机器学习入门:极度舒适的GBDT原理拆解
机器学习入门:极度舒适的GBDT拆解
本文旨用小例子+可视化的方式拆解GBDT原理中的每个步骤,使大家可以彻底理解GBDT
Boosting→Gradient Boosting
Boosting是集成学习的一种基分类器(弱分类器)生成方式,核心思想是通过迭代生成了一系列的学习器,给误差率低的学习器高权重,给误差率高的学习器低权重,结合弱学习器和对应的权重,生成强学习器。

Boosting算法要涉及到两个部分,加法模型和前向分步算法。
加法模型就是说强分类器由一系列弱分类器线性相加而成。一般组合形式如下:
$$F_M(x;P)=\sum_{m=1}^n\beta_mh(x;a_m)$$
其中,$h(x;a_m)$就是一个个的弱分类器,$a_m$是弱分类器学习到的最优参数,$β_m$就是弱学习在强分类器中所占比重,P是所有$α_m$和$β_m$的组合。这些弱分类器线性相加组成强分类器。
前向分步就是说在训练过程中,下一轮迭代产生的分类器是在上一轮的基础上训练得来的。也就是可以写成这样的形式:
$$F_m (x)=F_{m-1}(x)+ \beta_mh_m (x;a_m)$$
Gradient Boosting = Gradient Descent + Boosting
Boosting 算法(以AdaBoost为代表)用错分数据点来识别问题,通过调整错分数据点的权重来改进模型。Gradient Boosting通过负梯度来识别问题,通过计算负梯度来改进模型。
Gradient Boosting每次迭代的目标是为了减少上一次的残差,在残差减少的梯度(Gradient)方向上建立一个新的模型,每个新的模型的建立是使之前模型的残差往梯度方向减少。
第t轮的第i个样本的损失函数的负梯度为:
$$
\large {r_{mi}} = -\left[\frac{\partial L(y_i,f(x_i))}{\partial f(x_i)} \right]{f(x)=f{m-1}(x)}
$$
此时不同的损失函数将会得到不同的负梯度,如果选择平方损失
$L(y_i,f(x_i)) = \frac{1}{2}(y_i - f(x_i))^2$
负梯度为$r_{mi} = y_i - f(x_i)$
此时我们发现GBDT的负梯度就是残差,所以说对于回归问题,我们要拟合的就是残差。

GBDT回归算法
输入是训练集样本$T={(x_,y_1),(x_2,y_2), ...(x_m,y_m)}$, 最大迭代次数T, 损失函数L。
输出是强学习器$f(x)$
- 初始化弱学习器
- 对迭代轮数t=1,2,...T有:
$f_0(x) = \underbrace{arg; min}{c}\sum\limits{i=1}^{m}L(y_i, c)$
a)对样本$i=1,2,...m$,计算负梯度
$$r_{ti} = -\bigg[\frac{\partial L(y_i, f(x_i)))}{\partial f(x_i)}\bigg]{f(x) = f{t-1};;(x)}$$
b)利用$(x_i,r_{ti});; (i=1,2,..m)$, 拟合一颗CART回归树,得到第t颗回归树,其对应的叶子节点区域为$R_{tj}, j =1,2,..., J$。其中J为回归树t的叶子节点的个数。
c) 对叶子区域$j =1,2,..J$,计算最佳拟合值
$$c_{tj} = \underbrace{arg; min}{c}\sum\limits{x_i \in R_{tj}} L(y_i,f_{t-1}(x_i) +c)$$
d)更新强学习器
$$f_{t}(x) = f_{t-1}(x) + \sum\limits_{j=1}^{J}c_{tj}I(x \in R_{tj})$$
3) 得到强学习器f(x)的表达式
$$f(x) = f_T(x) =f_0(x) + \sum\limits_{t=1}{T}\sum\limits_{j=1}{J}c_{tj}I(x \in R_{tj})$$
二元GBDT分类算法
对于二元GBDT,如果用类似于逻辑回归的对数似然损失函数,则损失函数为:
