键的语句Sj。
为了更高效,可以用散列表(哈希表)来找到对应的switch表达式的值的条目,就会有一条跳转指令转到默认语句。
16. 过程的中间代码(这里只是讨论属于“函数”来表示带有返回值的过程):
函数类型。一个函数类型必须包含它的返回值类型和形式参数类型。当然返回值可以为空
符号表。在设编译器处理到一个函数定义时,最上层的符号表为s。
17.总结:
*** 选择一个中间表示形式:中间表示形式通常是一个图形表示方式和三地址代码的组合。
*** 翻译表达式:通过在各个形如 E → E1 op E2 的产生式中加入语义动作,带有复杂运算的表达式可以被分解成一个由单一运算组成的序列。
*** 检查类型:一个表达式E1 op E2的类型是由运算符op以及E1和E2的类型巨鼎的。自动类型转换叫做隐式转换,例如从integer整型转换到float。还有一种叫显式转换也叫强子转换。
*** 使用符号表来实现声明:一个声明指定了一个名字的类型。一个类型的宽度是指存放该类型的变量所需要的存储空间。使用宽度,一个变量在运行时刻的相对地址可以计算为相对于某个数据区域的开始地址的偏移量。
*** 将数组扁平化:为实现快读访问,数组元素村房子啊一段连续的空间内。数组的数组可被扁平化,当做各个元素的一维数组进行处理。数组的类型用于计算一个数组元素相对于数组基地址的偏移量。
*** 为布尔表达式产生跳转代码:在短路(或者说跳转)代码中,布尔表达式的值被隐含在代码所到达的位置中。一万布尔表达式B常常被用于决定控制流,例如在if(B)中就是这样,因此跳转指令是有用的。
*** 用控制流实现语句:通过集成next标号就可以实现语句的翻译,其中next标记了这个语句的代码之后的第一条指令。翻译条件语法S→if(B)S1时,只需要将第一个标记S1的代码其实位置的新标号和S.next分别作为B的真值出口和假值出口传递给其他处理程序。
*** 可以选择使用回填技术:回调是一种布尔表达式和语句进行一趟式代码生成的技术。
*** 实现记录:记录和类中的字段名可以当做声明序列进行处理。一个记录类型包含了关于它的各个域的类型和相对地址的信心。可以使用一个符号表对象来实现这个目的。
//*************************运行时刻环境***********************************//
1. 为了做到这一点,编译器创建并管理一个运行时刻环境(run-time environment),它编译得到的目标程序就运行在这个环境中。这个环境处理很多事物,包括在为源程序中命名的对象分配和安排存储位置,确定目标程序访问变量时使用的极值,过程间的链接,参数传递机制,以及操作系统、IO设备以及其他程序接口。
2. 存储组织(这个位置主要讲的是内存)
*** 从编译器编写者的角度来看,正在执行的目标程序在它自己的逻辑地址空间内运行,其中每个程序值都在这个空间中有一个地址。对这个逻辑地址的空间管理和组织是由编译器、操作系统和目标机共同完成的。操作系统将逻辑地址映射为物理地址,而物理地址对整个内存空间编址。
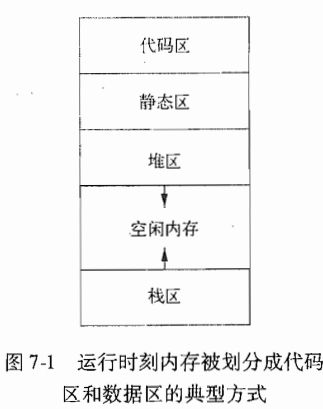
*** 下图是:运行时刻内存被划分成代码去和数据区的典型方式。
*** 一个名字所需要的存储空间大小是由它的类型决定的。基本数据类型,比如字符、整数、浮点可以存储在整数个字节中。聚合数据类型,比如数组或者字典或者结构的存储空间大小必须足以存放这个类型的所有分量。
*** 数据对象的存储布局受目标机的寻址约束的影响很大。在很多机器中,执行整数加法的指令可能需要整数时对齐的,也就是说这些数必须被放在一个能够被4整除的地址上。尽管C语言或者类似的语言中一个有10个字符的数组只需要能够存放10个字符的空间,但是编译器可能为了对齐而给它分配12个字节,其中的两个字节未使用。因为对齐的原因而产生的闲置空间成为补白padding。