Tensorflow学习教程------tensorboard网络运行和可视化
tensorboard可以将训练过程中的一些参数可视化,比如我们最关注的loss值和accuracy值,简单来说就是把这些值的变化记录在日志里,然后将日志里的这些数据可视化。
首先运行训练代码

#coding:utf-8
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data #载入数据集
mnist = input_data.read_data_sets("MNIST_data", one_hot=True)
#每个批次的大小
batch_size = 100
#计算一共有多少个批次
n_batch = mnist.train.num_examples // batch_size #参数概要 传入一个参数可以计算这个参数的各个相关值
def variable_summaries(var):
with tf.name_scope('summaries'):
mean = tf.reduce_mean(var)
tf.summary.scalar('mean', mean)#平均值
with tf.name_scope('stddev'):
stddev = tf.sqrt(tf.reduce_mean(tf.square(var - mean)))
tf.summary.scalar('stddev', stddev)#标准差
tf.summary.scalar('max', tf.reduce_max(var))#最大值
tf.summary.scalar('min', tf.reduce_min(var))#最小值
tf.summary.histogram('histogram', var)#直方图 with tf.name_scope('input'):
#定义两个placeholder
x = tf.placeholder(tf.float32, [None,784],name='x-input') #输入图像
y = tf.placeholder(tf.float32, [None,10],name='y-input') #输入标签
#创建一个简单的神经网络 784个像素点对应784个数 因此输入层是784个神经元 输出层是10个神经元 不含隐层
#最后准确率在92%左右
with tf.name_scope('layer'):
with tf.name_scope('wights'):
W = tf.Variable(tf.zeros([784,10]),name = 'W') #生成784行 10列的全0矩阵
variable_summaries(W)
with tf.name_scope('biases'):
b = tf.Variable(tf.zeros([1,10]),name='b')
variable_summaries(b)
with tf.name_scope('softmax'):
prediction = tf.nn.softmax(tf.matmul(x,W)+b) #二次代价函数
#loss = tf.reduce_mean(tf.square(y-prediction))
#交叉熵损失
with tf.name_scope('loss'):
loss =tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels =y,logits = prediction))
tf.summary.scalar('loss',loss)
#使用梯度下降法
