sparkRDD:第1节 RDD概述;第2节 创建RDD
RDD的特点:
(1)rdd是数据集;
(2)rdd是编程模型:因为rdd有很多数据计算方法如map,flatMap,reduceByKey等;
(3)rdd相互之间有依赖关系;
(4)rdd是可以分区的,如下图所示:
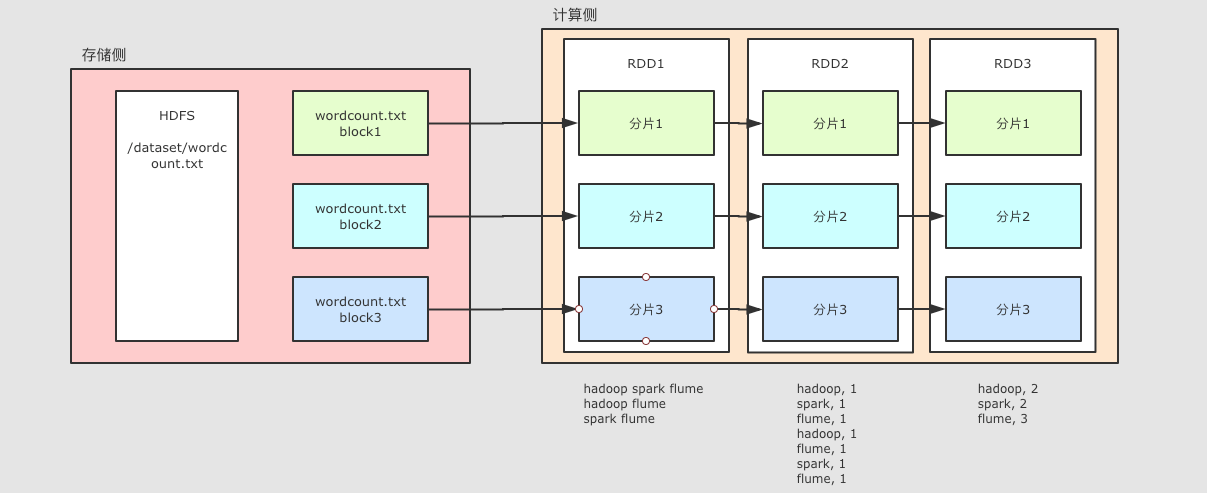
=======================================
Spark计算模型RDD
一、 课程目标
目标1:掌握RDD的原理
目标2:熟练使用RDD的算子完成计算任务
目标3:掌握RDD的宽窄依赖
目标4:掌握RDD的缓存机制
目标5:掌握划分stage
目标6:掌握spark的任务调度流程
二、 弹性分布式数据集RDD
2. RDD概述
2.1 什么是RDD
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变、可分区、里面的元素可并行计算的集合。RDD具有数据流模型的特点:自动容错、位置感知性调度和可伸缩性。RDD允许用户在执行多个查询时显式地将数据缓存在内存中,后续的查询能够重用这些数据,这极大地提升了查询速度。
Dataset:一个数据集合,用于存放数据的。
Distributed:RDD中的数据是分布式存储的,可用于分布式计算。
Resilient:RDD中的数据可以存储在内存中或者磁盘中。
2.2 RDD的属性


1) A list of partitions :一个分区(Partition)列表,数据集的基本组成单位。
对于RDD来说,每个分区都会被一个计算任务处理,并决定并行计算的粒度。用户可以在创建RDD时指定RDD的分区个数,如果没有指定,那么就会采用默认值。(比如:读取HDFS上数据文件产生的RDD分区数跟block的个数相等)
2)A function for computing each split :一个计算每个分区的函数。
Spark中RDD的计算是以分区为单位的,每个RDD都会实现compute计算函数以达到这个目的。
3)A list of dependencies on other RDDs:一个RDD会依赖于其他多个RDD,RDD之间的依赖关系。
RDD的每次转换都会生成一个新的RDD,所以RDD之间就会形成类似于流水线一样的前后依赖关系。在部分分区数据丢失时,Spark可以通过这个依赖关系重新计算丢失的分区数据,而不是对RDD的所有分区进行重新计算。
4)Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned):一个Partitioner,即RDD的分区函数(可选项)。
当前Spark中实现了两种类型的分区函数,一个是基于哈希的HashPartitioner,另外一 个是基于范围的RangePartitioner。只有对于key-value的RDD,才会有Partitioner(必须要产生shuffle),非key-value的RDD的Parititioner的值是None。
5)Optionally, a list of preferred locations to compute each split on (e.g. block locations for an HDFS file):一个列表,存储每个Partition的优先位置(可选项)。
对于一个HDFS文件来说,这个列表保存的就是每个Partition所在的块的位置。按照“移动数据不如移动计算”的理念,Spark在进行任务调度的时候,会尽可能地将计算任务分配到其所要处理数据块的存储位置(spark进行任务分配的时候尽可能选择那些存有数据的worker节点来进行任务计算)。
2.3 为什么会产生RDD?
