Python---4字符串与编码
字符编码
字符串比较特殊的是还有一个编码问题。
因为计算机只能处理数字,如果要处理文本,就必须先把文本转换为数字才能处理。最早的计算机在设计时采用8个比特(bit)作为一个字节(byte),所以,一个字节能表示的最大的整数就是255(二进制11111111=十进制255),如果要表示更大的整数,就必须用更多的字节。比如两个字节可以表示的最大整数是65535,4个字节可以表示的最大整数是4294967295。
由于计算机是美国人发明的,因此,最早只有127个字符被编码到计算机里,也就是大小写英文字母、数字和一些符号,这个编码表被称为ASCII编码,比如大写字母A的编码是65,小写字母z的编码是122。
但是要处理中文显然一个字节是不够的,至少需要两个字节,而且还不能和ASCII编码冲突,所以,中国制定了GB2312编码,用来把中文编进去。
你可以想得到的是,全世界有上百种语言,日本把日文编到Shift_JIS里,韩国把韩文编到Euc-kr里,各国有各国的标准,就会不可避免地出现冲突,结果就是,在多语言混合的文本中,显示出来会有乱码。
因此,Unicode应运而生。Unicode把所有语言都统一到一套编码里,这样就不会再有乱码问题了。
Unicode标准也在不断发展,但最常用的是用两个字节表示一个字符(如果要用到非常偏僻的字符,就需要4个字节)。现代操作系统和大多数编程语言都直接支持Unicode。
现在,捋一捋ASCII编码和Unicode编码的区别:ASCII编码是1个字节,而Unicode编码通常是2个字节。
字母A用ASCII编码是十进制的65,二进制的01000001;
字符0用ASCII编码是十进制的48,二进制的00110000,注意字符'0'和整数0是不同的;
汉字中已经超出了ASCII编码的范围,用Unicode编码是十进制的20013,二进制的01001110 00101101。
你可以猜测,如果把ASCII编码的A用Unicode编码,只需要在前面补0就可以,因此,A的Unicode编码是00000000 01000001。
新的问题又出现了:如果统一成Unicode编码,乱码问题从此消失了。但是,如果你写的文本基本上全部是英文的话,用Unicode编码比ASCII编码需要多一倍的存储空间,在存储和传输上就十分不划算。
所以,本着节约的精神,又出现了把Unicode编码转化为“可变长编码”的UTF-8编码。UTF-8编码把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节。如果你要传输的文本包含大量英文字符,用UTF-8编码就能节省空间:
| 字符 | ASCII | Unicode | UTF-8 |
|---|---|---|---|
| A | 01000001 | 00000000 01000001 | 01000001 |
| 中 | x | 01001110 00101101 | 11100100 10111000 10101101 |
从上面的表格还可以发现,UTF-8编码有一个额外的好处,就是ASCII编码实际上可以被看成是UTF-8编码的一部分,所以,大量只支持ASCII编码的历史遗留软件可以在UTF-8编码下继续工作。
搞清楚了ASCII、Unicode和UTF-8的关系,我们就可以总结一下现在计算机系统通用的字符编码工作方式:
在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。
用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件:

浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器:

所以你看到很多网页的源码上会有类似<meta charset="UTF-8" />的信息,表示该网页正是用的UTF-8编码。
Python的字符串
在最新的Python 3版本中,字符串是以Unicode编码的,也就是说,Python的字符串支持多语言,例如:
>>> print('包含中文的str')
包含中文的str
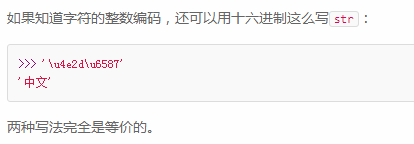
对于单个字符的编码,Python提供了ord()函数获取字符的整数表示,chr()函数把编码转换为对应的字符:
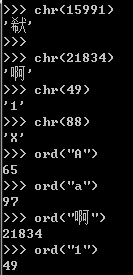
由于Python的字符串类型是str,在内存中以Unicode表示,一个字符对应若干个字节。如果要在网络上传输,或者保存到磁盘上,就需要把str变为以字节为单位的bytes。
Python对bytes类型的数据用带b前缀的单引号或双引号表示:
x = b'ABC'
要注意区分'ABC'和b'ABC',前者是str,后者虽然内容显示得和前者一样,但bytes的每个字符都只占用一个字节。
以Unicode表示的str通过encode()方法可以编码为指定的bytes,例如:

纯英文的str可以用ASCII编码为bytes,内容是一样的,含有中文的str可以用UTF-8编码为bytes。含有中文的str无法用ASCII编码,因为中文编码的范围超过了ASCII编码的范围,Python会报错。
在bytes中,无法显示为ASCII字符的字节,用\x##显示。
反过来,如果我们从网络或磁盘上读取了字节流,那么读到的数据就是bytes。要把bytes变为str,就需要用decode()方法:
>>> b'ABC'.decode('ascii')
'ABC'
>>> b'\xe4\xb8\xad\xe6\x96\x87'.decode('utf-8')
'中文'
如果bytes中包含无法解码的字节,decode()方法会报错:

如果bytes中只有一小部分无效的字节,可以传入errors='ignore'忽略错误的字节:
>>> b'\xe4\xb8\xad\xff'.decode('utf-8', errors='ignore')
'中'
要计算str包含多少个字符,可以用len()函数:
>>> len('ABC')
3
>>> len('中文')
2
len()函数计算的是str的字符数,如果换成bytes,len()函数就计算字节数:
>>> len(b'ABC')
3
>>> len(b'\xe4\xb8\xad\xe6\x96\x87')
6
>>> len('中文'.encode('utf-8'))
6
可见,1个中文字符经过UTF-8编码后通常会占用3个字节,而1个英文字符只占用1个字节。
在操作字符串时,我们经常遇到str和bytes的互相转换。为了避免乱码问题,应当始终坚持使用UTF-8编码对str和bytes进行转换。
由于Python源代码也是一个文本文件,所以,当你的源代码中包含中文的时候,在保存源代码时,就需要务必指定保存为UTF-8编码。当Python解释器读取源代码时,为了让它按UTF-8编码读取,我们通常在文件开头写上这两行:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
第一行注释是为了告诉Linux/OS X系统,这是一个Python可执行程序,Windows系统会忽略这个注释;
第二行注释是为了告诉Python解释器,按照UTF-8编码读取源代码,否则,你在源代码中写的中文输出可能会有乱码。
申明了UTF-8编码并不意味着你的.py文件就是UTF-8编码的,必须并且要确保文本编辑器正在使用UTF-8 without BOM编码:

如果.py文件本身使用UTF-8编码,并且也申明了# -*- coding: utf-8 -*-,打开命令提示符测试就可以正常显示中文:

格式化
最后一个常见的问题是如何输出格式化的字符串。我们经常会输出类似'亲爱的xxx你好!你xx月的话费是xx,余额是xx'之类的字符串,而xxx的内容都是根据变量变化的,所以,需要一种简便的格式化字符串的方式。
在Python中,采用的格式化方式和C语言是一致的,用%实现,举例如下:

%运算符就是用来格式化字符串的。
在字符串内部,%s表示用字符串替换,%d表示用整数替换,有几个%?占位符,后面就跟几个变量或者值,顺序要对应好。如果只有一个%?,括号可以省略。