#train_step = tf.train.GradientDescentOptimizer(0.2).minimize(loss)
train_step = tf.train.AdamOptimizer(1e-3).minimize(loss) #学习率一般设置比较小 收敛速度快 #初始化变量
init = tf.global_variables_initializer() #结果存放在布尔型列表中
#argmax能给出某个tensor对象在某一维上的其数据最大值所在的索引值
with tf.name_scope('accuracy'):
with tf.name_scope('correct_prediction'):
correct_prediction = tf.equal(tf.argmax(y,1), tf.argmax(prediction,1))
with tf.name_scope('accuracy'):
accuracy = tf.reduce_mean(tf.cast(correct_prediction,tf.float32))
tf.summary.scalar('accuracy',accuracy)
#合并所有的summary
merged = tf.summary.merge_all()
with tf.Session() as sess:
sess.run(init)
writer = tf.summary.FileWriter('/home/xxx/logs/',sess.graph) #定义记录日志的位置
for epoch in range(50):
for batch in range(n_batch): #
batch_xs,batch_ys = mnist.train.next_batch(batch_size)
summary,_ = sess.run([merged,train_step],feed_dict={x:batch_xs,y:batch_ys})
writer.add_summary(summary,epoch) #将summary epoch 写入到writer
acc = sess.run(accuracy,feed_dict={x:mnist.test.images, y:mnist.test.labels})
print ("Iter " + str(epoch) + ",Testing Accuracy " + str(acc))
注意我将训练日志保存在 /home/xxx/logs/ 路径下,打开终端,输入以下命令 tensorboard --logdir=/home/xxx/logs/ 如下图所示
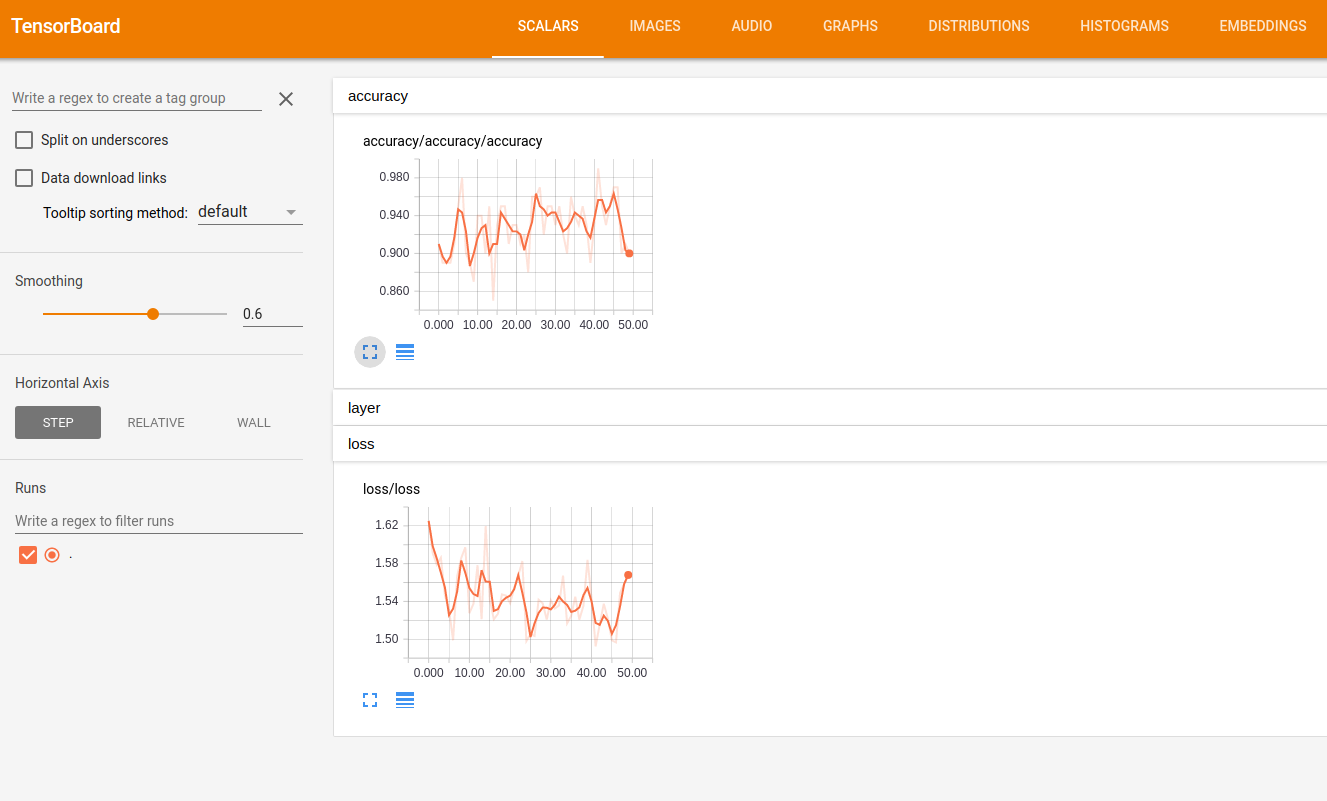
在浏览器中输入127.0.0.1:6006,可以看到可视化效果,如loss和accuracy的变化折线图
Tensorflow学习教程------tensorboard网络运行和可视化的更多相关文章
- Tensorflow学习教程------读取数据、建立网络、训练模型,小巧而完整的代码示例
紧接上篇Tensorflow学习教程------tfrecords数据格式生成与读取,本篇将数据读取.建立网络以及模型训练整理成一个小样例,完整代码如下. #coding:utf-8 import t ...
- Tensorflow学习教程------过拟合
Tensorflow学习教程------过拟合 回归:过拟合情况 / 分类过拟合 防止过拟合的方法有三种: 1 增加数据集 2 添加正则项 3 Dropout,意思就是训练的时候隐层神经元每次随机 ...