(1) 传统的MapReduce虽然具有自动容错、平衡负载和可拓展性的优点,但是其最大缺点是采用非循环式的数据流模型,使得在迭代计算中要进行大量的磁盘IO操作。RDD正是解决这一缺点的抽象方法。
(2) RDD是Spark提供的最重要的抽象的概念,它是一种具有容错机制的特殊集合,可以分布在集群的节点上,以函数式编程来操作集合,进行各种并行操作。可以把RDD的结果数据进行缓存,方便进行多次重用,避免重复计算。
2.4 RDD在Spark中的地位及作用
(1) 为什么会有Spark?
因为传统的并行计算模型无法有效的解决迭代计算(iterative)和交互式计算(interactive);而Spark的使命便是解决这两个问题,这也是他存在的价值和理由。
(2) Spark如何解决迭代计算?
其主要实现思想就是RDD,把所有计算的数据保存在分布式的内存中。迭代计算通常情况下都是对同一个数据集做反复的迭代计算,数据在内存中将大大提升IO操作。这也是Spark涉及的核心:内存计算。
(3) Spark如何实现交互式计算?
因为Spark是用scala语言实现的,Spark和scala能够紧密的集成,所以Spark可以完美的运用scala的解释器,使得其中的scala可以向操作本地集合对象一样轻松操作分布式数据集。
(4) Spark和RDD的关系?
RDD是一种具有容错性、基于内存计算的抽象方法,RDD是Spark Core的底层核心,Spark则是这个抽象方法的实现。
3. 创建RDD
1)由一个已经存在的Scala集合创建。
val rdd1 = sc.parallelize(Array(1,2,3,4,5,6,7,8))
2)由外部存储系统的文件创建。包括本地的文件系统,还有所有Hadoop支持的数据集,比如HDFS、Cassandra、HBase等。
val rdd2 = sc.textFile("/words.txt")
3)已有的RDD经过算子转换生成新的RDD
val rdd3=rdd2.flatMap(_.split(" "))
sparkRDD:第1节 RDD概述;第2节 创建RDD的更多相关文章
- Spark RDD概念学习系列之如何创建RDD
不多说,直接上干货! 创建RDD 方式一:从集合创建RDD (1)makeRDD (2)Parallelize 注意:makeRDD可以指定每个分区perferredLocations参数,而para ...
- 【Spark】【RDD】从本地文件系统创建RDD
练习作业 完成任务从文件创建三个RDD(math bigdata student) cd ~ touch math touch bigdata touch student pwd 启动Spark-sh ...
- 创建RDD
RDD创建 在Spark中创建RDD的创建方式大概可以分为三种:从集合中创建RDD:从外部存储创建RDD:从其他RDD创建. 由一个已经存在的Scala集合创建,集合并行化,而从集合中创建RDD,Sp ...