$L(y, f(x)) = log(1+ exp(-yf(x)))$
其中y∈{?1,+1}。则此时的负梯度误差为
$$r_{ti} = -\bigg[\frac{\partial L(y, f(x_i)))}{\partial f(x_i)}\bigg]{f(x) = f{t-1};; (x)} = y_i/(1+exp(y_if(x_i)))$$
对于生成的决策树,我们各个叶子节点的最佳负梯度拟合值为
$$c_{tj} = \underbrace{arg; min}{c}\sum\limits{x_i \in R_{tj}} log(1+exp(-y_i(f_{t-1}(x_i) +c)))$$
由于上式比较难优化,我们一般使用近似值代替
$$c_{tj} = \sum\limits_{x_i \in R_{tj}}r_{ti}\bigg / \sum\limits_{x_i \in R_{tj}}|r_{ti}|(1-|r_{ti}|)$$
除了负梯度计算和叶子节点的最佳负梯度拟合的线性搜索,二元GBDT分类和GBDT回归算法过程相同。
小例子+可视化理解GBDT
上面对原理进行了分析之后,大致对GBDT有了一定的认识,为了更加形象的解释GBDT的内部执行过程,这里引用《统计学习方法》中adaboost一节中的案例数据来进行进一步分析。强烈建议大家对比学习,看一下Adaboost和 GBDT 的区别和联系。
数据集如下:

采用GBDT进行训练,为了方便,我们采用MSE作为损失函数,并且将树的深度设为1,决策树个数设为5,其他参数使用默认值
import numpy as np
import pandas as pd
from sklearn import tree
import matplotlib.pyplot as plt
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.model_selection import train_test_split
X = np.arange(1,11)
y = np.array([5.56, 5.70, 5.91, 6.40, 6.80, 7.05, 8.90, 8.70, 9.00, 9.05])
display(X,y)
gbdt = GradientBoostingRegressor(n_estimators=5,max_depth=1)
gbdt.fit(X.reshape(-1,1),y)
其中GradientBoostingRegressor主要参数如下
GradientBoostingRegressor(alpha=0.9, criterion='friedman_mse', init=None,
learning_rate=0.1, loss='ls', max_depth=1,
max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=5,
n_iter_no_change=None, presort='auto',
random_state=None, subsample=1.0, tol=0.0001,
validation_fraction=0.1, verbose=0, warm_start=False)
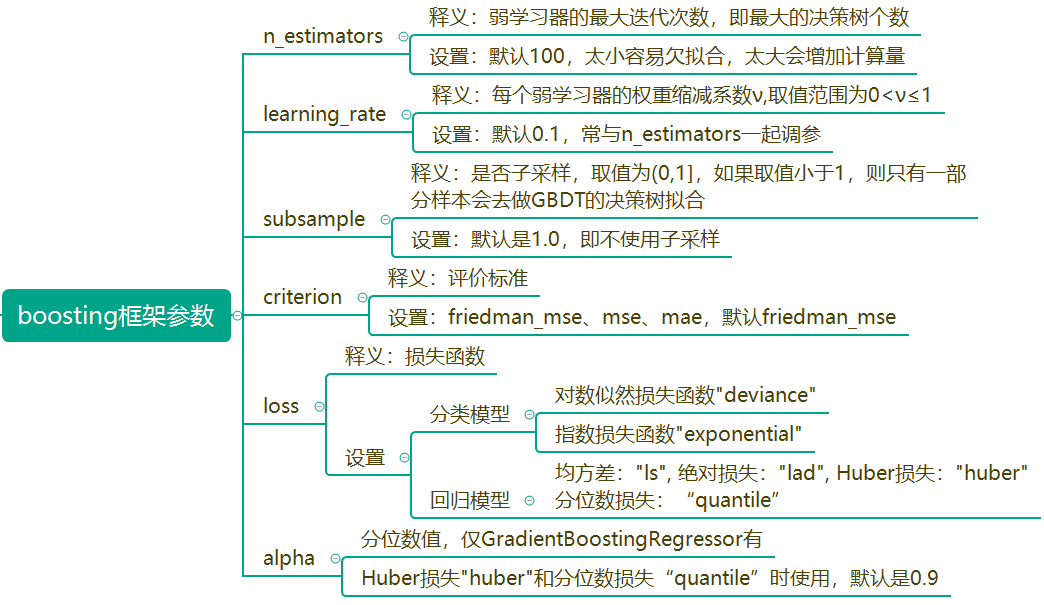
其他参数为决策树参数,大家应该已经很熟悉了,不再赘述。
下面我们根据GBDT回归算法原理,开始分步硬核拆解:
第一步:根据初始化公式
$f_0(x) = \underbrace{arg; min}{c}\sum\limits{i=1}^{m}L(y_i, c)$
可以计算出$F_{0}(x)=7.307$(本例中,恰好为yi均值)
第二步:计算损失函数的负梯度值:
$$r_{ti} = -\bigg[\frac{\partial L(y_i, f(x_i)))}{\partial f(x_i)}\bigg]{f(x) = f{t-1};; (x)}$$
由于是MSE损失,上式等于$\hat{y}i = y_i - F{m-1}(x_i)$,结果如下:
#计算残差
y - y.mean()
[out]:
array([-1.747, -1.607, -1.397, -0.907, -0.507, -0.257, 1.593, 1.393,
1.693, 1.743])
第三步:对上面残差拟合第一棵树
根据所给的数据,可以考虑的切分点为1.5、2.5、3.5、4.5、5.5、6.5、7.5、8.5、9.5分别计算$y_i - F_{0}(x_i)$的值,并计算出切分后的左右两侧加和MSE最小的切分,最后得到的是6.5
找到最佳的切分点之后,我们可以得到各个叶子节点区域,并计算出$R_{jm}$和$\gamma_{jm}$.此时,$R_{11}$为$x$小于6.5的数据,$R_{21}$为x大于6.5的数据。同时,
$$r_{11} = \frac{1}{6} \sum_{x_i \in R_{11}} y_{i}=-1.0703$$
$$r_{21} = \frac{1}{4} \sum_{x_i \in R_{21}} y_{i}=1.6055$$
print((y - y.mean())[:6].mean(),
(y - y.mean())[6:10].mean())
[out]:-1.07 1.605
#计算mse
print(
((y - y.mean())**2).mean(),
((y[:6] - y[:6].mean())**2).mean(),
((y[6:10] - y[6:10].mean())**2).mean())
[out]
1.911421 0.309689 0.0179686
第一棵树的可视化
tree.plot_tree(gbdt[0,0],filled=True)

最后:更新$F_{1}(x_i)$的值
$F_1(x_i)=F_{0}(x_i)+ \rho_m \sum^2_{j=1} \gamma_{j1} I(x_i \in R_{j1})$,其中$\rho_m$为学习率,或称shrinkage,目的是防止预测结果发生过拟合,默认值是0.1。
至此第一轮迭代完成,后面的迭代方式与上面一样,
本例中我们生成了5棵树,大家可以用tree.plot_tree可视化其他树

课后作业,大家可以思考一下,第二棵树中的value是如何计算出来的?其实很简单哈????
迭代$m$次后,第$m$次的$F_{m}(x)$即为最终的预测结果。
$$
F_{m}(x) = F_{m-1}(x) + \rho_{m} h(x; a_m)$$
参考
https://www.cnblogs.com/pinard/p/6140514.html
https://blog.csdn.net/u014168855/article/details/105481881
https://www.csuldw.com/2019/07/12/2019-07-12-an-introduction-to-gbdt/

机器学习入门:极度舒适的GBDT原理拆解的更多相关文章
- 极度舒适的 Python 入门教程,小猪佩奇也能学会~
编程几乎已经成为现代人的一门必修课,特别是 Python ,不仅长期霸占编程趋势榜.薪资榜第一,还屡屡进入小学教材,甚至成为浙江省信息技术高考项目-- 今天,小编带来了一门极度舒适的 Python 入 ...
- [转]MNIST机器学习入门
MNIST机器学习入门 转自:http://wiki.jikexueyuan.com/project/tensorflow-zh/tutorials/mnist_beginners.html?plg_ ...
- 梯度提升树(GBDT)原理小结(转载)
在集成学习值Adaboost算法原理和代码小结(转载)中,我们对Boosting家族的Adaboost算法做了总结,本文就对Boosting家族中另一个重要的算法梯度提升树(Gradient Boos ...
- 机器学习之梯度提升决策树GBDT
集成学习总结 简单易学的机器学习算法——梯度提升决策树GBDT GBDT(Gradient Boosting Decision Tree) Boosted Tree:一篇很有见识的文章 https:/ ...