如果空间比较紧张,编译器可能会压缩数据以消除补白。但是,在运行时刻可能需要额外的指令来定位被压缩数据,使得机器在操作这些数据时就好像它们是对其的。
*** 生成的目标代码的大小在编译时刻就已经固定下来了,因此编译器可以将可执行目标代码放在一个静态确定区域:代码区。
*** 代码区:这个区通常位于存储的底端。
*** 静态区:放置在这个区域的数据对象包括全局变量和编译器产生的数据,比如用于支持垃圾回收的信息等。
之所以将尽可能多的数据对象进行静态分配,是因为这些对象的地址可以被编译到目标代码中。在fortran早期的版本中,所有数据对象都可以进行静态分配。
*** 堆和栈:被放在剩余地址空间的相对两段。这些区域是动态的,他们的大小会随着程序运行而改变。这两个区域根据需要向对方增长。栈区用来存放称为活动记录的数据结构,这些活动记录在函数调用过程中生成。在实践中,栈向较低地方增长,而堆向较高地方增长。
*** 很多程序设计语言支持程序员通过程序控制人工分配和回收数据对象。例如,C语言中的malloc和free函数就可以用来获取和释放任意存储块。堆区被用来管理这种具有长生命周期的数据。
*** 静态存储分配(static)和动态存储分配(dynamic)
*** 栈式存储:一个过程的局部名字在栈中分配空间。
*** 堆存储:有些数据的声明周期要比创造它的某次过程调用更长,这些数据通常被分配在一个可复用存储的堆中。
后面会讲到栈管理和堆管理两大部分,对于其他语言尤其是C语言这种权限比较高的语言,对于内存的理解是比较重要的。
3. 空间的栈式分配:
有些语言使用过程、函数或方法作为用户自定义动作的单元,几乎所有针对这些语言的编译器都把他们(至少一部分)运行时刻存储按照一个栈进行管理。每当一个过程被调用时,用于存放该过程的局部变量的空间被压入栈;当这个过程结束时,该空间被弹出这个栈。我们将看到,这种安排不仅运行活跃时段不交叠的多个过程调用之间共享空间,而且运行我们以如下方式作为编译代码:它的非局部变量的相对地址总是固定和过程调用的序列无关。
3.1 活动树
加入过程调用(或者说过程的活动)在时间上不是嵌套的,那么栈式分配就不可行了。下面例子说明栈的调用:

该程序将9个整数读入到一个数组a,并使用递归的快速排序算法对这些整数排序。
1. q的该次活动正常结束,俺么基本上在任何语言中,控制流从p中调用q的点之后继续。
2. q的该次活动(或q调用的某个过程)直接或间接的中止了,也就是说不能再继续执行了。在这种情况下,q和p同时结束。
3.q的该次活动因为q不能处理的某个异常而结束。
因此,我们可以用一棵树来表示在整个程序运行期间的所有过程的活动,这棵树称为活动树(activation tree)。树中的每个结点对应于一个活动,根节点的启动程序执行main过程的活动。
3.2 readArray函数
仅用于将数据加载到数组a中。数组a的第一个和最后一个元素没有用于存放输入数据,而用于存放主函数中设定的“限值”。假定我们a[0]被设为小于所有可能输入数据值的值,而a[10]被设为大于所有数据值的值。
3.3 partition函数
函数partition对数组中第m个元素到第n个元素的部分进行分割,使得a[m]到a[n]之间的小元素存放在前面,而大的元素存放在尾部,但是这两组内部不一定是排好序的。
3.4 quicksort函数
递归过程quicksort首先确定它是否需要对多个数组元素进行排序。
4. 活动记录
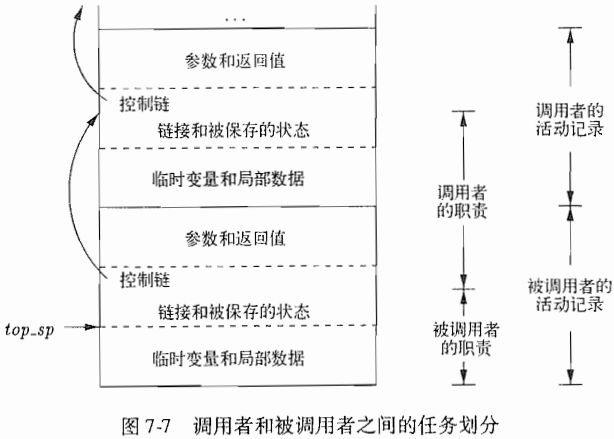
过程调用和返回通常由一个称为控制栈(control stack)的运行时刻栈进行管理。每个活跃的活动都有一个位于控制栈中的活动记录(activation record,有时也称为帧frame)。活动树的根位于栈底,栈中全部活动记录的序列对应于在活动树中到达当前控制所在的活动结点的路径。控制程序所在的活动记录位于栈顶。