- Spark练习之创建RDD(集合、本地文件),RDD持久化及RDD持久化策略
Spark练习之创建RDD(集合.本地文件) 一.创建RDD 二.并行化集合创建RDD 2.1 Java并行创建RDD--计算1-10的累加和 2.2 Scala并行创建RDD--计算1-10的累加和 ...
- 第一节 JavaScript概述
第一节 JavaScript概述 JavaScript:其实就是对HTML+CSS静态页面进行样式修改,使其实现各种动态效果. 编写JS脚本基本步骤: 1. HTML+CSS静态布局: 2. 确定要修 ...
- 弹性分布式数据集RDD概述
[Spark]弹性分布式数据集RDD概述 弹性分布数据集RDD RDD(Resilient Distributed Dataset)是Spark的最基本抽象,是对分布式内存的抽象使用,实现了以操作 ...
- Spark-Core RDD概述
一.什么是RDD 1.RDD(Resilient Distributed DataSet)弹性分布式数据集 2.是Spark中最基本的数据抽象 3.在代码中是一个抽象类,它代表一个弹性的.不可变的.可 ...
- 无法读取配置节“protocolMapping”,因为它缺少节声明
无法读取配置节“protocolMapping”,因为它缺少节声明 1.正常情况 : Web.config文件中有protocolMapping节点, 发现在IIS部署时使用了.NET 2.0的 ...
- 创建RDD的方式
创建RDD的方法: JavaRDD<String> lines = sc.textFile("hdfs://spark1:9000/spark.txt"); Jav ...
随机推荐
- Javascript——(2)DOM
1.DOM 1)直接寻找 (1)document.getElementById() //根据ID获取一个标签: (2) document.getElementsByName() // ...
- 面试问烂的 Spring AO,全文详解
本人免费整理了Java高级资料,涵盖了Java.Redis.MongoDB.MySQL.Zookeeper.Spring Cloud.Dubbo高并发分布式等教程,一共30G,需要自己领取.传送门:h ...
- mybatis-01-简单概述基础点
1.mybatis的优点 mybatis:半自动化持久化框架 sql(专注数据)和java编码(专注业务)分离 可使用简单的xml或者注解用于配置和原始映射 将接口和java中的pojo映射成数据库中 ...
- Java进阶学习(2)之对象交互(上)
对象交互 对象交互 对象的识别 时钟小程序 把现实世界用对象去建模,去分解问题规模,最终抽象成对象和对象的模型 例如11:03的小程序,可以抽象成一个显示类,一个类生成两个对象去表示时钟 packag ...
- 如何切换虚拟机(centos6)和windows
通过设置热键,选择Ctrl+Alt+Fx即可.重启linux之后按Ctrl+Alt+Fx切换不同的终端的就可以了 图一. 图二.
- 什么是DO / DTO / BO / VO /AO ?
转载:https://blog.csdn.net/ouzhuangzhuang/article/details/86644476 POJO 是 DO / DTO / BO / VO 的统称. DO(D ...
- 计算机二级-C语言-程序填空题-190110记录-文件写入与文件读出显示
//给定程序功能是:从键盘输入若干行文本(每行不超过80个字符),写到文件myfile4.txt中,用-1(独立一行)作为字符串输入结束的标志,然后将文件的内容读到显示在屏幕上.文件的读写分别由自定义 ...
- 一个HTTP数据包的奇幻之旅
我是一个HTTP数据包,不知谁创建了我,把我丢到这个房间. 突然,来了一个大汉,我吓得缩到角落. “该启程了,站起来”. “去哪里啊?” 我弱弱的问. “还能去哪里,你是一个数据包,当然要出远门,完成 ...
- C# 面试编程算法题
求以下表达式的值: 1. 1 - 2 + 3 - 4 + … + m public static int Foo1(int m) { ; ; i <= m; i++) { == ) { sum ...
- Spring Boot 定时任务 Quartz 使用教程
Quartz是一个完全由java编写的开源作业调度框架,他使用非常简单.本章主要讲解 Quartz在Spring Boot 中的使用. 快速集成 Quartz 介绍 Quartz 几个主要技术点 Qu ...