常见的占位符有:
| 占位符 | 替换内容 |
|---|---|
| %d | 整数 |
| %f | 浮点数 |
| %s | 字符串 |
| %x | 十六进制整数 |
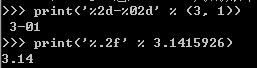
其中,格式化整数和浮点数还可以指定是否补0和整数与小数的位数:
如果你不太确定应该用什么,%s永远起作用,它会把任何数据类型转换为字符串:
>>> 'Age: %s. Gender: %s' % (25, True)
'Age: 25. Gender: True'
有些时候,字符串里面的%是一个普通字符怎么办?这个时候就需要转义,用%%来表示一个%:
>>> 'growth rate: %d %%' % 7
'growth rate: 7 %'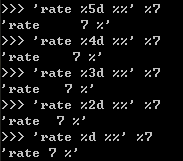
format()
另一种格式化字符串的方法是使用字符串的format()方法,它会用传入的参数依次替换字符串内的占位符{0}、{1}……,不过这种方式写起来比%要麻烦得多:
>>> 'Hello, {0}, 成绩提升了 {1:.1f}%'.format('小明', 17.125)
'Hello, 小明, 成绩提升了 17.1%'
Python---4字符串与编码的更多相关文章
- python基础——字符串和编码
python基础——字符串和编码 字符串也是一种数据类型,但是,字符串比较特殊的是还有一个编码问题. 因为计算机只能处理数字,如果要处理文本,就必须先把文本转换为数字才能处理.最早的计算机在设计时采用 ...
- python基础——字符串、编码、格式化
1.三种编码:ascii Unicode utf8 2.字符串和编码数字的两个函数:ord(字符转数字ord(‘A’)=65)和 chr(数字转字符chr(65)=A) 3.bytes存储编码,记住两 ...
- Python基础(字符串和编码)
字符编码 我们已经讲过了,字符串也是一种数据类型,但是,字符串比较特殊的是还有一个编码问题. 因为计算机只能处理数字,如果要处理文本,就必须先把文本转换为数字才能处理.最早的计算机在设计时采用8个比特 ...
- 六 Python基础 字符串和编码
字符编码 我们已经讲过了,字符串也是一种数据类型,但是,字符串比较特殊的是还有一个编码问题. 因为计算机只能处理数字,如果要处理文本,就必须先把文本转换为数字才能处理.最早的计算机在设计时采用8个比特 ...
- Learning Python 005 字符串和编码
Python 字符串和编码 介绍 计算机是美国人发明的,最早只有127个字母被编码到计算机,这个编码表被称为ASCII编码,比如大写字母A的编码是65,小写字母z的编码是122. 处理中文一个字节显然 ...
- Python的字符串和编码
1. 字符编码 字符串也是一种数据类型,但是,字符串比较特殊的是还有一个编码问题. 因为计算机只能处理数字,如果要处理文本,就必须先把文本转换为数字才能处理.最早的计算机在设计时采用8个比特(bit) ...
- python中字符串的编码和解码
1. 常用的编码 ASCII:只能表示一些字母,数字和特殊的字符,占一个字节 GBK:国家简体中文字符集和繁体字符集,兼容ASCII,占两个字节 Unicode:能够表示全世界上所有的字符,Unico ...
- python 改变字符串的编码方式
字符串str的编码方式为utf-8,转化为gbk,分为两步 1. str=str.decode('utf-8') 2. str=str.encode('gbk')
- Python字符串的编码与解码(encode与decode)
首先要搞清楚,字符串在Python内部的表示是unicode编码,因此,在做编码转换时,通常需要以unicode作为中间编码,即先将其他编码的字符串解码(decode)成unicode,再从unico ...
- python语言学习8——字符串和编码
Unicode编码 计算机只能处理数字,如果要处理文本,就必须把文本转化为数字才能处理 有许多编码标准,但是不同的编码标准有时候会混乱,所以Unicode应运而生 Unicode把所有语言统一到一套编 ...
随机推荐
- flask web实战1.27
1.在pycharm的terminal中输入 生成requirements.txt文件 pip freeze > requirements.txt 安装requirements.txt依赖 pi ...
- PANIC: ANDROID_SDK_HOME is defined but could not find Nexus_5_API_23.ini file in $ANDROID_SDK_HOME\
运行模拟器总是出现这个错误 后来把系统环境变量中的ANDROID_SDK_HOME 删掉就好了 我去,好神奇的操作
- BTree
hash.平衡二叉树.BTree.B+tree的区别 https://blog.csdn.net/qq_40673786/article/details/90082444 联合索引在B+树上的结构介绍 ...
- Android开发学习1----AndroidStudio的安装、创建第一个Android Studio文件、Android Studio界面介绍和HelloWord!
移动开发的工具有很多:Android Studio,eclipse,Hbuilder等,其中,现如今最火的开发工具是Android Studio,Android Studio是谷歌自己推出的一款集成开 ...
- 2017NOIP模拟赛三 A酱的体育课
据说改编自$CodeM 美团点评编程大赛初赛A 轮$ 简单的水题...考试的时候没想到,xjb打了暴力. 显然,第$x$个人排在第$y$个位置的情况总数为$(n-1)!$,在这些情况中,第$x$人对答 ...
- 007.前端开发知识,前端基础CSS(2020-01-28)
一.布局 一列固定宽度且居中 两列左窄右宽型 通栏平均分布型 1.一列固定宽度且居中布局<body> .top+.banner+.main+.footer 按Tab键,得到下框中代码 &l ...
- Exchange Onine功能介绍
Exchange Online是Office 365中提供的一个邮箱服务.Microsoft Exchange Online是将Microsoft Exchange Server功能作为基于云的服务提 ...
- XRichText
XRichText是一个可以显示Html富文本的TextView.可以用于显示新闻.商品详情等场景.欢迎star.fork,提出意见. 使用 Gradle : compile 'cn.droidlov ...
- Go-Micro框架入门教程(一)---框架结构
Go语言微服务系列文章,使用golang实现微服务,这里选用的是go-micro框架,本文主要是对该框架的一个架构简单介绍. 1. 概述 go-micro是go语言下的一个很好的微服务框架. 1.服务 ...
- @EnableGlobalMethodSecurity(prePostEnabled = true)
http://www.bubuko.com/infodetail-2243816.html