列举可能出现在一个活动记录中的各种类型的数据:
1. 临时值。比如当表达式求值过程中产生的中间结果无法存放在寄存器中时,就会生成这些临时值。
2. 对应于这个活动记录的过程的局部数据。
3. 保存的机器状态,其中包括对此过程的此次调用之前的机器状态信息。这些信息通畅柏阔返回地址(程序计数器的值,被调用过程必须返回到该值所指位置)和一些寄存器中的内容(调用过程会使用这些内容,被调用过程必须在返回时回复这些内容)。
4. 一个“访问链”。当被调用国产需要其他地方(比如另一个活动记录)的某个数据是访问链进行定位。
5. 一个控制链(control link),指向调用者的活动记录。
6.当被调用函数有返回值时,要有一个用于存放这个返回值的空间。不是所有的被调用过程都有返回值,即使有,我们也可能倾向于将该值放到一个寄存器中提高效率。
7.调用过程使用的是在参数(actual parameter)。这些值通常将尽可能的放在寄存器中,而不是放在活动记录中,因为存放在寄存器中会得到更好的效率。
下图是一个向下增长的活动记录栈

5. 调用代码序列
实现过程调用的代码段成为调用代码序列(calling sequence)。这个代码序列为一个活动记录在栈中分配空间,并在此记录的字段中填写信息。返回代码序列(return sequence)是一段类似的代码,他回复机器状态,使得调用过程能够在调用结束之后继续执行。
6. 栈中的变长数据

7. 栈中非局部数据的访问
//************************代码生成***********************************//
1. 本章目录:
** 代码生成器设计中的问题
** 目标语言
** 目标代码中的地址
** 基本块和流图
** 基本块的优化
** 一个简单的代码生成器
** 窥孔优化
** 寄存器分配和指派
** 通过树重写来选择指令
** 表达式的优化代码的生成
** 使用动态规划的代码生成
//*************************机器无关优化***********************************//
//*************************指令级并行***********************************//
//*************************并行性和局部性优化***********************************//
//*************************过程间分析***********************************//
- 编译原理-词法分析05-正则表达式到DFA-01
编译原理-词法分析05-正则表达式到DFA 要经历 正则表达式 --> NFA --> DFA 的过程. 0. 术语 Thompson构造Thompson Construction 利用ε ...
- 跟vczh看实例学编译原理——三:Tinymoe与无歧义语法分析
文章中引用的代码均来自https://github.com/vczh/tinymoe. 看了前面的三篇文章,大家应该基本对Tinymoe的代码有一个初步的感觉了.在正确分析"print ...
- 跟vczh看实例学编译原理——二:实现Tinymoe的词法分析
文章中引用的代码均来自https://github.com/vczh/tinymoe. 实现Tinymoe的第一步自然是一个词法分析器.词法分析其所作的事情很简单,就是把一份代码分割成若干个tok ...
- 跟vczh看实例学编译原理——一:Tinymoe的设计哲学
自从<序>胡扯了快一个月之后,终于迎来了正片.之所以系列文章叫<看实例学编译原理>,是因为整个系列会通过带大家一步一步实现Tinymoe的过程,来介绍编译原理的一些知识点. 但 ...