- tensorfllow MNIST机器学习入门
MNIST机器学习入门 这个教程的目标读者是对机器学习和TensorFlow都不太了解的新手.如果你已经了解MNIST和softmax回归(softmax regression)的相关知识,你可以阅读 ...
- 机器学习入门:K-近邻算法
机器学习入门:K-近邻算法 先来一个简单的例子,我们如何来区分动作类电影与爱情类电影呢?动作片中存在很多的打斗镜头,爱情片中可能更多的是亲吻镜头,所以我们姑且通过这两种镜头的数量来预测这部电影的主题. ...
- Azure机器学习入门(三)创建Azure机器学习实验
在此动手实践中,我们将在Azure机器学习Studio中一步步地开发预测分析模型,首先我们从UCI机器学习库的链接下载普查收入数据集的样本并开始动手实践: http://archive.ics.uci ...
- GBDT原理及利用GBDT构造新的特征-Python实现
1. 背景 1.1 Gradient Boosting Gradient Boosting是一种Boosting的方法,它主要的思想是,每一次建立模型是在之前建立模型损失函数的梯度下降方向.损失函数是 ...
- 机器学习入门 - Google机器学习速成课程 - 笔记汇总
机器学习入门 - Google机器学习速成课程 https://www.cnblogs.com/anliven/p/6107783.html MLCC简介 前提条件和准备工作 完成课程的下一步 机器学 ...
随机推荐
- java实现第六届蓝桥杯循环节长度
循环节长度 两个整数做除法,有时会产生循环小数,其循环部分称为:循环节. 比如,11/13=6=>0.846153846153..... 其循环节为[846153] 共有6位. 下面的方法,可以 ...
- 从程序员到项目主管再到项目总监,一个IT从业者三个职业生涯阶段的工作生活日常
这是王不留的第 8 篇原创文章 前段时间写过<王不留的十多年工作和生活的流水帐>,在知乎.简书,还有不少微信的朋友私信问我每天四点钟是如何做到的?你现在的作息时间是怎么安排的? 于是,我将 ...
- 基于ABP做一个简单的系统——实战篇:1.项目准备
现阶段需要做一个小项目,体量很小,业务功能比较简单,就想到用最熟悉的.net来做,更何况现在.net core已经跨平台,也可以在linux服务器上部署.所以决定用.net core 3.1+mysq ...
- 用云开发Cloudbase,实现小程序多图片内容安全监测
前言 相比于文本的安全检测,图片的安全检测要稍微略复杂一些,当您读完本篇,将get到 图片安全检测的应用场景 解决图片的安全校验的方式 使用云调用方式对图片进行检测 如何对上传图片大小进行限制 如何解 ...
- Java虚拟机性能调优(一)
Java虚拟机监控与调优,借助Java自带分析工具. jps:JVM Process Status Tool,显示指定系统内所有的HotSpot虚拟机进程 jstat:JVM Statistics M ...
- javaweb之Servlet,http协议以及请求转发和重定向
本文是作者原创,版权归作者所有.若要转载,请注明出处. 一直用的框架开发,快连Servlet都忘了,此文旨在帮自己和大家回忆一下Servlet主要知识点.话不多说开始吧 用idea构建Servlet项 ...
- 为什么要使用Mybatis-现有持久化技术的对比
1)JDBC SQL 夹在Java代码块里,耦合度高导致硬编码内伤 维护不易且实际开发需求中SQL有变化,频繁修改的情况很多 2)Hibernate 和 JPA 长难复杂SQL, 对于Hibernat ...
- vim改变字体和查看映射的(mapping)命令
临时修改.通过gvim Command MODE,输入如下命令即可: Linux/Unix: set guifont=Monospace\空格14 注意这里需要对空格使用\进行转义 Windows: ...
- ViewDragHelper类的基本使用
在android的开发包android.support.v4.widget中有一个ViewDragHelper类.这个类的作用是帮助我们处理View的拖拽滑动.在一个ViewGroup类的内部定义一个 ...
- OO第一单元——谜之随性总结
前言 第一单元的作业主要是以多项式求导为载体来训练我们的面向对象的思维,难度循序渐进,复杂度也一直在提高,但是面向对象的体现性也越来越强,当然带来的优势与便利也在逐步提升.下面的内容主要从需求分析,代 ...