- Tensorflow学习教程------代价函数
Tensorflow学习教程------代价函数 二次代价函数(quadratic cost): 其中,C表示代价函数,x表示样本,y表示实际值,a表示输出值,n表示样本的总数.为简单起见,使用一 ...
- tensorflow学习笔记----TensorBoard讲解
TensorBoard简介 TensorBoard是TensorFlow自带的一个强大的可视化工具,也是一个Web应用程序套件.TensorBoard目前支持7种可视化,Scalars,Images, ...
- tensorflow 学习教程
tensorflow 学习手册 tensorflow 学习手册1:https://cloud.tencent.com/developer/section/1475687 tensorflow 学习手册 ...
- Tensorflow学习教程------利用卷积神经网络对mnist数据集进行分类_利用训练好的模型进行分类
#coding:utf-8 import tensorflow as tf from PIL import Image,ImageFilter from tensorflow.examples.tut ...
- Tensorflow学习教程------创建图启动图
Tensorflow作为目前最热门的机器学习框架之一,受到了工业界和学界的热门追捧.以下几章教程将记录本人学习tensorflow的一些过程. 在tensorflow这个框架里,可以讲是若数据类型,也 ...
- Tensorflow学习教程------lenet多标签分类
本文在上篇的基础上利用lenet进行多标签分类.五个分类标准,每个标准分两类.实际来说,本文所介绍的多标签分类属于多任务学习中的联合训练,具体代码如下. #coding:utf-8 import te ...
- Tensorflow学习教程------非线性回归
自己搭建神经网络求解非线性回归系数 代码 #coding:utf-8 import tensorflow as tf import numpy as np import matplotlib.pypl ...
随机推荐
- linux7 安装Docker
Docker:用白话文简单介绍就是一个集装箱,可以将其运行环境及依赖打包,方便各种场合使用.Docker 让开发者可以打包他们的应用以及依赖包到一个可移植的容器中,然后发布到任何流行的 Linux 机 ...
- Day5-T3
原题目 要开运动会了,神犇学校的n个班级要选班服,班服共有100种样式,编号1~100.现在每个班都挑出了一些样式待选,每个班最多有100个待选的样式.要求每个班最终选定一种样式作为班服,且该班的样式 ...
- Minikube安装
参考 https://blog.csdn.net/liumiaocn/article/details/52041726?locationNum=4&fps=1 中文社区API http://d ...
- python 数据处理 对txt文件进行数据处理
数据: 对txt文件进行数据处理: txt_file_path = "basic_info.txt" write_txt_file_path = "basic_info1 ...
- python 输入年月日,返回当天是星期几
引入内置模块calendar,输入年.月.日,根据weekday(year,month,day)的返回值,输出该日期是星期几.函数weekday()返回0-6分别对应星期一至星期日 import ca ...
- SpringBoot---条件(th:if)
Thymeleaf 的条件判断是 通过 th:if 来做的,只有为真的时候,才会显示当前元素 <p th:if="${testBoolean}" >如果testBool ...
- Numpy中np.random.randn与np.random.rand的区别,及np.mgrid与np.ogrid的理解
np.random.randn是基于标准正态分布产生的随机数,np.random.rand是基于均匀分布产生的随机数,其值在[0,1). np.mgrid 与np.ogrid的理解及区别:np.mgr ...
- MFC 状态栏的使用 CstatusBar
你在源文件头文件声明一下 CStatusBar zhuangtailan; 然后在窗口初始化添加以下代码 zhuangtailan.Create(this);//意思是在本窗口创建 UINT id ...
- Day 29:HTML常用标签
软件的结构: cs结构的软件的缺点:更新的时候需要用户下载更新包然后再安装,需要开发客户端与服务端. cs结构软件的优点: 减轻服务端的压力,而且可以大量保存数据在客户端. C/S(Client ...
- 51nod 1276:岛屿的数量 很好玩的题目
1276 岛屿的数量 题目来源: Codility 基准时间限制:1 秒 空间限制:131072 KB 分值: 20 难度:3级算法题 收藏 取消关注 有N个岛连在一起形成了一个大的岛屿,如果海平 ...