- 跟vczh看实例学编译原理——零:序言
在<如何设计一门语言>里面,我讲了一些语言方面的东西,还有痛快的喷了一些XX粉什么的.不过单纯讲这个也是很无聊的,所以我开了这个<跟vczh看实例学编译原理>系列,意在科普一些 ...
- 编译原理-词法分析04-NFA & 代码实现
编译原理-词法分析04-NFA & 代码实现 0.术语 NFA 非确定性有穷自动机nondeterministic finite automation. ε-转换ε-transition 是无 ...
- .NET程序的简单编译原理
1.不管是什么程序,最终的执行官是CPU,而CPU只认识1和0的机器码. 2.我们现在写的一般是高级语言写的程序.CPU是不认识我们用高级语言写的源代码的,那应该怎么办才能让CPU执行我们写好的程序尼 ...
- Atitit.编译原理与概论
Atitit.编译原理与概论 编译原理 词法分析 Ast构建,语法分析 语意分析 6 数据结构 1. ▪ 记号 2. ▪ 语法树 3. ▪ 符号表 4. ▪ 常数表 5. ▪ 中间代码 1. ▪ 临 ...
- 编译原理简单语法分析器(first,follow,分析表)源码下载
编译原理(简单语法分析器下载) http://files.cnblogs.com/files/hujunzheng/%E5%8A%A0%E5%85%A5%E5%90%8C%E6%AD%A5%E7%AC ...
随机推荐
- 汉诺塔(思维、DP思想)
链接:https://ac.nowcoder.com/acm/contest/3007/C来源:牛客网 题目描述 现在你有 N 块矩形木板,第 i 块木板的尺寸是 Xi*Yi,你想用这些木板来玩汉诺塔 ...
- RCE
RCE remote command/code execute 远程系统命令/代码执行 系统从设计上需要给用户提供指定的远程命令操作的接口.可以测试一下自动运维平台. 在PHP中,使用system.e ...
- 吴裕雄--天生自然C++语言学习笔记:C++ 数据类型
使用编程语言进行编程时,需要用到各种变量来存储各种信息.变量保留的是它所存储的值的内存位置.这意味着,当创建一个变量时,就会在内存中保留一些空间. 可能需要存储各种数据类型(比如字符型.宽字符型.整型 ...
- aced六类股票问题
一.状态转移框架 在我们刷题的过程中,很多同学肯定会遇到股票问题这类题目,股票问题有很多种类型,大多数同学都知道要用动态规划去做,但是往往写不对状态转移方程,我刚接触这类问题时也是一头雾水,但是掌握了 ...
- Day 8:方法上自定义泛型、类上、接口上、泛型的上下限
泛型 泛型是jdk1.5使用的新特性 泛型的好处: 1. 将运行时的异常提前至了编译时 2. 避免了无谓的强制类型转换 泛型在集合中的常见应用: ArrayList<Strin ...
- axios基础介绍
axios基础介绍 get请求要在params中定义,post要在data中定义.
- javaScript_BOM浏览器对象模型
BOM:浏览器对象模型 Browser Object Model 用来访问和操作浏览器窗口,使JavaScript有能力与浏览器对话 通过使用BOM ,可以移动窗口,更改状态栏.执行其他不与页面内容发 ...
- mysql数值类型总结及常用函数
最近在学习下,总结一下mysql数值类型: mysql字符类型分: 1.整数类型: 字节 值范围 INTERGER 1 ...
- 创建简单spring boot项目
简介 使用spring boot可以轻松创建独立的,基于Spring框架的生产级别应用程序.Spring boot应用程序只需要很少的spring配置 特点 创建独立的Spring应用程序 直接嵌入t ...
- Java线程——线程之间的死锁
一,什么是死锁? 所谓的死锁是指多个线程因为竞争资源而造成的一种僵局(相互等待),若无外力的作用,这些进程都不能向前推进. 二,死锁产生的条件? (1)互斥条件:线程要求对所分配的资源(如打印机)进行 ...